学习笔记|B 站 UP 主 刘二大人 《PyTorch深度学习实践》视频知识点总结
结尾附上源代码
传送门 PyTorch深度学习实践------ 卷积神经网络
1. 卷积的数学表达
1.1多通道卷积计算公式
对于一个多通道输入特征图 X ∈ R C i n × H × W \boldsymbol{X} \in \mathbb{R}^{C_{in} \times H \times W} X∈RCin×H×W 和一个卷积核 K ∈ R C o u t × C i n × k h × k w \boldsymbol{K} \in \mathbb{R}^{C_{out} \times C_{in} \times k_h \times k_w} K∈RCout×Cin×kh×kw,输出特征图 Y ∈ R C o u t × H ′ × W ′ \boldsymbol{Y} \in \mathbb{R}^{C_{out} \times H' \times W'} Y∈RCout×H′×W′ 的每个元素可由以下公式计算:
Y c , i , j = ∑ c ′ = 1 C i n ∑ m = 0 k h − 1 ∑ n = 0 k w − 1 X c ′ , i + m , j + n ⋅ K c , c ′ , m , n + b c Y_{c, i, j} = \sum_{c'=1}^{C_{in}} \sum_{m=0}^{k_h-1} \sum_{n=0}^{k_w-1} X_{c', i+m, j+n} \cdot K_{c, c', m, n} + b_c Yc,i,j=c′=1∑Cinm=0∑kh−1n=0∑kw−1Xc′,i+m,j+n⋅Kc,c′,m,n+bc
符号说明
- C i n C_{in} Cin:输入通道数
- C o u t C_{out} Cout:输出通道数(即卷积核数量)
- k h , k w k_h, k_w kh,kw:卷积核的高度和宽度
- b c b_c bc:对应输出通道的偏置项
- i , j i, j i,j:输出特征图上的空间坐标
2. 直观过程图解
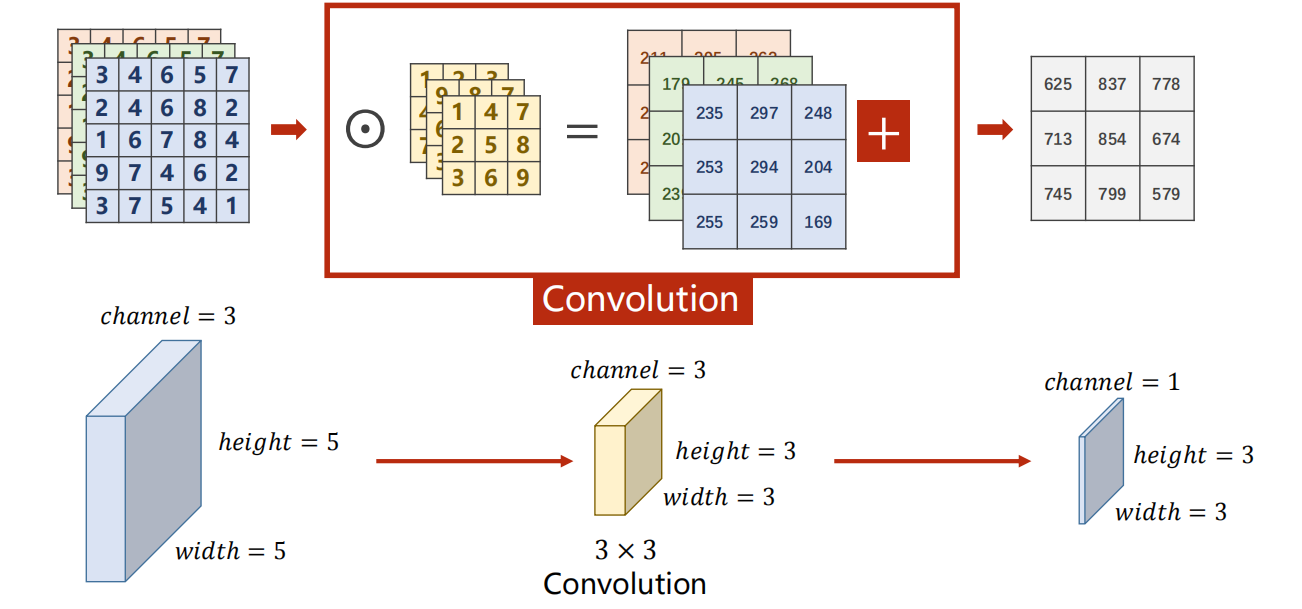
2.1 数值计算过程(上半部分)
- 输入 :左侧是一个
5×5的三通道输入特征图(可理解为一张三通道的小图像)。 - 卷积核 :中间是一个
3×3的三通道卷积核。 - 卷积操作 :卷积核在输入特征图上滑动,每到一个位置,就与对应区域的所有通道进行逐元素相乘再求和的点积运算,得到一个输出值。
- 偏置与输出 :将所有点积结果加上偏置(图中"+"号),最终得到右侧
3×3的单通道输出特征图。
2.2 维度变化过程(下半部分)
- 输入维度 :
height = 5, width = 5, channel = 3 - 卷积核 :
3 × 3 - 输出维度 :
height = 3, width = 3, channel = 1
这里的维度变化遵循了无填充(padding=0)、步长为1(stride=1)的卷积尺寸计算公式:
输出尺寸 = 输入尺寸 − 卷积核尺寸 步长 + 1 = 5 − 3 1 + 1 = 3 \text{输出尺寸} = \frac{\text{输入尺寸} - \text{卷积核尺寸}}{\text{步长}} + 1 = \frac{5 - 3}{1} + 1 = 3 输出尺寸=步长输入尺寸−卷积核尺寸+1=15−3+1=3
