当真实数据由于隐私法律或合规要求而不能离开你自己的集群,或者你需要对模型部署与性能拥有更强控制力时,就有必要在自己的集群内运行模型。
当前市面上的模型种类很多,其中不少是开源的,并且可免费用于商业用途。Hugging Face 是目前最大的社区,你不仅可以在那里找到模型,还能找到数据集和各类库。关于当前开源大语言模型的清单,请参见第 2 章。
无论你是从哪里获取模型的,不管它是否开源,把模型部署到 Kubernetes 上时,总有一些方面并不取决于模型本身。但与此同时,也有一些方面必须仔细分析具体模型,才能确定最佳方案。
本章介绍了多种在运行时管理模型生命周期的方法与模式,重点关注一些最常用的 LLM 运行时。在深入讨论部署细节之前,请先阅读下面的侧栏内容,它介绍了支撑大多数现代 LLM 的 Transformer 架构背景知识。
TRANSFORMER 架构与注意力机制
生成式 AI 是一个非常庞大的领域,不同模型类别的成熟度差异显著,其中文本生成模型是使用最广、优化最充分的一类。
现代 LLM 主要基于 Transformer 架构或其某种变体(例如混合专家架构,mixture of experts),尽管 Transformer 不仅用于文本任务,也被用于视觉和多模态任务。这类模型可以覆盖多种与文本处理相关的用例:聊天机器人、代码生成、翻译、摘要等。
Transformer 架构是一种深度学习架构,由 Google 于 2017 年提出,其目标是通过注意力机制,更高效地追踪长程依赖。与循环神经网络(RNN)等其他架构相比,这种架构的主要优势在于它没有循环单元。这意味着它不会把某个神经元的输出作为另一个神经元的输入,因此在训练时具有很强的并行化能力。
长程依赖是自然语言处理中的一个核心概念:一句话的含义会受到上下文的影响。
注意力机制通过为句子的不同组成部分分配不同的权重(或重要性)来模拟人类的注意力。尤其是,多头注意力机制会并行运行多次注意力机制,生成不同的输出,最后再将这些输出拼接起来并进行线性变换。
关于 Transformer 架构与注意力机制的更多内容,请参见文章 "How do Transformers work?" 。
"它在我机器上能跑"
在我们开始探讨如何把模型部署到 Kubernetes 集群之前,先来了解一下如何在你本地机器上运行一个模型。
简而言之,部署一个模型既需要模型本身,也需要一个能够加载并执行它的运行时。正如前文所述,基于 Transformer 的模型是最常见的 LLM。因此,你可以使用 Hugging Face 的 Transformers 库来加载模型并调用它。这并不意味着每一台笔记本电脑都能承载类似的工作负载,也不意味着任意规模的模型都能被加载。某些模型确实可以在 CPU 上执行,但性能会非常有限(生成一句完整的话可能需要几十秒)。不过,GPU 基本上是必需的。此外,内存需求与模型规模直接相关。一个拥有 70 亿参数(即 7B)的模型通常被视为小语言模型(SLM),加载它大约需要一块拥有 15 GB 显存的 GPU。而一个 70B 模型则大约需要 140 GB 的内存。
请看示例 1-1,其中给出了一个展示该方法的代码示例。
示例 1-1. 使用 Transformers 加载并执行 Llama 3 1B
ini
import transformers
import torch
import os
model_id = "meta-llama/Llama-3.2-1B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
token=os.environ.get("HF_TOKEN")
)
messages = [
{"role": "user", "content": "Hey how are you doing today?"}
]
result = pipeline(messages, max_new_tokens=256)
print(result[0]["generated_text"][-1]["content"]) Hugging Face 格式的模型标识符。
加载并初始化模型。
使用 bfloat16 精度,以获得更好的性能与内存效率。
某些模型需要 Hugging Face token 才能授权下载。你可以在 Hugging Face 个人资料设置中获取该 token。
从结果中提取并只打印助手的回复内容。
虽然这个示例展示了加载并运行模型的基本机制,但它在真实场景中存在局限。提示词是硬编码的,而且用户无法与模型交互。要让它具备实用性,我们需要接收用户输入,并通过一个能够处理多个请求的端点把模型暴露出来。
回到示例 1-1,我们可以通过让端点接收提示词来增强它的灵活性,使之更接近真实世界场景。最简单的改进方式之一,就是避免每次运行时启动时都临时下载模型。开发与实验阶段,在启动过程中下载并初始化模型是一种很常见的模式,但也完全可以,而且通常也更建议,在不访问互联网的前提下就让模型在集群中可用。模型有不同的文件格式、存储方式和加载技术;更多内容请参见第 2 章。
下一步是通过一个端点暴露模型,这样提示词就可以动态传入,而且多个用户都可以调用它。一种简单的做法是使用 Python 生态,尤其是 FastAPI 和 Pydantic。见示例 1-2。
示例 1-2. FastAPI generate 端点
python
from fastapi import FastAPI
from pydantic import BaseModel
import transformers
app = FastAPI()
class InputText(BaseModel):
text: str
class OutputText(BaseModel):
text: str
def get_pipeline():
model_id = "meta-llama/Llama-3.2-1B-Instruct"
return transformers.pipeline(
"text-generation",
model=model_id,
device_map="auto"
)
pipeline = get_pipeline()
@app.post("/generate", response_model=OutputText)
async def generate_func(prompt: InputText):
output = pipeline(prompt.text)
return {"text": output[0]["generated_text"]}创建一个容器镜像并将其部署到 Kubernetes 上是可行的,但生产级工作负载还需要更多考虑。可扩展性、吞吐量、可复现性和监控,对于生产部署都至关重要。
与此同时,这个例子其实并不真正依赖于具体模型本身。这意味着我们已经在构建一个通用的东西,而且它可能还能被进一步泛化。本质上,我们是在重新实现一个模型服务器。
