Transformer实战(37)------Transformer模型训练追踪与监测
0. 前言
在训练深度学习模型过程中,需要考虑到多种因素,以进行高效训练。在本节中,将介绍通过工具进行模型训练追踪,学习如何通过日志记录并使用 TensorBoard 和 Weights & Biases (W&B) 进行监控。使我们能够高效地托管和追踪模型数据,如损失值或其他有助于优化模型训练的度量指标。
1. 追踪模型指标
我们已经学习了如何训练语言模型,简单分析了最终结果,了解了模型训练过程,并与超参数优化 (HyperParameter Optimization, HPO)进行了比较。在本节中,我们将介绍如何通过一些外部工具进行模型训练的可视化监控。
深度学习中有许多重要的模型训练追踪框架,如 MLflow、Neptune、TensorBoard、W&B、CodeCarbon 和 ClearML。本节中,我们将使用 TensorBoard 和 W&B。前者将训练结果保存到本地并在训练结束时进行可视化,而后者则可以在云平台上实时监控模型训练进度。接下来,从 TensorBoard 开始。
2. 使用 TensorBoard 追踪模型训练
TensorBoard 是专为深度学习设计的可视化工具。它具有许多功能,例如追踪训练、将嵌入投影到低维空间以及可视化模型图,本节中,我们主要使用它来追踪和可视化损失等度量指标。对于 Transformer 模型来说,使用 TensorBoard 追踪指标非常简单,只需在模型训练代码中添加几行代码即可,其他部分几乎保持不变。
本节中,我们将训练 IMDb 情感分析微调模型,并追踪指标。我们使用 IMDb 数据集训练了一个情感模型,数据集包括 4000 个训练样本、1000 个验证样本和 1000 个测试样本。
