从零开始训练一个 LLM,需要大量计算资源和专业能力,而这是大多数组织都不具备的。本章不会讨论如何从头创建模型,而是聚焦于:如何针对你的具体用例,对一个已有的 LLM 进行定制化。我们将介绍几种常见的调优技术,以及在 Kubernetes 上可用于实现和部署相应训练任务的相关技术。首先,我们先简要看看 LLM 是如何被创建出来的,以及"模型定制"在整个流水线中处于什么位置。
LLM 创建概述
不同模型提供方在 LLM 训练技术上的做法差异很大,而且它们通常会大量投入去开发专有方法。大多数伴随模型发布而公开的技术论文,往往都会省略实现细节,因此很难真正复现。DeepSeekV3 的技术论文是一个少见的例外,它提供了异常详细的技术文档。
当前许多创新主要集中在新的模型架构 上,尤其是更高效的 attention 机制。而对于数据集整理方式 以及调优方法,公开细节通常很少。
训练通常从数据清洗 和去重 开始。第一阶段------预训练(pre-training) ------会消耗绝大多数时间与成本:需要使用数千块 GPU,对全部数据进行处理,持续数周之久。这个阶段产出的结果,是一个基础模型(base model / foundation model) 。它能够预测文本,但还不具备对具体任务的理解,也不具备适当的内容边界意识。
下一步是 alignment(对齐) 。它的目标是让 LLM 能够按照人类偏好,以安全且可靠的方式执行任务。这个阶段有点类似于艾萨克·阿西莫夫提出的"机器人三定律":就像机器人需要一套核心原则,才能确保它们与人类安全互动一样,LLM 也需要一套行为边界,才能在执行任务时避免造成伤害。
对齐阶段需要经过整理的标注数据 以及一种奖励机制,由人类或专门的奖励模型来评估模型响应的质量。
确实可以找到那些只经历了预训练阶段的 base model,但绝大多数公开可用模型其实都已经经历过 alignment,因此它们已经可以用于某一类特定任务。
而模型定制 ,也就是通常所说的 post-training(后训练) ,就是发生在一个已经完成对齐的模型之上。图 6-1 展示了这一创建流水线的高层结构。
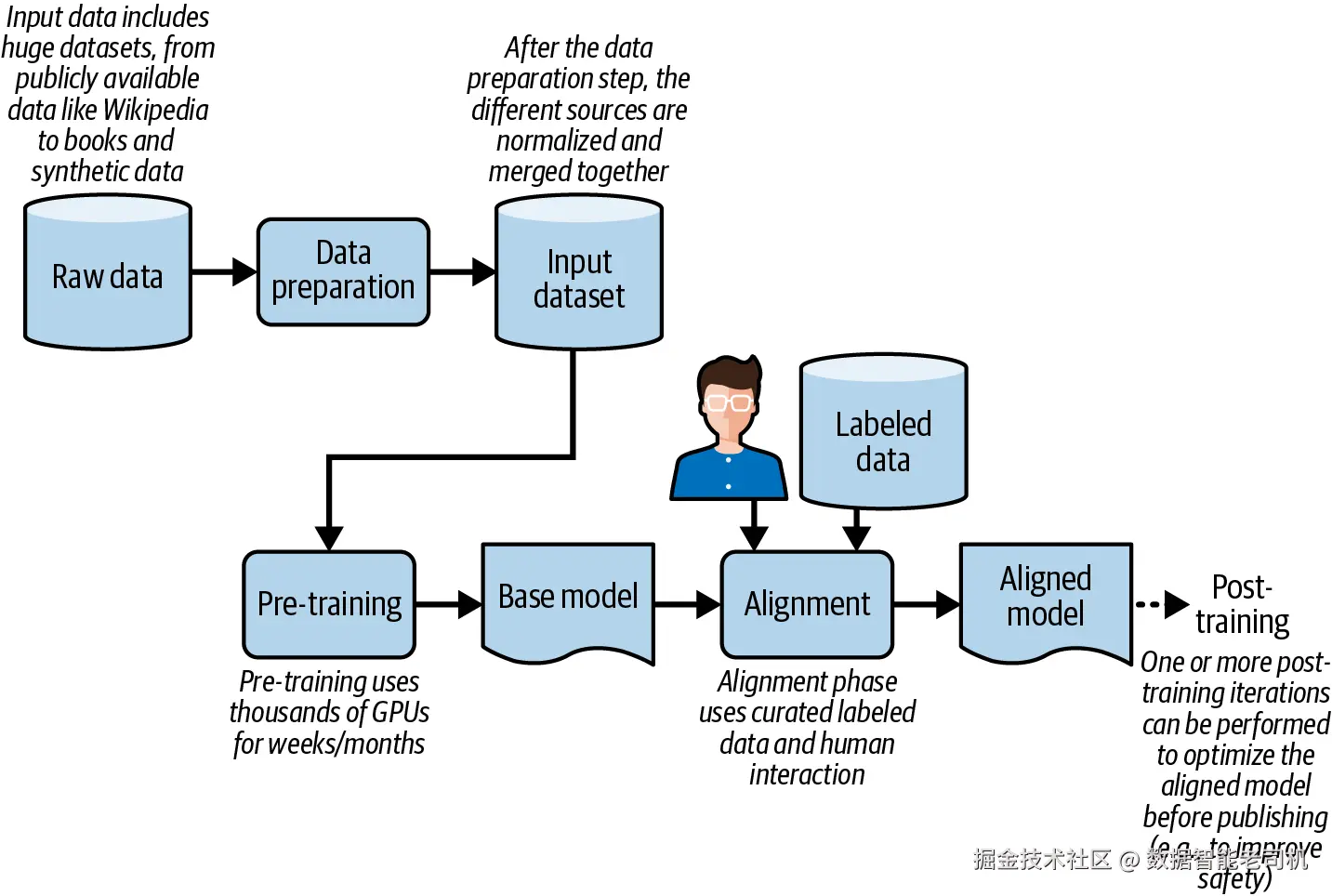
图 6-1 LLM 创建流水线
在本章中,你会反复看到诸如 model tuning 、model customization 和 post-training 这些术语在不同上下文中出现(下一侧栏会对这些概念做一个澄清)。
模型调优、模型定制与后训练
Model tuning(模型调优) 是一个比较宽泛的术语,用来泛指各种 fine-tuning 技术,并不专属于 LLM,它同样适用于预测式 AI。
Model customization(模型定制) 是一个更广的概念,它涵盖所有用于修改 LLM 或让 LLM 学会新任务的技术。其中有些方法与传统 fine-tuning 并不相同,甚至可能需要多步流程,包括人工参与。
Post-training(后训练) 指的是 LLM 创建流水线中的那个特定阶段,也就是模型定制发生的阶段。这个阶段可以执行多次,以增量方式向模型注入新的策略或知识。
在本书中,这几个术语经常会被交替使用,因为它们本质上都涉及"修改模型",而且在 Kubernetes 平台上会带来相似的运维挑战。
LLM 与传统预测式 AI 模型最本质的不同,在于它的通用性 。一个 LLM 可以执行大量不同任务,而传统机器学习模型通常只擅长单一任务。正因如此,我们先讲了推理:因为在很多情况下,你甚至完全不需要训练,只要对一个现有 LLM 做适当适配,就能用于不同场景。
在深入训练技术之前,先弄清楚"什么时候你根本不需要训练"是很有价值的。很多场景其实可以通过其他替代方案解决,从而完全避开训练带来的复杂性与成本。
Prompt 与上下文工程
LLM 真正强大的地方在于:它们在不修改模型本身的情况下就能发挥作用 。通过精心设计输入与上下文,你通常就能达到目标,而无需训练。这些替代方案不只是更简单,在很多场景下,它们甚至就是正确的选择。
Prompt engineering(提示工程) ,就是构造详细且具体的指令(prompt),以引导 LLM 输出的过程。这组指令对提升回答准确性至关重要。如今,这个领域几乎已经发展成一种独立专业:它形成了一整套最佳实践,用于指导人们如何更有效地与 LLM 沟通,从而获得尽可能准确的结果。
有效的 prompt engineering,并不仅仅是说明"任务是什么",还包括描述以下内容:
- 场景(scenario) ,例如:"这是一家名为 ABC 的航空公司"
- 模型应扮演的角色(role) ,例如:"你是一个帮助客户的 AI 助手聊天机器人"
- 任务边界(boundaries) ,用于减少幻觉或约束行为,例如:"你只能回答与我们公司相关的问题,并且只有在你确定答案时才回答"
这类 prompt 通常由服务提供方预先设置,并以 system prompt 的形式隐藏在最终用户看不到的地方。
不过,system prompt 不能被当作安全控制手段来依赖 ------因为它们可以被 prompt injection 或 jailbreaking 技术绕过。对于有安全要求的生产系统,还必须在应用层实现额外防护,例如输入校验、输出过滤和内容审核。
此外,由于每个 LLM 都只是在一个庞大但有限的数据集上训练出来的,因此 prompt engineering 的另一个重要用途,是把额外数据注入 prompt 中,强制模型在生成时使用这些信息。
基础的、手工式的 prompt engineering,后来逐渐演化为一系列成熟模式,使整个系统变得更强大,甚至可以让模型动态调用工具,以检索信息或执行动作。这正是 AI agent 的核心原则之一,通常被称为 context engineering(上下文工程) 。
