论文信息
- 标题:Adding Conditional Control to Text-to-Image Diffusion Models
- 会议:arXiv preprint arXiv:2302.05543
- 单位:斯坦福大学
- 代码:github.com/lllyasviel/ControlNet
- 论文:https://arxiv.org/pdf/2302.05543
开篇:文生图的「控制难题」
玩过Stable Diffusion的朋友大概率都有过这种崩溃:明明prompt写了「站在厨房的厨师,左手颠锅右手拿铲,身体正对镜头」,结果生成的图里人物姿势千奇百怪,手指还经常多出来几根;想画一张精准构图的场景图,改了几十版prompt,出来的画面还是和脑子里的构想差了十万八千里。
这就是文生图扩散模型的天生短板:纯文本prompt根本无法实现细粒度的空间构图控制。文字擅长描述语义和风格,却很难精准表达复杂的布局、人物姿势、物体轮廓、空间深度这些空间信息,想要一张符合预期的图,往往要经历无数次的prompt修改和试错。
而2023年横空出世的ControlNet,直接把这个行业难题给彻底解决了。它能让你用一张边缘图、姿势骨架图、深度图、甚至随手画的涂鸦,精准控制Stable Diffusion的生成过程,想让人物摆什么姿势就摆什么姿势,想让画面是什么构图就是什么构图,也因此成了AI绘图圈里当之无愧的「控制神器」。
研究背景:给大模型加控制的两大核心挑战
在ControlNet出现之前,业内已经做了很多尝试来解决扩散模型的控制问题,但都卡在了两个核心痛点上:
痛点1:空间控制的粒度不足
早期的控制方法,要么是靠修改prompt、调整CLIP特征、修改交叉注意力层,要么是用空间掩码做局部控制,只能解决简单的图像变体、局部重绘(inpainting)问题。面对深度图生成、姿势控制、边缘引导这类复杂的空间控制需求,这些方法要么效果拉胯,要么完全不work。想要真正实现端到端的精准空间控制,必须靠数据驱动的学习方案。
痛点2:微调大模型的「灾难性遗忘」
想要给预训练的大模型加新的条件控制,最直接的办法就是全模型微调,但这条路根本走不通:
- 预训练的Stable Diffusion是用LAION-5B里数十亿张图片训出来的,而特定控制条件的数据集(比如人体姿势、边缘图),最大的也只有10万张左右,规模差了5万倍;
- 直接用小数据集微调大模型,必然会出现过拟合 和灾难性遗忘------模型学会了控制条件,却把原本强大的文生图能力给丢了,生成的画面质量断崖式下跌。
业内也有一些轻量化微调方案来缓解这个问题,比如LoRA、Adapter、HyperNetwork、Side-Tuning等,这些方法通过冻结原模型、只训练少量新增参数来避免遗忘,但它们的网络结构都太浅,没法处理复杂的野外条件图和高层语义信息,控制效果始终达不到工业级要求。
ControlNet的出现,完美解决了这两个核心痛点:它既保留了预训练大模型的全部生成能力,又能学习到复杂的空间条件控制,甚至单张消费级显卡就能完成训练。
核心方法:ControlNet的架构设计
ControlNet的核心设计思路极其巧妙:锁住预训练大模型的全部参数,做一个可训练的编码器副本,用「零卷积」层把两者连接起来,既复用了大模型的强大特征提取能力,又不会破坏原模型的权重,还能学习到新的条件控制能力。
3.1 ControlNet基本单元
我们先从最基础的神经块讲起,任何深度网络都是由一个个基础神经块堆叠而成的,比如ResNet块、Transformer块、卷积-归一化-激活块等。
基础神经块公式
一个预训练好的神经块,可以用这个公式表示:
y = F ( x ; Θ ) y=\mathcal {F}(x;\Theta ) y=F(x;Θ)
我们把公式里的每个字母拆解得明明白白,连大白话解释都给你安排上:
| 符号 | 专业名称 | 通俗解释 |
|---|---|---|
| y y y | 神经块输出特征图 | 这个网络块处理完输入后,输出的图片特征信息 |
| F ( ⋅ ) \mathcal{F}(\cdot) F(⋅) | 预训练神经块运算函数 | Stable Diffusion里已经训好的网络模块,比如ResNet块、ViT注意力块,是大模型能力的核心 |
| x x x | 输入特征图 | 上一层网络传递过来的图片特征,是这个模块的处理对象 |
| Θ \Theta Θ | 预训练神经块的参数 | 这个模块里已经训好的权重和偏置,是我们要完全锁住、绝对不动的部分,保住大模型的「老本」 |
ControlNet的核心改造
给这个基础神经块加上ControlNet,只需要三步:
- 锁住原模型 :把原神经块的参数 Θ \Theta Θ完全冻结,训练过程中绝对不更新,彻底避免灾难性遗忘;
