在BPE理论篇中,我们理解了 BPE 的核心思想:从 256 个字节值出发,反复合并最高频的相邻符号对,用更大的词表换取更短的序列。这篇实践篇,我们用 Python 从零把它写出来。
全文代码可以直接复制运行,不依赖任何第三方库。
一、文本到字节:一切的起点
BPE 操作的对象不是字符串,而是字节序列。这是很多人的第一个误解:以为分词器直接处理文字。实际上,无论什么语言的文本,第一步都要通过 UTF-8 编码转成字节流。Python 中只需一行:
python
text = "Hello, 你好! 😄"
# 文本 → UTF-8 字节 → 整数列表
tokens = list(text.encode("utf-8"))
print(f"原始文本: {text}")
print(f"字符数: {len(text)}")
print(f"字节序列: {tokens}")
print(f"字节数: {len(tokens)}") 运行结果:
原始文本: Hello, 你好! 😄
字符数: 12
字节序列: [72, 101, 108, 108, 111, 44, 32, 228, 189, 160, 229, 165, 189, 33, 32, 240, 159, 152, 132]
字节数: 19 12个字符变成了 19 个字节。英文字母各占 1 字节,中文汉字各占 3 字节,emoji 占了 4 字节,另外包含了2个标点符号和2个空格。这也直观地说明了为什么中文在大模型中"更费 token":同样一个字符,中文在起跑线上就比英文多出 2 个字节,需要更多的合并才能压缩成一个 token。
list(text.encode("utf-8")) 将字节对象转成整数列表,方便后续用 Python 进行操作。此时每个整数都在 0~255 范围内,这就是 BPE 的初始词表---256 种字节值,每种对应一个 token。
二、基础实现
2.1 统计相邻符号对
有了字节序列,BPE 的每一轮都需要回答同一个问题:哪个相邻符号对出现得最多? 这就是 get_stats 函数的职责。
理论篇中我们讲过,BPE 用大小为 2 的滑动窗口扫描序列,逐位统计所有相邻对。Python 中有一个非常简洁的写法---zip(ids, ids[1:]):
python
def get_stats(ids):
"""统计序列中所有相邻符号对的出现次数"""
counts = {}
for pair in zip(ids, ids[1:]):
counts[pair] = counts.get(pair, 0) + 1
return counts 返回的字典中,键是符号对的元组(如 (101, 108)),值是出现次数。
-
如果你不熟悉这个写法,可以拆开看看它在做什么:
python# 演示 zip 的配对效果 sample = [1, 2, 3, 4, 5] print(list(zip(sample, sample[1:]))) # [(1, 2), (2, 3), (3, 4), (4, 5)]zip把原列表和偏移一位的列表"拉链式"配对,天然生成了所有相邻对。相比手动用for i in range(len(ids)-1)再(ids[i], ids[i+1]),这种写法更 Pythonic,也更不容易出错counts.get(pair, 0) + 1是另一个实用技巧:如果pair不在字典中,返回默认值 0 再加 1,避免了KeyError。
-
用我们的字节序列试一下:
pythonstats = get_stats(tokens) print(f"共 {len(stats)} 种不同的符号对")输出:
bash共 18 种不同的符号对 -
为了方便查看,我们先实现一个辅助函数。把字节值转成可读字符,方便后续查看输出------ASCII 范围内的直接转字符,超出的显示为
?:python# 辅助函数:字节值转可读字符(非 ASCII 显示为 ?) def show_byte(b): return chr(b) if b < 128 else "?"现在来统计并展示频率最高的 5 个符号对:
