📖 点击展开/收起 文章目录
文章目录
- <本节内容简介>
- 归并排序(外排序)
-
- 外排序的意义以及原理
- [1. 生成随机数据(data.txt)](#1. 生成随机数据(data.txt))
- [2. 取n个数据排好序到文件中](#2. 取n个数据排好序到文件中)
- [3. 归并文件](#3. 归并文件)
- [4. 文件归并排序](#4. 文件归并排序)
- 计数排序
- 下面我来总结一下各大排序的稳定性与时间复杂度
- 在这里我们也是终于结束了排序,结束了我们的初阶数据结构的章节,道阻且长,我们还需努力,下一章节我会开启C++,感谢大家的支持
<本节内容简介>
- 计划任务
- 外排序归并
- 硬盘删除原理讲解
- 计数排序
- 总结各大排序的时间复杂度和稳定性
归并排序(外排序)
外排序的意义以及原理
其实我们的排序是分为内排序外排序的,
内排序 : 在内存中排序
外排序 : 要在硬盘操纵
如今我们学的排序中只有归并是外排序
外排序的意义但数据量巨大的时候,超过分派的内存大小,这时候就是外排序发力的时候
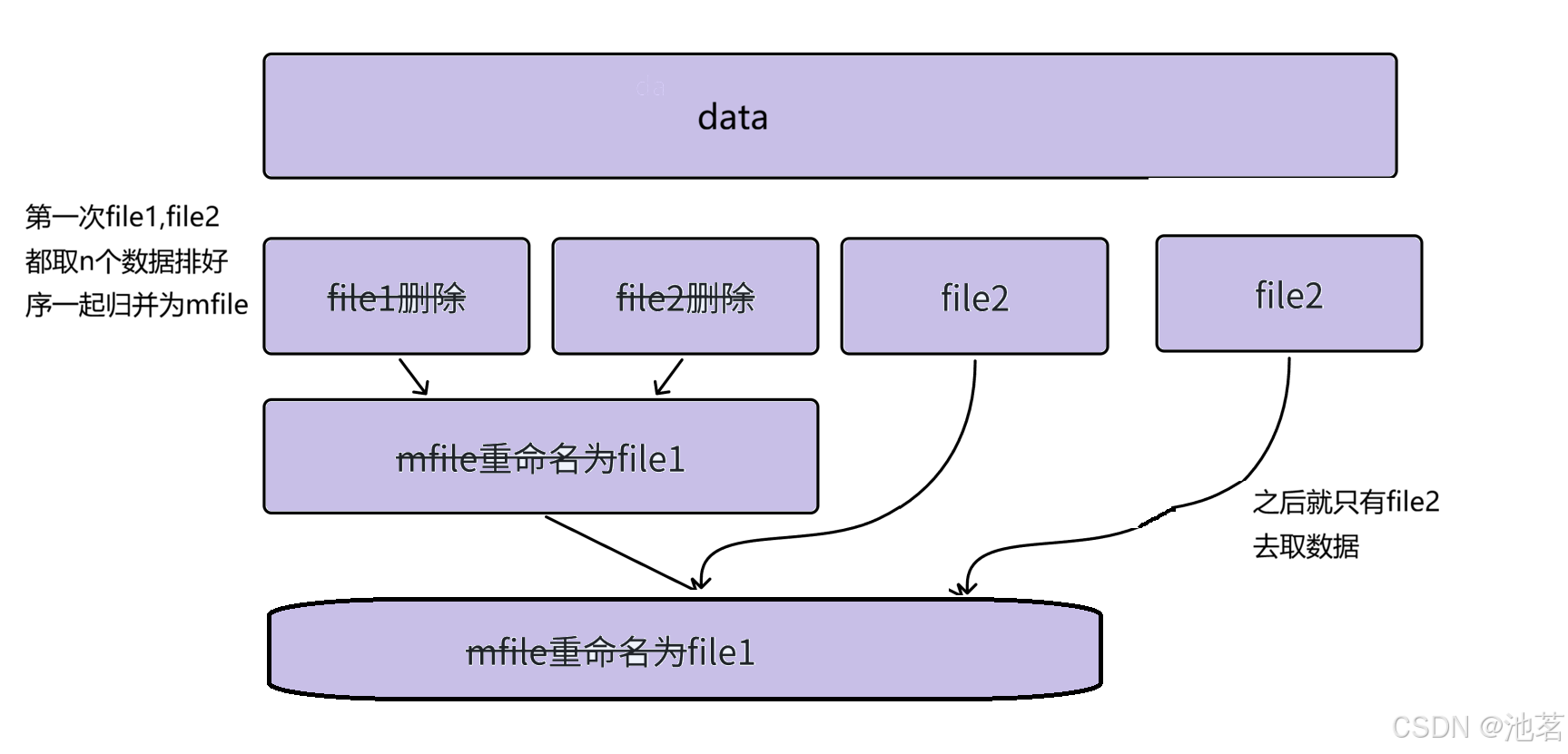
文件归并排序思路:
这里需要四个文件,data.txt(原始数据) file1.txt, file2.txt, mfile.txt
1. 生成随机数据(data.txt)
我这里造数据只在注释里面略讲,详细步骤请去下面链接
创造数据的讲解,堆排序
c
void CreatData(int n)
{
const char* file = "data.txt";
FILE* fin = fopen(file, "w");//这里w是双引号
if (fin == NULL)
{
perror("fopen fail");
exit(-1);
}
for (int i = 0; i < n; i++)
{
int x = rand() % 10000 + i;
//注意这里写文件要在每个数据后面加'\n'不加的话,存入文件中间数据会连成一片,无法正确读取
fprintf(fin, "%d\n", x);
}
// 打开文件之后不要忘记关闭文件
fclose(fin);
}2. 取n个数据排好序到文件中
解读一下这里的参数,
- 这里
FILE* fout是在void MergeFileSort(const char* data, int n)中打开的data.txt传入这个是为了在上次读的数据基础上,继续往读数据, a是数组,用于存放每次读到的N个数据,得到之后排序,再往传入的file中间写const char* file是读取N个数据排序好,存入这个文件中int n每次都读n个数据
