目录
[1.1 导入依赖库并配置浏览器](#1.1 导入依赖库并配置浏览器)
[1.2 定义爬取单页评价的核心函数](#1.2 定义爬取单页评价的核心函数)
[1.3 爬取优质好评(含自动翻页)](#1.3 爬取优质好评(含自动翻页))
[1.4 爬取差评(逻辑与好评一致)](#1.4 爬取差评(逻辑与好评一致))
[2.1 导入 Pandas 并读取差评数据](#2.1 导入 Pandas 并读取差评数据)
[2.2 读取优质好评数据](#2.2 读取优质好评数据)
[3.1 导入 Jieba 并对差评分词](#3.1 导入 Jieba 并对差评分词)
[3.2 对优质好评分词](#3.2 对优质好评分词)
[4.1 读取停用词库](#4.1 读取停用词库)
[4.2 定义停用词过滤函数](#4.2 定义停用词过滤函数)
[4.3 过滤差评的停用词](#4.3 过滤差评的停用词)
[4.4 过滤好评的停用词](#4.4 过滤好评的停用词)
在电商运营、用户体验分析等场景中,商品评价是最直接的用户反馈来源。通过分析好评可以提炼商品核心卖点,分析差评能定位用户不满的关键问题。但苏宁易购的评价数据以非结构化文本形式呈现,且分散在多页中,手动采集和处理效率极低。
本文将完整讲解如何通过 Python 实现苏宁易购商品评价的自动化爬取,并对爬取后的文本进行中文分词、停用词过滤等预处理,最终得到可直接用于词频统计、情感分析、词云制作的结构化数据。整个流程零基础也能看懂,代码可直接复用。
| 技术工具 | 作用 |
|---|---|
| Selenium | 模拟浏览器操作,爬取动态加载的多页评价数据 |
| Pandas | 读取 / 处理文本数据,结构化存储结果 |
| Jieba | 中文分词工具,将完整评价拆分为单个词汇 |
| TXT/Excel | 存储原始评价数据和处理后的分词数据 |
| 停用词库(StopwordsCN.txt) | 过滤无意义词汇,提升文本分析质量 |
第一步:自动爬取苏宁易购评价数据
使用 Selenium 启动 Edge 浏览器,访问指定商品的好评 / 差评页面,定位评价内容元素提取文本,自动点击 "下一页" 按钮爬取多页数据,最终将好评 / 差评分别保存到优质好评1.txt和差评1.txt文件中。
1.1 导入依赖库并配置浏览器
python
# 导入Selenium核心库
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import time
from selenium.webdriver.common.by import By
# 配置Edge浏览器选项
chrome_options = Options()
# 指定Edge浏览器的安装路径(需根据自己电脑路径修改)
chrome_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
# 初始化Edge浏览器驱动(启动浏览器)
driver = webdriver.Edge(options=chrome_options)Options():用于配置浏览器启动参数,这里指定了 Edge 浏览器的安装路径,确保 Selenium 能找到并启动浏览器;
webdriver.Edge():初始化 Edge 驱动,创建一个自动化的浏览器实例,后续所有页面操作都基于这个实例。
