一、前言
在Hadoop 2.0之前,MapReduce框架身兼"资源管理"与"作业调度"两职,随着集群规模扩大,这种紧耦合设计成为性能瓶颈。YARN(Yet Another Resource Negotiator)的诞生,正是为了解决这一问题------它将资源管理与计算框架解耦,让Hadoop从一个单一的计算平台,演变为一个支持多种计算模型(如Spark、Flink、Storm)的通用资源调度平台。
你可以把YARN想象成大数据集群的"操作系统"。它不关心你运行的是MapReduce、Spark还是其他什么程序,它只负责一件事:高效、公平地管理整个集群的CPU、内存等硬件资源,并把这些资源分配给上面跑的各种"应用程序"。
二、核心架构:从"紧耦合"到"中心调度"
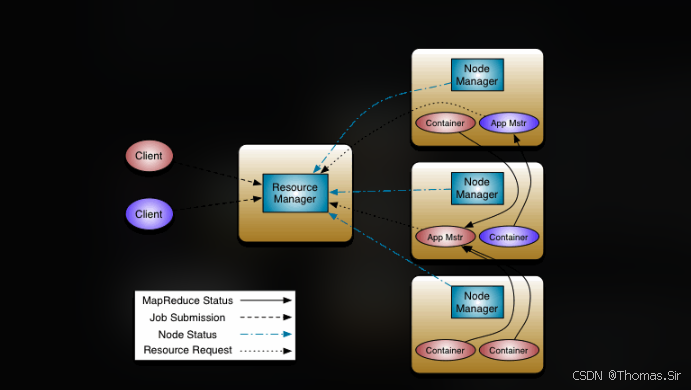
YARN采用经典的主从(Master/Slave)架构,核心思想是将Hadoop 1.0中JobTracker的职能一分为二:一个全局的资源管理者(ResourceManager)和多个每应用的任务管理者(ApplicationMaster)。这种分离带来了巨大的灵活性和可扩展性。
🏛️ YARN 核心组件角色图
ResourceManager (RM)
集群的"总指挥",负责所有应用的资源分配与调度。它包含两个关键子模块:调度器(Scheduler) 负责纯粹的资源分配决策;**应用管理器(ApplicationsManager)**负责接受应用提交、启动AM并在失败时重启它。
NodeManager (NM)
每个工作节点上的"管家"。它负责启动和管理RM分配来的容器(Container),监控本节点的资源使用情况(CPU、内存、磁盘、网络),并定期向RM发送心跳报告。
ApplicationMaster (AM)
每个应用程序的"项目经理"。一个应用对应一个AM。它向RM为内部的任务(如MapTask、ReduceTask)申请资源(Container),并与NM协作来启动、监控这些任务,在任务失败时负责重试。
Container