当然这里可能会遇到一个问题,加入读不到N个数据,data中没有足够N个数据的量咋办?
这就是我们给个返回值的好处,每次返回读到的数据个数
下面是fscanf返回值的文档表述
这里我建议大家去查英文文档,不会的单词可以自己查,不要机翻,程序员是因该会看英文文档的,在后面的C++部分我会经常给大家展示英文文档
下面是原文档链接大家可以自己进去看看
C/C++英文文档

这段英文讲的是什么呢?
返回值是成功匹配并赋值的输入项个数
举个例子:fscanf(fp, "%d %s", &n, str)
- 如果成功读入一个整数和一个字符串,返回 2;
- 如果只成功读入整数(第二个匹配失败),返回 1;
- 如果第一个匹配就失败,返回 0;
- 如果遇到文件末尾或发生输入错误,返回 EOF(通常为 -1)
利用fscanf返回值只要没读到文件末尾,我num++,num就可以做计数器来记录读入了多少个数据
在进行我文件操作别忘记关闭文件,打开文件要进行检查,与malloc类似
c
int ReadNDataToFile(FILE* fout, const char* file, int n,int* a)
{
int num = 0; int x;
//利用fscanf返回值只要没读到文件末尾,我num++,num就可以做计数器来记录读入了多少个数据
while (num<n&& fscanf(fout, "%d", &x) != EOF)
{
a[num++] = x;
}
if (num == 0)return 0;
//排序数据
HeapSort(a, num);
//打开文件
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen fail");
exit(-1);
}
//向文件file中写入读到的num个数据
for (int i = 0; i < num; i++)
{
fprintf(fin, "%d\n", a[i]);
}
//关闭文件
fclose(fin);
return num;
}3. 归并文件
c
void MergeFile(const char* file1, const char* file2, const char* mfile)
{
//打开三个文件
FILE* fout1 = fopen(file1, "r");
FILE* fout2 = fopen(file2, "r");