1.2 定义爬取单页评价的核心函数
python
def get_py_content(file):
"""
提取当前页面的所有评价内容并写入文件
:param file: 保存评价的文件对象
"""
# 定位评价内容元素:苏宁评价文本的核心class为body-content
pj_elements_content = driver.find_elements(by=By.CLASS_NAME, value='body-content')
# 遍历每个评价元素,提取文本并写入文件(每行一条评价)
for element in pj_elements_content:
file.write(element.text + '\n')find_elements(By.CLASS_NAME, 'body-content'):通过类名定位页面中所有评价文本元素,返回元素列表;element.text:提取元素的纯文本内容(去除 HTML 标签);- 循环写入文件:保证每条评价单独一行,方便后续读取处理。
1.3 爬取优质好评(含自动翻页)
python
# 访问好评页面(替换为目标商品的好评URL)
driver.get("https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-good.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166")
# 打开文件(指定utf-8编码避免中文乱码)
yzpj_file = open('优质好评1.txt', 'w', encoding='utf-8')
# 爬取第一页好评
get_py_content(yzpj_file)
# 自动翻页爬取多页好评
# 定位"下一页"按钮(XPATH定位class为next rv-maidian的元素)
next_elements = driver.find_elements(By.XPATH, '//*[@class="next rv-maidian"]')
print(f"是否找到下一页按钮:{next_elements}") # 调试用,查看是否定位到按钮
# 循环翻页:只要存在下一页按钮,就继续爬取
while next_elements != []:
next_element = next_elements[0] # 取第一个下一页按钮
time.sleep(1) # 等待1秒,确保页面加载完成
next_element.click() # 点击下一页
get_py_content(yzpj_file) # 爬取新页面的好评
# 重新定位下一页按钮,判断是否还有下一页
next_elements = driver.find_elements(By.XPATH, '//*[@class="next rv-maidian"]')
# 关闭好评文件,释放资源
yzpj_file.close()driver.get():访问指定的好评页面 URL;
open('优质好评1.txt', 'w', encoding='utf-8'):以写入模式打开文件,encoding='utf-8'是避免中文乱码的关键;
翻页逻辑:通过 XPATH 定位 "下一页" 按钮,循环判断按钮是否存在,存在则点击并爬取新页面数据,直到无下一页为止;
