一 背景
随着AI技术的快速发展,对GPU的需求也日益增加;但是,在实际生产环境中,受限于业务的模型特点及SLA等,GPU利用率普遍比较低,硬件算力被严重浪费。在这种情况下,GPU隔离能力对于最大化利用硬件资源就至关重要,本文基于NVIDIA场景,通过分析阐述业内隔离技术方案,引出他们的优势与缺陷,进而提出B站在隔离技术上的改进思路。
二 隔离思路
2.1 两种维度
如图1所示,假设有A、B、C这3个不同模型大小的任务在GPU上混跑。在空间维度上,一次调度上GPU运行的任务,并不能充分利用全部的GPU资源,GPU资源的饱和度利用不高。在时间维度上,多个任务之间交替运行,存在切换和等待开销,所以在实际使用时,为了保障业务的SLA,对于延迟敏感的高优业务就需要独占GPU资源,GPU利用率就会比较低下。
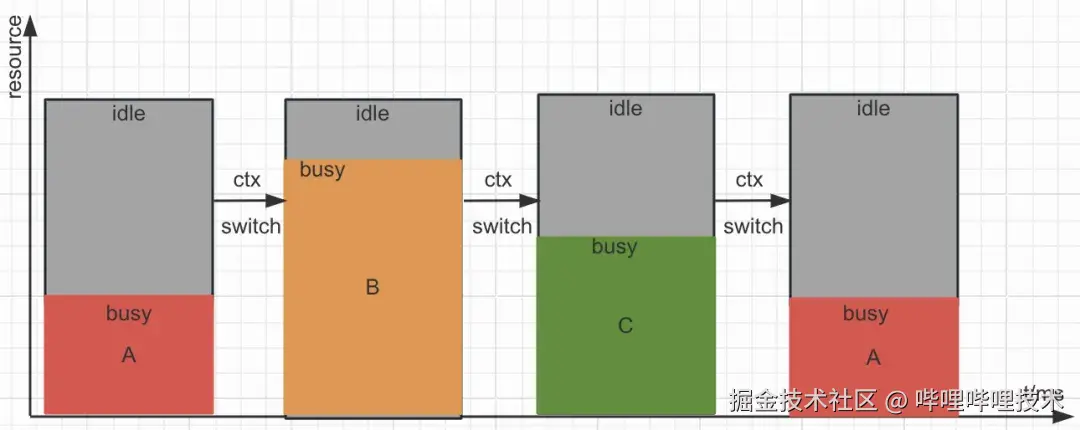
图1 GPU运行示意图
为提升 GPU 资源利用率,可以从空间和时间两个维度切分GPU算力资源来实现多任务的高效并行与资源复用。
在空间维度上切分算力,即空分方案,该方案着眼于在GPU资源核心的极致挖掘,通过实现多个任务并行运行,目的是充分利用图1中的idle部分的算力,提升GPU资源的饱和度利用。这种方案往往由硬件厂商实现,通常为各种虚拟化方案,这类切分往往是静态的,不同虚设备之间无法共享资源,容易出现资源浪费,并且实现通常是黑盒的,难以根据业务实际需求进行适配。
在时间维度上切分算力,即时分方案,该方案聚焦于任务的时间管理,通过对时间片的拦截,有效地减少任务切换所需要的等待时间,从而保障业务Qos的高标准。由于弹性特质,相对于空分方案,能更好的利用空闲资源,但官方往往不提供这类解决方案,或提供的方案很难产品化,因此,业界通常需要自主开发相应的解决方案。
2.2 CUDA计算软件栈
为了理解下文业界隔离方案是怎么实现的,我们需要先掌握整个资源分配过程中,都会涉及哪些软件栈。
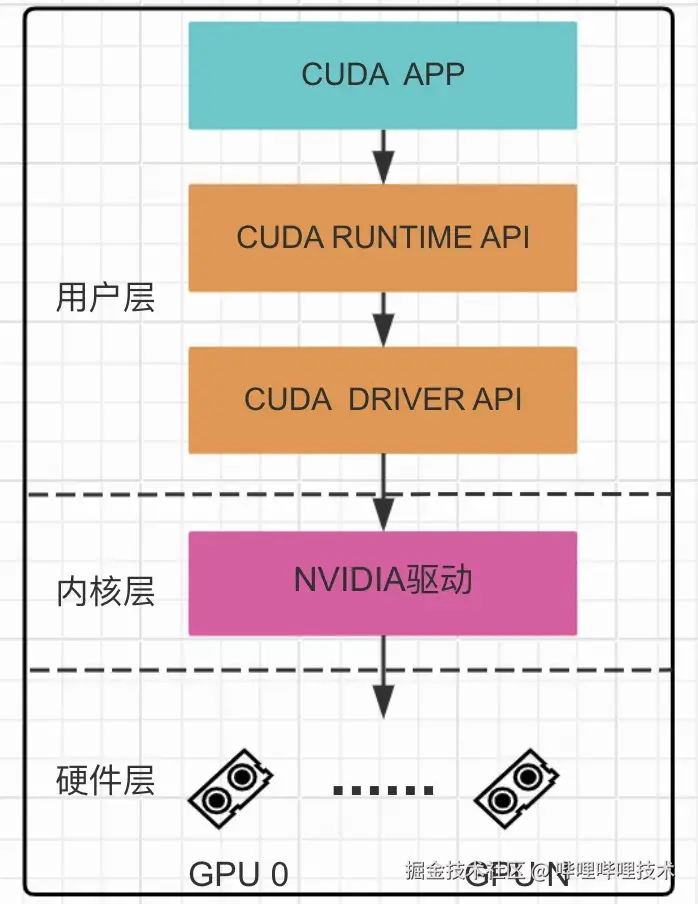
图2 cuda计算软件栈
如图2所示,CUDA计算主要包括以下几个方面:从顶层的应用程序开始,依次经过CUDA库(包括CUDA RUNTIME和CUDA DRIVER层),再到底层的内核驱动,最终到达GPU硬件本身。在此架构中,
- 用户层:包括应用程序和CUDA库,其中CUDA API细分为两个主要层次12:
- CUDA Runtime API: higher-level抽象层,通过cudart动态库提供,其所有入口点都以cuda为前缀,易于使用,为CUDA开发者在编程时提供了便利。
- CUDA Driver API: low-level,通过 cuda 动态库提供,其所有入口点都以 cu 为前缀,提供了更精细的控制,尤其是对上下文和模块加载的控制。
- 内核层:主要就是NVIDIA GPU的驱动程序,负责管理GPU资源,处理与操作系统的交互,并提供基本的硬件抽象;
- 硬件层:主要就是NVIDIA的GPU硬件,它提供了并行处理能力。
从API库到最终的GPU硬件,每一个阶段的转发都有被拦截的可能性,于是,业界基于上述的计算软件栈,实现了各式各样的GPU隔离共享方案。
三 业界方案
目前空分方案主要是NVIDIA提供的MPS和MIG方案,时分方案主要是以CUDA劫持方案和内核拦截方案为主,以下简要介绍下几种方案上的区别。
3.1 NVIDIA官方
NVIDIA提供了一些黑盒逻辑的隔离功能,其中,针对容器共享GPU的技术,以MPS和MIG相对比较常见。
3.1.1 MPS
通常在GPU上执行多个任务时,采用的是"单任务"的工作模式,即同一个时刻只有一个任务(用不同的context区分)在GPU上执行。MPS技术则通过整合多个任务的CUDA context至一个CUDA context,这些任务共享GPU算力,共同使用显存,据此充分利用GPU资源。原理示意如图3所示3:
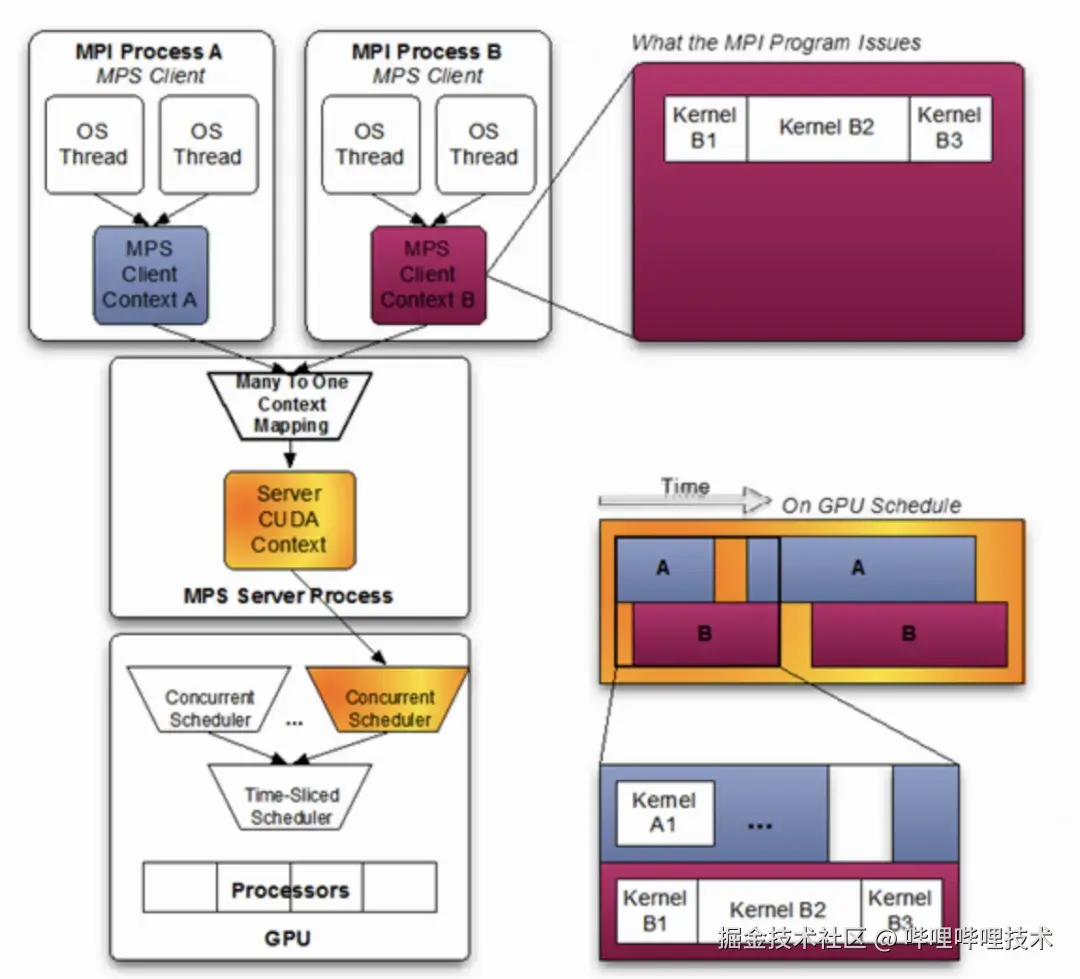
图3 MPS原理示意图
但是,由于是多个任务context的整合,一个任务失败,不免会影响到其他任务,存在故障传播的问题,并且由于是黑盒逻辑,故障诊断也是一个难题。
3.1.2 MIG
自NVIDIA A100系列GPU起,引入了MIG(Multi-Instance GPU)技术,它实现了硬件级别的空间分割复用和隔离。如图4所示4,MIG允许将单个GPU分割成多个独立的实例,每个实例拥有自己的资源配额,从而在硬件层面上实现了资源的隔离。
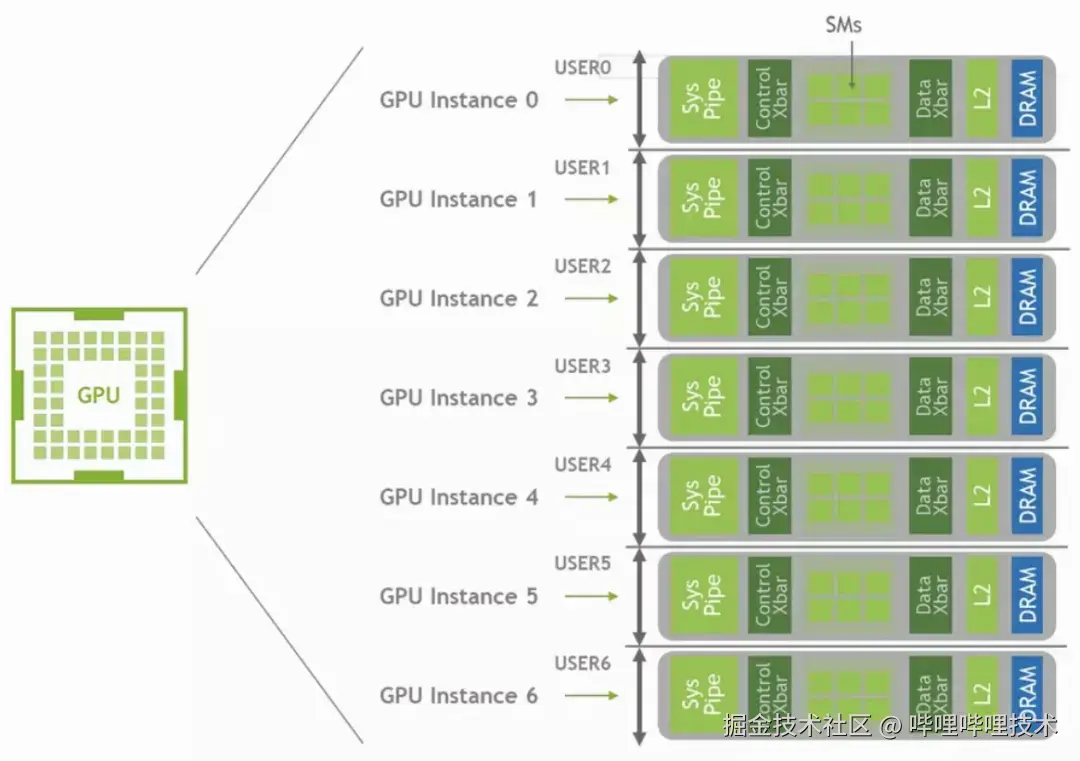
图4 MIG原理示意图
