MySQL22 - 分库分表的聚合问题
文章目录
- [MySQL22 - 分库分表的聚合问题](#MySQL22 - 分库分表的聚合问题)
-
- 一:问题的引入
- 二:切开后怎么聚合
-
- 1:什么时候该分
- 2:多维查询的三种解法
-
- 2.1:异构索引表(双写冗余)
- [2.2:大宽表 + ElasticSearch](#2.2:大宽表 + ElasticSearch)
- 三:分表后SQL三大坑
-
- [1:分表后的全局 ID 怎么生成](#1:分表后的全局 ID 怎么生成)
- [2:分表后,怎么做深分页(Limit 10000, 10)](#2:分表后,怎么做深分页(Limit 10000, 10))
- [3:扩容怎么办?原本 16 个库不够用了,要扩到 32 个](#3:扩容怎么办?原本 16 个库不够用了,要扩到 32 个)
一:问题的引入
你们公司的订单表有 2 亿数据,怎么做的分库分表?
如果我们按用户 ID(user_id)取模,分了 16 个库,每个库 64 张表,一共 1024 张表。这样用户查自己的订单特别快,直接定位到具体的表。
此时问题就来了,那商家(Seller)要查自己店铺的订单列表怎么办? 商家又没有 user_id,按你的分法,商家查一次岂不是要扫描全部 1024 张表?这系统能不崩?
yaml
# ds0 是数据源名称,db0 是实际的数据库名称。在配置中:
# ds0 是一个逻辑名称,代表一个数据库连接配置
# db0 是 MySQL 中真实的数据库名
databaseName: order_system
dataSources:
ds0:
url: jdbc:mysql://localhost:3306/db0
username: root
password: ******
ds1:
url: jdbc:mysql://localhost:3306/db1
username: root
password: ******
# ... 一直到 ds15,共16个数据源
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds$->{0..15}.t_order_$->{0..63}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds$->{user_id % 16}
table_inline:
type: INLINE
props:
algorithm-expression: t_order_$->{user_id % 64}内部执行情况如下:假设我们要插入一条订单数据:
sql
INSERT INTO t_order (order_id, user_id, amount)
VALUES (10001, 12345, 299.00);第1步:ShardingSphere 接收 SQL
应用层发送 SQL 到 ShardingSphere,它作为中间件拦截了这个 SQL。
第2步:分片路由计算
根据配置的分片算法计算:
java
user_id = 12345
// 计算目标库:user_id % 16 = 12345 % 16 = 9
// 所以目标库是 ds9
// 计算目标表:user_id % 64 = 12345 % 64 = 57
// 所以目标表是 t_order_57第3步:SQL 路由改写
ShardingSphere 将原始 SQL 改写为:
sql
-- 原SQL
INSERT INTO t_order (order_id, user_id, amount) VALUES (10001, 12345, 299.00);
-- 改写后的SQL
INSERT INTO ds9.t_order_57 (order_id, user_id, amount) VALUES (10001, 12345, 299.00);第4步:查找数据源配置
ShardingSphere 查找 ds9 对应的实际数据库连接:
yaml
ds9: # 逻辑数据源
url: jdbc:mysql://localhost:3306/db9 # 实际数据库是 db9
username: root
password: ******第5步:执行 SQL
ShardingSphere 连接到 localhost:3306/db9 数据库,执行:
sql
