一、创建虚拟环境
首先创建虚拟环境
conda create -n ai_dev激活虚拟环境
conda activate ai_dev使用conda安装pytorch
conda 会自动处理 CUDA 版本兼容和依赖,避免 pip 安装时的版本不匹配问题
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidiapytorch安装成功
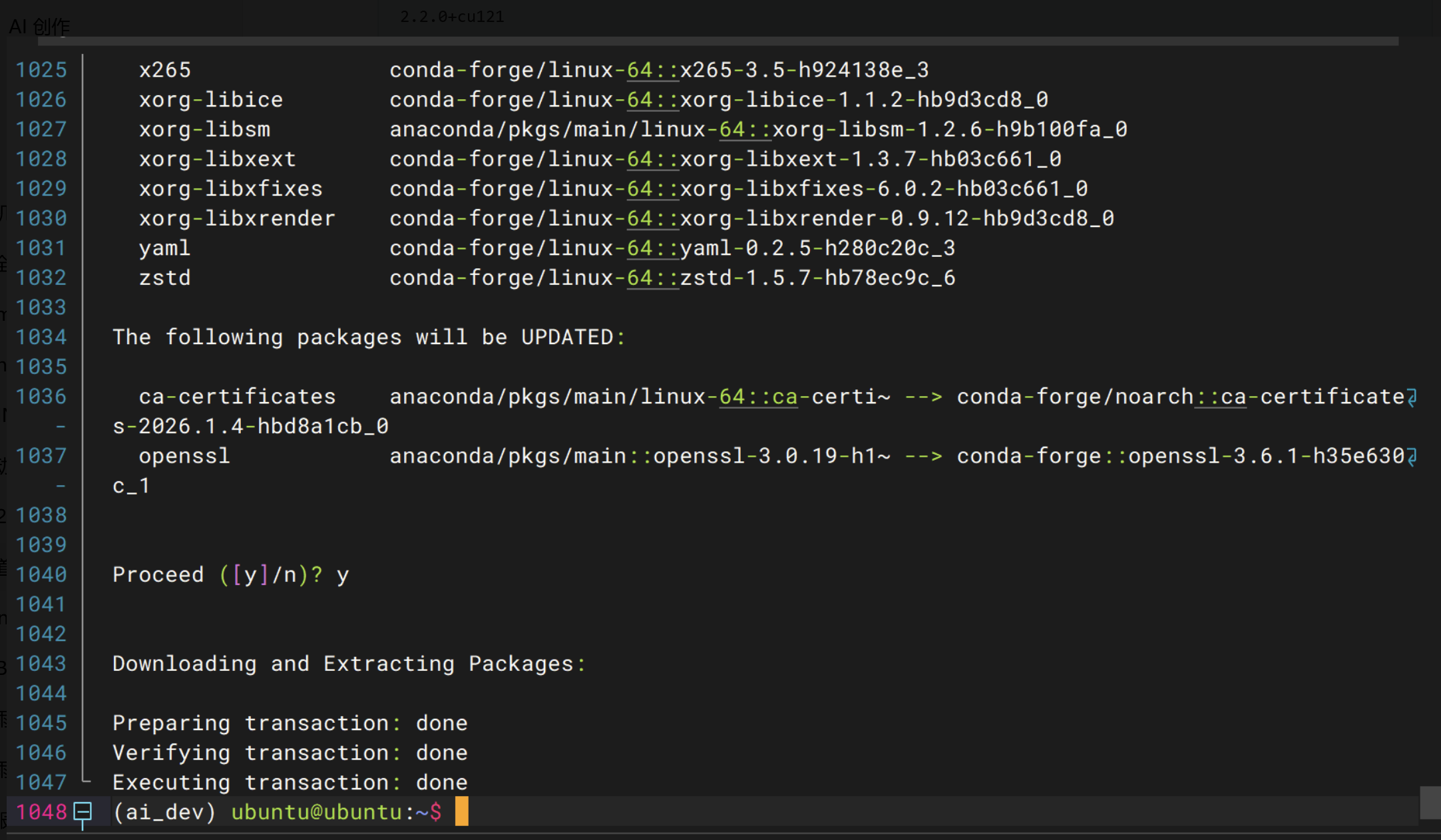
在 ai_dev 环境中执行以下命令,检查 PyTorch 和 CUDA 是否可用:
python -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA可用:', torch.cuda.is_available())"此处我报了错误
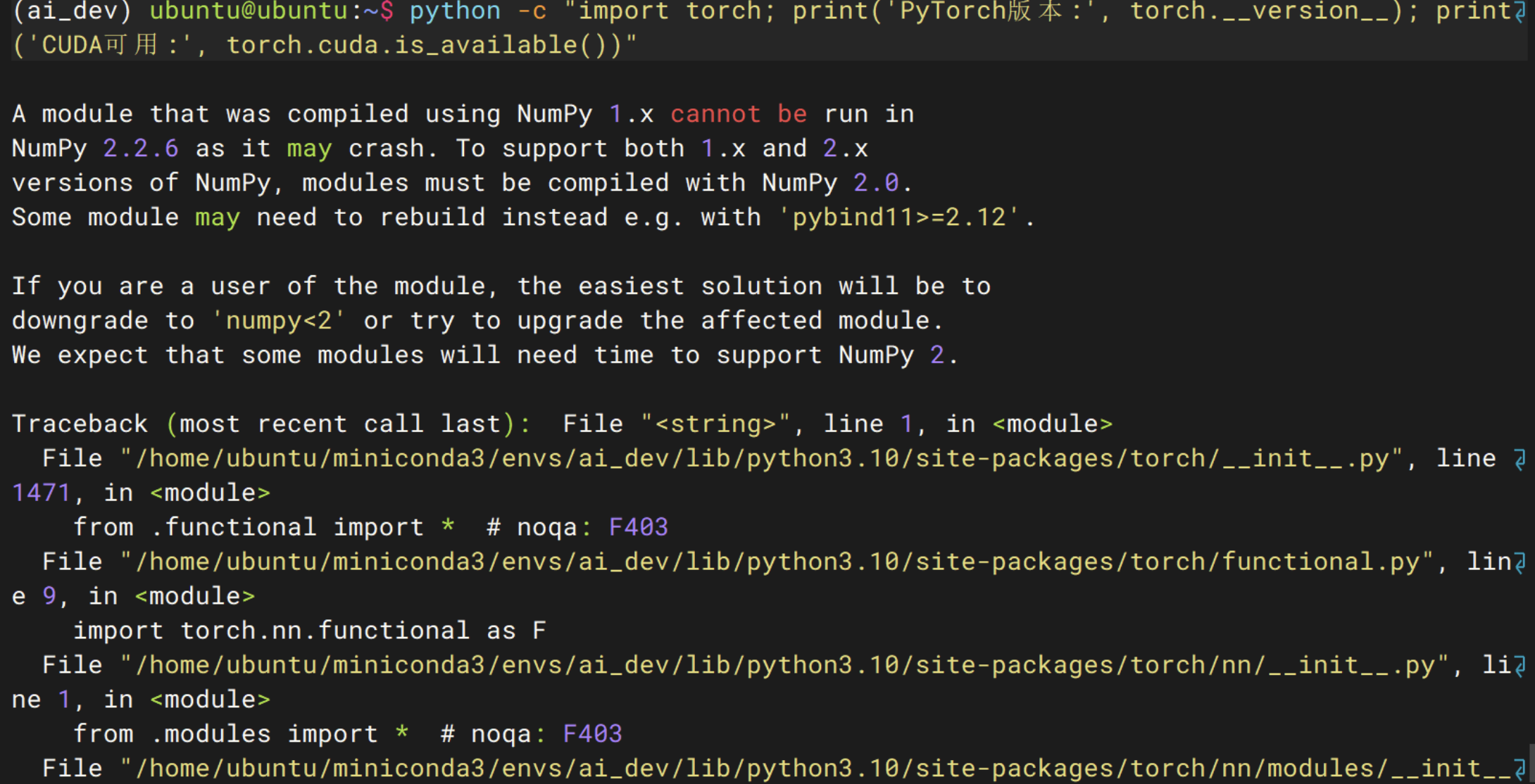
降级numpy
conda 会自动处理依赖冲突,如果 opencv-python 需要 numpy>=2,它会提示你是否降级 opencv-python,选择 y 即可。
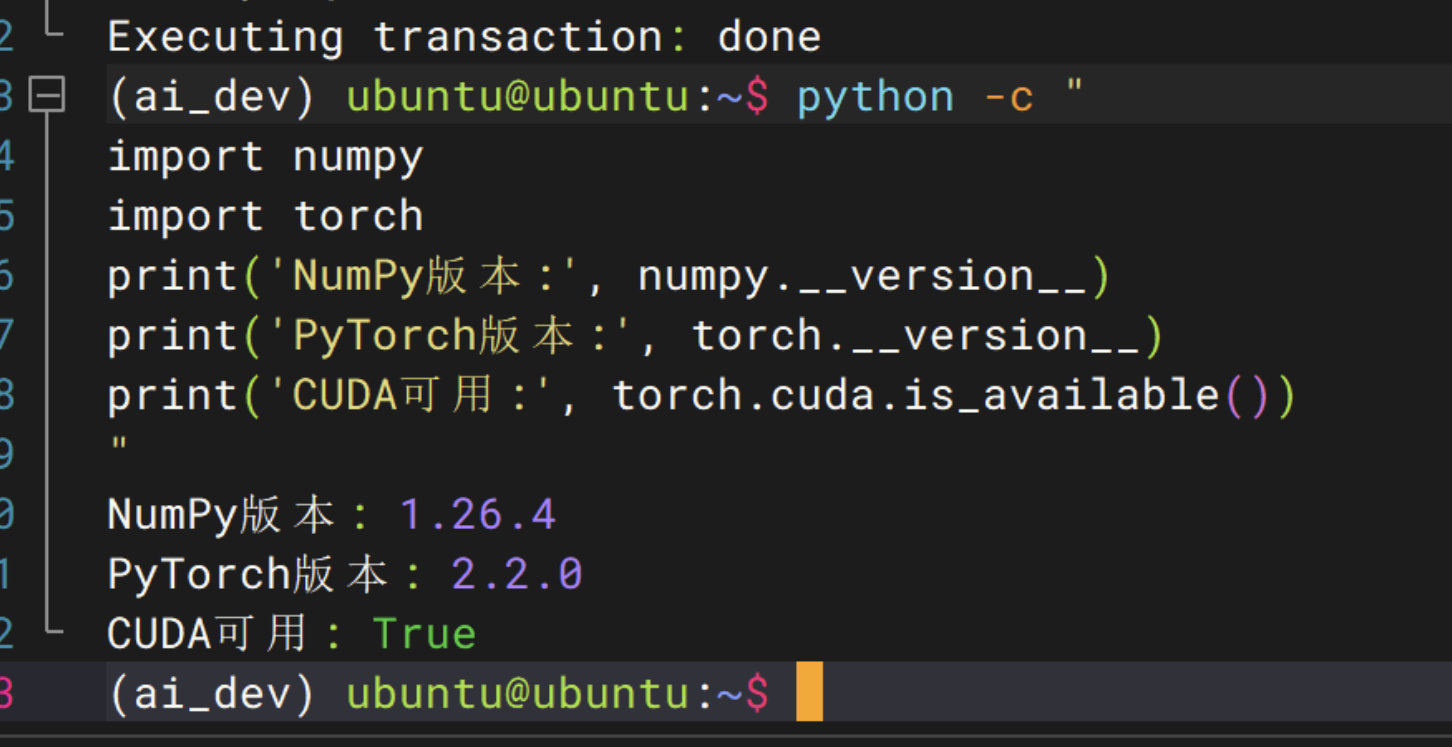
conda install "numpy<2"执行以下命令,检查 NumPy 版本和 PyTorch 初始化是否正常:
python -c "
import numpy
import torch
print('NumPy版本:', numpy.__version__)
print('PyTorch版本:', torch.__version__)
print('CUDA可用:', torch.cuda.is_available())
"环境已经就绪:
二、大模型部署
安装git-lfs
sudo apt update && sudo apt install -y git-lfs创建目录并下载开源模型
# 1. 创建目录结构(在你的用户目录下)
mkdir -p ~/ai_project ~/models/llm ~/models/sdxl
cd ~/ai_project
# 2. 下载 Qwen-7B-Chat(开源LLM,文本核心)
git lfs install
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git /home/ubuntu/models/llm/Qwen-7B-Chat查看模型部署位置