之所以叫这个名字,是因为主要的工程工作,实际上都落在了"为 LLM 构造输入上下文"上;而这个过程往往是复杂的、多组件协同的,并且具有迭代性。
当前最广泛采用的上下文增强模式之一,就是 RAG(retrieval-augmented generation,检索增强生成) 。它会根据用户的问题,从外部数据源中检索相关信息,并把这些信息注入上下文。
在 RAG 模式下,额外数据会先通过专门的 embedding 模型,被转化为 embedding 向量并写入向量数据库。当用户请求到来时,系统会先针对向量数据库执行一次查询,通常使用相似度搜索算法(例如 approximate nearest neighbors,近似最近邻)来找出与用户输入在语义上最接近的内容。然后,这些额外上下文会被拼接进 prompt 中,供模型在回答时使用。
这种方案可以帮助注入模型训练时并不存在的外部知识或近期知识 ,例如企业私有数据,或者训练截止日期之后才发布的信息。虽然每个模型的上下文窗口有限,但 RAG 的应对方式并不是试图把整个知识库都塞进去,而是只筛选并注入与当前问题最相关的数据。
图 6-2 展示了一个 RAG 流水线的高层表示。关于 RAG 的实现模式与最佳实践,详见"Retrieval-Augmented Generation"。
如果你想回顾 embedding 相关知识,可以参考"Understanding LLM Fundamentals",尤其是其中关于 "Prefill" 的部分;不过,即使不复习这些背景知识,也并不妨碍你理解这里的内容。
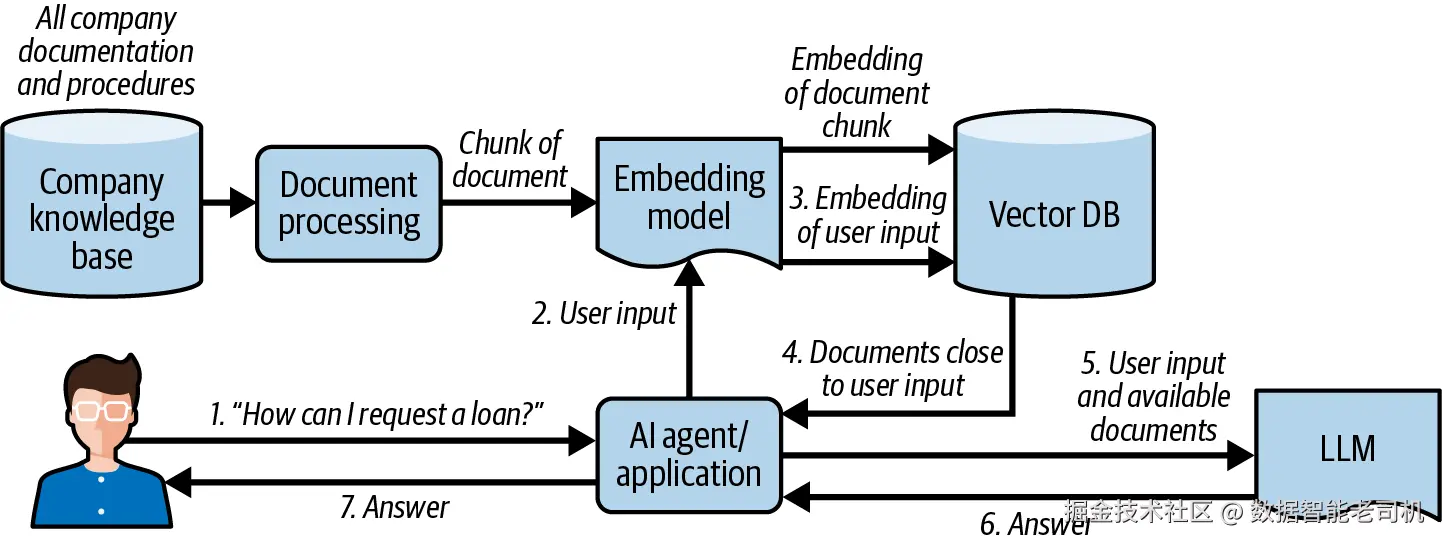
图 6-2 RAG 流水线示意
像 RAG 这样的方案之所以越来越流行,核心就在于它非常灵活。你可以在几分钟内把新数据写入向量数据库,从而刷新整套方案的"知识"。这一趋势,再加上 agentic AI 模式的普及,正在快速占领相当大一部分原本属于模型定制的空间。
有一点很重要:所有 prompt 与上下文工程技术,既适用于通用模型,也适用于已经调优过的模型 。你完全可以把 RAG 和模型定制结合起来使用。问题从来都不是"二选一",而是:哪种组合能在性能、成本与可维护性之间,为你带来最好的平衡?
什么时候应该做模型定制
虽然 RAG 与 prompt engineering 很强大,但它们并不总是成本效益最优的方案。
当你需要把知识或行为直接嵌入模型本身时,模型定制就会体现出价值。
通过 prompt 和 RAG 去影响模型行为,确实很强,也常常已经足够。
但这种方式有其局限,在某些场景下,模型定制会是更好的选择。
正如"vLLM Runtime Parameters Tuning"一节所说,较大的上下文窗口会在推理时消耗更多 GPU 显存。
因此,模型定制是控制推理成本的重要手段之一 。它可以把企业的一些核心知识------尤其是那些变化缓慢的知识------直接嵌入模型本身,从而减少每次请求都必须携带大上下文窗口的需要。
举个例子,一家银行可以创建一个定制化模型,把贷款、交易、信用风险等领域知识直接内化到模型里。这些信息变化并不频繁,因此把它们嵌入模型,比起在每次请求时都作为上下文重新提供,要合理得多。这样做的结果,就是更低的推理成本 ,以及潜在上更好的性能表现。
同样的原则也适用于模型大小。一个小而专用的模型(甚至可能是通过 distillation,从大模型蒸馏得到的)可以和一个更大的、未调优模型一样有效,甚至更有效。
这一点在 SLM(Small Language Model,小语言模型) 上尤其重要,因为它们所需的服务资源更少。一个 SLM 通常拥有 80 亿到 160 亿参数,因此在时间和资源受限的情况下,它会是一个很好的调优候选。
模型蒸馏(model distillation) 是另一种思路:用一个更大的 teacher model 去训练一个更小、更高效的 SLM,使后者继承前者的知识,同时又只需要更少的计算资源。
既然我们已经理解了何时应该做模型定制,接下来就来看看可以采用哪些具体训练技术。
模型调优
让一个模型持续训练、也就是通常所说的 post-training ,在机器学习领域并不是新鲜事。
在传统预测式 AI 中,模型经常会在第二阶段通过 fine-tuning 的方式,利用新数据对模型进行更新。
而在生成式 AI 语境下,这项工作通常是为了让模型在某个特定领域中更专门化、表现更好,同时通过使用更小、更专用的模型,来降低整个方案的总体成本,而不是一直依赖那些更大、更昂贵的模型。图 6-3 展示了一个高层流程:如何通过 fine-tuning,把新知识嵌入原始模型。

图 6-3 Fine-tuning 概念图
尽管 fine-tuning 相比 pre-training 的复杂度与成本要低一个数量级,但它仍然可能需要运行很多小时,甚至好几天。
不过,在某些情况下,根本不需要做完整 fine-tuning。比如,用户可能只是想缩小模型应该回答的领域范围------这有点类似前面提到的 prompt engineering 用例,只不过现在这类能力变成了模型的内建特性 ,并且更不容易受到外部攻击影响。
这一类更轻量的方法,被统称为 PEFT(Parameter-Efficient Fine-Tuning,参数高效微调) 。
无论是完整 fine-tuning,还是 PEFT 方法,Hugging Face 都提供了一个 TRL(Transformer Reinforcement Learning) 库,其中包含 SFTTrainer 这个工具类。它可以加载模型,并执行多种调优技术,同时还支持在训练中做评估以计算准确率。
什么是监督式微调(Supervised Fine-Tuning)?