- 做可训练副本 :把原神经块完整克隆一份,得到参数为 Θ c \Theta_c Θc的可训练副本,初始值和原块 Θ \Theta Θ完全一致,训练时只有这个副本会更新;
- 零卷积连接:用两个「零卷积层」把副本和原块连接起来,实现控制特征的融合。
这里必须重点讲零卷积 :它就是一个1×1的卷积层,权重和偏置全部初始化为0。通俗说,训练刚开始的时候,这个卷积层就是个「透明人」,对输入信号完全没有任何修改,不会给原模型引入一丁点儿有害噪声。
ControlNet核心计算公式
完整的ControlNet块运算公式如下:
y c = F ( x ; Θ ) + Z ( F ( x + Z ( c ; Θ z 1 ) ; Θ c ) ; Θ z 2 ) y_{c}=\mathcal{F}(x ; \Theta)+\mathcal{Z}\left(\mathcal{F}\left(x+\mathcal{Z}\left(c ; \Theta_{z 1}\right) ; \Theta_{c}\right) ; \Theta_{z 2}\right) yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
我们依旧把每个字母拆解得清清楚楚,绝不放过任何一个细节:
| 符号 | 专业名称 | 通俗解释 |
|---|---|---|
| y c y_c yc | ControlNet块最终输出 | 融合了原模型生成能力和条件控制信息的最终特征,会送入后续网络 |
| F ( x ; Θ ) \mathcal{F}(x ; \Theta) F(x;Θ) | 锁定的原神经块输出 | 完全保留了Stable Diffusion原本的生成能力,是整个模型的基础 |
| Z ( ⋅ ) \mathcal{Z}(\cdot) Z(⋅) | 零卷积运算 | 权重和偏置都初始化为0的1×1卷积层,是ControlNet的核心设计 |
| c c c | 外部控制条件 | 我们输入的控制蓝图,比如Canny边缘图、人体姿势骨架、深度图、分割图、涂鸦等 |
| Θ z 1 \Theta_{z1} Θz1 | 第一个零卷积的参数 | 初始全0,作用是把外部控制条件 c c c编码成和输入特征 x x x同维度的特征,让两者能相加融合 |
| Θ c \Theta_c Θc | 可训练副本的参数 | 和原块初始值完全一致,训练时仅更新这个副本,学习控制条件的特征 |
| Θ z 2 \Theta_{z2} Θz2 | 第二个零卷积的参数 | 初始全0,作用是把副本输出的控制特征,调整成和原块输出同维度,最终和原块输出相加融合 |
训练初始态的关键特性
在训练的第一步,因为两个零卷积的权重和偏置全都是0,所以公式里后面加的那一长串控制项,结果全都是0,此时:
y c = y y_{c}=y yc=y
这就是ControlNet最天才的设计:训练初期,模型的输出和原预训练模型完全一致,不会给原模型引入任何有害噪声,彻底避免了训练初期破坏预训练骨干网络的问题。通俗说就是,ControlNet一开始完全是「跟着原模型走」,不会瞎搞,训练过程中才慢慢学会怎么把控制条件加进去,绝不会把原模型的本事给弄丢了。
基础结构可视化
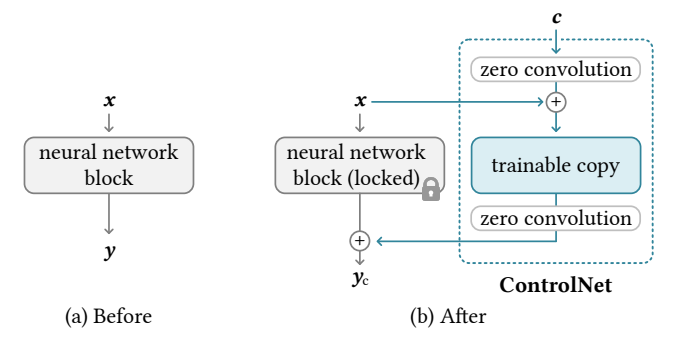
图片1 ControlNet基本结构示意图(出处:论文原文Figure 2)
图片分析:
- 左侧(a)是原生的预训练神经块,输入特征 x x x经过网络块处理后输出 y y y;
- 右侧(b)是加入ControlNet后的结构,灰色块是完全锁定的原神经块,蓝色块是可训练的副本,白色块是零卷积层;
- 外部控制条件 c c c经过第一个零卷积后,和输入特征 x x x融合,送入可训练副本;副本的输出经过第二个零卷积后,和原块的输出相加,得到最终结果。
3.2 ControlNet对接Stable Diffusion的完整实现
论文里以Stable Diffusion为例,详细讲了ControlNet的工程落地,我们先快速过一下Stable Diffusion的核心结构:
Stable Diffusion的生成核心,是一个经典的U-Net网络,包含编码器、中间块、带跳跃连接的解码器三部分,总共25个块:12个编码器块、1个中间块、12个解码器块。其中12个编码器块分布在4个分辨率上:64×64、32×32、16×16、8×8,每个分辨率对应3个块。
ControlNet的整体架构对接
ControlNet的对接逻辑极其简洁,完全不修改Stable Diffusion的原生结构:
- 把Stable Diffusion的12个编码器块+1个中间块,完整克隆出一套可训练的副本,原块完全锁定不动;