ls ~/models/llm/Qwen-7B-Chat-Int4/模型权重文件:

确保在 ai_project 目录下:
cd ~/ai_project创建 llm_deploy.py 文件
vim llm_deploy.py-
按 i 键(底部出现
-- INSERT --),进入编辑模式; -
粘贴代码
隧道通用问题问答(彻底截断无关内容)
def general_qa(self, query):
prompt = f"""
你是专业的隧道工程咨询助手,仅回答隧道相关专业问题,回答要简洁、专业、易懂。
用户问题:{query}
强制要求:只输出问题的核心回答,禁止续写任何无关内容、测试题、其他领域知识!回答完立即停止。
"""
start_time = time.time()
messages = [{"role": "user", "content": prompt}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = self.tokenizer([text], return_tensors="pt").to(DEVICE)# 移除了不支持的 stop_sequence 参数 generated_ids = self.model.generate( **model_inputs, generation_config=self.model.generation_config ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] # 后处理:截断所有无关内容,只保留核心回答 stop_keywords = [ "准噶尔盆地", "下列哪个选项", "以下哪个选项", "论文的关键词", "Photoshop", "编程语言", "选择题", "1. ", "2. ", "3. ", "4. ", "味精的主要成分是什么?", "iMore详细解释一下", "定义"人工智能"", "省略号的作用是什么", "慢性阻塞性肺疾病的诊断依据", "海外市场", "智能健康手环", "产品名称", "目标受众", "预算", "方法", "解释", "预计效果", "想出一种新的方式", "推广一款新产品", "为什么这种方法有效" ] for kw in stop_keywords: if kw in response: response = response.split(kw)[0].strip() break # 清理首尾多余空格/换行 