FILE* mfin = fopen(mfile, "w");
int ret1,ret2,x1,x2;
//接收返回值,如果读到文件末尾,只要有一个文件读到文件末尾就跳出循环
ret1 = fscanf(fout1, "%d", &x1);
ret2 = fscanf(fout2, "%d", &x2);
while (ret1!=EOF&&ret2!=EOF)
{
if (x1>x2)
{
fprintf(mfin, "%d\n", x2);
ret2 = fscanf(fout2, "%d", &x2);
}
else
{
fprintf(mfin, "%d\n", x1);
ret1 = fscanf(fout1, "%d", &x1);
}
}
//将剩余一个文件中剩余数据写入文件mfile
while (ret1 != EOF)
{
fprintf(mfin, "%d\n", x1);
ret1 = fscanf(fout1, "%d", &x1);
}
while (ret2 != EOF)
{
fprintf(mfin, "%d\n", x2);
ret2 = fscanf(fout2, "%d", &x2);
}
//记得关闭文件
fclose(fout1);
fclose(fout2);
fclose(mfin);
}4. 文件归并排序
核心部分
先归并两文件
移除flie1,file2
重名名mflie为file1
循环终止条件
ReadNDataToFile(fout, file2, m,a) == 0我们设计返回值就起作用了当不再能从data中读到数据,证明我们把它读完了
这里要用到几个没见过的函数
这里传参很简单我就不讲了,也很好理解
while (1)
{
MergeFile(file1, file2, mfile);
remove(file1);
remove(file2);
rename(mfile, file1);
if (ReadNDataToFile(fout, file2, m,a) == 0)
break;
}
c
void MergeFileSort(const char* data, int n)
{
srand((unsigned int)time(0));
FILE* fout = fopen(data, "r");
if (fout == NULL)
{
perror("fopen fail");
exit(-1);
}
//设置每次读入数据的量
int m = 1000000;
