1. 问题描述
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
题目看起来还是有点抽象的,我们看看官方给的示例。
Leetcode官方给出的示例如下:

现在我们基本上可以理解题目了:题目给出一个整数数组,里面的元素是乱序 的,并且可能含有重复 的元素,我们需要从数组中找出一个连续的序列,使得这个序列在所有连续序列中是最长的,最后返回这个最长连续序列的长度。
2. 解题思路
为了达到题目要求的时间复杂度,本题我们需要使用到哈希表的空间换时间特性。
从上面的示例中可以看出,重复的元素对最终获得的结果是没有任何帮助的,因此我们要处理掉重复元素。这里我们采用unordered_set,它的底层实现是哈希表,但和unordered_map不同的是,unordered_set只存储key键,不存储value值,里面的元素是无序的,且不允许重复。因此后面当我们将数组nums的元素全部插入到哈希表中时,哈希表中最终的元素是不重复的。
去掉了重复元素之后,我们需要考虑如何对重复元素进行处理。
首先我们要明确目标,要在哈西表中寻找能组成连续序列的元素,对于连续序列,一个比较好的办法就是从他的头部或者尾部入手,这里我们选择头部。试着思考一下一个连续序列的头部有什么特点,显而易见,如果一个连续序列的头部为num,那么哈希表中是不存在num-1这个元素的。利用好这个特点,我们就可以进一步提升程序运行效率。
因此,我们在遍历哈希表时,当遍历到每一个元素num时都检测一下num-1是否存在,就能判断元素num是不是序列的头部了。
如果num-1不存在,说明num确实是一个连续序列的头部,我们在依次判断num+1,num+2等等是否存在,直到下一个连续的元素不存在为止,那么这个序列的长度就显而易见了。
我们记录这个序列的长度,再和其他序列的长度比较,最终得到最长序列的长度。
解题思路已经梳理的差不多了,下一章我们进入代码实战。
3. 具体代码实现
完整代码如下:
cpp
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> hash;//创建哈希表
hash.reserve(nums.size());//预分配内存
for(int& num : nums)
{
hash.insert(num);//将数组元素插入到哈希表并去掉重复元素
}
int longest_count = 0;//最大序列长度
for(const int& num : hash)//这里如果使用引用传递就必须要加const,后面解释为什么
{
if(!hash.count(current_num - 1))
{
int current_count = 1;//当前正在处理的序列长度
int current_num = num;
while(hash.count(current_num + 1))
{
current_count += 1;
current_num += 1;
}
longest_count = max(longest_count,current_count);//更新最大序列长度
}
}
return longest_count;
}
};虽然代码中出现了循环嵌套,for 里面套 while,但由于我们加入了只从序列起点开始 的判断逻辑,每个数字作为序列中间成员 时会被直接跳过,每个数字只有在作为序列起点 被探测或者作为序列成员被计数时才会被访问。
因此每个元素在整个过程中最多被访问两次,总时间复杂度是线性的 O(n)。
4. C++核心知识点总结
在解决最长连续序列这个问题的过程中,我们完成的不仅仅是一道算法题,还对 C++ 的几个核心底层机制有了一定的了解。
4.1 unordered_set 与 unordered_map深度辨析
之前使用的都是unordered_map,这道题是我第一次接触到unordered_set 。本小节我将详细对比他们两者的差异,以更好地了解他们不同的使用场景。
unordered_set 和 unordered_map 都是 C++ STL 中基于哈希表 的两个最常用的无序关联容器,它们在底层实现上非常相似,但在语义和使用场景上有明显区别。
下面列表对比二者的特点:
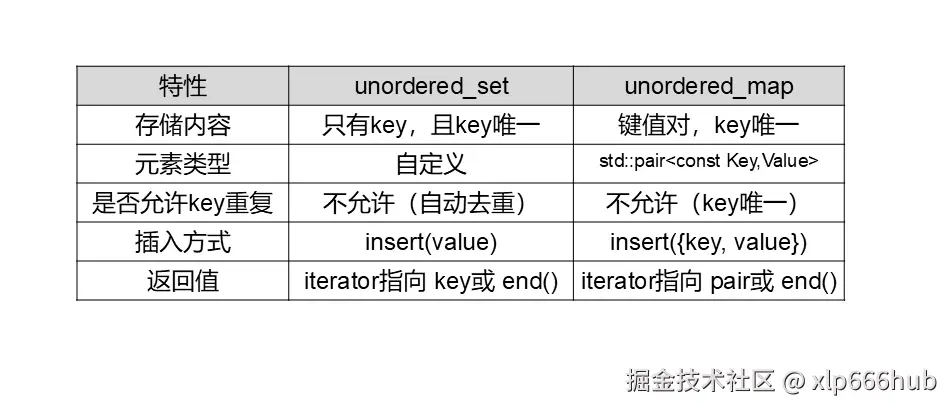
本题中我们只关心元素是否存在,且不需要存储值value,因此unordered_set是首选。
4.2 预分配内存
