YOLO26:面向实时目标检测的核心架构改进与性能基准测试
摘要
本研究全面分析了Ultralytics YOLO26模型,重点阐述其核心架构改进与面向边缘端实时目标检测的性能基准。YOLO26于2025年9月发布,是YOLO系列最新、最先进的成员,专为在边缘及低功耗设备上实现高效性、精准度与部署便捷性而设计。本文依次详述YOLO26的架构创新,包括移除分布焦点损失(DFL)、采用端到端无NMS推理、集成渐进式损失平衡(ProgLoss)与小目标感知标签分配(STAL)机制,以及引入MuSGD优化器以实现稳定收敛。除架构外,本研究将YOLO26定位为多任务框架,支持目标检测、实例分割、姿态/关键点估计、定向检测与分类任务。本文给出YOLO26在NVIDIA Jetson Nano、Orin等边缘设备上的性能基准,并与YOLOv8、YOLO11、YOLOv12、YOLOv13及基于Transformer的检测器进行对比。本文还探讨了YOLO26的实时部署路径、灵活的导出格式(ONNX、TensorRT、CoreML、TFLite)以及INT8/FP16量化方案。文中列举YOLO26在机器人、制造业、物联网领域的实际应用案例,彰显其跨行业适配能力。最后,本文讨论了YOLO26的部署效率与广泛应用价值,并展望了YOLO26及YOLO系列的未来发展方向。
关键词:YOLO26;边缘人工智能;多任务目标检测;无NMS推理;小目标识别;单次目标检测;目标检测;MuSGD优化器
1 引言
目标检测已成为计算机视觉领域最核心的任务之一,使机器能够定位并分类图像或视频流中的多个目标。从自动驾驶、机器人到安防监控、医学影像、农业与智能制造,实时目标检测算法都是人工智能(AI)应用的核心支撑。在众多算法中,单次目标检测(YOLO) 系列凭借精准度与前所未有的推理速度,成为实时目标检测领域最具影响力的模型家族。
自2016年问世以来,YOLO历经多次架构迭代,每一代都解决了前代的局限,同时融合了神经网络设计、损失函数与部署效率的前沿技术。
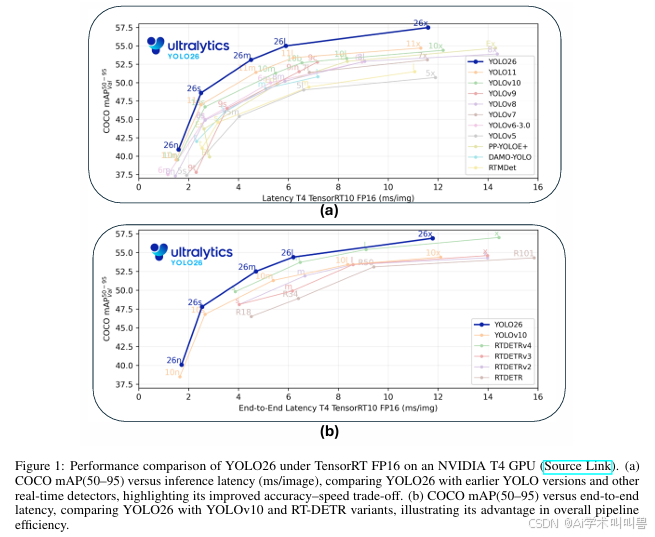
2025年9月发布的YOLO26,是YOLO系列的最新里程碑,其设计重心从渐进式架构复杂度 转向面向部署的简化设计 ,核心体现为精简的回归逻辑、端到端预测特性,以及新型优化技术带来的训练阶段改进。这种边缘优先 的设计理念在精度-延迟趋势对比中得以印证:Ultralytics官方数据显示,在NVIDIA T4 GPU、TensorRT10、FP16精度下,YOLO26的COCO mAP(50-95)与推理延迟表现,优于YOLO11、YOLOv10、YOLOv9、YOLOv8、YOLOv7、YOLOv6-3.0、YOLOv5等前代YOLO模型,以及PP-YOLOE+、DAMO-YOLO、RTMDet等主流实时检测器。
在相同的COCO mAP(50-95)与端到端延迟维度下,将YOLO26与YOLOv10、RT-DETR系列等Transformer类实时基线模型对比,凸显YOLO26在保持高检测质量的同时,降低了整体流水线延迟,这一特性对低功耗、延迟敏感的边缘设备尤为关键。
YOLO框架由约瑟夫·雷蒙及其团队于2016年首次提出,颠覆了目标检测的范式。与R-CNN、Faster R-CNN等传统两阶段检测器(将区域提议与分类分离)不同,YOLO将检测任务建模为单一回归问题 。通过卷积神经网络(CNN)单次前向传播直接预测边界框与类别概率,YOLO在保持竞争力精度的同时实现了实时速度。这种高效性让YOLOv1在机器人、自主导航、实时视频分析等延迟关键型应用中极具吸引力。
后续的YOLOv2(2017)与YOLOv3(2018)在保持实时性能的同时大幅提升精度。YOLOv2引入批量归一化、锚框与多尺度训练,增强了不同尺寸目标的检测鲁棒性。YOLOv3采用基于Darknet-53的更深架构,结合多尺度特征图优化小目标检测。这些改进让YOLOv3多年来成为学术界与工业界的标准方案。