然而,这项技术存在一定的局限性,首先,并非所有型号的GPU都支持这一功能,仅在一些高端的GPU上提供支持;其次,MIG最多仅支持7个独立实例的创建,这限制了MIG在更多实例数量的场景中的应用;并且,GPU资源的切分是静态的,一旦GPU资源被分配给某个任务,就无法在运行时更改这些资源的分配,缺乏灵活性。
3.2 CUDA 劫持
CUDA劫持方案发生在CUDA Runtime和CUDA Driver之间,通过劫持对CUDA Driver API的调用来做到资源隔离,例如,腾讯早期开发的GaiaGPU方案56。这类方案在算力隔离方面,在launch kernel时,会评估这次内核发射对GPU使用率的影响。如果发现该kernel会使得GPU使用率超标,则推迟下发kernel运行的API,直到 GPU 使用率下降至允许本次 CUDA kernel 的运行之后,据此达到算力隔离的目标。
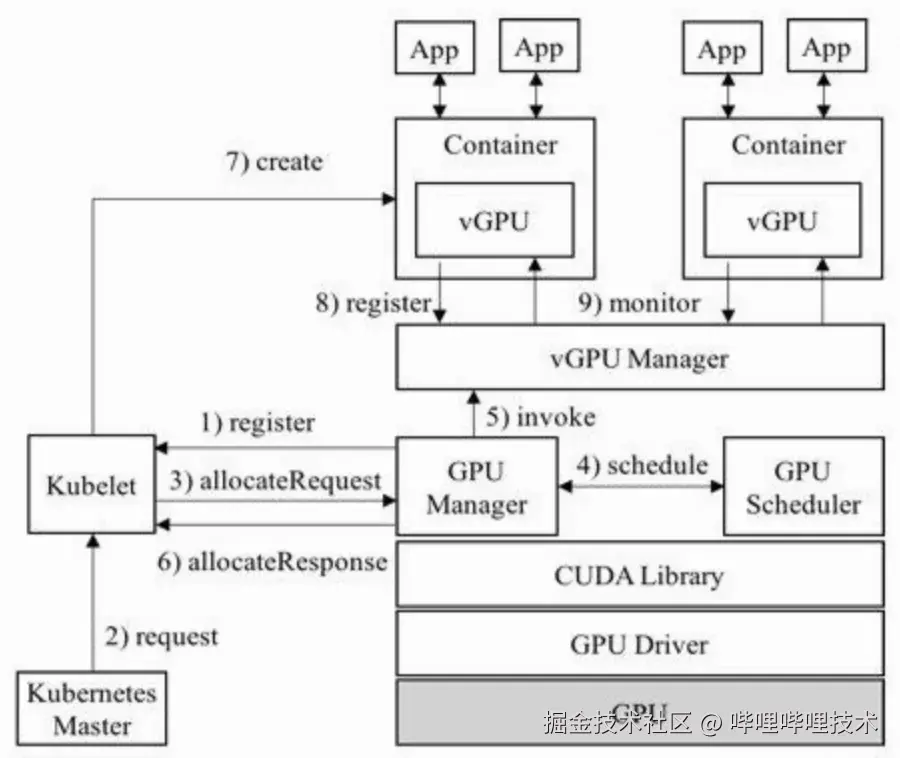
图5 GaiaGPU架构图
由于API的功能是公开的,通过劫持特定调用,可以简单的拒绝或延后任务对于资源的申请行为,但这里存在两个问题,一是算力消耗缺乏反馈机制,依赖轮询造成浪费,二是申请下发后便失去了控制权,容易超算力配额引入误差。
3.3 内核拦截
内核拦截发生在Cuda driver API和Nvidia Driver之间,也是业界比较成熟的方案。不管是腾讯的qGPU2、阿里的cGPU7、还是百度的GPU隔离方案8,在实现上基本是类似的。如图6,以百度的隔离方案为例:
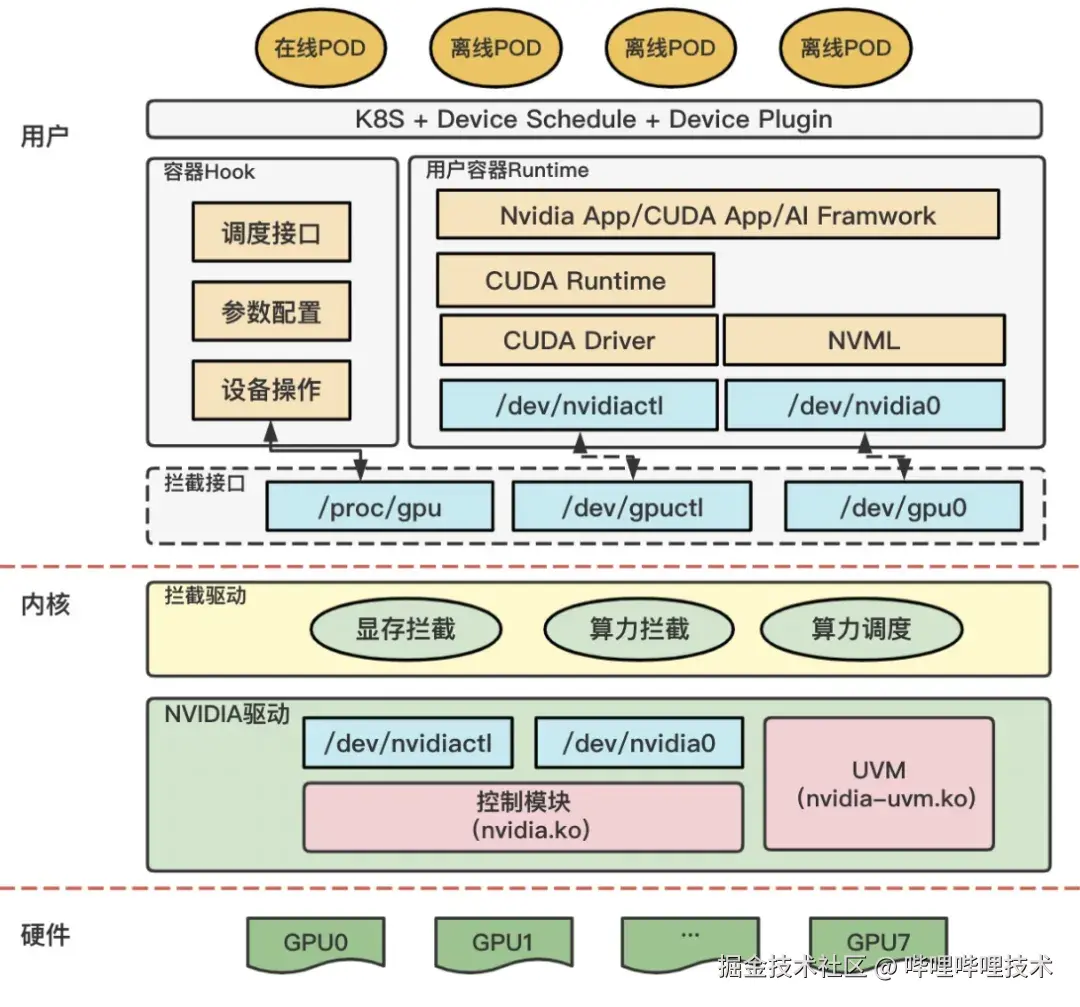
图6 百度双引擎GPU虚拟化内核态原理图
具体拦截设计如下:
- 在没有拦截驱动的时候, 用户程序APP->CUDA RUNTIME->CUDA DRIVER,底层库通过设备文件来访问真实的设备驱动;如图6,是通过GPU驱动的提供的设备如/dev/nvidia0来访问驱动的。
- 做了拦截之后,可以提供假的设备文件(/dev/gpu0)。有了假的设备文件,APP调用时会进入到拦截驱动里,拦截驱动就会把对GPU的访问进行一个拦截,解析信息,然后再把访问发给真实的GPU驱动,GPU处理完之后,再做一次拦截,把信息做解析和修改,注入给APP。
该方案需要深入理解CUDA和GPU之间交互的方式,并对其中的关键参数进行修正,但该交互行为本身是黑盒,版本迭代后还可能会失效,并不易于维护。
四 内核隔离方案