SFTTrainer 里的 SFT,全称是 Supervised Fine-Tuning Trainer 。
之所以在很多场景中提到 fine-tuning 时通常省略 "supervised",是因为业内默认都知道这里讲的 fine-tuning 指的就是监督式过程。
虽然也存在一些非监督式 fine-tuning 技术,但绝大多数方法都需要有标注的数据作为输入------这些标注数据要么由人类完成,要么由其他模型完成。原因很简单:如果你希望模型学会某种特定策略或知识,那么输入数据集中就必须包含这种你希望模型学进去的特征。
不过,生成式模型所用的标注数据,与分类任务中的标注数据并不相同。
在分类任务中,标签通常是离散类别,例如 spam / not-spam;
而对 LLM 来说,标签则是完整的期望输出文本 。
训练样本通常是输入-输出序列对,例如:
- 输入:"Translate to French: Hello"
输出:"Bonjour" - 输入:"Summarize: article"
输出:"The article discusses X, Y, and Z."
在训练过程中,模型通过在输出序列的每一步预测"下一个词",并在预测错误时做调整来学习。
无论是分类还是生成,它们都属于"监督式"训练,因为训练时都提供了正确答案;只不过生成任务预测的是 token 序列,而不是单一类别。
构造监督式输入数据集,通常是一个非常昂贵的过程。
因此,这类精心整理的数据集,其规模往往比预训练时所用的无监督数据集小好几个数量级。
Fine-Tuning
对模型做 fine-tuning,本质上就是继续训练模型,以便把额外知识或任务能力嵌入进去,例如 instruction following、question answering 或 chat 能力。
换句话说,完整 fine-tuning 会修改模型的全部参数,从而产出一个新的独立模型。虽然它是从原模型衍生而来,但它已经被新的训练数据彻底适配过了。
这种做法需要相当可观的标注数据(通常至少要几十万条新样本),才能对模型产生足够强的影响,使其真正学会新概念。
因此,这是一项非常昂贵 的活动。
从 Kubernetes 平台的角度看,它意味着训练阶段需要大量 GPU;而在服务阶段,也需要单独的 GPU 来承载这个新模型,因为在推理时,几乎没有高效方式可以把它与原模型以"分层"或"组合"的形式融合起来。
虽然这在预测式 AI 中是主流做法,但在生成式 AI 里,完整 fine-tuning 面临的挑战更大:
- 数据集准备成本高
- 训练和推理本身都很昂贵
- 还存在 catastrophic forgetting(灾难性遗忘) 风险,也就是模型在学新东西时,把以前学过的知识忘掉了
前面已经提到,可以使用 Hugging Face 的 SFTTrainer 来执行这一类 fine-tuning(见示例 6-1)。
示例 6-1 使用 SFTTrainer 做监督式微调
ini
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoModelForCausalLM
train_dataset = load_dataset("json", data_files="my_file.json")
original_model = AutoModelForCausalLM.from_pretrained(...)
trainer = SFTTrainer(
model=original_model,
train_dataset=train_dataset,
)
trainer.train()
trainer.save_model("target_location")其中:
- 加载一个包含新内容的数据集,供模型学习。它可以是 Hugging Face 上的公开数据集,也可以是本地文件。
- 加载模型时所用的函数,与推理时用的是同一个。模型当然可以在线下载,但通常会先在本地准备好。
参数高效微调(Parameter-Efficient Fine-Tuning)
PEFT(Parameter-Efficient Fine-Tuning) 是一组调优技术的统称,它采用的是一种不同于完整 fine-tuning 的思路。
原始模型本身保持不变;相反,系统会构造一些新的层,在推理时与原模型一起组合,从而影响模型行为。
从概念上说,它和 prompt engineering 有点像:两者都试图在不彻底重训模型 的前提下影响模型行为。
但 PEFT 是把"学到的参数"直接嵌入模型架构里,而 prompt engineering 则是在运行时通过文本提示来影响模型。
从 Kubernetes 平台角度看,PEFT 在训练和服务两个阶段都更容易管理:
- 训练阶段只需要更少的数据样本(通常在 100 到 1000 条标注样本之间),因此训练任务更短,对硬件要求也更低。
- 服务阶段也更高效:基础模型可以在运行时与一个或多个调优层动态组合在一起,而且现代推理引擎已经原生支持这一点。
关于高效模型存储,见"OCI Image for Storing Model Data";
关于推理路由,见"LLM-Aware Routing"。
PEFT 的主要缺点在于:与完整 fine-tuning 相比,它对模型的影响是有限的 。完整 fine-tuning 会修改所有参数,而 PEFT 只会影响其中很小的一部分。
例如,LoRA(Low-Rank Adaptation) 是最流行的 PEFT 算法之一;在一个 Llama 3.1 8B 模型上,LoRA 可能只会调优不到 1% 的总参数。
Hugging Face 专门提供了一个名为 peft 的库,用来收集各种 PEFT 算法,而且它与 SFTTrainer 原生集成(见示例 6-2)。
示例 6-2 使用 SFTTrainer 做 LoRA 微调
ini
from datasets import load_dataset
from trl import SFTTrainer
from peft import LoraConfig
from transformers import AutoModelForCausalLM
train_dataset = load_dataset("json", data_files="my_file.json")
original_model = AutoModelForCausalLM.from_pretrained(...)
lora_config = LoraConfig(...)
