之前初步探索了强化学习TD3算法。
https://blog.csdn.net/liliang199/article/details/158321952
TD3是解决DDPG中因函数近似误差导致的Q值过高估计问题。
这里进一步分析TD3算法的理论推导过程,尝试从新的角度理解TD3算法。
1 TD3流程
TD3流程如下所示
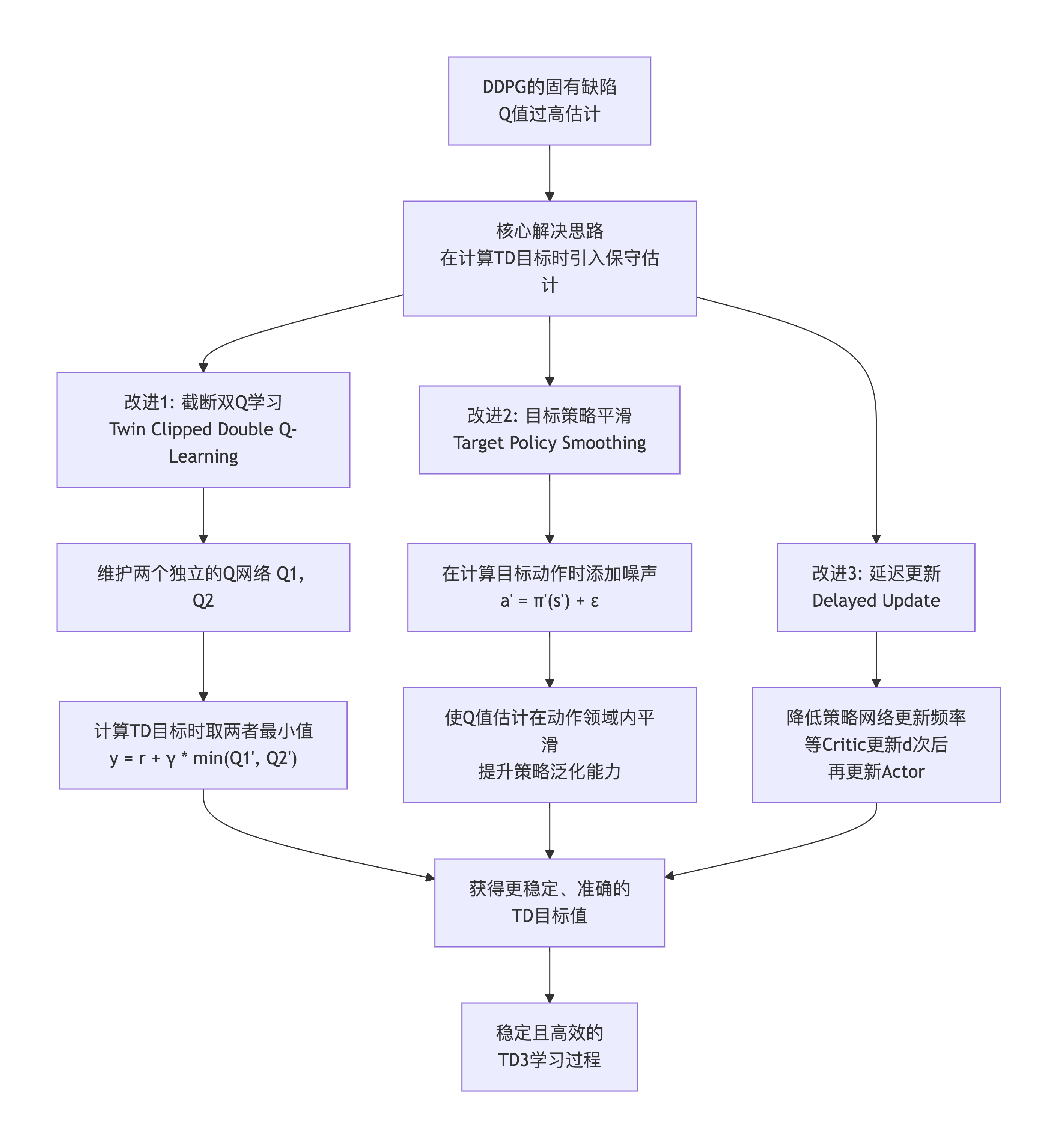
TD3算法主要围绕Critic(价值网络)和Actor(策略网络)的更新展开。
2 Critic网络推导
Critic网络的目标是构建更可靠的学习目标,准确评估状态-动作对的价值。
在TD3中,这一步的推导引入了前两项关键改进。
2.1 目标策略平滑
目标策略平滑(Target Policy Smoothing),作用是防止Critic对某些动作产生过高估计,使价值估计更平滑。
计算目标值时,不会直接使用目标策略网络
输出的下一个动作
,而是给它添加一个截断的噪声
。
这里是从均值为0、标准差为
的正态分布中采样,并截断在
范围内。
相当于在目标动作周围构建了一个邻域,要求Critic对这个邻域内的动作都给出相近的价值估计。
2.2 截断双Q学习
截断双Q学习(Clipped Double Q-Learning)直接解决单估计器带来的过高估计问题。
TD3维护两个Critic网络和
,以及对应的目标网络
和
。
在计算目标值时,对于由目标策略平滑得到的动作
,两个目标Critic网络分别给出估计值。
TD3取其中的较小值作为最终的目标值。这一取小操作是抑制过高估计的关键。
其中,是奖励,
是折扣因子,
表示是否结束。
2.3 Critic网络的损失函数
得到了目标值 后,两个Critic网络的更新方式就是标准的回归问题。
它们损失函数是均方误差MSE,目标是让自己的预测值尽可能地接近目标值
。
3 Actor网络推导
Actor的目标是找到能最大化价值的动作。这一步的推导引入了第三项关键改进:延迟更新。
3.1 延迟的策略更新
即Delayed Policy Updates,在Critic的价值估计尚未稳定时,避免Actor盲目地迎合可能错误的估计,从而减少震荡和发散。
Actor的更新频率低于Critic。通常,每更新2次Critic,才更新1次Actor。这确保了Actor总是在一个相对准确的价值函数面上进行梯度上升。
3.2 Actor网络策略梯度
当轮到Actor更新时,它使用其中一个Critic,通常为的输出来指导自己。
其目标是最大化期望回报。在实际计算中,通过对采样批次求平均来近似梯度。
直观感觉,对于采样状态,Actor输出动作
获得Critic 即
评分尽可能高。
4 参数更新训练流程
最后,整个网络的参数更新方式如下,这使得上述推导能够闭环:
1)Critic网络
通过最小化各自的损失函数来更新参数
,
。
2)Actor网络
通过最大化即最小化
来更新参数
。
3)目标网络更新
采用软更新,即Polyak Averaging方式,缓慢地将当前网络的参数复制给目标网络,以稳定训练。
其中是一个很小的数(如 0.005)。
reference
Twin-Delayed DDPG (TD3)
https://skrl.readthedocs.io/en/develop/api/agents/td3.html
Twin Delayed DDPG
https://spinningup.readthedocs.io/zh-cn/latest/algorithms/td3.html#pseudocode
强化学习算法TD3的探索和学习
https://blog.csdn.net/liliang199/article/details/158321952
Twin-Delayed Deep Deterministic (TD3) Policy Gradient Agent
强化学习之图解PPO算法和TD3算法