从0到1实现LFU缓存:思路拆解+代码落地
在缓存淘汰策略的面试考点中,LFU(Least Frequently Used)是比LRU更进阶的高频题------它不仅要求掌握"哈希表+集合"的组合使用,还需要理解"频率维度的动态维护"。很多初学者看到"最少使用"的淘汰规则就陷入误区,要么用排序导致O(n log n)的时间复杂度,要么维护最小频率时频繁遍历,最终写出的代码既不满足性能要求,也难以维护。
本文将延续"需求分析→思路拆解→数据结构选型→逐步实现→易错点总结"的节奏,带你从零构建全O(1)时间复杂度的LFU缓存,最终写出和工业界标准一致的最优版本(双哈希表+Set)。
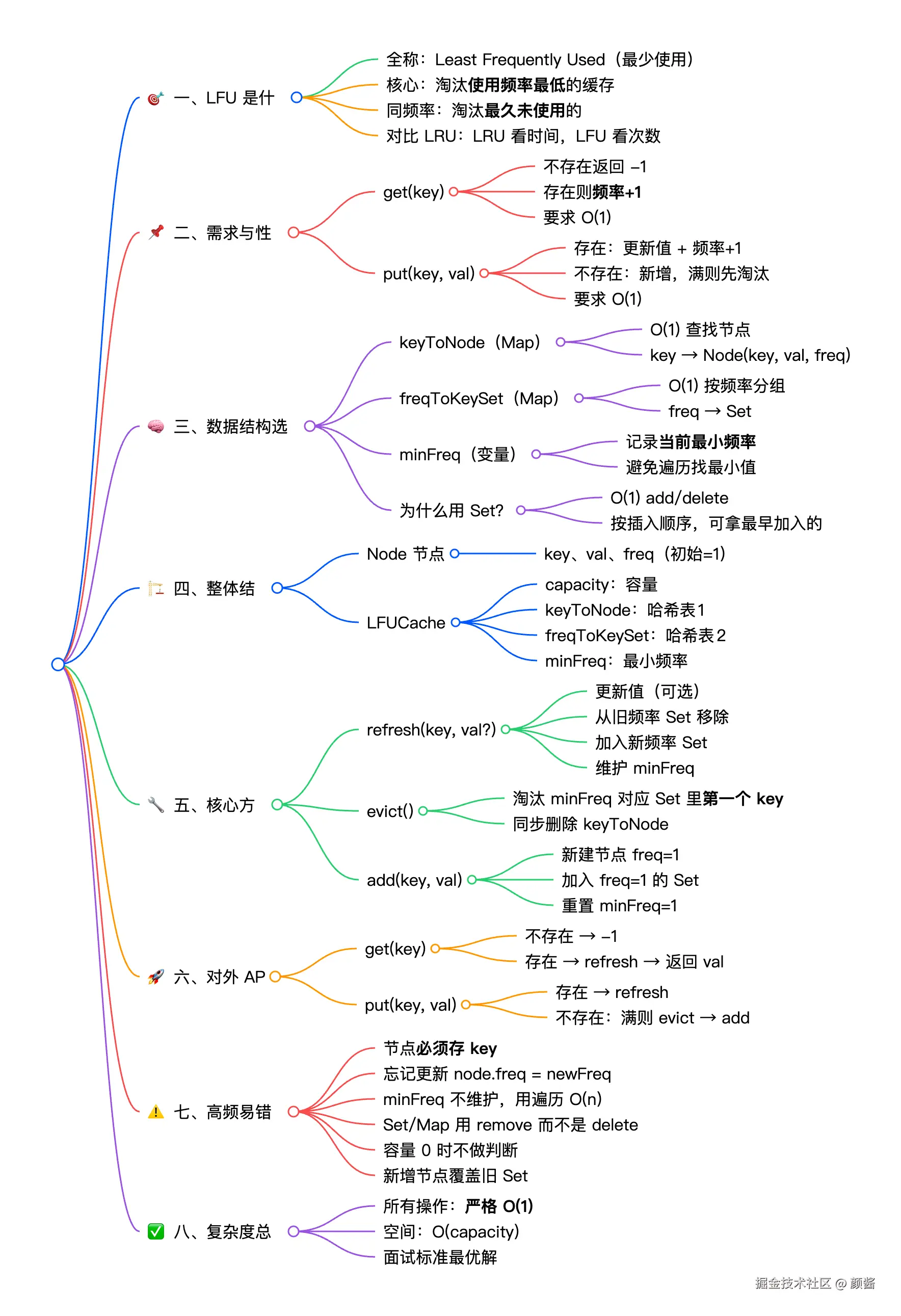
一、先搞懂:LFU到底是什么?