在分析了B站的业务场景后,我们发现具备弹性能力的时分方案最为合适。然而纵观业内,官方没有提供这类手段,非官方的劫持方案又由于黑盒问题,存在各种隐患,一度让我们陷入困境,最终NVIDIA驱动的开源为我们打开了新的思路。
相对于各类劫持,直接在驱动层进行参数和结果的修正,无疑是更加透明和高效的。通过分析驱动代码,结合GPU运行原理知识,我们验证了这条路径是可行的,并基于此设计实现了一套内核隔离方案,完美契合了B站业务场景的需求。
接下来我们将从NVIDIA开源驱动出发,解析GPU运行机制,并和大家分享一下我们内核隔离方案的设计思路。
4.1 驱动视角
根据驱动代码及相关文献101112,我们可以从驱动角度上展示CUDA任务到GPU上运行的详细过程,如图7所示:
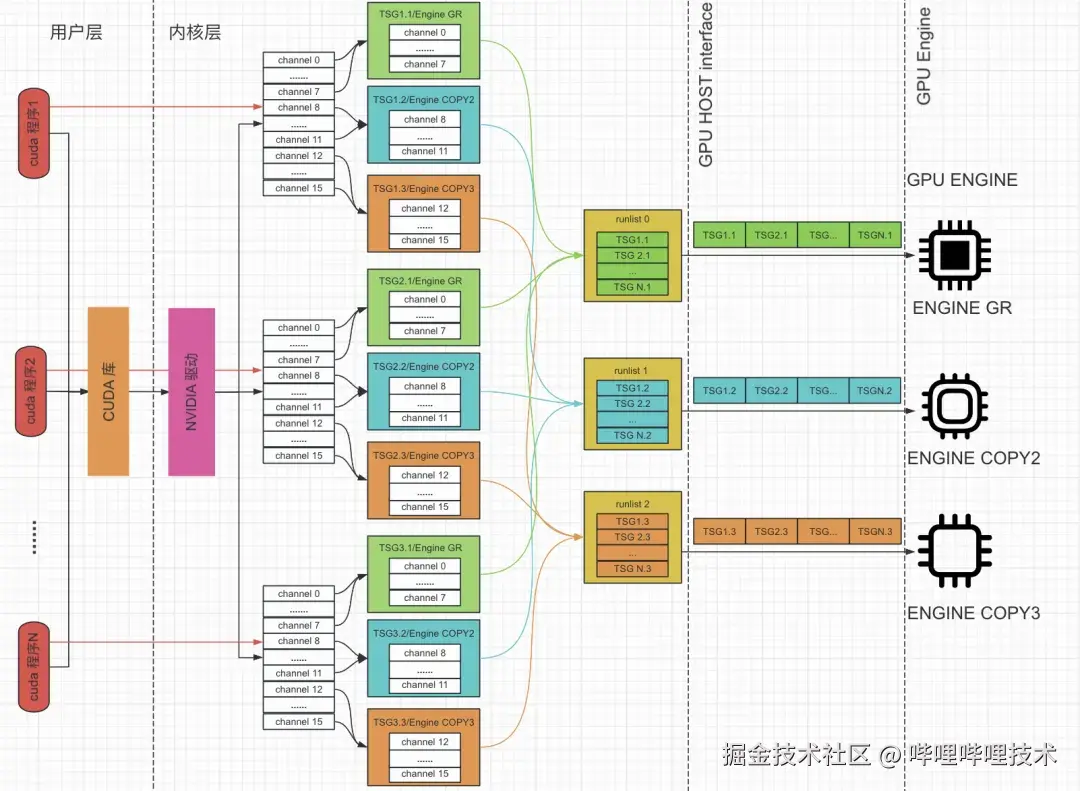
图7 多个GPU程序混跑运行机制
GPU 内部由多个功能单元组成,在驱动中称为 Engine,主要包含:
- Compute/Graphics Engine:包含通用处理核心,负责 CUDA 计算和图形渲染;
- Copy Engine:专门处理 GPU 与 CPU 之间的异步数据拷贝;
- NVENC/NVDEC Engine:用于视频编解码等特定任务等。
GPU Host 是 CPU 与 GPU 之间的桥梁,由 runlist processor 和 context switcher 组成:
- runlist processor 负责扫描 runlist,选择下一个待运行的 channel
- 在选择 channel 后,如果该 channel 的 context 与当前正在运行的 context 不同,就需要 context switcher 执行上下文切换操作。
具体调度流程如下:
-
从驱动角度看,为了向 GPU 提交计算或数据拷贝等请求,会为每个程序创建一个或多个 channels;
-
这些 channels 被组织到 TSG(Time Slice Group) 中,同一 TSG 内的 channels 共享相同的 GPU context 信息;
-
TSG会根据分配的Engine type找到自己的runlist
-
GPU Host 通过读取runlist以查找下游Engine要完成的工作,具体地,GPU HOST识别到有待处理命令的channel,会从相应runlist上按照时间片轮转的方式摘取一个TSG,再从TSG选择相应的channel,将其调度到特定的Engine上运行。
