翻译自:Claude Code vs. Codex: The Definitive Guide
我用了几个月 Claude Code,后来转投 Codex,最近又换回了 Claude。选它的原因跟 benchmark 跑分无关。我也拿同一个任务测试过两者。
本文内容 :我会聊聊 Claude Code 和 Codex 的各个方面,驱动它们的旗舰模型 Opus 4.6 vs. GPT-5.3-Codex 有什么区别,哪些因素真正影响你的 AI 编程体验,以及一个小型案例------我是如何用这两个工具搭建同一个 RAG pipeline 的。
先说清楚,这篇文章大概需要 12 分钟阅读时间。如果你打算每个月花 200 美元订阅其中之一,这时间花得值。
Opus 4.6 vs. GPT-5.3-Codex:任务完成时间跨度
Codex 和 Claude Code 之间有一个可靠的对比维度:任务完成时间跨度 (Completion Time Horizon),详见此处。
这个指标回答的问题是:这个模型能可靠地完成多长时间的任务? 任务完成时间跨度指的是模型以一定可靠性成功完成任务的时长(按人类专家完成时间衡量)。所以一个"2小时跨度 50%成功率"意味着:给你一个人类专家需要 2 小时的任务,AI 大约有五成把握能搞定。
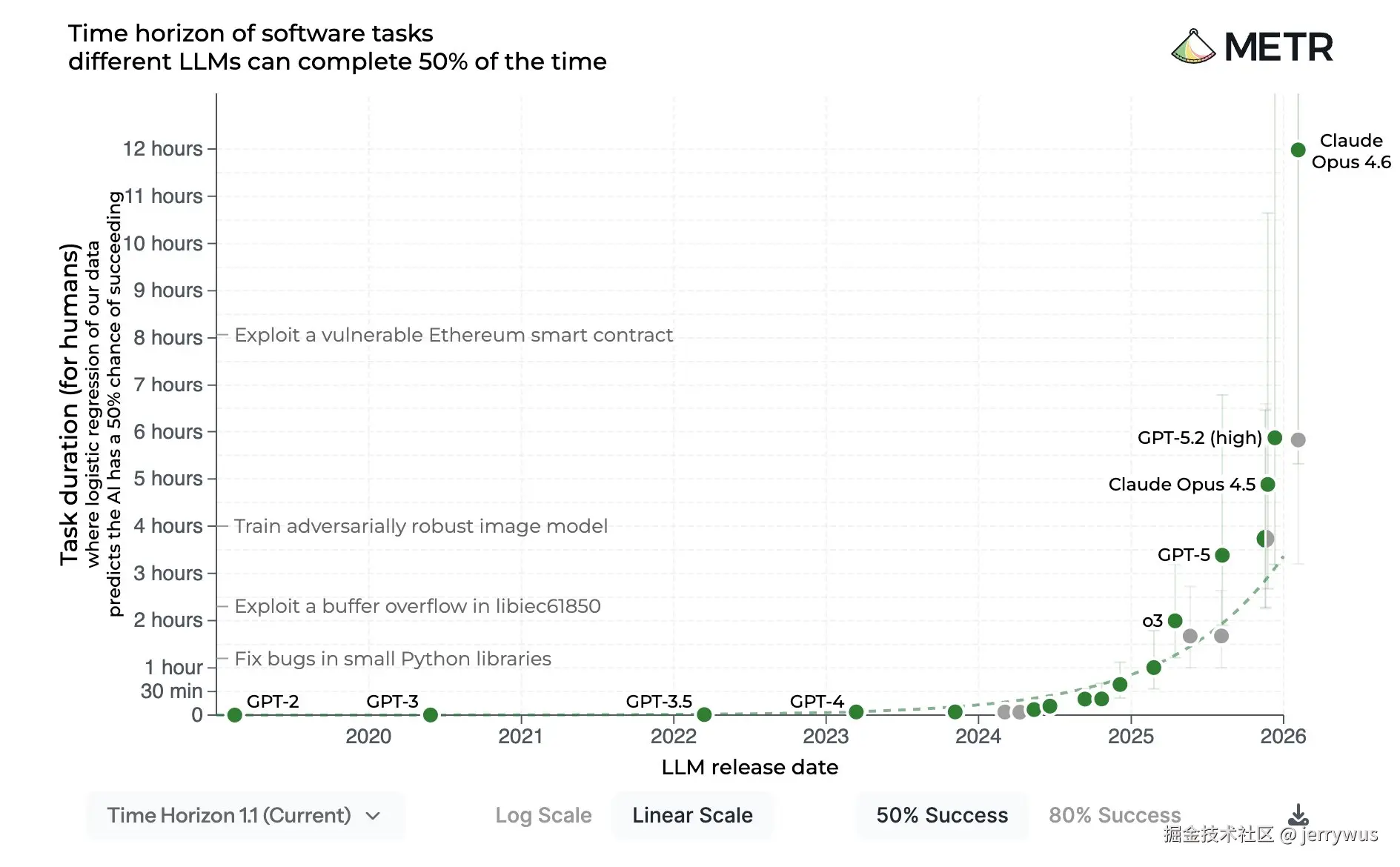
这项研究为每个模型配置了合适的 scaffold,包括 Claude Code 和 Codex。所以虽然焦点在模型本身而非 scaffold,但我们也能借此了解这些 scaffold 有多可靠。它告诉我们这些编程 agent 能处理多难、多长的任务。
如图所示,Opus 4.6 和 GPT-5.3-Codex 之间差距很大。Opus 4.6 在 50% 成功率下的任务完成时长是 12 小时,而 GPT-5.3-Codex 是 5 小时 50 分钟。这个差距在 80% 成功率时有所缩小。
这清楚地表明两个模型之间存在差距,进而也体现在 Claude Code 和 Codex 上------它们处理困难任务的能力有所不同。但这个差距不一定直接映射到你用它们做的事上,心里有点数就行。
Claude Code 更快,但速度没那么重要
Claude 比 Codex 快是出了名的。但跟编程 agent 打交道是长期过程。
如果一个 agent 完成任务只用了一半时间,但之后需要你花 10 分钟调试那破玩意儿,而另一个虽然多花了点时间实现,但完成后不用你盯着------那多出来的时间 100% 值得花。
这不是说 Claude Code 或 Codex 更容易犯错的------只是你自己评估这些 agent,或者听别人吹嘘它们的编程速度时,这句话值得记在心里。
任务类型对 agent 很重要
Codex 和 Claude Code 的表现取决于你用它做什么任务。在 AI 工程任务中,可能一个表现更好;但在 Web 开发任务中,同一个模型可能被吊打。