YARN对资源的抽象封装。它是一个动态资源分配单位,包含了任务运行所需的内存、CPU核心、磁盘等资源配额。任务必须在Container中运行,这为资源隔离和管理提供了基础。
三、工作流程:一个MapReduce作业的旅程
理解YARN最好的方式,是跟踪一个MapReduce作业从提交到完成的完整生命周期。这个过程清晰地展示了各组件如何协同工作。
具体步骤可以分解如下:
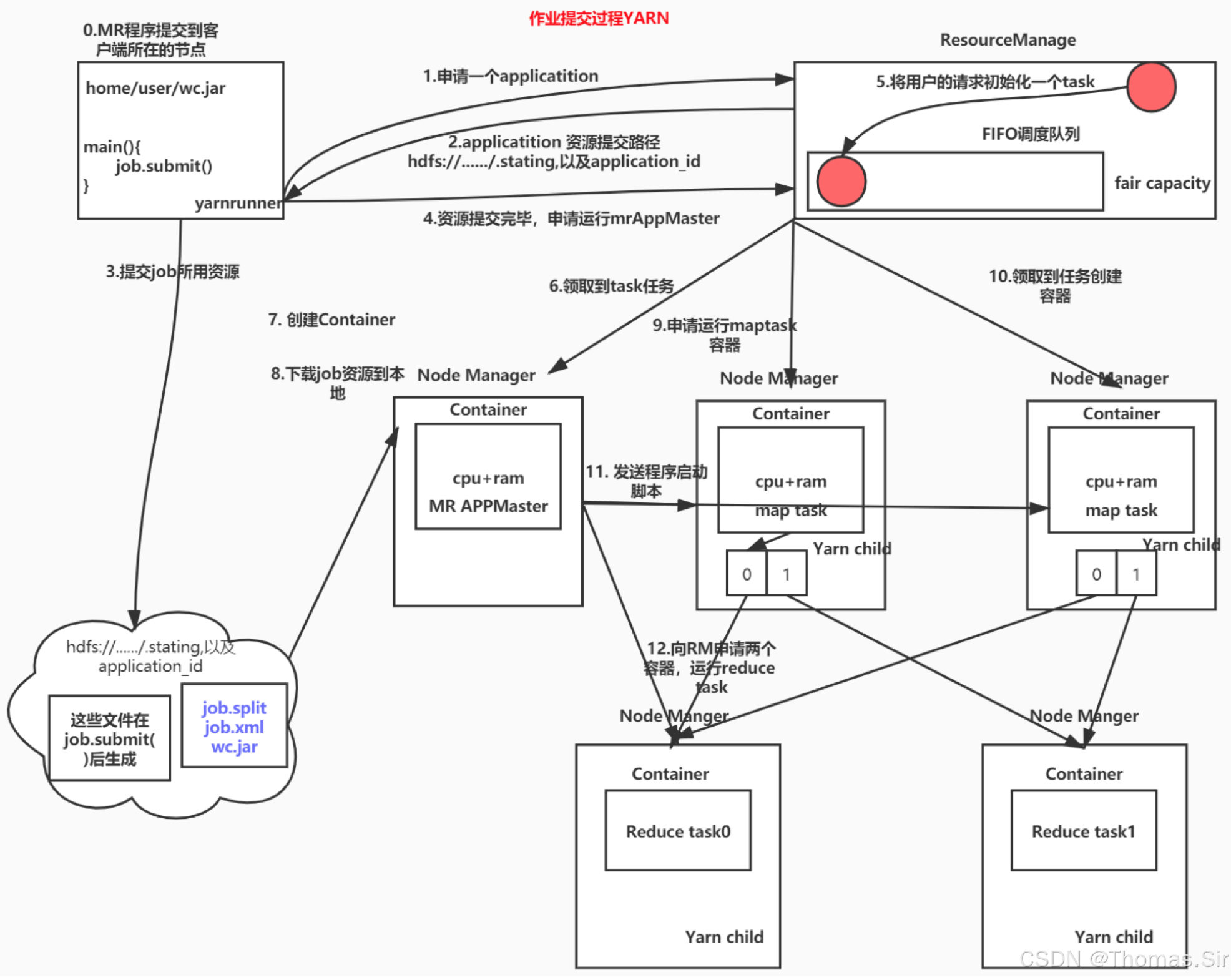
- 步骤 1:提交作业:客户端(Client)向ResourceManager提交应用,包括ApplicationMaster的启动命令和配置。
- 步骤 2:启动AM:RM的ApplicationsManager为应用分配第一个Container,并与某个NodeManager通信,在其中启动该应用的ApplicationMaster。
- 步骤 3:AM注册:AM启动后,首先向RM注册自己,以便客户端可以查询应用状态。
- 步骤 4:申请资源:AM根据计算逻辑(如需要多少MapTask)向RM的Scheduler轮询申请运行任务所需的Container资源。
- 步骤 5:启动任务:RM分配资源后,AM与对应的NodeManager通信,发送Container启动上下文(CLC),NodeManager据此启动Container并执行任务代码(如MapTask)。
- 步骤 6:监控与通信:运行中的任务向AM汇报状态和进度。AM持续监控,并在任务失败时向RM申请新资源以重启任务。
- 步骤 7:作业完成:所有任务完成后,AM向RM注销并自行关闭,其占用的Container资源被释放回集群。
四、深入机制:通信、调度与资源模型
YARN的稳定运行依赖于一套清晰的通信协议和灵活的调度策略。
📡 RPC通信协议
YARN组件间通过RPC(远程过程调用)协议进行通信,这是一种"拉"式模型,由客户端主动连接服务器。主要协议包括:
ApplicationClientProtocol
客户端与RM之间,用于提交应用、查询应用状态。
ApplicationMasterProtocol
AM与RM之间,AM通过它向RM注册、注销和为任务申请资源。
ContainerManagementProtocol