模型服务器
模型服务器(model server,或 serving runtime)是一个包含一个或多个运行时的组件。它可以分布式地同时使用多个 GPU,并执行多种类型的模型。模型通过 API(REST 或 gRPC)对外暴露,并被优化以最大化吞吐量、最小化延迟(见图 1-1)。
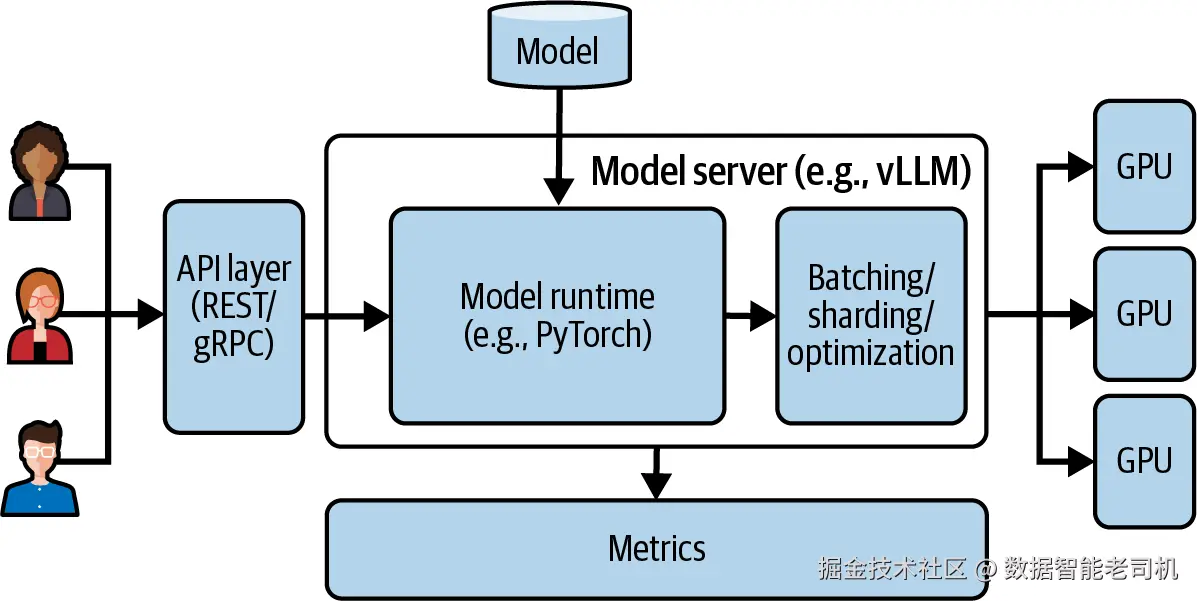
图 1-1. 模型服务器架构
这个概念并不新,也并非生成式 AI 所特有。现有很多模型服务器使用通用框架来服务各类传统机器学习模型,例如分类和回归任务,这些统称为预测式 AI(predictive AI)。其中一些也正在演进以支持生成式 AI。虽然概念相同,但暴露出来的 API 却很不一样。在预测式 AI 中,端点通常是通用的 /predict 或 /infer,因为模型表现得像一个黑盒函数。而在生成式 AI 中,API 更面向具体任务,因为相似的模型可能执行不同类型的动作,也可能处理不同类型的模态(参见"多模态模型"):文本生成、摘要、分类、文生图等。
NOTE
模型服务器通过 API 暴露 AI 模型,客户端必须使用这个 API。这个 API 可能是某个具体模型服务器实现特有的,从而打破了模型服务器原本想提供的抽象,因为客户端应用本不应该绑定到某个特定实现上。
这个问题并不新,也不是生成式 AI 独有的。对于预测式 AI,KServe 的 open-inference-protocol(OIP)定义了一套规范,用于标准化 "infer" 端点。大多数模型服务器都已采用它,而且它如今也正在扩展,以纳入生成式 AI。
用于调用生成式 AI 模型的 API 总体上仍处于实验阶段,并且会因模型类型和任务不同而有很大差异。对于文本生成模型而言,OpenAI 的 Chat Completions API 已经成为一种事实标准。
从 Kubernetes 平台视角来看,每一种模型服务器在部署拓扑上通常都比较相似。不过,你仍然需要了解模型类型和任务类型,因为扩缩容策略、硬件优化方式以及需要观察的指标,都是特定于模型服务器的。我们将在第 5 章更深入地讨论这些内容。
多模态模型
很多 LLM 通常只处理一种模态:输入和输出都是文本。多模态模型则能够处理更丰富的一组模态,例如图像、视频、音频、数学公式等等。尤其是,它们的主要目标之一是融合不同模态来执行任务,比如文生图:输入是文本查询,输出则是一张生成的图像。你也可以反向操作,或者在同一次查询中混合多种模态,比如同时提供一张图像和一个文本查询,以返回一张新的图像或一段文本。
从模型架构视角来看,虽然许多流行的图像/音频生成模型采用的是基于扩散(diffusion-based)的架构(如 Stable Diffusion),也有一些使用 Transformer 架构(如 DALL-E、Imagen 和 AudioLM)。这一类模型属于生成式 AI 的范畴,但它们并不是 LLM。尽管它们在医疗、电商、内容创作等多个行业中的采用率越来越高,但与文本生成模型相比,它们的标准化程度要低得多。它们通常被集成到专用产品中,例如图像编辑器和聊天界面。
本书默认聚焦于适用于更广泛用例集合的、基于 LLM Transformer 的体系。这意味着模型输出是文本,但这并不妨碍输入中同时包含图像、音频和文本,从而使它们成为多模态模型。
现在我们已经理解了模型服务器是什么,接下来来看看一些具体实现。我们将考察几种流行的 LLM 模型服务器,包括 vLLM、TGI、llama.cpp 和 NVIDIA NIM,并强调它们各自的优势与适用场景。
vLLM
vLLM 是 Linux Foundation AI & Data 旗下的一个用于 LLM 推理与服务的项目。这个项目非常活跃,拥有数千个 fork、数百位贡献者,支持五十多种模型架构,具备端到端优化技术,并支持多家硬件厂商。它既是一个可以在 Python 中直接使用的库(见示例 1-3),同时项目本身也包含 CLI 和一个兼容 OpenAI 的服务端。
示例 1-3. 在 vLLM 中加载模型并执行推理
ini
from vllm import LLM
# Load the model
llm = LLM(model="meta-llama/Meta-Llama-3-8B")
# Invoke the model
results = llm.generate("LLMs are great for")
# Extract the result
print(results[0].outputs[0].text)我们的目标是在 Kubernetes 上服务这个模型,因此 vLLM 应当运行在容器中,而服务端模式则是最佳选项。启动服务端所需的配置非常少。不过,有一个关键差异需要注意:在生产 Kubernetes 环境中,你更可能使用模型的本地副本,而不是在运行时临时从 Hugging Face 拉取。你需要把本地模型的位置显式传给服务端。见示例 1-4。
示例 1-4. 启动 vLLM 服务并通过 curl 调用
arduino
# start the server
vllm serve \
--port=8080 \
--model=/mnt/models \
--served-model-name=meta-llama/Meta-Llama-3-8B
# invoke the model
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3-8B",
"prompt": "LLMs are great for",
"max_tokens": 10,
"temperature": 0
}'启动 vLLM 服务。
指向包含模型的目录路径(容器内本地路径)。
模型名称。
模型应生成的 token 数量。
temperature 控制采样的随机性;设为 0 会使生成结果是确定性的。
从 Kubernetes 平台视角来看,有很多参数会影响运行时如何加载和执行模型,但从部署角度看,这些通常相对透明。诸如 PagedAttention、FlashAttention 和 speculative decoding(推测解码)之类的优化,主要聚焦于更高效的注意力管理和更快的执行。它们虽然不会直接改变部署方式,但会影响扩展性和资源优化效果。
关于这些优化技术及其影响的更深入说明,请参见下面的侧栏内容。
LLM 推理优化
LLM 执行优化是一个快速演进的领域,持续不断有新的进展出现。在这个领域中,学术研究与推理引擎实现之间的联系非常紧密。
新的优化技术频繁涌现,而要正确评估它们的实际收益,往往需要时间。
在这种背景下,我们已经提到了一些关键优化,比如 PagedAttention 和 Flash Attention,它们在优化内存管理时,专门用于加速 self-attention,因为这一阶段具有平方级的时间与内存复杂度。