(1) 如果尚未安装 TensorBoard,可以通过以下命令安装:
shell
$ pip install tensorboard(2) 保持 IMDb 情感分析的其他代码不变,设置训练参数:
python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
# The output directory where the model predictions and checkpoints will be written
output_dir='./MyIMDBModel',
do_train=True,
do_eval=True,
# The number of epochs, defaults to 3.0
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
# Number of steps used for a linear warmup
warmup_steps=100,
weight_decay=0.01,
logging_strategy='steps',
# TensorBoard log directory
logging_dir='./logs',
logging_steps=50,
# other options : no, steps
evaluation_strategy="steps",
save_strategy="steps",
fp16=cuda.is_available(),
load_best_model_at_end=True
)其中,logging_dir 的值将作为参数传递给 TensorBoard。由于训练数据集的大小为 4000,训练批大小为 16,因此每个 epoch 有 250 步 (4000 / 16),也就是说,三个 epoch 共为 750 步。
将 logging_steps 设置为 50,表示采样间隔。由于间隔减少,模型性能的上升或下降细节会被更详细地记录下来。我们可以进一步缩小采样间隔,以获得更高的分辨率,便于深入分析。
每隔 50 步,模型的性能将通过我们在 compute_metrics() 中定义的指标进行评估,包括准确率(accuracy)、F1 分数、精确度 (precision) 和召回率 (recall)。因此,我们将记录 15 次 (750 / 50) 性能评估结果。运行 trainer.train() 时,训练过程开始,并在 logging_dir='./logs' 目录中记录日志。
将 load_best_model_at_end 设置为 True,以便管道加载性能最好的模型权重。一旦训练完成,可以看到最佳模型是从 checkpoint-200 加载的,损失值为 0.465。
(3) 启动 TensorBoard:
shell
$ tensorboard --logdir logs输出结果如下所示:
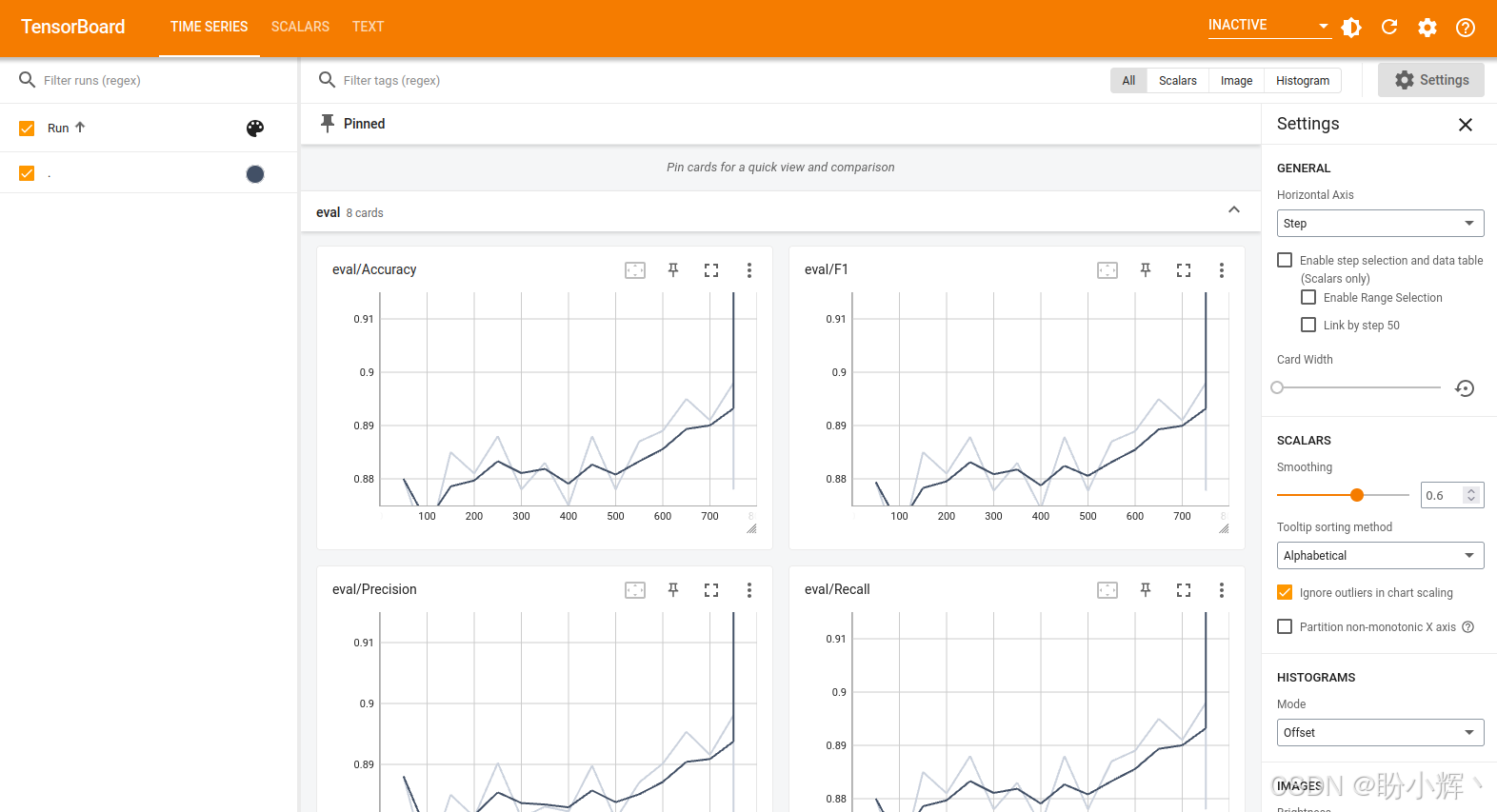
可以看到,我们可以追踪之前定义的指标。横轴从 0 到 750,这是我们之前计算的步数。查看 eval/loss 图表,点击左下角的最大化图标时,可以看到下图:

在上图中,我们将 TensorBoard 仪表板左侧的平滑度设置为 0,以便更精确地查看分数并关注全局最小值。如果训练过程波动性较大,平滑功能可以帮助查看整体趋势,它起到移动平均 (Moving Average, MA) 的作用。观察上图可以看到,在第 200 步时最佳模型的损失值为 0.465。
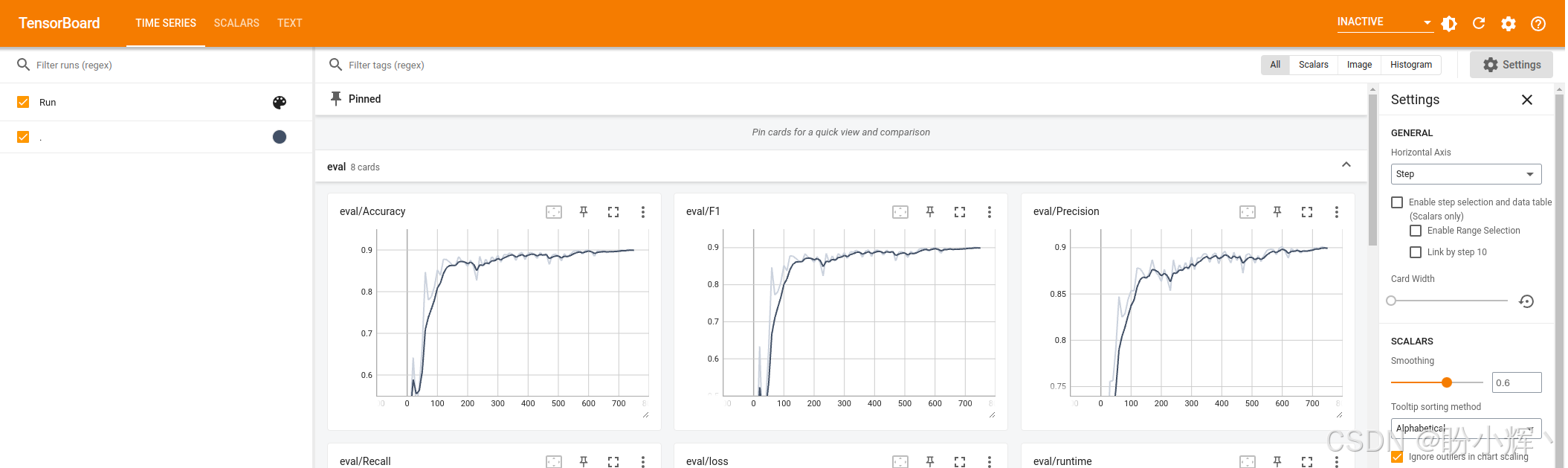