trainer = SFTTrainer(
model=original_model,
train_dataset=train_dataset,
peft_config=lora_config,
)
trainer.train()
trainer.save_model("target_location")相比完整 fine-tuning,这里的唯一区别,就是初始化了一个 PEFT 配置(这里是 LoRA)。这个配置里有很多参数,详细说明可参考 Hugging Face PEFT 文档。
启用 PEFT 也很简单:只要把 lora_config 实例作为 peft_config 参数传进去即可。
LoRA 是目前应用最广泛的 PEFT 技术,因此值得进一步解释它究竟是如何工作的,以及为什么它会如此高效。
低秩适配(Low-Rank Adaptation)
LoRA(Low-Rank Adaptation) 的做法是:在训练时冻结原始模型权重 ,只训练一小部分新增参数。
这些新增参数会被组织成较小的矩阵,称为 adapter。这些低秩矩阵学习到权重更新,而它们的乘积会与原始权重结合起来发挥作用。
在传统 fine-tuning 中,训练过程会直接学习一个新的、与原权重同尺寸的完整矩阵,用来表示权重更新。
而 LoRA 则会把这个大的更新矩阵做分解:不是直接学习整个大矩阵,而是学习两个更小的低秩矩阵。当这两个小矩阵相乘时,它们的乘积就近似于原本那个完整更新矩阵。
正是这种分解方式,让训练变得显著更高效。图 6-4 对这一过程做了图形化展示。
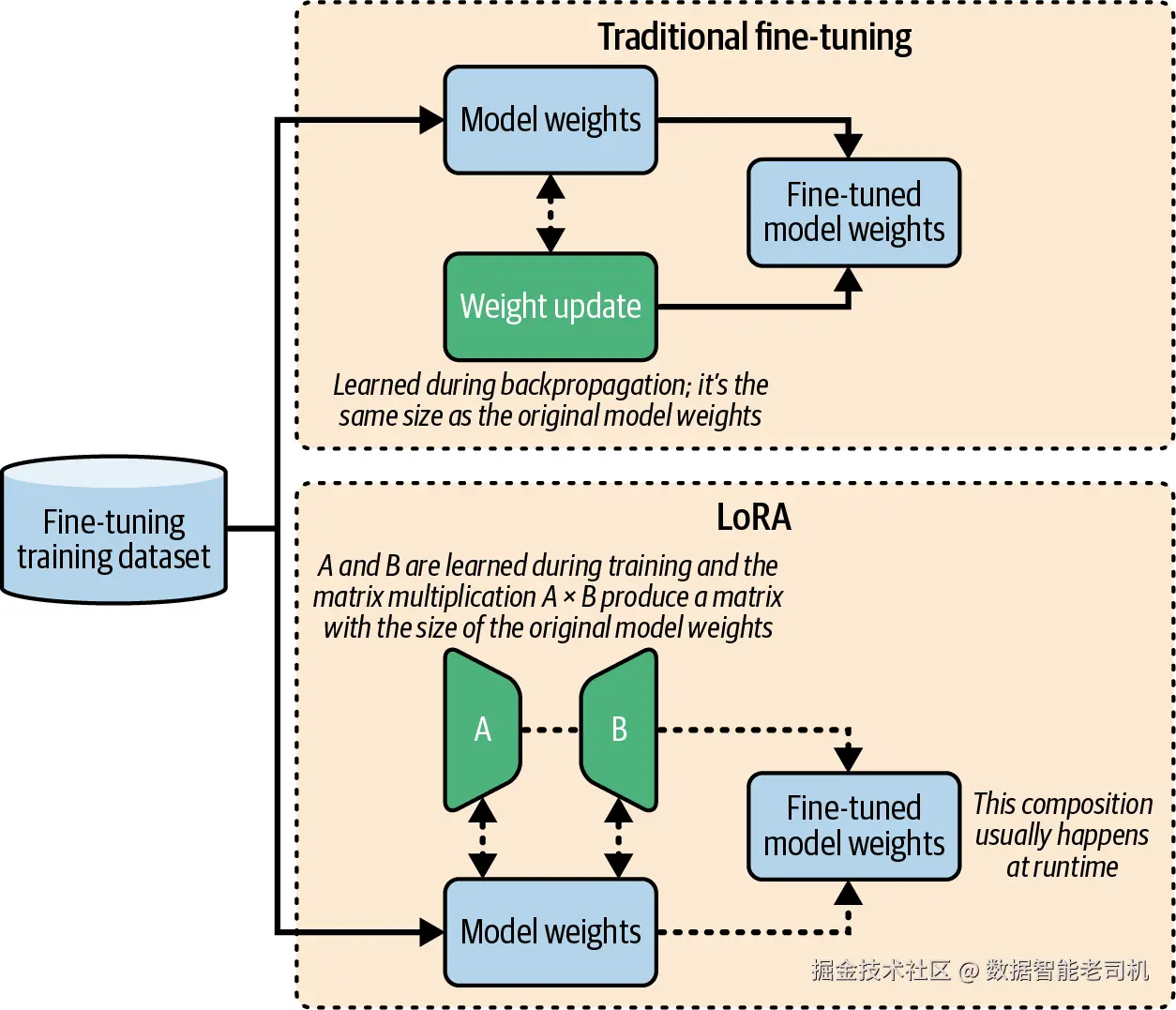
图 6-4 LoRA 分解与完整 fine-tuning 的对比
LoRA 适用于大量 LLM,并且还存在许多针对特定场景的变体。
其中两个比较典型的特化版本是:
- X-LoRA :把这一思路扩展到了 MoE(Mixture-of-Experts) 架构
- QLoRA:结合量化技术,以进一步降低 fine-tuning 过程中的显存需求
LoRA 有两个核心优势:
第一,训练阶段更便宜------无论是时间成本还是硬件成本,都明显低于完整 fine-tuning。
第二,推理阶段也更高效------因为 base model 本身没有被修改,所以 adapter 可以在运行时动态与之组合。
这两个小矩阵(A 和 B)的总大小,通常只相当于原始模型大小的 1% 到 10% 。因此,在只够服务一个 base model 的硬件条件下,你往往可以同时服务一个 base model 和多个 LoRA 微调模型。
图 6-5 展示了 LoRA adapter serving 的示意图。
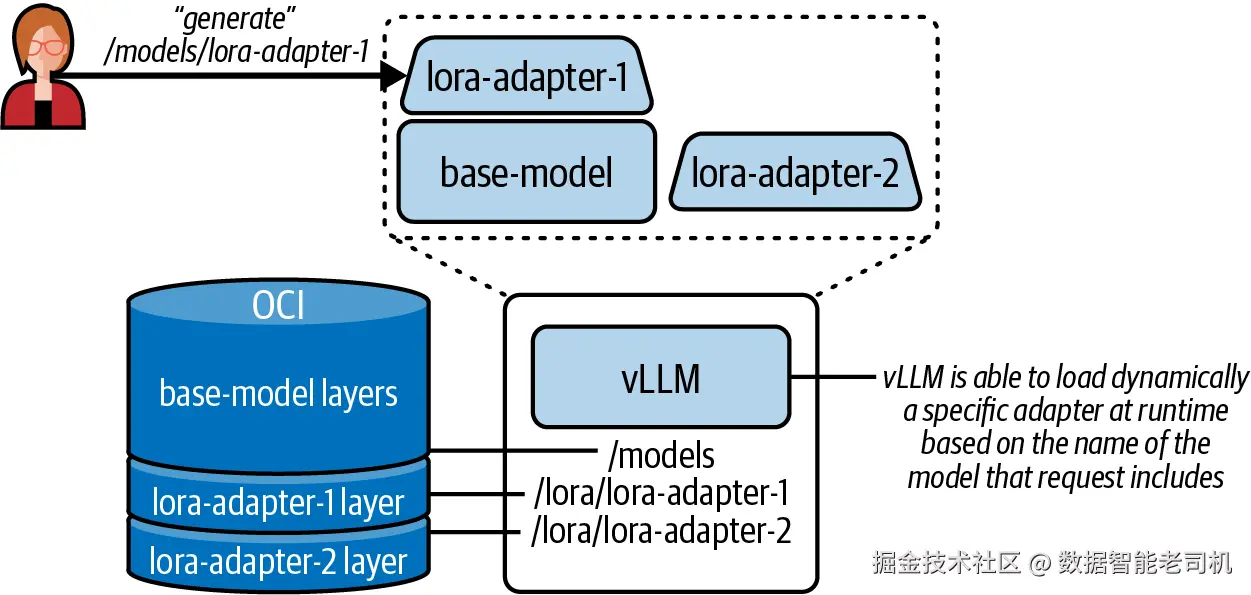
图 6-5 LoRA adapter 的服务方式
尽管这并不是 LoRA 的典型用法,但你仍然可以把 LoRA adapter 与 base model 合并起来,以便做测试。示例 6-8 展示了如何实现这一点。
如果你想更深入了解 LoRA,Sebastian Raschka 的博客文章 Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation) 很值得参考。
更高级的调优技术
完整 fine-tuning 和 PEFT 并不是调优模型的全部方式;新的、更复杂的技术还在不断出现。
其中很多新方法都不是单一训练循环,而是多步工作流,甚至会在前一轮迭代中先用模型生成 synthetic data,再拿这些数据进入下一轮训练。
较常见的高级技术包括:
- GRPO(Group Relative Policy Optimization)
- DPO(Direct Preference Optimization)
- 模型蒸馏(model distillation)
- 模型合并(model merging)
- 奖励建模(reward modeling)
本书不会详细展开这些高级方法,因为每一种方法本身都是一个复杂主题,而且它们彼此差异也很大。
例如,GRPO 是 DeepSeek 团队提出的一项创新;而 InstructLAB 则是 IBM Research 提出的一整套 alignment tuning 方法论。
如需进一步了解,可以参考 Hugging Face 的 TRL 库,它把很多这类技术都收录进来了,并为每种方法提供了对应的 trainer 类。
本书的重点在于生成式 AI 的运维挑战 。
从 Kubernetes 平台视角看,这些调优方法通常会表现为:长时间运行、涉及多个部署、绝大多数组件都需要专用 GPU、并且组件间必须安全通信 的复杂拓扑。
而这种通信的安全性,对生产工作负载至关重要,这一点会在"Training Job Security"中展开。
在 Kubernetes 上运行调优任务
在理解了不同调优技术及其权衡之后,下面这一节会转向它们在 Kubernetes 上如何落地运维。
到目前为止,我们已经介绍了创建和调优 LLM 的核心概念:从传统的完整 fine-tuning,到 PEFT,再到更复杂的调优流水线。理解这些不同方法很重要,因为从 Kubernetes 平台角度看,它们会带来不同的影响与挑战。
这一节将从具体实现细节,转向平台需求 。
所有这些调优技术,至少都包含一个需要 GPU 扩展的训练阶段。前几章中讲过的那些用于推理的 GPU 管理原则,在这里大多同样适用。关于如何为 GPU 配置 Kubernetes,以及如何调度依赖 GPU 的工作负载,可回看第 3 章。
虽然为 GPU 工作负载做资源供给并不是新鲜事,但在训练场景下,还有一个额外而巨大的挑战:网络很容易成为系统瓶颈 。
训练任务和推理请求完全不是一回事;即便只是一个 SLM,做调优时所需的硬件资源也往往高于服务同一模型时所需的资源。
