幻觉的定义及出现的原因
幻觉的定义
大语言模型在处理自然语言时,有时会出现幻觉,表现为回答不准确或前后不一致的问题。这些幻觉可以分为两类:
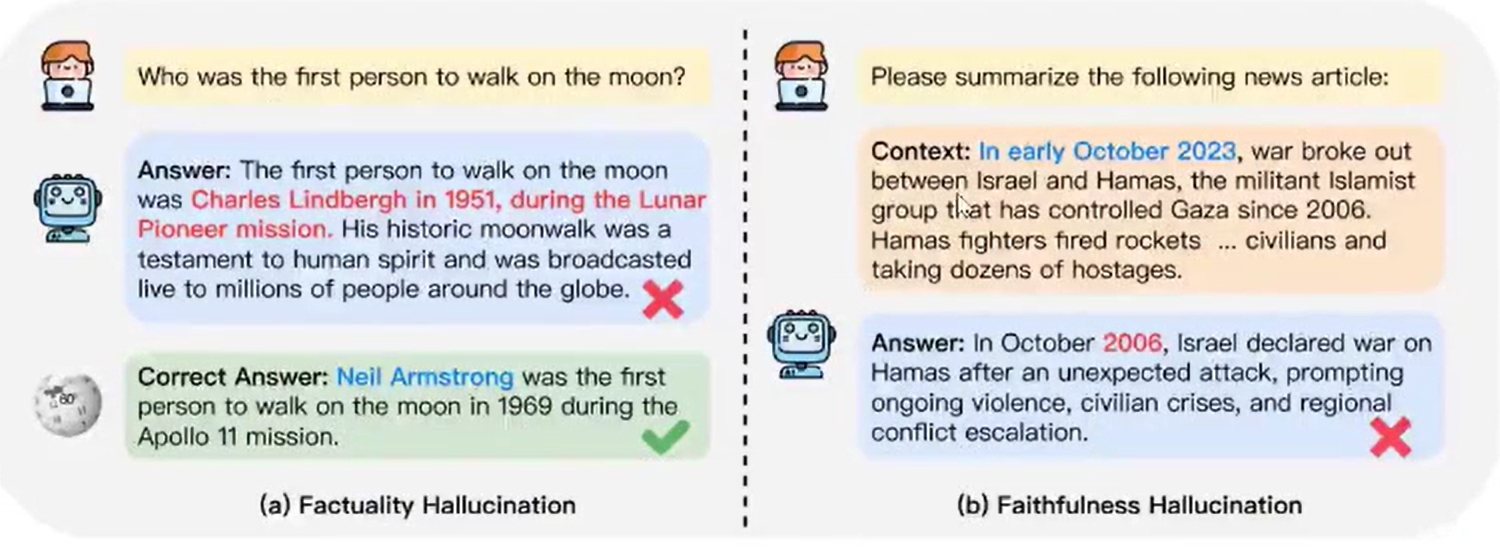
- 事实性幻觉: 指模型生成的内容与可验证的现实事实不一致。比如提问 "第一个在月球上行走的人是谁?",模型回复 "Charles Lindbergh 在 1951 年月球先驱任务中第一个登上月球",而实际上,第一个登上月球的人是 Neil Armstrong。而事实性幻觉又分为事实不一致(与现实世界信息相矛盾)和事实捏造(压根没有,无法根据现实信息验证)。
- 忠实性幻觉: 指模型生成的内容与用户的指令或上下文不一致。比如让模型总结今年 10 月的新闻,结果模型却在说 2006 年 10 月的事。忠实性幻觉也可以细分,分为指令不一致(输出偏离用户指令)、上下文不一致(输出与上下文信息不符)、逻辑不一致(推理步骤以及与最终答案之间不一致)三类。
例如下方左侧为 事实性幻觉,右侧为 忠实性幻觉:
产生幻觉的原因
那么致使大模型产生幻觉的原因都有哪些?其实可以划分成三大来源:数据源、训练过程 和 推理。
数据源导致的幻觉
首先病从口入,大模型的粮食数据,是致使它产生幻觉的一大原因。这里面就包括 数据缺陷 和 数据中捕获的事实知识的利用率低。
具体来说,数据缺陷分为错误信息和偏见(重复偏见、社会偏见),此外大模型也存在知识边界,所以存在领域知识缺陷和过时的事实知识。即便大模型吃掉了大量的数据,也会在利用时出现问题。
