Capture III -- 存储和查询
聊完了数据模型和查询语言,这一章我们聊一聊数据存储和查询优化。数据库分为两类:OLTP 和 OLAP。
| 引擎类型 | 请求数量 | 数据量 | 瓶颈 | 存储格式 | 用户 | 场景举例 | 产品举例 |
|---|---|---|---|---|---|---|---|
| OLTP | 相对频繁,侧重在线交易 | 总体和单次查询都相对较小 | Disk Seek | 多用行存 | 比较普遍,一般应用用的比较多 | 银行交易 | MySQL |
| OLAP | 相对较少,侧重离线分析 | 总体和单次查询都相对巨大 | Disk Bandwidth | 列存逐渐流行 | 多为商业用户 | 商业分析 | ClickHouse |
其中,OLTP 侧,常用的存储引擎又有两种流派:
| 流派 | 主要特点 | 基本思想 | 代表 |
|---|---|---|---|
| log-structured 流 | 只允许追加,所有修改都表现为文件的追加和文件整体增删 | 变随机写为顺序写 | Bitcask、LevelDB、RocksDB、Cassandra、Lucene |
| update-in-place 流 | 以页(page)为粒度对磁盘数据进行修改 | 面向页、查找树 | B 族树,所有主流关系型数据库和一些非关系型数据库 |
下面,我们先聊聊 OLTP 数据库的存储和查询方式。
OLTP型
Bitcask
我们首先介绍一种很特殊但实现很简单的数据库 --- Bitcask。之所以特殊,是因为他是一个全内存数据库,之所以简单,是因为他的核心 get/set 指令如下
bash
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}从 shell 脚本可以看出,其存取的基本原理为:
- set:在文件末尾追加一个 KV 对。
- get:匹配所有 Key,返回最后(也即最新)一条 KV 对中的 Value。
可以看出这是一种典型的以读换写:写很快,但是读需要全文逐行扫描,会慢很多。为了加快读,Bitcask 在内存中构建了一个哈希索引。索引定义如下:
- Key 是查询 Key
- Value 是 KV 条目的起始位置和长度。
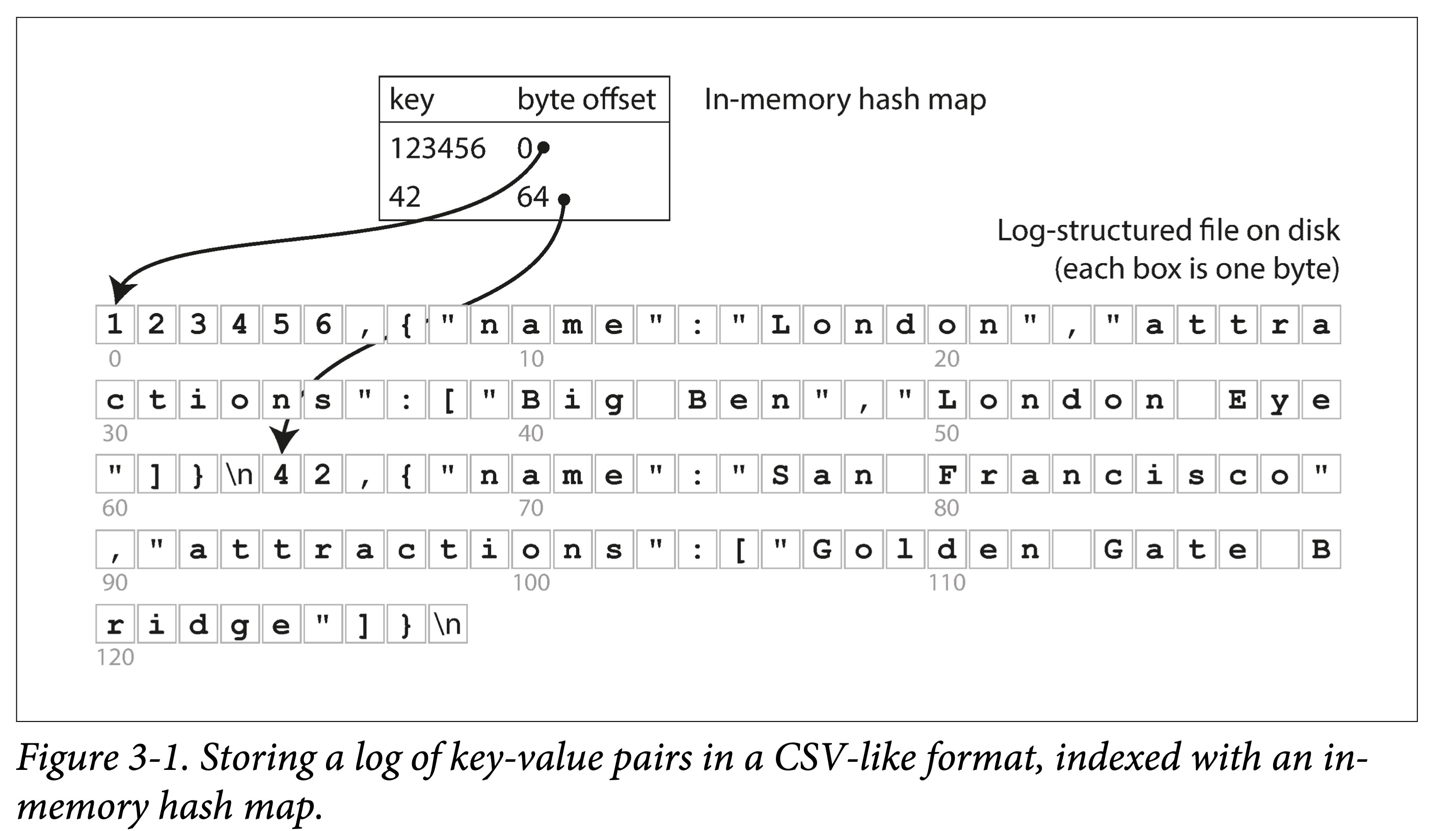
看来很简单,但这正是 Bitcask 的基本设计,但关键是,他 Work(在小数据量时,即所有 key 都能存到内存中时)能提供很高的读写性能:
- 写:文件追加写。
- 读:一次内存查询,一次磁盘 seek;如果数据已经被缓存,则 seek 也可以省掉。
如果你的 key 集合很小(意味着能全放内存),但是每个 key 更新很频繁,那么 Bitcask 便是你的菜。
你可能有很多疑惑?
- 由于频繁写入,单个文件越来越大,磁盘空间不够怎么办?
- Bitcask 如何应对数据的更新?