另一个重要投资方向,是通过多种量化技术缩小模型规模,同时尽可能减少性能损失;这些技术会降低模型权重所使用的浮点数精度。
除了运行时优化之外,模型蒸馏(model distillation)也提供了另一条通向更快推理的路径:通过训练一个更小的"学生"模型去逼近更大的"教师"模型的行为。这种模型构建技术可以显著缩小模型体积,同时尽可能保留原始能力。
推测解码(speculative decoding)是一种利用双模型方案的优化技术:一个小而快的"草稿"模型先向前预测若干 token,然后由大模型一次性验证这些预测。通过减少昂贵的大模型运行频率,同时保持相同的输出质量,推测解码可以将吞吐量提升 1.5 到 3 倍,具体取决于序列的可预测性。
关于模型定制技术的更多内容,请参见第 6 章。
优化 LLM 执行的方式有很多。本书并不打算逐一解释。幸运的是,从 MLOps 工程师的视角看,你并不需要成为 LLM 优化内部机制方面的专家。你只需要使用一个活跃开发、社区庞大的模型服务器,这样每当新的优化出现时,它都能被纳入进来。以 vLLM 为例,它的配置通常只需要调整运行时启动参数,而且项目越来越擅长根据待执行的模型自动检测并应用合适的配置,因此默认值大概率就足够可用。
有些配置,例如量化,会影响模型质量,也需要调参以找到恰当的权衡。这属于模型开发与调优的范畴,因此到了推理阶段,理想情况下你应当已经拿到作为部署一部分的配置结果。
另一方面,作为一名 MLOps 工程师,你需要关注那些会对并行化和扩缩容产生更大影响的参数:多节点分布式服务会影响整体拓扑,通常还需要额外组件来管理协调,并且会让部署变成有状态的。我们将在第 4 章更详细地讨论模型运行问题。
Hugging Face Text Generation Inference
Hugging Face Text Generation Inference(TGI)是 Hugging Face 创建的一个开源模型服务器实现,用于服务文本生成模型,同时也被用于支撑其产品化服务。Hugging Face 之所以在本章中多次被提到,是因为它是当前最活跃的生成式 AI 社区,你可以在其中共享生成式 AI 模型(基础模型或微调模型)、数据集和各种库。许多最常用的生成式 AI 库,比如 transformers、peft 或 diffusers,都是在这个社区中孵化出来的。
TGI 现在支持多个推理后端,因此你可以根据硬件与性能需求选择最合适的后端,同时保持 API 一致。支持的后端包括 TGI 原生的 CUDA 后端(针对 NVIDIA GPU 优化)、NVIDIA TensorRT-LLM、llama.cpp(用于 CPU 部署)以及 AWS Neuron(用于 AWS Trainium 和 Inferentia 芯片)。多后端支持正成为模型服务器的一个新趋势,像 Triton 和 TGI 这样的项目都在采用这种方式,以提供更灵活的部署选项。它的主要优势在于,你可以针对特定硬件和用例选取最优后端;但与此同时也有代价:尽管这些后端通过统一 API(例如兼容 OpenAI 的端点)对外暴露,不同后端的配置参数与调优选项却存在显著差异。当你需要在后端之间切换,或者对性能做细粒度调优时,这会让优化与调试变得更复杂。
与 vLLM 类似,TGI 提供了一个 launcher,用于启动服务并加载模型。见示例 1-5。
示例 1-5. 使用原生 API 和 OpenAI API 启动 TGI 服务
vbnet
# start the server
text-generation-launcher \
--port 8080 \
--model-id /mnt/models
# invoke the model using TGI API
curl localhost:8080/generate_stream \
-H 'Content-Type: application/json' \
-X POST \
-d '{"inputs":"LLMs are great for",
"parameters":{"max_new_tokens":10}
}'
# invoke the model using OpenAI-compatible API
curl localhost:3000/v1/chat/completions \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "tgi",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "LLMs are great for"
}
],
"max_tokens": 10
}'启动命令。
包含模型的目录路径(容器内本地路径)。
使用 TGI 原生 API 调用模型。
TGI 现在也支持兼容 OpenAI 的 API。
最常见的一类微调模型之一是 "instruct" 模型,它们被设计为遵循人类指令。在这种场景下,system prompt 用于定义模型的角色。
前面关于参数及其对 Kubernetes 影响的讨论,同样适用于 TGI。
除了 vLLM 和 TGI 之外,还有若干模型服务器在特定用例中也值得关注。
其他模型服务器
尽管 vLLM 和 TGI 是最常见的开源 LLM 模型服务器,但在特定部署场景和硬件配置下,其他实现也值得纳入考量。
llama.cpp
llama.cpp 是一个运行 Llama 模型的 C++ 实现。
它最初是专门针对 Llama 模型,用 C++ 对 Transformer 架构进行完整重实现的项目。随着时间推移,它逐渐演进为支持多种其他模型。其重点一直是高效率,因此它也是在笔记本本地运行类似模型时最推荐的选项。尽管它仍然需要较强的机器配置,但它已被 Ollama、Ramalama 和 LM Studio 等项目广泛采用。虽然它并不是为高并发的大规模生产部署而设计的,llama.cpp 却非常适合资源受限环境。一个活跃的社区持续将其他模型服务器中的优化与技术移植到 C++ 生态中,使得 llama.cpp 在设备端推理和本地开发等边缘场景中越来越强大。llama.cpp 发展带来的一个结果,就是 GGUF 文件格式的诞生,而这个格式如今也已被其他库采纳。
除了核心库之外,它还提供了一个 Python 服务端,能够像其他模型服务器一样暴露兼容 OpenAI 的 API;见示例 1-6。
示例 1-6. 启动 llama.cpp Python 服务端
bash
python -m llama_cpp.server \
--model /mnt/models 启动 llama.cpp 服务。
模型所在位置(容器内本地路径)。
TIP
假设你有一台至少拥有 24 GB 内存的强力机器,即使没有 GPU,借助构建于 llama.cpp 之上的工具,在本地运行量化后的 LLM 也会变得异常简单。