哪个编程任务更适合 Codex 或 Claude Code?这个研究做得还不够。
比如说,低级编程(low-level programming)该用哪个就不清楚。理想情况下,你应该在简单可验证的环境中先测试两者,再决定all in。但对大多数人来说,花 300-400 美元两个都买下来不太现实。
要全面对比两个 agent 在各种编程任务中的表现,是个有趣的研究方向。但也没那么轻松,因为这些 agent 和驱动它们的模型每隔几个月就会大幅变脸。
两者是如何诞生的
Claude Code 最初是 Anthropic 的 @bcherny 做的副业项目,做了个终端原型,能跟 Claude API 交互、读文件、跑 bash 命令。
内部团队到第五天就有一半人开始用了。然后 Claude Code 在 2025 年 2 月 24 日以研究预览版发布,用的是 Claude 3.7 Sonnet。花了一段时间被开发者大规模采用,之后 Anthropic 也发布了 VS Code 扩展。
OpenAI 这边,最初的 Codex 模型是 12B 参数的 GPT-3 微调版,基于 GitHub 代码,最终驱动了第一版 GitHub Copilot。但新的 Codex 是完全不同的产品。
Codex CLI 在 2025 年 4 月 16 日首发是终端 agent,之后随着更好的模型不断进化。最新版 GPT-5.3-Codex(2026年2月5日)被 OpenAI 称为"第一个参与创造自己的模型"。
@GergelyOrosz 做了两个很有意思的采访,分别关于 Claude Code 和 Codex 的开发者,涉及技术栈、开发方式、以及各自是怎么起步的。值得一看。
2025年9月24日
Claude Code 是怎么构建的?Claude Code 自己写 90% 的代码,工程师每天大概提交 5 个 PR,人均 PR 产出比去年增长了 67%,而团队规模翻了一倍。更多细节在今天的深度报道里:newsletter.pragmaticengineer.com/p/how-claud... @bcherny, @_catwu, @sidbid)
技术栈和驱动模型
Claude Code 用 TypeScript 写的,用 React + Ink 做终端 UI。打包成单个 Bun 可执行文件(Anthropic 在 2025 年 12 月收购 Bun 就是为了这个)。它用的 Opus 和 Sonnet 模型都支持 100 万 token 的上下文窗口。
Codex CLI 用 Rust 写的,追求性能、正确性和可移植性。OpenAI 甚至把这个 Rust TUI 库 Ratatui 的维护者挖来了团队。
两个 CLI 工具都是围绕模型包了层薄薄的外壳,通过 API 调用。我注意到用 Claude Code CLI 时有些小"故障",在 Codex 上不太明显------考虑到技术栈,这也意料之中。