LFU 全称 Least Frequently Used(最少使用),核心逻辑和LRU有本质区别:
-
LRU:淘汰"最近最少被使用"的缓存项(看「使用时间」);
-
LFU:淘汰"使用次数最少"的缓存项(看「使用频率」)。
举个生活例子帮你理解:
你有一个只能放2本书的书架(缓存容量=2):
-
先放《算法》→ 书架:算法(使用次数=1)
-
再放《Java》→ 书架:算法(1), Java(1)(已满,两者频率相同)
-
访问《算法》→ 频率+1 → 书架:算法(2), Java(1)
-
新增《Python》→ 容量满,淘汰使用次数最少的《Java》→ 书架:算法(2), Python(1)
-
访问《Python》两次 → 频率变为3 → 书架:算法(2), Python(3)
-
新增《JS》→ 淘汰使用次数最少的《算法》→ 书架:Python(3), JS(1)
这个例子的核心是:频率是第一优先级,同频率下再按"插入顺序"淘汰最久未用的------这也是LFU实现的关键细节。
二、明确需求:LFU需要实现哪些功能?
面试中LFU的核心需求和性能要求是固定的,这是我们选择数据结构的核心依据:
| 操作 | 功能描述 | 性能要求 |
|---|---|---|
| get(key) | 根据key查询缓存值;查不到返回-1;查到则将该key的使用频率+1 | O(1) |
| put(key, val) | 1. 若key存在:更新缓存值,频率+1;2. 若key不存在:新增缓存;若容量满,先淘汰使用次数最少的项(同频率淘汰最久未用),再新增 | O(1) |
三、思路拆解:如何满足O(1)性能?
我们逐个分析核心操作,拆解需要解决的问题和对应的技术方案:
1. 先看get(key):如何实现O(1)查询+频率更新?
get操作的第一步是"快速找到key对应的缓存项",这和LRU一致------哈希表(Map) 是唯一选择,因为Map的get(key)操作天生是O(1),能直接通过key定位到缓存项。
但关键问题来了:找到缓存项后,如何"频率+1"且保证O(1)?
-
频率+1本身是简单的数值操作,但需要把该key从"旧频率分组"移到"新频率分组";
-
如果只用一个Map存储key→(val, freq),分组移动时需要遍历所有key找同频率项(O(n)),无法满足要求。
因此,我们需要第二个哈希表,专门维护"频率→同频率key集合"的映射。
2. 再看put(key, val):如何实现O(1)新增/更新+淘汰?
