一、单机多卡并行
在训练和预测时,将一个小批量的计算切分到多个GPU上来达到加速目的。
常用的切分方案:
- 数据并行:将小批量分成n块,每个GPU拿到完整参数计算一块数据的梯度
- 模型并行:将模型分成n块,每个GPU拿到一块模型计算它的前向和反向结果(用于超大模型)
- 通道并行(数据+模型并行)
多GPU实现:
python
%matplotlib inline
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
python
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
def lenet(X, params):
h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])
h1_activation = F.relu(h1_conv)
h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))
h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])
h2_activation = F.relu(h2_conv)
h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))
h2 = h2.reshape(h2.shape[0], -1)
h3_linear = torch.mm(h2, params[4]) + params[5]
h3 = F.relu(h3_linear)
y_hat = torch.mm(h3, params[6]) + params[7]
return y_hat
loss = nn.CrossEntropyLoss(reduction='none')
python
# 把参数放到哪个设备
def get_params(params, device):
new_params = [p.clone().to(device) for p in params]
for p in new_params:
p.requires_grad_()
return new_params
new_params = get_params(params, d2l.try_gpu(0))
print('b1 weight:', new_params[1])
print('b1 grad:', new_params[1].grad)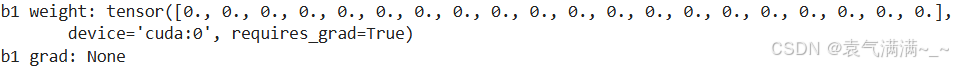
python
# allreduce函数将所有向量相加,并将结果广播给所有GPU
def allreduce(data):
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device)
for i in range(1, len(data)):
data[i] = data[0].to(data[i].device)
data = [torch.ones((1, 2), device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('before allreduce:\n', data[0], '\n', data[1])
allreduce(data)
print('after allreduce:\n', data[0], '\n', data[1])
python
# 将一个小批量数据均匀地分布在多个GPU上
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices) # 将输入数据分割并分发到指定的多个设备上