这一过程的本质是:用一个可学习的卷积核作为"特征检测器",在输入中滑动并提取与核模式匹配的特征,最终将多通道输入压缩为单通道的特征图,实现了从原始数据到有效特征的转换。
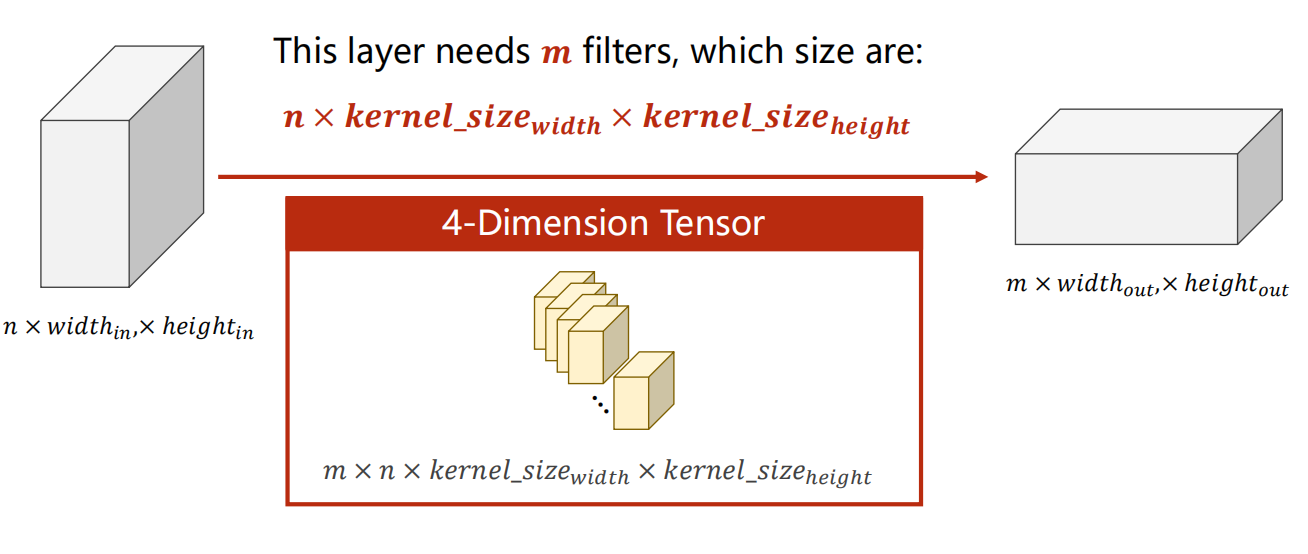
图中明确指出,该层需要 m m m 个滤波器,每个滤波器的尺寸是 n × k e r n e l _ s i z e w i d t h × k e r n e l _ s i z e h e i g h t n \times kernel\size{width} \times kernel\size{height} n×kernel_sizewidth×kernel_sizeheight。
- 每个滤波器(卷积核)都能"看到"输入的全部 ( n ) 个通道,从而学习到跨通道的复杂特征。
- 所有 ( m ) 个滤波器组合在一起,就构成了完整的四维权重张量 ( m \times n \times k_w \times k_h )。
- 最终,输入的 ( n ) 个通道被映射为输出的 ( m ) 个通道,实现了特征的提取与通道数的变换,为后续的网络层提供了更丰富、更抽象的特征表示。
视频中代码
python
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # -1 此处自动算出的是320
x = self.fc(x)
return x
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()1、torch.nn.Conv2d(1,10,kernel_size=3,stride=2,bias=False)
1是指输入的Channel,灰色图像是1维的;10是指输出的Channel,也可以说第一个卷积层需要10个卷积核;kernel_size=3,卷积核大小是3x3;stride=2进行卷积运算时的步长,默认为1;bias=False卷积运算是否需要偏置bias,默认为False。padding = 0,卷积操作是否补0。
2、self.fc = torch.nn.Linear(320, 10),这个320获取的方式,可以通过x = x.view(batch_size, -1) # print(x.shape)可得到(64,320),64指的是batch,320就是指要进行全连接操作时,输入的特征维度。
GPU版本
python
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # -1 此处自动算出的是320
# print("x.shape",x.shape)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
return correct/total
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list,acc_list)
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()