response = response.strip() mem_used = torch.cuda.max_memory_allocated(DEVICE) / 1024 / 1024 / 1024 print(f"通用问答推理耗时:{time.time()-start_time:.2f}s,显存占用:{mem_used:.2f}G") return response -
按 Esc 键退出编辑模式,输入
:wq按回车,保存并退出。
执行 ls 命令,终端显示 llm_deploy.py 就说明文件创建成功

运行LLM
执行命令(指定用卡 0,避免显存冲突):
CUDA_VISIBLE_DEVICES=0 python llm_deploy.py这里报错没有安装transformers依赖:

安装transformers:
python -m pip install transformers==4.37.2 torchvision==0.17.2 --break-system-packages再次运行LLM
这里报错

安装这个包:
python -m pip install tiktoken --break-system-packages在安装另外两个依赖包
python -m pip install einops transformers_stream_generator --break-system-packages安装torch
python -m pip install torch==2.3.0 torchvision==0.18.0 --break-system-packages安装transformers_stream_generator
python -m pip install transformers_stream_generator --break-system-packages因为加载 GPTQ 量化模型需要 auto-gptq 包,我们先把它装上:
安装gptq
python -m pip install auto-gptq --break-system-packages安装一个gptq依赖库optimum
python -m pip install optimum --break-system-packages三、封装api
现在大模型已经可以启动了,我们封装一个api实现前后端分离。
封装fastapi
# 确保你在 ai_dev 环境中
conda activate ai_dev