python# 按频率降序,展示前 5 个 top5 = sorted(stats.items(), key=lambda x: x[1], reverse=True)[:5] for pair, count in top5: left, right = show_byte(pair[0]), show_byte(pair[1]) print(f"{pair}: {count}次 → '{left}' + '{right}'")(72, 101): 1次 → 'H' + 'e' (101, 108): 1次 → 'e' + 'l' (108, 108): 1次 → 'l' + 'l' (108, 111): 1次 → 'l' + 'o' (111, 44): 1次 → 'o' + ','
其中,频率最高的那个 pair,就是下一步要合并的目标。
2.2 合并符号对
找到最高频的 pair 后,下一步是遍历整个序列,把所有出现的该 pair 替换为一个新的 token ID。这个操作需要注意一个关键点:替换不能重叠。
举个例子:序列 [1, 1, 1] 中合并 (1, 1),应该得到 [新token, 1](前两个合并,第三个落单),而不是 [新token, 新token](重叠使用了中间的 1)。
实现方式是用一个指针从左到右扫描,匹配到 pair 就合并并跳过两个位置,否则逐个前进:
python
def merge(ids, pair, idx):
"""将序列中所有出现的 pair 替换为新 token idx"""
new_ids = []
i = 0
while i < len(ids):
# 如果当前位置匹配 pair 的前半部分,且下一个位置匹配后半部分
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i + 1] == pair[1]:
new_ids.append(idx)
i += 2 # 跳过两个位置
else:
new_ids.append(ids[i])
i += 1
return new_ids i += 2 是整个函数的关键------它保证了被合并的两个位置不会再参与后续匹配。这和理论篇中讲的"统计时窗口可以重叠,但替换时不能"是同一件事,只不过这里我们用代码把它表达了出来。
-
验证一下:
pythontest = [5, 6, 6, 7, 9, 1] print(f"原始: {test}") merged_test = merge(test, (6, 7), 99) print(f"合并(6,7)→99: {merged_test}")输出:
bash原始: [5, 6, 6, 7, 9, 1] 合并(6,7)→99: [5, 6, 99, 9, 1] 注意第一个
6没有被合并因为它和后面的6构成的是(6, 6)而不是(6, 7)。merge 函数只替换精确匹配的 pair。 -
还有一个容易忽略的细节:合并后,参与合并的 token 并没有从词表中消失。看结果
[5, 6, 99, 9, 1]---第一个6因为不匹配(6, 7)而被保留了下来,它仍然是一个有效的独立 token。合并只是在匹配到的位置把两个相邻 token 替换成一个新的,不会影响同一 token 在其他位置的存在。
三、训练:迭代合并构建词表
3.1 训练流程
有了 get_stats 和 merge 这两个基础函数,训练过程就是把它们组合成一个循环:
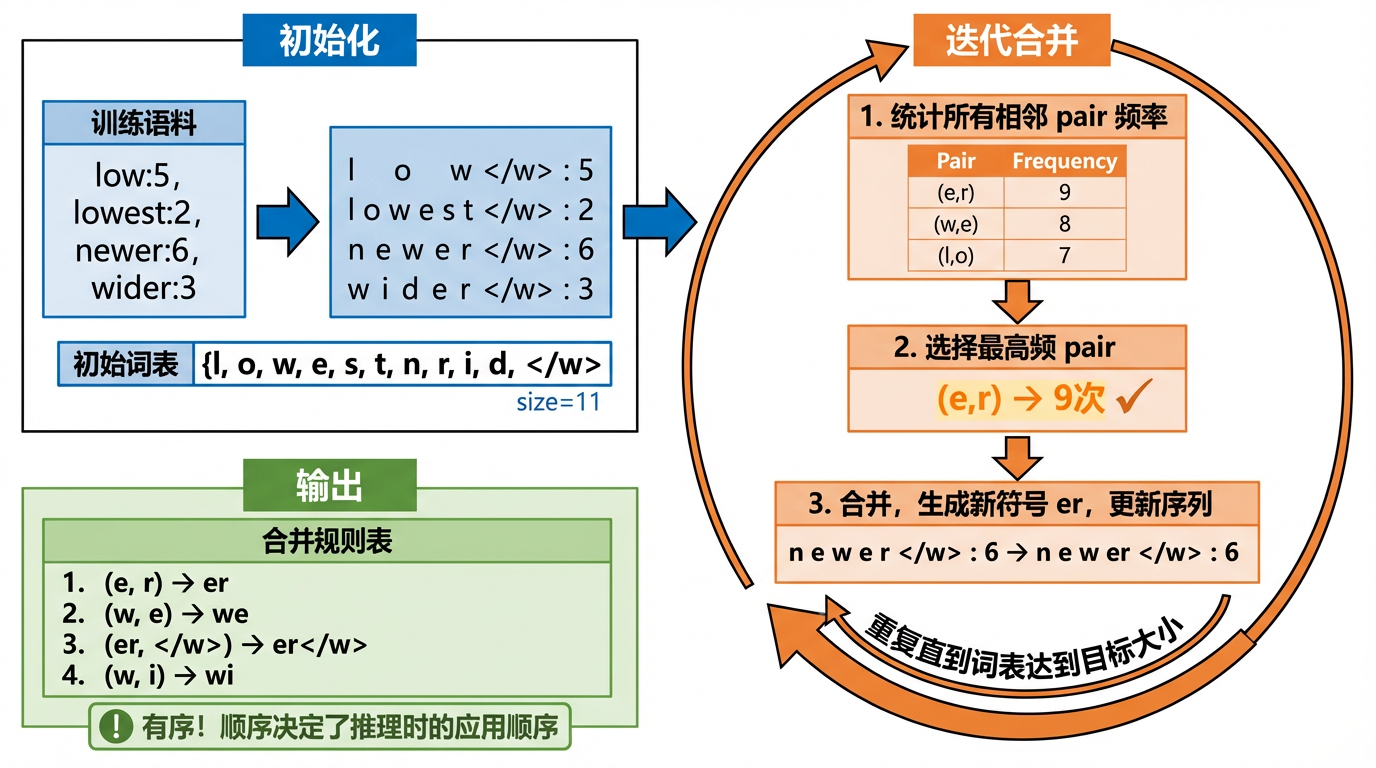
-
统计所有相邻 pair 的频率
-
找出频率最高的 pair
-
用一个新 token ID 替换所有该 pair
-
记录这条合并规则
-
回到第 1 步,重复
-
循环的次数就是
vocab_size - 256因为初始词表有 256 个字节值(0~255),每合并一次新增一个 token。为什么是 256?因为一个字节能表示的值恰好是 2 8 2^8 28,也就是256 种。这不仅仅是 ASCII------0~127 对应 ASCII 字符(如 72 →
H),而 128~255 是 UTF-8 多字节序列的组成部分(比如汉字"你"编码为[228, 189, 160],这三个字节各自占据初始词表的一个位置)。vocab_size >= 256的约束就是要求词表至少覆盖所有字节值,否则有些字节就无法表示。新增的合并 token 从 ID 256 开始编号。