接下来,如果我们将 logging_steps 设置为 10,就能获得更高的分辨率,如下图所示。因此,将记录 75 次 (750 / 10) 性能评估结果。当我们以这种分辨率重新运行整个流程时,在第 220 步时得到了最佳模型,损失值为 0.238,优于之前的结果,如下图所示。由于分辨率更高,会观察到更多的波动:
我们已经学习了 TensorBoard 的使用。接下来,我们使用 W&B 进行实时模型训练追踪。
3. 使用 W&B 实时追踪模型训练
与 TensorBoard 不同,W&B 提供了一个云平台仪表盘,我们可以在云端追踪和备份所有训练结果,还支持团队协作开发和共享。训练代码运行在本地机器上,而日志保存在 W&B 云端。最重要的是,我们可以实时追踪训练过程,并实时将结果共享。我们可以通过对现有代码进行微小改动来启用 W&B 进行模型训练追踪。
(1) 首先,我们需要在wandb.ai上创建一个账户,然后安装 Python 库:
shell
$ pip install wandb(2) 接下来,以 IMDb 情感分析代码为例,并对其进行少量修改。导入所需库并登录 W&B:
python
import wandb
!wandb loginW&B 会要求提供一个API 密钥,此外,也可以通过设置 WANDB_API_KEY 环境变量来提供 API 密钥:
shell
!export WANDB_API_KEY=e7d*********(3) 保持 IMDb 情感分析代码不变,只需向 TrainingArguments 中添加两个参数:report_to="wandb" 和 run_name="...",以启用 W&B 的日志记录功能:
python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