因此,一个训练任务通常很可能需要同一节点上的多块 GPU,甚至跨多个节点的多块 GPU(见图 6-6)。
在这种场景下,根据具体所使用的调优方法,系统会在模型执行的每一个"step"之前,把模型的分片权重在所有 GPU 上汇聚起来(特别是在每一层的前向传播和反向传播过程中)。
这会导致 GPU 之间持续不断地进行数据洗牌(data shuffling),而根据模型大小和 GPU 数量不同,这种流量很容易达到每秒数 GB 。
带宽 ,因此成为训练可扩展性的首要挑战。
为解决这个问题,整个软件与硬件栈都必须协同优化:从专用网络接口与协议,到更高效的 kernel 实现,再到 GPU 特定指令。
和推理优化类似,训练也依赖一些能够利用专用 GPU 指令的 kernel 实现,例如 Liger Kernel(针对 Triton 优化) 和 FlashAttention。
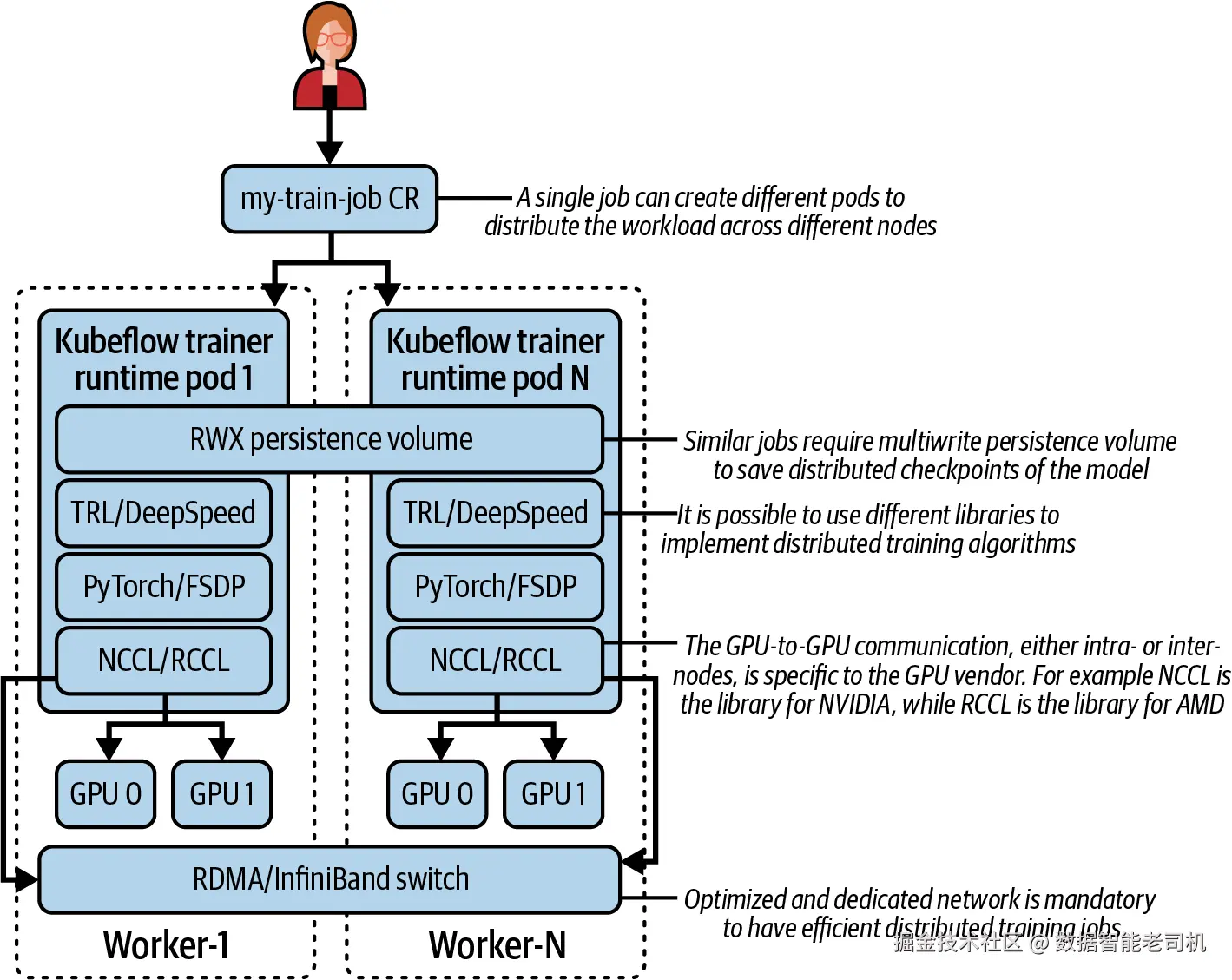
图 6-6 多节点训练任务
attention kernel 是一个核心组件,通常被封装在更高层、面向最终用户的库里。
虽然 Hugging Face 提供了很多这类库,例如 Transformers,但也存在其他选择,例如 DeepSpeed 和 NVIDIA 的 Megatron-LM。
尽管这些库在 API 和配置方式上有所不同,但它们几乎都构建在 PyTorch 之上。
而 PyTorch,如今已经成为 LLM 实现中事实上的标准深度学习库。
注意(NOTE)
PyTorch 是一个开源机器学习库,最初由 Meta 创建,现在归属于 Linux Foundation 旗下的 PyTorch Foundation。
它有很多不同用途;但在 LLM 开发语境中,它主要被用作核心深度学习库:像 Hugging Face Transformers 这样的终端用户库,本质上都是基于 PyTorch 构建的,并且已经逐步放弃了对 TensorFlow 或 JAX 等其他深度学习库的支持。
PyTorch 项目包含很多不同的软件包,覆盖从神经网络核心实现,到编译器,再到专门支持分布式训练的 distributed package 等大量能力。
其中,FSDP2(Fully Sharded Data Parallel) 是最常用的、用于把训练任务扩展到多节点的库之一。
无论软件栈还是硬件栈,都还在快速演化。理想情况下,未来这些复杂性会越来越多地被隐藏成实现细节,不再需要平台使用者显式关心。
但优化网络栈仍然是无法绕开的挑战,这一点会在"Network Optimization for Distributed Training"中重点讨论。
而要在大规模上管理这种复杂性,就需要一套专门工具,把分布式训练基础设施从数据科学家的视角中抽象出去,让他们能够专注于模型开发本身。
Kubeflow Trainer
Kubeflow Trainer 是 Kubeflow 生态中的一个组件,专门用于管理 LLM fine-tuning 的扩展与分布式执行。
Kubeflow 项目的目标,是成为 Kubernetes 上 AI 平台的基础设施;它最初源于预测式 AI,如今正在不断演进,以支持生成式 AI 工作负载。
在第 2 章中,我们已经介绍过 Kubeflow 的另一个组件------Kubeflow Model Registry(见"Kubeflow Model Registry")。
Kubeflow Trainer 的唯一目标,就是管理那些在 Kubernetes 上配置、部署和扩展长时间运行训练任务时所需要的基础构件。
它的 API 是为两类不同角色而设计的:
- 平台管理员(platform administrator) :通过
TrainingRuntime配置集群与可用资源 - 数据科学家 / AI 工程师 :通过
TrainJob提交训练任务
由于这两类角色拥有不同技能与工具链,Kubeflow Trainer 还提供了一个 Python Kubeflow SDK ,它可以把 TrainJob 的创建过程抽象起来,让数据科学家不必直接与 Kubernetes 资源打交道。
图 6-7 展示了 Kubeflow Trainer 的完整架构。
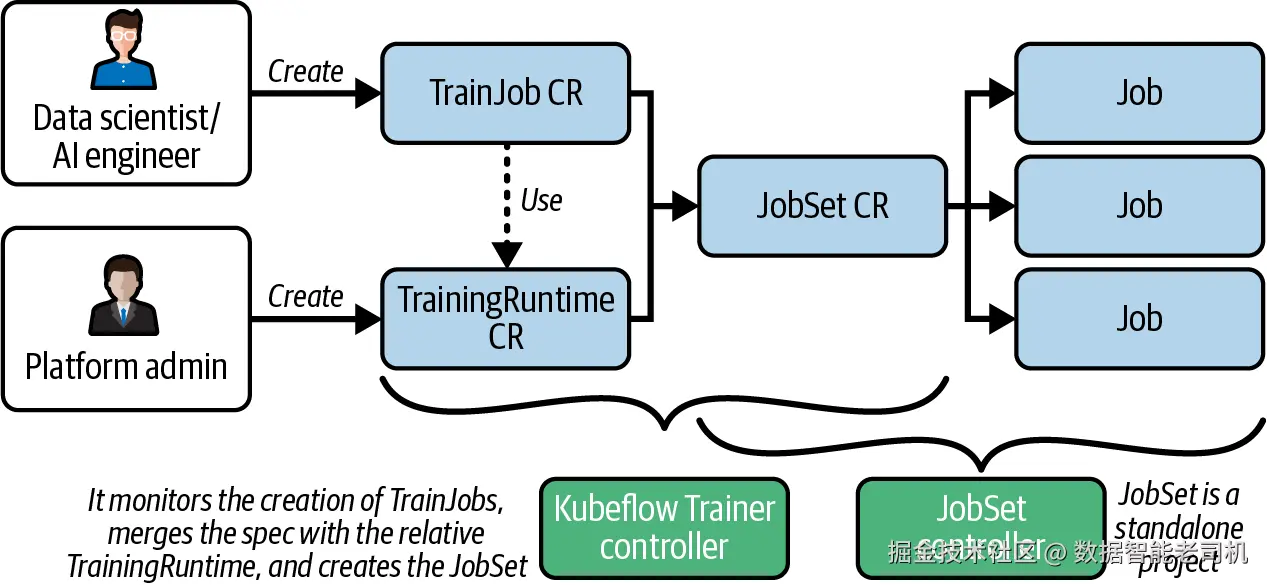
图 6-7 Kubeflow Trainer 架构
TrainingRuntime(以及面向全集群配置的 ClusterTrainingRuntime)与推理场景下 KServe 的 ServingRuntime 是对应关系,这一点在"KServe"一节中已经介绍过。
它本质上是一个模板,用来声明某种 runtime(例如 PyTorch)可用,并描述其容器镜像及其他选项。
与 ServingRuntime 类似,TrainingRuntime 只在其所在 namespace 内可见,而 TrainJob 必须与其位于同一 namespace 才能使用它。
而 ClusterTrainingRuntime 则对整个集群可见。
Kubeflow Trainer 支持多种分布式训练框架,例如 PyTorch 、DeepSpeed 、MLX 和 MPI 。
也正因为支持多框架,它要求 TrainingRuntime 必须带有一个 trainer.kubeflow.org/framework 标签。
SDK 会使用这个标签,为对应框架(例如 PyTorch 对应的 torch)及其 trainer 应用正确配置。
这里的 trainer ,指的是那个使用底层框架来定义并执行训练任务的库;它既可以是 BuiltinTrainer ,也可以是 CustomTrainer。
