最近在尝试实现一版简洁版本的 OpenClaw,实践了很多用 OpenClaw 直接实现代码生成的工程任务,发现不符合预期,最后经过多轮调试和思考方法论,总结了这篇文章的方法。
代码生成类 Agent 最大的问题从来不是"写不出来",而是写出来的东西很难稳定地跑通 。
尤其在多步任务里:早期一个小错误没被及时发现,后面步骤就会在错误前提上越走越远,最后只能靠人工兜底。
这篇文章整理一种偏工程化的执行方法:Veri-ReActAgent,它并不追求更"聪明"的自省,而是把测试驱动开发(TDD)的约束,插进 ReAct(Reasoning + Acting)的闭环里,让每一步都有可执行的验收。
为什么传统 ReAct 在编码任务里容易失控
ReAct 的经典循环是:思考 → 行动 → 观察。
用于检索、工具调用、对话任务时很有效,但在编码任务里有一个结构性短板:
- 观察不等于验证:很多 Agent 的"观察"只是"文件写入成功""命令执行了",并不等于功能正确。
- 错误传播 :例如
put没有正确更新数据结构,后面的get、淘汰策略、并发控制都会在错误假设上继续推进。 - 环境噪声:缺依赖、运行态污染、状态残留,会让 Agent 把环境问题误判成逻辑问题,反复重试。
用一句话概括:Agent 缺的是客观、可执行、可重复的最小验证。
Veri-ReActAgent 的核心:无验证,不前行
Veri-ReActAgent 的做法很直接:把"写测试"变成每一步的硬门槛。
它把一个任务拆成原子步骤,并为每个步骤绑定一个最小测试脚本(min_test_script)。执行产物必须通过该测试,才允许进入下一步。
关键组件
- 规划智能体(Architect) :把大任务拆解成"步骤 + 验收"。
- 执行智能体(Coder) :只负责实现当前步骤。
- 验证智能体(Verifier) :在隔离环境中运行最小测试,只依据结果给出通过/失败与错误日志。
- 循环控制器(Controller) :驱动流程、做失败分流与计划修剪。
创新 1:把计划写成「任务-验证」对
传统计划往往是"先实现 A,再实现 B",但缺少"怎么证明 A 已经做对了"。
Veri-ReActAgent 要求规划阶段输出结构化条目,每条都包含:
task:要实现什么verification_point:验收点是什么min_test_script:能独立运行的最小测试
示例(以 LRU 缓存为例):
swift
[
{
"id": 1,
"task": "创建 LRUCache 类框架及 __init__ 方法,初始化容量",
"verification_point": "类可被成功实例化",
"min_test_script": "from lru_cache import LRUCache\ncache = LRUCache(2)\nprint('PASS_INIT')"
},
{
"id": 2,
"task": "实现 put(key, value) 方法,将键值对存入缓存字典",
"verification_point": "调用 put 后,缓存字典内容正确更新",
"min_test_script": "from lru_cache import LRUCache\ncache = LRUCache(2)\ncache.put(1, 'a')\nassert cache.cache == {1: 'a'}\nprint('PASS_PUT')"
}
]这里的关键不是"测试写得多完整",而是:每步至少有一个可执行的客观门槛。
创新 2:验证与生成分离,且验证在干净环境中执行
把验证交给独立 Verifier,有两个工程价值:
- 避免自我欺骗:同一个模型既写代码又判对错,容易被"自洽"的幻觉说服。
- 把失败变成可诊断信号:测试失败是明确的日志与堆栈,不是泛泛的"反思"。
验证环境建议隔离(例如 Docker/沙箱/一次性工作目录),以减少:
- 依赖污染
- 缓存/临时文件导致的假通过
- 隐式全局状态导致的偶现问题
创新 3:失败后不是"重试",而是"分类处理 + 动态修剪计划"
Veri-ReActAgent 的失败处理不是简单让 Coder 再写一遍,而是先回答一个问题:失败属于哪一类?