我们在创建哈希表之后写了这样一行代码:
cpp
hash.reserve(nums.size());为了了解这行代码的作用,我们先来看看没有这行代码的情况。
如果没有这行代码,也就是在常规情况下,我们向哈希表插入元素,随着元素的增多,当达到负载因子的阈值时,就会触发rehash导致重新哈希,这就涉及到申请新内存、重新计算所有元素的哈希值并搬迁。这会大幅拖慢程序的运行效率。
在这种情况下,预分配的作用就体现出来了。我们使用reserve提前告知容器的预期规模,能够有效地避免程序运行过程中动态扩容的开销,提升程序的运行效率。
由于数组nums中的元素可能存在重复,我们为哈希表预分配的内存一定是大于或者等于哈希表实际占用内存的,因此直接使用nums.size()即可。
4.3 key的只读属性
在上面代码的实现中,有这样一行代码:
cpp
for(const int& num : hash)我在注释中提到,如果这里使用了引用传递&,那么就必须要加上const。
下面解释一下为什么。
哈希表中的key决定了它存储在哪个桶里,如果允许通过引用随意修改 key 的值,那么该 key 将由于哈希值改变而导致在表中丢失。
此外,C++ 标准库规定 unordered_set 的迭代器指向的是 const 元素 。因此,若使用引用传递 ,必须加上 const 限定符,否则编译器会为了保护数据结构完整性而拒绝编译。
这里可能有人会问,如果不使用引用传递,直接使用常规的值传递可以吗?
答案是:理论和实际上都是完全行得通的,但是程序的运行效率会被大大拖慢。
因为值传递会将原本的值再拷贝一份,然后使用。而如果使用引用传递,num就只是原本数据的一个别名,不会有额外的拷贝开销,从而能够提升程序的运行效率,前提是加上const。
4.4 count和find
unordered_set 和 unordered_map 中的 count() 与 find() 是最常用的两种判断 key 是否存在的方法。他们的区别如下:
count:当要判断的key存在时,返回 1,不存在时返回 0。
find:当要判断的key存在时,返回指向该元素的迭代器,不存在时返回end()。
这样看来,它们的使用场景基本就划分开了。
当我们只需要知道某个key是否存在,而不需要value时,就可以使用count。
当我们需要拿到value或者修改value时,就必须使用find。
4.5 std::max详解
std::max 是定义在 C++ 标准库头文件 <algorithm> 中的一个函数模板,它的基本功能是比较两个或多个值 ,并返回其中的最大值。
我们常规的选出最大值的写法如下:
cpp
if (current_count > longest_count)
{
longest_count = current_count;
}但是使用std::max 会更加简洁:
cpp
longest_count = std::max(longest_count, current_count);使用std:max有个需要注意的点:max的参数类型必须完全相同,如果不同必须强制类型转换。
从 C++11 开始,就可以通过初始化列表(大括号)一次性比较多个数:
cpp
int result = max({a, b, c, d});此外,std::max 内部通常是通过常引用传递参数的。这意味着即使你比较的是两个巨大的对象(比如两个超长的字符串),它也不会产生额外的内存拷贝,性能非常出色。
4.6 insert和push_back辨析
可能有人会存在这样的疑惑:为什么在 vector 中我们习惯用 push_back,而到了 unordered_set 却必须用 insert?其实这背后的逻辑完全不同。
push_back从字面意思来看就是从后面推入,实际上的原理也大致相同。适用的容器有vector、list、deque 等序列式容器。它有一个前提------容器必须是有序的,也就是说新来的元素必须放在队伍的最末尾。
insert从字面意思来看是插入,适用unordered_set、set、map 等关联式容器。关联式容器(尤其是哈希表)并不关心先后顺序。就拿哈希表来说,一个元素具体放在哪个桶是要根据计算出来的哈希值决定的,而不是简单的按顺序放。
如果你尝试对哈希表使用 push_back,编译器会直接报错。原因很简单:哈希表并没有末尾的概念。
到这里,代码中涉及到的 C++ 知识点已经梳理完了,希望对大家有所帮助。
本文结束。