随着高精度需求的提升(尤其在航空影像、农业、医学分析等复杂场景),YOLO模型向更先进的架构演进。YOLOv4(2020)采用跨阶段局部网络(CSPNet)、Mish激活函数,结合马赛克数据增强、CIoU损失等先进训练策略。
由Ultralytics开发的YOLOv5(2020)虽非官方版本,却凭借PyTorch实现、庞大社区支持与跨平台简化部署广受青睐。YOLOv5还实现了模块化设计,更易适配分割、分类、边缘部署等场景。
后续YOLOv6、YOLOv7(2022)融合了先进优化技术、参数高效模块与Transformer类结构,在保持实时推理的同时,将YOLO精度推向新高度。至此,YOLO生态已成为目标检测研究与部署的主流选择。
现代YOLO的主要维护方Ultralytics,在YOLOv8(2023)中重新定义了框架。YOLOv8采用解耦检测头、无锚框预测与优化训练策略,精度与部署灵活性大幅提升。其简洁的Python API、对TensorRT、CoreML、ONNX的兼容,以及面向速度/精度权衡的多版本(nano、small、medium、large、extra-large),使其在工业界广泛应用。
随后YOLOv9、YOLOv10、YOLO11快速迭代,每一代都突破了架构与性能边界。YOLOv9提出通用高效层聚合网络(GELAN)与渐进式蒸馏,兼顾效率与表征能力;YOLOv10通过混合任务对齐分配平衡精度与推理延迟;YOLO11进一步优化了Ultralytics的设计理念,在GPU上实现更高效率,同时保持优秀的小目标性能。这些模型巩固了Ultralytics在生产级YOLO模型开发中的领先地位。
YOLO11之后,YOLOv12、YOLOv13推出以注意力为核心的设计与先进架构组件,力求在多数据集上最大化精度。这些模型探索了多头自注意力、优化多尺度融合与更强的训练正则化策略,虽取得优异基准成绩,但仍依赖非极大值抑制(NMS)与分布焦点损失(DFL),在低功耗设备上带来延迟开销与导出难题。
基于NMS后处理与复杂损失函数的局限,Ultralytics官方团队研发了YOLO26。2025年9月,在伦敦举办的YOLO Vision 2025大会上,Ultralytics正式发布YOLO26,作为面向边缘计算、机器人与移动AI的下一代模型。
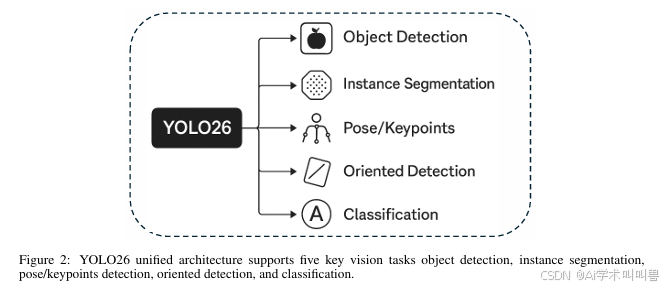
YOLO26围绕简洁、高效、创新 三大核心原则设计,其设计理念与五大支持任务:目标检测、实例分割、姿态/关键点检测、定向检测、分类。
推理阶段,YOLO26移除NMS ,实现原生端到端预测,消除了后处理瓶颈、降低延迟波动、简化部署中的阈值调优。
回归阶段,移除DFL ,将分布边界框解码简化为更轻量、硬件友好的形式,可无缝导出至ONNX、TensorRT、CoreML、TFLite,为边缘与移动流水线提供实用优势。
这些改进共同实现了更精简的计算图、更快的冷启动速度与更少的运行时依赖,对CPU与嵌入式场景尤为友好。
训练稳定性与小目标检测能力通过渐进式损失平衡(ProgLoss)与 小目标感知标签分配(STAL)实现:ProgLoss自适应加权损失项,避免训练后期简单样本主导损失;STAL优先为微小/遮挡目标分配标签,提升航空、机器人、智能摄像头场景中杂乱、遮挡、运动模糊下的召回率。
优化器采用MuSGD,融合SGD的泛化能力与类Muon优化器的动量/曲率特性,实现更快、更平稳的收敛,在不同尺度模型上均有稳定表现。
功能上,YOLO26的五大能力共享统一的骨干网络、颈部网络与精简检测头:
- 目标检测:无锚框、无NMS的边界框与置信度预测
- 实例分割:轻量级掩码分支,共享主干特征
- 姿态/关键点检测:紧凑的关键点检测头,适配人体/部件关键点