- 副本的输出,经过零卷积层调整后,分别加到Stable Diffusion U-Net对应的12个跳跃连接+1个中间块里,直接控制解码器的去噪过程;
- 整个架构对Stable Diffusion没有任何侵入性修改,完美兼容所有社区微调的SD模型。
整体架构可视化
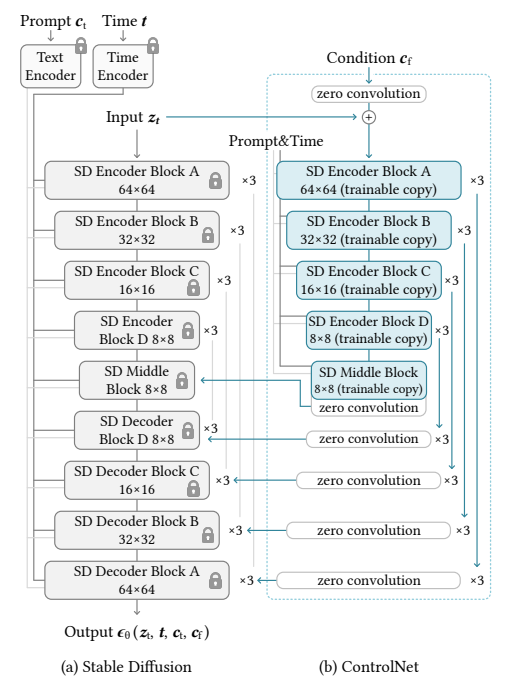
图片2 Stable Diffusion与ControlNet的整体架构图(出处:论文原文Figure 3)
图片分析:
- 左侧(a)是Stable Diffusion原生的U-Net架构,灰色块是编码器、中间块和解码器;
- 右侧(b)是加入ControlNet后的完整架构,灰色块依旧是锁定的原生SD网络,蓝色块是ControlNet新增的可训练编码器副本,白色块是零卷积层;
- 输入的控制条件经过编码后,送入ControlNet的可训练副本,最终输出的控制特征,逐分辨率加到SD的解码器跳跃连接里,实现对生成过程的精准控制。
计算效率与条件编码
- 计算效率:在单张NVIDIA A100 PCIE 40GB显卡上测试,加入ControlNet后,仅比原生Stable Diffusion多占用23%的显存,单步训练时间仅增加34%,轻量化程度拉满。
- 条件编码网络 :Stable Diffusion是在64×64的隐空间中完成扩散过程的,而我们输入的控制图通常是512×512的像素级图像,因此需要一个小网络把条件图编码到隐空间。论文里用了一个4层的卷积网络 E ( ⋅ ) \mathcal{E}(\cdot) E(⋅),公式如下:
c f = E ( c i ) c_{f}=\mathcal {E}(c_{i}) cf=E(ci)
其中:- c i c_i ci:输入的像素空间条件图(512×512),比如边缘图、姿势图;
- E ( ⋅ ) \mathcal{E}(\cdot) E(⋅):条件编码网络,4个卷积层,卷积核4×4、步长2×2,激活函数ReLU,通道数依次为16、32、64、128,和整个模型联合训练;
- c f c_f cf:编码后的隐空间条件特征(64×64),和SD的隐空间输入尺寸完全匹配,送入ControlNet的可训练副本。
3.3 训练细节与关键发现
扩散模型的训练目标
ControlNet完全复用了扩散模型的经典训练目标,也就是预测加在隐向量里的噪声,损失函数公式如下:
L = E z 0 , t , c t , c f , ϵ ∼ N ( 0 , 1 ) ∥ ϵ − ϵ θ ( z t , t , c t , c f ) ∥ 2 2 \mathcal{L} = \mathbb{E}_{z_0, t, c_t, c_f, \epsilon \sim \mathcal{N}(0,1)} \left \\left\\\| \\epsilon - \\epsilon_\\theta(z_t, t, c_t, c_f) \\right\\\|_2\^2 \\right L=Ez0,t,ct,cf,ϵ∼N(0,1)∥ϵ−ϵθ(zt,t,ct,cf)∥22
每个符号的详细解释:
| 符号 | 专业名称 | 通俗解释 |
|---|---|---|
| L \mathcal{L} L | 整体损失函数 | 训练的核心目标就是让这个值越小越好,用的是扩散模型经典的均方误差损失 |
| E ⋅ \mathbb{E}\\cdot E⋅ | 数学期望 | 对括号里所有随机变量的结果取平均值 |
| z 0 z_0 z0 | 干净隐向量 | 真实图片经过VAE编码后,得到的无噪声隐空间特征,是扩散模型的训练目标 |
| t t t | 扩散时间步 | 代表给图片加噪声的步数,t越大,加的噪声越多,图片越模糊 |
| c t c_t ct | 文本特征 | 输入的prompt经过CLIP文本编码器编码后的特征,控制生成的语义和风格 |
| c f c_f cf | 条件编码特征 | 公式(4)里的ControlNet控制特征,控制生成的空间布局和结构 |
| ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0,1) ϵ∼N(0,1) | 随机噪声 | 从标准正态分布中采样的噪声,是扩散过程中往图片里添加的内容 |
| z t z_t zt | 加噪隐向量 | 给干净的 z 0 z_0 z0加了t步噪声后的隐向量,是网络的输入 |
| ϵ θ ( ⋅ ) \epsilon_\theta(\cdot) ϵθ(⋅) | 待训练的U-Net | 原生SD U-Net+ControlNet的整体网络,目标是预测出加在 z t z_t zt里的真实噪声 ϵ \epsilon ϵ |