Ollama 提供了一个简洁的 CLI,只需一条命令即可下载并运行模型:
arduinoollama run llama3.2:3bRamalama 也提供了类似的简洁体验,并支持多个模型注册表和容器运行时:
arduinoramalama run llama3.2:3b这两个工具底层都使用 llama.cpp 来处理模型执行,并对外暴露兼容 OpenAI 的推理 API。相比之下,Ramalama 通过基于容器的执行提供了更强的隔离性,而 Ollama 则拥有更成熟的开发者体验和更易用的模型管理能力。二者都非常适合本地开发、实验和原型验证,然后再部署到生产 Kubernetes 集群中。
NVIDIA NIM
NVIDIA 是 AI GPU 的主要提供商,同时也提供训练和服务模型所需的软件。NVIDIA NIM 是一套面向 Kubernetes 的解决方案,旨在简化 LLM 在 NVIDIA 硬件上的部署与优化。它采取了不同的方式:针对每个模型家族提供精心整理的容器镜像,其中模型由 NVIDIA 直接测试并发布。你可以在文档中查看受支持模型列表(如 Llama 和 Mistral)。这种方式旨在通过预优化的模型配置文件,简化部署配置。
与 TGI 类似,NVIDIA NIM 支持多个推理后端:TensorRT-LLM(一个用于在 NVIDIA GPU 上优化 LLM 推理的开源库)、vLLM 和 SGLang。NIM 会根据检测到的 GPU 硬件和可用模型配置文件,自动选择最佳后端,优先级为 TensorRT-LLM > vLLM > SGLang。选择过程是自动完成的,依据包括是否存在预优化的 TensorRT 引擎以及其他参数。这种面向硬件的后端选择机制,使用户无需手工配置,也能从最合适的推理引擎中获益。
除了后端选择之外,NVIDIA NIM 的另一个突出特点在于其带有明显主张的设计中包含了一些值得注意的功能:本地模型缓存和硬件优化。本地缓存通过 PersistentVolume 实现,目标是简化并加速 LLM 模型服务中的一个主要痛点:加载时间。模型只会下载一次,后续副本创建或重启都不会再次触发下载。硬件优化则是另一项关键能力:NVIDIA NIM 能检测可用加速器,为当前配置选择最合适的模型变体,并据此自动调整模型服务器设置。关于 NVIDIA NIM 架构的更多细节,请见图 1-2。
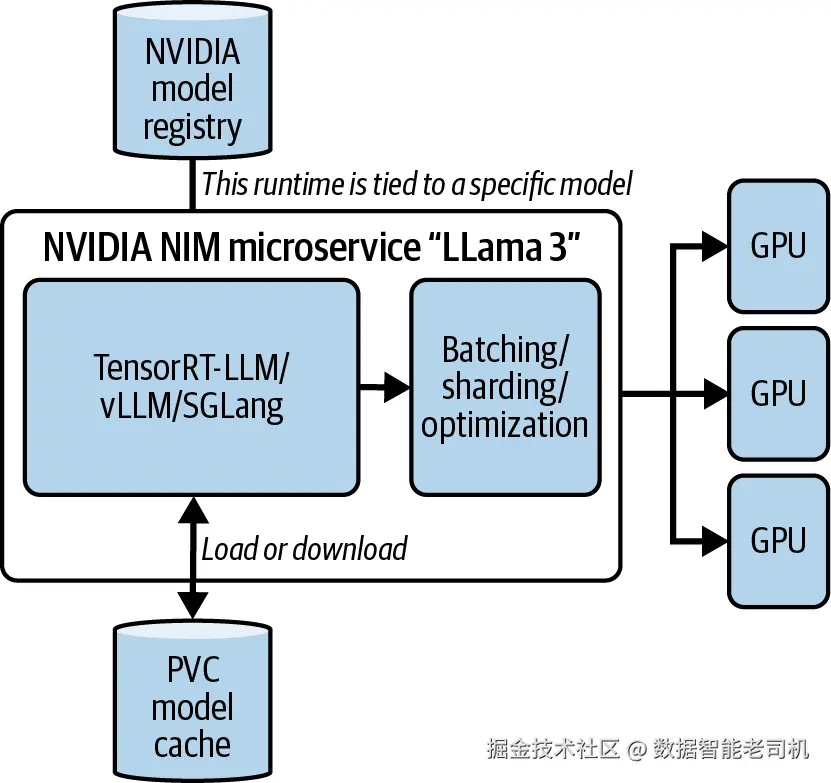
图 1-2. NVIDIA NIM 架构
SGLang
SGLang 是一个面向大语言模型和视觉语言模型的开源高性能服务框架,旨在提供低延迟、高吞吐的推理能力。该项目已在业界获得广泛采用,并以其先进的优化技术著称。
许多性能提升都由 SGLang 项目推动,例如 RadixAttention------这是一种复杂的缓存机制,会将 key-value(KV)缓存存储在一棵 radix tree(基数树)结构中。这样可以高效地进行前缀搜索和跨请求缓存复用,特别适用于具有公共提示前缀的工作负载,或者可复用先前上下文的多轮对话场景。SGLang 支持 continuous batching(连续批处理)、speculative decoding(推测解码)以及多种量化技术。
与 vLLM 和 TGI 一样,SGLang 也暴露兼容 OpenAI 的 API,并支持大多数 LLM 模型架构。
启动一个 SGLang 服务端与其他模型服务器类似。示例 1-7 给出了一个例子。
示例 1-7. 启动 SGLang 服务端
css
python -m sglang.launch_server \
--model-path /mnt/models \
--port 8080启动 SGLang 服务。
模型目录路径(容器内本地路径)。
SGLang 特别适合那些需要高缓存命中率的场景,例如智能体在相似上下文下进行多次调用,或者应用具有结构化提示词、能够复用前缀的场景。
手动将模型部署到 Kubernetes
现在我们已经理解了模型服务器是什么,并考察了若干专门面向 LLM 的实现,接下来把其中一个部署到 Kubernetes 上。我们将从使用标准 Kubernetes 资源的手动方式开始,以了解生产部署中实际涉及哪些内容。
这种 DIY(自己动手)方式始终可用,而且在某些情况下是必要的------例如你需要对部署的每一个细节都进行定制,即便是在控制器环境中也是如此。
假设你要使用 vLLM,并且已经有了要用的镜像。在示例 1-8 中,你很容易看出部署中大多数需要考虑的配置:要暴露的端口、模型所在路径,以及 GPU 配置和执行模型所需参数,而这些参数本质上又是模型特定的。
示例 1-8. 使用 GPU 启动 vLLM 服务
ini
# specify which of the available GPUs to use
CUDA_VISIBLE_DEVICES=0,1
vllm serve \
--port=8080 \
--model=/mnt/models \
--served-model-name=meta-llama/Meta-Llama-3-8B现在我们已经知道如何创建部署、要使用的模型名称以及 GPU 要求,就可以继续了。请看示例 1-9,其中给出了完整的部署规范(包含 PersistentVolumeClaim),可直接应用到你的集群中。
示例 1-9. 使用 GPU 部署 vLLM 服务
yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: vllm
spec:
replicas: 1
template:
spec:
containers:
- resources:
limits:
cpu: '4'
memory: 12Gi
nvidia.com/gpu: '1'
requests:
cpu: '2'
name: vllm
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: huggingface-secret
key: token
args: [
"--port",
"8080",
"--model",
"meta-llama/Meta-Llama-3-8B",
"--download-dir",
"/models-cache" ]
ports:
- name: http
containerPort: 8080
protocol: TCP
volumeMounts:
- name: models-cache
mountPath: /models-cache
image: vllm/vllm-openai:latest
volumes:
- name: models-cache
persistentVolumeClaim:
claimName: vllm-models-cache