- 定向检测:旋转边界框,适配倾斜目标与细长目标
- 分类:单标签逻辑回归,适配纯识别任务
这种一体化设计支持多任务训练或任务专属微调,无需重构架构;简化的导出格式保证了跨加速器的可移植性。
综上,YOLO26通过端到端推理、无DFL回归、ProgLoss、STAL与MuSGD的组合,实现了部署更快、训练更稳、能力更广 的突破。
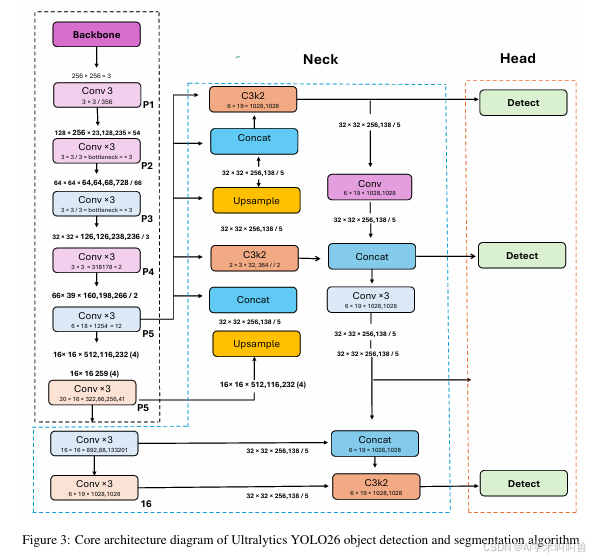
2 YOLO26的架构改进
YOLO26采用精简高效的流水线设计,专为边缘与服务器平台的实时目标检测打造。模型流程始于图像/视频流输入,经缩放、归一化等预处理后,输入骨干特征提取网络;紧凑高效的卷积网络捕捉视觉特征的层级表征,为兼顾不同尺度目标鲁棒性,架构生成多尺度特征图,保留大/小目标的语义信息;这些特征图经轻量级特征融合颈部网络高效整合;检测处理在直接回归头 中完成,与前代YOLO不同,该模块无需NMS即可输出边界框与类别概率,实现端到端无NMS推理 ,消除后处理开销、加速部署。
训练稳定性与精度由ProgLoss损失平衡与STAL标签分配模块保障,确保损失项加权均衡、提升小目标检测效果。
模型优化由MuSGD优化器 驱动,融合SGD与Muon优势,实现更快、更可靠的收敛。
部署效率通过量化进一步提升,支持FP16与INT8精度,在CPU、NPU、GPU上实现加速,精度损失极小。
最终输出边界框、类别预测等结果,可叠加在输入图像上可视化。
整体而言,YOLO26的架构实现了精度、稳定性与部署简洁性的均衡设计。
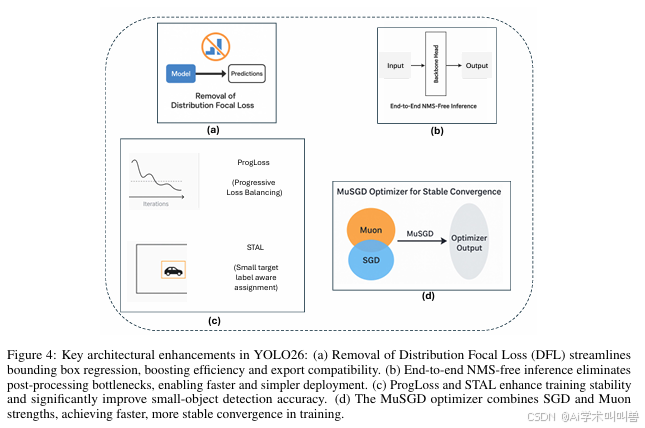
2.1 移除分布焦点损失(DFL)
YOLO26最核心的架构简化之一,是移除分布焦点损失(DFL)模块。DFL曾应用于YOLOv8、YOLO11等前代模型,初衷是通过预测边界框坐标的概率分布提升框回归精度,但也带来了显著的计算开销与导出难题。实际部署中,DFL需要推理与模型导出阶段的特殊处理,增加了ONNX、CoreML、TensorRT、TFLite等硬件加速器的部署复杂度。
移除DFL后,YOLO26简化了架构,将边界框预测回归为更直接的任务,且未牺牲性能。对比分析表明,结合ProgLoss与STAL后,YOLO26的精度与基于DFL的YOLO模型相当甚至更优。此外,移除DFL大幅降低推理延迟、提升跨平台兼容性,使其更适配边缘AI场景(轻量化、硬件友好是核心需求)。
相比之下,YOLOv12、YOLOv13保留DFL,尽管在GPU环境下精度优异,但在资源受限设备上的适用性受限。因此,YOLO26迈出了关键一步:将前沿目标检测精度与移动、嵌入式、工业应用的实际需求对齐。
2.2 端到端无NMS推理
YOLO26另一项突破性创新,是原生支持无NMS的端到端推理。传统YOLO模型(YOLOv8至YOLOv13)高度依赖NMS后处理,通过保留最高置信度边界框过滤重复预测。NMS虽有效,但会增加流水线延迟,且需要手动调优交并比(IoU)阈值等超参数。这种对人工后处理的依赖,让部署流水线更脆弱,尤其在边缘设备与延迟敏感应用中。
YOLO26重新设计预测头,直接输出无冗余的边界框预测,无需NMS 。这种端到端设计降低了推理复杂度,消除了手动调参需求,简化了生产系统集成。基准测试显示,YOLO26的推理速度快于YOLO11、YOLOv12,nano版本CPU推理速度最高提升43%,对手机、无人机、嵌入式机器人平台(毫秒级延迟影响实际操作)极具优势。
除速度外,无NMS设计提升了复现性与部署可移植性,模型无需复杂后处理代码。尽管RT-DETR、Sparse R-CNN等先进检测器已尝试无NMS推理,但YOLO26是首个采用该范式且保持YOLO经典速度-精度权衡的YOLO版本。与仍依赖NMS的YOLOv13相比,YOLO26的端到端流水线成为实时检测的前瞻性架构。