int* a = (int*)malloc(m*sizeof(int));
if (a == NULL)
{
perror("malloc fail");
exit(-1);
}
//给文件命名
const char* file1 = "file1.txt";
const char* file2 = "file2.txt";
const char* mfile = "mfile.txt";
//第一次写入数据
ReadNDataToFile(fout, file1, m,a);
ReadNDataToFile(fout, file2, m,a);
while (1)
{
MergeFile(file1, file2, mfile);
remove(file1);
remove(file2);
rename(mfile, file1);
//循环终止条件
if (ReadNDataToFile(fout, file2, m,a) == 0)
break;
}
//关闭文件,释放开的空间
free(a);
fclose(fout);
}
我在观察文件归并时发现了一个问题,每次读的数据量越大,文件归并排序就越快,而且在不同数据量下有些文件会出现有些文件不会出现 我开始以为我写错代码逻辑了但是我去查了一下资料,并不是我写错逻辑
出现这种现象的原因:是文件打开/关闭的次数和 Windows 文件资源管理器刷新频率之间的关系。
当每次读入的数据量小(比如 10 万条) → 归并轮数多 → 你需要反复打开、关闭、删除、重命名文件
然而最费时间的就是文件打开与关闭内部那些排序反而并不是很费时间,在内存中排100万数据与排10万个数据区别不大都是一瞬间的事情主要还是打开与关闭文件
Windows 资源管理器的刷新不是实时,它的刷新间隔通常是 几百毫秒到几秒。
你能看见中间文件,不是因为操作慢,而是因为操作次数多且分布在较长的时间轴上,刚好撞上了 Windows 的定时刷新;你看不见,是因为操作次数太少、太快,刷新还没来得及"拍照"就已经结束了。
每次读写文件时的打开关闭文件都是在留时间给Windos文件资源管理器来刷新文件来给你看到
因此你看到的那些文件不是是实时文件状态,只是某个时间的一张快照
- m==100000每次读一百万个数据
- m==100000每次读十万个数据

- m==100000每次读十万个数据
由此我延伸又问了deepseek一些问题
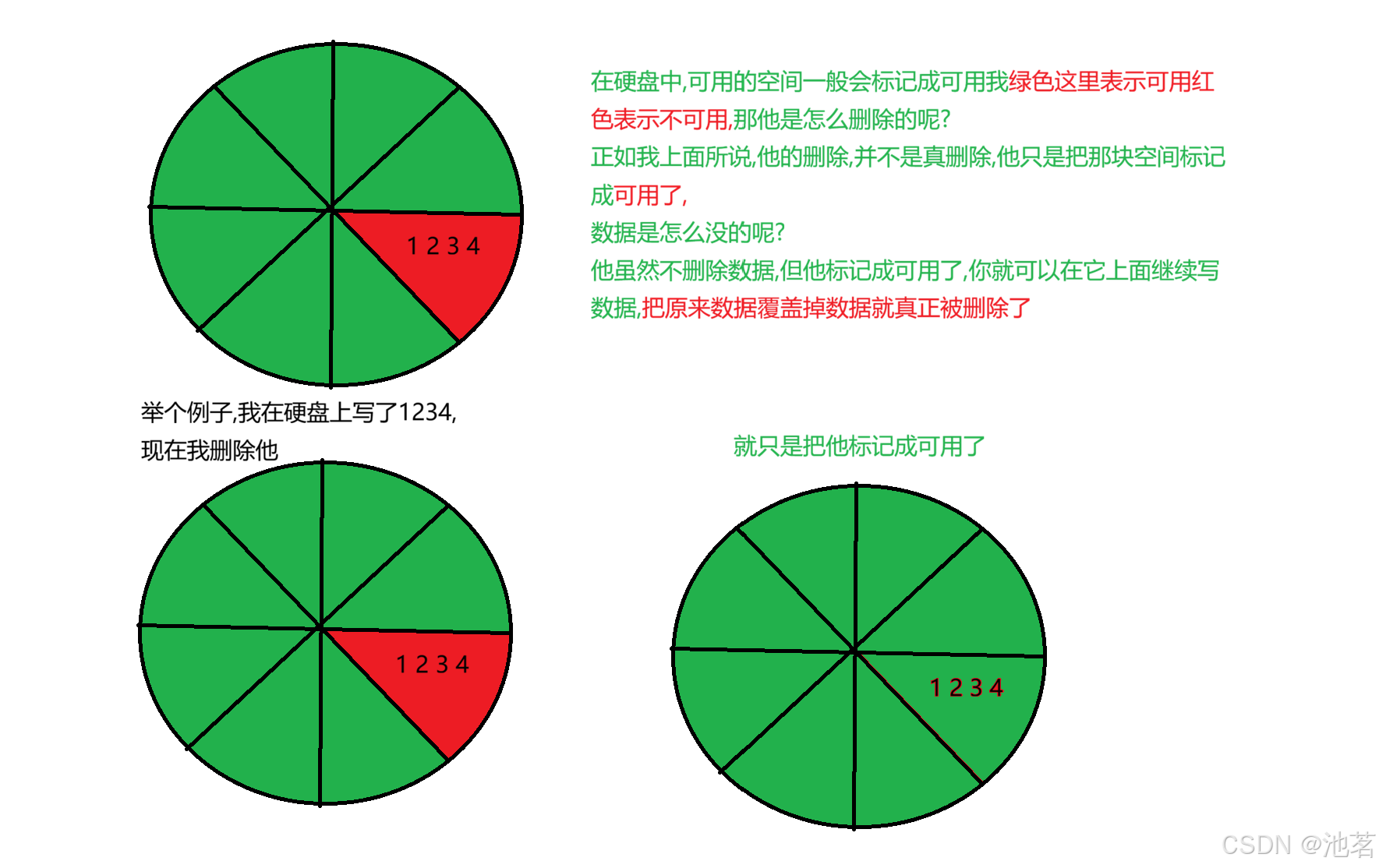
我问他remove是真正把数据删除了吗?物理消失了吗?