实际上,Bitcask 具有如下三种机制:
- 分割文件:化整为零
Bitcask 不会让单个数据文件无限增长。它将写入操作局限在一个活动文件中,采用仅追加的方式顺序写入,保证了极高的写入吞吐量。当这个活动文件的大小达到用户设定的阈值(例如 4MB 或 1GB)后,它会被立即关闭,变为一个只读的旧数据文件。之后系统会创建一个全新的活动文件来继续承接写入请求。通过这种方式,庞大的数据被分解为一个个大小适中、不可变的旧文件和一个接受写入的活动文件,为后续的清理奠定了基础。 - 标记过期:写入即生效
Bitcask 的处理方式很巧妙,它把"修改"和"删除"也当作一次新的写入。当更新一个已有 Key 时,Bitcask 并不会去找到并覆盖旧的数据。它只是在当前活动文件的末尾追加写入一条新的 Key-Value 数据,然后更新内存中的索引(KeyDir),让索引指向新数据的位置。执行删除操作时,Bitcask 同样是追加写入一条特殊的记录,称为墓碑值(Tombstone),并更新内存索引,标记该 Key 已被删除。
这样一来,旧的数据文件里就积压了大量"无效"的旧版本数据和被标记删除的数据,它们白白占着磁盘空间,等待被清理。 - 合并清理:后台回收,一劳永逸
这是解决磁盘空间问题的核心步骤。Bitcask 会在后台定期或手动执行一个名为 合并(Merge) 的操作。
这个过程就像一个高效的档案整理员:合并进程会遍历所有只读的旧数据文件。他会根据内存中的最新索引,找出每个 Key 在旧文件中的最新、有效的那条数据。对于被标记了"墓碑值"的 Key,则直接忽略,表示这些数据可以被物理删除了。
将这些筛选出的有效数据,重新写入到一组新的数据文件中。这些新文件只包含每个 Key 的最新值,因此体积会小很多。合并完成后,系统会用这些新生成的、更紧凑的文件,去替换掉那些包含大量垃圾数据的旧文件。被替换的旧文件就可以被安全地删除,从而真正释放磁盘空间。
为了加速系统重启后内存索引的重建,Bitcask 在合并时还会为每个新数据文件生成一个对应的 提示文件(Hint File)。它相当于一份精简的索引,只记录 Key 的位置信息,不包含 Value,加载速度极快。
当然,Bitcask 还有很多其他的 feature,在这里我就不一一介绍了,感兴趣的友友们可以去 Bitcask 自行了解。
SSTable
对于 KV 数据,BitCask 的存储结构是:
- 外存上日志片段
- 内存中的哈希表
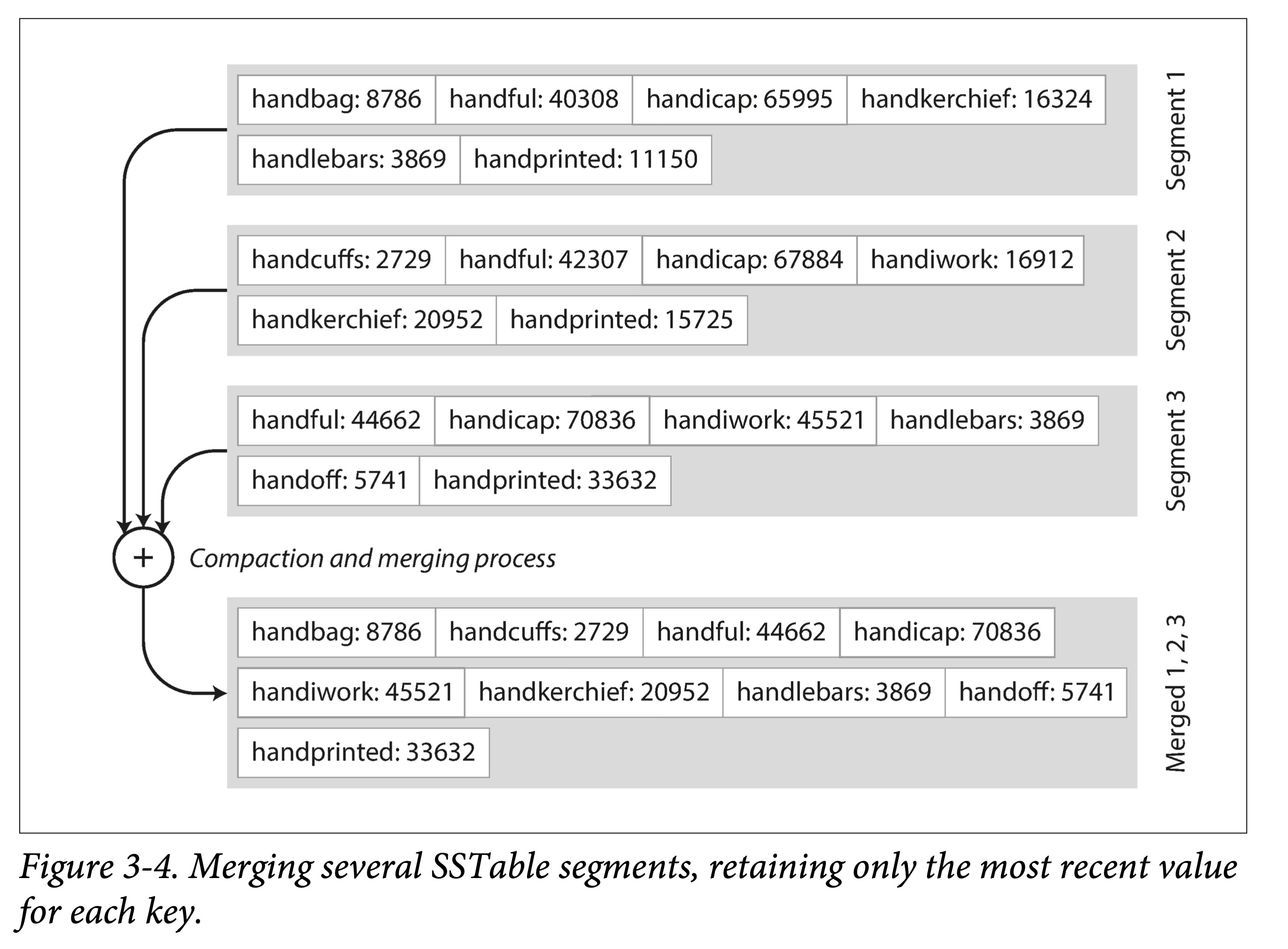
其中外存上的数据是简单追加写而形成的,并没有按照某个字段有序。假设加一个限制,让这些文件按 Key 有序。我们称这种格式为:SSTable(Sorted String Table)。这种文件格式的优点是:
-
高效的数据文件合并。即有序文件的归并外排,顺序读,顺序写。
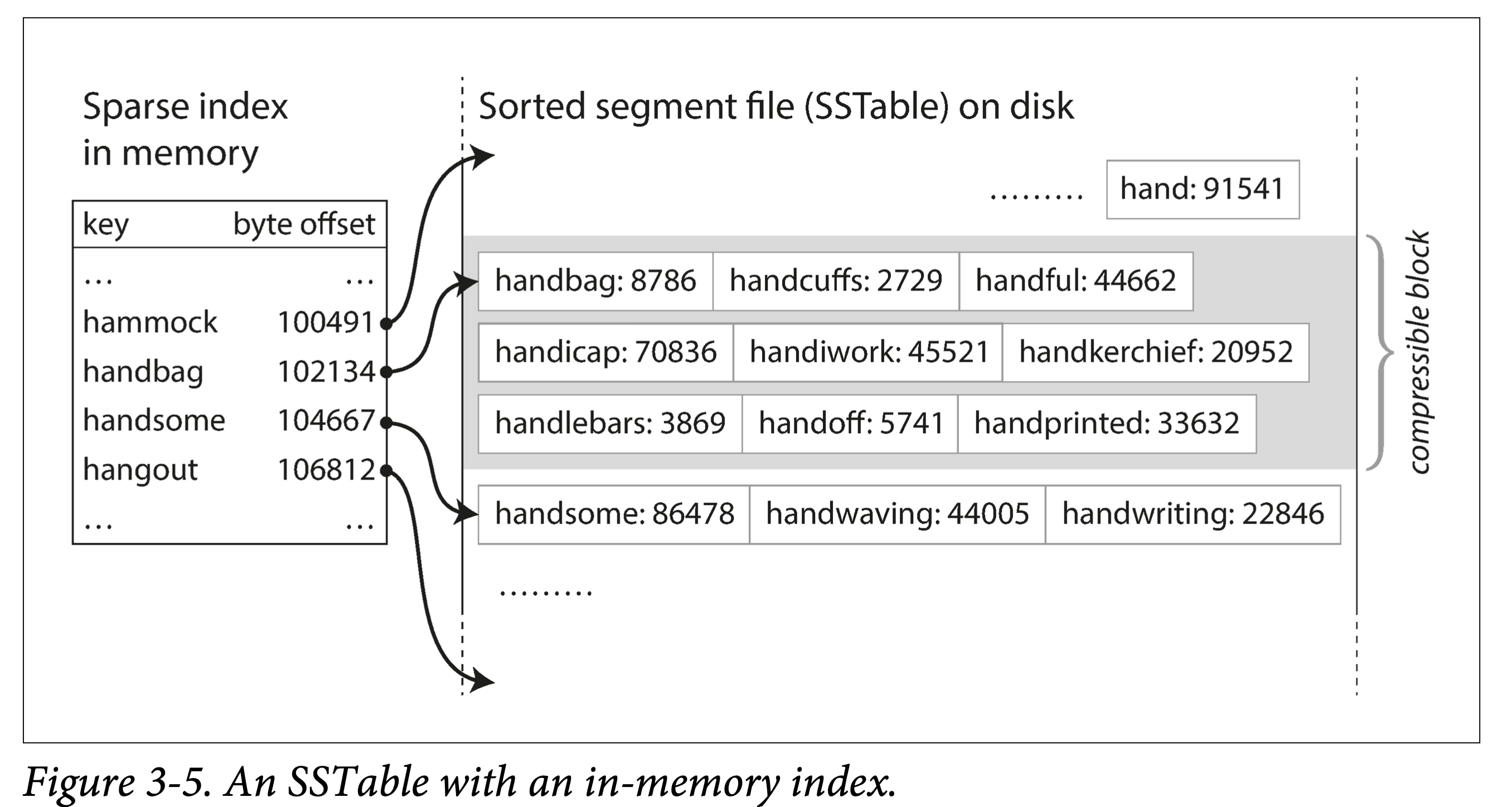
-
不需要在内存中保存所有数据的索引。仅需要记录下每个文件界限(以区间表示:startKey, endKey,当然实际会记录的更细)即可。查找某个 Key 时,去所有可能包含该 Key 的 block 对应的文件二分查找即可。
SSTables 格式听起来很美好,但须知数据是乱序的来的,我们如何得到有序的数据文件呢?
-
构建 SSTable 文件。将乱序数据在外存(磁盘 or SSD)中上整理为有序文件,是比较难的。但是在内存就方便的多。于是一个大胆的想法就形成了:
- 在内存中维护一个有序结构(称为 MemTable)。红黑树、AVL 树、跳表。
- 到达一定阈值之后全量 dump 到外存。
-
维护 SSTable 文件。对于上述复合结构,我们怎么进行查询:
- 先去 MemTable 中查找,如果命中则返回。
- 再去 SSTable 按时间顺序由新到旧逐一查找。
同样,如果 SSTable 文件越来越多,则查找代价会越来越大。因此需要将多个 SSTable 文件合并,以减少文件数量,同时进行 GC,我们称之为紧缩( Compaction),这一流程我们也很熟悉了。如果出现宕机,内存中的数据结构将会消失。解决方法也很经典:WAL(预写日志,Write-Ahead Logging)。
LSM-Tree
将前面两节的一些碎片有机的组织起来,便是时下流行的存储引擎 LevelDB 和 RocksDB 后面的存储结构:LSM-Tree。
这种数据结构是 Patrick O'Neil 等人,在 1996 年提出的:The Log-Structured Merge-Tree。Elasticsearch 和 Solr 的索引引擎 Lucene,也使用类似 LSM-Tree 存储结构。但其数据模型不是 KV,而是类似:word → document list。
LSM-Tree 在 SSTable 基础上进行了一些优化,例如:
- 优化 SSTable 的查找。常用 Bloom Filter。该数据结构可以使用较少的内存为每个 SSTable 做一些指纹,起到一些初筛的作用。
- 层级化组织 SSTable。用以控制 Compaction 的顺序和时间。常见的有 size-tiered 和 leveled compaction。LevelDB 便是支持后者而得名。前者比较简单粗暴,后者性能更好,也因此更为常见。