除此之外,大模型可能会过度依赖训练数据中的一些模式,如位置接近性、共现统计数据和相关文档计数,从而导致幻觉,比如:如果训练数据中频繁出现 "加拿大" 和 "多伦多",那么大模型可能会错误地将多伦多识别为加拿大的首都。
训练过程导致的幻觉
在模型的预训练阶段(大模型学习通用表示并获取世界知识)、对齐阶段(微调整模型使其更好地与人类偏好一致)两个阶段产生的问题也会导致幻觉的发生。
预训练阶段可能会存在:
- 架构缺陷:基于前一个 token 预测下一个 token,这种单向建模阻碍了模型捕获复杂的上下文关系的能力;自注意力模块存在缺陷,随着 token 长度增加,不同位置的注意力被稀释。
- 暴露偏差:训练策略也有缺陷,模型推理时依赖于自己生成的 token 进行后续预测,模型生成的错误 token 会在整个后续 token 中产生级联错误。
对齐阶段可能会存在:
- 能力错位:大模型内在能力与标注数据中描述的功能之间可能存在错位。当对齐数据需求超出这些预定义的能力边界时,大模型会被训练来生成超出其自身知识边界的内容,从而放大幻觉的风险。
- 信念错位:基于RLHF等的微调,使大模型的输出更符合人类偏好,但有时模型会倾向于迎合人类偏好,从而牺牲信息真实性。
推理导致的幻觉
大模型产生幻觉的第三个关键因素是推理,存在两个问题:
- 固有的抽样随机性:在生成内容时根据概率随机生成
- 不完美的解码表示:上下文关注不足(过度关注相邻文本而忽视了源上下文)和softmax瓶颈(输出概率分布的表达能力受限)
