如何将代码发布到生产环境
如何快速且可靠地将代码发布到生产环境,是工程师和技术领导者都需要思考的问题。能够同时做到"快速/高频发布"和"保证高质量"的团队,将比难以兼顾这两点的竞争对手拥有巨大的优势。
本文将涵盖以下内容:
- 代码发布的两个极端。
- 不同类型公司的典型发布流程。
- 负责任发布的原则和工具。
- 额外的验证层与高级工具。
- 承担务实的风险以提高速度。
本文的扩展版本最初发表于 The Pragmatic Engineer Newsletter。如果您还没订阅,可以在这里免费注册:
1. 代码发布的两个极端
在代码发布方面,了解两种截然不同的极端方式会很有帮助。下表展示了"YOLO(直接干)"和"严谨验证"两种模式。
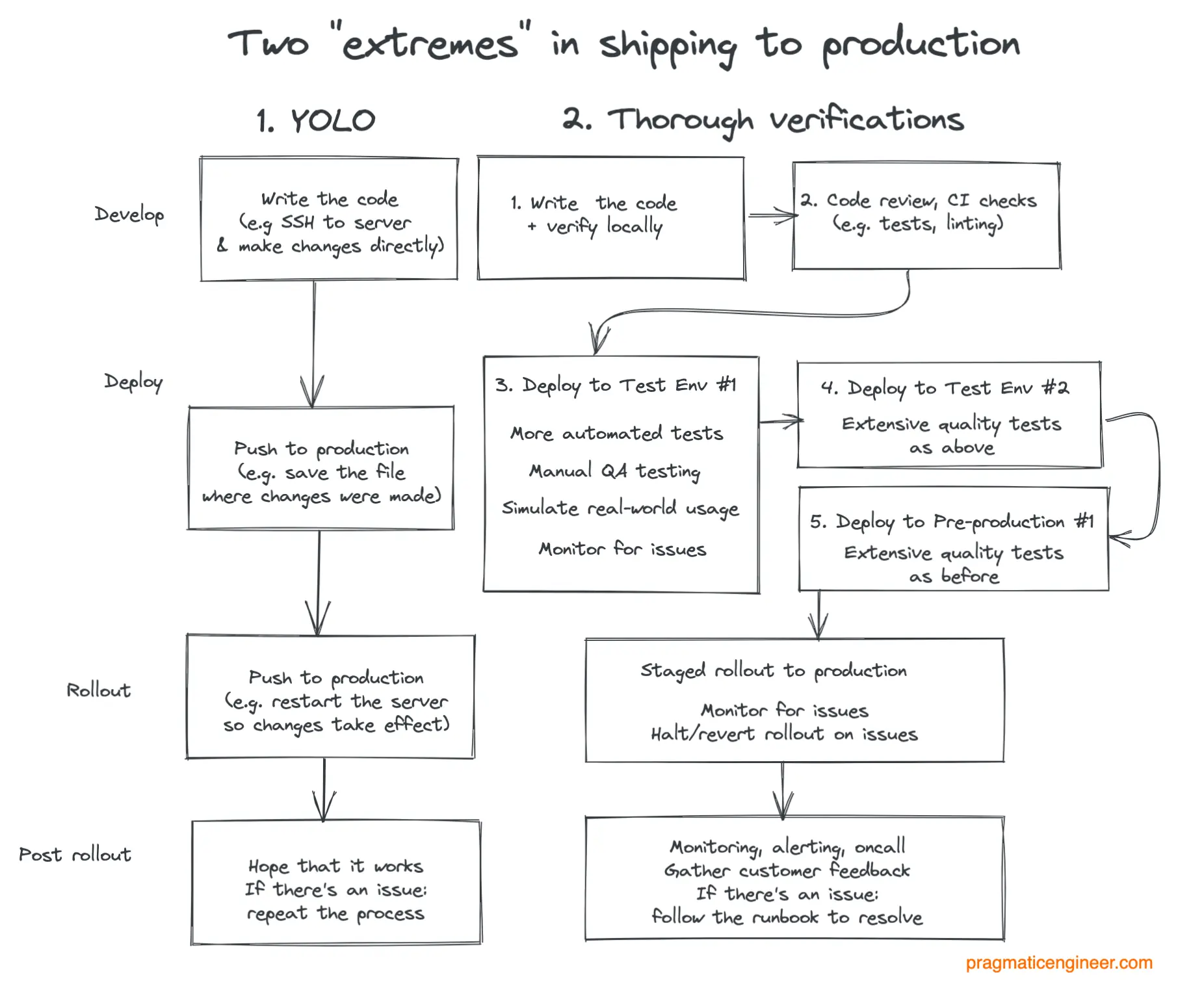 代码发布的两个"极端":YOLO 和 极其严谨的验证
代码发布的两个"极端":YOLO 和 极其严谨的验证
1. YOLO (You Only Live Once / 只活一次) 发布:这种方式常见于原型设计、个人项目或 Alpha/Beta 等不稳定产品版本。有时,紧急变更也会用这种方式上线。
理念很简单:直接在生产环境中改代码,然后看看能不能跑通。YOLO 发布的例子包括:
- SSH 连上生产服务器 → 用编辑器(如 vim)修改文件 → 保存并重启服务器 → 查看是否生效。
- 修改代码文件 → 不经过代码审查(Code Review)直接强行提交 → 推送并部署服务。
- 登录生产数据库 → 直接执行 SQL 修复数据问题 → 祈祷问题解决了。
就速度而言,YOLO 是最快的。但由于没有任何安全网,它引入新 Bug 的概率也是最高的。对于几乎没有用户的产品来说,搞坏生产环境的代价很低,所以这种做法也无可厚非。
YOLO 发布常用于:
- 个人副业项目。
- 没有客户的早期初创公司。
- 工程实践糟糕的中型公司。
- 在缺乏规范的公司里处理紧急故障时。
随着产品增长、客户变多,代码变更在到达生产环境前就需要额外的验证。这就来到了另一个极端:团队想尽一切办法,力求发版时做到零 Bug。
2. 多阶段严谨验证:对于拥有大量重要客户的成熟产品,一个 Bug 就可能导致客户损失资金或流失到竞争对手那里,因此需要采取极其严密的发布流程。
这种方式会设置多个验证层,旨在尽可能准确地模拟真实的线上环境。常见的层级包括:
- 本地验证:工程师用工具抓出明显的错误。