2.3 ProgLoss与STAL:提升训练稳定性与小目标检测
训练稳定性与小目标识别是目标检测的长期难题。YOLO26通过**渐进式损失平衡(ProgLoss)与小目标感知标签分配(STAL)**解决这一问题。
- ProgLoss:训练中动态调整不同损失项的权重,避免模型过拟合主导类别、忽略稀有/小类别,提升泛化能力,防止训练后期不稳定。
- STAL:显式优先为小目标分配标签,解决小目标像素少、易遮挡的检测难题。
二者结合,让YOLO26在COCO、无人机影像等含小/遮挡目标的数据集上精度大幅提升。
前代YOLOv8、YOLO11未集成此类针对性机制,通常需要数据集专属增强或外部训练技巧才能实现合格的小目标性能;YOLOv12、YOLOv13通过注意力模块与多尺度特征融合尝试解决,但增加了架构复杂度与推理成本。YOLO26以更轻量的方式实现了同等/更优效果,进一步适配边缘AI场景。凭借ProgLoss与STAL,YOLO26成为鲁棒的小目标检测器,同时保持YOLO系列的高效性与可移植性。
2.4 MuSGD优化器:实现稳定收敛
YOLO26的最后一项创新,是引入MuSGD优化器。该优化器融合随机梯度下降(SGD)与近期提出的Muon优化器(灵感源自大语言模型LLM训练优化策略),结合SGD的鲁棒性、泛化能力与Muon的自适应特性,实现多数据集上更快收敛、更稳定的优化。
这种混合优化器体现了深度学习的前沿趋势:自然语言处理(NLP)与计算机视觉技术的交叉融合。借鉴LLM训练经验,YOLO26获得了YOLO系列前所未有的稳定性提升。实验表明,MuSGD让YOLO26以更少训练轮次达到竞品精度,降低训练时间与计算成本。
前代YOLO(YOLOv8至YOLOv13)采用标准SGD或AdamW优化器,虽有效但需要大量超参调优,且在高方差数据集上收敛不稳定。相比之下,MuSGD提升了可靠性,同时保持YOLO轻量化训练的特性。对开发者而言,这意味着更短的开发周期、更少的训练重启、更可预测的部署性能。通过集成MuSGD,YOLO26不仅是推理优化模型,更是对研究者与工业从业者友好的训练架构。
3 基准测试与对比分析
3.1 检测与分割性能指标
检测结果显示,YOLO26随模型尺度增大,COCO mAP(50-95)持续提升,同时在CPU(ONNX)、GPU(TensorRT)运行时保持可预测的低推理延迟。其中,YOLO26-m、YOLO26-l实现53%、55%以上的强检测精度,延迟远低于Transformer类竞品,印证了无NMS推理与精简回归设计的优势。模型参数与计算量(FLOPs)呈现良好的缩放特性,凸显YOLO26在多部署目标下的效率。
分割结果表明,YOLO26在多任务场景中仍保持上述优势。从nano到extra-large版本,YOLO26-seg实现有竞争力的边界框与掩码mAP,计算量可控、吞吐量实时,即便端到端评估也表现优异。与依赖更重Transformer编码器的YOLOv10、RT-DETR系列相比,YOLO26的精度-延迟权衡更均衡,尤其适配边缘与CPU推理。
综上,检测与分割基准证明:YOLO26并非简单的迭代优化,而是YOLO系列面向部署的演进,在严格延迟约束下,高效衔接了轻量化设计与高精度实时感知。
表1 Ultralytics YOLO26目标检测性能指标(640px)
