本篇技术博文摘要 🌟
- 文章开篇回顾基础概念,随后深入解析传统文本表示方法 :包括基于词频统计的词袋模型 (含代码示例与优劣分析)、衡量词项重要性的TF-IDF (详解计算公式与实现),以及捕捉局部语序的N-gram模型。
- 第二部分重点转向词向量表示 ,依次剖析了Word2Vec 的两种架构与实现、GloVe 的全局统计思想及其与Word2Vec的对比,以及能更好处理未登录词的FastText 。第三部分聚焦上下文感知的表示 ,详解了ELMo 的动态词向量特性及其双向语言模型架构,并系统介绍了BERT及其变体的关键创新与常见模型。
- 文章进而概述了当前主流的预训练+微调范式及各类模型特点。
- 最后,在文档级表示 部分,涵盖了生成文档向量的Doc2Vec 、基于Sentence-BERT的句向量方法 ,以及用于主题发现的LDA主题模型 ,均附有原理说明与代码示例。文末总结了文本表示方法的发展历程 ,并为不同应用场景提供了清晰的选型指导,形成从理论到实践的完整知识体系。
引言 📘
- 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。
- 我是盛透侧视攻城狮,一个"什么都会一丢丢"的网络安全工程师,目前正全力转向AI大模型安全开发新战场。作为活跃于各大技术社区的探索者与布道者,期待与大家交流碰撞,一起应对智能时代的安全挑战和机遇潮流。

上节回顾
目录
[本篇技术博文摘要 🌟](#本篇技术博文摘要 🌟)
[引言 📘](#引言 📘)
[2.1词袋模型(Bag of Words)](#2.1词袋模型(Bag of Words))
[2.3N-gram 模型](#2.3N-gram 模型)
[2.3.1N-gram 模型常见类型](#2.3.1N-gram 模型常见类型)
[2.3.2N-gram 模型代码示例](#2.3.2N-gram 模型代码示例)
[3.1Word2Vec 原理与实现](#3.1Word2Vec 原理与实现)
[3.2.2GloVe词向量与 Word2Vec 对比](#3.2.2GloVe词向量与 Word2Vec 对比)
[4.1ELMo 模型](#4.1ELMo 模型)
[4.1.1ELMo 模型核心特点](#4.1.1ELMo 模型核心特点)
[4.1.2ELMo 模型架构示意图](#4.1.2ELMo 模型架构示意图)
[4.2BERT 及其变体](#4.2BERT 及其变体)
[4.2.2BERT 及其变体常见变体](#4.2.2BERT 及其变体常见变体)
[4.2.3BERT 及其变体代码示例](#4.2.3BERT 及其变体代码示例)

1.文本表示方法
文本表示是自然语言处理(NLP)中的基础任务,它将非结构化的文本数据转化为计算机可以处理的数值形式。
本文将系统介绍 NLP 中常用的文本表示方法,从传统方法到现代深度学习技术,帮助读者全面理解这一核心概念。

2.传统文本表示
2.1词袋模型(Bag of Words)
- 词袋模型是最简单的文本表示方法之一,它将文本视为一个无序的词汇集合。
2.1.1基本概念
- 忽略词语顺序和语法,只关注词语是否出现
- 构建词汇表,统计每个词在文档中出现的次数
- 最终表示为一个高维稀疏向量
2.1.2词袋模型代码示例
python
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names_out())
print(X.toarray())
2.1.3优缺点分析
✅ 优点:
- 实现简单,计算效率高
- 适用于小规模数据集和简单任务
❌ 缺点:
- 忽略词序和语义信息
- 高维稀疏性问题
- 无法处理同义词和多义词

2.2TF-IDF
- TF-IDF(Term Frequency-Inverse Document Frequency)是对词袋模型的改进,考虑了词语在整个语料库中的重要性。
2.2.1TF-IDF计算公式
- TF(词频):
词在文档中出现的次数 / 文档总词数- IDF(逆文档频率):
log(文档总数 / 包含该词的文档数)- TF-IDF = TF × IDF
2.2.2TF-IDF代码实现
python
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(corpus)
print(tfidf_vectorizer.get_feature_names_out())
print(X_tfidf.toarray())2.2.3优缺点
✅ 优点:
- 降低常见词的影响,突出重要词
- 比简单词袋模型效果更好
❌ 缺点:
- 仍然无法捕捉语义关系
- 高维问题依然存在