但无论有多少变种和优化,LSM-Tree 的核心思想都是保存一组合理组织、后台合并的 SSTables。可以方便的进行范围遍历,可以变大量随机为少量顺序。
B族树
B 树于 1970 年被 R. Bayer and E. McCreight 提出后,便迅速流行了起来。现在几乎所有的关系型数据中,它都是数据索引标准一般的实现。与 LSM-Tree 一样,它也支持高效的点查和范围查。但却使用了完全不同的组织方式。
其特点有:
- 以页(在磁盘上叫 page,在内存中叫 block,通常为 4k)为单位进行组织。
- 页之间以页 ID 来进行逻辑引用,从而组织成一颗磁盘上的树。
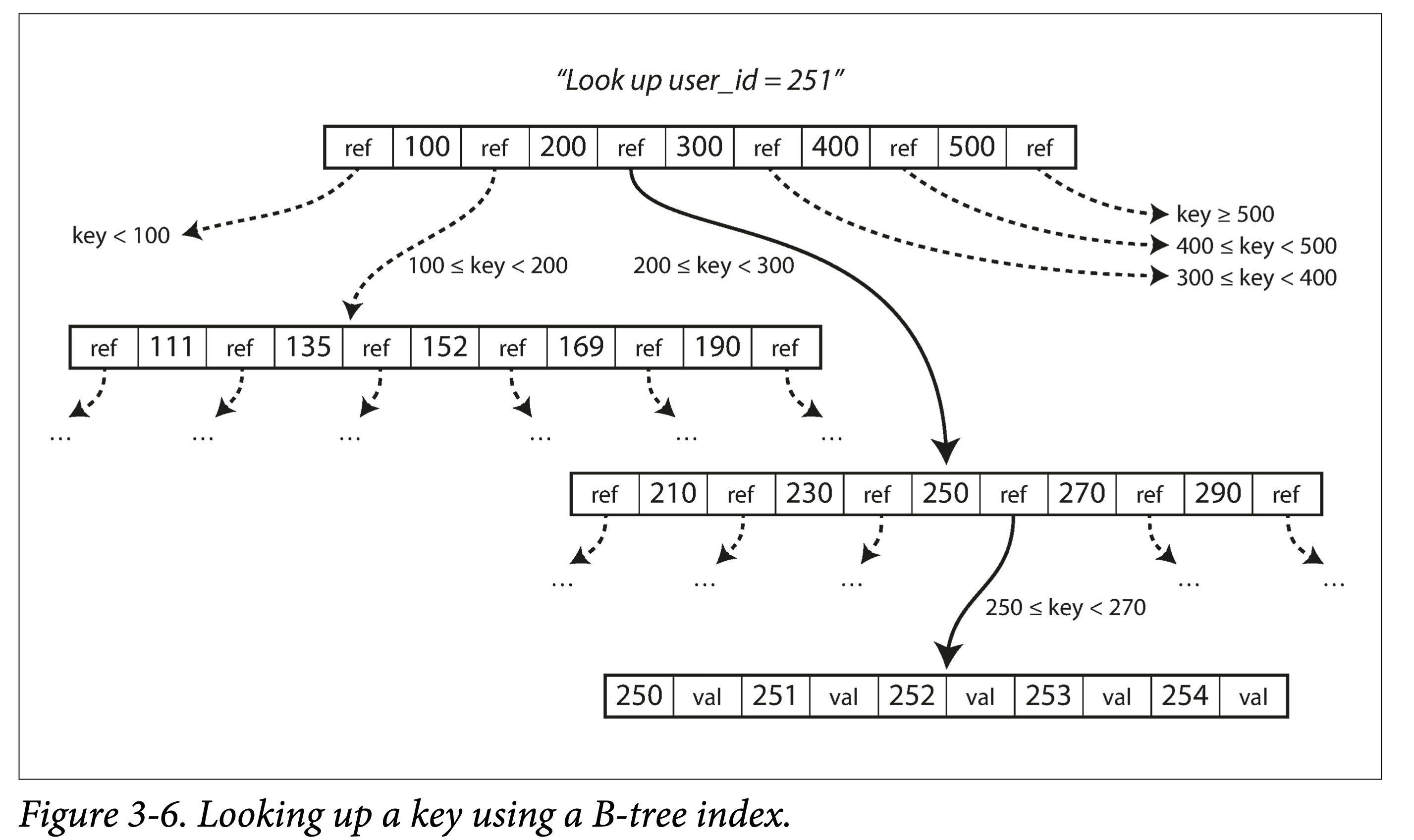 查找。从根节点出发,进行二分查找,然后加载新的页到内存中,继续二分,直到命中或者到叶子节点。查找复杂度为 O(logn),其中 n 为树的节点总数,影响树高度的因素:分叉数(某节点具有的子节点数,通常是几百个)。
查找。从根节点出发,进行二分查找,然后加载新的页到内存中,继续二分,直到命中或者到叶子节点。查找复杂度为 O(logn),其中 n 为树的节点总数,影响树高度的因素:分叉数(某节点具有的子节点数,通常是几百个)。
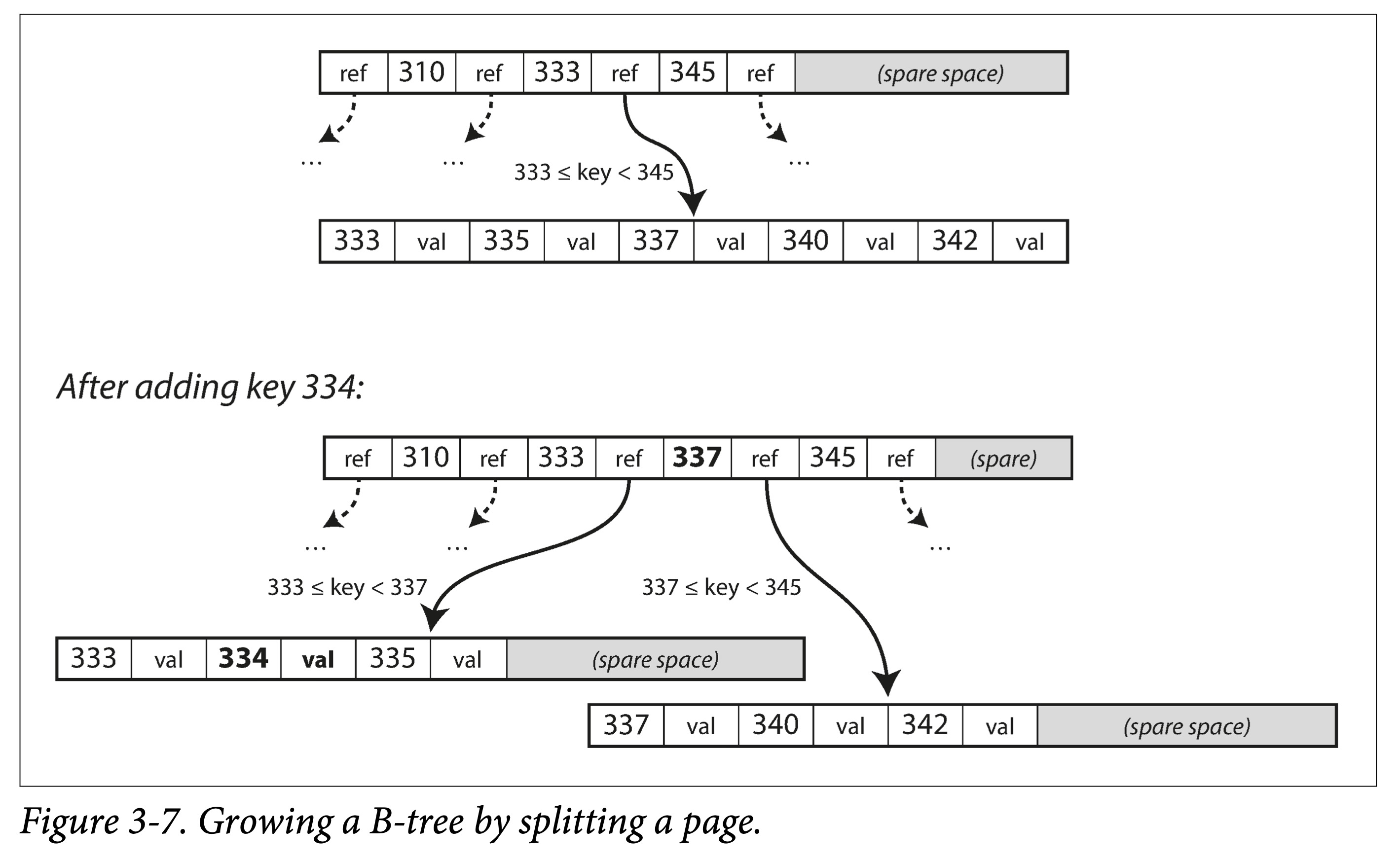
插入 or 更新 。和查找过程一样,定位到原 Key 所在页,插入或者更新后,将页完整写回。如果页剩余空间不够,则分裂后写入。
分裂 or 合并 。级联分裂和合并。
某条记录大于一个 page 怎么办? 树的节点是逻辑概念,page or block 是物理概念。一个逻辑节点可以对应多个物理 page。
B 树不像 LSM-Tree,会在原地修改数据文件。在树结构调整时,可能会级联修改很多 Page。比如叶子节点分裂后,就需要写入两个新的叶子节点,和一个父节点(更新叶子指针)。他的解决方案是:
- 增加预写日志(WAL),将所有修改操作记录下来,预防宕机时中断树结构调整而产生的混乱现场。
- 使用锁机制对树结构进行并发控制。
B 树出来了这么久,有了很多优化:
- 不使用 WAL,而在写入时利用 Copy On Write 技术。同时,也方便了并发控制。如 LMDB、BoltDB。
- 对中间节点的 Key 做压缩,保留足够的路由信息即可。以此,可以节省空间,增大分支因子。
- 为了优化范围查询,有的 B 族树将叶子节点存储时物理连续。但当数据不断插入时,维护此有序性的代价非常大。
- 为叶子节点增加兄弟指针,以避免顺序遍历时的回溯。即 B+ 树的做法,但远不局限于 B+ 树。
- B 树的变种,分形树,从 LSM-tree 借鉴了一些思想以优化 seek。