不过这些故障也就是轻微烦人而已,真的不影响编程体验。
Benchmark 很接近,但有细节差异:Token 经济性
最大的性能差异不是准确率,而是 Token 效率。Morphism 的 Opus vs Codex 全面评测 揭示了一个有趣的差距。
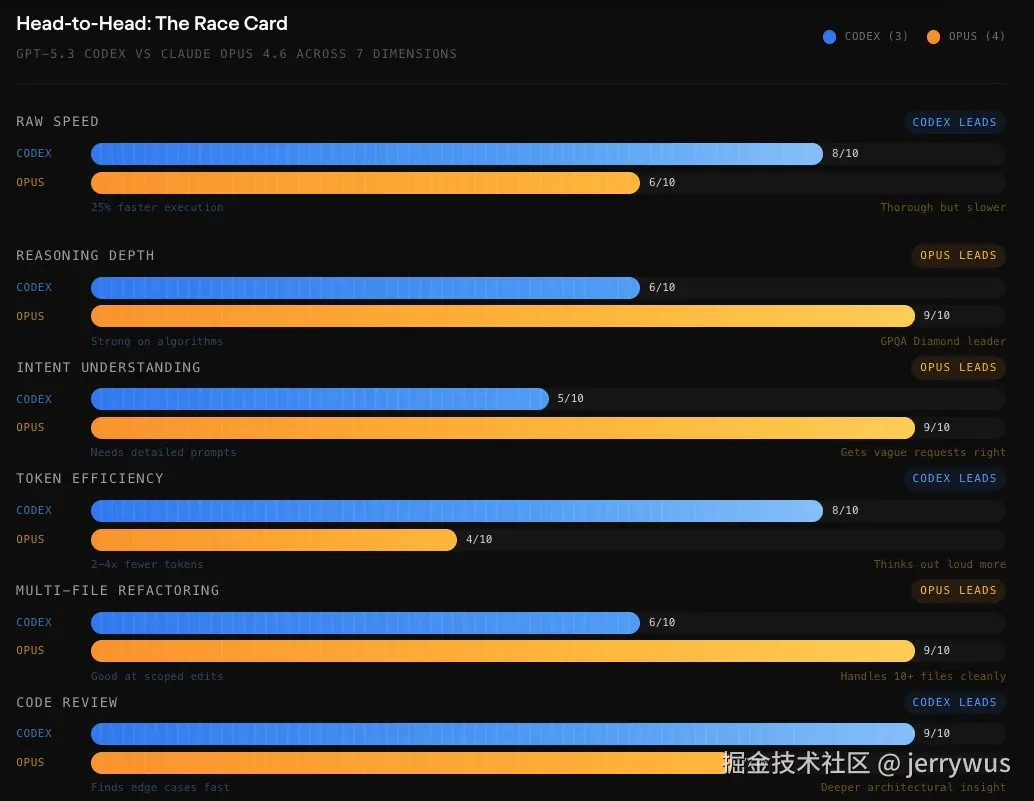
在相同任务上,Claude Code 比 Codex 多消耗 3.2--4.2 倍的 Token。 做一个 Figma 插件,Codex 用了 150 万 Token,Claude 用了 620 万。
如果这是真的,意味着你花同样的钱订阅 Claude Code,更容易撞到 Token 上限。
感觉最重要
Claude 像个帮你干活的高级工程师,Codex 像个承包商,你把任务丢给它,然后回来取结果。
这是开发者描述两者差异的普遍方式。
据报 Claude Code 有很强的交互感,还有深度推理能力------这跟 Opus 的定位相符。它会问你问题,展示推理过程,解释它的做法。虽然我那一次对比实验里没这种情况,但从用了好几个月的经验来看,我能确认这是真的。
Codex 以第一次尝试的准确率著称,代价是实现速度稍微慢一点。
话虽如此,如果你在 AGENTS.md 里具体说明你想要什么,两者行为的差异会大幅缩小。如果你明确要求模型在开始干活前跟你确认实现计划,它就会照做------不管你用的是"高级工程师"agent 还是"承包商"agent。
这不是说两者真的没区别------区别是有的。
只是没你在 X 上看到的那么夸张。
快速数据
VS Code Marketplace 上,Claude Code 有 610 万安装量,评分 4/5;Codex 有 540 万安装量,评分 3.5/5。
GitHub 上,Claude Code 大约 65--72K 星,Codex 约 64K 星。

为什么我现在换回 Claude Code
Anthropic 的生态拉力强
选 Codex 还是 Claude Code 不只是编程问题。你订阅任何一个,等于订阅了整个 Anthropic/OpenAI 生态,这个因素值得考虑。

我个人觉得 Claude 正在变成一个像 Apple 那样火热的生态,现在有 Claude Cowork、Claude Chat 和 Claude Code。Anthropic 似乎也在用 Claude app 慢慢搭建一个更安全、更温顺的 OpenClaw(主动式个人 agent),零敲碎打的功能正在逐步推出。
3月7日
今天我们在 Claude Code 桌面版推出本地定时任务。创建一个你想定期运行的任务计划,只要电脑醒着它们就会跑。
OpenAI 这边,目前我没看到什么诱人的东西。除了 Codex,其他的都挺无聊。我没感觉到一个生态,只感觉是零散的碎片,而且外面有更好的替代品。
