版本与引用边界
- 论文:Drive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving(arXiv:2601.22032v1,2026-01-29)。
- 代码:官方仓库 https://github.com/linhanwang/Drive-JEPA(下文简称 Drive-JEPA repo)。
- 本文目标:给出"能对照论文、能对照代码路径、能跑通脚本闭环"的工程化解读。
- 说明:论文中的"Driving Video Pretraining(V-JEPA 预训练阶段)"在开源仓库里未必完整包含训练代码;若缺失,本文会明确标注"只在论文中出现/在 repo 中仅体现为 checkpoint 加载"。
目录
- 1 创新点(论文贡献拆解)
- 2 原理与代码实现分析(论文 §3 对照实现)
- 3 代码结构 / 模型结构(repo 导航图)
- 4 数据准备 / 环境配置 / 训练与测试闭环(可复制 runbook + 坑位清单)
1. 创新点:Drive-JEPA 到底"新"在哪里?
论文在 Introduction 里把问题拆成两个瓶颈:
- 视频世界模型预训练对规划迁移增益有限:像素重建太贵且可能学到与决策无关的视觉细节;而 latent dynamics 方法往往作为辅助损失,规模化后提升不明显。
- 监督的多模态不足:真实驾驶数据里每个场景通常只有"一条人类轨迹",但未来行为本质多模态,导致 imitation learning 易 mode collapse。
Drive-JEPA 的创新点可以归纳为(论文贡献点 + 方法结构):
- 把 V-JEPA 引入端到端驾驶:用"预测 latent 表征"的自监督目标替代像素重建,训练更高效,并利用 EMA + stop-grad 避免表征塌陷。
- 把"多模态轨迹"从生成问题转成"蒸馏监督":用规则模拟器离线打分,得到每个场景的多条高质量 pseudo-teacher trajectories,训练时指导 proposal 分布,而不是只对齐单一人类轨迹。
- 提出 momentum-aware trajectory selection:在"每帧评分选择"的基础上加入跨帧畸变/舒适度项,减少帧间抖动,提高长时舒适性指标(论文强调对 NAVSIM v2 的 EC 有显著改善)。
- proposal-centric 的轻量辅助任务:不依赖昂贵的 dense perception supervision(BEV seg / 3D det 等),而围绕 proposal waypoints 做 mapping 与 collision 的轻量预测任务。
1.1 用 §4 Experiments 表格"量化"创新点(建议读者先看这一段)
论文第 4 节的几张对比表,基本把 Drive-JEPA 的价值讲得很清楚:
- Perception-free(仅前视相机 + 简单 decoder)也能拉开差距 :Table 1 显示在 perception-free planner 对比中,PDMS 从 83.8/85.1/86.1 提升到 89.0 ,同时预训练数据规模扩大到 208h(相较 prior 的 ~20h 或 128h)。论文摘要也概括为"perception-free setting 提升约 3 PDMS"。
- NAVSIM v1(PDMS):93.3(ViT/L)且对 ResNet34 设定为最优 :Table 2(v1)中,Drive-JEPA(ViT/L, Camera)达到 93.3 PDMS ,论文正文也指出在 ViT/L 设定下"仅次于 DriveSuprim(93.5,使用更强数据增强)";同时在 ResNet34(Camera)设定下,Drive-JEPA 达到 91.5 PDMS ,优于同表中的其它方法。另在 perception-free block(ViT/L, Camera)为 89.0 PDMS,并且论文强调该分数已"接近依赖 perception annotations 的方法"。