| B-Tree | LSM-Tree | 备注 | |
|---|---|---|---|
| 优势 | 读取更快 | 写入更快 | |
| 写放大 | 1. 数据和 WAL 2. 更改数据时多次覆盖整个 Page | 1. 数据和 WAL 2. Compaction | SSD 不能过多擦除。因此 SSD 内部的固件中也多用日志结构来减少随机小写 |
| 写吞吐 | 相对较低:1. 大量随机写 | 相对较高:1. 较低的写放大(取决于数据和配置)2. 顺序写入 3. 更为紧凑 | |
| 压缩率 | 存在较多内部碎片 | 1. 更加紧凑,没有内部碎片 2. 压缩潜力更大(共享前缀) | 但紧缩不及时会造成 LSM-Tree 存在很多垃圾 |
| 后台流量 | 更稳定可预测,不会受后台 compaction 突发流量影响 | 1. 写吞吐过高,compaction 跟不上,会进一步加重读放大 2. 由于外存总带宽有限,compaction 会影响读写吞吐 3. 随着数据越来越多,compaction 对正常写影响越来越大 | RocksDB 写入太过快会引起 write stall,即限制写入,以期尽快 compaction 将数据下沉 |
| 存储放大 | 有些 Page 没有用满,存在碎片 | 同一个 Key 存多遍 | |
| 并发控制 | 1. 同一个 Key 只存在一个地方 2. 树结构容易加范围锁 | 同一个 Key 会存多遍,一般使用 MVCC 进行控制 |
索引
在介绍 Bitcask、SSTable和LSM-Tree 时,我们提到了哈希索引。这一节,我们再详细地介绍下索引。
- 数据库索引
- 维度1:存储结构(物理存储)
- 聚集索引。数据本身按某个字段有序存储,该字段通常是主键,则称基于此字段的索引为聚集索引,他会将索引和整行数据存在一块。
- 非聚集索引。基于其他字段的索引为非聚集索引,在索引中存储的是索引列的值 + 指向数据行的指针。
- 维度2:数据结构(实现机制)
- B+Tree 索引(含多列索引)
- 全文索引(倒排索引)
- 模糊索引(GIN/GiST/Trigram)
- 哈希索引
- 空间索引(R-Tree)
- 维度3:使用特性(逻辑属性)
- 覆盖索引
- 唯一索引
- 前缀索引
- 函数索引
- 维度1:存储结构(物理存储)
OLAP型
聊完了 OLTP,很多友友好奇 OLAP 是什么呢?其实,一开始对于 AP 场景,仍然使用的传统的 TP 数据库。在模型层面来说,SQL 足够灵活,能够基本满足 AP 查询需求。但在实现层面,传统数据库在 AP 负载中的表现(大数据量吞吐较低)不尽如人意,因此大家开始转向在专门设计的数据库中进行 AP 查询,我们称之为数据仓库(Data Warehouse)。