| ∣ ⋅ ∣ 2 2 |\cdot|_2^2 ∣⋅∣22 | L2范数平方 | 也就是均方误差,用来衡量网络预测的噪声和真实噪声之间的差距 |
训练的两个关键技巧
- 随机置空文本prompt:训练过程中,随机把50%的文本prompt替换成空字符串。这个技巧能让ControlNet学会直接从条件图里识别语义信息,哪怕没有任何文本prompt,也能根据输入的边缘图、姿势图生成合理的图片,大幅提升了模型的鲁棒性。
- 突然收敛现象:因为零卷积的存在,训练全程模型都能生成高质量的图片,绝不会出现训崩的情况。而且模型不是慢慢学会控制条件,而是在某个训练步数(通常不到10000步)突然就完美学会了跟随输入条件,论文把这个现象命名为「sudden convergence phenomenon(突然收敛现象)」。
突然收敛现象可视化
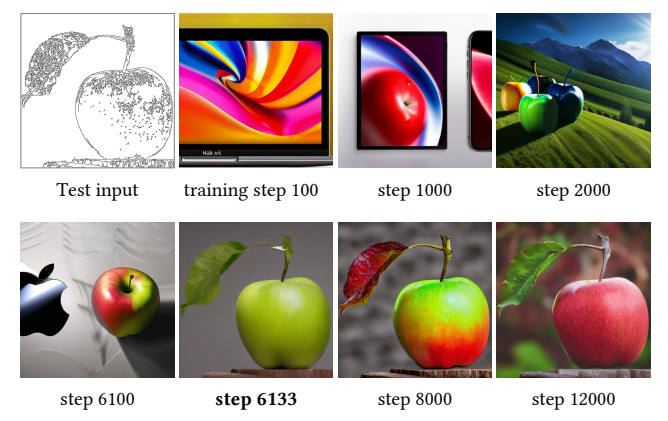
图片3 突然收敛现象可视化(出处:论文原文Figure 4)
图片分析:
- 训练步数100、1000、2000时,模型还完全没有跟随输入的边缘条件,生成的画面和输入的房子轮廓毫无关系,但画面质量依旧很高,没有出现训崩的情况;
- 到了6133步,模型突然就完美贴合了输入的边缘图,生成的房子轮廓和输入完全一致;
- 后续8000、12000步,生成的细节越来越丰富,控制效果也越来越稳定。
3.4 推理阶段的核心优化技巧
CFG分辨率加权(CFG Resolution Weighting)
玩过SD的朋友都知道,CFG(Classifier-Free Guidance)是控制生成图贴合prompt程度的核心参数,原生CFG的公式如下:
ϵ p r d = ϵ u c + β c f g ( ϵ c − ϵ u c ) \epsilon_{prd}=\epsilon_{uc}+\beta_{cfg}(\epsilon_{c}-\epsilon_{uc}) ϵprd=ϵuc+βcfg(ϵc−ϵuc)
每个符号的解释:
| 符号 | 通俗解释 |
|---|---|
| ϵ p r d \epsilon_{prd} ϵprd | 模型最终输出的预测噪声,用来做去噪生成 |
| ϵ u c \epsilon_{uc} ϵuc | 无条件输出,也就是prompt为空时模型预测的噪声 |
| ϵ c \epsilon_c ϵc | 条件输出,也就是有文本prompt和ControlNet条件时模型预测的噪声 |
| β c f g \beta_{cfg} βcfg | CFG权重,用户可调节,值越大,生成图越贴合prompt和条件,但也越容易失真 |
ControlNet在推理时,会遇到一个CFG的矛盾问题:
- 如果把ControlNet的条件同时加到 ϵ u c \epsilon_{uc} ϵuc和 ϵ c \epsilon_c ϵc里,会完全抵消CFG的作用,生成的画面缺乏多样性,细节模糊;
- 如果只把ControlNet的条件加到 ϵ c \epsilon_c ϵc里,又会让CFG的强度过高,生成的画面生硬、有伪影。
论文提出了CFG分辨率加权 的解决方案:给ControlNet和SD之间的每个连接,都乘一个权重 w i = 64 / h i w_i=64/h_i wi=64/hi,其中 h i h_i hi是对应块的特征图尺寸。比如8×8的低分辨率块, w i = 64 / 8 = 8 w_i=64/8=8 wi=64/8=8;16×16的块, w i = 4 w_i=4 wi=4;64×64的高分辨率块, w i = 1 w_i=1 wi=1。
这个方案的核心逻辑是:低分辨率块负责控制整体的结构和布局,给更高的权重;高分辨率块负责控制细节,给更低的权重。这样既保证了整体结构的控制效果,又保留了画面的细节和多样性,完美平衡了CFG的强度。
CFG分辨率加权效果对比

图片4 CFG与CFG分辨率加权的效果对比(出处:论文原文Figure 5)
图片分析:
- (a) 是输入的Canny边缘图,目标是生成对应的房子;
- (b) 是无CFG的结果,整体结构对了,但细节极其模糊,缺乏质感;
- © 是无CFG-RW的结果,结构贴合了,但画面生硬,有明显的伪影和过曝;
- (d) 是加入完整CFG-RW的结果,既完美贴合了输入的边缘轮廓,画面细节又极其丰富,光影和质感都拉满了。
多ControlNet组合
如果想同时用多个条件控制生成,比如同时控制人物的姿势和画面的深度,直接把对应ControlNet的输出加在一起就行,不需要额外的加权、插值或者其他复杂操作,简单到离谱。

图片5 多条件组合控制效果(出处:论文原文Figure 6)