2.3N-gram 模型
- N-gram 模型考虑了词语的顺序信息,通过连续n个词的组合来表示文本。
2.3.1N-gram 模型常见类型
- Unigram (1-gram):单个词
- Bigram (2-gram):两个连续词的组合
- Trigram (3-gram):三个连续词的组合
2.3.2N-gram 模型代码示例
python
bigram_vectorizer = CountVectorizer(ngram_range=(2, 2))
X_bigram = bigram_vectorizer.fit_transform(corpus)
print(bigram_vectorizer.get_feature_names_out())2.3.3优缺点
✅ 优点:
- 捕捉局部词序信息
- 可以表示短语和固定搭配
❌ 缺点:
- 维度爆炸问题更严重
- 仍然无法处理长距离依赖

3.词向量表示
3.1Word2Vec 原理与实现
- Word2Vec 是一种基于神经网络的词向量表示方法,由 Google 在 2013 年提出。
3.1.1Word2Vec两种模型架构
- CBOW(Continuous Bag of Words):通过上下文预测当前词
- Skip-gram:通过当前词预测上下文
3.1.2Word2Vec代码实现
python
from gensim.models import Word2Vec
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 获取词向量
vector = model.wv['cat']
# 找相似词
similar_words = model.wv.most_similar('cat')3.1.3Word2Vec特点
- 低维稠密向量(通常50-300维)
- 可以捕捉词语的语义和语法关系
- 支持向量运算(如:king - man + woman ≈ queen)

3.2GloVe词向量
- GloVe(Global Vectors for Word Representation)结合了全局统计信息和局部上下文窗口的优点。
3.2.1GloVe词向量核心思想
- 基于词共现矩阵
- 优化目标是使两个词的向量点积等于它们共现次数的对数
3.2.2GloVe词向量与 Word2Vec 对比
| 特性 | Word2Vec | GloVe |
|---|---|---|
| 训练方式 | 局部窗口 | 全局统计 |
| 计算效率 | 较高 | 较低 |
| 小数据集表现 | 较好 | 一般 |
| 大数据集表现 | 好 | 更好 |

3.3FastText
- FastText 是 Facebook 开发的词向量模型,特点是考虑子词(subword)信息。
3.3.1FastText主要特点
- 将词表示为字符n-gram的集合
- 可以处理未登录词(OOV)
- 特别适合形态丰富的语言
3.3.2FastText代码示例
python
from gensim.models import FastText
model = FastText(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 即使单词不在词典中也能获得向量
vector = model.wv['unseenword']4.上下文感知的表示
4.1ELMo 模型
- ELMo(Embeddings from Language Models)是最早的上下文相关词表示方法之一。
4.1.1ELMo 模型核心特点
- 基于双向LSTM语言模型
- 词语的表示取决于整个输入句子
- 生成多层表示(可以组合不同层次的语
4.1.2ELMo 模型架构示意图
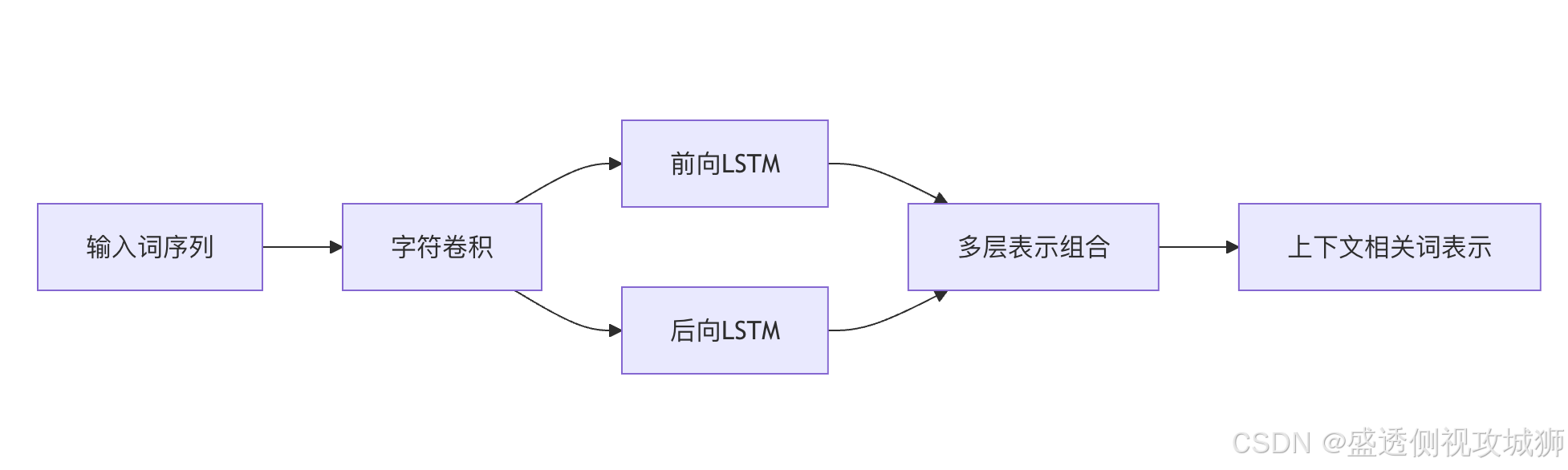
4.2BERT 及其变体
- BERT(Bidirectional Encoder Representations from Transformers)是 Google 提出的预训练语言模型。
4.2.1BERT及其变体关键创新
- Transformer 架构
- 掩码语言模型(MLM)训练目标
- 下一句预测(NSP)任务
4.2.2BERT 及其变体常见变体
- RoBERTa:优化训练策略
- DistilBERT:轻量版BERT
- ALBERT:参数共享减少模型大小
4.2.3BERT 及其变体代码示例
python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state5.预训练语言模型概述
5.1现代NLP主要使用预训练+微调范式
- 预训练阶段:在大规模语料上训练通用语言表示
- 微调阶段:在特定任务数据上调整模型参数
5.2模型特点表
| 模型 | 发布时间 | 主要特点 |
|---|---|---|
| Word2Vec | 2013 | 静态词向量 |
| GloVe | 2014 | 全局统计+局部窗口 |
| ELMo | 2018 | 双向LSTM,上下文相关 |
| BERT | 2018 | Transformer,双向上下文 |
| GPT-3 | 2020 | 单向Transformer,生成能力强 |