- BuiltinTrainer(例如 TorchTune)会提供一个预定义好的训练脚本,适合一些常见用例,例如 LLM fine-tuning。你只需要给它传入输入数据集和 LoRA 配置等参数即可。它灵活性较低,但上手更容易。
- CustomTrainer 则完全交由用户掌控:用户可以定义一个 Python 函数,把整个训练流程都写进去。这样一来,数据科学家拥有最大灵活性,而管理员只需要定义与之兼容的
TrainingRuntime即可。
TrainJob 对象定义了训练代码,并引用某个 training runtime。正如前面所说,SDK 会把这些配置过程大大简化,因此数据科学家不需要手写这些对象。
当 TrainJob 被创建后,Kubeflow Trainer controller 会把它与 TrainingRuntime 合并,生成一个 JobSet 以及相应的 Kubernetes jobs。
JobSet 是一个 Kubernetes 自定义资源,用来表示一组 Kubernetes job。
它来自一个独立的 JobSet 项目,目标是统一 Kubernetes 上 HPC 与 AI/ML 训练工作负载的部署 API。
Kubeflow Trainer 的安装和其他 Kubernetes controller 一样,比较直接(见示例 6-3)。
示例 6-3 安装 Kubeflow Trainer
ini
export VERSION=v2.1.0
export URL="https://github.com/kubeflow/trainer.git/manifests/overlays"
kubectl apply --server-side -k "${URL}/manager?ref=${VERSION}"
kubectl apply --server-side -k "${URL}/runtimes?ref=${VERSION}"这里:
- 用你希望安装的版本替换变量值,例如
v2.1.0。 - 虽然 Kubeflow Trainer 项目内置了一组
ClusterTrainingRuntime,方便快速上手,但在生产环境中,通常预期是由管理员自己定义一组经过筛选的 runtime。
Kubeflow Trainer 提供了一套内置的 ClusterTrainingRuntime,但它们并不是必须使用的。你完全可以跳过这一步安装,转而使用一个或多个自定义 runtime 来替换这些默认项(见示例 6-4)。
示例 6-4 ClusterTrainingRuntime
yaml
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: my-torch-distributed-runtime
labels:
trainer.kubeflow.org/framework: torch
spec:
mlPolicy:
numNodes: 1
torch:
numProcPerNode: auto
template:
spec:
replicatedJobs:
- name: node
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
template:
spec:
containers:
- name: node
image: pytorch/pytorch:2.7.1-cuda12.8-cudnn9-runtime 其中:
- 如果你想创建的是 namespace 级别的 runtime,而不是全集群可见的版本,就把
ClusterTrainingRuntime换成TrainingRuntime。 - 数据科学家会通过这里定义的名字来选择自己想用的 runtime。
- SDK 会利用这个 label 来指导
TrainJob的配置。 spec中可以定义很多默认值,例如这里就表示该任务最多只能使用一个节点。- 管理员往往会想控制集群中允许使用的镜像,因此可以把这里的镜像替换成内部定制镜像。该镜像通常和 GPU 厂商绑定;这里这个镜像显然是针对 NVIDIA CUDA 的。
当集群配置完成、TrainingRuntime 已经可用之后,平台管理员的工作基本就完成了。接下来,数据科学家就可以专注于创建训练任务(见示例 6-5)。
示例 6-5 使用 Hugging Face TRL 编写 CustomTrainer 函数
ini
def my_custom_trainer(**kwargs):
from datasets import load_dataset
from transformers import AutoTokenizer, set_seed
from trl import SFTTrainer
# It is not mandatory to set a fixed seed but it is useful for reproducibility
set_seed(kwargs["seed"])
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(
..., # kwargs[...]
use_fast=True
)
# Load datasets
train_dataset = load_dataset(
..., # kwargs[...]
)
# Initialize Trainer
trainer = SFTTrainer(
model=...,
args=...,
train_dataset=train_dataset,
eval_dataset=...,
peft_config=...,
processing_class=tokenizer,
)
trainer.train()
trainer.save_model(
..., # kwargs[...]