time.sleep(1):固定等待 1 秒,防止页面未加载完成就爬取导致数据缺失。
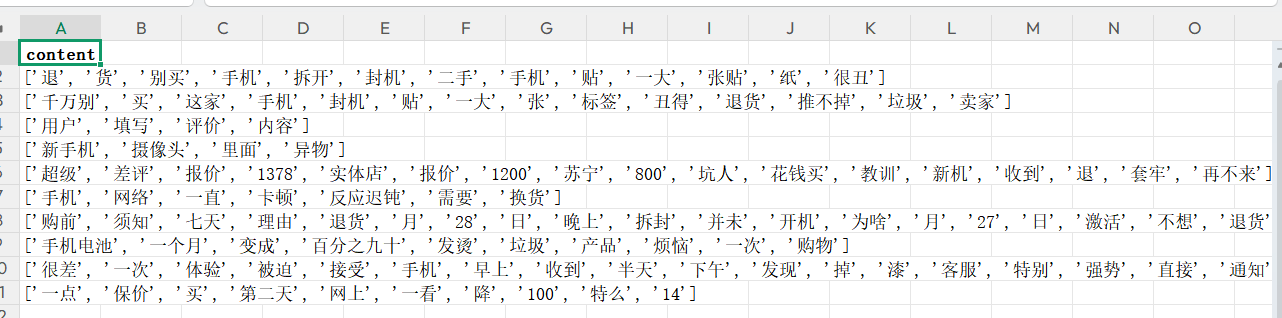
爬取结果:
1.4 爬取差评(逻辑与好评一致)
python
# 访问差评页面(替换为目标商品的差评URL)
driver.get("https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-bad.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166")
# 打开差评文件
cp_file = open('差评1.txt', 'w', encoding='utf-8')
# 爬取第一页差评
get_py_content(cp_file)
# 自动翻页爬取多页差评
next_elements = driver.find_elements(By.XPATH, '//*[@class="next rv-maidian"]')
print(f"是否找到下一页按钮:{next_elements}")
while next_elements != []:
next_element = next_elements[0]
time.sleep(1)
next_element.click()
get_py_content(cp_file)
next_elements = driver.find_elements(By.XPATH, '//*[@class="next rv-maidian"]')
# 关闭差评文件
cp_file.close()
# 关闭浏览器,释放所有资源
driver.quit()仅替换了页面 URL 和保存文件名称,核心逻辑与好评爬取完全一致;
driver.quit():关闭浏览器,避免进程残留(重要!)。
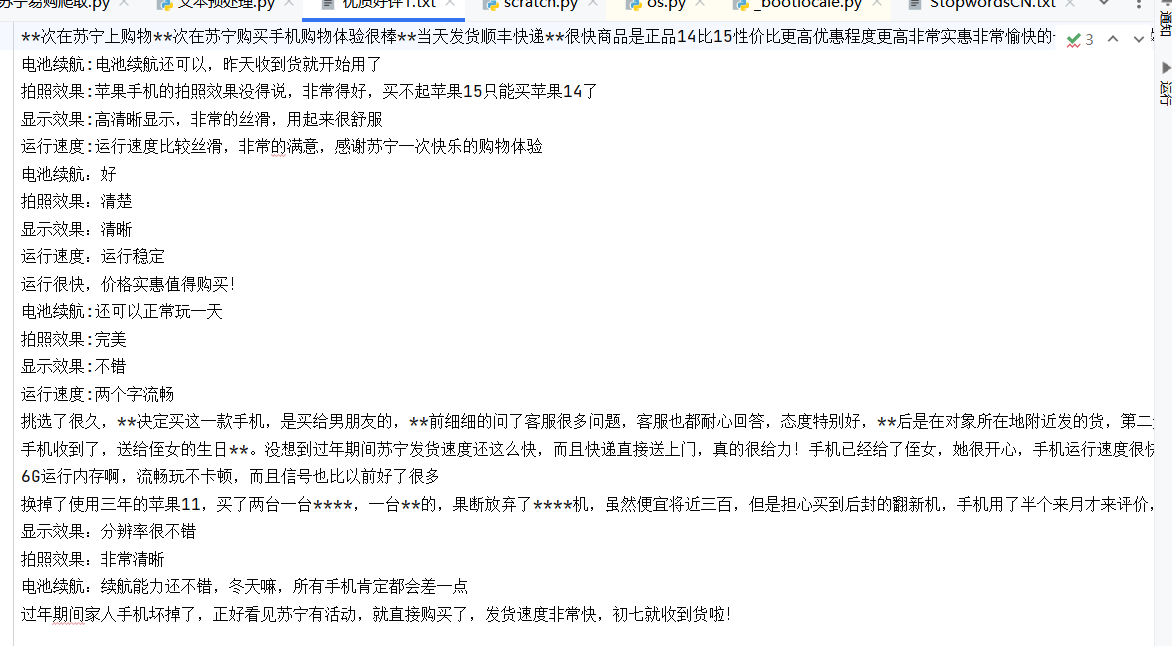
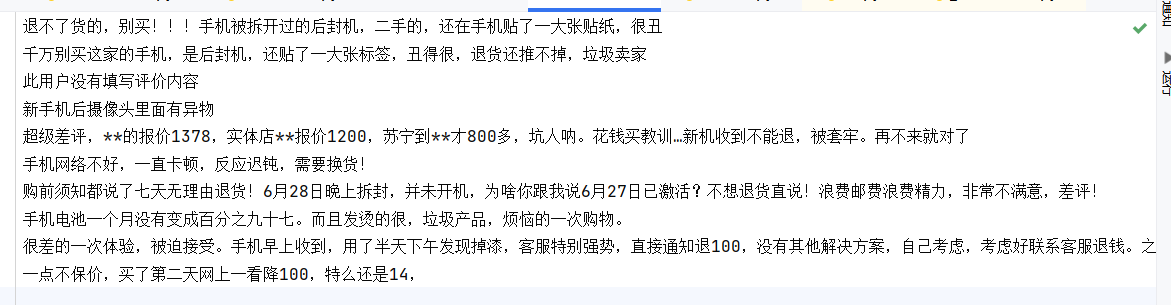
第二步:读取评价数据并规范化
爬取的评价数据保存在 TXT 文件中,无表头且格式不统一。使用 Pandas 读取文件,将默认列名重命名为content,统一数据格式,为后续分词做准备。
爬取结果:
2.1 导入 Pandas 并读取差评数据
python
import pandas as pd
# 读取差评TXT文件
cp_content = pd.read_table(
r".\差评1.txt", # 文件路径
encoding='utf-8', # 编码格式
engine='python', # 解决中文路径/编码问题
header=None # 说明文件无表头
)
# 重命名列名为content,方便后续操作
cp_content.rename(columns={0: "content"}, inplace=True)pd.read_table():专门用于读取文本文件,比read_csv更适配无分隔符的纯文本;
engine='python':解决 Windows 系统下中文路径或编码导致的读取失败问题;
header=None:告知 Pandas 文件没有表头,避免将第一条评价误判为列名;