AM与NM之间,AM通过它要求NM启动或停止Container。
ResourceTracker
NM与RM之间,NM通过它向RM注册并定时发送心跳,汇报节点资源和Container状态。
🎯 可插拔的调度器
RM中的Scheduler是一个"纯调度器",它不负责监控应用状态或容错,只专注于根据策略分配资源。其核心策略是可插拔的,常见的两种是:
- 容量调度器(Capacity Scheduler):将集群资源划分为多个队列,每个队列被分配一定的资源容量。这种方式适合多租户共享的大集群,能保证每个组织或项目获得约定的最低资源配额。
- 公平调度器(Fair Scheduler):旨在让所有运行中的应用平均地共享资源。当只有一个应用时,它独占资源;当新应用提交时,资源会被释放并公平地重新分配。这种方式更适合动态变化、交互式查询多的场景。
五、Yarn 三种调度算法
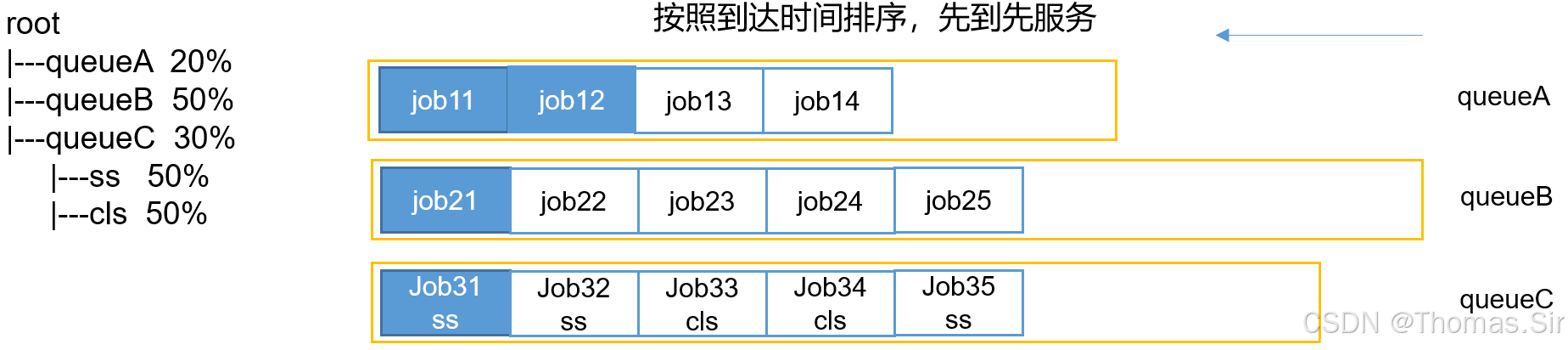
5.1 先进先出(FIFO Scheduler)
优点:简单易懂;
缺点:不支持多队列,生产环境很少使用;
容量调度器(Capacity Scheduler)(面试重点)
特点:
(1)多队列:每个队列配置一定资源量,每个队列采用FIFO调度策略
(2)容量保证:管理员可为队列设置资源最低保证和资源使用上限
(3)灵活性:如果一个队列资源有余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
(4)多租户:支持多用户共享集群和多应用程序同时运行。
为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
5.2 分配算法
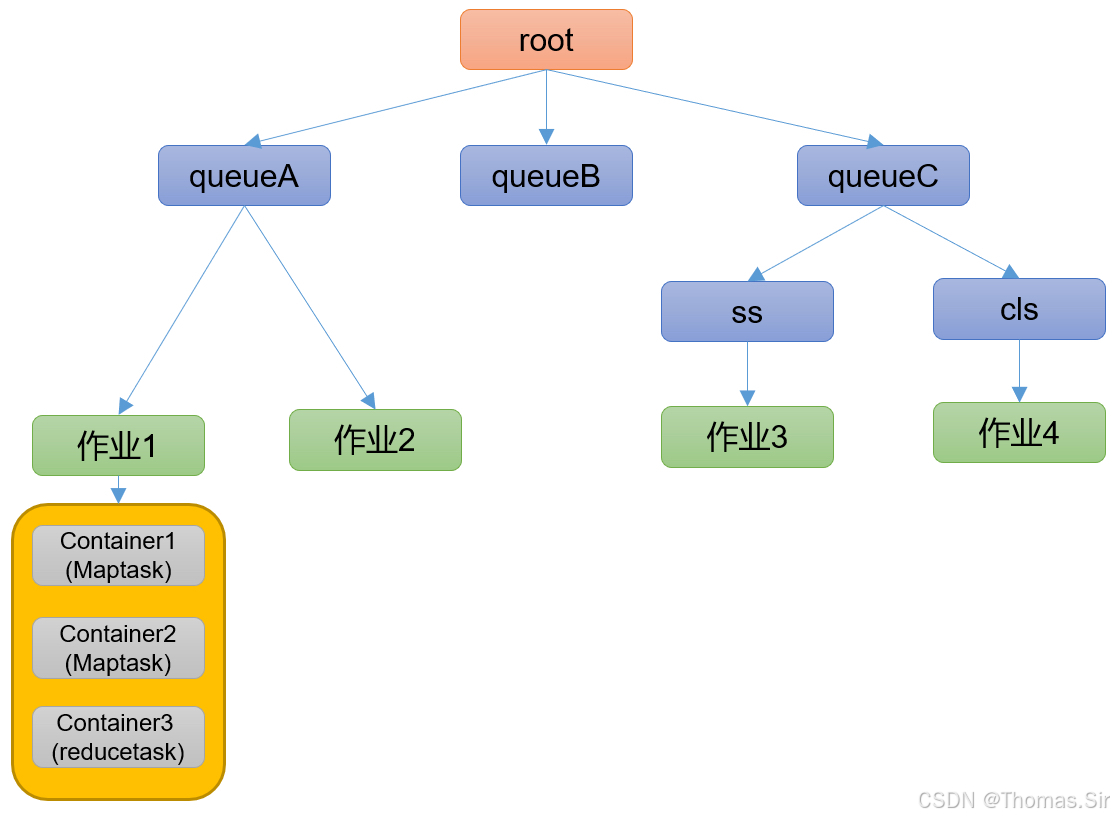
- 5.2.1 队列资源分配
从root开始,使用深度优先算法,有限选择资源占用率最低的队列分配资源。
- 5.2.2 作业资源分配
默认按照提交作业的优先级和提交时间顺序分配资源。
- 5.2.3 容器资源分配
按照容器的优先级分配资源;
如果优先级相同,按照数据的本地性原则:(1)任务和数据在同一节点