INSERT INTO t_order_57 (order_id, user_id, amount)
VALUES (10001, 12345, 299.00);第6步:返回结果
数据库执行成功,返回结果给 ShardingSphere,再返回给应用。
| 逻辑数据源 | 实际数据库 | 包含的表 |
|---|---|---|
| ds0 | db0 | t_order_0 ~ t_order_63 |
| ds1 | db1 | t_order_0 ~ t_order_63 |
| ds2 | db2 | t_order_0 ~ t_order_63 |
| ... | ... | ... |
| ds9 | db9 | t_order_0 ~ t_order_63 |
| ... | ... | ... |
| ds15 | db15 | t_order_0 ~ t_order_63 |
二:切开后怎么聚合
所以分库分表不仅仅是"把数据切开"这么简单,难点永远在于 "切开后怎么聚合"
1:什么时候该分
面试里问"什么时候分库分表",很多人上来就背:"阿里开发手册说单表超过 500 万行或者 2GB 就要分......",显然过于教条了,现在的现在的硬件(SSD + 大内存),单表跑个 1000 万数据,索引建好了照样飞快。
所有真正逼你分库分表的,通常不是 "存储容量",而是 "连接数 " 和 "维护成本":
-
连接数瓶颈 :一个 MySQL 实例的连接数是有限的(通常几千个)。当并发 QPS 极高,所有请求都打到一个主库,数据库连接池瞬间被打爆,这时候必须 "分库" 来分摊并发写压力。
-
DDL 痛苦 :给一张 5000 万行的表加个字段,你试试?锁表能锁到你怀疑人生,业务直接停摆。这时候必须 "分表" 来降低单表大小。
DDL:动结构(Create、Alter、Drop)
操作后自动提交,不能回滚,影响数据库结构
DML:动数据(Insert、Update、Delete)
操作表里的数据,可以回滚(在事务中)
DQL:查数据(Select)
最常用的操作,不修改数据
DCL:控权限(Grant、Revoke)
TCL:管事务(Commit、Rollback)
2:多维查询的三种解法
2.1:异构索引表(双写冗余)
既然切分维度不能兼顾,那就 用空间换时间
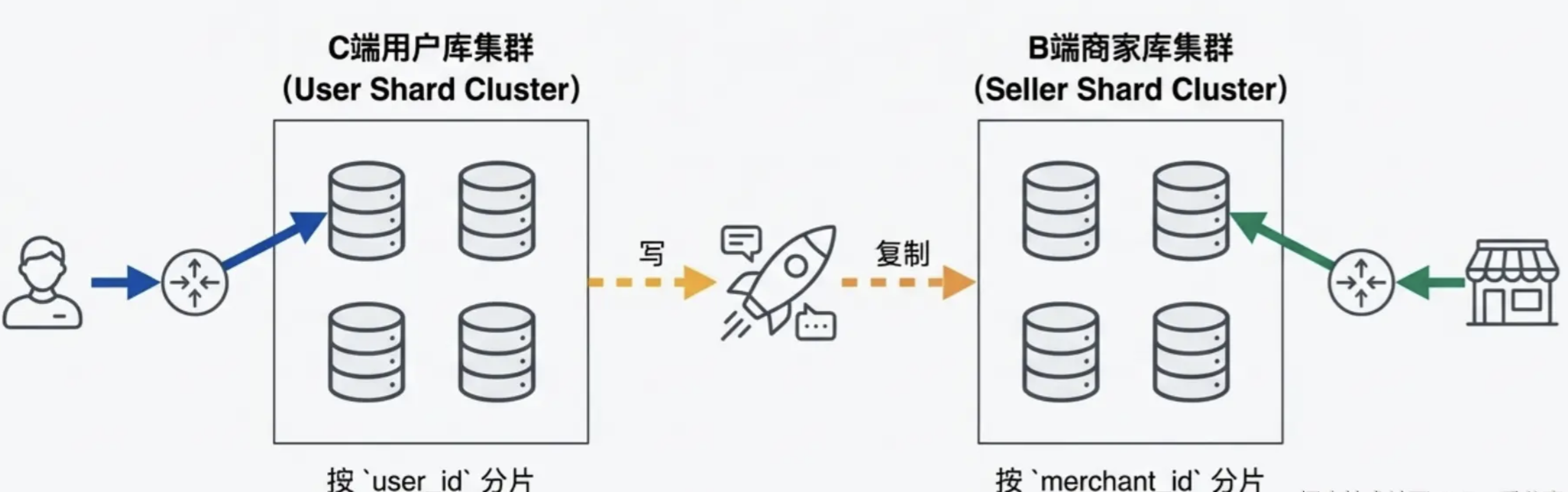
- C 端(用户视角) :主库依然按 user_id % 16 分片。用户查订单,快如闪电。
- B 端(商家视角) :再搞一套"商家库",数据按 merchant_id % 16 分片。
- 同步机制:用户下单写入"用户库"成功后,异步把数据同步一份到"商家库"。
这种方案需要配置两个独立的 ShardingSphere 规则,一个用于用户库,一个用于商家库:
yaml
# shardingsphere-config.yaml
databaseName: order_system
dataSources:
# 用户库数据源 (16个)
user_ds0:
url: jdbc:mysql://localhost:3306/user_db0
username: root
password: ******
user_ds1:
url: jdbc:mysql://localhost:3306/user_db1
username: root
password: ******
# ... user_ds2 ~ user_ds15
# 商家库数据源 (16个)
merchant_ds0:
url: jdbc:mysql://localhost:3306/merchant_db0
username: root
password: ******
merchant_ds1:
url: jdbc:mysql://localhost:3306/merchant_db1
username: root
password: ******
# ... merchant_ds2 ~ merchant_ds15
rules:
- !SHARDING
tables:
# 用户视角的订单表配置
t_order_user:
actualDataNodes: user_ds$->{0..15}.t_order_user_$->{0..63}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: user_db_inline