图片分析:同时输入了人体姿势和深度图两个条件,不管prompt是「boy」还是「astronaut」,生成的人物都完美贴合了输入的姿势和深度,实现了多维度的精准控制,没有出现任何冲突。
全类型条件支持
ControlNet支持的控制条件极其丰富,包括Canny边缘、Hough直线、用户涂鸦、人体关键点、语义分割图、表面法线图、深度图、卡通线稿等等,哪怕没有任何文本prompt,也能完美识别条件里的语义信息,生成高质量的图片。

图片6 无prompt条件下的多类型控制效果(出处:论文原文Figure 7)
图片分析:第一行是输入的控制条件,包括草图、法线图、深度图、Canny边缘、直线检测、软边缘、分割图、人体姿势,下面所有行都是无prompt生成的结果。可以看到,ControlNet完美识别了每个条件里的语义和结构,生成的画面和输入条件完全贴合,哪怕没有任何文本描述,也能生成合理的高质量图片。
实验验证:效果碾压同期所有方法
论文做了极其全面的实验,从消融实验、用户研究、定量指标对比,到和工业级模型的盲测,全方位验证了ControlNet的优越性。
4.1 消融实验:验证每个组件的核心作用
论文做了两组对照消融实验,来验证零卷积和完整可训练副本的作用:
- 对照组1:把零卷积替换成高斯初始化的标准卷积层;
- 对照组2:把完整的可训练副本,替换成单个卷积层,命名为ControlNet-lite。
同时测试了4种真实用户会遇到的prompt场景:
- 无prompt:prompt为空,完全靠ControlNet控制;
- 不充分prompt:只写了「高质量、细节丰富的专业图片」,没提画面里的物体;
- 冲突prompt:prompt写的是「美味的蛋糕」,和输入的房子草图完全冲突;
- 完美prompt:完整描述了画面内容「一座房子,高质量、4K、超细节」。
消融实验可视化结果

图片7 不同架构的消融实验效果对比(出处:论文原文Figure 8)
图片分析:
- (a) 完整的ControlNet:4种场景全部完美适配,哪怕prompt是冲突的「美味的蛋糕」,也能跟着输入的房子草图生成房子,同时融入蛋糕的风格,控制能力拉满;
- (b) 去掉零卷积的版本:效果直接崩了,生成的画面和输入条件完全不贴合,说明零卷积确实保护了预训练骨干网络不被破坏,去掉之后模型直接学废了;
- © ControlNet-lite轻量化版本:能力严重不足,无prompt和不充分prompt的场景直接失效,说明完整的可训练副本,是保证ControlNet复杂控制能力的核心。
4.2 定量评估:全指标碾压基线方法
用户偏好打分
论文邀请了12位用户,对20组 unseen 的手绘草图生成结果,从「画面质量」和「条件贴合度」两个维度打分,1分最差,5分最好,平均打分结果如下:
表格1 不同方法的用户平均打分(出处:论文原文Table 1)
| Method | Result Quality ↑ | Condition Fidelity ↑ |
|---|---|---|
| PITI 89 | 1.10 ± 0.05 | 1.02 ± 0.01 |
| Sketch-Guided 88 (β=1.6) | 3.21 ± 0.62 | 2.31 ± 0.57 |
| Sketch-Guided 88 (β=3.2) | 2.52 ± 0.44 | 3.28 ± 0.72 |
| ControlNet-lite | 3.93 ± 0.59 | 4.09 ± 0.46 |
| ControlNet | 4.22 ± 0.43 | 4.28 ± 0.45 |
表格分析:完整的ControlNet在「画面质量」和「条件贴合度」两个维度,都拿到了全场最高分,远超同期的所有基线方法。哪怕是轻量化的ControlNet-lite,也比之前的Sketch-Guided方法表现更好,充分证明了ControlNet架构的优越性。
分割条件重建精度
论文用ADE20K分割数据集,测试了不同方法对分割条件的还原能力,用IoU(交并比)衡量,IoU越高,代表生成的图和输入分割图的贴合度越高,结果如下:
表格2 语义分割标签重建IoU结果(出处:论文原文Table 2)
| ADE20K (GT) | VQGAN 19 | LDM 72 | PITI 89 | ControlNet-lite | ControlNet |
|---|---|---|---|---|---|
| 0.58 ± 0.10 | 0.21 ± 0.15 | 0.31 ± 0.09 | 0.26 ± 0.16 | 0.32 ± 0.12 | 0.35 ± 0.14 |
表格分析:ControlNet的IoU达到了0.35,远超VQGAN、LDM、PITI这些基线方法,说明ControlNet对分割条件的还原能力,是所有方法里最强的。