# 使用 conda 安装 fastapi 和 uvicorn
conda install fastapi uvicorn -c conda-forge先确保你在 ~/ai_project 这个文件夹里:
cd ~/ai_project创建并打开 tunnel_llm_api.py 文件:
vim tunnel_llm_api.py粘贴代码
import torch
import json
import time
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# ========== 初始化FastAPI ==========
app = FastAPI(title="隧道LLM API服务", version="1.0")
# ========== 模型配置 ==========
DEVICE = "cuda:0"
MODEL_PATH = "/home/ubuntu/models/llm/Qwen-7B-Chat"
TORCH_DTYPE = torch.float16
MAX_NEW_TOKENS = 2048
# ========== 全局加载模型(启动时加载一次) ==========
print("开始加载LLM模型...")
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH, trust_remote_code=True, resume_download=True
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map=DEVICE,
torch_dtype=TORCH_DTYPE,
trust_remote_code=True,
resume_download=True
)
# 通用问答配置
general_gen_config = GenerationConfig(
temperature=0.7, top_p=0.9, repetition_penalty=1.1, max_new_tokens=MAX_NEW_TOKENS, do_sample=True
)
# 结构化任务配置
structured_gen_config = GenerationConfig(
temperature=0.01, top_p=0.9, repetition_penalty=1.2, max_new_tokens=MAX_NEW_TOKENS, do_sample=False
)
print("模型加载完成!")
