
好,我们先回顾一下前两节课的核心内容:
-
在第10课里,我们已经尝试了通过
ollama的api把一段文本转换为【句向量】。 -
在第11课里,我们则通过python代码把一段markdown文档切分为一小段一小段的文本,适合生成句向量了。
没错,这节课的目标是:利用上面的工具,生成句向量,并且存起来。
一、向量存储库的选择
市面上有非常多的向量数据库,比如老牌的 Milvus、云端的 Pinecone、或者 Qdrant。但我们选择了 ChromaDB,原因只有两个字:优雅。
你只需要 pip install chromadb。然后在代码里写一句 chromadb.PersistentClient(path="./my_rag_db")。它就会在你的项目目录下建一个普通文件夹,把所有数据存在里面。没有服务进程,不需要配置端口,随时打包带走。
不需要docker,不需要端口,不需要关心一大堆环境问题,就是这么简单优雅。
但它也有个非常容易踩坑的点:它采用 "写入时推断 (Schema-on-Write)"。
它不需要你提前像写 SQL 那样定义表结构、定义 512 维度、定义余弦相似度算法。你往里扔什么模型算出来的向量,它就自动锁死什么格式。
二、双引擎,更强力
ChromaDB 的能力,并不是简单的向量存储和查询,准确来说,关于数据,它内置了两种强力引擎:
- 结构化引擎:SQLite (专门管理元数据)
- 向量引擎:hnswlib (专门负责算距离)
当我们拆分数据后,进行插入时,实际上做了两次插入:
-
第一次:存入一段带有 Metadata 的数据(比如 {"source": "company_rules.md", "章节": "考勤管理"})以及它的原始文本时,这部分数据是被存放在本地的 SQLite 关系型数据库里的。
-
第二次:用 bge-small 算出来的 512 维向量数组,没有存在 SQLite 里(因为关系型数据库没法算高维距离),而是被塞进了一个用 C++ 写的底层图索引库------hnswlib。
等到查询时,通过分层方式,先查询SQLite再查询hnswlib,能做到极致提速。
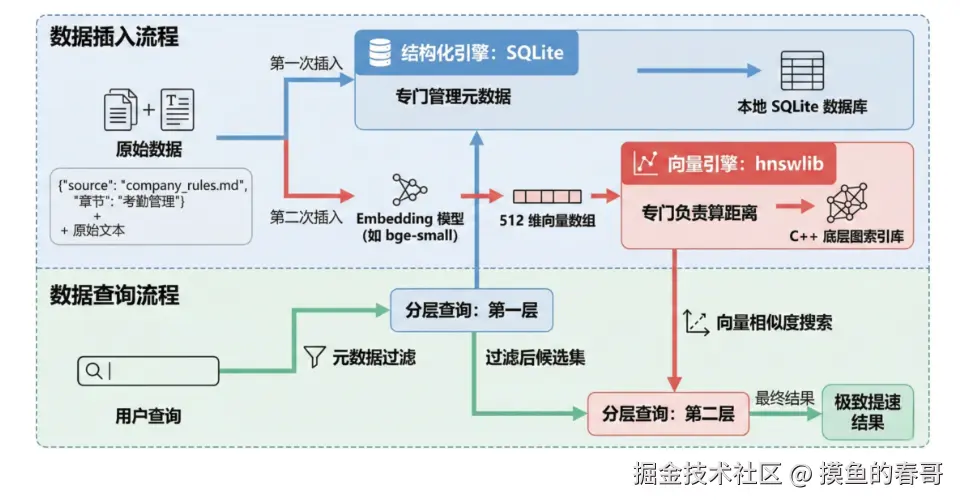
当你发起一次带条件的查询时,SQLite 先干活,挑出符合 Metadata 条件的文档 ID 集合;然后把这个集合扔给 hnswlib,说:"兄弟,别全库搜了,只在这几个 ID 对应的图节点里,帮我找出离问题向量最近的 3 个!" 这就保证了既有 100% 的条件准确率,又有毫秒级的向量搜索速度。
三、计算向量
按照常规编程思路来说,我们的思路通常是这样的:
- 通过调用ollama的api获取到每个文本片段的句向量
- 调用向量数据库的api把这些句向量以及它们的元数据存起来。
思路上完全正确!
但实际上我们并不是按照这个思路编写代码的,因为我们这次要用到的向量数据库 chromadb,它天然就是为这些场景而生的,所以我们的实际编码思路应该是:
- 定义好像ollama发请求的函数
- 准备好文本切片和元数据
- 把这些交给 chromadb,它会按上面的思路完成工作。
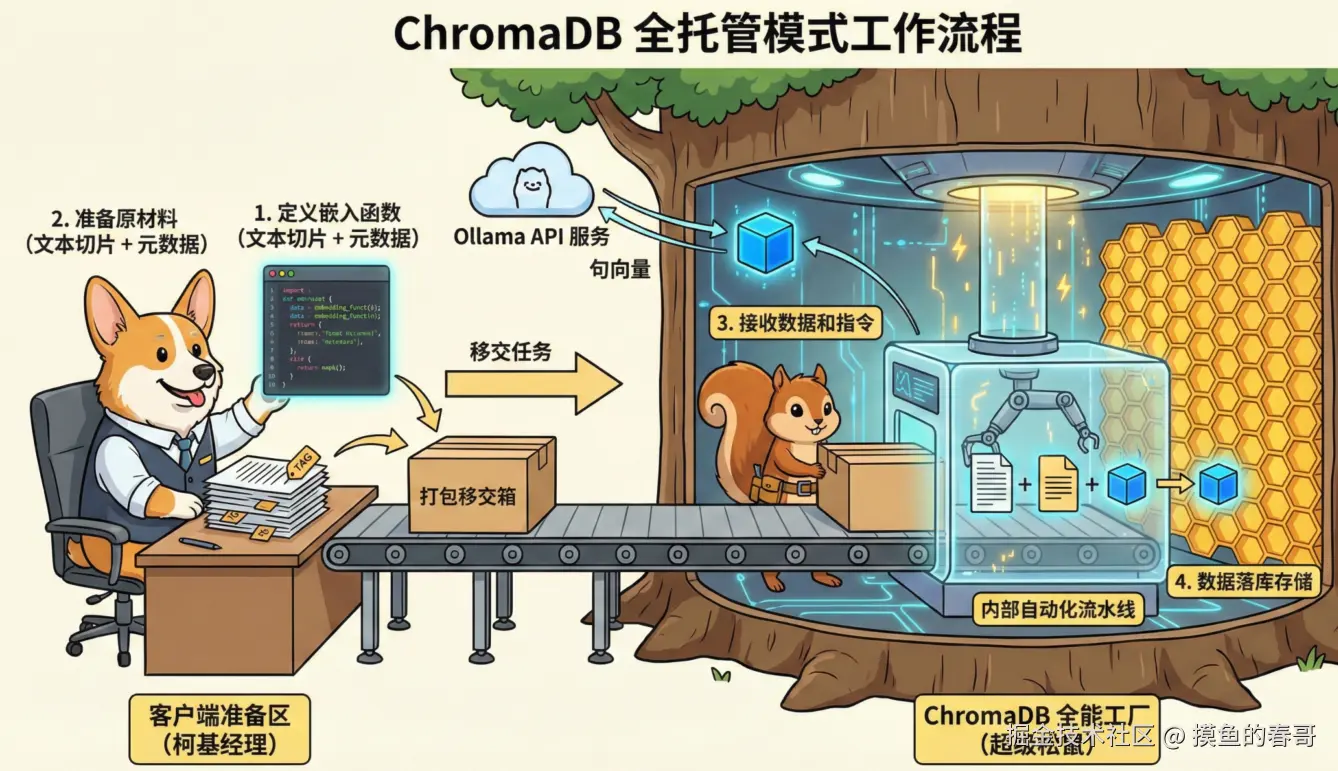
其核心代码如下所示:
python
import chromadb
import ollama
class OllamaEmbeddingFunction:
def __init__(self, model_name):
self.model_name = model_name
def __call__(self, input):
# 自动调用本地 Ollama 计算句向量
response = ollama.embed(model=self.model_name, input=input)
return response['embeddings']
def name(self):
return self.model_name
def main():
client = chromadb.PersistentClient(path=DB_PATH)
# 获取或创建集合
collection = client.get_or_create_collection(
name=COLLECTION_NAME,
embedding_function=OllamaEmbeddingFunction(model_name=MODEL_NAME)
)
collection.add(
documents=docs_texts,
metadatas=docs_metadatas,
ids=docs_ids
)你可能注意到了,上面我们传入了一个 docs_ids,这是什么?为什么要有这个东西?
四、chromadb 拒绝自动生成主键
在使用 chromadb 之前,我们需要了解它一个相比于传统关系型数据库差异最大的点:
- chromadb 不提供自动生成主键的能力。
为什么不呢?
原因很残酷,如果数据库帮你自动生成了 ID(比如 1, 2, 3 或者随机的 abc-123),会导致两个致命问题:
-
无法更新和删除:如果你的文档改了一个错别字,你想更新向量库。因为你不知道 ChromaDB 当初给这段话分配了什么 ID,你就没法精准替换它。
-
灾难级的"重复存入":如果你明天不小心把这个 Python 脚本又跑了一遍,自动生成 ID 会导致数据库里出现两份完全一样的文本和向量。搜的时候,前两个结果可能是一模一样的话。
所以,处于工程上的考量,ChromaDB 把 ID 的控制权交给了开发者,开发者必须在insert时,主动传入 ids。
五、选择你的id
目前最主流的做法有两种:
- 插入前生成uuid,简单直接,但每次生成产生的id肯定不同。
- 计算切片的hash,然后和文档名拼接,形成一个能够在机制上保证如果文本没变,那id就稳定的产物。
如果你对id稳定有比较大的诉求,那就选方案2,如果没有,只是用它做demo或者做文档检索,可以先用方案1,简单高效。
python
docs_ids.append(str(uuid.uuid4()))六、先删后插
当你的原始文档更新了(比如改了一个错别字、增加了一段话),切分后的块会发生剧烈的"雪崩移位"。
比如第一句话多说了几个字,导致第一章后续所有切片都跟着偏移变化了。
这样,当你重新训练后再次入库时,为了防止重复落库或者数据污染,最稳妥和简单的做法是:
利用 Metadata 中埋好的 source 标签,在入库前,一键清空该文档在库里的所有旧数据,然后重新完整插入。
python
collection.delete(where={"source": SOURCE_NAME})
# 执行写入 (因为前面已经删干净了,这里直接用 add 即可)
collection.add(
documents=docs_texts,
metadatas=docs_metadatas,
ids=docs_ids
)七、测试代码
你可以在 demo 工程获取到生成向量库的代码。
尝试执行以下命令:
bash
python .\lesson_09\split_and_save.py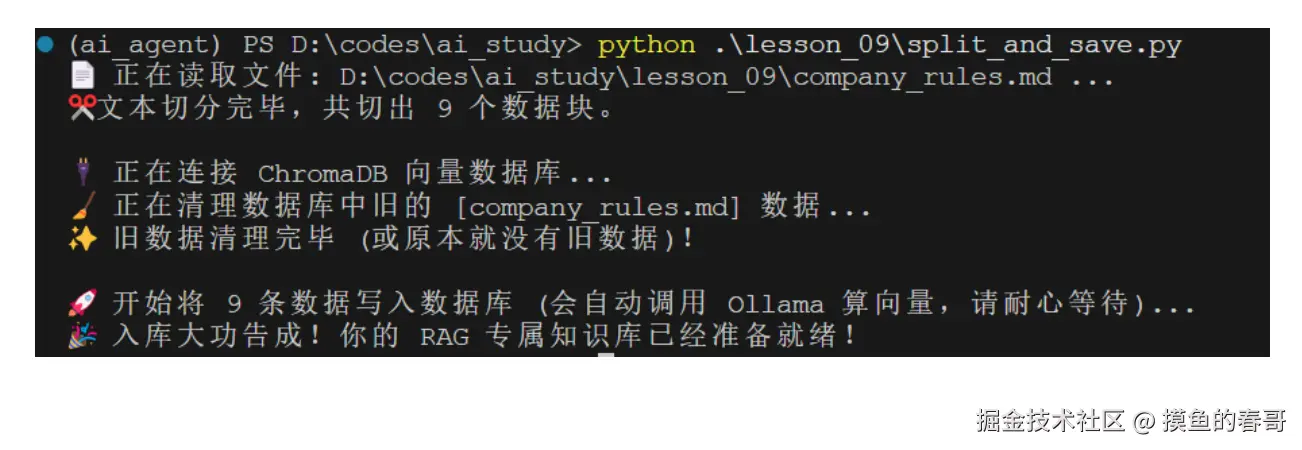
即可看到切分、向量化、入库成功。
下一步预告
本节课我们完成了向量化和入库。
下节课,我们将完成RAG最后的拼图:查询!
敬请期待!