生成质量与文本贴合度
论文用FID、CLIP分数、CLIP美学分数,全面评估了生成图的质量,其中:
- FID:弗雷歇 inception距离,越低代表生成图和真实图的分布越接近,质量越高;
- CLIP-score:越高代表生成图和文本prompt的贴合度越好;
- CLIP-aes.:越高代表生成图的美学质量越好。
表格3 分割条件生成的全指标对比(出处:论文原文Table 3)
| Method | FID ↓ | CLIP-score ↑ | CLIP-aes. ↑ |
|---|---|---|---|
| Stable Diffusion | 6.09 | 0.26 | 6.32 |
| VQGAN 19* | 26.28 | 0.17 | 5.14 |
| LDM 72* | 25.35 | 0.18 | 5.15 |
| PITI 89 | 19.74 | 0.20 | 5.77 |
| ControlNet-lite | 17.92 | 0.26 | 6.30 |
| ControlNet | 15.27 | 0.26 | 6.31 |
表格分析:
- ControlNet的FID只有15.27,是所有方法里最低的,说明生成的画面质量远超其他基线方法;
- ControlNet的CLIP分数和原生Stable Diffusion完全持平,美学分数也几乎和原生SD一致,说明ControlNet在给SD加上超强控制能力的同时,完全没有损失SD原本的生成质量和文本贴合能力,完美解决了「加控制就丢质量」的行业难题。
与工业级模型的盲测对比
Stable Diffusion V2的Depth-to-Image模型,是用NVIDIA A100大集群、数千小时GPU算力、1200万+训练图片训出来的工业级模型。而ControlNet只用了20万训练样本、单张RTX 3090Ti消费级显卡、5天的训练时间,就达到了几乎一样的效果。
论文做了用户盲测:先用100张图让用户学会区分两个模型的生成结果,再用200张图让用户判断每张图是哪个模型生成的。最终用户的平均判断准确率只有0.52±0.17,和瞎猜的50%几乎没有区别。通俗说就是,单卡3090训出来的ControlNet,效果和大厂用集群训出来的工业级模型,人眼根本分不出来。
4.3 与同期方法的可视化对比
论文把ControlNet和同期的PITI、Sketch-Guided、Taming Transformers等方法做了可视化对比,结果如下:

图片8 与同期方法的效果对比(出处:论文原文Figure 9)
图片分析:可以清晰看到,其他方法生成的画面,要么和输入的草图、分割图、边缘图完全不贴合,要么细节模糊、结构崩坏;而ControlNet生成的画面,既完美贴合了输入的控制条件,细节又极其丰富清晰,效果直接碾压了同期的所有方法。
4.4 拓展性与兼容性验证
数据集大小的鲁棒性
论文测试了不同训练数据集大小对ControlNet的影响,结果如下:

图片9 不同训练数据集大小的效果对比(出处:论文原文Figure 10)
图片分析:哪怕只有1000张训练图片,ControlNet也不会训崩,能生成可识别的狮子;5万张图片训练的模型,效果已经非常出色;300万张图片训练的模型,效果直接拉满。这说明ControlNet对小数据集极其友好,不会出现过拟合,可扩展性极强。
社区模型迁移能力
因为ControlNet完全没有修改Stable Diffusion的原生网络结构,所以训好的ControlNet可以直接迁移到各种社区微调的SD模型上,比如Comic Diffusion、Protogen 3.4,不需要重新训练。

图片10 社区模型迁移效果(出处:论文原文Figure 12)
图片分析:同一个预训练ControlNet,在原生SD1.5、Comic Diffusion、Protogen 3.4上都能完美生效,生成的房子既完全贴合了控制条件,又保留了对应模型的独特风格,兼容性直接拉满。
核心代码实现
下面我们用PyTorch实现ControlNet的核心模块,包括零卷积层、ControlNet基本块、条件编码器,完全对齐论文里的架构设计。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# -------------------------- 核心:零卷积层 --------------------------
class ZeroConv2d(nn.Module):
"""
零卷积层:1×1卷积,权重和偏置全部初始化为0
对应论文里的Z(·)零卷积运算
"""
def __init__(self, in_channels, out_channels):
