1 模型概述
在自然语言处理(Natural Language Processing, NLP)领域,Transformer1架构的问世掀起了技术革新的浪潮。Decoder-Only模型作为Transformer1架构的重要变体,近年来实现了跨越式发展。与Encoder-Only、Encoder-Decoder等架构形式不同,Decoder-Only模型深耕文本生成任务,能够基于对输入信息的深度理解,生成逻辑连贯、语义通顺的文本内容。该模型的核心优势在于,可依托给定上下文逐步生成符合人类语言表达习惯的文本序列,因此在文章创作、智能对话系统、代码自动生成等实际场景中均展现出优异的表现。
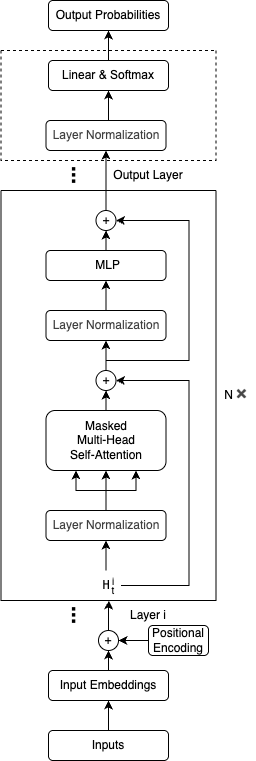
图1-1 Decoder-Only模型结构
模型的整体结构如图 1-1 所示。首先,先把输入作嵌入,把输入嵌入和位置嵌入直接相加,然后进入解码器。解码器由N个相同的解码层组成,每一层由Masked多头自注意力机制1和多层感知机(Multi Layer Perceptron,MLP)两个子层组成,每个子层都是一个残差块。在得到解码器的输出之后,经过输出层就完成了一次文本生成。注意为了使模型中的残差连接生效,所有子层和嵌入层的输出维度都是 dmodel。
2 嵌入层
嵌入层将输入的文本序列中的每个Token转化为对应的稠密向量表示。这一步骤使得模型能够从原始的离散文本数据中提取出更具语义信息的连续向量,便于后续的处理。
嵌入层是模型处理文本输入的第一步,为后续的注意力机制和其他层提供了可操作的向量数据基础。Decoder-Only模型一般使用类似于Transformer1中的可学习嵌入层将输入Tokens转换为维度为dmodel的向量。
3 位置编码
由于Transformer1架构本身不具备对序列中元素位置信息的天然感知能力,所以就需要将"位置编码"添加到输入嵌入中为每个Token的嵌入向量添加位置信息,这样,模型在处理文本时就能够区分不同位置的Token,从而捕捉到文本的顺序信息。
"位置编码"是补充文本位置信息的关键环节,使得模型在后续的计算中能够利用位置特征进行更准确的语义理解和文本生成。
4 Masked多头自注意力机制
注意力机制是Decoder-Only模型的核心组件之一。它通过计算每个Token与其他Token之间的注意力分数,确定当前Token在生成过程中对其他Token的关注程度。具体来说,每个Token会生成查询、键和值向量,通过点积计算注意力分数。在注意力机制中,划分多头可以让模型在并行的低维子空间中,同时捕捉多种不同类型的依赖关系(如局部依赖、全局依赖、特定语义关联),既提升了模型的表达能力,又优化了计算效率。同时,为了保证在生成过程中模型只能利用已生成的前文信息,而不能"偷看"未来的信息,使用因果掩码进行限制。
注意力机制负责捕捉文本中的长距离依赖关系和上下文信息,使得模型能够根据前文生成合理的后续文本,在文本生成的连贯性和逻辑性方面起着至关重要的作用。
5 MLP
MLP 对每个 Token 经过注意力机制处理后的隐藏状态进行进一步的特征变换。Decoder-Only模型的MLP一般由两层全连接网络组成,对每个Token的隐藏状态独立进行处理,增加模型的非线性表达能力,从而能够学习到更复杂的文本特征。
MLP 是对注意力机制输出进行特征增强的重要环节,为模型生成高质量的文本输出提供了更强大的特征基础。
6 层归一化
层归一化对每个Token的隐藏状态在特征维度上执行归一化操作,能够有效稳定模型训练过程、加速收敛。在Decoder-Only模型的演进过程中,早期结构借鉴原始Transformer1,在多头自注意力层与MLP层的输出之后施加层归一化;而当前主流模型则普遍采用前置归一化策略,即在各子层输入之前进行归一化处理,进一步提升深度模型训练的稳定性。
通过在子层计算前对特征分布进行标准化,层归一化可显著缓解深层网络训练过程中的梯度波动问题,使模型在大规模数据与深层架构下仍能平稳收敛。
7 残差连接
残差连接通过将输入直接加到经过处理后的输出上,解决了深层神经网络训练过程中的梯度消失问题,使得模型能够更容易地学习到复杂的特征。在注意力机制和MLP的输出中,都会添加残差连接操作。残差连接和层归一化都是保证模型训练稳定性和高效性的关键技术,对于构建深层、强大的Decoder-Only模型起着不可或缺的作用。
8 输出层
最后一层依次由一个层归一化、一个线性变换和一个Softmax函数组成。线性变换将解码器输出的隐藏状态映射到与词表大小相同的维度,Softmax函数则将这些值转化为词表中每个Token的概率分布。模型根据这个概率分布选择概率最高的Token作为生成的下一个词。输出层是模型生成最终文本输出的环节,将模型学习到的语义和特征信息转化为具体的文本Tokens。
9 训练
训练过程中采用经典的Teacher Forcing策略。对于自回归语言模型(Language Model,LM)而言,下一个词的预测依赖于前文所有已生成的 Tokens。若在训练阶段让模型基于自身上一步的预测结果继续生成,会导致误差累积传播,使得序列越往后预测难度越大、损失越高,最终造成模型优化困难。
因此,在训练时会将真实标注序列作为解码器的输入,使模型每一步都基于正确的历史Tokens进行预测。该方式能够仅对当前待预测Token进行损失计算与梯度更新,避免前期预测误差对后续步骤产生干扰,从而显著提升训练稳定性与收敛速度。
训练时,解码器的输入记为 decoder_input_ids,其与标签 labels 高度相关但存在明确的错位关系。其中,labels=tokens+ending letter,decoder_input_ids=start letter + tokens,二者形成一一对应的序列偏移,使得解码器的输出可直接与labels计算损失。
在注意力机制中,为确保模型在生成过程中仅能利用已生成的前文信息,而无法依赖未来位置的 Tokens,采用因果掩码进行约束,从而保证训练与推理阶段的行为一致。
10 推理
在自回归LM的推理阶段,每个词的生成均依赖于此前所有已生成的序列。为启动生成过程,模型首先需要输入一个起始标记(start letter),不同模型所采用的起始标记通常不同。
在生成首个词后,模型会将起始标记与已预测出的所有Tokens拼接为新的输入序列,继续迭代生成下一个词。这一过程不断重复,直至模型输出终止标记(ending letter),生成过程才正式结束。
参考文献
1 Vaswani A, Shazeer N, Parmar N, et al. Attention is all you needJ. Advances in neural information processing systems, 2017, 30.
2 He K, Zhang X, Ren S, et al. Deep residual learning for image recognitionC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.