(2)任务和数据在同一机架
(3)任务和数据不在同一节点也不在同一机架
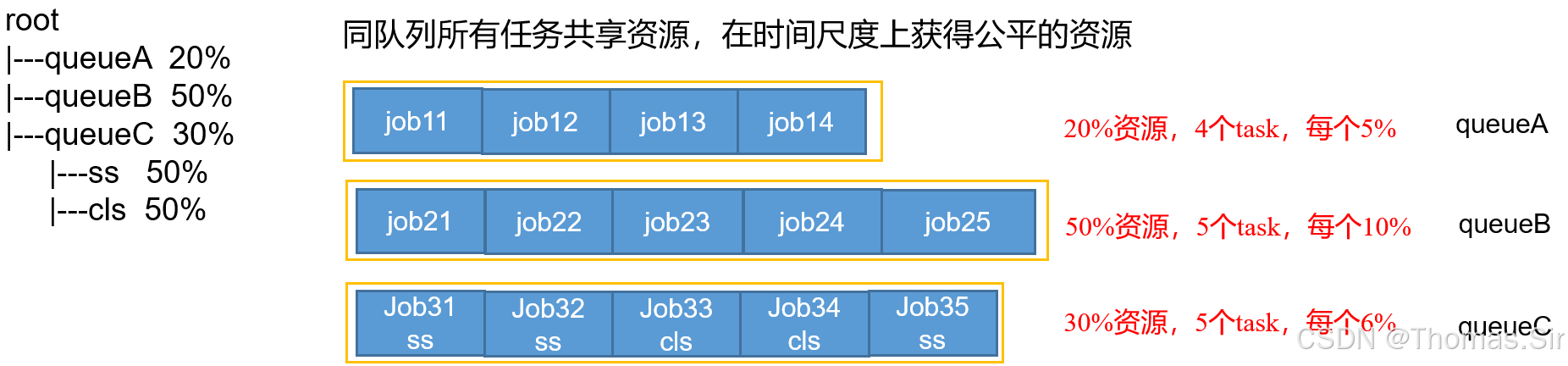
公平调度器(Fair Scheduler)
与容量调度器相同点:
(1)多队列:支持
(2)容量保证:管理员可为队列设置资源最低保证和资源使用上限
(3)灵活性:如果一个队列资源有余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
(4)多租户:支持多用户共享集群和多应用程序同时运行。
为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
与容量调度器不同点:
(1)核心调度策略不同
容量调度器:优先选择资源利用率低的队列
公平调度器:优先选择对资源的缺额比较大的
(2)每个队列可以单独设置资源分配方式
容量调度器:FIFO、DRF
公平调度器:FIFO、FAIR、DRF
分配方式
(1) FIFO策略:公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
(2)Fair策略:公平的策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
具体资源分配流程和容量调度器一致;(1)选择队列 (2)选择作业 (3)选择容器。此三步,每一步都是按照公平策略分配资源
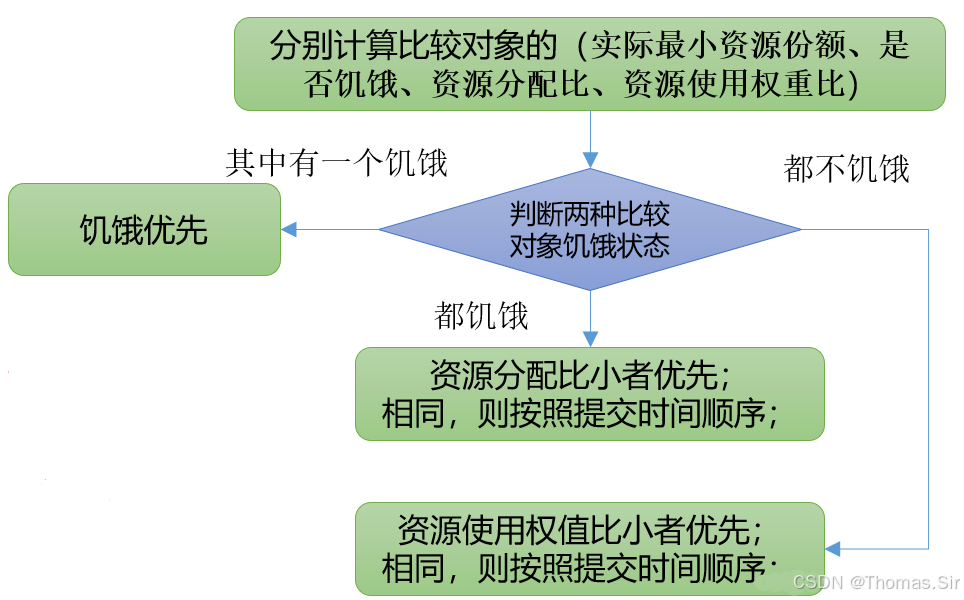
实际最小资源份额: mindshare = Min(资源需求量,配置的最小资源)
是否饥饿: isNeedy = 资源使用量 < mindshare(实际最小资源份额)
资源分配比: minShareRatio = 资源使用量 / Max (minshare,1)
资源使用权重比: useToWeightRatio = 资源使用量 / 权重
5.3 分配算法
5.3.1 队列资源分配
总资源100,有三个队列,需求 队列A 20、队列B 50、队列C 30:
第一次算:100/3 = 33.33
队列A:分33.33 --->多13.33
队列B:分33.33 --->少16.67