3.2 实现
python
def train(text, vocab_size):
"""
训练 BPE 分词器
参数:
text: 训练文本
vocab_size: 目标词表大小(必须 >= 256)
返回:
merges: 合并规则字典 {(p0, p1): new_idx}
vocab: 词表字典 {idx: bytes}
"""
assert vocab_size >= 256, "词表大小不能小于 256(初始字节数)"
num_merges = vocab_size - 256
tokens = list(text.encode("utf-8"))
# 记录合并规则
merges = {}
for i in range(num_merges):
stats = get_stats(tokens)
if not stats:
break
# 找出频率最高的 pair
pair = max(stats, key=stats.get)
# 分配新 token ID(从 256 开始)
idx = 256 + i
# 执行合并
tokens = merge(tokens, pair, idx)
merges[pair] = idx
print(f"合并 {i+1}/{num_merges}: {pair} → {idx} (出现 {stats[pair]} 次)")
# 构建词表:idx → bytes
vocab = {idx: bytes([idx]) for idx in range(256)}
for (p0, p1), idx in merges.items():
vocab[idx] = vocab[p0] + vocab[p1]
print(f"\n训练完成!")
print(f"原始长度: {len(list(text.encode('utf-8')))} 字节")
print(f"压缩后: {len(tokens)} token")
print(f"压缩率: {len(list(text.encode('utf-8'))) / len(tokens):.2f}x")
print(f"词表大小: {len(vocab)}")
return merges, vocab-
训练函数有两个产出,理解它们的区别很重要:
merges是合并规则字典,记录"哪两个 token 合并成了哪个新 token"。编码时需要它来决定怎么切分新文本。vocab是词表字典,记录"每个 token ID 对应什么字节"。解码时需要它来把 token 还原成文本。
-
构建 vocab 的那几行代码值得细看:
-
先用
{idx: bytes([idx]) for idx in range(256)}初始化 256 个原始字节。也就是把整数 0~255 各自转成对应的单字节 bytes对象,建立初始词表的映射:
bash{0: b'\x00', 1: b'\x01', 2: b'\x02', 3: b'\x03', 4: b'\x04', 5: b'\x05', ...} -
然后按合并顺序遍历 merges,每个新 token 的字节就是它的两个"父 token"字节的拼接。
其实,就是把合并规则也写进词表。比如训练时
(32, 116) → 256,这行代码就做:vocab[256] = vocab[32] + vocab[116],即b ' '+ b't' = b' t'。这样每个合并产生的 token ID 都能查到它对应的完整字节序列,解码时直接查表就行。 -
这里依赖了 Python 3.7+ 字典保持插入顺序的特性:如果顺序乱了,后面的 token 可能引用到还未创建的父 token,导致错误。
-
3.3 测试
用一段真实文本来训练。为了看到有意义的合并效果,我们需要一段足够长的文本:
python
training_text = """The quick brown fox jumps over the lazy dog. The dog barked at the fox.
The fox ran quickly through the forest. The forest was dark and quiet.
Natural language processing is a subfield of linguistics and artificial intelligence.
Language models process text by breaking it into tokens. Tokenization is the first step.
The byte pair encoding algorithm iteratively merges the most frequent pairs of bytes.
This process continues until the desired vocabulary size is reached.
Understanding tokenization helps explain why language models behave the way they do.
The relationship between tokens and words is not always straightforward.
Some words are split into multiple tokens while common words remain as single tokens.
This encoding scheme balances vocabulary size with sequence length efficiently."""
merges, vocab = train(training_text, vocab_size=276) 运行输出(部分):
bash
合并 1/20: (101, 32) → 256 (出现 27 次)
合并 2/20: (115, 32) → 257 (出现 25 次)
合并 3/20: (101, 110) → 258 (出现 14 次)
合并 4/20: (104, 256) → 259 (出现 13 次)
...
合并 20/20: (111, 107) → 275 (出现 6 次)
训练完成!
原始长度: 796 字节
压缩后: 597 token
压缩率: 1.33x
词表大小: 276 这里有一个非常值得注意的现象:看第 4次合并,(104, 256) → 259。token 256 是第 1 次合并刚产生的 "e "(e+空格),现在它和 104(字母 "h")合并成了 "he "。新 token 立刻参与了下一轮合并 ------这就是理论篇中说的"层层嵌套的二叉树结构"。token 259 ("he ") 的内部结构是:
259 = (104, 256) = (104, (101, 32)) = "h" + ("e" + " ") = "he " 随着合并次数增加,token 会变得越来越长,从单个字节逐渐积累成常见的词或短语片段。20 次合并的压缩率只有 1.35 x 1.35x 1.35x,但真实的分词器执行 50,000+次合并后,压缩率可以达到 3 ∼ 4 x 3 \sim 4x 3∼4x。
三、编码与解码
编码和解码是分词器对外提供的两个核心接口。
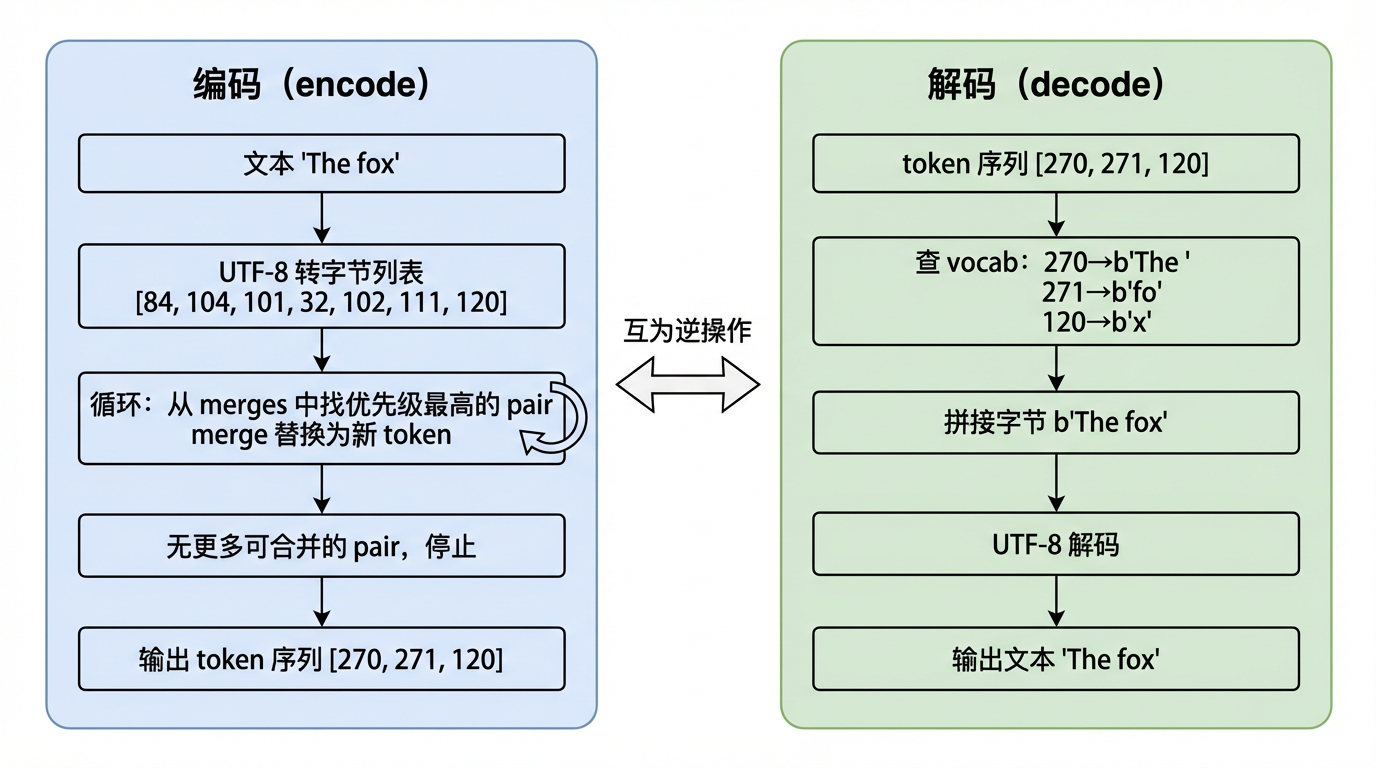
3.1 解码:从 token 还原文本
我们先讲解码,因为它更简单,也更容易建立直觉。
-
解码要做的事情很直接:给定一个 token ID 序列,在词表中查找每个 ID 对应的字节,把所有字节拼接起来,最后用 UTF-8 解码回字符串。
pythondef decode(ids, vocab): """将 token 序列解码为文本""" tokens = b"".join(vocab[idx] for idx in ids) text = tokens.decode("utf-8", errors="replace") return text -
短短两行代码,但
errors="replace"这个参数值得专门说一说。 并非所有字节序列都是合法的 UTF-8 编码。UTF-8 有严格的格式规则,比如字节值 128(二进制
10000000)不能作为一个字符的起始字节。如果 LLM 恰好预测出这样一个 token,decode("utf-8")默认会抛出UnicodeDecodeError。加上errors="replace"后,无效字节会被替换为�(U+FFFD 替换字符),程序不会崩溃:python# 正常解码 print(decode([72, 101, 108, 108, 111], vocab)) # → "Hello" # 无效 UTF-8 字节 print(decode([128], vocab)) # → "�"(替换字符) 当你在 LLM 的输出中看到
�时,通常就意味着模型生成了无法解码为有效 UTF-8 的 token 序列。这在实际使用中很少见,但一个健壮的分词器必须处理这种边界情况。OpenAI 的 tiktoken 源码中也用了同样的errors="replace"策略。
3.2 编码:从文本到 token
-
编码是解码的反向操作:给定文本,输出 token 序列。这是实现中最需要小心的部分。
-
基本流程和解码类似,先把文本转成字节列表。但接下来不是简单地查表,而是要按合并规则的原始顺序,逐条尝试应用。
(1) 实现
整体逻辑分三步:
- 初始化:和训练一样,先把文本转成字节列表,作为初始 token 序列
- 循环合并 :每轮用
get_stats统计当前所有相邻 pair,从中挑出在merges里优先级最高的那个,调用merge执行替换 - 终止:当序列中没有任何相邻 pair 存在于合并规则中时,停止循环,返回最终的 token 序列
和训练的区别在于:训练时每轮选频率最高的 pair(max),编码时每轮选在合并规则中编号最小 的 pair(min)。这是因为编码不是在"发现新规则",而是在"重放已有规则"。
python
def encode(text, merges):
"""将文本编码为 token 序列"""
tokens = list(text.encode("utf-8"))
while len(tokens) >= 2:
# 统计当前所有相邻 pair
stats = get_stats(tokens)
# 找到在 merges 中优先级最高(索引最小)的 pair
# 不在 merges 中的 pair 赋予无穷大,表示不参与合并
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
# 如果没有任何 pair 在合并规则中,停止
if pair not in merges:
break
idx = merges[pair]
tokens = merge(tokens, pair, idx)
return tokens(2) 说明
-
这段代码中最关键的一行是
min(stats, key=lambda p: merges.get(p, float("inf")))。拆开理解这行代码:
stats是当前序列中所有相邻 pair 的字典,比如{(84, 104): 1, (104, 101): 2, ...}min(stats, key=...)遍历stats中的每个 pair,按key函数的返回值取最小的那个merges.get(p, float("inf"))是key函数------如果 pairp在合并规则中,返回它的新 token ID(如 256、257...),ID 越小说明越早被创建;如果不在合并规则中,返回float("inf")(正无穷),保证它永远不会被选中
所以最终效果是:在当前序列存在的所有相邻 pair 中,挑出在合并规则里编号最小(最早创建)的那一个。
-
为什么必须按原始顺序? 因为后面的合并规则可能依赖前面的结果。回顾训练输出:
- 规则 1:
(101, 32)→ 256(e + 空格 →"e ") - 规则 4:
(104, 256)→ 259(h +"e "→"he ")
- 规则 1:
-
如果我们跳过规则 1 直接尝试规则 4,序列中根本不存在 token 256,规则 4 永远无法匹配。编码时的合并顺序必须和训练时一致,这是 BPE 正确性的基本保证。
-
还有一个特殊情况需要处理:当输入只有一个字符(或为空)时,序列长度不足 2,没有任何 pair 可以合并。
while len(tokens) >= 2这个条件自然处理了这种边界情况。
3.3 测试编码-解码的一致性
这是验证实现正确性最可靠的方式。
-
用训练文本验证
pythonassert decode(encode(training_text, merges), vocab) == training_text print("训练文本: 编码-解码一致 ✓")输出:
bash训练文本: 编码-解码一致 ✓ -
用从未见过的文本验证:
pythonencoded = encode(new_text, merges) decoded = decode(encoded, vocab) print(f"\n新文本: '{new_text}'") print(f"编码: {encoded}") print(f"解码: '{decoded}'") assert decoded == new_text print("新文本: 编码-解码一致 ✓")输出:
bash新文本: 'The fox and the dog are friends.' 编码: [270, 271, 120, 32, 263, 100, 261, 259, 100, 111, 103, 32, 267, 256, 102, 114, 105, 258, 100, 115, 46] 解码: 'The fox and the dog are friends.' 新文本: 编码-解码一致 ✓
对新文本的分词也能正确工作,这说明我们的分词器具备泛化能力------训练时学到的合并规则可以应用到任何新文本上。
- 最后要强调一点:编码-解码的一致性是单向的。
decode(encode(text)) == text始终成立,但反过来encode(decode(ids)) == ids不一定。因为并非所有 token 序列都能解码为合法的 UTF-8 字符串,errors="replace"会引入�导致信息丢失。
四、完整代码
将所有部分整合为一个可直接运行的脚本:
python
"""BPE 分词器完整实现:训练 + 编码 + 解码"""
def get_stats(ids):
"""统计序列中所有相邻符号对的出现次数"""
counts = {}
for pair in zip(ids, ids[1:]):
counts[pair] = counts.get(pair, 0) + 1
return counts
def merge(ids, pair, idx):
"""将序列中所有出现的 pair 替换为新 token idx"""
new_ids = []
i = 0
while i < len(ids):
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i + 1] == pair[1]:
new_ids.append(idx)
i += 2
else:
new_ids.append(ids[i])
i += 1
return new_ids
def train(text, vocab_size):
"""训练 BPE 分词器,返回 (merges, vocab)"""
assert vocab_size >= 256
num_merges = vocab_size - 256
tokens = list(text.encode("utf-8"))
merges = {}
for i in range(num_merges):
stats = get_stats(tokens)
if not stats:
break
pair = max(stats, key=stats.get)
idx = 256 + i
tokens = merge(tokens, pair, idx)
merges[pair] = idx
vocab = {idx: bytes([idx]) for idx in range(256)}
for (p0, p1), idx in merges.items():
vocab[idx] = vocab[p0] + vocab[p1]
return merges, vocab
def encode(text, merges):
"""文本 → token 序列"""
tokens = list(text.encode("utf-8"))
while len(tokens) >= 2:
stats = get_stats(tokens)
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
if pair not in merges:
break
tokens = merge(tokens, pair, merges[pair])
return tokens
def decode(ids, vocab):
"""token 序列 → 文本"""
tokens = b"".join(vocab[idx] for idx in ids)
return tokens.decode("utf-8", errors="replace")
# ---- 示例运行 ----
if __name__ == "__main__":
training_text = """The quick brown fox jumps over the lazy dog. The dog barked at the fox.
The fox ran quickly through the forest. The forest was dark and quiet.
Natural language processing is a subfield of linguistics and artificial intelligence.
Language models process text by breaking it into tokens. Tokenization is the first step.
The byte pair encoding algorithm iteratively merges the most frequent pairs of bytes.
This process continues until the desired vocabulary size is reached.
Understanding tokenization helps explain why language models behave the way they do.
The relationship between tokens and words is not always straightforward.
Some words are split into multiple tokens while common words remain as single tokens.
This encoding scheme balances vocabulary size with sequence length efficiently."""
# 训练
print("=== 训练 ===\n")
merges, vocab = train(training_text, vocab_size=276)
original_len = len(list(training_text.encode("utf-8")))
compressed_len = len(encode(training_text, merges))
print(f"\n原始: {original_len} 字节 → 压缩后: {compressed_len} token")
print(f"压缩率: {original_len / compressed_len:.2f}x")
# 编码-解码验证
print("\n=== 编码-解码验证 ===\n")
assert decode(encode(training_text, merges), vocab) == training_text
print("训练文本: ✓")
test_text = "The fox and the dog are friends."
assert decode(encode(test_text, merges), vocab) == test_text
print(f"新文本 '{test_text}': ✓")
# 展示分词结果
print("\n=== 分词示例 ===\n")
for text in ["The fox", "tokenization", "Hello, 你好!"]:
ids = encode(text, merges)
parts = [decode([id], vocab) for id in ids]
print(f" '{text}' → {ids}")
print(f" 拆分: {parts}\n")五、总结
回顾整个实现,核心就是三个函数加一个循环:
| 函数 | 作用 | 一句话描述 |
|---|---|---|
get_stats |
统计 | 滑动窗口数相邻 pair 频率 |
merge |
替换 | 从左到右把 pair 换成新 token |
train |
训练 | 循环调用上面两个函数,构建合并规则 |
encode |
编码 | 按合并规则的顺序逐条应用 |
decode |
解码 | 查词表拼字节,UTF-8 解码 |
-
几个值得记住的实现细节:
zip(ids, ids[1:])是统计相邻 pair 的惯用写法,比手动索引更简洁不易出错- 合并时
i += 2保证替换不重叠,对应理论篇中"统计可重叠,替换不可重叠"的规则 - 编码时用
min而非max,按合并规则的原始顺序处理,保证前序依赖(后面的规则可能依赖前面创建的 token) - 解码时
errors="replace"优雅处理无效 UTF-8 字节,这也是 OpenAI tiktoken 的做法 - 编码-解码一致性是单向的 :
decode(encode(text)) == text始终成立,反之不然 - vocab 构建依赖字典的插入顺序 ,Python 3.7+ 保证有序,更早的版本需要用
OrderedDict
-
这是最基础的 BPE 实现。真实的分词器(如 GPT 系列使用的 tiktoken)还引入了许多工程优化:
- 正则预分割(先按空格、标点等切成"词",避免跨词合并)
- 特殊 token 处理(如
<|im_start|>) - 多线程加速等。
但核心算法和我们这里实现的完全一致,理解了这 50 行代码,你就理解了所有 BPE 分词器的骨架。