-
一. 机械硬盘
-
逻辑上是"真删除":这和你用 Shift+Delete 直接删除文件是一样的,文件路径会立即从文件系统中"消失",自然也不会进入回收站,所以你用常规方法找不到它。
-
物理上可能是"假删除":文件路径虽然看不见了,但只要磁盘空间没被新数据覆盖,通过专业数据恢复软件就能找回来。这是因为 remove 只是在硬盘的"目录"上做了个标记,告诉系统这个位置的数据可以覆盖了。
上面只是我了解到的浅薄知识,如有不对,请批评
在电脑中,我们多了一步回收站,回收站就不会标记成可用,为了让你反悔恢复文件,他暂时不让那片空间可用,你可以做个实验,你把1G数据的文件手动删除,到回收站,你会发现那个硬盘上可用空间没有增大,但你从回收站把该文件彻底删除,他就会增大 -
二. SSD硬盘
-
- TRIM指令:当你删除文件时,操作系统会立刻发送TRIM指令给SSD。SSD收到后,实际擦除那些闪存块中的数据(标记为无效并立即回收)。所以文件数据可能在几毫秒内就被物理擦除,不再像机械硬盘那样"只改标记、数据暂留"。
-
- 写入放大与垃圾回收:SSD不能覆盖写,必须先擦除整个块才能写入新数据。为了性能,SSD固件会后台做垃圾回收------提前把无效页擦除。这意味着删除操作很可能被立即执行物理擦除。
-
- 磨损均衡:为了延长寿命,SSD会把数据分布在不同的闪存单元。即使你只删除一个小文件,它可能早已被移动过多次,删除后原始位置的数据也可能被其他数据覆写。
-
结果:在SSD上误删文件后,恢复成功率远低于机械硬盘。因为数据可能已被TRIM和垃圾回收彻底清除。恢复工具往往无法直接读取被TRIM过的块(SSD返回的全是0)。只有极少数专业实验室能在SSD主控层面尝试恢复,成本极高。
由此,我们想想这样有什么应用呢?
-
- 数据恢复
别再花很多钱去找电脑维修店脑版恢复数据了,既然你了解到了有这些原理,恢复数据也就不神奇了,市面上有很多成熟免费的软件下面分享一下
-- Recuva:个人使用完全免费,界面友好,有深度扫描模式。适合恢复误删的照片、文档。
-- TestDisk & PhotoRec:开源免费,功能极为强大。TestDisk 擅长恢复分区表、修复启动扇区;PhotoRec 则是"签名恢复"的典范------它不管你原来是什么文件系统,直接根据文件头尾去硬盘里捞数据。你在课堂上学的"文件有固定头部"这一点,就是 PhotoRec 的工作基础。
- 数据恢复
注意: 既然了解到原理,你误删文件尽量越早恢复文件越好,因为文件位置被复写了就不好恢复了,另外SSD硬盘删除机制更复杂,不易恢复
-
- steam第一次下载过的游戏,第二次下载会很快
在steam他会有depotcache,一些游戏缓存,你删除了游戏,这些缓存还在你电脑里面
重复下载就会很快
- steam第一次下载过的游戏,第二次下载会很快
计数排序
-
- 简单来说,计数排序就是造出来一个初始化为零的数组,等遍历原数组,大小与原数组大小一致的,就在计数数组对应下标位置加1
类似于下图
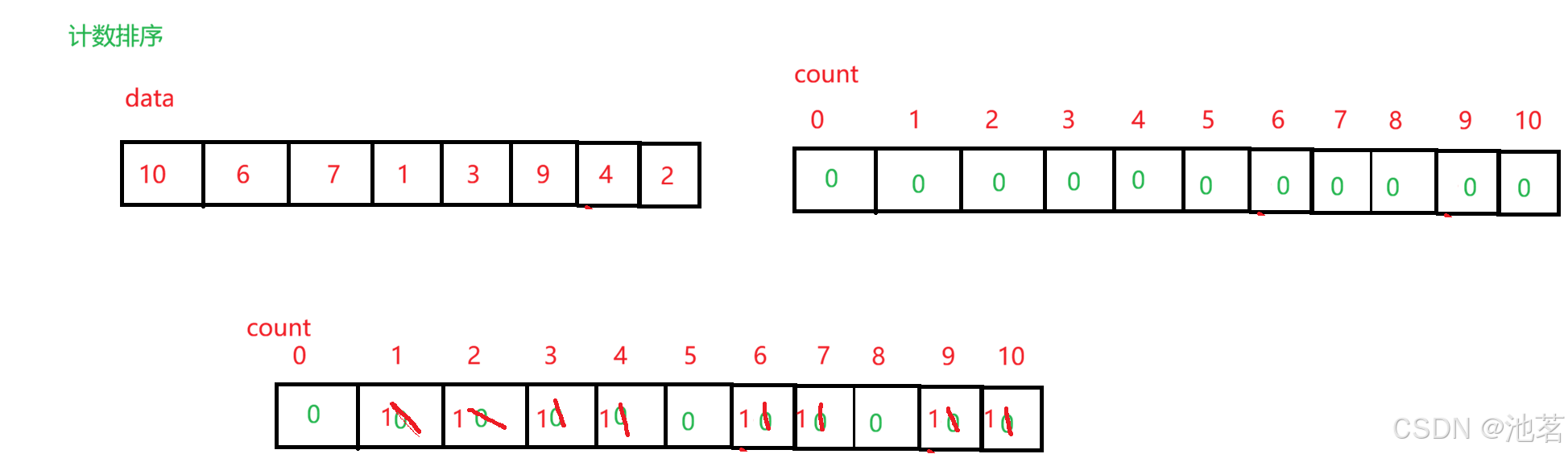
- 简单来说,计数排序就是造出来一个初始化为零的数组,等遍历原数组,大小与原数组大小一致的,就在计数数组对应下标位置加1
-
- 但问题应运而生,如果这样的话数组下标代表值,空间复杂度就高了

- 但问题应运而生,如果这样的话数组下标代表值,空间复杂度就高了
-
- 那他是怎么排序的?
