我是一个 C++ 小白,这篇文章旨在记录我使用 C++ 学习链表的整个过程,也希望能对其他的 C++ 初学者提供一点帮助。
1. C++标准的链表节点定义
1.1 定义
Leetcode 官方使用的标准定义方式是这样的:
cpp
struct ListNode {
int val; // 数据域
ListNode *next; // 指针域(C++里不需要写 struct ListNode*,直接写 ListNode*)
// 下面是构造函数
// 1.默认无参构造函数
ListNode() : val(0), next(nullptr) {}
// 2.只传入数据的构造函数
ListNode(int x) : val(x), next(nullptr) {}
// 3.传入数据和下一个节点指针的构造函数
ListNode(int x, ListNode *next) : val(x), next(next) {}
};1.2 构造函数
在 C 语言 里,内存分配和数据初始化是分离 的。你用 malloc 申请了一块内存时,里面装的是垃圾数据,所以你每次创建一个新节点,都必须强迫自己写三行代码,就像这样:
cpp
Node* n = (Node*)malloc(sizeof(Node));
n->data = 10;
n->next = NULL;这样做相当麻烦,而且很容易因为粗心而导致程序崩溃,于是 C++ 发明了构造函数。构造函数的作用是:只要对象一创建,编译器就会自动帮你执行一段你提前写好的代码,从而完成初始化。
构造函数其实就是一个特殊的函数 ,它写在 struct 或 class 的里面,它有三个特点:
- 名字必须和结构体的名字一模一样,比如结构体叫
ListNode,构造函数就必须叫ListNode。 - 绝对不能写返回值类型。
- 不能手动调用它,它是在用
new分配内存时,由系统自动触发的。
我们来看看刚才那段 C++ 定义,里面写了 3 个构造函数。(注:C 语言不允许同名函数,但 C++ 允许,只要它们的参数不一样就行,这在 C++ 里叫函数重载。编译器会根据你传的参数,自动判断你要用哪一个。)
无参构造函数:
cpp
ListNode() : val(0), next(nullptr) {}- 当写下
ListNode* n = new ListNode()时会触发这个无参构造函数。 - 冒号
:与冒号之后大括号之前的内容叫做初始化列表 。它把成员变量val赋值为 0,把next赋值为nullptr。 - 活都在冒号后面干完了,大括号里不需要再写额外的代码了。
带一个参数的构造函数:
cpp
ListNode(int x) : val(x), next(nullptr) {}- 当写下
ListNode* n = new ListNode(10)时触发这个构造函数。 - 把传进来的
10赋给val,同时自动把next变成nullptr,这样就再也不怕忘记给next置空了。
带两个参数的构造函数:
cpp
ListNode(int x, ListNode *next) : val(x), next(next) {}- 当写下
ListNode* n = new ListNode(10, some_pointer)时触发这个构造函数。 - 同时初始化数据和下一个节点的指针。
此外,在 C++ 中使用 nullptr 表示空指针,它带有明确的指针类型,比 C 语言里的宏定义 NULL更安全。
1.3 C++ 的内存分配
在 C++ 里,永远不要对类或结构体使用 malloc 和 free,我们要用 new 和 delete。
new不仅会分配内存,还会自动调用构造函数。- delete不仅会释放内存,还会调用析构函数。
下面我们尝试用 C++ 创建一条简单的链表并打印,链表节点就是上面的标准定义,main函数如下:
cpp
#include <iostream>
int main()
{
//方式一,带一个参数的构造函数
/*
ListNode* node1 = new ListNode(1);
ListNode* node2 = new ListNode(2);
ListNode* node3 = new ListNode(3);
//要手动连接
node1->next = node2;
node2->next = node3;
ListNode* head = Node1;
*/
//方式二,带俩个参数的构造函数
ListNode* head = new ListNode(1, new ListNode(2, new ListNode(3)));
//遍历打印
ListNode* curr = head;
while (curr != nullptr)
{
std::cout << curr->val << " -> ";
curr = curr->next;
}
std::cout << "nullptr" << std::endl;
//释放内存
//简单起见,这里按顺序释放
delete head->next->next;
delete head->next;
delete head;
return 0;
}编译运行后结果如下:

2. 虚拟头节点
在讲虚拟头节点之前,请先回忆一下你以前用 C 语言写链表时,最烦人的情况是什么?