-
Engine 执行 channel 中提交的命令,完成计算或数据拷贝任务。
根据我们在x86_64的A10机器上的trace结果来看,会为一个常见的CUDA程序默认创建共16个channels,3个TSG以及3个runlist。其中,8个计算的channels会被加到一个TSG,这个TSG默认分配Compute/Graphics Engine;8个用于数据拷贝的channels会被分别加到两个TSG中,分别对应两种COPY Engine。A10卡上默认的映射如表1所示:
表1 A10机器CUDA程序映射关系

每种Engine会被绑定到一个runlist,在A10机器上,CUDA程序用到的Engine和runlist的对应关系,通常如表2所示:
表2 A10机器上Engine类型和runlist对应关系

在表2中,Timeslice指代了runlist中每个条目(即TSG)一次调度默认最多可执行的时间。以runlist0上的TSG为例,时间片为2ms,即在不发生抢占的情况下,runlist0上一个TSG调度到Compute/Graphics Engine上,默认最多可运行时间为2ms。这意味着,只有TSG用完了2ms的时间片或者TSG在2ms以内就执行完了,TSG之间才会发生调度切换。
由此可知,在单个GPU上跑混多个任务时,TSG之间的切换以及上下文切换是影响任务延迟的主要因素。
4.2 隔离设计
4.1节主要阐述了驱动在算力资源方面是如何进行管理的,在定位到驱动代码的具体实现后,就可以对下发到设备的显存和算力请求做出调整。我们引入bilibili GPU Manager(以下简称BGM)内核模块来联动Cgoup子系统和显卡驱动实现隔离。
显存隔离的设计原理框图,如图8所示:
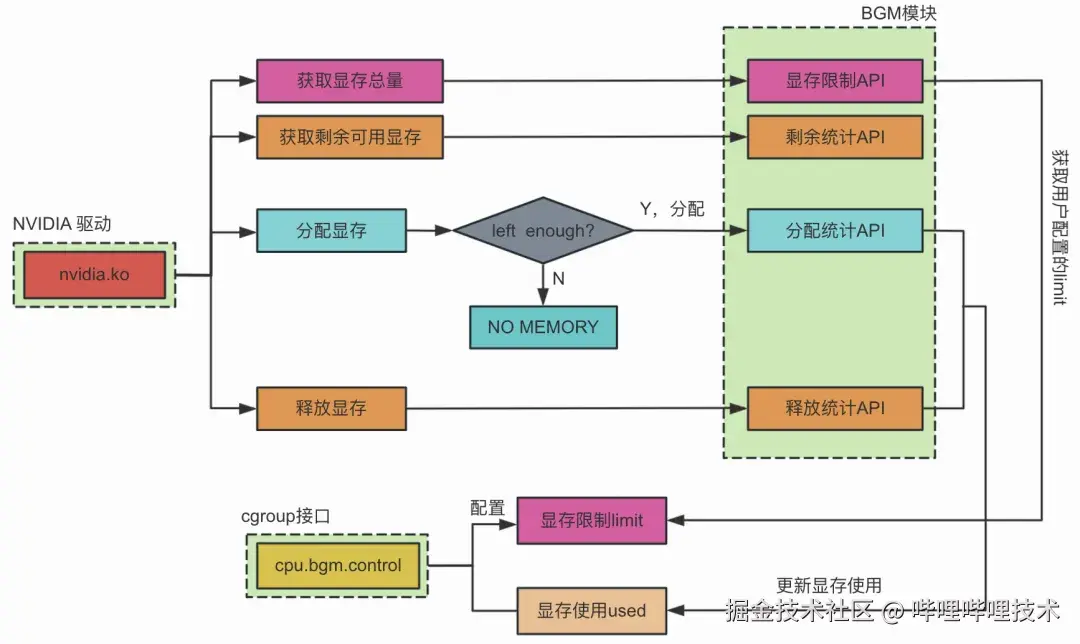
图8 bilibili gpu manager显存隔离设计框图
具体地,显存隔离步骤如下:
1)用户通过cgroup接口配置显存信息,用于限制业务可用的显存上限,记为limit;
2)当驱动在获取设备可用的显存总量信息时,会调用BGM模块的显存限制API获取用户配置的limit,得到一个假的显存总量;
3)在获取设备剩余可用显存信息时,会调用BGM模块显存剩余API,更新limit在不断分配之后的剩余显存量,记为left;
4)在驱动分配显存时,会先判断剩余显存量left是否满足本次分配size要求,满足要求则进行分配,不满足则报NO MEMORY;
5)每次显存的分配和释放,都将通过分配统计和释放统计API计入任务组的显存使用,记为used。
基于此,达到显存隔离以及cgroup统计显存使用的目标。
算力隔离的设计原理框图,如图9所示:
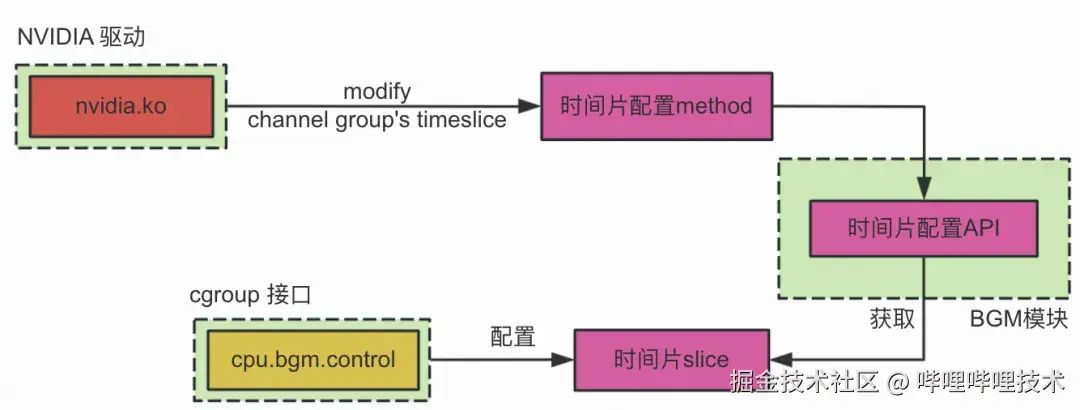
图9 bilibili gpu manager算力隔离设计框图
具体地,算力隔离步骤如下:
-
用户通过cgoup接口中配置算力(slice)信息;
-
CUDA程序运行时,经驱动调用相关方法设置TSG的时间片时,会调用BGM模块的时间片限制API获取用户通过cgoup接口配置的slice,用这个slice替换默认的时间片,作为TSG的时间片;
于是,用户通过配置slice,就可以控制TSG调度上Engine一次可执行的时间片上限,据此达到算力隔离的目的。
举个例子说明本隔离方案在算力隔离方面可以达到的效果,假设存在3种业务在一张GPU卡上混跑,并且业务对应的TSG都能跑满2ms。那么,不同时间片配置下的业务切换示意如图10所示:

图10.1 默认2ms业务切换示意图

图10.2 时间片1ms业务切换示意图

图10.3 不同时间片业务切换示意图
图10 不同时间片配置下应用切换示意图
如图10.1所示,在默认(无算力隔离)情况下混部多个业务,一个任务用完了2ms的时间片,才会切换到另一个任务。计入上下文切换损耗的时间,那么,APP0业务至少要等4ms才能再次被调度执行。如果GPU上混部更多个业务,等待的时间将会更长。
如图10.2所示,同样是均分算力,但是通过隔离手段限制TSG的时间片为1ms,即这些应用一次调度最多可运行1ms,那么,相较于默认情况,APP0业务得到再次调度的等待时长将会减半。
如图10.3所示,不均分算力,通过隔离手段,限制APP0对应TSG时间片为4ms,APP1和APP2的为1ms,即APP0一次调度最多可运行4ms,APP1和APP2最多可运行1ms。通过给高优任务大的时间片,低优任务小的时间片,一方面可以实现让高优任务尽可能在一个时间片完成任务;另一方面,也可以减小高优任务等待切换的时间;这样,可以有效地提升高优任务的性能,并减小受干扰程度。
这样,用户可以根据实际需求合理分配不同业务的时间片,达到切分算力和保障高优的目标。
4.3 效果验证