有了计数数组,原来每个值在count\[\]数组中都标记有位置而且是按有序排列
我们遍历count数组如果为零我就跳过,大于零,我就取她的下标放到我这个位置
如下图动画
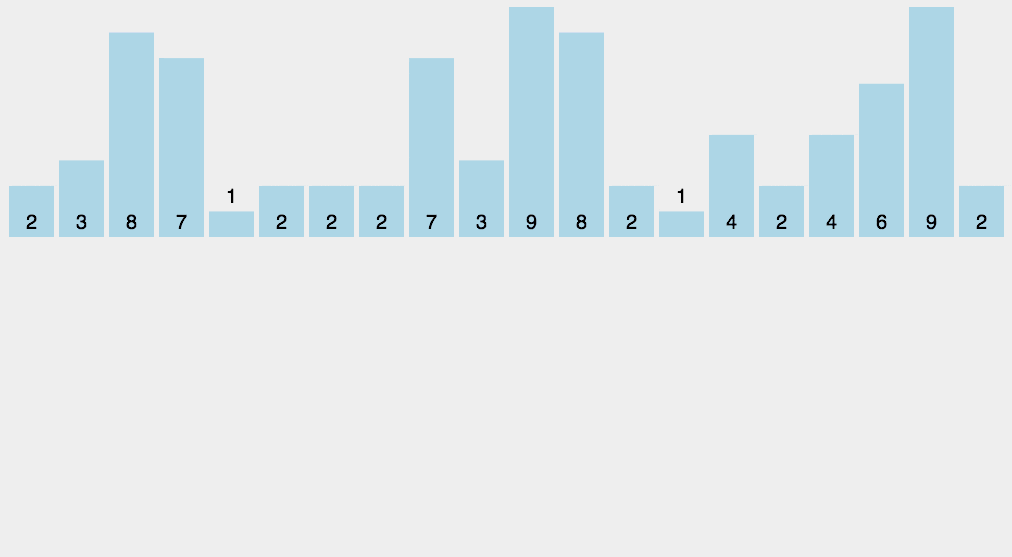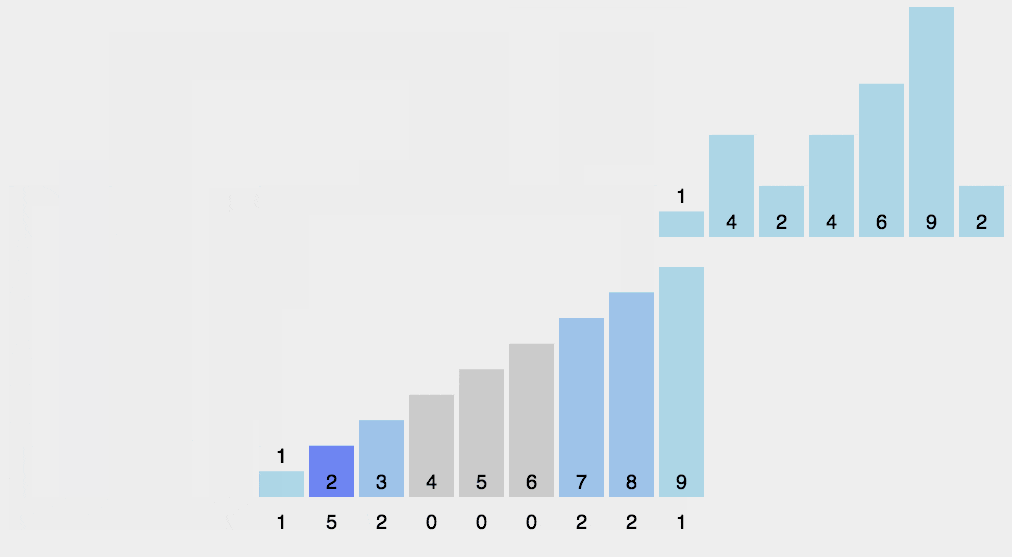