AP 建模:星状型和雪花型
AP 中的处理模型相对较少,比较常用的有星状模型,也称为维度模型。
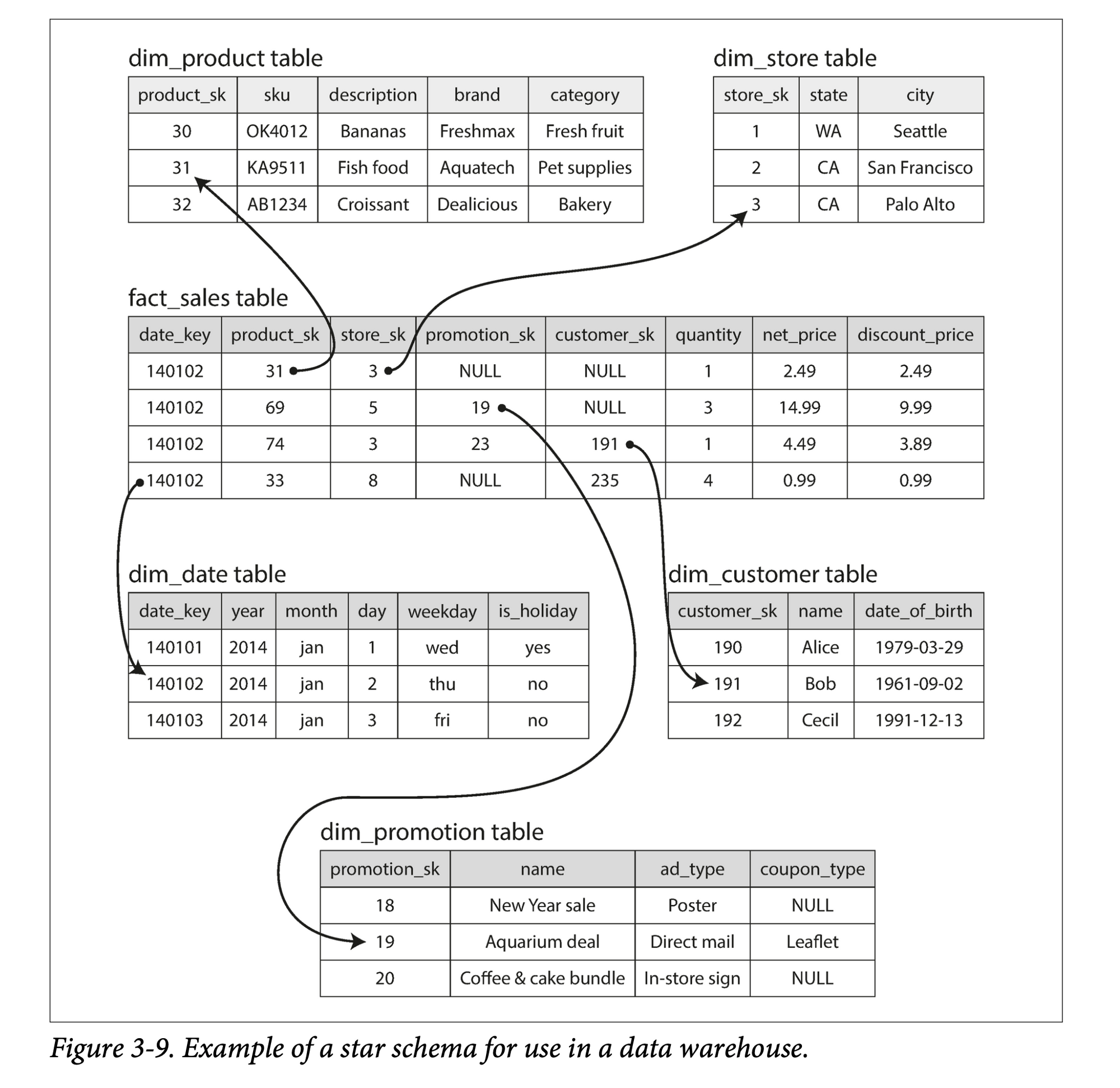
如上图所示,星状模型通常包含一张事件表(fact table) 和多张维度表(dimension tables)。事件表以事件流的方式将数据组织起来,然后通过外键指向不同的维度。
星状模型的一个变种是雪花模型,可以类比雪花(❄️)图案,其特点是在维度表中会进一步进行二次细分,讲一个维度分解为几个子维度。比如品牌和产品类别可能有单独的表格。星状模型更简单,雪花模型更精细,具体应用中会做不同取舍。
在典型的数仓中,事件表可能会非常宽,即有很多的列:一百到数百列。
列存
前一小节我们提到了维度表和事实表,对于后者来说,有可能达到数十亿行和数 PB 大。虽然事实表可能通常有几十上百列,但是单次查询通常只关注其中几个维度(列)。
由于传统数据库通常是按行存储的,这意味着对于属性(列)很多的表,哪怕只查询一个属性,也必须从磁盘上取出很多属性,无疑浪费了 IO 带宽,增大了读放大。
于是一个很自然的想法呼之欲出:每一个列分开存储好不好?
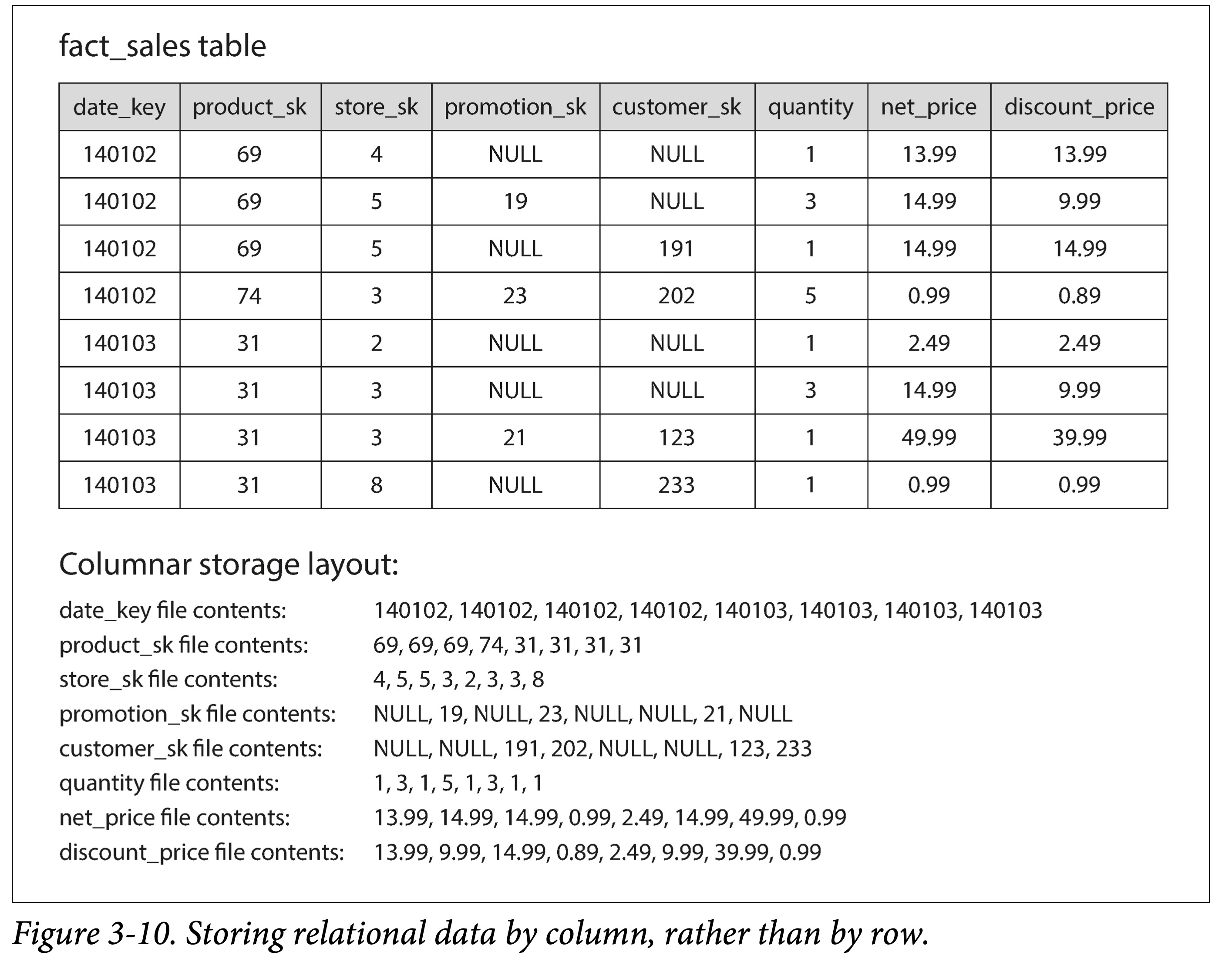
可以看出,不同列之间同一个行的字段可以通过下标来对应。
列压缩
将所有数据分列存储在一块,带来了一个意外的好处,由于同一属性的数据相似度高,因此更易压缩。
如果每一列中值阈相比行数要小的多,可以用位图编码(bitmap encoding)。举个例子,零售商可能有数十亿次的销售交易,但只有 100,000 个不同的产品。

上图中,是一个列分片中的数据,可以看出只有 {29, 30, 31, 68, 69, 74} 六个离散值。针对每个值出现的位置,我们使用一个 bit array 来表示:
- bit map 下标对应列的下标
- 值为 0 则表示该下标没有出现该值
- 值为 1 则表示该下标出现了该值
如果 bit array 是稀疏的,即大量的都是 0,只要少量的 1。其实还可以使用游程编码(RLE,Run-length encoding) 进一步压缩:
- 将连续的 0 和 1,改写成 数量+值,比如 product_sk = 29 是 9 个 0,1 个 1,8 个 0。
- 使用一个小技巧,将信息进一步压缩。比如将同值项合并后,肯定是 0 1 交错出现,固定第一个值为 0,则交错出现的 0 和 1 的值也不用写了。则 product_sk = 29 编码变成 9,1,8