我已经在用 Claude Chat 而不是 ChatGPT 了。对我来说,跟 Opus 相比,ChatGPT 现在基本没法用。UI、聊天风格、模型选择,没有一个让我有动力用 ChatGPT。
所以呢,因为我已经在高频使用 Claude Chat,打算折腾 cowork,目前没看到从 Claude Code 迁移到 Codex 有什么决定性的改进。换回 Claude Code、每月省下 200 美元,这决定做得相当轻松。
这成了影响我决定换回 Claude 的重大因素。
价格
Claude Code 和 Codex 的价格基本一样:
入门:都是 20 美元/月
高级用户:Claude Code 有个 Max 5x 档,100 美元/月
重度用户:都是 200 美元/月
Claude Code 真正亮眼的是它有个 100 美元的中档,而不是从 20 美元疯涨到 200 美元。而且我相信 Max 5x 计划(100 美元/月)对大多数开发者来说足够了。
所以可以说,Claude Code 实际上更便宜,因为它允许你选一个更便宜且够用的档,而不是逼你爬上价格阶梯。
技能和插件:开发者生态
技能(Skills)在 Claude Code 和 Codex 之间是兼容的,所以用哪个都感觉不出差别。但大多数技能中心和仓库都以 Claude Code 命名,可能有点混淆。
其他大多数事情也这样。你在 Reddit、X 或博客上看到的关于编程 agent 的帖子,大多关于 Claude Code 而不是 Codex------尽管两者原理相同。这本身就说明了很多问题:受欢迎程度和社区规模。
Codex 比 Claude Code 晚很久才支持技能和插件。但插件没有技能那么兼容。而且 Codex 的插件支持刚起步,没多少可用。
也就是说,很多开发者,包括我,根本不用插件。所以除非你特别需要各种插件支持,这方面不用纠结,也别把它当作选择依据。
RAG Pipeline:案例研究
我选了一个可以量化评估的任务来对比。问题是做一个落地页这种任务没法量化:一个人可能觉得好看,另一个可能说是紫色渐变的垃圾。
所以我选了个简单的 RAG pipeline 任务,因为生成的答案可以用数字衡量准确性。
如果你想做类似的对比,其他好想法包括:训练 vision model 或微调 LLM,或者测量低级程序的性能。
搭建检索 pipeline 是 AI 工程师的常见任务,你工作中可能用到 Claude Code 或 Codex。我让这两个编程 agent 给我搭一个论文问答 RAG pipeline。流程很简单:
- 取一批论文,提取文本
- 把内容分块(chunk)
- 把每块 embedding 到向量空间
- 用户提问时,找到跟问题 embedding 最接近的块
- 以原始形式检索出相关块(不是 embedding)
- 用这个上下文回答用户问题
这个任务足够简单,可以一次session 做完,但细节很复杂,对输出影响很大:用哪种分块策略、选什么 embedding 模型、用什么向量存储、如何处理"哪个块更接近查询"的置信度、是否重写用户问题来帮助找到更相似的块......
实验设置
我从 @huggingface 过去一周的每日论文里选了 5 篇,建了一个测试集(100 道题及标准答案),用来测试 Claude 或 Codex 的实现质量。
对两个 coding agent,我都是这么要求的:
- 做一个 Python RAG pipeline
- 用 PyMuPDF 处理所有 PDF
- 为这个用例选一个好的分块策略
- 创建 embedding 和持久化本地向量索引(你选)
- 用 llama-3.1-8b-instant 生成最终答案
- 如果没有足够证据,不要 hallucinate,返回 fallback
对 Codex 和 Claude Code,我都用了最流行且默认的模型:gpt-5.3-codex 和 Opus 4.6 ,都用 High effort(推理深度)。都没有 AGENTS.md。
它们怎么实现的 pipeline
我没注意到两个 agent 思考任务的方式有什么明显差别,除了 Codex 更啰嗦,会解释它的计划以及要做什么。Claude 直接写文件,执行命令,不说那么多。
Codex 完成任务比 Claude 花了更长时间。
更重要的是,Claude 端到端测试了脚本,确保 pipeline 能用。
Codex 则是做完了实现,但没有测试或运行程序,只是告诉我 pip install 依赖然后运行脚本。自然,我跑的时候报错了,Codex 解决了。Claude 的脚本跑起来一点问题没有。
我注意到 Codex 有这个模式:很多脏活累活它留给你做,而不是自己动手。
Codex 会告诉你并主动处理环境问题或实现困难,Claude 则自行修复------这取决于你的偏好,可能是好事也可能是坏事。
我还注意到,Codex 在新会话中第一个 token 的响应时间可以高达一分钟,Claude Code 这边短得多。
Claude Code vs. Codex 实现
两个 coding agent 的方案惊人地相似:
- 都选了 all-MiniLM-L6-v2 作为 embedding 模型
- 都选了 k=5 做 Top-K 检索
- 都在 system prompt 里限制 LLM 只准用提供的上下文
但这些地方它们走了不同的路:
- 向量存储 :Claude Code 选了 ChromaDB ,Codex 选了 FAISS------一个更底层的相似度搜索库,更省内存更快。
- 分块:Claude Code 用了递归字符分割。先试 \n\n,然后 \n,然后 ".",然后 " "。目标是 1000 字符,200 字符重叠。Codex 用了句子级别的词分割,每块最多 220 词,40 词重叠。Claude Code 按结构分割(段落→行→句子→词),按字符计量。Codex 先按句子切,然后打包进词预算的箱子里。Codex 的方法尊重句子边界,避免句子中间切断,但 220 词对这种上下文可能太小(学术文本)。