super().__init__()
# 1×1卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0)
# 权重和偏置全部初始化为0
nn.init.zeros_(self.conv.weight)
nn.init.zeros_(self.conv.bias)
def forward(self, x):
return self.conv(x)
# -------------------------- ControlNet基本块 --------------------------
class ControlNetBlock(nn.Module):
"""
ControlNet基本单元,对应论文3.1节的结构
包含锁定的原神经块、可训练副本、两个零卷积层
"""
def __init__(self, original_block, in_channels, condition_channels):
super().__init__()
# 锁定的原预训练神经块,完全冻结参数
self.original_block = original_block
for param in self.original_block.parameters():
param.requires_grad = False
# 可训练的副本,和原块结构完全一致,初始参数相同
self.trainable_copy = type(original_block)(**original_block.get_config())
self.trainable_copy.load_state_dict(original_block.state_dict())
# 两个零卷积层
self.zero_conv1 = ZeroConv2d(condition_channels, in_channels)
self.zero_conv2 = ZeroConv2d(in_channels, in_channels)
def forward(self, x, condition):
# 锁定的原块前向传播,输出完全和原生模型一致
original_out = self.original_block(x)
# 控制条件经过第一个零卷积,和输入特征融合
condition_feat = self.zero_conv1(condition)
copy_input = x + condition_feat
# 可训练副本前向传播
copy_out = self.trainable_copy(copy_input)
# 副本输出经过第二个零卷积,和原块输出融合
control_out = self.zero_conv2(copy_out)
final_out = original_out + control_out
return final_out
# -------------------------- 条件编码网络 --------------------------
class ConditionEncoder(nn.Module):
"""
条件编码网络,对应论文3.2节的E(·)
把512×512的像素级条件图,编码成64×64的隐空间特征
"""
def __init__(self, in_channels=3, out_channels=320):
super().__init__()
# 4层卷积,卷积核4×4,步长2×2,ReLU激活
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels, 16, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
# 最终对齐SD隐空间的通道数
nn.Conv2d(128, out_channels, kernel_size=1)
)
def forward(self, condition_img):
# 输入:[B, 3, 512, 512] 条件图
# 输出:[B, 320, 64, 64] 隐空间条件特征
return self.conv_layers(condition_img)
# -------------------------- 完整ControlNet核心逻辑 --------------------------
class ControlNet(nn.Module):
"""
完整的ControlNet实现,对接Stable Diffusion的U-Net编码器
"""
def __init__(self, sd_unet, condition_in_channels=3):
super().__init__()
self.sd_unet = sd_unet
# 冻结整个SD U-Net的参数
for param in self.sd_unet.parameters():
param.requires_grad = False
# 条件编码器
self.condition_encoder = ConditionEncoder(
in_channels=condition_in_channels,
out_channels=sd_unet.config.in_channels
)
# 克隆SD U-Net的编码器和中间块,构建可训练副本
self.down_blocks_copy = nn.ModuleList()
self.mid_block_copy = type(sd_unet.mid_block)(**sd_unet.mid_block.get_config())
self.mid_block_copy.load_state_dict(sd_unet.mid_block.state_dict())
# 克隆每个下采样块
for down_block in sd_unet.down_blocks:
copy_block = type(down_block)(**down_block.get_config())
copy_block.load_state_dict(down_block.state_dict())
self.down_blocks_copy.append(copy_block)
# 零卷积层,用于输出控制特征到SD U-Net的跳跃连接
self.zero_convs_down = nn.ModuleList([
ZeroConv2d(block.out_channels, block.out_channels)
for block in self.down_blocks_copy
])
self.zero_conv_mid = ZeroConv2d(
self.mid_block_copy.out_channels,
self.mid_block_copy.out_channels
)
def forward(self, latent, timestep, text_emb, condition_img):
# 1. 编码条件图
condition_feat = self.condition_encoder(condition_img)
# 2. SD U-Net的时间步和文本编码
t_emb = self.sd_unet.time_proj(timestep)
t_emb = self.sd_unet.time_embedding(t_emb)
# 3. ControlNet可训练副本的前向传播
x = latent + condition_feat
down_block_res_samples = []
# 下采样块前向
for down_block in self.down_blocks_copy:
x = down_block(x, t_emb, text_emb)
down_block_res_samples.append(x)
# 中间块前向
mid_out = self.mid_block_copy(x, t_emb, text_emb)
# 4. 零卷积处理控制特征,输出到SD U-Net
control_down_res = [
zero_conv(res)
for zero_conv, res in zip(self.zero_convs_down, down_block_res_samples)
]
control_mid = self.zero_conv_mid(mid_out)
return control_down_res, control_mid结论
ControlNet的出现,彻底改写了文生图扩散模型的控制范式,它的核心贡献可以总结为三点:
- 提出了一种全新的神经网络架构,能为预训练的文生图扩散模型,高效地添加空间条件控制能力,同时完全保留原模型的生成质量,彻底解决了微调过程中的灾难性遗忘问题;
- 开源了覆盖边缘、深度、姿势、分割、涂鸦等十几种场景的预训练ControlNet,单张消费级显卡就能完成训练和推理,把工业级的控制能力带到了普通用户手中;
- 通过全面的消融实验、用户研究和定量对比,充分验证了方法的有效性,效果碾压了同期所有的基线方法,也为后续扩散模型的控制研究奠定了核心基础。
直到今天,ControlNet依旧是AI绘图领域里最核心、使用最广泛的控制工具,从专业的影视概念设计、工业绘图,到普通用户的日常创作,都能看到它的身影。而它最天才的零卷积设计,也为大模型的轻量化微调、能力拓展,提供了一个全新的、极具启发性的思路。