- 由于我们知道 bit array 长度,则最后一个数字也可以省掉,因为它可以通过 array len - sum(other lens) 得到,则 product_sk = 29 的编码最后变成:9,1
位图索引很适合应对查询中的逻辑运算条件,比如:
SQL
WHERE product_sk IN(30,68,69)可以转换为 product_sk = 30、product_sk = 68和 product_sk = 69这三个 bit array 按位或(OR),最终变为
SQL
WHERE product_sk = 31列族
书中特别提到列族。它是 Cassandra 和 HBase 中的的概念,他们都起源于自谷歌的 BigTable 。注意到他们和列式存储有相似之处,但绝不完全相同:
- 同一个列族中多个列是一块存储的,并且内嵌行键。
- 并且列通常不压缩。
因此 BigTable 在用的时候主要还是面向行的,可以理解为每一个列族都是一个子表。
内存处理带宽
数仓的超大规模数据量带来了以下瓶颈:
- 内存处理带宽。数据从内存到 CPU 的通路是有限的。如果处理每行数据都要加载大量无关数据,或者数据格式不紧凑,那么内存带宽会成为瓶颈------CPU 在等数据,而不是在算数据。
- CPU 分支预测错误和流水线停顿。
什么是 CPU 分支预测错误呢?
- CPU 有个硬件单元叫分支预测器(Branch Predictor),它的作用是在分支指令的结果确定之前,根据历史执行模式猜测分支的走向,并让 CPU 推测执行猜中的分支指令。这样可以在等待分支结果的同时继续工作,避免流水线空闲。如果猜对了,效率提升;如果猜错了,需要清空推测执行的指令并重新开始。
举个🌰,
理想状态下,每个时钟周期都能完成一条指令(吞吐量为 1)。假设存在如下的分支指令:
shellcmp eax, 30 ; 比较 eax 是否等于 30 je label_true ; 如果相等,跳转到 label_true mov ebx, 1 ; 否则执行这里(常见路径) jmp next label_true: mov ebx, 2 ; 跳转到这里(罕见路径) next:当 CPU 遇到 je label_true(条件跳转指令)时,不知道下一指令是 mov ebx, 1 还是 mov ebx, 2,因为要等 cmp 的结果出来才知道,但这个结果要几个时钟周期后才能得到。
此时,CPU 有个硬件单元叫分支预测器(Branch Predictor),它会记录历史:之前 100 次这个跳转,95 次没跳,5 次跳了,预测:这次大概率也不跳,于是提前执行 mov ebx, 1 后面的指令。如果发现预测错误,则清空流水线。
为什么数仓会出现 CPU 分支预测错误和流水线停顿 瓶颈呢?