- CI(持续集成)验证:每个 Pull Request 都要自动跑单元测试和代码检查(Linting)。
- 部署前的自动化测试:在部署到下一个环境前,跑集成测试或端到端(E2E)测试等成本较高的测试。
- 测试环境 #1:跑冒烟测试等自动化测试。QA(测试工程师)也会在此手动测试并进行探索性测试。
- 测试环境 #2:让一小部分真实用户(如内部员工或付费 Beta 测试员)使用。配有监控,一旦发现问题立刻停止发布。
- 预发环境(Pre-production)#3:跑最后一轮自动和手动测试。
- 灰度发布(Staged rollout):先发给一小部分用户,监控核心指标是否健康,并查看客户反馈。根据变更的风险程度来调整灰度策略。
- 全量发布:灰度扩大后,最终推给所有客户。
- 发布后阶段 :生产环境难免出问题,团队需要监控、报警机制,以及与客户的反馈闭环。故障解决后,团队要遵循故障复盘最佳实践(我们之前探讨过)。
这种重型发布流程常见于:
- 医疗保健等受高度监管的行业。
- 电信运营商(发版前测半年都很正常)。
- 银行(Bug 会导致重大财务损失)。
- 缺乏自动化测试但希望保持高质量的传统公司,他们宁愿增加验证环节来牺牲发布速度。
2. 不同类型公司的典型流程
不同类型的公司通常是怎么发布的?以下是我基于观察所做的概括。虽然不能代表所有公司,但能体现出不同公司在发布策略上的差异:
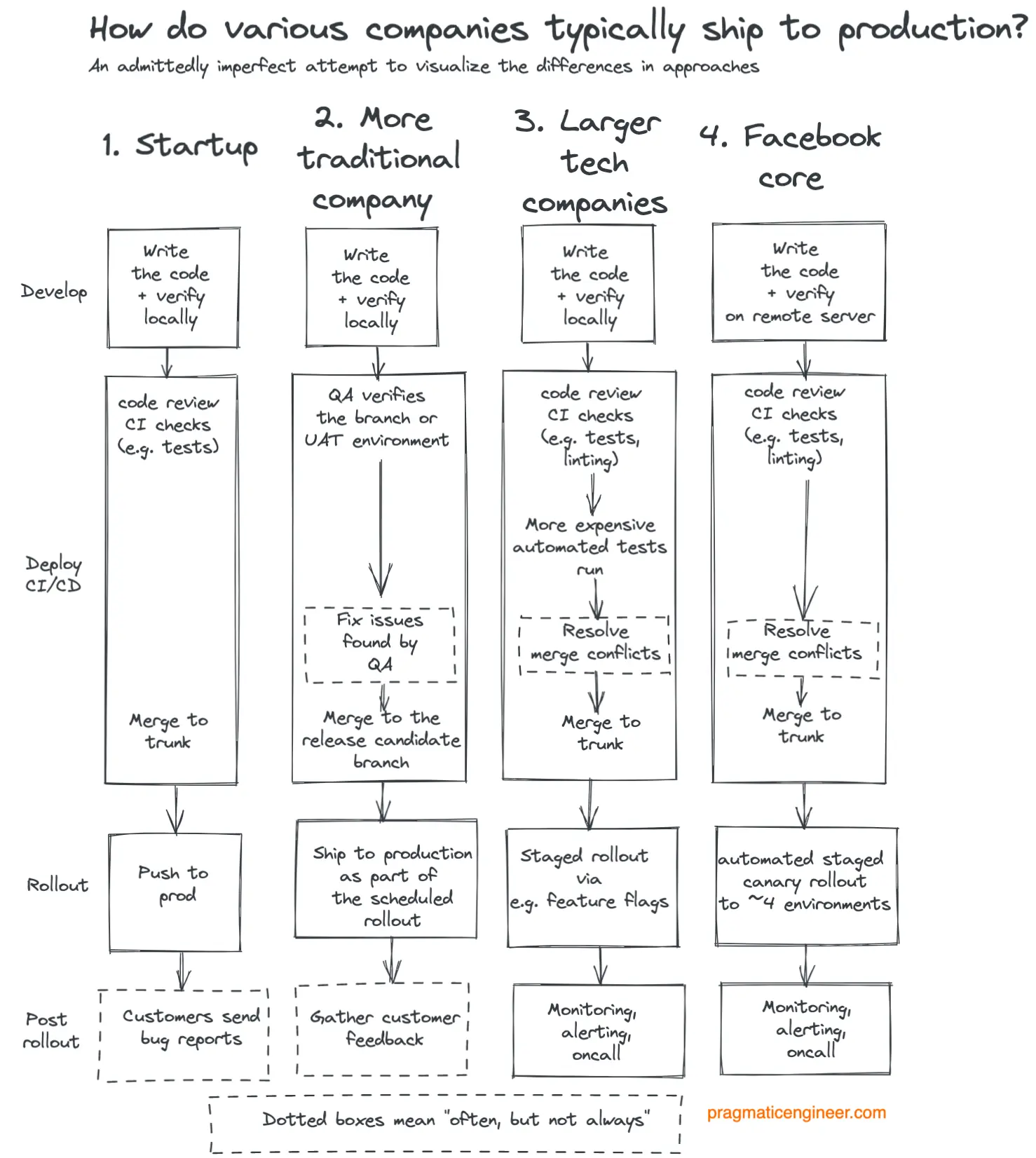 不同公司通常的发布方式
不同公司通常的发布方式
关于图表的说明:
1. 初创公司:质量检查通常比其他公司少。 他们优先考虑快速迭代,往往没有安全网。如果没有客户,这完全没问题。随着用户增加,团队需要找到避免 Bug 的方法,此时他们要么招聘 QA,要么投资自动化。
2. 传统公司:严重依赖 QA 团队。 虽然也会有自动化,但严重依赖庞大的 QA 团队来人工验证。通常在分支上开发,很少用主干开发(Trunk-based development)。代码通常在 QA 验证后按计划(如每周)推向生产环境。通常需要 QA 或 PM(产品/项目经理)的审批才能进入下一阶段。
3. 大型科技公司:在发布基础设施和自动化上投入巨大。 这些投资包括快速反馈的自动化测试、金丝雀发布(Canarying)、特性开关(Feature flags)和灰度发布。他们既要保质量,又要确保检查完毕后立刻发布(基于主干开发)。由于主干每天可能有上百次变更,处理代码冲突的工具变得至关重要。