# ========== 数据模型(API入参) ==========
class QueryRequest(BaseModel):
query: str
type: str = "general" # general:通用问答, intent:意图识别, warn:预警, disease:病害, collision:碰撞
# ========== 辅助函数 ==========
def extract_complete_json(text):
start_idx = text.find('{')
if start_idx == -1:
return None
brace_count = 0
end_idx = -1
for i in range(start_idx, len(text)):
if text[i] == '{':
brace_count += 1
elif text[i] == '}':
brace_count -= 1
if brace_count == 0:
end_idx = i
break
if end_idx == -1:
return None
return text[start_idx:end_idx+1]
def general_qa(query):
prompt = f"""
你是专业的隧道工程咨询助手,仅回答隧道相关专业问题,回答要简洁、专业、易懂。
用户问题:{query}
强制要求:只输出问题的核心回答,禁止续写任何无关内容!
"""
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(DEVICE)
generated_ids = model.generate(**model_inputs, generation_config=general_gen_config)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 截断无关内容
stop_keywords = ["准噶尔盆地", "下列哪个选项", "Photoshop", "1. "]
for kw in stop_keywords:
if kw in response:
response = response.split(kw)[0].strip()
return response.strip()
def generate_structured(prompt):
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(DEVICE)
generated_ids = model.generate(**model_inputs, generation_config=structured_gen_config)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
try:
json_str = extract_complete_json(response)
if json_str is None:
raise ValueError("未找到完整JSON")
return json.loads(json_str)
except Exception as e:
return {"error": "格式错误", "detail": str(e)}
# ========== API接口 ==========
@app.post("/api/chat")
async def chat(request: QueryRequest):
try:
start_time = time.time()
if request.type == "general":
# 通用问答
result = {"answer": general_qa(request.query)}
elif request.type == "intent":
# 意图识别
prompt = f"""
角色:隧道场景意图识别模型
输入:{request.query}
输出格式:{{"intent":"traffic_query","slot":{{"tunnel_name":"鹏鹄隧道","date":"今天"}}}}
"""
result = generate_structured(prompt)
elif request.type == "warn":
# 预警生成(示例参数,可从query提取)
prompt = f"""
角色:隧道预警生成模型
输入:指标=一氧化碳,当前值=200.22ppm,阈值=150ppm
输出格式:{{"warn_text":"","suggestion":""}}
"""
result = generate_structured(prompt)
elif request.type == "disease":
# 病害预测
prompt = f"""
角色:隧道病害预测模型
输入:病害类型=横向裂缝,当前面积=0.4540㎡,预测时间=12个月
输出格式:{{"future_area":"","growth_rate":"","level":"","secondary_risk":"","evolution_type":""}}
"""
result = generate_structured(prompt)