print('input :', data)
print('load into', devices)
print('output:', split)
python
def split_batch(X, y, devices):
"""将`X`和`y`拆分到多个设备上"""
assert X.shape[0] == y.shape[0]
return (nn.parallel.scatter(X, devices), nn.parallel.scatter(y, devices))
python
# 在一个小批量上实现多GPU训练
def train_batch(X, y, device_params, devices, lr):
X_shards, y_shards = split_batch(X, y, devices)
# 每个设备去算本设备样本上的损失函数,返回每个设备对应的损失
ls = [loss(lenet(X_shard, device_W),y_shard).sum()
for X_shard, y_shard, device_W in zip(
X_shards, y_shards, device_params)]
for l in ls:
l.backward() # 给每个设备计算梯度
with torch.no_grad():
# 对每个设备的每一层把梯度拿出来做allreduce
for i in range(len(device_params[0])):
allreduce([device_params[c][i].grad for c in range(len(devices))])
# 原因:
# 在数据并行训练中:每个GPU独立计算前向和反向传播,得到各自的梯度
# 通过allreduce同步梯度,确保所有模型副本保持一致
# 然后每个GPU用同步后的梯度更新自己的模型参数
for param in device_params:# 更新参数
d2l.sgd(param, lr, X.shape[0])
python
# 定义训练函数
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
device_params = [get_params(params, d) for d in devices]
num_epochs = 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
timer = d2l.Timer()
for epoch in range(num_epochs):
timer.start()
for X, y in train_iter:
train_batch(X, y, device_params, devices, lr)
torch.cuda.synchronize()
timer.stop()
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(
lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))
print(f'test acc: {animator.Y[0][-1]:.2f}, {timer.avg():.1f} sec/epoch '
f'on {str(devices)}')
python
# 在单个GPU上运行
train(num_gpus=1, batch_size=256, lr=0.2)
# 增加为2个GPU
train(num_gpus=2, batch_size=256, lr=0.2)多GPU简洁实现:
python
import torch
from torch import nn