队列C:分33.33 --->多3.33
第二次算:(13.33+3.33)/1 =16.66
队列A:分20
队列B:分33.33+16.66 = 50
队列C :分30
5.2.2 作业资源分配
(a)不加权(重点是Job个数)
(b)加权(关注点是Job的权重)
和队列分配的分配方式一样,以此类推,不断计算只不过一个除以Job个数、一个除以Job的权重
DRF策略
DRF(Doninant Resouree Fairmess),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
DRF调度:
假设集群一共有100 CPU和10T内存,而应用A需要(2CPU,300GB),应用B需要(6 CPU,100GB )。则两个应用分别需要A(2%CPU,3%内存)和B(6%CPU,1%内存)的资源,这就意味着A是内存主导的,B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
六、Yarn 工作流程
YARN的工作流程分为如下几个步骤:
- 用户向YARN中提交应用程序,其中包括 ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。
- ResourceManager 为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束。
- ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
- 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
- NodeManager为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可以随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
- 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
七、YARN的价值与演进
YARN的出现,是Hadoop从单一的批处理系统迈向通用大数据平台的关键一步。
| 对比维度 | Hadoop 1.0 (MRv1) | Hadoop 2.0+ (YARN) |
|---|---|---|
| 架构核心 | JobTracker 同时负责资源管理和作业调度/监控,紧耦合。 | ResourceManager 负责资源调度,ApplicationMaster 负责作业生命周期管理,解耦。 |
| 可扩展性 | 差。JobTracker 成为单点瓶颈,集群规模受限(约4000节点)。 | 高。分布式架构,可轻松管理上万节点集群。 |
| 资源利用率 | 低。基于静态的Map Slot和Reduce Slot,资源无法灵活共享。 | 高。统一的资源模型(Container),资源按需动态分配。 |
| 计算框架支持 | 仅支持MapReduce。 | 支持多种框架(如Spark、Flink、Storm等)在同一个集群上运行,实现资源复用。 |
| 升级与兼容性 | N/A | 保持API兼容,旧版MapReduce作业无需修改即可在YARN上运行。 |
此外,YARN还在持续演进,引入了诸如资源预留系统(ReservationSystem) 用于保障重要作业的资源,以及**联邦机制(Federation)**以支持超大规模集群或将多个独立集群逻辑上统一管理。
八、总结与展望
YARN通过将资源管理与计算框架分离,为Hadoop生态注入了前所未有的灵活性。它让企业可以用一个统一的集群来支撑批处理、交互查询、流计算、图计算等多种负载,极大地提升了资源利用率和运维效率。从资源管理系统的视角看,YARN弱化了上层计算框架的差异,让Spark、Flink等后起之秀能与MapReduce和谐共处,共同挖掘数据的价值。
理解YARN,就是理解现代大规模数据平台如何高效、稳定地调度和管理数以万计的计算任务。它是隐藏在Spark华丽API和Flink精准流处理背后的无名英雄,是支撑起整个大数据计算世界的坚实基座。
九、写在最后的话
"YARN的本质,是将集群资源池化,并提供了一个标准的'资源请求与交付'接口。任何计算框架,只要实现了这个接口,就能在同一个资源池上跳舞。"