elif request.type == "collision":
# 碰撞解析
prompt = f"""
角色:隧道碰撞解析模型
输入:{request.query}
输出格式:{{"car_type1":"SUV","car_type2":"货车","angle":"侧面","speed":"40km/h","time_steps":[1,3,5,10]}}
"""
result = generate_structured(prompt)
else:
raise HTTPException(status_code=400, detail="不支持的类型")
return {
"code": 200,
"msg": "success",
"data": result,
"time_cost": f"{time.time()-start_time:.2f}s"
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"服务器错误:{str(e)}")
# ========== 启动服务 ==========
if __name__ == "__main__":
# 启动API服务,允许外部访问(0.0.0.0)
import uvicorn
uvicorn.run(
app="tunnel_llm_api:app",
host="0.0.0.0", # 允许所有IP访问
port=8000, # 端口
workers=1, # 单进程(模型加载一次)
reload=False # 生产环境关闭热重载
)在目录下执行代码:
CUDA_VISIBLE_DEVICES=0 nohup python tunnel_llm_api.py > llm_api.log 2>&1 &CUDA_VISIBLE_DEVICES=0:指定用第 0 块 GPU 运行;nohup:后台运行,关闭终端也不会停;> llm_api.log 2>&1:把运行日志存到llm_api.log文件里;&:让程序在后台执行
查看模型加载实时日志:
tail -f llm_api.log模型加载成功:
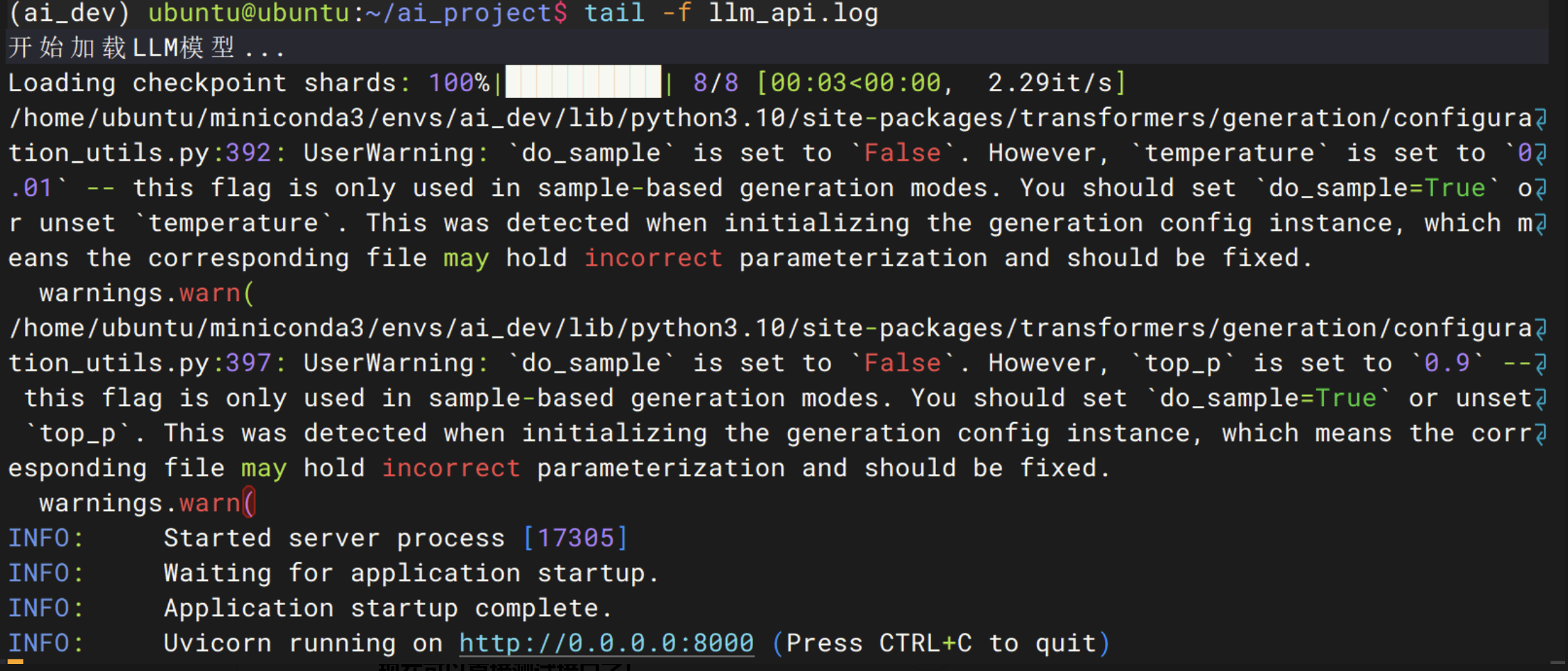
在另一个终端窗口(保持当前日志窗口打开,方便监控)执行:
conda activate ai_dev
cd ~/ai_project安装curl工具
sudo apt update && sudo apt install -y curl
# 测试通用问答
curl -X POST "http://localhost:8000/api/chat" -H "Content-Type: application/json" -d '{"query":"隧道通风系统有哪些类型?","type":"general"}'四、前端部署
首先检查进程是否还在
# 检查 API 服务进程
ps -ef | grep tunnel_llm_api.py
# 如果没有进程,重新启动
conda activate ai_dev
cd ~/ai_project
CUDA_VISIBLE_DEVICES=0 nohup python tunnel_llm_api.py > llm_api.log 2>&1 &Streamlit 是快速搭建 Python Web 应用的工具,无需写前端代码,先安装:
# 确保你在 ai_dev 环境中
conda activate ai_dev
# 使用 conda 安装 streamlit
conda install streamlit -c conda-forge在 ~/ai_project 目录下创建 llm_chat_app.py 文件:
# 进入项目目录
cd ~/ai_project
# 用 vim 创建并编辑文件
vim llm_chat_app.py
import streamlit as st
import requests
import time
# ===================== 页面基础配置 =====================
# 设置页面标题、图标、布局
st.set_page_config(
page_title="隧道工程大模型助手",
page_icon="⛰️",
layout="wide", # 宽屏布局
initial_sidebar_state="collapsed" # 收起侧边栏
)
# ===================== 样式美化(可选,提升体验) =====================
st.markdown("""
<style>
/* 聊天框样式 */
.stChatMessage {
padding: 1rem;
border-radius: 10px;
margin-bottom: 0.8rem;
}
/* 输入框样式 */
.stChatInput {
position: fixed;
bottom: 20px;
width: 80%;
left: 10%;
z-index: 999;
}
/* 标题样式 */
h1 {
text-align: center;
color: #2E86AB;
margin-bottom: 2rem;
}
</style>
""", unsafe_allow_html=True)