6.文档级表示
6.1Doc2Vec
- Doc2Vec 是 Word2Vec 的扩展,可以直接学习文档的向量表示
6.1.1Doc2Vec两种模型
- PV-DM(Distributed Memory):类似CBOW,加入文档ID
- PV-DBOW(Distributed Bag of Words):类似Skip-gram
6.1.2Doc2Vec代码示例
python
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(corpus)]
model = Doc2Vec(documents, vector_size=100, window=5, min_count=1, workers=4)
vector = model.infer_vector(["new", "document", "text"])6.2句向量与文档向量
6.2.1常用方法
- 平均法:对词向量取平均
- SIF:平滑逆频率加权平均
- BERT句向量:使用CLS标记或平均所有词向量
6.2.2代码示例(使用Sentence-BERT)
python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)6.3主题模型(LDA)
- 潜在狄利克雷分配(LDA)是一种无监督的主题建模方法
6.3.1基本原理
- 将文档表示为多个主题的混合
- 每个主题是词语的概率分布
- 通过变分推断或Gibbs采样学习
6.3.2代码示例
python
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
lda = LatentDirichletAllocation(n_components=2)
lda.fit(X)6.3.3应用场景
- 文档聚类
- 内容推荐
- 文本摘要

7.总结
7.1文本表示方法的发展历程
- 传统方法:简单高效,适合小规模数据
- 词向量:捕捉语义关系,维度低
- 上下文感知模型:动态表示,效果最好但计算成本高
- 文档表示:从词级别扩展到文档级别
7.2选择文本表示方
欢迎各位彦祖与热巴畅游本人专栏与技术博客
你的三连是我最大的动力
点击➡️指向的专栏名即可闪现
➡️计算机组成原理****
➡️操作系统
➡️****渗透终极之红队攻击行动********
➡️ 动画可视化数据结构与算法
➡️ 永恒之心蓝队联纵合横防御
➡️****华为高级网络工程师********
➡️****华为高级防火墙防御集成部署********
➡️ 未授权访问漏洞横向渗透利用
➡️****逆向软件破解工程********
➡️****MYSQL REDIS 进阶实操********
➡️****红帽高级工程师
➡️红帽系统管理员********
➡️****HVV 全国各地面试题汇总********