大模型幻觉的评估
目前对于大模型幻觉的评估,对于事实性幻觉和忠实性幻觉有不同的评估方法
其中事实性幻觉,有检索外部事实和不确定性估计两种方法。
检索外部事实是将模型生成 的内容与可靠的知识来源进行比较,列如同一个问题利用大语言模型生成内容,同时和外部检索到真实的信息进行对比校验。

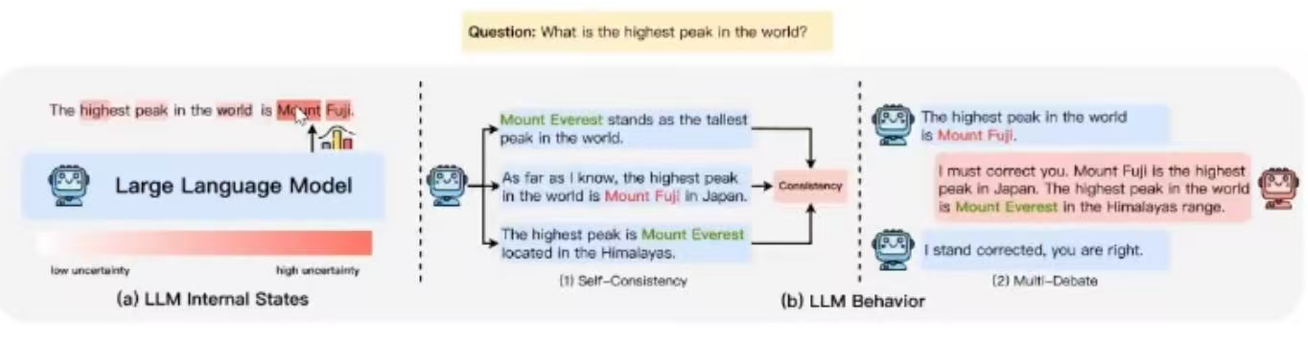
而 不确定性估计 的幻觉检测方法有两类:基于内部状态的方法和基于行为的方法。
-
基于内部状态的方法主要依赖于大模型的内部状态。例如,通过考虑关键概念的最小标记概率来确定模型的不确定性。
-
基于行为的方法主要依赖观察大模型的行为,不需要访问其内部状态。例如,通过采样多个响应并评估事实陈述的一致性来检测幻觉。
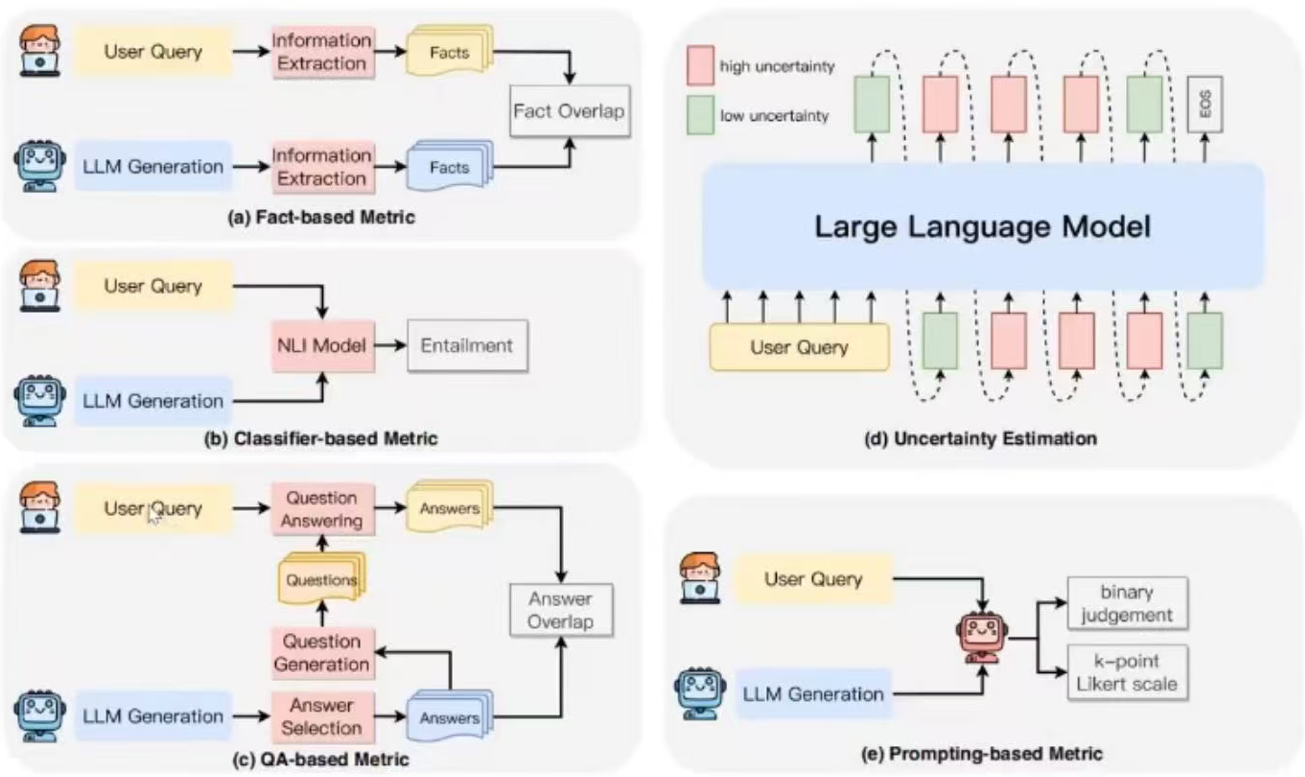
而检测 忠实性幻觉 也有 5 种主流方法:
-
基于事实的度量:测量生成内容和源内容之间事实的重叠程度来评估忠实性。
-
分类器度量:使用训练过的分类器来区分模型生成的忠实内容和幻觉内容。
-
问答度量:使用问答系统来验证源内容和生成内容之间的信息一致性。
-
不确定度估计:测量模型对其生成输出的置信度来评估忠实性。
-
提示度量:让大模型作为评估者,通过特定的提示策略来评估生成内容的忠实性。
大语言模型幻觉的缓解方案
幻觉和创造/创新/涌现其实只有一线之隔,大模型如果没有幻觉,那就永远无法产生新内容。所以,从涌现/创新的角度来说,大模型的幻觉永远不会被解决,在某些场合下只可能被缓解。
大语言模型幻觉的缓解方案也有数据、预训练、对齐、推理相关的方案,与LLM应用开发相关的主要在数据方面的处理。
缓解数据相关幻觉(重点)
减少错误信息和偏见,最直观的方法是收集高质量的事实数据,并进行数据清理以消除偏见。对于大语言模型知识边界的问题,有两种流行方法。一种是知识编辑,直接编辑模型参数弥合知识差距。另一种通过检索增强生成(RAG)利用非参数知识源。
检索增强生成具体分为三种类型:一次性检索、迭代检索和事后检索。
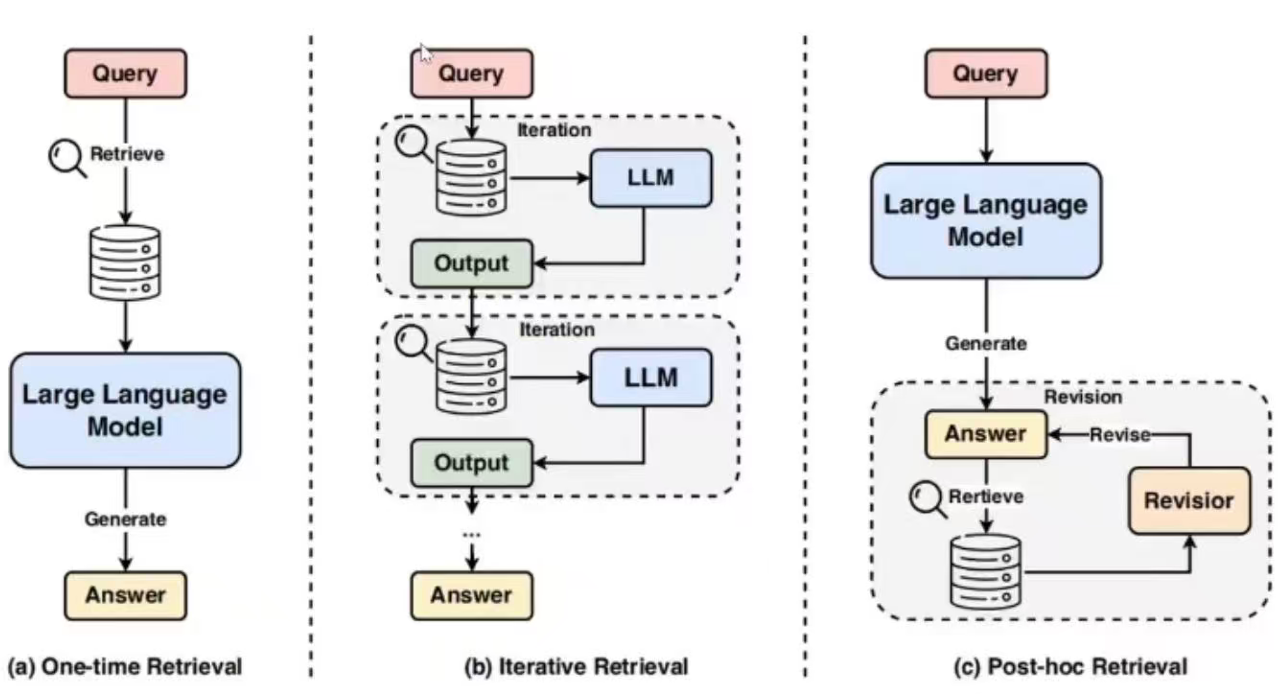
一次性检索是将从单次检索中获得的外部知识直接预置到大模型的提示中;迭代检索允许在整个生成过程中不断收集知识;事后检索是基于检索的修订来完善大模型输出。
缓解预训练相关幻觉
- 改进模型架构:使用双向自回归模型和注意力锐化技术,增强模型上下文的理解
- 优化训练目标:通过引入事实性增强的训练方法和上下文预训练,提升模型的事实关联和逻辑一致性
- 减少曝光偏差:采用新的监督信号和解码策略,减少训练与推理过程中的幻觉
缓解对齐相关幻觉
- 减少能力错位:通过改进人类偏好判断,确保模型生成内容在其知识范围内。
- 减少信念错位:聚合人类偏好和调整模型内部激活,减少模型迎合行为,避免生成与模型自身认知相驳的内容
缓解推理相关幻觉
- 增强事实性解码:动态调整解码策略,利用模型内部结构引导事实性回答。
- 增强忠实度解码:通过上下文和逻辑一致性策略,确保模型输出与用户指令或上下文保持一致。