- NAVSIM v2(EPDMS)SOTA:87.8,EC 明显强 :Table 3(v2)中,Drive-JEPA(ViT/L)达到 87.8 EPDMS 。更关键的是 Extended Comfort(EC)项很高(表中为 84.8),对应论文里"MTD 增加多样性后可能牺牲舒适度,再用 momentum-aware selection 把 EC 拉回来"的设计动机。
- 闭环 Bench2Drive:MTD 带来稳定增益(对 iPad) :Table 4(Bench2Drive)里,Drive-JEPA 的 Driving Score 为 157.85 ,对比 iPad 的 153.83 ,约 +4.0 DS(论文文字也强调这点)。
- "用什么预训练"很关键:V-JEPA objective 明显占优 :Table 7 对比主流视觉/视频预训练 encoder,在相同简单 decoder 的 perception-free setting 下:Epona(ViT/G)为 86.2 PDMS 、V-JEPA 2(ViT/L)为 86.1 PDMS ,而本文"Driving Video Pretraining + V-JEPA objective"(ViT/L)达到 89.0 PDMS;同时 MAE/DepthAnything 在该 setup 下"无法收敛"(论文原文)。
把这些表格结论串起来看,可以得到一个更工程化的 takeaway:Drive-JEPA 的"新"不只是提出了模块,而是把"高效可扩展的视频表征预训练(V-JEPA)"和"可离线缓存的多模态监督(MTD)"做成了一个能在 v1/v2 指标上同时拿到高安全/高效率/高舒适的闭环系统。
2. 原理与代码实现分析(论文 §3 对照实现)
这一部分按论文 §3.1--§3.6 组织,并在每一节给出"工程上应该出现的组件/脚本/文件"。
2.0 一张图看懂:三阶段 + 一个选择器
论文 Fig.2 把 Drive-JEPA 拆为三块主模块 + 一个选择器:
- Driving Video Pretraining:用 V-JEPA 自监督预训练 ViT 视频编码器,学到规划对齐的可预测表征。
- Waypoint-anchored Proposal Generation:生成多条候选轨迹 proposal,并迭代 refine。
- Multimodal Trajectory Distillation (MTD):用规则模拟器离线打分得到多模态伪教师轨迹,指导 proposal 分布,缓解 mode collapse。
- Momentum-aware Trajectory Selection:对 proposal 打分,并引入跨帧舒适度/畸变惩罚,抑制抖动。
论文 Fig.2(架构总览):
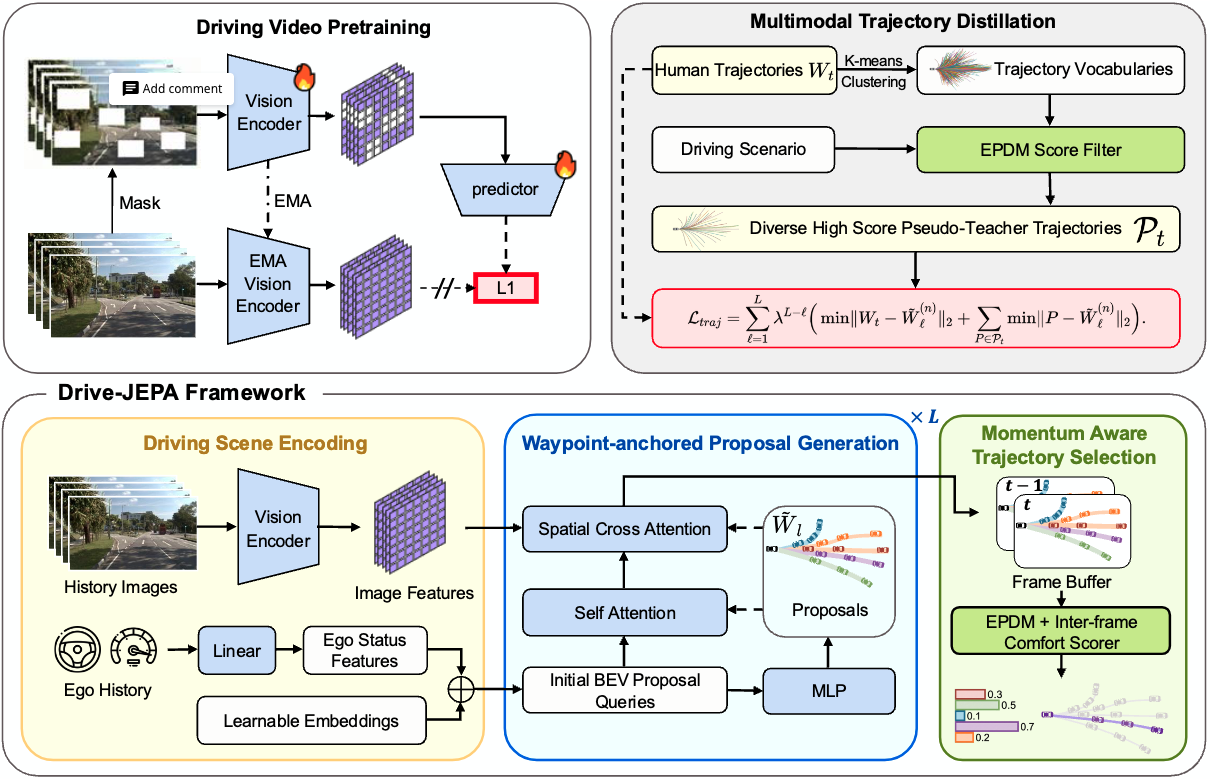
工程视角(更贴近代码数据流)的 Mermaid 版本:
Stage C: Distillation + Selection
Stage B: Proposal-centric Planner
Stage A: Driving Video Pretraining
pretrained weights
8 frames 2Hz front cam 512x256
ViT encoder E_theta
Predictor P_phi mask token Delta_y
EMA target E_theta_bar stop grad
Latent target
L1 loss on masked patches
Video BEV features F_t
Init queries Q0 N_p x M x D
Refine ell 0 to L-1 WADA plus MLP
Trajectory proposals W_tilde_L_n
Human traj W_t
L_traj
Pseudo teachers P_t from simulator
Scorer MLP outputs S
Momentum aware recalibration
Prev selected W_hat_prev
argmax select W_hat_t
2.1 V-JEPA:为什么适合"规划对齐"的视频预训练?(论文 §3.1, §3.2)
2.1.1 目标函数与防塌陷
论文 §3.1 给出 V-JEPA 目标(式 (1))。
- 输入是 masked view xxx(随机丢弃时空 patch)
- 目标是 target view yyy 的编码特征(EMA target encoder 产生,stop-gradient)
- 只在 mask 的位置上计算预测误差
minθ,ϕ,Δy ∥Pϕ(Δy,Eθ(x))−sg(Eθˉ(y))∥1 \min_{\theta,\phi,\Delta_y}\;\left\| P_{\phi}(\Delta_y, E_{\theta}(x)) - \operatorname{sg}(E_{\bar\theta}(y)) \right\|_1 θ,ϕ,Δymin∥Pϕ(Δy,Eθ(x))−sg(Eθˉ(y))∥1
两个稳定训练关键点:
- stop-gradient:目标分支不反传。
- EMA target encoder EθˉE_{\bar\theta}Eθˉ:指数滑动平均更新,避免表征塌陷。
工程映射:你在代码里通常会看到 online encoder / predictor / EMA target encoder / mask 策略与 mask token。
2.1.2 驾驶视频预训练数据形态(论文 §3.2)
论文明确了 clip 处理方式:
- 数据来源:CoVLA / DrivingDojo / OpenScene
- 仅 front-view camera
- 8 帧 clips、2 Hz、512×256
这决定了后续 planner 输入的时间窗口,也解释了论文 Appendix B 里提到"使用 ItI_tIt 与 It−1I_{t-1}It−1,输入张量为 2×512×2562\times512\times2562×512×256"。
代码侧提示:如果 repo 不包含完整 pretrain pipeline,至少会包含 encoder checkpoint 的加载/冻结/学习率设置等逻辑。
2.2 Perception-free 最小 decoder(论文 §3.2)
论文提供了一个非常"工程友好"的最小 perception-free 闭环:
- ViT encoder 提取时空特征 Ft∈RNf×D\mathbf{F}_t\in\mathbb{R}^{N_f\times D}Ft∈RNf×D
- MMM 个 learnable query embeddings Q∈RM×D\mathbf{Q}\in\mathbb{R}^{M\times D}Q∈RM×D(每个 query 对应一个未来 waypoint)
- Transformer decoder cross-attention:
H=TransformerDecoder(Q,Ft) \mathbf{H}=\text{TransformerDecoder}(\mathbf{Q},\mathbf{F}_t) H=TransformerDecoder(Q,Ft)
- MLP 输出 waypoints:
W^t=MLP(H) \hat{W}^t=\text{MLP}(\mathbf{H}) W^t=MLP(H)
监督:waypoint 的 MSE。
代码侧常见对应:
encoder+decoder+query embeddings+waypoint head。Drive-JEPA repo 中 perception-free agent 通常在navsim_v1/navsim/agents/drive_jepa_perception_free/。
2.3 Waypoint-anchored Proposal Generation(论文 §3.3)
核心:不要依赖固定离散 vocabulary(离散化误差、覆盖不足),而是 在线生成连续 proposals 并迭代 refine。
2.3.1 用 ego status 初始化 proposal queries
- 视觉特征 Ft∈RNf×D\mathbf{F}_t\in\mathbb{R}^{N_f\times D}Ft∈RNf×D
- ego status 投影为 et∈R1×D\mathbf{e}_t\in\mathbb{R}^{1\times D}et∈R1×D
- proposal queries:Q0∈RNp×M×D\mathbf{Q}_0\in\mathbb{R}^{N_p\times M\times D}Q0∈RNp×M×D(注入 et\mathbf{e}_tet + positional embeddings)
论文给的实现细节:Np=32N_p=32Np=32(§4.2)。
2.3.2 WADA:在"预测 waypoint 附近"做特征聚合
第 ℓ\ellℓ 次迭代:
- MLP 解码 Qℓ\mathbf{Q}\ellQℓ 得到候选轨迹 W~ℓ(n)\tilde{W}\ell(n)W~ℓ(n)
- WADA 在每个 waypoint 位置附近,从 Ft\mathbf{F}_tFt 聚合特征(论文类比 lift-splat 的 BEV sampling)
- 更新:
Qℓ+1=MLP(WADA(Qℓ,W~ℓ,Ft)) \mathbf{Q}{\ell+1}=\text{MLP}(\text{WADA}(\mathbf{Q}\ell,\tilde{W}_\ell,\mathbf{F}_t)) Qℓ+1=MLP(WADA(Qℓ,W~ℓ,Ft))
2.3.3 min-over-N + coarse-to-fine 轨迹损失(没有 MTD 时)
Ltraj=∑ℓ=0L−1λL−ℓ−1 minn∈{1..Np}∥Wt−W~ℓ(n)∥2 \mathcal{L}{traj}=\sum{\ell=0}^{L-1} \lambda^{L-\ell-1}\;\min_{n\in\{1..N_p\}} \|W_t-\tilde{W}_\ell(n)\|_2 Ltraj=ℓ=0∑L−1λL−ℓ−1n∈{1..Np}min∥Wt−W~ℓ(n)∥2
论文设 λ=0.1\lambda=0.1λ=0.1,鼓励从粗到细 refine。
问题:若每个场景只有一条人类轨迹 WtW_tWt,min-over-N 会把 proposals 拉向一个 mode(mode collapse)。
2.4 Multimodal Trajectory Distillation(论文 §3.4)
MTD 把"多模态缺失"变成一个离线打分 + 在线蒸馏的工程流程:
- 构建 trajectory vocabulary(8192 centers)
- 规则模拟器离线打分(EPDMS)
- 每个场景选择多条高质量 pseudo-teachers Pt\mathcal{P}_tPt
- 训练时对齐 human trajectory + pseudo-teachers
2.4.1 Vocabulary:8192 centers
论文:收集训练集里 >100k trajectories,用 k-means 选 8192 个中心。
2.4.2 离线打分:EPDMS + "8 waypoint → 41 point"
论文关键工程细节:
- PID controller:把 8 waypoints densify 为 41 点轨迹
- replay 其他 agent / 红绿灯等,计算碰撞与规则
- 论文提到对规则模拟器做了向量化加速,适配大规模离线 scoring
离线打分/缓存的 Mermaid(有助于理解 repo 的 metric cache):
Training time
Load scene token
Lookup cache path via metadata
Load P_t / metrics cache
Compute L_traj with human + P_t
Offline: build pseudo-teachers / caches
Collect trajectory vocabulary: k-means, 8192 centers
For each scene and each traj run rule-based simulation
Compute EPDMS/metrics; PID 8 wp to 41 pts
Select high-quality set: score >= 0.95
Sample N_pseudo trajectories per scene as P_t
Persist metric cache files
Write metadata CSV: token to cache path
2.4.3 伪教师选择:阈值 0.95(论文 Appendix B)
- simulated EPDMS 阈值:0.95
- 超过阈值的轨迹多于 NpseudoN_{pseudo}Npseudo 时:训练时从高分集合中均匀随机采样 NpseudoN_{pseudo}Npseudo 条
2.4.4 带伪教师的轨迹损失(论文式 (2))
∑ℓ=1LλL−ℓ(minn∥Wt−W~ℓ(n)∥2+∑P∈Ptminn∥P−W~ℓ(n)∥2) \sum_{\ell=1}^{L}\lambda^{L-\ell}\left( \min_n\|W_t-\tilde{W}_\ell(n)\|2 + \sum{P\in\mathcal{P}t}\min_n\|P-\tilde{W}\ell(n)\|_2 \right) ℓ=1∑LλL−ℓ(nmin∥Wt−W~ℓ(n)∥2+P∈Pt∑nmin∥P−W~ℓ(n)∥2)
论文 Fig.3(有/无 MTD 的 proposals 多样性对比):
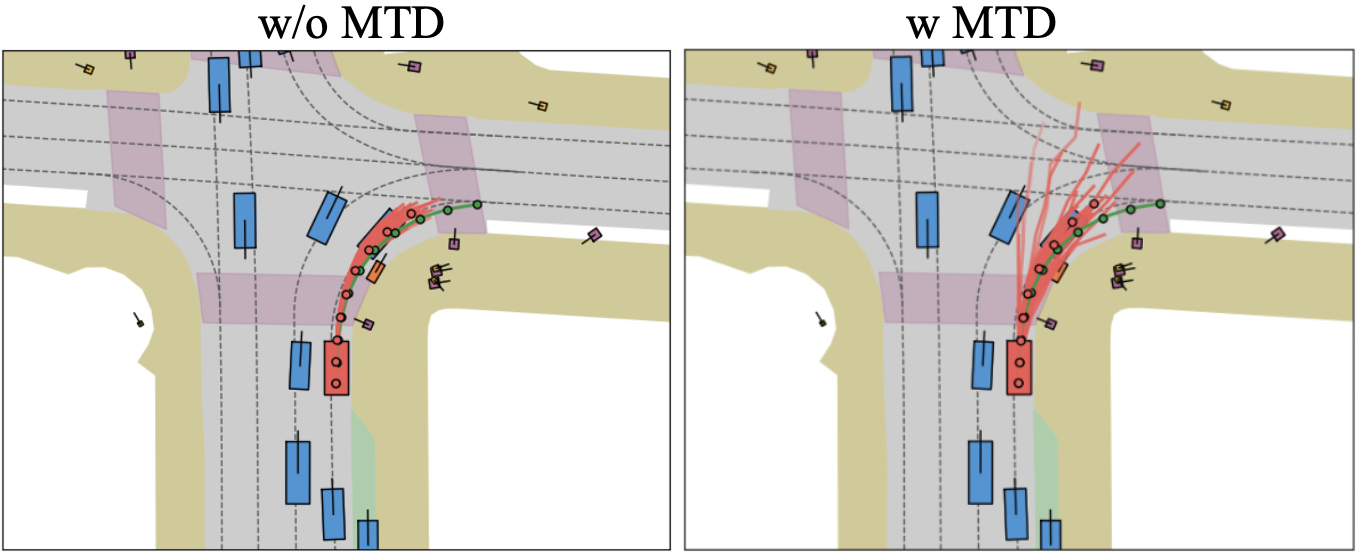
2.5 Momentum-aware Trajectory Selection(论文 §3.5)
2.5.1 Learned scorer
- 对 QL∈RNp×M×D\mathbf{Q}_L\in\mathbb{R}^{N_p\times M\times D}QL∈RNp×M×D 沿 waypoint 维度 max-pooling 得到 QˉL∈RNp×D\bar{\mathbf{Q}}_L\in\mathbb{R}^{N_p\times D}QˉL∈RNp×D
- MLP 输出 S∈RNp×1S\in\mathbb{R}^{N_p\times 1}S∈RNp×1
- BCE 训练:Lscore=BCE(S,S^)\mathcal{L}_{score}=\text{BCE}(S,\hat{S})Lscore=BCE(S,S^)(监督来自模拟器评估)
2.5.2 跨帧重标定:S←(7S+Sc)/8S \leftarrow (7S+S_c)/8S←(7S+Sc)/8
论文指出:MTD 提升多样性,但可能放大帧间差异导致不适。
- 计算 distortion-based comfort score ScS_cSc:用上一帧已选 W^t−1\hat{W}^{t-1}W^t−1 与当前 proposals 比较
- 重标定:
S←7S+Sc8 S \leftarrow \frac{7S + S_c}{8} S←87S+Sc
最终选择:W^t=W~L(argmaxnSn)\hat{W}^t=\tilde{W}_L(\arg\max_n S_n)W^t=W~L(argmaxnSn)。
2.6 Loss 组成:proposal-centric 轻量辅助任务(论文 §3.6)
论文采用两个辅助任务:
- proposal-centric mapping(on-road / on-route):
Lmap=BCE(R,R^),R∈RNp×M×2 \mathcal{L}_{map}=\text{BCE}(R,\hat{R}),\quad R\in\mathbb{R}^{N_p\times M\times 2} Lmap=BCE(R,R^),R∈RNp×M×2
- proposal-centric collision prediction(log-replay simulation 得到 waypoint collision probability):