| 检测模型 | 尺寸(px) | mAP val 50--95 | mAP val 50--95 (端到端) | CPU ONNX速度(ms) | T4 TRT10速度(ms) | 参数(M) | 计算量(B) |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9±0.7 | 1.7±0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2±0.9 | 2.5±0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0±1.4 | 4.7±0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2±2.0 | 6.2±0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8±4.0 | 11.8±0.2 | 55.7 | 193.9 |
表2 Ultralytics YOLO26实例分割性能指标(640px)
| 实例分割模型 | 尺寸(px) | 边界框mAP 50--95 (端到端) | 掩码mAP 50--95 (端到端) | CPU ONNX速度(ms) | T4 TRT10速度(ms) | 参数(M) | 计算量(B) |
|---|---|---|---|---|---|---|---|
| YOLO26n-seg | 640 | 39.6 | 33.9 | 53.3±0.5 | 2.1±0.0 | 2.7 | 9.1 |
| YOLO26s-seg | 640 | 47.3 | 40.0 | 118.4±0.9 | 3.3±0.0 | 10.4 | 34.2 |
| YOLO26m-seg | 640 | 52.5 | 44.1 | 328.2±2.4 | 6.7±0.1 | 23.6 | 121.5 |
| YOLO26l-seg | 640 | 54.4 | 45.5 | 387.0±3.7 | 8.0±0.1 | 28.0 | 139.8 |
| YOLO26x-seg | 640 | 56.5 | 47.0 | 787.0±6.8 | 16.4±0.1 | 62.8 | 313.5 |
3.2 分类性能指标(ImageNet数据集)
YOLO26在ImageNet数据集上的分类性能显示,模型从YOLO26n到YOLO26x,Top-1精度从71.4%稳步提升至79.9%,所有版本Top-5精度均保持90%以上。重要的是,精度提升伴随可预测的延迟增长,即便是最大模型,TensorRT FP16推理延迟仍低于4毫秒。紧凑的计算量与参数数量表明,YOLO26分类头保持了高效性,适配边缘与嵌入式平台的实时图像识别。
表3 YOLO26图像分类性能指标(224px)
| 分类模型 | 尺寸(px) | Top-1精度 | Top-5精度 | CPU ONNX速度(ms) | T4 TRT10速度(ms) | 参数(M) | 计算量(B@224) |
|---|---|---|---|---|---|---|---|
| YOLO26n-cls | 224 | 71.4% | 90.1% | 5.0±0.3 | 1.1±0.0 | 2.8 | 0.5 |
| YOLO26s-cls | 224 | 76.0% | 92.9% | 7.9±0.2 | 1.3±0.0 | 6.7 | 1.6 |
| YOLO26m-cls | 224 | 78.1% | 94.2% | 17.2±0.4 | 2.0±0.0 | 11.6 | 4.9 |
| YOLO26l-cls | 224 | 79.0% | 94.6% | 23.2±0.3 | 2.8±0.0 | 14.1 | 6.2 |
| YOLO26x-cls | 224 | 79.9% | 95.0% | 41.4±0.9 | 3.8±0.0 | 29.6 | 13.6 |
3.3 姿态估计性能指标(COCO数据集)
YOLO26在COCO数据集上的姿态估计性能显示,不同尺度模型的姿态mAP持续提升,nano版本端到端姿态mAP为57.2%,extra-large版本达71.6%。精度提升伴随延迟与计算量的可预测增长,同时保持GPU实时推理、CPU近实时推理。结果表明,YOLO26将高效设计延伸至姿态估计任务,适配边缘与服务器平台的实时人体/目标关键点分析。
表4 YOLO26姿态估计性能指标(640px)
| 姿态模型 | 尺寸(px) | 姿态mAP 50--95 (端到端) | 姿态mAP 50 (端到端) | CPU ONNX速度(ms) | T4 TRT10速度(ms) | 参数(M) | 计算量(B) |
|---|---|---|---|---|---|---|---|
| YOLO26n-pose | 640 | 57.2% | 83.3% | 40.3±0.5 | 1.8±0.0 | 2.9 | 7.5 |
| YOLO26s-pose | 640 | 63.0% | 86.6% | 85.3±0.9 | 2.7±0.0 | 10.4 | 23.9 |
| YOLO26m-pose | 640 | 68.8% | 89.6% | 218.0±1.5 | 5.0±0.1 | 21.5 | 73.1 |
| YOLO26l-pose | 640 | 70.4% | 90.5% | 275.4±2.4 | 6.5±0.1 | 25.9 | 91.3 |
| YOLO26x-pose | 640 | 71.6% | 91.6% | 565.4±3.0 | 12.2±0.2 | 57.6 | 201.7 |
3.4 定向目标检测(OBB)性能(DOTA v1数据集)
YOLO26在DOTA v1数据集上的定向目标检测性能显示,随模型尺度增大,测试mAP持续提升,extra-large版本端到端mAP(50-95)达56.7%。尽管OBB任务输入分辨率更高、计算需求更大,YOLO26仍保持高效推理,小/中版本GPU延迟低于5毫秒。结果表明,YOLO26将边缘优化、无NMS设计有效延伸至旋转目标检测,适配航空影像、遥感应用。
表5 YOLO26定向目标检测性能指标(1024px)
| 定向检测模型 | 尺寸(px) | 测试mAP 50--95 (端到端) | 测试mAP 50 (端到端) | CPU ONNX速度(ms) | T4 TRT10速度(ms) | 参数(M) | 计算量(B) |
|---|---|---|---|---|---|---|---|
| YOLO26n-obb | 1024 | 52.4% | 78.9% | 97.7±0.9 | 2.8±0.0 | 2.5 | 14.0 |
| YOLO26s-obb | 1024 | 54.8% | 80.9% | 218.0±1.4 | 4.9±0.1 | 9.8 | 55.1 |
| YOLO26m-obb | 1024 | 55.3% | 81.0% | 579.2±3.8 | 10.2±0.3 | 21.2 | 183.3 |
| YOLO26l-obb | 1024 | 56.2% | 81.6% | 735.6±3.1 | 13.0±0.2 | 25.6 | 230.0 |
| YOLO26x-obb | 1024 | 56.7% | 81.7% | 1485.7±11.5 | 30.5±0.9 | 57.6 | 516.5 |
4 Ultralytics YOLO26的实时部署
过去十年,目标检测模型的演进不仅体现在精度提升,更体现在部署复杂度的增长。早期R-CNN系列检测器精度优异,但计算成本高、分多阶段处理,限制了实时与嵌入式应用。YOLO系列将检测重构为单阶段回归问题,实现普通GPU的实时推理,颠覆了行业格局。但YOLOv1至YOLOv13的精度提升,往往伴随DFL、NMS等额外组件与更重的骨干网络,增加了部署阻力。YOLO26直接解决这一长期难题,精简架构与导出流程,降低多硬件、软件生态的部署门槛。
4.1 灵活的导出与集成路径