# ===================== 初始化聊天历史 =====================
# 首次打开页面时,创建空的聊天记录
if "messages" not in st.session_state:
st.session_state.messages = [
{"role": "assistant", "content": "你好!我是隧道工程专业助手,有任何隧道相关问题都可以问我~"}
]
# ===================== 显示聊天历史 =====================
st.title("⛰️ 隧道工程大模型助手")
# 遍历聊天记录,显示每一条消息
for msg in st.session_state.messages:
# 设置消息角色(用户/助手),对应不同的头像和颜色
with st.chat_message(msg["role"], avatar="👤" if msg["role"] == "user" else "🤖"):
st.markdown(msg["content"])
# ===================== 接收用户输入并调用API =====================
# 底部输入框,提示文字:"请输入你的隧道相关问题..."
if user_prompt := st.chat_input("请输入你的隧道相关问题..."):
# 1. 显示用户输入的消息
with st.chat_message("user", avatar="👤"):
st.markdown(user_prompt)
# 2. 把用户消息加入聊天历史
st.session_state.messages.append({"role": "user", "content": user_prompt})
# 3. 调用已部署的 LLM API 服务
with st.spinner("🤖 模型正在思考中..."):
try:
# 调用 API 的核心代码
response = requests.post(
url="http://192.168.2.199:8000/api/chat", # 你的 API 地址
json={
"query": user_prompt, # 用户输入的问题
"type": "general" # 通用问答类型
},
headers={"Content-Type": "application/json"},
timeout=30 # 超时时间30秒(模型推理需要时间)
)
# 检查 API 响应状态
response.raise_for_status()
result = response.json()
# 4. 处理 API 返回结果
if result["code"] == 200:
# 成功:提取模型回答
model_answer = result["data"]["answer"]
# 显示推理耗时(可选)
model_answer += f"\n\n⏱️ 推理耗时:{result['time_cost']}"
else:
# 失败:显示错误信息
model_answer = f"❌ 服务响应错误:{result['msg']}"
except requests.exceptions.ConnectionError:
model_answer = "❌ 连接失败!请检查 API 服务是否启动,或 IP/端口是否正确。"
except requests.exceptions.Timeout:
model_answer = "❌ 请求超时!模型推理时间过长,请稍后再试。"
except Exception as e:
model_answer = f"❌ 调用失败:{str(e)}"
# 5. 显示模型回答
with st.chat_message("assistant", avatar="🤖"):
st.markdown(model_answer)
# 6. 把模型回答加入聊天历史
st.session_state.messages.append({"role": "assistant", "content": model_answer})启动 Streamlit Web 服务
在 ~/ai_project 目录下执行启动命令:
# 确保在 ai_dev 环境中
conda activate ai_dev
# 启动 Streamlit 服务(允许内网访问,端口8501)
streamlit run llm_chat_app.py --server.address 0.0.0.0 --server.port 8501改成后台常驻:
conda activate ai_dev
cd ~/ai_project
# 停止可能的 API 服务进程
pkill -f tunnel_llm_api.py
# 停止可能的 Streamlit 服务进程
pkill -f streamlit后台启动 LLM API 服务(必须先启动,因为 Web 界面依赖它)
CUDA_VISIBLE_DEVICES=0 nohup python tunnel_llm_api.py > llm_api.log 2>&1 &在另外一个终端执行
nohup streamlit run llm_chat_app.py --server.address 0.0.0.0 --server.port 8501 > streamlit.log 2>&1 &