针对TensorFlow的一个benchmark13,resnet50模型,我们在A10卡上对不同的batchsize,做了如下测试:
- 混跑2pod
算力比为1:3,两个pods的吞吐比如图11所示:
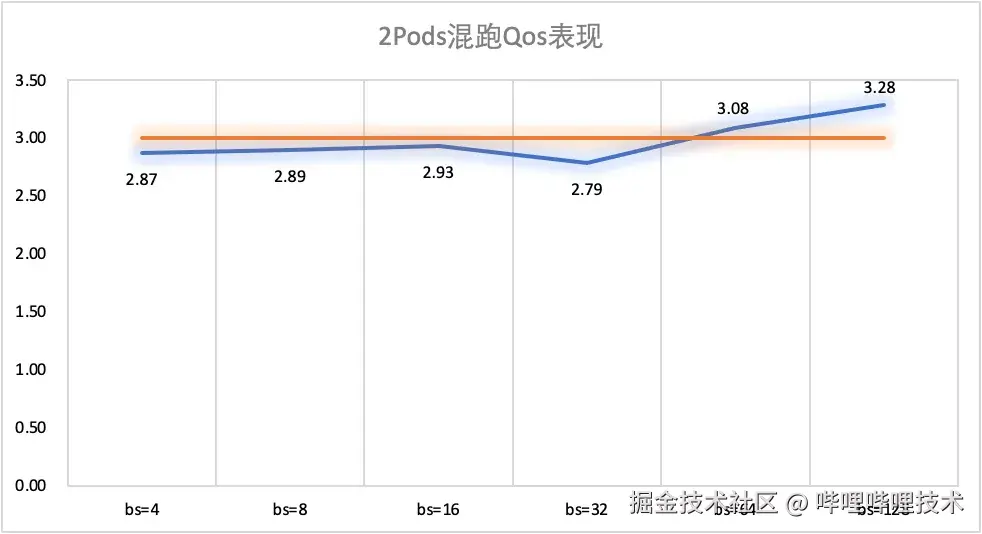
图11 不同算力2pods混跑的Qos表现
- 混跑4pod
算力比为1:2:3:4,不同算力pods的吞吐信息如图12所示:
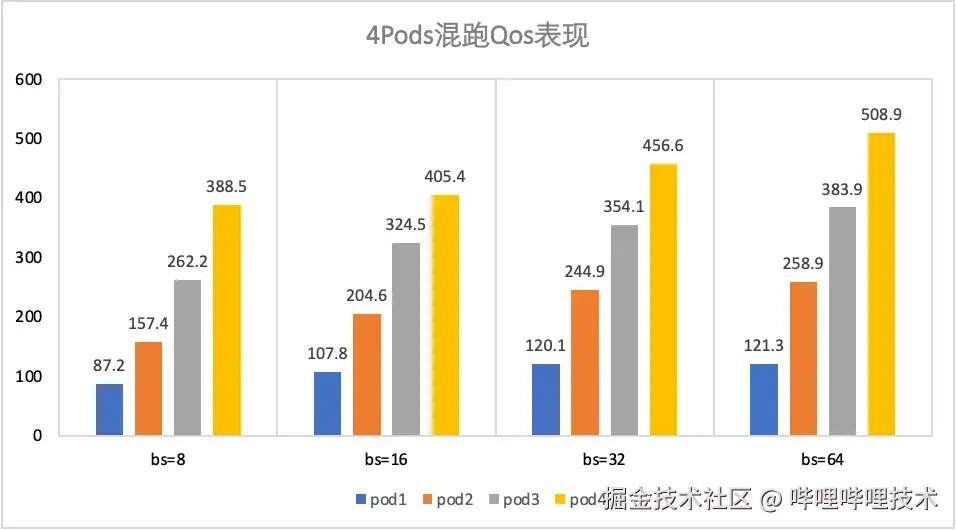
图12 不同算力4pods混跑的Qos表现
如图11和图12所示,配置2个不同算力的pods(1:3)进行混跑,吞吐比在不同batchsize的情况下,基本都在理论值3附近;配置4个不同算力的pods(1:2:3:4)进行混跑,吞吐比在不同batchsize的情况下,表现和算力配置基本一致。
在后面做了平台化适配之后,我们也上实际业务进行了相关验证,总体可以满足GPU混部隔离的需求。
五 总结与展望
本文探讨了NVIDIA GPU结合CUDA计算在实际生产中面临的利用率低下问题,并介绍了一系列基于CUDA软件栈的隔离共享解决方案。特别地,bilibili GPU Manager项目借助NVIDIA驱动开源的优势,通过BGM模块联动Linux内核和NVIDIA驱动,成功实现了算力和显存的精细隔离。通过调整Time Slice Group的时间片配置,可优化多业务场景下的任务等待时间,保障多个业务在GPU上混部的运行性能。
bilibili GPU Manager虽然在内核层实现了隔离,但该方案本质上还是时分复用,高优任务对离线业务的抢占,还是会有所受限,同时不同任务的切换也存在损耗。然而,一方面,随着NV驱动的进一步开放,在抢占模式以及interleave Frequency等细节上可以继续深挖,做到更细致的隔离;另一方面,如果对延迟实在比较敏感,也可以同时在用户态同时做一些调度策略上的调整,做到更好的隔离效果。
通过该项隔离技术,我们希望在GPU混部中能够做到更可控、更灵活的应对不同的业务环境。由于CUDA内部的某些逻辑并不透明,文中阐述不当之处,欢迎业界专家提出宝贵意见和纠正,也请大家继续关注我们的进展~~
六 参考文献
1 CUDA Toolkit Documentation 12.4 Update 1(*docs.nvidia.com/cuda/index....