4. Facebook (Meta) 核心产品:拥有少见的高效方法。 它的自动化测试没外界想象的多,但拥有极其强大的自动化金丝雀发布功能。代码会经过 4 个环境:自动化测试环境 -> 全体员工使用环境 -> 小区域测试市场 -> 全量用户。任何阶段指标异常,发布都会自动停止。
在 Facebook 工程文化 一文中,一位前员工回忆了如何拦截一个险些造成大祸的广告 Bug:
"当时我在广告团队,有个代码改动搞坏了特定类型的广告,如果发出去会让公司遭受巨大经济损失。但这个 Bug 在第二阶段就被拦截了。由于每个阶段都监控了海量健康指标,一旦出问题就会触发警报。而且所有 Facebook 员工都会使用生产前版本的 App,这意味着他们有约 7.5 万名员工在充当测试员,帮忙发现任何功能退化。"
3. 负责任发布的原则和工具
如果你想负责任地发布代码,以下原则值得参考。你不必全部照做,但可以思考一下"为什么不这么做"。
1. 使用本地或隔离的开发环境 :工程师应该能在本地或专用的隔离环境中开发。不过像 Meta 等公司正在转向远程专用服务器开发(详见 Facebook 工程文化)。
2. 本地验证:写完代码后,先自己在本地测试一下。
3. 考虑并测试边缘情况:代码在真实世界会遇到哪些特殊情况?列出这些边缘情况,尽量写自动化测试,或者至少手动测一下。如果你和 QA 合作,他们在这方面能帮大忙。
4. 编写自动化测试:手动验证后,加上自动化测试。如果是 TDD(测试驱动开发),则顺序相反。
5. 找人 Code Review(代码审查) :写清楚变更说明和你测过的边缘情况,找了解背景的同事帮忙看看代码。阅读更多关于如何做好代码审查。
6. 确保所有自动化测试通过:提交代码前,跑遍系统里所有的现有测试,降低引入回归 Bug 的风险。这通常通过 CI/CD 系统自动完成。
7. 监控核心健康指标:如何知道你的改动没搞坏系统?你需要监控。比如在 Uber,如果代码发布导致用户叫车成功率下降,就会触发警报,团队必须介入排查。
8. 安排值班(Oncall):发布后有些问题很久才会暴露。需要有了解系统、知道如何止损的工程师轮值。团队应准备好排障手册(Runbooks),并进行值班培训。
9. 建立无指责的故障处理文化 :从故障中学习,详见故障复盘最佳实践。
4. 额外的验证层与方法