# The output directory where the model predictions and checkpoints will be written
output_dir='./MyIMDBModel',
do_train=True,
do_eval=True,
# The number of epochs, defaults to 3.0
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
# Number of steps used for a linear warmup
warmup_steps=100,
weight_decay=0.01,
logging_strategy='steps',
# TensorBoard log directory
logging_dir='./logs',
logging_steps=50,
# other options : no, steps
evaluation_strategy="steps",
save_strategy="steps",
fp16=True,
load_best_model_at_end=True,
learning_rate=5e-5,
report_to="wandb",
run_name="IMDB-batch-16-lr-5e-5"
)(4) 然后,调用 trainer.train() 时,日志记录会开始上传到 W&B 的云端。调用后,检查云端仪表盘并查看其变化。当 trainer.train() 成功完成后,执行以下代码以告知 W&B 实验结束:
python
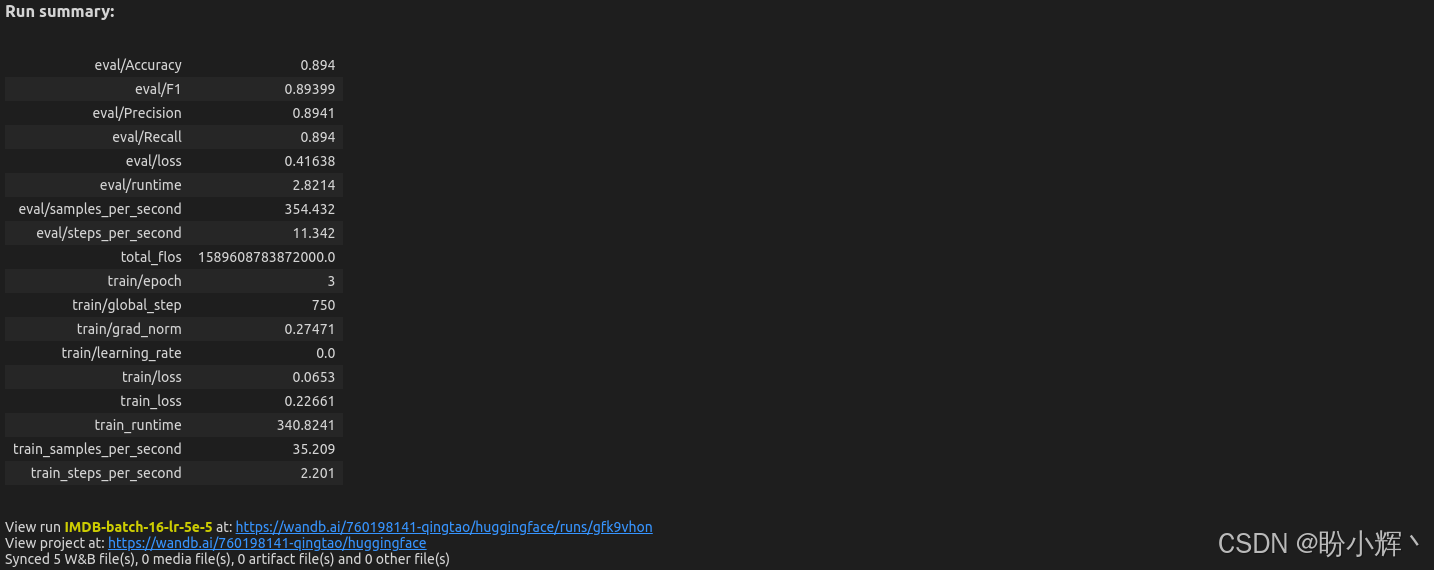
wandb.finish()执行后,运行历史也会输出到本地:
(5) 连接到 W&B 提供的链接时,可以看到以下界面:
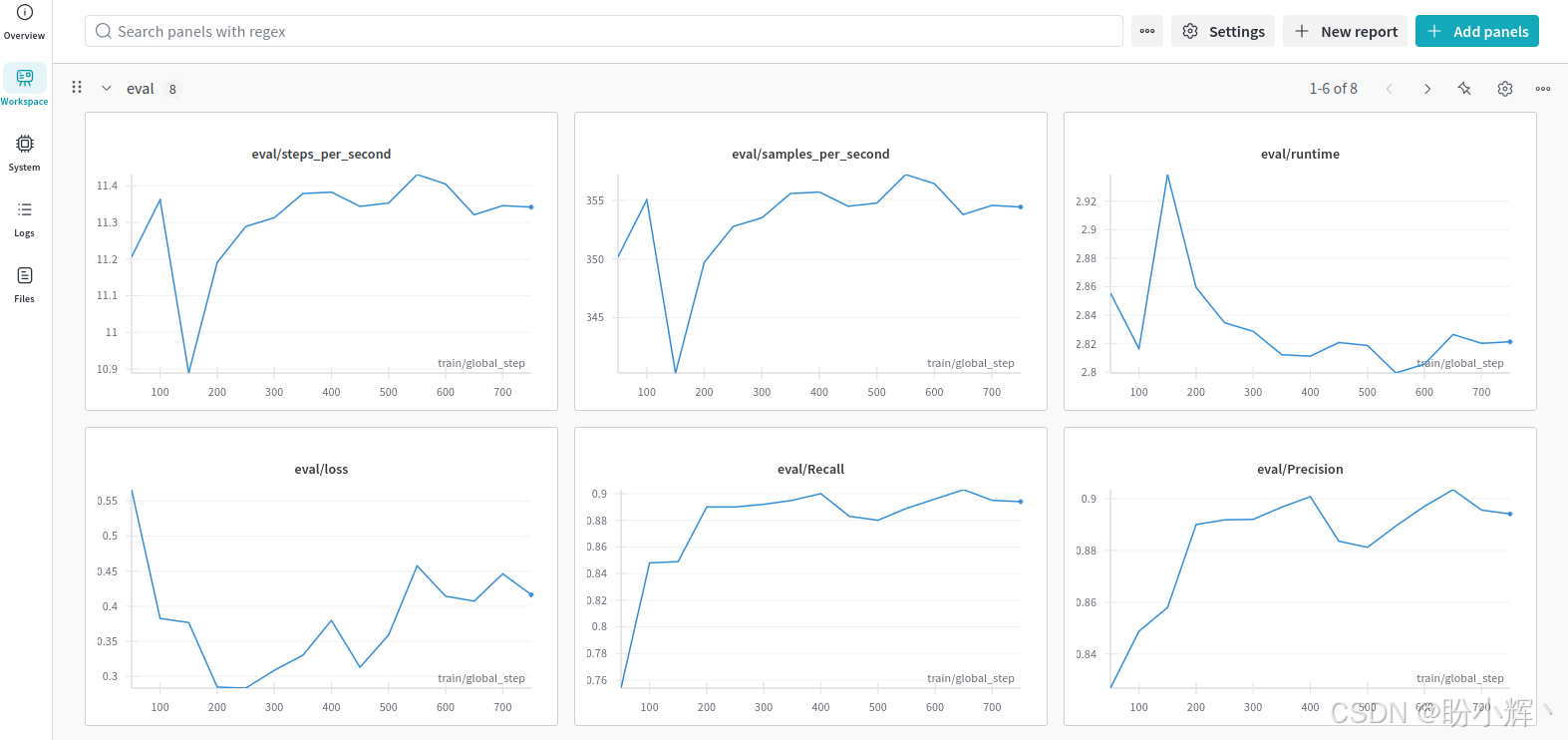
可视化界面为我们提供了单次运行的汇总性能结果。可以看到,我们可以追踪在 compute_metrics() 函数中定义的指标。
(6) 接下来,查看评估损失。下图显示了与 TensorBoard 相同的图表,其中最小损失值约为 0.28319,出现在第 250 步。
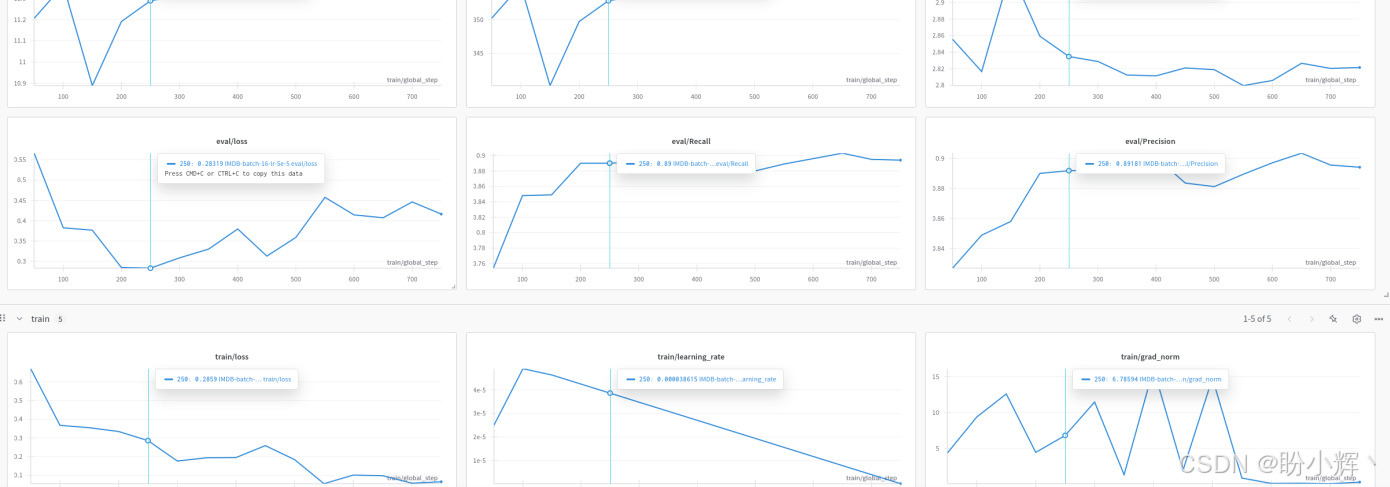
我们只可视化了单次运行的结果,W&B 允许我们动态地同时探索多次运行的结果。例如,我们可以可视化使用不同超参数(如学习率或批大小)的模型结果。为此,我们需要用不同的超参数设置实例化 TrainingArguments 对象,并相应地更改 run_name="..." 来区分每次运行。
(7) 下图展示了我们使用不同超参数进行的多次 IMDb 情感分析运行结果。还可以看到我们使用了不同的批大小和学习率:
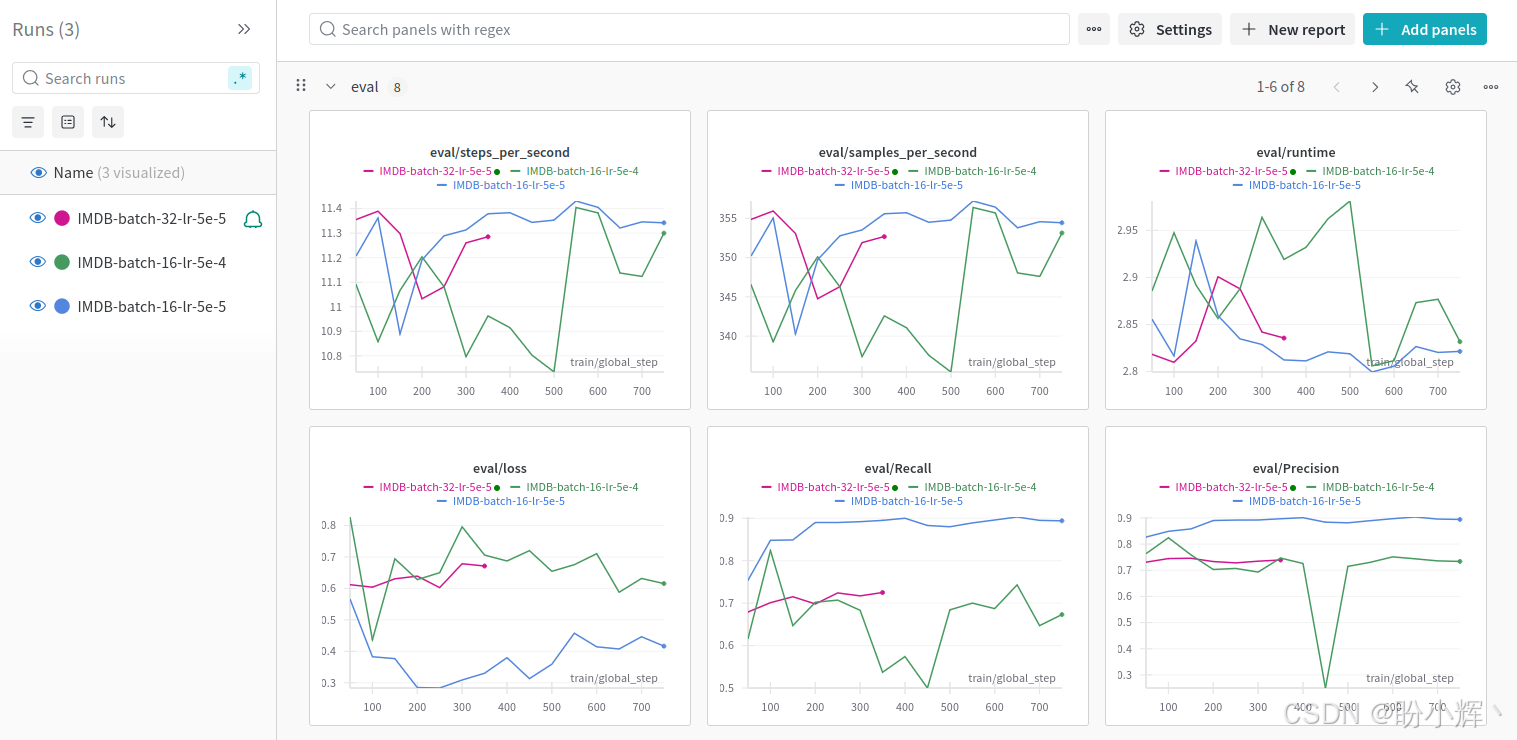
W&B 还提供了许多其它有用的功能,例如,它可以自动化超参数优化和模型空间搜索,称为 W&B sweeps。此外,它还提供了与 GPU 消耗、CPU 利用率等相关的系统日志。使用这些实用工具对于开发更好的模型至关重要。
小结
在本节中,我们介绍了模型训练追踪工具。我们学习了如何追踪模型训练过程,获得更高质量的模型并进行错误分析。我们使用了两种工具来监控训练过程:TensorBoard 和 W&B,这些工具能够有效地追踪并优化模型训练。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型
Transformer实战(35)------跨语言相似性任务
Transformer实战(36)------Transformer模型部署