2 GPU虚拟化,算力隔离,和qGPU - 知乎(*zhuanlan.zhihu.com/p/377073683...
3Multi-Process Service :: GPU Deployment and Management Documentation(*docs.nvidia.com/deploy/mps/...
4docs.nvidia.com/datacenter/...
5 J. Gu, S. Song, Y. Li and H. Luo, "GaiaGPU: Sharing GPUs in Container Clouds," 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), Melbourne, Australia, 2018, pp. 469-476, doi: 10.1109/BDCloud.2018.00077.
6 GitHub - tkestack/vcuda-controller(*github.com/tkestack/vc...
7 GPU容器共享技术cGPU的优势及架构_GPU云服务器(EGS)-阿里云帮助中心(*help.aliyun.com/zh/egs/what...
10 nvidia.github.io/open-gpu-do...
11 J. Bakita and J. H. Anderson. Demystifying NVIDIA GPU Internals to Enable Reliable GPU ManagementJ.
12 S. H. Duncan, L. V. Shah, S. J. Treichler, D. E. Wexler, J. F. Duluk Jr, P. B. Johnson, and J. S. R. Evans, "Concurrent execution of independent streams in multi-channel time slice groups," U.S. Patent 9,442,759, Sep.,2016
13 GitHub - tensorflow/benchmarks: A benchmark framework for Tensorflow(*github.com/tensorflow/...
-End-
作者丨糖冬青