应该就是处理头节点了。
假如我们要删除链表中的某个节点:
- 如果要删除的是中间 的节点,很简单,找到它的前一个节点
prev,让prev->next = curr->next就可以了。 - 但如果恰好要删除的是第一个节点头节点 呢?头节点没有前一个节点,这时候你必须写特殊的
if逻辑来处理,比如if (head->val == target) { head = head->next; }。 - 同样,在头部插入 节点,也需要单独处理
head指针的变化。
在 C++ 算法题中,为了不写这堆恶心边界判断,引入了虚拟头节点 。它的核心思想是: 在原本的头节点前面,人为地加上一个假节点。 这样一来,原本的头节点就变成了第二个节点,链表里的所有节点都有了前一个节点。不管你要在头部插入、还是删除头部,逻辑都变得和处理中间节点一模一样。
下面是 LeetCode 第 203 题,一道很经典的链表题,我们直接用虚拟头节点秒杀它:
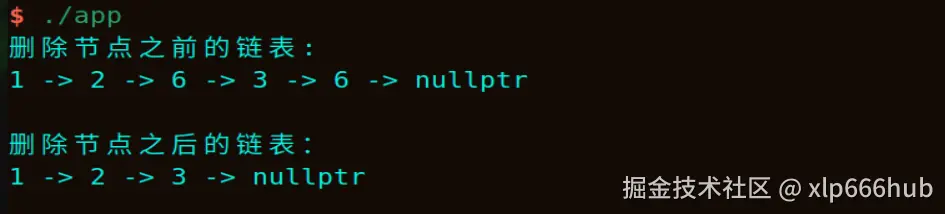
假设链表是:1 -> 2 -> 6 -> 3 -> 6,我们要删除所有值为 6 的节点。代码如下:
cpp
ListNode* removeElements(ListNode* head, int val)
{
//1. 创建虚拟头节点,值随便给一个。
ListNode* dummy = new ListNode(0);
//2. 让虚拟头节点连接到真实的头节点上
//现在的结构变成了:dummy(0) -> 1 -> 2 -> 6 -> 3 -> 6
dummy->next = head;
//3. 定义一个指针用于遍历
//为什么不从 head 开始?因为我们要删除节点,必须找到它的"前一个节点"
ListNode* curr = dummy;
//4. 开始遍历,当前节点的下一个节点不能为空
while (curr->next != nullptr)
{
//如果下一个节点的值等于我们要删除的值
if (curr->next->val == val)
{
//记录要删除的节点
ListNode* toDelete = curr->next;
//跨过要删除的节点
curr->next = curr->next->next;
//释放内存
delete toDelete;
}
else
{
//如果下一个节点不用删除,指针才往前走
curr = curr->next;
}
}
//5. 遍历结束,所有的 6 都被删了
//现在我们要返回新的头节点。新的头节点是 dummy 的下一个节点
ListNode* newHead = dummy->next;
//把我们借来的 dummy 节点也删掉,防止内存泄漏
delete dummy;
return newHead;
}对上面的main函数稍作修改,并使用我们编写的删除节点函数,运行结果如下:
3. 链表核心算法套路
3.1 快慢指针
什么是快慢指针呢?顾名思义,我们定义两个指针,它们都在链表上面跑,快指针一次走两步,慢指针一次走一步。
这个简单的设定,就可以完美解决两大类经典的链表面试题:
3.1.1 寻找链表的中间节点
如果我让你找一个数组的中间元素,很简单,数组长度除以 2 当下标就行。
但链表不能通过下标访问,你不知道它的长度。有一种笨办法:先遍历一遍链表算出长度 L,然后再从头遍历跑到 L/2 的位置。需要遍历 1.5 次。但是如果使用快慢指针只需要遍历 1 次。
C++ 代码实现如下:
cpp
ListNode* middleNode(ListNode* head)
{
//1. 两个指针都从头节点出发
ListNode* slow = head;
ListNode* fast = head;
//2. 循环条件极其关键:快指针本身不能为空,且快指针的下一个也不能为空
while (fast != nullptr && fast->next != nullptr)
{
slow = slow->next; // 慢指针走 1 步
fast = fast->next->next; // 快指针走 2 步
}
//3. 当循环结束时,fast 走到头了,slow 刚好停在中间节点
return slow;
}循环条件那块可能有点难以理解,下面我简单解释一下:
如果fast每次只走一步,那很好判断:当fast已经指向最后一个节点时,下一次循环中fast就会指向nullptr,这之后fast就不能再走了,所以我们只需要fast != nullptr作为我们的循环条件即可。
但是对于fast每次走两步的情况,要分类讨论:一种情况是fast已经为nullptr了(当fast指向倒数第二个节点时,下一轮循环再走两步,刚好为nullptr),这时就不能继续走了;另一种情况是当fast指向最后一个节点时,由于fast每次要走两步,走第一步时fast为nullptr,要走第二步时就会发现没地方走了,因此当fast已经指向最后一个节点时,也不能继续走了。
所以,循环条件应该长上面那样。
还有一个可能会引起程序崩溃的小细节:while (fast != nullptr && fast->next != nullptr) 中,fast != nullptr必须在&&的前面。根据短路求值特性,如果&&前面为false,那么整体就为false,不会去看&&后面。
试想一下当fast已经为nullptr了,如果我们写while (fast != nullptr && fast->next != nullptr) ,由于不满足&&前面的条件,就不回去判断&&后面的条件,也就不会出现非法解引用的问题。但是如果我们写while (fast->next != nullptr && fast != nullptr),问题就出现了,fast已经为nullptr了,我们还去访问fast->next,程序瞬间崩溃。
3.1.2 判断链表是否有环
正常链表走到最后是 nullptr,但有些坏链表的尾节点指向了前面的某个节点,形成了一个死循环,也就是环形链表。怎么判断一个链表有没有环?
依然是快慢指针的解法,快指针每次走两步,慢指针每次走一步。
如果链表没有环,快指针肯定会先遇到 nullptr,游戏结束。如果链表有环,快指针和慢指针都会进入环里,不停地转圈。因为快指针速度快,它早晚会从后面追上慢指针,所以只要两人相遇,就说明必定有环。
代码如下:
cpp
bool hasCycle(ListNode *head)
{
//如果链表为空,或者只有一个节点且没成环,直接返回 false
if (head == nullptr || head->next == nullptr) return false;
ListNode* slow = head;
ListNode* fast = head;
while (fast != nullptr && fast->next != nullptr)
{
slow = slow->next;
fast = fast->next->next;
//看看内存地址是否相同
if (slow == fast)
{
return true; //发现环
}
}
return false; //fast 遇到了 nullptr,说明没环
}3.2 链表反转
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
输入:1 -> 2 -> 3 -> 4 -> 5 -> nullptr
输出:5 -> 4 -> 3 -> 2 -> 1 -> nullptr
可能会有人第一反应是:把 1 和 5 的值互换,2 和 4 的值互换......
但是在真实的工程中,节点里的数据可能是一个几十兆大小的复杂对象,拷贝数据的代价极高。
正确的做法是:改变指针的指向。,把 1 -> 2 变成 1 <- 2。
为什么我们需要三个指针?请看下面分析:
- 假设当前我们正在处理节点 2,我们要把 2 的
next指向 1,我们需要一个指针指向当前的节点,叫curr,当前指向 2。 - 我们需要知道 2 应该指向谁,所以需要一个指针记录前面的节点,叫
prev,当前指向 1。 - 当你执行
curr->next = prev,把 2 指向 1 之后,2 原本指向 3 的那根线断了,链表从 3 开始的后半截直接丢失。 - 因此,在断开之前,必须用第三个临时指针
nextTemp把 3 给记住。
知道为什么需要三个指针之后,我们来看看循环里面要做什么:
ListNode* nextTemp = curr->next,记住后面的节点,防止丢失。curr->next = prev,真正的反转操作,把箭头往回指。prev = curr,prev往前走一步,为下一次循环做准备。curr = nextTemp,当前节点处理完了,去处理下一个。
完整代码实现如下:
cpp
ListNode* reverseList(ListNode* head)
{
//1. 初始化两个指针
ListNode* prev = nullptr; //一开始,头节点反转后会变成尾节点,它的 next 应该是 nullptr
ListNode* curr = head; //curr从头节点开始
//2. 开始遍历,只要 curr 还没走到链表外面就一直循环
while (curr != nullptr)
{
//第一步:保存下一个节点
ListNode* nextTemp = curr->next;
//第二步:反转当前节点的箭头,让它指向上一个节点
curr->next = prev;
//第三步:prev 往前走一步
prev = curr;
//第四步:curr 往前走一步
curr = nextTemp;
}
//3. 循环结束时,返回新的头节点
return prev;
}可能有人会对最后返回prev存疑,这里简单解释一下:在最后一轮while循环中,由于curr->next为nullptr,所以nextTemp 也为nullptr,此时prev是倒数第二个节点,curr就往回指向它前面的节点,然后prev往前走,走到原始链表的最后一个节点,也就是翻转后链表的头节点,最后curr指向nullptr。因此,应该返回prev。
4. C++ 标准库中的链表
在 C++ 中,自带了两种链表:
std::list:双向链表。最常用,每个节点既有next也有prev。std::forward_list:单向链表。C++11 引入的,就是为了省那一点点prev指针的内存,只有在极端抠内存的嵌入式场景才会用,普通开发很少用。
我们主要看std::list。
4.1 怎么用
cpp
#include <iostream>
#include <list> //必须包含这个头文件
int main()
{
//创建一个存 int 的双向链表
std::list<int> myList;
//创建的同时赋初值 (C++11 新特性)
std::list<int> nums = {10, 20, 30, 40};
}4.2 核心API
相比于以前用 C 语言写个尾部插入都要写个 while 循环找尾巴,C++ 的 std::list 简直不要太方便:
cpp
#include <iostream>
#include <list>
int main()
{
std::list<int> l = {2, 3};
//1. 头尾插入删除,时间复杂度全是 O(1)
l.push_front(1);//头部插入 1 -> 变成了 {1, 2, 3}
l.push_back(4);//尾部插入 4 -> 变成了 {1, 2, 3, 4}
l.pop_front(); //删除头部 -> 变成了 {2, 3, 4}
l.pop_back(); //删除尾部 -> 变成了 {2, 3}
//2. 高级删除
l.push_back(2); //现在是 {2, 3, 2}
l.remove(2); //自动遍历,把链表里所有等于 2 的节点全部删除,变成 {3}
//3. 怎么遍历
l = {10, 20, 30};
//方式一:类似于 Java/Python 的 for-each 循环,推荐这种写法
for (int val : l)
{
std::cout << val << " ";
}
std::cout << "\n";
//方式二:使用迭代器,迭代器本质上就是 C++ 封装过的高级指针
for (std::list<int>::iterator it = l.begin(); it != l.end(); ++it)
{
std::cout << *it << " "; //用 * 解引用,和 C 语言的指针一模一样
}
std::cout << "\n";
return 0;
}因为 std::list 是 C++ 封装好的,拿不到底层的 ListNode*,怎么办?
C++ 提供了一个叫 迭代器 的东西。
l.begin():返回指向链表第一个元素的迭代器(高级指针)。l.end():返回指向链表最后一个元素之后的迭代器。++it:迭代器往后走一步。*it:获取当前节点的值。
5. 写在最后
刚开始连节点定义都写不利索,慢慢学会了构造函数、虚拟头节点、快慢指针这些花活。有时候代码跑不通,debug 半天发现是个空指针,就像生活里那些突如其来的坑,你不提前判断一下if p != nullptr,直接就崩。快慢指针教我的不是怎么找中间节点,而是有些事你得慢下来才能看清,有些事得快起来才能追上。
最后发现,学链表最难的其实不是反转,也不是判环,而是记得delete。你new了多少,就得delete多少,不然内存就泄漏了。这大概也是生活教会我的事:欠的债总要还,占的坑总要清,体面地退出,把资源还给系统,才算一个完整的闭环。
本文结束。