Lcolli=∥Av−A^v∥+0.1 BCE(Av,A^v) \mathcal{L}_{colli}=\|A_v-\hat{A}_v\| + 0.1\;\text{BCE}(A_v,\hat{A}_v) Lcolli=∥Av−A^v∥+0.1BCE(Av,A^v)
总损失:
L=Ltraj+wscoreLscore+wmapLmap+wcolliLcolli \mathcal{L}=\mathcal{L}{traj}+w{score}\mathcal{L}{score}+w{map}\mathcal{L}{map}+w{colli}\mathcal{L}_{colli} L=Ltraj+wscoreLscore+wmapLmap+wcolliLcolli
权重(论文给定):wscore=1, wmap=2, wcolli=1w_{score}=1,\;w_{map}=2,\;w_{colli}=1wscore=1,wmap=2,wcolli=1。
3. 代码结构 / 模型结构(repo 导航图)
这一节假设你已经 clone 了 Drive-JEPA repo,并关注 navsim_v1/ 相关实现(该 repo 用 NAVSIM devkit 做训练/评测闭环)。
3.1 论文模块 → repo 位置(索引表)
| 论文模块 | 你在代码里应该找的对象 | Drive-JEPA repo 位置(常见) |
|---|---|---|
| Perception-free planner | transformer decoder + learnable queries + waypoint head | navsim_v1/navsim/agents/drive_jepa_perception_free/drive_jepa_model.py |
| Perception-based planner | proposal queries、迭代 refine、proposal head、scorer head 等 | navsim_v1/navsim/agents/drive_jepa_perception_based/drive_jepa_model.py + drive_jepa_config.py |
| 数据缓存(features/targets) | dataset caching 入口脚本、cache_path 组织 | navsim_v1/navsim/planning/script/run_dataset_caching.py + navsim_v1/scripts/training/*_cache.sh |
| metric cache(伪教师/评测中间量) | caching 入口、metadata CSV、token→path loader | navsim_v1/navsim/planning/script/run_metric_caching.py + navsim_v1/navsim/common/dataloader.py |
| cache 序列化格式 | lzma+pickle dump/load、落盘结构 | navsim_v1/navsim/planning/metric_caching/metric_cache.py + metric_cache_processor.py |
| PDM/EPDM 评测入口 | PDM score 评测脚本、token 交集逻辑 | navsim_v1/navsim/planning/script/run_pdm_score.py |
| comfort 指标实现 | accel/jerk/yaw rate 等阈值判定与聚合 | navsim_v1/navsim/planning/simulation/planner/pdm_planner/scoring/pdm_scorer.py + pdm_comfort_metrics.py |
注意:V-JEPA 预训练阶段若未完全开源,你在 repo 里可能只能找到"加载 V-JEPA 2 / Drive-JEPA encoder checkpoint"的逻辑,而找不到完整的自监督训练脚本。
3.2 为什么"metric cache + metadata CSV"是刚需?
从论文 §3.4 就能推断:要对每个场景的候选轨迹做规则模拟器评测并筛 pseudo-teacher,在线算会非常慢;所以工程上必然要:
- 把每个 token 对应的 cache 文件落盘
- 用 metadata CSV 建立 token → cache_path 的映射
- 评测/训练时按 token 读取
并且(这是你在跑评测最容易踩的坑之一):
- 评测时常见实现会对 scene tokens 与 metric cache tokens 取交集;缺 cache 的 token 会被跳过,导致"评测样本数变少/结果不完整"。
4. 数据准备 / 环境配置 / 训练与测试闭环(runbook)
本节目标是跑通:
数据与路径 →(可选)metric cache →(可选)feature cache → 训练 → PDM score 评测
4.1 环境准备(以 repo README 为准)
下面是一组常见的安装序列(以 Drive-JEPA repo README 的描述为基准思路;具体版本以你 clone 的 README 为准):
bash
conda create -n drive-jepa python=3.9 -y
conda activate drive-jepa
# 典型:CUDA toolkit 12.1 + torch cu121
# (如果你机器/驱动不匹配,请用你本机可用的 CUDA/torch 组合)
pip install -r requirements.txt
# 安装 navsim devkit(repo 通常要求在 navsim_v1 下 editable 安装)
cd navsim_v1
pip install -e .4.2 环境变量(scripts/env.sh)
repo 通常提供 navsim_v1/scripts/env.sh,用于统一设置数据根目录、地图根目录、实验输出目录等。你需要确保这些变量和你机器上的真实路径一致。
常见变量(示例,名称以 env.sh 为准):
NUPLAN_MAPS_ROOTOPENSCENE_DATA_ROOTNAVSIM_EXP_ROOTNAVSIM_DEVKIT_ROOT
使用方式(示例):
bash
source navsim_v1/scripts/env.sh4.3 (可选但强烈建议)生成 metric cache(伪教师/评测中间量)
你可以把 metric cache 理解为:把规则模拟器相关的昂贵计算提前离线化。
典型入口(Hydra 驱动):
navsim_v1/navsim/planning/script/run_metric_caching.py
跑完后通常会有:
- cache 文件(通常是
lzma + pickle) metadata/*.csv(token → cache path)
4.4 生成 feature cache(dataset caching)
repo 往往把"从原始数据提特征/提监督"也做成缓存,便于训练时 use_cache_without_dataset=True 这种模式。
脚本入口示例:
navsim_v1/scripts/training/run_drive_jepa_perception_based_cache.shnavsim_v1/scripts/training/run_drive_jepa_perception_free_cache.sh
它们通常会调用:
navsim_v1/navsim/planning/script/run_dataset_caching.py
4.5 训练(torchrun + Hydra 配置)
脚本入口示例:
navsim_v1/scripts/training/train_drive_jepa_perception_based.shnavsim_v1/scripts/training/train_drive_jepa_perception_free.sh
它们通常会调用:
navsim_v1/navsim/planning/script/run_training.py
常见训练形态:
use_cache_without_dataset=Truecache_path=...
4.6 评测(PDM score)
脚本入口示例:
navsim_v1/scripts/evaluation/eval_drive_jepa_perception_based.shnavsim_v1/scripts/evaluation/eval_drive_jepa_perception_free.sh
底层调用通常是:
navsim_v1/navsim/planning/script/run_pdm_score.py
4.7 高概率坑位清单(建议放到博文结尾)
- tokens 交集导致"评测样本变少":缺 metric cache 的 token 会被跳过。
- metadata CSV 里的路径可能需要改写:尤其是你在不同机器/不同目录迁移 cache 时。
- env.sh 路径一致性:地图根目录、数据根目录、实验输出根目录必须一致,否则 caching/train/eval 很容易各写各的。
- cache 文件格式/压缩 :metric cache 常见是
lzma + pickle;如果你用错误方式打开,会出现解压/反序列化错误。
附录:论文核心表格摘录(重排版)
说明:以下表格是对论文 §3/§4 中核心表格的"摘录/重排",只保留本文正文里反复引用的关键行与关键指标,方便读者快速对照;完整表格请以论文原文为准。
A.1 Table 1(Perception-free planners,对应论文 Table 1 / Table 2 的 perception-free block)
| 方法 | Encoder size | Data scale | PDMS |
|---|---|---|---|
| LAW | 21M | ~20h | 83.8 |
| World4Drive | 21M | ~20h | 85.1 |
| Epona | 1.1B | 128h | 86.1 |
| Drive-JEPA (Ours) | 307M | 208h | 89.0 |
备注:论文 HTML 的 Table 1 在 arXiv 转换中列名缺失,上表的方法名用 Table 2(perception-free setting)中对应的 PDMS 行做了对齐;Epona 的 PDMS 在 Table 2 中显示为 86.2,Table 1 为 86.1(可能是四舍五入差异)。
A.2 Table 2(NAVSIM v1:关键对比行)
Perception-free(论文 Table 2 第一 block):
| 方法 | Backbone | Inputs | PDMS |
|---|---|---|---|
| LAW | ResNet34 | C & L | 83.8 |
| World4Drive | ResNet34 | C & L | 85.1 |
| Epona | ViT/G | Camera | 86.2 |
| Drive-JEPA (Ours) | ViT/L | Camera | 89.0 |
Perception-based(ViT/L + Camera 的头部对比):
| 方法 | Backbone | Inputs | PDMS |
|---|---|---|---|
| iPad | ViT/L | Camera | 91.7 |
| DriveSuprim | ViT/L | Camera | 93.5 |
| Drive-JEPA (Ours) | ViT/L | Camera | 93.3 |
Perception-based(ResNet34 + Camera 的头部对比):
| 方法 | Backbone | Inputs | PDMS |
|---|---|---|---|
| iPad | ResNet34 | Camera | 91.1 |
| Drive-JEPA (Ours) | ResNet34 | Camera | 91.5 |
A.3 Table 3(NAVSIM v2:关键对比行)
| 方法 | Backbone | EPDMS | EC |
|---|---|---|---|
| iPad | ViT/L | 85.8 | 74.6 |
| DriveSuprim | ViT/L | 87.1 | 78.6 |
| Drive-JEPA (Ours) | ViT/L | 87.8 | 84.8 |
A.4 Table 4(Bench2Drive:关键对比行)
| 方法 | Driving Score (DS) | Success Rate (SR) | Efficiency | Comfortness |
|---|---|---|---|---|
| iPad | 153.83 | 35.51 | 33.18 | 60.52 |
| Drive-JEPA (Ours) | 157.85 | 30.24 | 36.82 | 64.52 |
A.5 Table 7(主流视觉/视频预训练对比:关键对比行)
| Vision Encoder | Size | PDMS |
|---|---|---|
| Epona | ViT/G | 86.2 |
| SigCLIP | ViT/L | 83.4 |
| V-JEPA 2 | ViT/L | 86.1 |
| Driving video pretraining + V-JEPA objective (Ours) | ViT/L | 89.0 |
备注:论文 Table 7 中 MAE / DepthAnything 在该 perception-free setup 下为 "-",论文文字说明为"无法收敛(could not converge)"。
参考链接
- 论文 HTML(arXiv):https://arxiv.org/html/2601.22032
- 论文 PDF(arXiv):https://arxiv.org/pdf/2601.22032v1
- 官方代码仓库:https://github.com/linhanwang/Drive-JEPA