)这里有几点要注意:
- 这个自定义 trainer 函数必须是自包含 的,因此 import 语句也必须写在函数体里。这个例子使用的是 Hugging Face 系列库:
datasets用于加载训练集(以及可选的评估集),transformers用于 tokenizer,trl用于真正的 trainer 类。要注意,这里没有任何 Kubeflow Trainer 专属代码;它只是一个普通的 Python 训练函数,本身就可以被直接调用。 - tokenizer 与被调优的模型是对应的。为了避免训练过程被 tokenizer 成为瓶颈,最好使用支持并发的 fast tokenizer。
- 数据集承载着模型在 fine-tuning 中要学习的新知识。它可以是公开数据集,但更常见的是自定义数据集。
SFTTrainer的初始化方式与前面示例一致。这里就是你选择模型、指定数据集以及配置 PEFT 技术(例如LoraConfig)的地方。train()方法会真正启动训练。像 GPU 数量、worker 数量等硬件配置不在这里指定,而是在创建 job 时再定义(见示例 6-6)。
注意(NOTE)
当你调用 client.train(func=my_custom_trainer) 时,SDK 会把你的 Python 函数序列化,并嵌入到 TrainJob 自定义资源中。
而 TrainingRuntime 所使用的基础容器镜像(其中已经预装了 PyTorch、Transformers、PEFT 等依赖)会在运行时把这个函数反序列化并执行。
这与传统 Kubernetes 工作流很不一样:你不需要 为了修改训练逻辑去重新构建和推送自定义镜像------只需重新运行一遍 SDK 命令即可。
它的代价是:基础镜像必须已经包含你所需的全部依赖,而且你的函数必须是可序列化的(例如 import 只能引用已安装包,不能带复杂闭包)。
在 trainer 函数中定义好训练逻辑和配置后,接下来就可以通过 Kubeflow Python SDK 创建 TrainJob 了。
示例 6-6 通过 Kubeflow SDK 创建 TrainJob
ini
from kubeflow.trainer import CustomTrainer, TrainerClient
client = TrainerClient()
torch_runtime = client.get_runtime("my-torch-distributed-runtime")
job_name = client.train(
trainer=CustomTrainer(
# The custom trainer function is injected here with its parameters
func=my_custom_trainer,
func_args=..., # load_args()
num_nodes=8,
resources_per_node={
"cpu": 4,
"memory": "64Gi",
"nvidia.com/gpu": 1,
},
),
runtime=torch_runtime,
)
client.wait_for_job_status(name=job_name, status={"Running"})
_ = client.get_job_logs(job_name, follow=True)
# It is possible to get all the steps and the status for each of them
# steps = client.get_job(name=job_name).steps
# client.delete_job(job_name) 其中:
- 这个例子里,通过前面定义的函数构造了一个
CustomTrainer,然后由TrainerClient提交对应的TrainJob。 - 硬件需求是在 job 提交时指定的。硬件配置与模型大小以及所采用的调优方式直接相关。这个示例的配置,适合用 PEFT LoRA 去定制一个
Meta-Llama-3.1-8B-Instruct模型。 - client 可以等待某个特定状态出现。这里这是一个阻塞调用,示例中用它来等待 job 进入
Running状态。你还可以拉取日志,或者配置 TensorBoard。TensorBoard 最初来自 TensorFlow 项目,但现在已经兼容包括 PyTorch 在内的多种库。 - 虽然你可以随时删除 job,即便它还在运行中也可以,但这样做也会把
TrainJob对象及其在 Kubernetes 中的关联元数据一并删除。如果你没有外部实验跟踪系统,那么最好保留已完成任务,以便留下训练记录。
一点 YAML 魔法
像示例 6-6 这样的训练任务,需要很多参数,常常超过 10 个。如果 job 创建代码是在 Jupyter Notebook 中运行的------例如借助 Kubeflow Notebooks 组件------那么就可以通过一个叫 yamlmagic 的库,非常方便地管理这些参数。
这个项目是一个 Python 模块,可以通过 pip install yamlmagic 安装,并用 %load_ext yamlmagic 载入。
加载之后,你可以使用一个以 %%yaml my_params 开头的 notebook cell,把参数写成 YAML。
从第二行开始的内容会被解析成 YAML,并自动转成 Python 字典 my_params,可以直接拿来用。示例 6-7 展示了如何在 Jupyter Notebook 中使用 yamlmagic 配置训练参数。
示例 6-7 在 Jupyter Notebook 中使用 yamlmagic 配置训练参数
ini
# In a Jupyter Notebook cell
%load_ext yamlmagic
%%yaml training_config
model_name: meta-llama/Llama-3.2-3B
dataset: openai/gsm8k
num_epochs: 3
learning_rate: 2.0e-4
output_dir: /mnt/models/llama-gsm8k
# Now use the config with Kubeflow SDK
from kubeflow.trainer import TrainingClient
client = TrainingClient()
client.train(
name="llama-math-tuning",
model=training_config["model_name"],
dataset=training_config["dataset"],
num_epochs=training_config["num_epochs"],
learning_rate=training_config["learning_rate"],
output_dir=training_config["output_dir"]
)在 LoRA 示例中,训练过程并不会产出一个新的完整模型;相反,每个保存下来的 checkpoint 都是一个 LoRA adapter ,它可以在运行时动态与 base model 组合。
这正是图 6-5 所描述的那种高效服务多个调优模型的方式。
当然,这并不是最适合高效 serving 的方式;但在某些测试场景中,把 LoRA adapter 与 base model 合并,生成一个新的独立模型仍然很有用。这个场景在示例 6-8 中说明。
示例 6-8 将 LoRA adapter 与 base model 合并
ini
from peft import PeftModel
from transformers import AutoModelForCausalLM
base_model = AutoModelForCausalLM.from_pretrained(
...,
device_map="cuda"
)
finetuned_path = "/opt/app-root/Meta-Llama-3.1-8B-Instruct/checkpoint-100/"
model = PeftModel.from_pretrained(base_model, finetuned_path)
merged_model = model.merge_and_unload()
merged_model.save(...)这里:
- 必须先加载 base model。
device_map参数会让模型直接加载到 GPU 上。 - 你需要知道 LoRA 调优结果存放的路径。训练过程中每经过一个 epoch,都会生成一个新的 checkpoint(也可视作一个 model candidate);这里例子中选择的是编号为 100 的 checkpoint。
- 当 base model 和 fine-tuned layer 一起被加载之后,就可以通过
merge_and_unload()方法把它们合并成一个新模型。
示例 6-8 从管理员和数据科学家的双重视角,展示了 Kubeflow Trainer 在一个分布式模型定制项目中的协作方式。
而像 /opt/app-root/Meta-Llama-3.1-8B-Instruct/checkpoint-100/ 这样的 checkpoint 路径,显然依赖于持久化存储基础设施,否则它们会随着短暂训练任务结束而消失。
关于训练工作负载的存储解决方案,包括 PersistentVolumes、对象存储和分布式文件系统,可参见"Storage for Training"。
不过,这还只是第一步。
从平台视角看,如何调度这类长时间运行、资源密集型 的工作负载,还需要额外优化,以确保集群公平使用资源,并避免尤其是 GPU 这类昂贵硬件被低效占用。
这里尚未展开的一个重要挑战,就是 gang scheduling(组团调度) 。分布式工作负载往往要求系统中的所有 Pod 同时 部署成功,任务才能正确启动。这是一种典型的"要么全有,要么全无 "语义。
第 7 章会专门聚焦这些平台级优化,其中就包括对 gang scheduling 的独立讨论。
对于数据科学家来说,使用体验要简单得多,因为 Kubeflow 生态能让他们把关注点放在模型定制生命周期本身,而只需有限了解底层 Kubernetes 平台。
提示(TIP)
Kubeflow 项目包含很多组件,用于支持完整的 MLOps 或 LLMOps 生命周期。
例如,"Kubeflow Model Registry"一节已经介绍了 Kubeflow model registry,重点在于模型元数据管理;而本章介绍的 Kubeflow Trainer,则用于支持分布式训练任务。
数据科学家还可以借助另外两个 Kubeflow 组件,来开发和管理 fine-tuning 示例中的 Python 代码:Kubeflow Notebooks 和 Kubeflow Pipelines。
- Kubeflow Notebooks 提供了对基于 Web 的 IDE(例如 Jupyter)的基础设施管理,使数据科学家能够自助式地创建环境,并方便地试验 Kubeflow Trainer SDK。
- 当他们完成实验并定义好训练任务之后,就可以用 Kubeflow Pipelines 把 notebook 转换成一个可复现的 pipeline。这样,这套逻辑就能被多次执行,用于模型再训练;既可以把 notebook 代码拆解成多个独立步骤,也可以直接把 notebook 整体嵌入到 pipeline 中。
其他框架
虽然 Kubeflow Trainer 对绝大多数用例来说已经是一个很完整的方案,但生态中还有若干值得考虑的替代方案。
Kubeflow Trainer 的设计思路,是用 Kubernetes-native 的方式来管理分布式训练任务的生命周期,同时允许平台管理员和数据科学家继续使用各自熟悉的工具。
不过,除了 Kubeflow Trainer 和 Hugging Face 的 TRL 这种偏平台型、以 Kubernetes 为核心的训练方案之外,还有一些项目和库更专注于 fine-tuning 过程本身的效率、速度与资源管理,例如 DeepSpeed 、Unsloth ;此外,结合 KubeRay 的 Ray 也为 Kubernetes 上分布式训练工作负载提供了另一种编排思路。
DeepSpeed
DeepSpeed 是一个深度学习优化库,它封装在 PyTorch 之上,目的是简化训练任务管理。
在 Kubeflow Trainer 中使用 DeepSpeed,与前面的例子非常相似:你只需要选择一个兼容 DeepSpeed 的 TrainingRuntime(例如默认的 DeepSpeed distributed runtime),然后稍微改造一下自定义 trainer 逻辑(见示例 6-9)。
示例 6-9 使用 DeepSpeed 的 trainer 函数
ini
def my_custom_deepspeed_trainer(**kwargs):
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
from datasets import load_dataset
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
import deepspeed
# Initialize DeepSpeed distributed training
deepspeed.init_distributed(dist_backend="nccl")
local_rank = int(kwargs["local_rank"])
# Set seed for reproducibility
set_seed(kwargs["seed"])
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(..., use_fast=True) # kwargs[...]