YOLO26的核心优势之一,是可无缝集成现有生产流水线。Ultralytics维护的活跃Python包,统一支持训练、验证与导出,降低从业者的技术接入成本。与前代YOLO需要自定义转换脚本实现硬件加速不同,YOLO26原生支持多种导出格式:
- TensorRT:GPU最大加速
- ONNX:跨平台通用兼容
- CoreML:iOS原生集成
- TFLite:安卓与边缘设备
- OpenVINO:英特尔硬件优化
丰富的导出格式让研究者、工程师、开发者可快速从原型落地生产,避免前代模型的兼容性瓶颈。
历史上,YOLOv3至YOLOv7导出至NVIDIA TensorRT、Apple CoreML等专用推理引擎时,常需要手动处理;Transformer类检测器(如DETR系列)因动态注意力机制,在PyTorch环境外转换困难。相比之下,YOLO26通过移除DFL、采用无NMS预测头,在不牺牲精度的前提下实现跨平台兼容,成为目前部署最友好的检测器之一,巩固了其边缘优先的定位。
4.2 量化与资源受限设备
除导出灵活性外,实际部署的核心挑战是资源受限设备的效率保障。手机、无人机、嵌入式视觉系统等边缘设备通常无独立GPU,需要平衡内存、功耗与延迟约束。量化是降低模型尺寸、计算负载的通用方案,但多数复杂检测器在激进量化下精度大幅下降。YOLO26的设计充分考虑这一局限:
得益于精简架构与简化边界框回归流水线,YOLO26在**半精度(FP16)与整数(INT8)**量化下均保持稳定精度。
- FP16量化:利用GPU原生混合精度算术,加速推理、降低内存占用;
- INT8量化:将模型权重压缩为8位整数,大幅减小模型尺寸、降低功耗,同时保持竞争力精度。
基准实验证实,YOLO26在量化条件下的稳定性优于YOLO11、YOLOv12,适配NVIDIA Jetson Orin、高通骁龙AI加速器、ARM架构CPU的智能摄像头等紧凑型硬件。
相比之下,RT-DETRv3等Transformer检测器在INT8量化下性能骤降,核心原因是注意力机制对低精度敏感;YOLOv12、YOLOv13在GPU服务器精度优异,但量化后在低功耗设备上性能大幅衰减。因此,YOLO26树立了目标检测领域量化感知设计 的新标杆,证明架构简洁性直接转化为部署鲁棒性。
4.3 跨行业应用:从机器人到制造业
部署优化的实际价值,在跨行业应用中得以充分体现。
- 机器人领域:实时感知是导航、操作、人机安全协作的关键。YOLO26的无NMS预测、稳定低延迟推理,让机器人系统更快、更可靠地理解环境。例如,搭载YOLO26的机械臂可在动态场景中更精准识别抓取目标,移动机器人在杂乱环境中更好地识别障碍物。与YOLOv8、YOLO11相比,YOLO26推理延迟更低,在高速场景中决定了安全规避与碰撞的差异。
- 制造业领域:YOLO26可用于自动化缺陷检测与质量保障。传统人工检测劳动密集、易出错;前代YOLOv8已应用于智能工厂,但导出复杂、NMS延迟限制了大规模部署。YOLO26通过OpenVINO、TensorRT实现轻量化部署,让制造商可将实时缺陷检测系统直接集成生产线。早期基准显示,基于YOLO26的缺陷检测流水线,吞吐量与运营成本优于YOLOv12、DETR等Transformer方案。
4.4 YOLO26部署的核心启示
综上,YOLO26的部署特性凸显了目标检测演进的核心主题:架构效率与精度同等重要 。过去五年,从卷积YOLO到Transformer DETR、RT-DETR,模型愈发复杂,但实验室性能与生产落地的差距限制了其影响力。YOLO26通过架构简化、导出兼容、量化鲁棒弥合这一差距,将前沿精度与实际部署需求对齐。
- 移动应用开发者:通过CoreML、TFLite无缝集成,模型在iOS/安卓原生运行;
- 云/本地服务器部署企业:TensorRT、ONNX导出提供可扩展加速方案;
- 工业/边缘用户:OpenVINO、INT8量化保证资源严格约束下的稳定性能。