- 数据分布不均匀性加剧
SQL-- 不同时间段的查询 SELECT * FROM orders WHERE amount > 1000; -- 平时:只有 5% 的订单金额 > 1000(容易预测"不满足") -- 双十一:80% 的订单金额 > 1000(预测器频繁出错) -- 双十一后:又回到 5%(再次频繁出错)
- 数据局部性丧失
小数据量(全内存):
┌─────────────────────────┐
│ 满足不满足满足... │ ← 全部在内存,可以学习模式
└─────────────────────────┘
大数据量(磁盘分批加载):
┌──────────┐ 第一批:全是北京用户(全部满足 city='北京')
├──────────┤ 第二批:全是上海用户(全不满足)
├──────────┤ 第三批:混和数据(部分满足)
└──────────┘
每次换批次,分支模式剧变,预测器无所适从- 缓存失效加剧
shell; 处理第1行 cmp age, 30 ; age 在缓存中 je check_city ; 预测器学习:这次跳了 ; 处理第2行(可能缓存未命中,等待加载) ; CPU 空闲,预测器无法学习新模式 ; 处理第3行(数据终于来了) cmp age, 30 ; 模式已经变了 ; 预测器还在用第1行的模式,大概率猜错

关于内存的瓶颈可以通过前述的数据压缩来缓解。对于 CPU 的瓶颈可以使用:
- 列式存储和压缩可以让数据尽可能多地缓存在 L1 中,结合位图存储进行快速处理。
- 使用 SIMD 用更少的时钟周期处理更多的数据。
列式存储的排序
-
由于数仓查询多集中于聚合算子(比如 sum,avg,min,max),列式存储中的存储顺序相对不重要。但也免不了需要对某些列利用条件进行筛选,为此我们可以如 LSM-Tree 一样,对所有行按某一列进行排序后存储。
注意,不可能同时对多列进行排序。因为我们需要维护多列间的下标间的对应关系,才可能按行取数据。同时,排序后的那一列,压缩效果会更好。
-
此外,在分布式数据库中,同一份数据我们会存储多份。对于每一份数据,我们可以按不同列有序存储。这样,针对不同的查询需求,便可以路由到不同的副本上做处理。当然,这样也最多只能建立副本数(通常是 3 个左右)列索引。
这一想法由 C-Store 引入,并且为商业数据仓库 Vertica 采用。
列式存储的写入
上述针对数仓的优化(列式存储、数据压缩和按列排序)都是为了解决数仓中常见的读写负载,读多写少,且读取都是超大规模的数据。一个很自然的现象是,我们针对读做了优化,就让写入变得相对困难。
像 B 树那样的原地更新是不太行的。举个🌰,要在中间某行插入一个数据,纵向来说,会影响所有的列文件(如果不做 segment 的话);为了保证多列间按下标对应,横向来说,又得更新该行不同列的所有列文件。
所幸我们有 LSM-Tree 的追加流。将新写入的数据在内存中 Batch 好,按行按列,选什么数据结构可以看需求。然后达到一定阈值后,批量刷到外存,并与老数据合并。
数仓 Vertica 就是这么做的。
聚合:数据立方和物化视图
物化,可以简单理解为持久化。本质上是一种空间换时间的 tradeoff。
数据仓库查询通常涉及聚合函数,如 SQL 中的 COUNT、SUM、AVG、MIN 或 MAX。如果这些函数被多次用到,每次都即时计算显然存在巨大浪费。因此一个想法就是,能不能将其缓存起来。
其与关系数据库中的视图(View)区别在于,视图是虚拟的、逻辑存在的,只是对用户提供的一种抽象,是一个查询的中间结果,并没有进行持久化。
物化视图本质上是对数据的一个摘要存储,如果原数据发生了变动,该视图要被重新生成。因此,如果写多读少,则维持物化视图的代价很大。但在数仓中往往反过来,因此物化视图才能较好的起作用。
物化视图一个特化的例子,是数据立方(data cube,或者 OLAP cube):按不同维度对量化数据进行聚合。
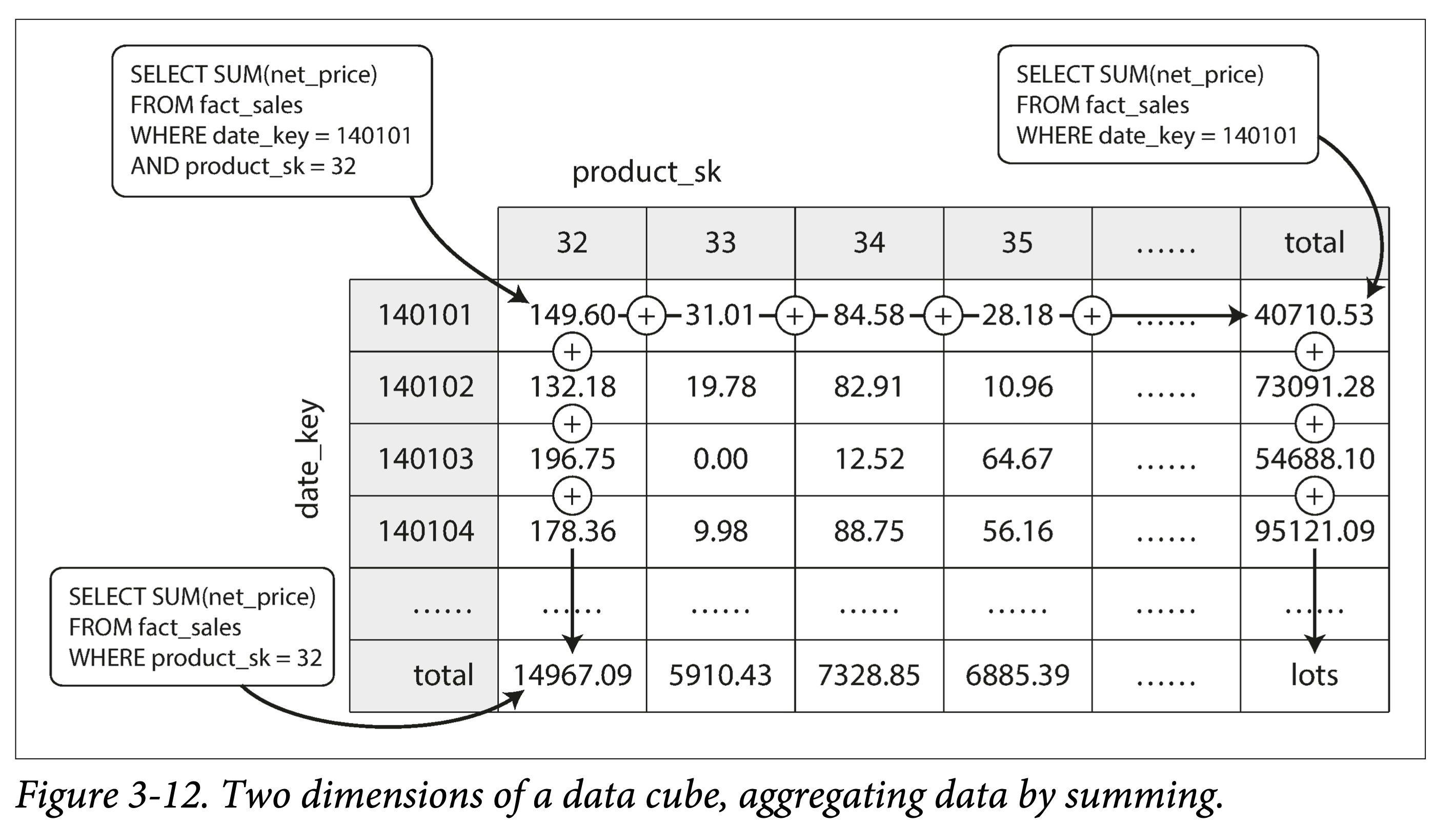
上图是一个按日期和产品分类两个维度进行加和的数据立方,当针对日期和产品进行汇总查询时,由于该表的存在,就会变得非常快。
在实际中,需要针对性的识别(或者预估)每个场景查询分布,针对性的构建物化视图。