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-models-cache
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 100Gi除了传统的 CPU 和内存资源外,你还可以指定模型所需的 GPU 数量。
vLLM 的一种用法是在运行时临时从 Hugging Face 下载模型,这就需要通过环境变量注入 token。
vLLM 镜像的入口点本身就会启动服务,因此只需要额外指定附加参数即可。
如果采用运行时下载模型的方式,通常建议指定一个持久化的模型缓存目录,以存放模型。
需要暴露的端口(之后可以通过 Service 和 Ingress 对外暴露)。
要作为缓存使用的持久化卷。
Taint 可以阻止非 GPU 工作负载被调度到 GPU 节点,而 toleration 则允许该 GPU 工作负载被调度到那些带有 taint 的节点上。
这个例子并未涵盖 Kubernetes 中的 GPU 配置(第 3 章会进一步讨论)、重启策略、扩缩容以及探针配置。它也只适用于模型可部署到单节点上的场景,而不适用于分布式服务场景。
虽然这种手动方式可行,而且相对自包含,但它也暴露出明显的复杂性:GPU 资源管理、toleration 与 taint、存储配置、密钥管理,以及模型特定参数,都需要显式配置。随着你部署多个具有不同要求的模型,这种复杂性会成倍增加。每新增一个模型,就意味着又要新增一份 Deployment 清单、一个 PVC、仔细协调资源请求,并手工管理配置变更。
这也正是模型服务器控制器存在的原因:它们通过更高层级的 API 来抽象这些复杂度,让你关注模型部署本身,而不是底层 Kubernetes 基础设施细节。
模型服务器控制器
正如我们在手动部署中看到的,把模型部署到 Kubernetes 上需要管理大量资源:Deployment、PersistentVolumeClaim、GPU 配置、toleration,以及模型特定参数。模型服务器控制器通过自定义资源定义(CRD)提供更高层级的抽象,从而简化这一复杂性。
控制器让你可以在更高层声明你的意图,而不是手工编写部署清单并协调多个 Kubernetes 资源。CRD 方式还提供了集中式状态信息,使你更容易监控模型部署的健康状况和运行状态。图 1-3 在之前的模型服务器架构图基础上扩展了主要控制器组件:一个或多个 Kubernetes CustomResourceDefinition,以及一个 Kubernetes controller。
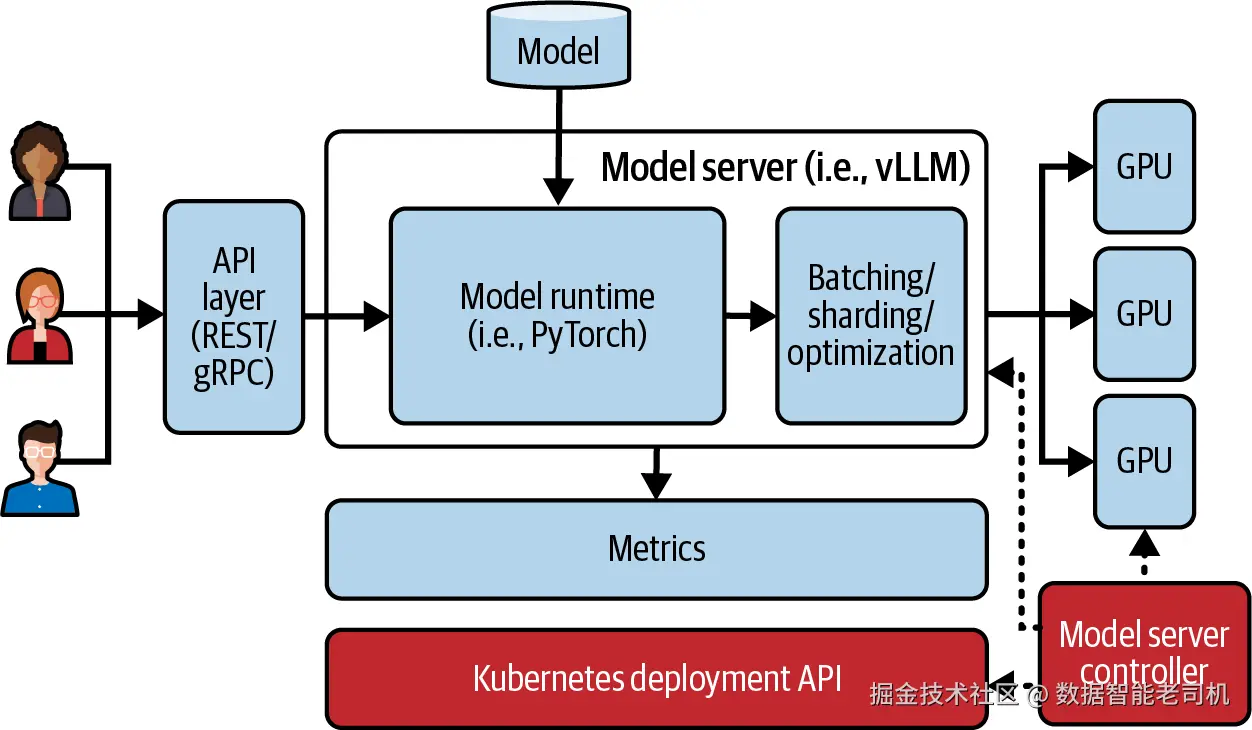
图 1-3. 模型服务器控制器架构
每个模型服务器通常都会提供容器镜像,因此你不需要自己构建它们;但与此同时,选择正确的容器镜像并不简单:每种加速器都有不同的驱动和框架(例如 NVIDIA 使用 CUDA,AMD 使用 ROCm 等),因此这一点必须特别留意。这个问题有点类似于多架构容器:你可以很容易地选择架构(例如 ARM64 或 i386),然后获取对应的容器版本。但对于加速器来说,这个过程目前仍然相当手工。关于 Kubernetes 如何通过 device plug-in 管理 GPU 和加速器访问,请参见第 3 章。
下面我们来看两种常见的模型服务器控制器方案:KServe 和 Ray Serve。
KServe
KServe 是 CNCF(Cloud Native Computing Foundation)旗下的一个项目,提供 Kubernetes 上的模型推理平台,旨在管理模型服务器和模型的生命周期及其连接方式。它利用 Kubernetes 组件来提供弹性扩缩容、路由、金丝雀发布、密度打包,以及更一般意义上将模型推理端点暴露出来的能力。
该项目最初作为 Kubeflow 社区中的 KfServing 创建,后来发展为独立项目(尽管它仍属于 Kubeflow 生态的一部分)。它最初主要面向预测式 AI,直到最近才演进以支持生成式 AI。
KServe 作为 Kubernetes 原生组件构建,扩展了 Kubernetes API,并通过多个 CustomResourceDefinition 以声明式方式映射不同概念。我们不会覆盖 KServe 提供的全部 API 和概念,因为其中大多数仍然主要适用于预测式 AI。
从技术栈角度看,它有三种不同的部署模式:Knative、Standard 和 ModelMesh(见图 1-4)。
Knative
Knative 是最完整的栈,使用 Knative 和 Istio 来管理自动扩缩容、滚动更新、流量管理和组合能力(也包括通过 Knative Eventing 进行的组合)。在这种模式下,每个模型都会变成一个 KnativeService。
Standard
Standard 与 Knative 相反,不依赖 Kubernetes 之外的额外组件。在这种模式下,对于每个模型,KServe 都会创建一个新的 Deployment。KServe 0.16 引入了一种新的部署方式:通过 LLMInferenceService CRD 来管理高级且可扩展的 LLM 部署,这可以看作是 Standard 部署模式的演进。
ModelMesh
ModelMesh 方案专门面向高密度部署场景,也就是你需要在同一集群中部署大量模型------可能成百上千个------而使用独立 Deployment 的资源开销太大。在这种模式下,模型服务器会根据请求动态加载和卸载模型。
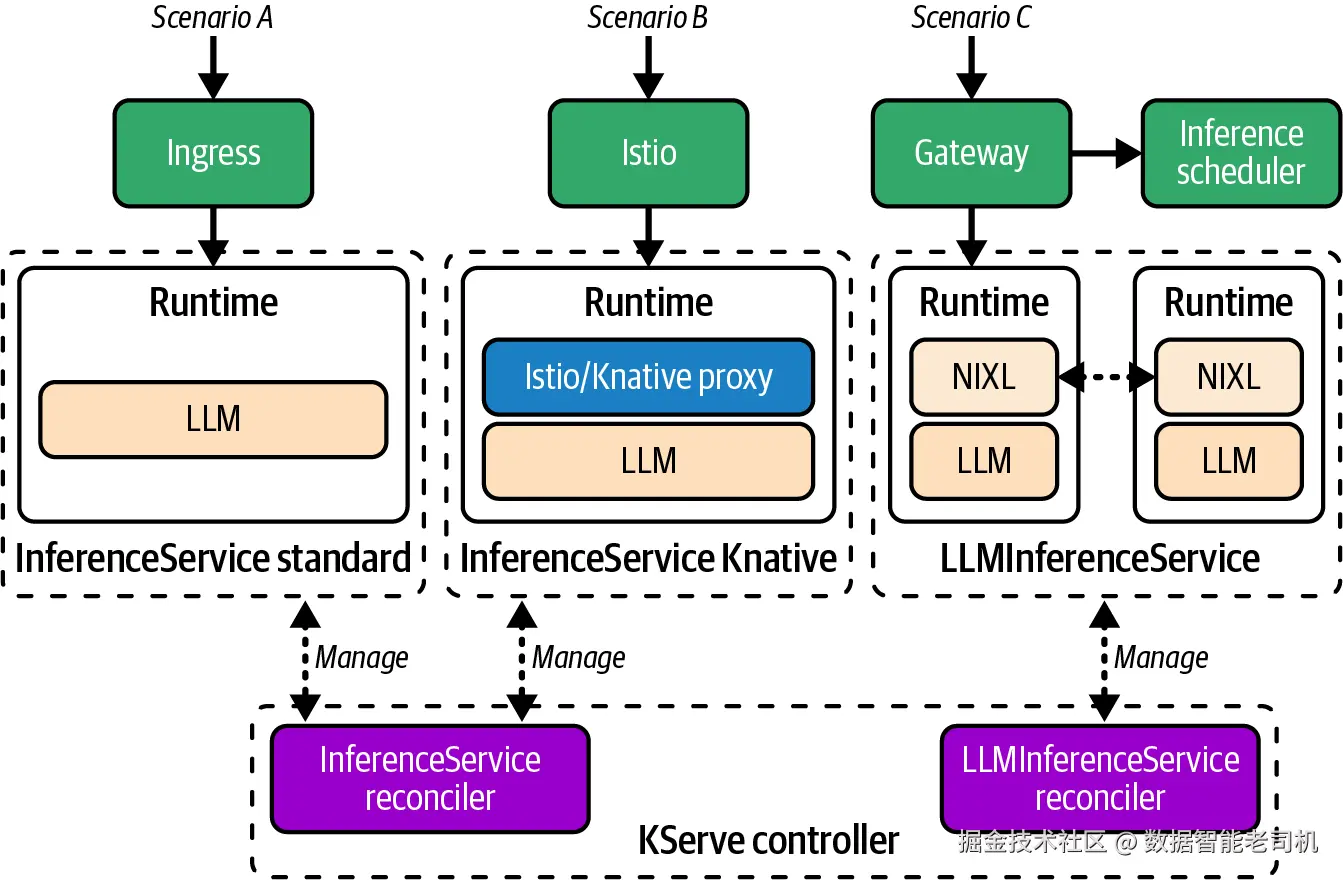
图 1-4. KServe Standard、Knative 和 LLMInferenceService 部署架构
TIP
从 KServe 0.16 开始,部署模式的命名进行了调整,以便更清晰:
- Serverless 现在更名为 Knative,以反映其底层技术(Knative Serving)。
- RawDeployment 现在更名为 Standard,这是一个更直观的名字,对应标准 Kubernetes 部署。
- ModelMesh 保持不变。
在本书中,我们统一使用新术语。如果你使用的是较老版本的 KServe(0.16 之前),请将 "Knative" 对应理解为 "Serverless",将 "Standard" 对应理解为 "RawDeployment"。
ModelMesh 部署模式其实并不真正适用于生成式 AI:这类模型的体积和复杂度,基本上不允许你在同一个节点上同时部署多个。另一方面,Knative 和 Standard 两种部署模式通常都适用于生成式 AI。不过,对于更小的模型,比如 Phi、Gemma,以及 Llama 的紧凑变体(参数规模低于 30B),它们可以运行在消费级硬件上,因而可能受益于动态扩缩容;而更大的生产级 LLM 通常需要静态管理的专用 GPU 资源,这使得在 Knative 模式下充分利用动态自动扩缩容的优势变得困难。在接下来的讨论中,我们将默认采用 Standard 作为部署模式。