失败分类(常见三类)
- 语法/运行错误 :如
SyntaxError、TypeError、NameError - 逻辑错误 :如
AssertionError(测试期望不满足) - 环境错误 :如
ModuleNotFoundError、系统依赖缺失、权限问题
动态修剪策略
- 逻辑错误:只修当前步骤,直到最小测试通过。
- 环境错误:在当前步骤之前插入"环境准备步骤"(装依赖、写 stub、修 import 路径等),再回到原步骤。
- 计划错误:如果验收点本身不合理(例如验证依赖外部服务但未明确),需要回退到规划侧重写后续条目。
动态修剪的目标是:把修复发生在错误源头,而不是把错误带到下一步。
系统工作流

这套方法适合什么场景
Veri-ReActAgent 更像工程流水线,适用于:
- 任务可拆解:能拆成若干可验收步骤(编码、数据处理、运维脚本等)。
- 每一步能写最小验证:哪怕只是"能 import","能跑通一条 happy path"。
- 对可靠性敏感:例如交付型任务、需要持续集成的项目。
反过来,如果任务本身无法明确验收(纯创意写作、开放式探索),强行 TDD 化会降低效率。
实操建议:把"最小测试"写得更像工程
- 优先写冒烟测试(smoke test) :先保证能跑通,再逐步增加断言。
- 测试脚本要独立:避免依赖外部服务;如果必须依赖,写清楚 mock 或启动方式。
- 一条测试只验证一个点:否则失败原因不清晰,反而增加修复成本。
- 把环境准备显式化:依赖安装、路径配置、数据下载,尽量变成可重复执行的步骤。
局限与下一步
- 测试生成质量 :如果
min_test_script太弱,可能放过错误;太强则会拖慢迭代。 - 隔离环境成本:Docker/沙箱启动有开销,需要做缓存与复用策略。
- 计划颗粒度:步骤太粗,定位困难;太细,管理成本变高。
可预期的演进方向包括:
- 更智能的最小测试生成(覆盖边界条件、随机化、属性测试)
- 经验库(常见失败类型 → 修复策略模板)
- 多验证者交叉评审(同一实现用不同测试角度验证)
总结
ReAct Loop 和 VeriReAct Loop 运行对比:
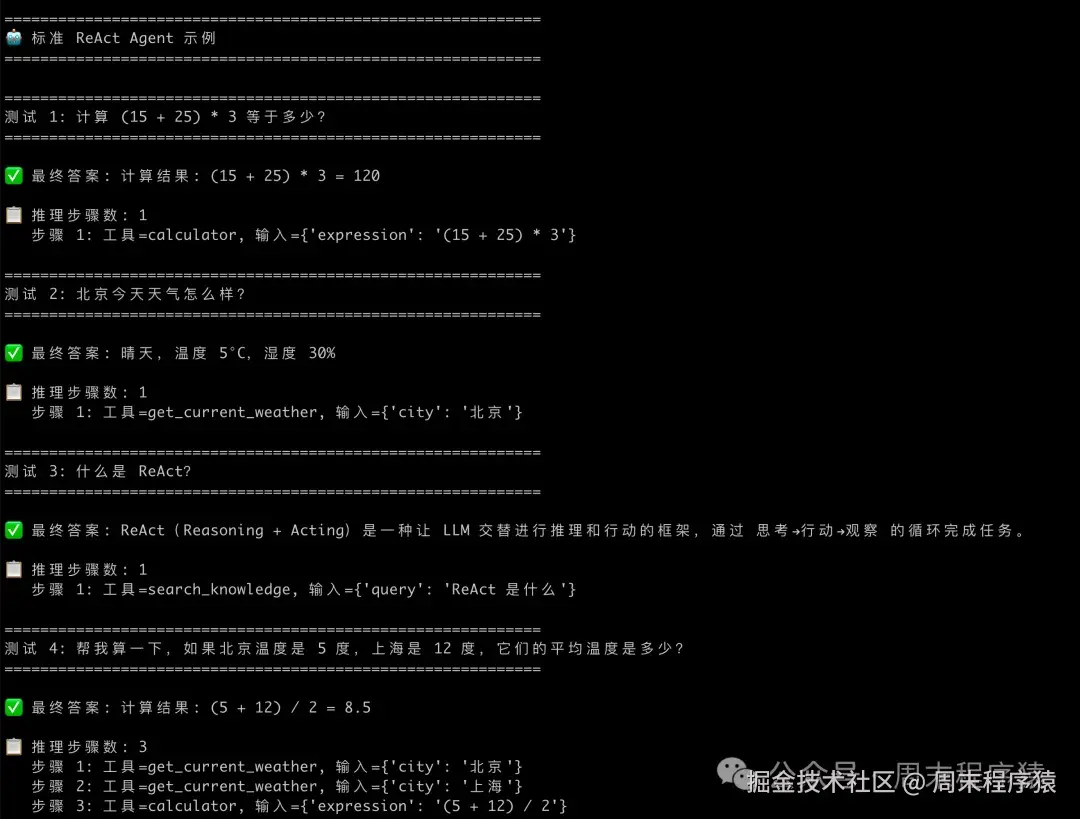
==ReAct Loop ==
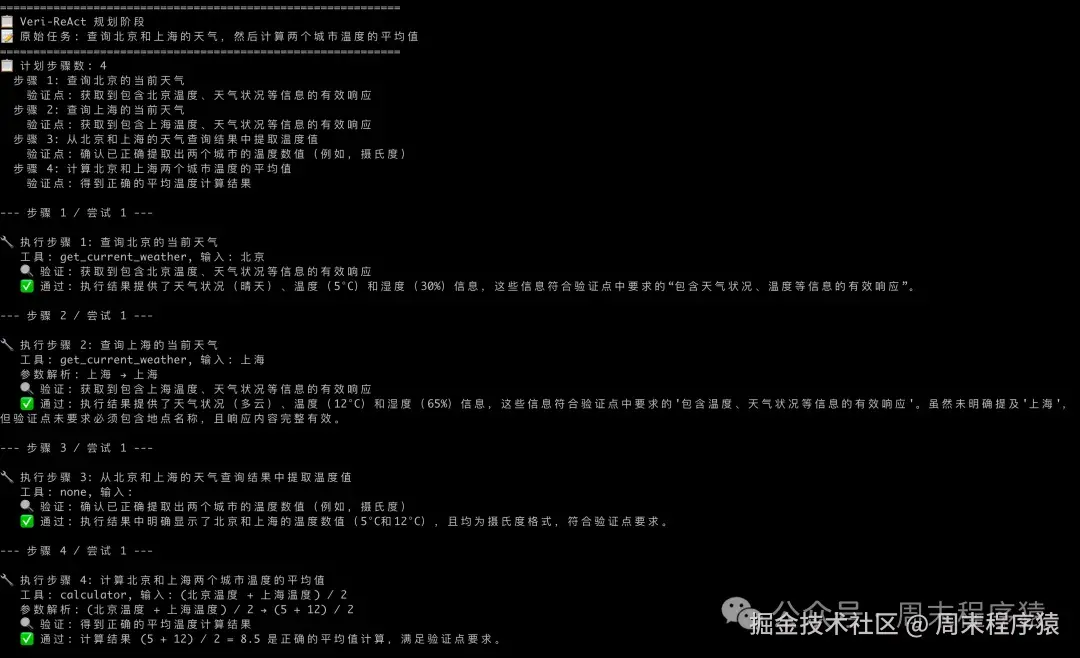
==VeriReAct Loop ==
Veri-ReActAgent 的价值不在于"更会反思",而在于把编码任务从"靠自洽推理"拉回到工程世界:
- 每一步都有可执行的验收
- 验证与生成分离
- 失败后按类型修复,并动态调整计划
最终代码(有兴趣的可以自取,比较费 token,谨慎尝试)
- API 使用硅基流动的,平台地址:cloud.siliconflow.cn/i/RKNWP9gN
python
"""
本文件包含两部分:
1. 标准 ReAct Agent ------ 经典的 思考→行动→观察 循环
2. Veri-ReAct Agent ------ 在每一步加入最小化验证,实现"无验证,不前行"
依赖安装:
pip install langchain langchain-openai
环境变量配置:
export OPENAI_API_BASE="https://api.siliconflow.cn/v1" # API 基础地址
export OPENAI_API_KEY="sk-xxx" # API 密钥
"""
import json
import os
import traceback
from typing import Any, Dict, List, Optional
# 从环境变量读取 API 配置
OPENAI_API_BASE = os.getenv("OPENAI_API_BASE", "")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "")
DEFAULT_MODEL: str = os.getenv("DEFAULT_MODEL", "deepseek-ai/DeepSeek-V3.2")