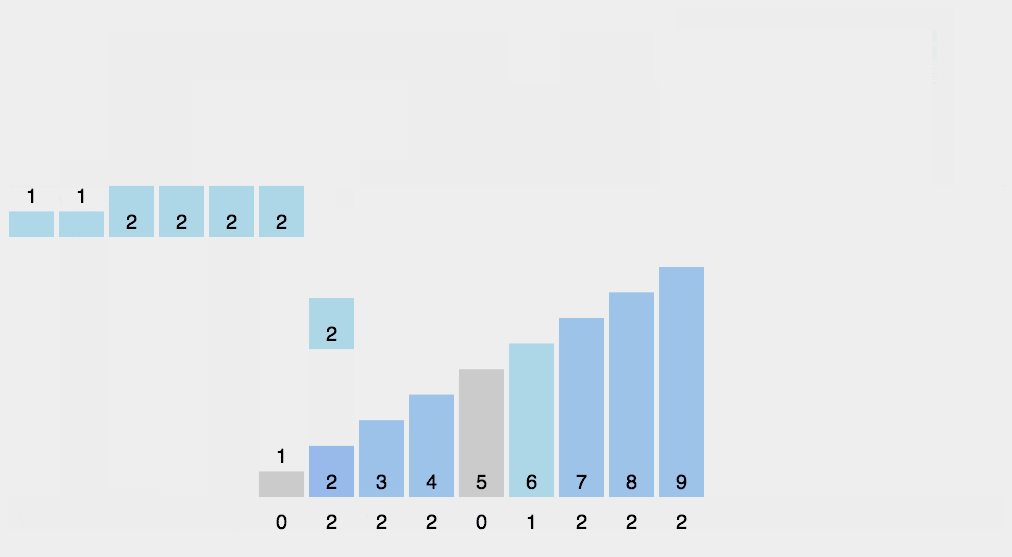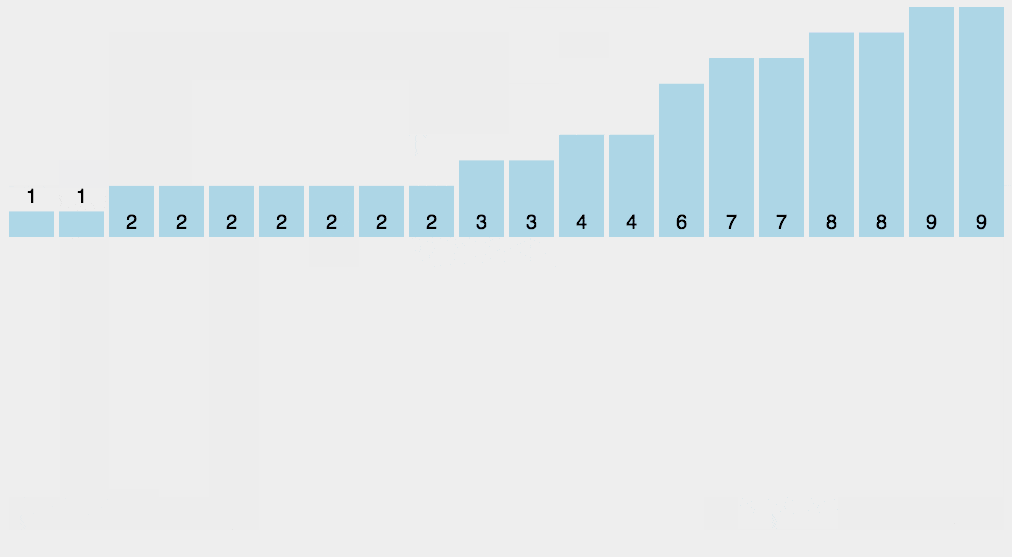
他的时间复杂度是O(N),但也有极大的局限性,如果1,100000这种相差巨大的数据,她的空间就开得很大浪费空间,因此他很不常用
- 那他是怎么排序的?