KServe 提供的两个主要 API 用于部署模型:ServingRuntime 和 InferenceService。
ServingRuntime
ServingRuntime 相当于一个 Pod 模板,其中声明了模型服务器。它指定要使用的模型服务器镜像、一些参数,以及它能够服务的模型类型。这个概念把运行时配置和模型配置分离开来。这种分离使项目所有者能够更好地控制模型服务器版本、默认配置和运行时生命周期管理。你也可以使用 ClusterServingRuntime 来配置一个在整个集群范围内可用的运行时。见示例 1-10。
示例 1-10. KServe 中用于 vLLM 的 ServingRuntime
yaml
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: vllm
spec:
containers:
- args:
- --model
- /mnt/models/
- --port
- "8080"
name: kserve-container
image: vllm/vllm-openai:latest
ports:
- containerPort: 8080
name: http1
protocol: TCP
multiModel: false
supportedModelFormats:
- autoSelect: true
name: pytorch 这个自定义 ServingRuntime 的名称。KServe 自带一些预配置的 ServingRuntime(其中就包括一个名为 "HuggingFace Runtime"、内部使用 vLLM 的实现),可以直接使用。不过,在本例中我们定义了自己的 vLLM ServingRuntime,以便完全掌控配置和参数。
这里本质上是 podSpec,可以配置运行模型服务器所需的全部参数。
这里指定要使用的镜像。注意,应用该资源后并不会立即部署模型服务器,而只是让它在该命名空间内可被使用。
vLLM 和大多数模型服务器一样,底层实际运行模型时使用的是 PyTorch,因此这里声明这个运行时能够服务 PyTorch 模型。
InferenceService
InferenceService 表示用户希望服务的模型。这个对象可以指定要使用的 ServingRuntime,也可以根据模型格式自动选择。创建该资源后,将触发模型服务器的部署以及模型的连接配置。在同一个 spec 中,还可以覆盖 ServingRuntime 中指定的默认参数,并增加一些针对该模型的专属配置。见示例 1-11。
示例 1-11. 使用 Standard 部署模式的 InferenceService
yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: Meta-Llama-3-8B
annotations:
serving.kserve.io/deploymentMode: Standard
spec:
predictor:
model:
modelFormat:
name: pytorch
runtime: vllm
storageUri: pvc://llama/model
containers:
resources:
limits:
cpu: "4"
memory: 50Gi
nvidia.com/gpu: "1"
requests:
cpu: "1"
memory: 50Gi
nvidia.com/gpu: "1"这个 annotation 用于选择部署模式。
声明模型类型后,KServe 可以自动找到能够处理它的 ServingRuntime。
这个字段通过名称引用 ServingRuntime,它提供了 InferenceService 所需的容器镜像和配置。
这个字段指定从哪里获取模型;在本例中,是从集群本地的一个 PVC 获取。
对于每个模型,都可以覆盖资源配置,以匹配该模型的实际需求。
其他概念与 API
KServe 的 API 非常灵活,还包含许多并非部署 LLM 所绝对必需,但可以支持更高级、可组合用例的概念。你可以配置 inference logger,把模型的每一次输入和输出都转发到日志服务中,以便审计或训练使用;还可以做预处理和后处理,甚至通过 InferenceGraph 组合不同模型。关于更完整的说明,请参见 KServe Control Plane API 文档。
ServingRuntime 与 InferenceService 分离的一个主要好处,是在管理职责上形成更清晰的边界,因为运行时生命周期和模型生命周期是非常不同的。KServe 还提供其他额外优势,例如支持多种存储选项:KServe 控制器会注入一个名为 storage initializer 的 initContainer,它负责读取模型位置,执行下载(如有需要),并将模型复制到模型服务器中的某个目录。你还可以通过 ClusterStorageContainer API 替换这个 storage initializer 容器,使用一个自定义实现,以支持自定义协议,从而集中管理可用模型目录。我们将在第 2 章更详细地讨论如何打包、注册和加载模型。
KServe 正在积极演进,以通过新的 API 面向 LLM 特有需求提供更好的支持(见下一节)。
从 InferenceService 到 LLMInferenceService
KServe 0.16 引入了一个新的 LLMInferenceService CustomResourceDefinition,专门用于管理复杂的大规模 LLM 部署。传统的 InferenceService API 虽然可以用于基础 LLM 服务,但 LLMInferenceService 提供了更适合高级部署拓扑的能力,这些拓扑在生产级生成式 AI 工作负载中非常常见,包括带有 KV cache 感知调度的智能路由、解耦式服务(disaggregated serving)以及多节点分布式推理。
从实现角度来看,LLMInferenceService 采用 Standard 部署模式,创建普通的 Kubernetes Deployment 资源,这反映出一种根本性的转变:LLM 工作负载的管理方式正在改变。这种演进要求人们重新思考传统的自动扩缩容和流量管理方案,以适应长生命周期 GPU 工作负载的独特特征------在这种场景下,稳定性、资源可预测性,以及基于模型状态的智能路由,比快速扩缩容更重要。
示例 1-12 展示了一个配置示例,它突出了关键组件,以及 LLMInferenceServiceConfig(充当基础模板)与 LLMInferenceService(引用该配置并可覆盖特定设置)之间的关系。这个示例演示了 router 部分,其中包括 gateway 和 scheduler,用于智能路由;还展示了 parallelism 设置,用于在多个 GPU 间做分布式推理。
表 1-1 对传统的 InferenceService + ServingRuntime 方式,与新的 LLMInferenceService + LLMInferenceServiceConfig API 进行了比较,突出了它们在能力与适用场景上的关键差异。
这些特性对于部署超大模型(70B+ 参数)尤为重要,因为此类模型通常需要多块 GPU 或者更复杂的服务架构。关于分布式推理模式与技术的更多细节,请参见 llm-d 项目。我们将在第 4 章详细讨论解耦式服务与高级部署拓扑。
示例 1-12. 带有分布式推理和基础配置的 LLMInferenceService
yaml
# Base configuration template
apiVersion: serving.kserve.io/v1alpha1
kind: LLMInferenceServiceConfig
metadata:
name: vllm-llama-config
spec:
template:
containers:
- name: kserve-container
image: vllm/vllm-openai:latest
args:
- --port=8080
- --model=/mnt/models
resources:
limits:
nvidia.com/gpu: "1"
cpu: "4"
memory: 50Gi
router:
gateway: {}
route: {}
scheduler: {}
parallelism:
tensorParallelism: 2
---
# Actual LLM deployment
apiVersion: serving.kserve.io/v1alpha1
kind: LLMInferenceService
metadata:
name: llama-3-8b
spec:
baseRefs:
- vllm-llama-config
model:
uri: pvc://llama/model
name: meta-llama/Llama-3.1-8B-Instruct
replicas: 3
# Optionally override base configuration here
...用于服务模型的 vLLM 容器镜像和启动参数。
包含 gateway、route 和 scheduler 的 router 规范,用于实现带 KV cache 感知调度的智能路由。
用于分布式推理的并行策略:tensor parallelism、data parallelism 和 expert parallelism。
对基础配置模板的引用;可以引用多个配置,后引用的会覆盖前面的配置。
用于定义模型来源及其特征的模型配置。
用于横向扩容的副本数;它可以覆盖基础配置中的设置。
表 1-1. 用于预测式 AI 和生成式 AI 的 KServe API 对比
| 方面 | InferenceService + ServingRuntime | LLMInferenceService + LLMInferenceServiceConfig |
|---|---|---|
| 主要用例 | 预测式 AI(分类、回归) | 生成式 AI(LLM、文本生成) |
| 部署模式 | 单节点、简单扩缩容 | 多节点分布式推理、解耦式服务 |
| 配置模板 | ServingRuntime 定义模型服务器模板 | LLMInferenceServiceConfig 定义带继承机制的基础 LLM 配置 |
| 路由与调度 | 基础负载均衡 | 高级路由,包含 gateway、scheduler 和 KV cache 感知调度 |
| 并行支持 | 有限 | 原生支持 tensor、data 和 expert parallelism |
| 典型模型规模 | 小到中等模型 | 大模型(7B--405B+ 参数) |
如果说 KServe 采取的是 Kubernetes 原生路线,那么 Ray 则体现了另一种理念:它优先强调 Python-first 的开发体验,并引入了自己的编排层。
Ray Serve 与 KubeRay
与 KServe 相比,Ray 是一个更年轻、但范围更广的项目。它是一个开源框架,旨在更容易地构建和扩展机器学习应用。它具有非常强的 Python 风格,对于有 Python 经验的人来说非常友好,而且它允许你直接在 Python 代码中配置所有活动。
Ray 并不是专门为模型服务而生的,相反,它定义了一组相当通用的核心概念:Task、Actor、Object、Placement Group 和 Environment Dependency。这些核心概念与 Ray Cluster 一起,定义了执行模型,并被用来构建和扩展其他所有功能。图 1-5 展示了一个 Ray 集群的拓扑,其中包含 head node 和 worker nodes。
如果你想系统打好 Ray 的基础,我们推荐阅读 Max Pumperla 等人所著的 Learning Ray(O'Reilly,2023)。
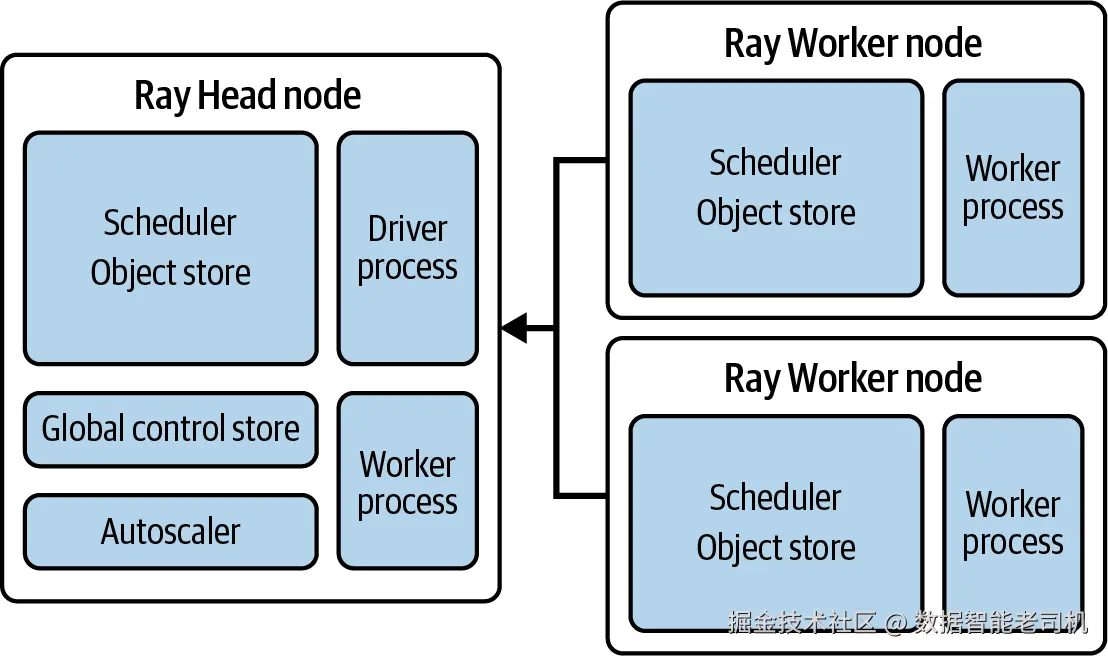
图 1-5. Ray Cluster 拓扑
从图 1-5 中可以看出,Ray Cluster 并不是以 Kubernetes 为中心设计的。它自身拥有一套独立的基础设施,用来管理任务调度与作业编排,而这些事情在 Kubernetes 中原本通常是通过 Kubernetes API 和不同 worker 节点完成的。Ray 有 head node 的概念,它作为作业入口,然后把作业分发到一个或多个 worker node 上执行。
Ray 提供的功能集合覆盖了大多数机器学习用例;Ray Train、Ray Tune 和 Ray Serve 只是其中的一部分。Ray Serve 是我们用来服务模型的组件,其部署是用 Python 定义的,不论是暴露端点还是初始化模型,方式都是一致的。示例 1-13 展示了一个非常简化的场景,其中配置并部署了一个基于 Transformer 的模型,和本章第一节中的做法类似。由于它直接在代码中配置,Ray Serve 非常灵活;你很容易找到把它与 FastAPI 集成来暴露端点的例子,或者结合 vLLM 这样的库来部署完整模型服务器的例子。
示例 1-13. 使用 Transformer 模型的 Ray Serve
python
from starlette.requests import Request
from typing import Dict
from transformers import pipeline
from ray import serve
@serve.deployment
class TransformerModelDeployment:
def __init__(self):
self._model = pipeline(
"my-transformer-model")
def __call__(self, request: Request) -> Dict:
return self._model(
request.query_params["text"])[0]
serve.run(
TransformerModelDeployment.bind(),
route_prefix="/my-model/")装饰器函数,可以在这里配置大多数部署相关内容,例如自动扩缩容。
__init__ 方法应该用于加载模型;在这个例子中,它加载的是一个基于 Transformer 的 pipeline。
这个方法会以给定的前缀部署模型。
Ray 的 API 对数据科学家或一般 Python 开发者而言都非常友好,但要把 Ray Cluster 部署到 Kubernetes 上,仍然需要额外的帮助,以便将所有组件与 Deployment、Ingress 等 Kubernetes 概念正确地连接起来。
KubeRay 项目正是为了解决从本地 Ray 执行过渡到 Kubernetes 的问题而创建的。这是必要的,因为 Ray Cluster 和 Ray 应用本身并不是原生围绕 Kubernetes 设计的,尤其是 Ray Cluster 具有 head node 和 worker nodes,它们需要以多个部署的形式被正确配置,并彼此协同工作。
KubeRay 通过 Kubernetes 的 CustomResourceDefinition 提供了多个 Ray API,其中尤其值得注意的是 RayService 对象,它用一个统一概念同时表示一个多节点 Ray Cluster 和使用该集群的 Ray Serve 应用。示例 1-14 并不是完整规范,但突出了主要元素。
示例 1-14. RayService CR 片段
yaml
apiVersion: ray.io/v1alpha1
kind: RayService
metadata:
name: my-transformer-model
spec:
serveConfigV2: |
applications:
- name: my-transformer-model
import_path: my-transformer-model:deployment
runtime_env:
working_dir: "https://my-git-repo.com/main.zip"
rayClusterConfig:
rayVersion: %VERSION%
headGroupSpec:
...
template:
spec:
containers:
- name: ray-head
image: rayproject/ray-ml:%VERSION%
ports:
...
- containerPort: 8000
name: serve
workerGroupSpecs:
- replicas: 1
groupName: gpu-group
template:
spec:
containers:
- name: ray-worker
image: rayproject/ray-ml:%VERSION%
tolerations:
- key: "ray.io/node-type"
operator: "Equal"
value: "worker"
effect: "NoSchedule"这个字段包含了 Ray Serve 应用的全部配置。
应用代码会从 working_dir 指定的位置下载。
该部分 spec 用于配置 Ray Cluster 的 head node 和 worker nodes。
这里必须指定 Ray 版本,并在所用镜像中保持一致。
除了 serving 本身之外,head node 还会暴露其他多个组件,例如 dashboard 或 client。
和前面一些示例一样,这里也可以配置 toleration 与 taint,以匹配节点要求(例如 GPU 节点或专用 Ray 节点)。
从 Kubernetes 平台视角来看,相比 KServe,Ray 在 API 和管理方式上显然没有那么"原生熟悉",但与此同时,它让数据科学家和 Python 开发者能够完全掌控部署。这种灵活性非常有价值,尤其是在你需要配置更复杂的服务拓扑时,比如跨多主机的分布式服务或训练。
经验总结
-
在本章中,我们探讨了将 LLM 部署到 Kubernetes 所需的各类组件,从基础模型服务一直到面向生产的编排机制。
-
像 vLLM、TGI 和 SGLang 这样的模型服务器提供了关键优化能力(PagedAttention、FlashAttention 和 continuous batching),它们会直接影响吞吐量和延迟。虽然你也可以用 FastAPI 把推理代码容器化,但生产工作负载需要更专业的运行时,以最大化 GPU 利用率,并高效管理受内存约束的解码阶段。
-
服务运行时配置与模型生命周期管理之间的分离,反映了真实运维中的客观现实。KServe 通过 InferenceService 与 ServingRuntime 支持通用模型服务,并进一步引入 LLMInferenceService 和 LLMInferenceServiceConfig,以支持需要分布式推理和高级路由的复杂 LLM 部署。
-
这种分离承认了一点:运行时升级、模型发布和基础设施变更,本来就遵循不同的节奏,也往往由不同角色负责。平台团队可以管理运行时版本和容器镜像,而数据科学团队则可以独立部署和迭代模型,从而避免冲突,并支持并行工作流。
-
部署控制器的选择,本质上涉及一组根本性的权衡。KServe 与 Kubernetes 原语(Deployment、Service、Ingress)原生集成,这让它对平台运维人员来说更熟悉,但在自动扩缩容等高级能力上通常需要额外组件。Ray 则提供了 Python-first 的开发体验,并内建分布式服务能力,但它也引入了自己的一层编排体系,与 Kubernetes 部分重叠,从而在调试或资源管理时增加了运维复杂性。
-
在采用控制器之前,先从手动部署开始,对于早期项目仍然是合理的。理解底层的 Deployment、PersistentVolumeClaim 和 GPU 资源配置,有助于你看清控制器究竟自动化了什么;而当抽象层泄漏、问题暴露出来时,这种理解也能帮助你更快诊断问题。
-
当推理基础设施已经就位后,还有一个关键部分尚未解决:模型本身。下一章将聚焦模型数据管理这一挑战,以及如何高效地将模型引入你的集群的策略。