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_core.tools import tool as langchain_tool
from langchain_core.messages import HumanMessage, SystemMessage
# ============================================
# 第一部分:定义工具(Tools)
# Agent 可以调用的外部函数,用来扩展 LLM 的能力
# ============================================
@langchain_tool
def calculator(expression: str) -> str:
"""
计算数学表达式。
输入应该是一个有效的数学表达式,如 '2 + 2' 或 '3 * (4 + 5)'。
"""
try:
# 限制内置函数,防止任意代码执行
result = eval(expression, {"__builtins__": {}}, {})
returnf"计算结果: {expression} = {result}"
except Exception as e:
returnf"计算错误: {str(e)}"
@langchain_tool
def get_current_weather(city: str) -> str:
"""
获取指定城市的当前天气信息。
输入应该是城市名称,如 '北京' 或 '上海'。
"""
# 模拟天气数据(实际应用中应调用真实的天气API)
weather_data = {
"北京": "晴天,温度 5°C,湿度 30%",
"上海": "多云,温度 12°C,湿度 65%",
"广州": "小雨,温度 18°C,湿度 80%",
"深圳": "晴天,温度 20°C,湿度 70%",
}
return weather_data.get(city, f"抱歉,暂无 {city} 的天气信息")
@langchain_tool
def search_knowledge(query: str) -> str:
"""
搜索知识库获取相关信息。
输入应该是要搜索的问题或关键词。
"""
# 模拟知识库检索
knowledge_base = {
"python": "Python 是一种高级编程语言,以简洁易读著称,广泛应用于数据科学、Web 开发和人工智能领域。",
"agent": "AI Agent(智能体)是能够感知环境、做出决策并采取行动的自主系统,由模型、工具和指令三部分组成。",
"langchain": "LangChain 是一个用于开发 LLM 应用的框架,提供了构建 Agent、链式调用、记忆管理等功能。",
"react": "ReAct(Reasoning + Acting)是一种让 LLM 交替进行推理和行动的框架,通过 思考→行动→观察 的循环完成任务。",
}
for key, value in knowledge_base.items():
if key in query.lower():
return value
returnf"未找到与 '{query}' 相关的信息"
# ============================================
# 第二部分:ReAct 系统提示
# ============================================
REACT_SYSTEM_PROMPT = """你是一个智能助手,能够帮助用户完成各种任务。
重要指导方针:
1. 仔细分析用户的问题,选择最合适的工具
2. 如果问题可以直接回答而无需使用工具,直接回答即可
3. 每一步只调用一个工具,等待观察结果后再决定下一步
4. 回答要准确、简洁、有帮助
5. 如果工具返回的信息不足,可以尝试换一种方式调用或使用其他工具"""