c
void CountSort(int* a, int n)
{
int max, min,i;
max = min = a[0];
for (i = 0; i < n; i++) {
if (a[i] > max) {
max = a[i];
}
if (a[i] < min) {
min = a[i];
}
}
int range = max - min + 1;
int* count = (int*)calloc(range,sizeof(int));
if (count == NULL){
perror("calloc fail");
return;
}
for ( i = 0; i < n; i++){
count[a[i]-min]++;
}
i = 0;
for (int j = 0; j < range; j++){
while (count[j]--){
a[i++] = j+min;
}
}
free(count);
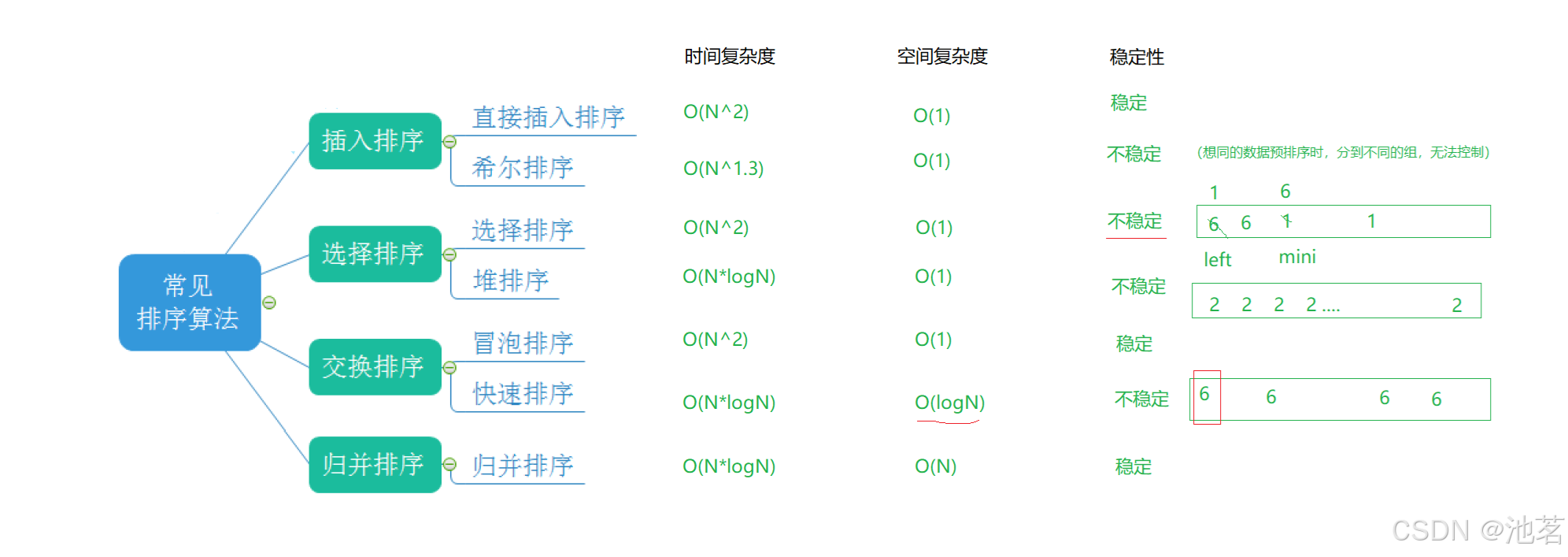
}下面我来总结一下各大排序的稳定性与时间复杂度
首先解释一下稳定性
排序的稳定性是指:在待排序的序列中,如果存在两个相等的元素(比如两个人都叫"张三",或者两个数值都是 5),排序后,它们原来的相对前后顺序保持不变。
简单说:稳定排序不会打乱原本相等元素之间的次序;不稳定排序可能会打乱。