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: user_table_inline
# 商家视角的订单表配置
t_order_merchant:
actualDataNodes: merchant_ds$->{0..15}.t_order_merchant_$->{0..63}
databaseStrategy:
standard:
shardingColumn: merchant_id
shardingAlgorithmName: merchant_db_inline
tableStrategy:
standard:
shardingColumn: merchant_id
shardingAlgorithmName: merchant_table_inline
shardingAlgorithms:
# 用户库分片算法
user_db_inline:
type: INLINE
props:
algorithm-expression: user_ds$->{user_id % 16}
user_table_inline:
type: INLINE
props:
algorithm-expression: t_order_user_$->{user_id % 64}
# 商家库分片算法
merchant_db_inline:
type: INLINE
props:
algorithm-expression: merchant_ds$->{merchant_id % 16}
merchant_table_inline:
type: INLINE
props:
algorithm-expression: t_order_merchant_$->{merchant_id % 64}
java
@Service
public class OrderService {
@Autowired
private RabbitTemplate rabbitTemplate;
@Transactional
public void createOrder(Order order) {
// 1. 写入用户库(主库)
orderMapper.insertToUserDb(order);
// 2. 发送消息,异步同步到商家库
rabbitTemplate.convertAndSend("order.exchange", "order.sync", order);
}
}
@Component
@Slf4j
public class OrderSyncConsumer {
@Autowired
private MerchantOrderMapper merchantOrderMapper;
@RabbitListener(queues = "order.sync.queue")
public void syncToMerchantDb(Order order) {
try {
// 3. 异步写入商家库
merchantOrderMapper.insertToMerchantDb(order);
} catch (Exception e) {
log.error("同步订单到商家库失败", e);
// 记录失败日志,后续补偿处理
}
}
}如果消息发送失败,或者消费者挂了,商家库岂不是一直少订单?
为了保证最终一致性,我们通常采用 RocketMQ 事务消息 或 本地事务表 + 定时轮询 模式
- 事务消息: 利用 MQ 的半消息机制,确保'本地订单入库'和'消息发送'要么同时成功,要么同时失败。
- 兜底重试: 配合定时任务扫描未确认的消息,确保 At Least Once(至少投递一次) ,保证商家库绝对不会丢单。"
2.2:大宽表 + ElasticSearch
如果运营人员要按"下单时间"、"金额"、"地区"等奇葩条件筛选,MySQL 分库分表就彻底歇菜了。
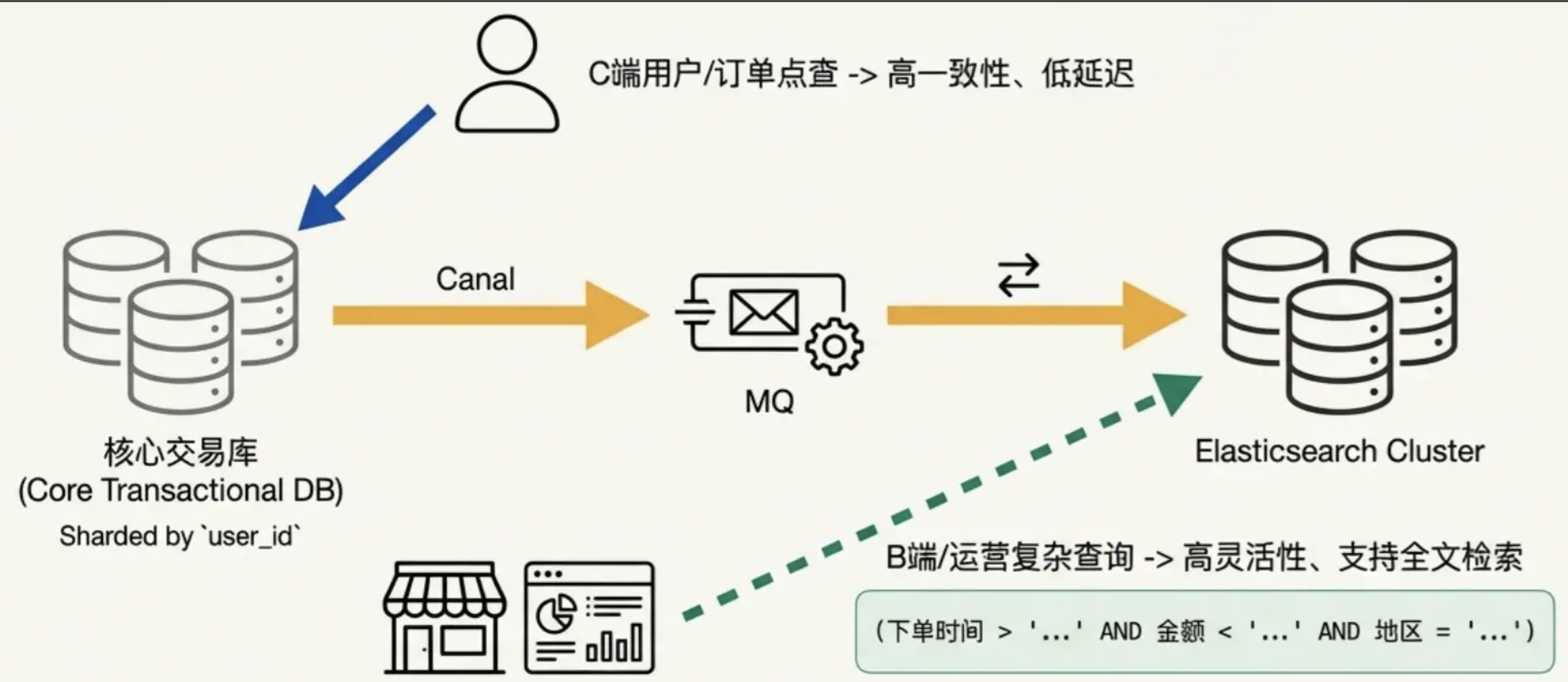
- MySQL 只负责核心交易链路(存、取、改状态),按 user_id 分片。
- 把数据通过 Canal + MQ 实时同步到 Elasticsearch (ES)。
- 商家查询、运营后台查询、复杂报表,全部走 ES。
ES 不是实时强一致的(通常有 1 秒延迟)。
如果商家刚收到新订单通知,点进去却在 ES 查不到,怎么办?
在代码层做降级逻辑。当 ES 查不到结果(或数据明显滞后)时,系统会自动降级回 MySQL 的商家异构库进行点查。虽然后端压力大一点,但保证了用户体验的闭环。
三:分表后SQL三大坑
1:分表后的全局 ID 怎么生成
绝对不能用自增主键。面试时推荐答 美团 Leaf 的号段模式。相比于雪花算法(Snowflake),它不强依赖机器时钟,不会因为时钟回拨导致 ID 重复,更适合严谨的金融级业务。
- 数据库自增ID:就像每次做蛋糕都要去总部申请一个唯一的编号,做完一个申请一个。总部很忙,一旦总部出问题,整个蛋糕店就得停工。
- Leaf号段模式:相当于总部一次性批发给蛋糕店一批连续编号的蛋糕券(比如 #1001-#2000)。蛋糕店自己用券卖蛋糕,速度极快。当券只剩10%时,就派个小弟异步去总部领下一批券(比如 #2001-#3000)。这样,即使总部暂时联系不上,蛋糕店也能靠手里的券继续营业
双buffer(双缓存区)是Leaf保证高可用和高性能的秘诀。每个业务在Leaf服务的内存中都有两个缓存区(Segment),当前一个Buffer的ID快用完时,会异步地去加载下一个Buffer,确保了发号过程行云流水,不会卡顿
1️⃣ 从美团官方GitHub仓库克隆Leaf项目:https://github.com/Meituan-Dianping/Leaf
2️⃣ 在你的MySQL中创建一个数据库(例如 leaf_db),执行建表语句并初始化
sql
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '业务标识,如 order',
`max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已分配的最大ID',
`step` int(11) NOT NULL COMMENT '号段步长,即每次批发的数量',
`description` varchar(256) DEFAULT NULL COMMENT '描述',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 初始化订单服务的发号记录
INSERT INTO leaf_alloc(biz_tag, max_id, step, description)
VALUES ('order', 1, 2000, '订单ID发号器');3️⃣ 修改 leaf-server/src/main/resources/leaf.properties 文件,开启号段模式并配置数据库连接
properties
# 开启号段模式
leaf.segment.enable=true
# 关闭雪花算法模式(两者不能同时开启)
leaf.snowflake.enable=false
# 数据库连接配置
leaf.jdbc.url=jdbc:mysql://你的数据库IP:3306/leaf_db?useUnicode=true&characterEncoding=utf8
leaf.jdbc.username=你的用户名
leaf.jdbc.password=你的密码4️⃣ 启动Leaf服务。你可以将它作为一个独立的发号中心集群来部署,以提高可用性
2:分表后,怎么做深分页(Limit 10000, 10)
分布式数据库的'内存杀手'。中间件需要去每个分片取前 10010 条,聚合排序,性能极差
- 业务规避: 禁止跳页,只允许'下一页'。
- Seek 游标法: 利用
WHERE id < last_id LIMIT 10的方式查询,利用索引避开 Offset 扫描。 - ES Scroll: 如果是极其复杂的深分页,直接走 ES。"
3:扩容怎么办?原本 16 个库不够用了,要扩到 32 个
采用 2 倍扩容(Scale Out) ,且必须配合 在线数据迁移
- 全量同步: 将旧库数据全量搬运到新库。
- 增量追平: 利用 Canal/DTS 追平迁移期间产生的增量数据。
- 数据校验: 全量比对一致后。
- 切流: 短暂切断写入(秒级),更新路由规则,将流量切到新库。