# ============================================
# 第三部分:创建标准 ReAct Agent
# ============================================
def create_react_agent_executor(
model_name: str = DEFAULT_MODEL,
temperature: float = 0,
max_iterations: int = 5,
verbose: bool = True,
):
"""
创建一个标准的 ReAct Agent。
参数:
model_name: 使用的模型名称
temperature: 生成温度,0 表示更确定性的输出
max_iterations: 最大推理循环次数,防止无限循环
verbose: 是否打印详细的推理过程
返回:
CompiledStateGraph 实例,可直接调用 .invoke() 执行任务
"""
# 1. 初始化 LLM
llm = ChatOpenAI(
model=model_name,
temperature=temperature,
base_url=OPENAI_API_BASE,
api_key=OPENAI_API_KEY,
cache=False,
)
# 2. 准备工具列表
tools = [calculator, get_current_weather, search_knowledge]
# 3. 使用 langchain 1.x 的 create_agent 创建 Agent
# create_agent 内部实现了 ReAct 循环:
# 调用 LLM → 如果 LLM 要求调用工具 → 执行工具 → 将结果反馈给 LLM → 循环
agent = create_agent(
model=llm,
tools=tools,
system_prompt=REACT_SYSTEM_PROMPT,
)
return agent
# ============================================
# 第四部分:Veri-ReAct Agent(带验证的 Agent 循环)
# 核心理念:每一步执行后,必须通过验证才能进入下一步
# ============================================
class VeriReActAgent:
"""
Veri-ReAct Agent:在标准 ReAct 循环的基础上,
为每一步绑定一个最小化验证函数。
工作流:
规划 → 对每一步: 执行 → 验证 → (通过则下一步 / 失败则重试或修正)
"""
def __init__(
self,
model_name: str = DEFAULT_MODEL,
temperature: float = 0,
max_retries_per_step: int = 3,
verbose: bool = True,
):
self.llm = ChatOpenAI(
model=model_name,
temperature=temperature,
base_url=OPENAI_API_BASE,
api_key=OPENAI_API_KEY,
cache=False,
)
self.max_retries_per_step = max_retries_per_step
self.verbose = verbose
self.execution_log: List[Dict[str, Any]] = []
def _log(self, message: str):
"""打印日志(verbose 模式下)"""
if self.verbose:
print(message)
asyncdef plan(self, task: str) -> List[Dict[str, Any]]:
"""
规划阶段:让 LLM 把任务分解为带验证点的原子步骤。
返回格式示例:
[
{
"id": 1,
"task": "计算 15 + 25 的结果",
"verification_point": "结果应该等于 40",
"tool": "calculator",
"tool_input": "15 + 25"
},
...