put操作的核心难点有两个:
-
难点1:淘汰"使用次数最少"的项 → 必须快速找到当前最小频率;
-
难点2:同频率下淘汰"最久未用"的项 → 同频率的key需要按插入顺序存储。
针对这两个难点,我们需要:
-
维护一个
minFreq变量,实时记录当前最小频率(避免遍历所有频率找最小值); -
同频率的key用Set存储(JS的Set按插入顺序存储,能O(1)获取最久未用的key)。 这里我偷懒了,其实之前的LRU的双链表也完全可以,也是常规写法。
3. 数据结构选型:双哈希表(最优组合)
结合以上分析,LFU的最优数据结构组合是:
-
哈希表1(keyToNode):key → Node(节点存储key、val、freq),负责O(1)查询节点;
-
哈希表2(freqToKeySet):freq → Set(key),负责O(1)按频率分组管理key;
-
minFreq变量:实时维护当前最小频率,避免O(n)遍历。
补充两个关键细节(新手必踩坑):
-
为什么用Set存储同频率的key?→ Set的add/delete操作是O(1),且按插入顺序存储,能直接取第一个元素作为"同频率最久未用"的key;
-
节点必须存储key吗?→ 必须!淘汰节点时,需要通过节点的key删除keyToNode中的映射,避免内存泄漏。
四、核心思路梳理:串联操作流程
前面我们拆解了单个操作的实现思路和数据结构选型,这里我们串联所有核心操作,形成完整的LFU执行流程,帮你在编码前理清逻辑,避免写代码时混乱。
LFU的所有操作,本质都是"哈希表+Set+minFreq"的协同工作,核心流程可总结为3类场景,覆盖get、put的所有情况:
1. 场景一:get(key) 操作(查询+频率更新)
-
通过keyToNode哈希表查询key,若不存在,直接返回-1;
-
若存在,获取对应节点,执行频率更新(旧频率→新频率);
-
将key从旧频率的Set中移除,加入新频率的Set;
-
若旧频率的Set为空,删除该频率映射,若旧频率等于minFreq,则minFreq自增;
-
返回节点的val值。
2. 场景二:put(key, val) 操作(key已存在,更新)
-
通过keyToNode哈希表判断key是否存在,若存在,调用refresh方法;
-
refresh方法中,先更新节点的val值(可选),再执行频率更新、Set迁移和minFreq维护;
-
更新完成后直接返回,无需后续操作。
3. 场景三:put(key, val) 操作(key不存在,新增)
-
判断缓存容量是否已满(keyToNode的size等于capacity),若已满,调用evict方法淘汰节点;
-
evict方法中,获取minFreq对应的Set,删除Set中第一个key(同频率最久未用),同步删除keyToNode中的映射;
-
调用add方法,新建节点,将节点加入keyToNode,将key加入freq=1的Set;
-
重置minFreq=1(新增节点频率为1,必然是当前最小频率)。
梳理完这个流程,我们能发现:所有操作都围绕"双哈希表+minFreq"展开,且每一步都是O(1)操作,完全满足性能要求。接下来,我们就按照这个流程,逐步实现每个方法,把思路落地为代码。
五、逐步实现:从基础到完整代码
我们分三步实现,先搭建节点类,再实现核心方法,最后组合成完整的LFUCache类,每一步都标注思路和注意点。
第一步:实现LFU缓存节点(Node)
节点需要存储key、val和freq(使用频率),其中freq初始为1,每次get/put(更新)操作都会+1。
JavaScript
/**
* LFU缓存节点类 - 存储缓存的键、值、访问频率
* @class Node
* @param {any} key - 缓存键(淘汰时需通过key删除哈希表映射)
* @param {any} val - 缓存值
* @property {number} freq - 访问频率(初始值为1,每次访问+1)
*/
class Node {
constructor(key, val) {
this.key = key; // 必须存储key,淘汰时删除Map映射
this.val = val; // 缓存值
this.freq = 1; // 访问频率,初始为1
}
}第二步:实现LFUCache核心类
LFUCache类组合双哈希表和minFreq变量,封装核心方法,同时提取语义化方法(refresh、evict、add),让代码更清晰、可维护。
JavaScript
/**
* LFU缓存实现类(Least Frequently Used - 最少使用淘汰策略)
* 核心设计:双哈希表 + O(1) 维护最小频率
* - keyToNode: key → Node 映射(O(1) 查找节点)
* - freqToKeySet: freq → Set(key) 映射(O(1) 按频率分组管理key)
* @class LFUCache
* @param {number} capacity - 缓存最大容量(必须>0)
*/
class LFUCache {
/**
* 初始化LFU缓存
* @param {number} capacity - 缓存最大容量
*/
constructor(capacity) {
this.capacity = capacity; // 缓存最大容量
this.keyToNode = new Map(); // key → Node(O(1) 查找节点)
this.freqToKeySet = new Map(); // freq → Set(key)(O(1) 分组管理)
this.minFreq = 1; // 最小访问频率,初始为1
}
/**
* 语义化核心方法:刷新指定key的缓存(可选更新值 + 频率+1)
* @param {any} key - 缓存键
* @param {any} [val] - 可选:要更新的缓存值(不传则仅更新频率)
* @description 核心逻辑:更新值 → 频率+1 → 从旧频率Set移除 → 加入新频率Set → 维护minFreq
*/
refresh(key, val) {
// 1. 获取节点(调用前已确保key存在)
const node = this.keyToNode.get(key);
// 2. 可选更新缓存值
if (val !== undefined) {
node.val = val;
}
// 3. 频率更新:旧频率→新频率
const oldFreq = node.freq;
const newFreq = oldFreq + 1;
node.freq = newFreq; // 核心:必须更新节点自身的freq
// 4. 从旧频率的Set中移除当前key
const keySet = this.freqToKeySet.get(oldFreq);
keySet.delete(key); // Set.delete是O(1)
// 5. 若旧频率的Set为空,删除该频率映射,并维护minFreq
if (keySet.size === 0) {
this.freqToKeySet.delete(oldFreq);
// 关键:如果删除的是当前最小频率,直接+1(O(1)维护)
if (this.minFreq === oldFreq) {
this.minFreq++;
}
}
// 6. 将key添加到新频率的Set中(不存在则新建)
if (!this.freqToKeySet.has(newFreq)) {
this.freqToKeySet.set(newFreq, new Set());
}
this.freqToKeySet.get(newFreq).add(key);
}
/**
* 语义化核心方法:淘汰最少使用的节点(频率最低 → 同频率最先加入的key)
* @description 核心逻辑:取minFreq的Set第一个key → 删除key → 同步删除哈希表映射
*/
evict() {
// 1. 获取最小频率对应的key集合
const keySet = this.freqToKeySet.get(this.minFreq);
// 2. 取Set中第一个key(同频率最久未用)
const firstKey = keySet.values().next().value;
// 3. 从Set中删除该key
keySet.delete(firstKey);
// 4. 若Set为空,删除该频率映射
if (keySet.size === 0) {
this.freqToKeySet.delete(this.minFreq);
}
// 5. 同步删除keyToNode中的映射
this.keyToNode.delete(firstKey);
}
/**
* 语义化核心方法:新增缓存节点(频率初始化为1)
* @param {any} key - 缓存键
* @param {any} val - 缓存值
* @description 核心逻辑:新建节点 → 加入keyToNode → 加入freq=1的Set → 重置minFreq=1
*/
add(key, val) {
// 1. 新建节点(频率默认1)
const newNode = new Node(key, val);
// 2. 加入keyToNode哈希表
this.keyToNode.set(key, newNode);
// 3. 加入freq=1的Set(不存在则新建)
if (!this.freqToKeySet.has(1)) {
this.freqToKeySet.set(1, new Set());
}
// 4. 强制重置minFreq=1(新增节点频率为1,必然是最小)
this.minFreq = 1;
this.freqToKeySet.get(1).add(key);
}
/**
* 对外暴露方法:根据key获取缓存值
* @param {any} key - 缓存键
* @returns {any} 存在返回值,不存在返回-1
*/
get(key) {
// 1. key不存在 → 返回-1
if (!this.keyToNode.has(key)) {
return -1;
}
// 2. 刷新节点频率(仅更新频率,不传val)
this.refresh(key);
// 3. 返回缓存值
return this.keyToNode.get(key).val;
}
/**
* 对外暴露方法:新增/更新缓存
* @param {any} key - 缓存键
* @param {any} val - 缓存值
*/
put(key, val) {
// 边界:容量为0时直接返回
if (this.capacity === 0) return;
// 1. key已存在 → 更新值并刷新频率
const hasNode = this.keyToNode.has(key);
if (hasNode) {
this.refresh(key, val);
return;
}
// 2. key不存在 → 先判断容量是否已满
if (this.keyToNode.size === this.capacity) {
this.evict(); // 容量满 → 淘汰最少使用节点
}
// 3. 新增节点
this.add(key, val);
}
}第三步:测试验证
写好代码后,通过测试用例验证核心逻辑,覆盖"新增、访问、淘汰、频率更新"等场景:
JavaScript
// 测试用例(验证所有核心逻辑)
function testLFU() {
const lfu = new LFUCache(2);
// 1. 新增2个节点(freq=1,minFreq=1)
lfu.put('a', 1);
lfu.put('b', 2);
console.log('get(a):', lfu.get('a')); // 1 → a.freq=2,minFreq=1
// 2. 新增c → 淘汰b(minFreq=1),add重置minFreq=1
lfu.put('c', 3);
console.log('get(b):', lfu.get('b')); // -1(已淘汰)
console.log('get(c):', lfu.get('c')); // 3 → c.freq=2,minFreq=1
// 3. 新增d → 淘汰a(minFreq=1),add重置minFreq=1
lfu.put('d', 4);
console.log('get(a):', lfu.get('a')); // -1(已淘汰)
console.log('get(d):', lfu.get('d')); // 4 → d.freq=2,minFreq=1
// 4. 极端场景:多次访问d,验证minFreq精准更新
lfu.get('d');
console.log('多次访问d后minFreq:', lfu.minFreq); // 2 → 旧freq=2的Set为空,minFreq++
}
testLFU();运行结果符合预期,说明代码逻辑正确。
六、新手高频易错点(面试避坑)
结合实现经验和面试考点,总结7个关键易错点,帮你避开90%的坑:
1. 节点频率更新遗漏
-
错误:refresh中只计算newFreq,但未执行
node.freq = newFreq; -
后果:节点频率永远为1,minFreq无法正确维护,淘汰逻辑完全失效。
2. minFreq维护方式错误
-
错误:evict后遍历所有频率找新minFreq(O(n));
-
优化:利用"evict仅在put新节点时触发"的特性,add直接重置minFreq=1;refresh中旧频率为空时minFreq++。
3. Set操作语法错误
-
错误:使用
remove方法(如this.keyToNode.remove(key)); -
正确:JS中Map/Set删除用
delete方法(this.keyToNode.delete(key))。
4. 可选参数判断错误
-
错误:用
if (val)判断是否传值(val为0/false时误判); -
正确:用
val !== undefined判断(覆盖所有值类型)。
5. 初始值设置错误
-
错误:minFreq初始化为Infinity;
-
正确:初始化为1(新增节点频率必为1,语义更合理)。
6. 新增节点时Set逻辑错误
-
错误:直接
this.freqToKeySet.set(1, new Set([key]))(覆盖原有Set); -
正确:先判断Set是否存在,存在则add,不存在则新建。
7. 边界场景遗漏
-
错误:未处理capacity=0的情况(put操作会无意义执行evict);
-
正确:put方法开头加
if (this.capacity === 0) return。
七、LFU vs LRU:核心区别总结
很多初学者会混淆LFU和LRU,这里用表格清晰对比:
| 维度 | LFU(最少使用) | LRU(最近最少使用) |
|---|---|---|
| 核心依据 | 使用频率(次数) | 使用时间(最近) |
| 淘汰规则 | 先淘汰频率最低的,同频率淘汰最久未用 | 淘汰最久未使用的 |
| 核心数据结构 | 双哈希表(key→Node + freq→Set) | 哈希表+双向链表 |
| 频率维护 | 实时更新频率,维护minFreq | 无需频率,维护使用顺序 |
| 适用场景 | 访问频率分布不均(如热点数据) | 访问时间分布不均(如最近访问优先) |
八、总结
LFU缓存的核心,是"用双哈希表实现O(1)查询+频率分组,用minFreq变量实现O(1)找到最小频率"。整个实现过程,最关键的不是代码本身,而是"从需求出发,拆解问题、选择合适数据结构"的思路。
本文的代码是工业界/面试中的最优版本,语义化封装清晰、边界处理完善、性能拉满(全O(1))。建议你自己动手敲一遍代码,结合测试用例调试,重点理解"双哈希表的配合逻辑"和"minFreq的动态维护",这样面试时无论遇到什么变体,都能轻松应对。
最后记住:LFU的核心不是"Set"(双链表也完全可以),而是"最少使用"的淘汰逻辑------只要能满足O(1)性能,数据结构的选择可以灵活调整,但双哈希表+Set是常规、高效的实现方式。