from d2l import torch as d2l
python
def resnet18(num_classes, in_channels=1):
"""稍加修改的 ResNet-18 模型。"""
def resnet_block(in_channels, out_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
d2l.Residual(in_channels, out_channels, use_1x1conv=True,
strides=2))
else:
blk.append(d2l.Residual(out_channels, out_channels))
return nn.Sequential(*blk)
net = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64), nn.ReLU())
net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1, 1)))
net.add_module("fc",
nn.Sequential(nn.Flatten(), nn.Linear(512, num_classes)))
return net
net = resnet18(10)
devices = d2l.try_all_gpus()
python
def train(net, num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
net = nn.DataParallel(net, device_ids=devices)
trainer = torch.optim.SGD(net.parameters(), lr)
loss = nn.CrossEntropyLoss()
timer, num_epochs = d2l.Timer(), 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
for epoch in range(num_epochs):
net.train()
timer.start()
for X, y in train_iter:
trainer.zero_grad()
X, y = X.to(devices[0]), y.to(devices[0])
l = loss(net(X), y)
l.backward()
trainer.step()
timer.stop()
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))
print(f'test acc: {animator.Y[0][-1]:.2f}, {timer.avg():.1f} sec/epoch '
f'on {str(devices)}')
python
# 在单个GPU上训练网络
train(net, num_gpus=1, batch_size=256, lr=0.1)
# 使用 2 个 GPU 进行训练
train(net, num_gpus=2, batch_size=512, lr=0.2)二、分布式训练
分布式同步数据并行是多GPU数据并行在多机器上的拓展。更复杂的分布式有异步、模型并行。
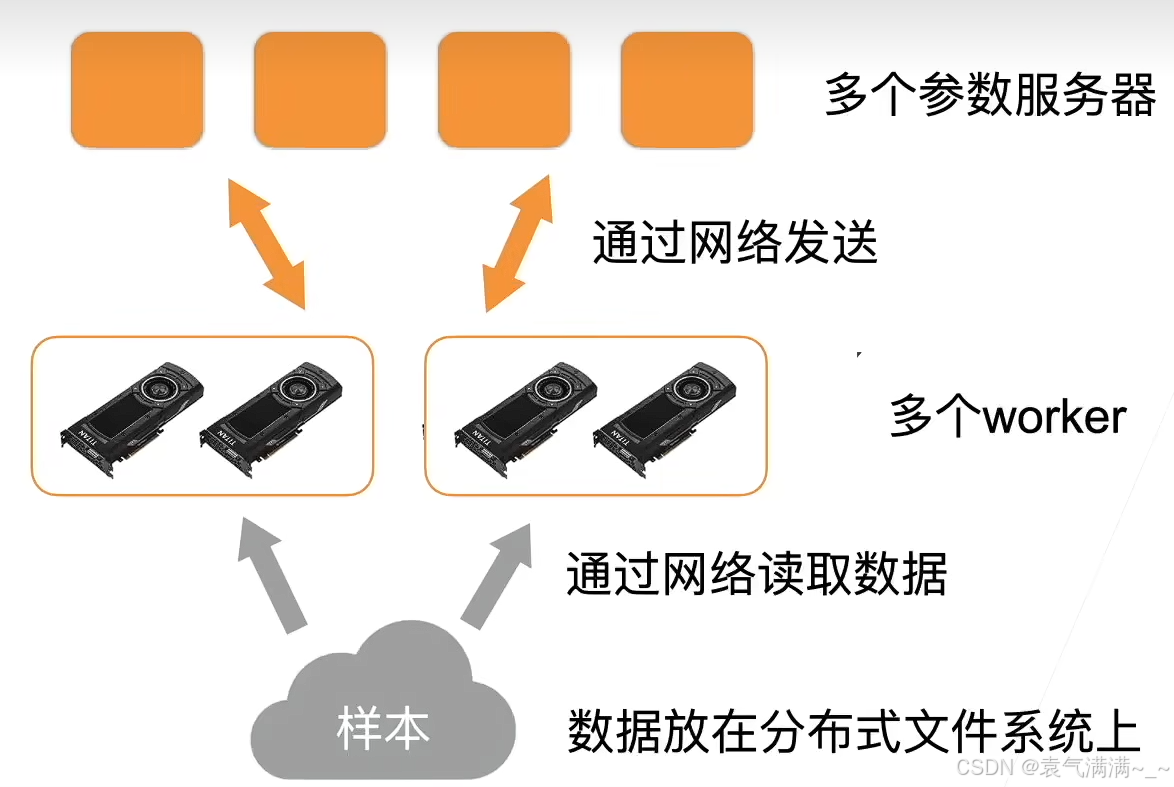
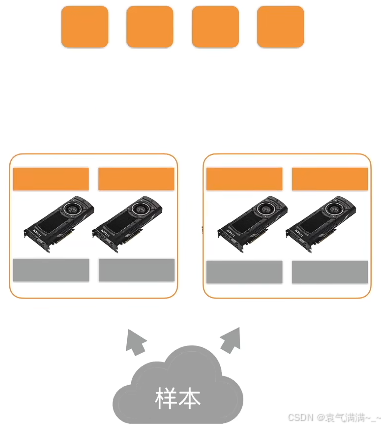
计算一个小批量:
- 每个计算服务器读取小批量中的一块
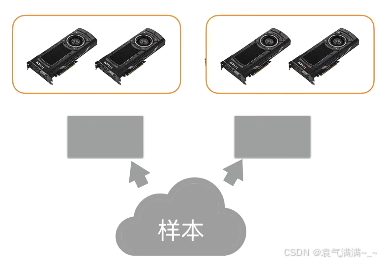
- 进一步将数据切分到每个GPU上