]
"""
self._log(f"\n{'='*60}")
self._log(f"📋 Veri-ReAct 规划阶段")
self._log(f"📝 原始任务: {task}")
self._log(f"{'='*60}")
response = await self.llm.ainvoke([
SystemMessage(content="""你是一个任务规划专家。将用户任务分解为原子步骤。
要求:
1. 每个步骤必须包含明确的验证点
2. 步骤之间有清晰的依赖关系
3. 返回 JSON 数组格式
返回格式(严格 JSON):
[
{
"id": 1,
"task": "步骤描述",
"verification_point": "如何验证这一步的正确性",
"tool": "要使用的工具名",
"tool_input": "工具输入参数"
}
]
可用工具: calculator(数学计算), get_current_weather(天气查询), search_knowledge(知识检索)
如果某步不需要工具,tool 字段填 "none"。"""),
HumanMessage(content=f"请分解任务: {task}"),
])
# 解析 LLM 返回的 JSON 计划
try:
content = response.content
# 尝试提取 JSON 部分(LLM 可能会在 JSON 前后加文字说明)
start = content.find("[")
end = content.rfind("]") + 1
if start != -1and end > start:
plan = json.loads(content[start:end])
else:
plan = json.loads(content)
except json.JSONDecodeError:
self._log("⚠️ 规划输出解析失败,使用默认单步计划")
plan = [{
"id": 1,
"task": task,
"verification_point": "任务完成",
"tool": "none",
"tool_input": "",
}]
self._log(f"📋 计划步骤数: {len(plan)}")
for step in plan:
self._log(f" 步骤 {step['id']}: {step['task']}")
self._log(f" 验证点: {step['verification_point']}")
return plan
asyncdef _resolve_tool_input(
self, step: Dict[str, Any], context: str
) -> str:
"""
根据前序步骤的执行上下文,将 tool_input 中的占位描述
解析为工具可直接执行的实际输入值。
例如:将 "(北京温度 + 上海温度) / 2" 解析为 "(5 + 12) / 2"
"""
raw_input = step.get("tool_input", "")
ifnot context ornot raw_input:
return raw_input
response = await self.llm.ainvoke([
SystemMessage(content="""你是一个参数解析器。根据上下文信息,将工具输入中的描述性文字替换为实际数值。
规则:
1. 只输出替换后的工具输入字符串,不要添加任何解释
2. 对于 calculator 工具,输出必须是纯数学表达式(如 "(5 + 12) / 2"),不能包含中文或变量名
3. 对于其他工具,输出替换后的实际参数值
4. 如果输入本身已经是可执行的,原样输出即可"""),
HumanMessage(content=f"上下文信息:\n{context}\n\n工具: {step.get('tool', 'none')}\n原始输入: {raw_input}\n\n请输出替换后的实际输入值:"),
])
resolved = response.content.strip()
self._log(f" 参数解析: {raw_input} → {resolved}")
return resolved
asyncdef execute_step(
self, step: Dict[str, Any], context: str = ""
) -> Dict[str, Any]:
"""
执行单个步骤:调用工具或让 LLM 直接处理。
返回:
{"success": bool, "output": str, "error": str | None}
"""
tool_name = step.get("tool", "none")
tool_input = step.get("tool_input", "")
self._log(f"\n🔧 执行步骤 {step['id']}: {step['task']}")
self._log(f" 工具: {tool_name}, 输入: {tool_input}")
try:
# 根据工具名分发执行
tool_map = {
"calculator": calculator,
"get_current_weather": get_current_weather,
"search_knowledge": search_knowledge,
}
if tool_name in tool_map:
# 根据上下文解析实际参数(将描述性文字替换为具体数值)
resolved_input = await self._resolve_tool_input(step, context)
result = tool_map[tool_name].invoke(resolved_input)
return {"success": True, "output": str(result), "error": None}
else:
# 无需工具,用 LLM 直接处理
response = await self.llm.ainvoke([
SystemMessage(content="你是一个精确的任务执行者。直接完成以下任务并返回结果。"),
HumanMessage(content=f"上下文信息: {context}\n\n任务: {step['task']}"),
])
return {"success": True, "output": response.content, "error": None}
except Exception as e:
return {"success": False, "output": "", "error": str(e)}
asyncdef verify_step(
self, step: Dict[str, Any], result: Dict[str, Any]
) -> Dict[str, Any]:
"""
验证阶段:检查执行结果是否满足验证点。
用独立的 LLM 调用来判断,避免执行者的"自我欺骗"。
返回:
{"passed": bool, "reason": str, "error_type": str | None}
error_type 可选值: "logic_error" / "env_error" / "plan_error" / None
"""
verification_point = step.get("verification_point", "")
self._log(f" 🔍 验证: {verification_point}")
response = await self.llm.ainvoke([
SystemMessage(content="""你是一个严格的验证审计员。
你的职责是判断执行结果是否满足验证点。
返回 JSON 格式:
{
"passed": true/false,
"reason": "判断理由",
"error_type": null 或 "logic_error" 或 "env_error" 或 "plan_error"
}
判断标准:
- 如果结果明确满足验证点,passed = true
- 如果结果包含错误信息或不满足验证点,passed = false
- error_type:
- logic_error: 逻辑错误(如计算结果不正确)
- env_error: 环境错误(如模块缺失、API 不可用)
- plan_error: 计划错误(验证点本身不合理)"""),
HumanMessage(content=f"""执行结果: {result['output']}
验证点: {verification_point}
是否有错误: {result['error']}
请判断是否通过验证。"""),
])
try:
content = response.content
start = content.find("{")
end = content.rfind("}") + 1
if start != -1and end > start:
verdict = json.loads(content[start:end])
else:
verdict = json.loads(content)
except json.JSONDecodeError:
# 解析失败时保守处理:如果执行本身成功就放行
verdict = {
"passed": result["success"] and result["error"] isNone,
"reason": "验证输出解析失败,根据执行状态判断",
"error_type": Noneif result["success"] else"logic_error",
}
status = "✅ 通过"if verdict.get("passed") else"❌ 未通过"
self._log(f" {status}: {verdict.get('reason', '')}")
return verdict
asyncdef run(self, task: str) -> Dict[str, Any]:
"""
运行完整的 Veri-ReAct 循环:
规划 → 逐步执行 → 每步验证 → 失败则重试/修正 → 汇总结果
"""
self._log(f"\n{'='*60}")
self._log(f"🚀 Veri-ReAct Agent 启动")
self._log(f"{'='*60}")
# 1. 规划
plan = await self.plan(task)
# 2. 逐步执行 + 验证
results = []
context_so_far = ""# 累积上下文,传递给后续步骤
for step in plan:
step_passed = False
for attempt in range(1, self.max_retries_per_step + 1):
self._log(f"\n--- 步骤 {step['id']} / 尝试 {attempt} ---")
# 执行
exec_result = await self.execute_step(step, context=context_so_far)
# 验证
verdict = await self.verify_step(step, exec_result)
# 记录日志
self.execution_log.append({
"step_id": step["id"],
"attempt": attempt,
"task": step["task"],
"output": exec_result["output"],
"passed": verdict.get("passed", False),
"error_type": verdict.get("error_type"),
"reason": verdict.get("reason", ""),
})
if verdict.get("passed"):
step_passed = True
context_so_far += f"\n步骤{step['id']}结果: {exec_result['output']}"
results.append({
"step_id": step["id"],
"task": step["task"],
"output": exec_result["output"],
"attempts": attempt,
})
break
else:
# 失败分类处理
error_type = verdict.get("error_type", "logic_error")
self._log(f" ⚠️ 失败类型: {error_type},准备重试...")