# Load datasets
train_dataset = load_dataset(...).with_format("torch") # kwargs[...]
train_loader = DataLoader(
dataset, batch_size=16, sampler=DistributedSampler(dataset)
)
# DeepSpeed configuration
ds_config = {
..., # kwargs[...]
}
# Initialize DeepSpeed engine.
model_engine, _, _, _ = deepspeed.initialize(
model=model,
config=ds_config,
model_parameters=model.parameters(),
)
num_epoch = int(...) # kwargs[...]
for epoch in range(num_epoch):
for batch_idx, batch in enumerate(train_loader):
for key in batch.keys():
batch[key] = batch[key].to(local_rank)
outputs = model_engine(batch)
loss = outputs.loss
model_engine.backward(loss)
model_engine.step()
model_engine.module.save_pretrained(...) # kwargs[...]
tokenizer.save_pretrained(...) # kwargs[...]这里:
- 你必须先初始化分布式训练。这里的
nccl用于 NVIDIA CUDA 硬件,而local_rank是作为训练脚本参数传入的环境变量。 - 示例中用 Hugging Face
datasets库加载数据集,并且可以很方便地转成 PyTorch dataset。 - engine 初始化会返回多个变量,但在这个例子里只需要
model_engine。 - 这个示例中训练循环写得比较显式,清楚展示了 forward pass、loss 计算和 backward pass。
Ray
虽然 Kubeflow Trainer 的灵活性已经足以应对大多数模型定制技术,但它并不是 Kubernetes 上分布式计算的唯一框架;Ray 也是一个有效选择。
Ray 提供了一整套面向 AI 平台的组件生态,之前在"Ray Serve and KubeRay"一节中已经提到过。
它的核心概念(例如 RayCluster,见图 1-5)本身就是通用的,因此同样适用于训练场景。Ray 与 Kubernetes 的集成则由 KubeRay 负责,它提供了所需 API。
这意味着,你可以先部署一个 RayCluster,然后再提交一个 RayJob,去执行一个长时间运行的、多节点的模型定制计算任务。
整体流程与 Kubeflow Trainer 的例子类似:你需要准备一个包含训练逻辑的 Python 脚本,创建 RayCluster(这一点 Kubeflow Trainer 不需要),然后再部署 job。
不过,两者在代码交付方式上存在明显差异:
- Kubeflow Trainer 会把 Python 函数序列化后直接注入资源对象
- Ray 则要求训练脚本已经被打包进容器镜像,或者可通过远程位置访问(例如 Git 仓库、挂载卷)
也就是说,在 Ray 中,RayJob CR 引用的是脚本路径,而不是把代码本身嵌进去。
这意味着:Ray 在代码变更后通常需要重新构建容器,因此它更适合那些本来就已经在使用 Ray 生态的团队;而 Kubeflow Trainer 的做法支持更快的"改完代码立即重跑",更适合快速实验。
如果你想看一个完整的、基于 DeepSpeed 和 Ray 的 LLM fine-tuning 示例,可以参考 opendatahub-io 仓库中的例子,它使用 CodeFlare SDK 来程序化配置 KubeRay 资源。
警告(WARNING)
要特别注意,不要把 Ray Tune 和 LLM 的"模型调优"混为一谈。
Ray Tune 是一个专门用于超参数调优与优化 的模块,它主要适用于预测式 AI。
在 Kubeflow 生态中,与之对应的项目是 Kubeflow Katib。
虽然 Ray Tune 不是为模型定制而设计的,但你仍然可以把它与 Hugging Face Transformers 结合起来,执行像 Population Based Training(PBT) 这样的超参数优化方法,这一点可参考相关示例。
Unsloth
Unsloth 这个项目专门面向 LLM 定制过程,目标是让它变得简单、快速,并且硬件要求有限 。
它拥有一个非常活跃且规模不小的社区。
虽然它本身并不是为 Kubernetes 上的大规模基础设施而设计的,但它的上手门槛很低,只要作为普通 Python 包在本地安装即可(pip install unsloth)。
从这个意义上说,它有点像 fine-tuning 领域里的 Ollama 或 llama.cpp ------只不过后两者主要面向本地推理。
尽管 Unsloth 本身是作为本地库设计的,但也可以借助 AIKit 项目把它部署到 Kubernetes 上。
经验总结
本章中,我们探讨了模型定制技术:从 prompt engineering,到完整 fine-tuning,再到如何在 Kubernetes 上运行训练任务。
大多数组织都没有足够资源去从零训练 foundation model。
模型定制通常是从一个已经完成 alignment 的基础模型开始的------这种模型已经具备任务理解能力,也已经有了安全边界------然后再通过 post-training 技术进一步专门化。
究竟应该选择 prompt engineering、PEFT,还是完整 fine-tuning,取决于你的数据集规模、可用计算预算,以及你希望对模型行为施加多大程度的改变。
完整 fine-tuning 会修改模型的全部参数,并产出一个新的独立模型。
这意味着在训练和推理两个阶段,它都需要独占的 GPU 资源。
这种方法通常需要几十万条标注样本,训练时间从多天到数周不等,而且往往需要多块 GPU 并行进行。
它还伴随着灾难性遗忘风险,也就是模型可能丢掉此前学会的知识。
从运维角度看,每一个 fine-tuned 模型都会成为一个独立部署制品,并拥有自己独立的 serving 基础设施。
PEFT 技术 ,例如 LoRA,则只修改不到 1% 的模型参数,生成的是一层 adapter,而不是一个完整模型。
这些 adapter 可以在推理时与 base model 动态组合。
训练通常只需要 100 到 1000 条标注样本,完成时间以小时计而不是天计。
多个 LoRA adapter 甚至可以共享同一个 base model deployment,从而降低显存占用,并支持根据请求路由动态选择 adapter。
Kubeflow Trainer 为 fine-tuning 任务提供了 Kubernetes-native API。
其中,TrainJob 自定义资源负责分布式训练协调;而它与 TRL 的 SFTTrainer 以及 Hugging Face PEFT 库的集成,又让训练参数可以声明式配置。
这种分工方式,使平台团队能够专注于任务调度与资源分配,而数据科学家则把精力放在数据集准备与超参数调优上。
它们之间的交接工作流其实很清晰:
平台工程师预先把 TrainingRuntime(包括容器镜像、集群策略、可用资源等)配置成集群级模板;
数据科学家则通过 Kubeflow Python SDK 提交 job,只需给出训练函数、数据集引用、超参数以及资源请求。
SDK 会把这些 Python API 调用翻译成 TrainJob 自定义资源,因此数据科学家无需手写 YAML,也无需直接理解 Kubernetes 原语。
平台团队负责监控 job 执行、管理集群容量,并处理诸如存储供给和网络优化等基础设施问题;而 SDK 则把这些复杂性从数据科学工作流中抽象掉了。
训练任务管理与推理服务在运维模式上有本质不同。
训练 job 是有明确完成条件的批处理工作负载 ,而不是长时间运行的服务。
因此,资源分配更偏向吞吐量而非延迟;checkpoint 管理对于应对抢占和恢复至关重要;而 gang scheduling 则能避免部分资源分配成功、部分失败,导致昂贵 GPU 节点被长时间卡死。
下一章将继续讨论:如何在生产规模上应对这些运维模式,包括 gang scheduling 、拓扑感知放置 、配额管理 和 网络优化。