从这一角度看,YOLO26不仅是目标检测研究的进步,更是AI部署民主化的重要里程碑。
5 结论与未来方向
5.1 结论
综上,YOLO26是YOLO目标检测系列的重大飞跃,将架构创新与部署实用主义 深度融合。模型通过移除DFL模块 、取消NMS后处理 实现设计简化:移除DFL精简了边界框回归、避免导出难题,拓宽硬件兼容性;无NMS端到端推理让网络直接输出最终检测结果,无需后处理,既降低延迟又简化部署流水线,是YOLO理念的自然演进。
训练阶段,YOLO26引入ProgLoss与STAL,稳定训练过程、大幅提升小目标检测精度;新型MuSGD优化器融合SGD与Muon特性,加速收敛、提升训练稳定性。
这些改进协同作用,让YOLO26成为更精准、更鲁棒、更快、更轻量的检测器。
性能基准对比表明,YOLO26相较于前代YOLO与同期模型优势显著:YOLO11以更高效率超越前代,YOLOv12通过注意力模块提升精度,YOLOv13通过超图优化进一步突破;与Transformer竞品相比,YOLO26大幅缩小精度差距,原生无NMS设计对标Transformer端到端思路,同时保持YOLO经典高效性。YOLO26在保证精度的同时,在通用硬件上大幅提升吞吐量、降低复杂度,CPU推理速度最高提升43%,成为资源受限环境下最实用的实时检测器之一。这种性能与效率的均衡,让YOLO26不仅在基准测试中表现优异,更在速度、内存、功耗受限的实际场景中脱颖而出。
YOLO26的核心贡献,是极致的部署优化 :模型架构专为实际应用设计,移除DFL与NMS,避免硬件加速器难以实现的操作,提升跨设备兼容性;支持ONNX、TensorRT、CoreML、TFLite、OpenVINO全格式导出,开发者可轻松集成至移动应用、嵌入式系统、云服务;更关键的是,YOLO26支持稳健量化,INT8/FP16部署精度损失极小,精简架构适配低比特推理,模型可压缩加速的同时保持可靠检测性能。这些特性让YOLO26在无人机、智能摄像头等CPU/小型设备上实现实时运行,解决了前代YOLO的部署难题。
整体而言,YOLO26弥合了前沿研究理念 与可部署AI方案的鸿沟,将最新计算机视觉技术直接交付给从业者,成为学术创新与工业应用的桥梁。
5.2 未来方向
展望未来,YOLO与目标检测研究的发展有几大核心方向:
- 多视觉任务统一化:YOLO26已实现检测、分割、姿态估计、定向检测、分类的一体化框架,体现多任务通用化趋势。未来YOLO可进一步融合开放词汇、基础模型能力,借助视觉-语言模型实现零样本任意类别识别,突破固定标签限制;基于基础模型与大规模预训练,下一代YOLO有望成为通用视觉AI,无缝处理新目标的检测、分割与描述。
- 半监督/自监督学习:前沿检测器仍高度依赖大规模标注数据集,而无标注/弱标注数据的训练技术快速发展。教师-学生训练、伪标签、自监督特征学习等方法可融入YOLO训练流程,降低人工标注需求。未来YOLO可自动利用海量无标注图像/视频提升识别鲁棒性,无需等量标注数据即可适配新领域、稀有类别。
- CNN与Transformer架构融合 :近期YOLO证明,在YOLO架构中注入注意力与全局推理能力可提升精度。未来YOLO将采用混合设计:卷积骨干网络实现高效局部特征提取,Transformer模块/解码器捕捉长距离依赖与上下文信息,优化复杂场景(拥挤、高上下文环境)的理解能力,融合CNN与Transformer的优势,应对多样化检测挑战。
- 边缘优先的训练与优化 :部署的重要性日益提升,未来研究将边缘感知训练与优化作为核心,而非将硬件约束作为后期考虑。模型设计将与目标平台协同进化,采用量化感知训练、自动模型压缩、硬件引导架构搜索等技术;将延迟、功耗等部署反馈直接融入训练循环,进一步提升实际效率。未来YOLO可在运行时约束下动态调整深度、分辨率、精度,或蒸馏为高精度紧凑型版本,适配物联网、AR/VR、自主系统等资源严格受限的实时场景。