if error_type == "plan_error":
self._log(f" 🔄 计划级错误,跳过此步骤")
break# 计划级错误不重试,直接跳过
ifnot step_passed:
self._log(f" ❌ 步骤 {step['id']} 在 {self.max_retries_per_step} 次尝试后仍未通过")
results.append({
"step_id": step["id"],
"task": step["task"],
"output": f"步骤失败: {verdict.get('reason', '未知原因')}",
"attempts": self.max_retries_per_step,
"failed": True,
})
# 3. 汇总
self._log(f"\n{'='*60}")
self._log(f"📊 执行摘要")
self._log(f"{'='*60}")
total_steps = len(plan)
passed_steps = sum(1for r in results ifnot r.get("failed"))
self._log(f" 总步骤: {total_steps}")
self._log(f" 通过步骤: {passed_steps}")
self._log(f" 失败步骤: {total_steps - passed_steps}")
return {
"task": task,
"total_steps": total_steps,
"passed_steps": passed_steps,
"results": results,
"execution_log": self.execution_log,
}
# ============================================
# 第五部分:运行示例
# ============================================
def run_standard_react():
"""运行标准 ReAct Agent 示例"""
print("\n" + "=" * 60)
print("🤖 标准 ReAct Agent 示例")
print("=" * 60)
agent = create_react_agent_executor(
model_name=DEFAULT_MODEL,
temperature=0,
max_iterations=5,
verbose=True,
)
# 测试用例
test_questions = [
"计算 (15 + 25) * 3 等于多少?",
"北京今天天气怎么样?",
"什么是 ReAct?",
"帮我算一下,如果北京温度是 5 度,上海是 12 度,它们的平均温度是多少?",
]
for i, question in enumerate(test_questions, 1):
print(f"\n{'='*60}")
print(f"测试 {i}: {question}")
print("=" * 60)
try:
# langchain 1.x create_agent 返回的是 CompiledStateGraph
# 输入格式为 {"messages": [HumanMessage(...)]}
result = agent.invoke(
{"messages": [HumanMessage(content=question)]}
)
# 提取最终回复(messages 列表中最后一条 AI 消息)
messages = result.get("messages", [])
final_answer = None
for msg in reversed(messages):
if hasattr(msg, "content") and msg.content andnot hasattr(msg, "tool_calls"):
final_answer = msg.content
break
print(f"\n✅ 最终答案: {final_answer}")
# 打印中间步骤(工具调用信息)
tool_calls = [
msg for msg in messages
if hasattr(msg, "tool_calls") and msg.tool_calls
]
if tool_calls:
print(f"\n📋 推理步骤数: {len(tool_calls)}")
for j, msg in enumerate(tool_calls, 1):
for tc in msg.tool_calls:
print(f" 步骤 {j}: 工具={tc['name']}, 输入={tc['args']}")
except Exception as e:
print(f"❌ 执行出错: {str(e)}")
traceback.print_exc()
asyncdef run_veri_react():
"""运行 Veri-ReAct Agent 示例"""
print("\n" + "=" * 60)
print("🛡️ Veri-ReAct Agent 示例(带验证机制)")
print("=" * 60)
agent = VeriReActAgent(
model_name=DEFAULT_MODEL,
temperature=0,
max_retries_per_step=100,
verbose=True,
)
# 一个需要多步推理的复合任务
task = "查询北京和上海的天气,然后计算两个城市温度的平均值"
result = await agent.run(task)
print(f"\n{'='*60}")
print(f"📊 最终结果")
print(f"{'='*60}")
print(f"任务: {result['task']}")
print(f"步骤通过率: {result['passed_steps']}/{result['total_steps']}")
print(f"\n各步骤结果:")
for r in result["results"]:
status = "❌"if r.get("failed") else"✅"
print(f" {status} 步骤 {r['step_id']}: {r['task']}")
print(f" 输出: {r['output'][:100]}")
print(f" 尝试次数: {r['attempts']}")
def main():
"""主入口"""
import asyncio
print("=" * 60)
print("LangChain ReAct Agent 循环示例")
print("=" * 60)
print("\n选择运行模式:")
print(" 1. 标准 ReAct Agent")
print(" 2. Veri-ReAct Agent(带验证机制)")
print(" 3. 全部运行")
choice = input("\n请输入选项 (1/2/3): ").strip()
if choice == "1":
run_standard_react()
elif choice == "2":
asyncio.run(run_veri_react())
elif choice == "3":
run_standard_react()
asyncio.run(run_veri_react())
else:
print("无效选项,默认运行标准 ReAct Agent")
run_standard_react()
if __name__ == "__main__":
main()