- 检索:两者都选了 Top-5 块。Claude Code 返回原始 L2 距离,Codex 返回内积(cosine)分数。
- 置信度:Claude Code 对最佳 L2 距离用单一阈值(>1.2 = 不相关),然后检查低置信度与高置信度块的距离平均值。Codex 用多标准三档:强、中等、不足。
- 代码架构:Claude Code:扁平函数,各模块常量,无模型一致性输入验证。Codex:OOP pipeline 类,集中配置,dataclasses,argparse CLI,模型一致性验证。Codex 明显工程化程度更高、可配置性更好。在更大更严肃的代码库里,这很关键。
结果
用 gpt-4 做 LLM-as-a-judge,两个 pipeline 的答案按四个标准比较:正确性、完整性、相关性、简洁性。
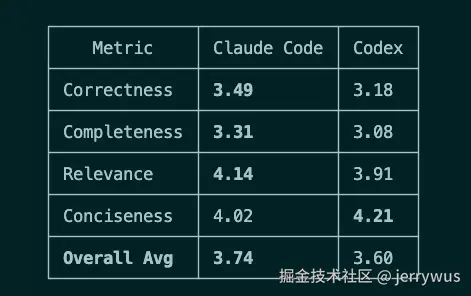
100 道题中,Claude Code 赢了 42 道,Codex 赢了 33 道,25 道平手。 Claude 赢主要是因为它的置信度阈值更松,可能还有生成温度稍高(0.2 vs Codex 的 0.1)。
加点盐
这只是个非常简单的设置。我主要是好奇两个 coding agent 实现同一个封闭任务时有什么不同的做法。在专业环境里,是开发者拍板整体架构:分块方法、向量数据库、检索策略等。而且在专业环境里,做这类系统需要更多测试和迭代改进,以及更可靠的测试集和验证。
不过可以预期,一个不太有经验的初级开发者做 RAG pipeline,会把这些决策交给 AI。
选一个吧
我觉得选 Claude Code 还是 Codex,没有绝对错误的选择。两者都比现有格局的模型强,完成任务的水平差不多。
我的两大因素是:Anthropic 生态,以及 100 美元/月的价位段。即使我需要升到 200 美元/月 档位,还是会为了前者留在 Anthropic 的 Claude Code。
最重要的是你用这些 scaffold 做什么,以及怎么用。
这个比任何 benchmark 都能更好地判断哪个更适合你------没有标准答案,只能凭感觉。你把两个都试过之后,哪个用起来更舒服,答案就在你心里。
有开发者比如 @steipete 坚决站 Codex,也有人相信 Opus 就是被 OpenAI 模型吊打。
我觉得两边都对,因为他们的工作流不同,对这些 coding agent 的"品味"也不同。
如果你犹豫不定,建议先试两个的 20 美元/月 版本,用跟你相关的编程领域,最好在几个可验证的任务上测试。
最后,跟其他 AI 相关的东西一样,格局几个月就变一次。你现在喜欢哪个,三个月后 agent 行为可能漂移,或者新模型出来了。
AI 领域很少有全球通用的标准答案,这个话题也不是 ;)