- 每个worker从参数服务器获取模型参数
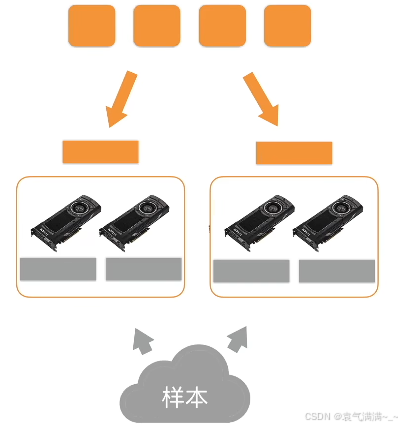
- 复制参数到每个GPU上
- 每个GPU计算梯度
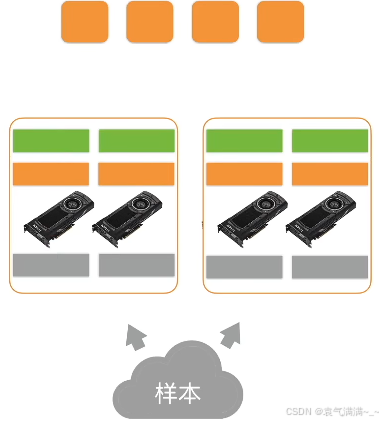
- 将所有GPU上的梯度求和
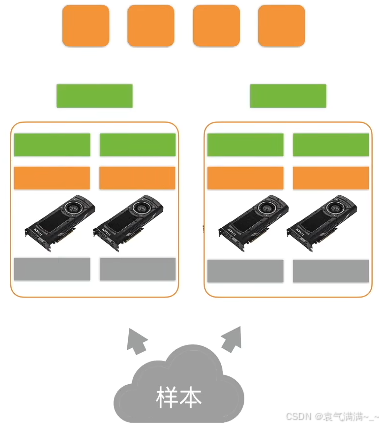
- 梯度传回服务器

- 每个服务器对梯度求和,并更新参数
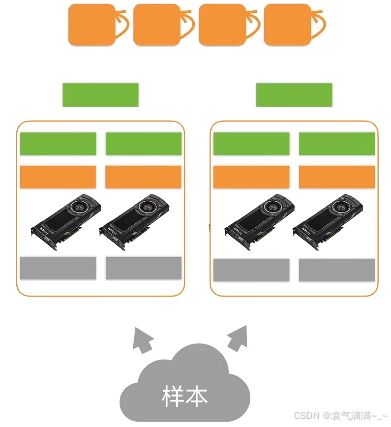
同步SGD:
- 每个worker都是同步计算一个批量,称为同步SGD。
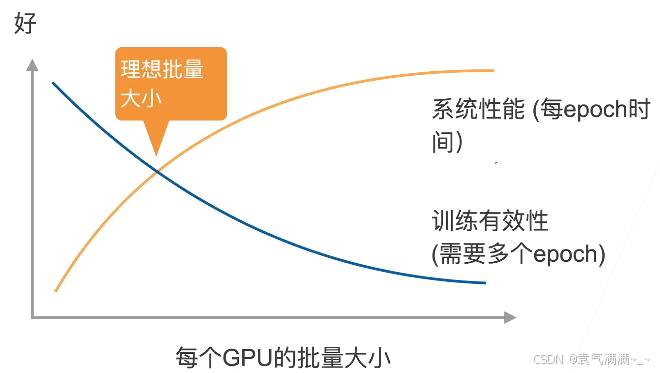
- 假设有 n 个GPU,每个GPU每次处理 b 个样本,那么同步SGD等价于在单GPU运行批量大小为 nb 的SGD。
- 在理想情况下, n 个GPU可以得到相对于单GPU的n倍加速。
性能:
- t1 = 在单GPU上计算b个样本梯度时间
- 假设有 m 个参数,一个worker每次发送和接收 m 个参数、梯度
- t2 = 发送和接收所用时间
- 每个批量的计算时间为 max(t1,t2)
- 选取足够大的b使得 t1>t2
- 增加 b 或 n 导致更大的批量大小,导致需要更多计算来得到给定的模型精度
三、BERT
它是基于微调的NLP模型。
BERT架构
- 只有编码器的Transformer
- 两个版本:
- Base:#blocks=12,hidden size=768,#heads=12,#parameters=110M
- Large:#blocks=24,hidden size=1024,#heads=16,#parameters=340M
- 在大规模数据上训练>3B词
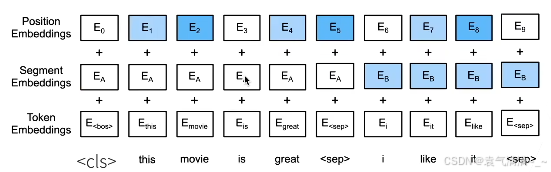
对输入的修改
- 每个样本是一个句子对
- 加入额外的片段嵌入
- 位置编码可学习
预训练任务1:带掩码的语言模型
- Transformer的编码器是双向,标准语言模型要求单向
- 带掩码的语言模型每次随机(15%概率)将一些词元换成<mask>
- 因为微调任务中不出现<mask>
- 80%概率下,将选中的词元变成<mask>
- 10%概率下,换成一个随机词元
- 10%概率下,保持原有的词元
预训练任务2:下一句子预测
- 预测一个句子对中两个句子是不是相邻
- 训练样本中:
- 50%概率选择相邻句子对:<cls> this movie is great <sep> i like it <sep>
- 50%概率选择随机句子对:<cls> this movie is great <sep> hello world <sep>
- 将<cls>对应的输出放到一个全连接层来预测
微调BERT
- BERT对每一个词元返回抽取了上下文信息的特征向量
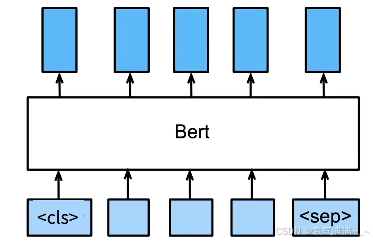
- 不同的任务使用不同的特征
- 句子分类:将<cls>对应向量输入到全连接层分类
- 命名实体识别(识别一个词元是不是命名实体,例如人名、机构等):将非特殊词元放进全连接层分类
- 问题回答(给定一个问题和描述文字,找出一个片段作为回答):对片段的每个词元预测它是不是回答的开头或结尾
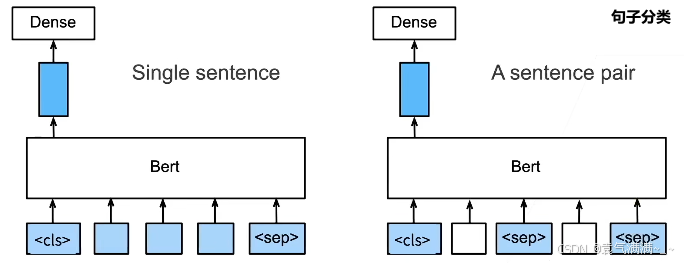
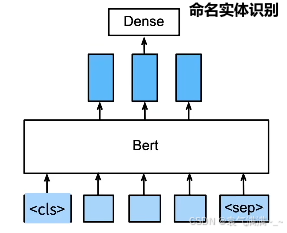
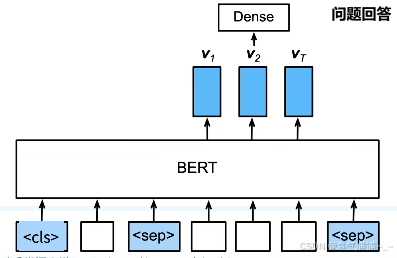
即使下游任务各有不同,使用BERT微调时均只需要增加输出层,但输入的表示和使用的BERT特征会不同。