公司还可以用哪些安全网?通常团队只会挑几个用,因为有些是互斥的(比如如果你已经在生产环境做多租户测试了,就不需要一堆测试环境了)。以下是 9 种常见方法:
1. 独立的部署环境 :如测试、UAT(用户验收测试)、Staging 或 Pre-prod 等环境。好处是多一层安全网,坏处是维护成本高(既费机器,又需要费力同步测试数据)。详见 Harness 团队的文章 构建和发布到部署环境。
2. 动态创建测试环境 :维护静态测试环境很痛苦(特别是数据迁移时)。投资自动化,实现一键拉起测试环境并填充数据,能极大提升开发和测试效率。
3. 专职 QA 团队:单纯的手动测试会拖慢速度。高效的 QA 是领域专家,他们不仅能做探索性测试发现边缘情况,还会参与测试自动化策略的制定,从而加速发布。
4. 探索性测试:模拟真实用户使用产品的行为,寻找隐藏问题。这需要对产品的深入了解和同理心,通常由 QA 或专门的第三方供应商来做。
5. 金丝雀发布(Canarying) :得名于矿工带下井的金丝雀(遇毒气先晕,起预警作用)。把新代码发给一小部分用户,监控没问题后再全量。通常通过负载均衡器或单节点部署实现。详见 LaunchDarkly 的这篇文章。
6. 特性开关(Feature flags)与实验:用代码里的开关把新功能藏起来,只对部分用户开放。常用于 A/B 测试实验:
javascript
if( featureFlags.isEnabled("Zeno_Feature_Flag")) {
// 执行新代码
} else {
// 执行旧代码
}7. 灰度发布(Staged rollout):分阶段发布。比如:新西兰 10% -> 新西兰 100% -> 全球 10% -> 全球 100%。每个阶段指标正常才进入下一阶段。
8. 多租户技术(Multi-tenancies) :越来越流行的方法,直接把代码发到生产环境 进行测试。请求中携带"租户"上下文(如:真实请求、测试请求),系统根据上下文做不同处理(比如遇到测试请求,支付系统会模拟扣款而不是真扣钱)。详见 Uber 和 Doordash 的实现。
9. 自动回滚:如 Booking.com 采用的做法,一旦发现新实验导致关键指标下降,系统立刻自动回滚。
10. 跨多个环境的自动发布与回滚:将自动回滚、灰度发布和多个测试环境结合起来,这是 Facebook 核心产品采用的独特模式。
5. 承担务实的风险以提高速度
有时为了追求速度,我们需要承担一些风险。该怎么做才务实?
明确哪些底线绝对不能碰:比如"绝不能不经测试强行提交"或"绝不能不经测试直接改生产数据库"。每个团队都要定好红线。如果必须打破规则来加快速度,请务必先获得团队成员的支持。
发布高风险变更时,提前打招呼:通知可能受影响的人,包括团队成员、上下游依赖方的值班人员、客服以及关注业务指标的业务方,让他们帮你留意异常。
准备易于执行的回滚计划 :万一搞砸了怎么恢复?特别是在改数据或配置时。早期 Facebook 甚至要求工程师在代码提交(Diffs)里写明回滚计划(详见 Facebook 工程文化)。
发布后紧盯用户反馈:发了高风险的改动后,主动去刷一刷用户论坛、评价和客服反馈,看看有没有人遇到问题。
记录故障并衡量影响:过去一个月系统挂了多少次?造成了多大业务影响?如果你不知道,那就等于盲飞。你需要这些数据来优化发布流程。
利用"错误预算(Error budgets)"决定能否冒险 :用 SLI(服务等级指标)和 SLO(服务等级目标)来设定一个可容忍的错误预算。只要预算没超,就可以尝试激进的高风险发布;一旦预算用光,就立刻停止走捷径。
6. 决定你采取的方法
本节内容请见订阅者完整文章。
7. 部署过程中需要纳入的其他内容
本节内容请见订阅者完整文章。
核心要点
最大的启示之一是:不要只关注怎么把代码发上去,还要关注出错后怎么快速恢复。最后总结几点:
- 发布快与质量高,可以兼得! 很多人误以为这是零和博弈。实际上,Code Review、CI/CD、自动化测试等工具能让你既快又好。
- 善用工具:本文列举了许多能让你更自信、更快速发版的方法。
- QA 是加速发布的好帮手:不要觉得 QA 会拖慢进度。他们的目标是高质量软件。与 QA 合作,共同探讨如何在保质量的前提下加快发布流程。
- 老系统改造更难:在新项目里引入先进的发布流程比较容易,在老代码库上改造虽然可行,但成本高昂。
- 接受 Bug 的存在:把精力放在"如何快速修复"上!很多团队过度纠结于"0 Bug 发布",反而忽视了如何快速发现并解决问题。
许多公司分享过他们的发布经验,以下文章值得一读:
- Monzo: 每天发布到生产环境 100 多次 (2022)
- Wayfair: 2 年内将部署频率提高 5 倍 (2021)
- Funda: 发布自动化 (2021)
- Harness: 构建与发布到部署环境 (2021)
- LinkedIn: 持续部署之旅的经验教训 (2019)
- Honeycomb CTO Charity Majors: 我在生产环境中测试 (2019)
- Up Bank: 持续交付 (2018)
- Facebook: 大规模快速发布 (2017)
- Uber: 自信地进行每日部署 (2016)
- The Guardian (卫报): 采用持续交付 (2015)
如果您喜欢这篇文章,欢迎订阅 The Pragmatic Engineer Newsletter 获取每周更新。在每期内容中,我都会通过工程经理和高级工程师的视角,探讨大型科技公司和高增长初创公司面临的挑战。👇