rename(columns={0: "content"}):将默认的列名(数字 0)改为有意义的content,便于后续通过列名提取数据。
2.2 读取优质好评数据
python
# 读取优质好评TXT文件(逻辑与差评一致)
yzpj_content = pd.read_table(
r".\优质好评1.txt",
encoding='utf-8',
engine='python',
header=None
)
# 重命名列名
yzpj_content.rename(columns={0: "content"}, inplace=True)第三步:中文分词(过滤无意义单字)
中文文本无法直接被机器分析,需要拆分为单个词汇(分词)。使用 Jieba 的lcut精确分词模式拆分评价文本,同时过滤掉长度≤1 的单字(如 "的、了、啊"),最后将分词结果保存为 Excel 文件
3.1 导入 Jieba 并对差评分词
python
import jieba
# 初始化空列表,存储分词结果
cp_segments = []
# 将DataFrame的content列转为列表,方便遍历
contents = cp_content["content"].values.tolist()
# 遍历每条差评内容,进行分词
for content in contents:
# jieba.lcut:精确分词模式,返回词汇列表
results = jieba.lcut(content)
# 过滤单字分词结果(仅保留长度>1的词汇)
if len(results) > 1:
cp_segments.append(results)
# 将分词结果转为DataFrame
cp_fc_results = pd.DataFrame({'content': cp_segments})
# 保存为Excel文件(index=False去除行索引)
cp_fc_results.to_excel('cp_fc_result.xlsx', index=False)jieba.lcut():精确分词模式,适合电商评价这类短文本,分词结果更精准;
content.values.tolist():将 DataFrame 的列数据转为 Python 列表,便于循环遍历;
len(results) > 1:过滤单字,避免 "的、我、这" 等无意义单字混入分词结果;
to_excel('cp_fc_result.xlsx', index=False):将分词结果保存为 Excel,index=False去除默认的行索引,让文件更整洁。

3.2 对优质好评分词
python
# 初始化空列表,存储好评分词结果
yzpj_segments = []
# 转为列表遍历
contents = yzpj_content["content"].values.tolist()
# 遍历分词
for content in contents:
results = jieba.lcut(content)
if len(results) > 1:
yzpj_segments.append(results)
# 转为DataFrame并保存
yzpj_fc_results = pd.DataFrame({'content': yzpj_segments})
yzpj_fc_results.to_excel('yzpj_fc_results.xlsx', index=False)第四步:过滤停用词(清洗冗余词汇)
分词结果中仍包含 "我、你、也、就" 等无实际意义的停用词,需要读取停用词库并过滤这些词汇,仅保留核心词汇(如 "续航、性价比、售后"),提升后续分析的准确性。
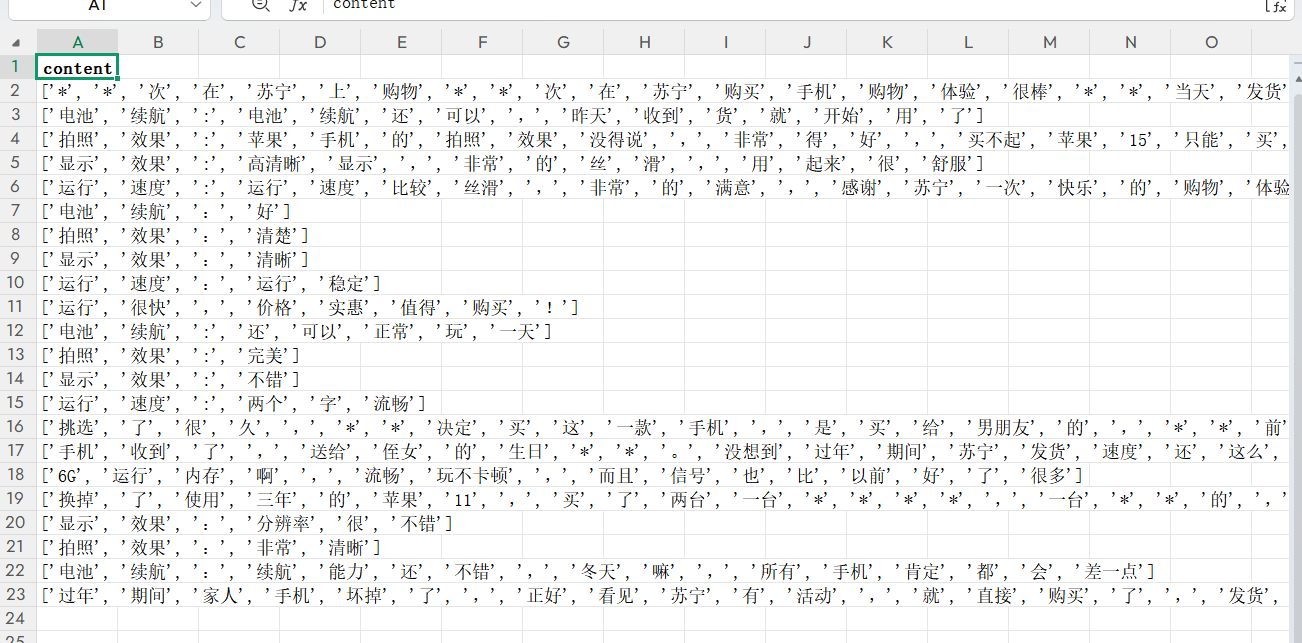
4.1 读取停用词库
StopwordsCN.txt:通用中文停用词库,文件中每行一个停用词;stopwords.stopword.values.tolist():将停用词列转为列表,后续通过in判断词汇是否为停用词
4.2 定义停用词过滤函数
python
def drop_stopwords(contents, stopwords):
"""
过滤分词结果中的停用词
:param contents: 分词后的内容列表
:param stopwords: 停用词列表
:return: 过滤后的分词结果
"""
# 初始化空列表,存储清洗后的结果
segments_clean = []
# 遍历每条分词结果
for content in contents:
line_clean = []
# 遍历每个词汇
for word in content:
# 仅保留非停用词的词汇
if word not in stopwords:
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean- 双层循环:外层遍历每条评价的分词结果,内层遍历每个词汇;
word not in stopwords:核心判断条件,剔除停用词,仅保留有意义的核心词汇。
4.3 过滤差评的停用词
python
# 将差评分词结果转为列表
cp_contents = cp_fc_results.content.values.tolist()
# 调用过滤函数
cp_fc_contents_clean_s = drop_stopwords(cp_contents, stopwords_list)4.4 过滤好评的停用词
python
# 将好评分词结果转为列表
yzpj_contents = yzpj_fc_results.content.values.tolist()
# 调用过滤函数
yzpj_fc_contents_clean_s = drop_stopwords(yzpj_contents, stopwords_list)4.5保存文件
python
cp_clean_df = pd.DataFrame({'content': cp_fc_contents_clean_s})
good_clean_df = pd.DataFrame({'content': yzpj_fc_contents_clean_s})
# 2. 保存为Excel文件
cp_clean_df.to_excel('cp_fc_result_clean.xlsx', index=False)
good_clean_df.to_excel('yzpj_fc_results_clean.xlsx', index=False)
print("停用词清洗完成!文件已保存:")
print("差评清洗结果:cp_fc_result_clean.xlsx")
print("好评清洗结果:yzpj_fc_results_clean.xlsx")运行结果: