功能概述
关键词审核是最简单、最快速的审核方式,通过维护一个关键词列表,对输入或输出进行子字符串匹配。当内容包含列表中的任何关键词时,判定为违规。
实现细节
数据结构
文件 : api/core/moderation/keywords/keywords.py
python
class KeywordsModeration(Moderation):
name: str = "keywords" # 策略标识
# 从基类继承
# self.app_id - 应用 ID
# self.tenant_id - 租户 ID
# self.config - 配置字典配置验证
方法 : validate_config()
python
@classmethod
def validate_config(cls, tenant_id: str, config: dict):
# 1. 验证基础结构
cls._validate_inputs_and_outputs_config(config, True)
# 2. 验证关键词字段
if not config.get("keywords"):
raise ValueError("keywords is required")
# 3. 验证关键词字符数
if len(config.get("keywords", [])) > 10000:
raise ValueError("keywords length must be less than 10000")
# 4. 验证关键词行数(最多100行)
keywords_row_len = config["keywords"].split("\n")
if len(keywords_row_len) > 100:
raise ValueError("the number of rows for the keywords must be less than 100")限制约束:
| 约束项 | 限制 | 说明 |
|---|---|---|
| 关键词总字符数 | ≤ 10,000 | 内存和性能考虑 |
| 关键词行数 | ≤ 100 | 防止过大的列表 |
| 输入/输出配置 | 至少启用一个 | 必须配置某种审核 |
| 预设响应 | ≤ 100 字符 | UI 限制 |
核心审核逻辑
方法 : moderation_for_inputs()
python
def moderation_for_inputs(
self,
inputs: dict,
query: str = ""
) -> ModerationInputsResult:
# 1. 初始化结果
flagged = False
preset_response = ""
# 2. 获取配置
if self.config is None:
raise ValueError("The config is not set.")
# 3. 检查输入审核是否启用
if self.config["inputs_config"]["enabled"]:
preset_response = self.config["inputs_config"]["preset_response"]
# 4. 合并输入内容(包括查询)
if query:
inputs["query__"] = query
# 5. 解析关键词列表(过滤空行)
keywords_list = [
keyword
for keyword in self.config["keywords"].split("\n")
if keyword
]
# 6. 执行匹配
flagged = self._is_violated(inputs, keywords_list)
# 7. 返回结果
return ModerationInputsResult(
flagged=flagged,
action=ModerationAction.DIRECT_OUTPUT,
preset_response=preset_response
)匹配逻辑:
- 遍历
inputs字典的每个值 - 对每个值调用
_check_keywords_in_value() - 进行不区分大小写的子字符串查找
- 任何一个值匹配即返回
True(短路求值)
关键字符串匹配
方法 : _check_keywords_in_value()
python
def _check_keywords_in_value(
self,
keywords_list: Sequence[str],
value: Any
) -> bool:
# 对每个关键词检查
return any(
keyword.lower() # 转换关键词为小写
in
str(value).lower() # 转换值为字符串并小写
for keyword in keywords_list
)匹配特性:
- ✅ 子字符串匹配("性感" 会匹配 "很性感")
- ✅ 不区分大小写("SPAM" 会匹配 "spam")
- ✅ 支持任意类型值(自动转换为字符串)
- ❌ 无法处理:变形、转义、符号隐藏等对抗手段
性能分析
时间复杂度
假设:
n= 关键词数量m= 单个内容长度k= 输入字典大小
匹配时间: O(n × m × k)
对每个输入值 (k)
对每个关键词 (n)
执行子字符串查找 (O(m))性能特点
| 操作 | 耗时 | 说明 |
|---|---|---|
| 关键词加载 | O(1) | 在 init 时完成 |
| 单次匹配 | O(n×m) | n=关键词数,m=内容长 |
| 整体审核 | O(k×n×m) | k=输入字段数 |
优化建议
缓存关键词集合:
python
# 当前实现在每次调用时重新分割
keywords_list = [k for k in self.config["keywords"].split("\n") if k]
# 优化:在 __init__ 时缓存
class KeywordsModeration(Moderation):
def __init__(self, app_id, tenant_id, config=None):
super().__init__(app_id, tenant_id, config)
if config:
self._keywords_cache = [
k for k in config.get("keywords", "").split("\n") if k
]使用 Trie 树:
python
# 对于超大关键词列表(>10,000),可使用 Trie 树
# 减少匹配时间到 O(m) 而非 O(n×m)
from pyahocorasick import Automaton
trie = Automaton()
for keyword in keywords_list:
trie.add_word(keyword.lower())
trie.make_automaton()使用场景
适用场景
-
简单过滤 - 敏感词/垃圾词过滤
keywords: 刷单 返利 外挂 -
行业合规 - 金融/医疗领域的禁用词
keywords: 保证收益 包治百病 秘方 -
品牌保护 - 竞争对手名称
keywords: ChatGPT4 DeepSeek
不适用场景
- ❌ 语义理解("这个不错" vs "这个不错" 表达不同意思)
- ❌ 多语言混合(中英混合的复杂内容)
- ❌ 对抗变形("s-p-a-m"、"sp@m" 等)
- ❌ 长文本精细化审核(仅适合简单过滤)
与其他策略的对比
| 特性 | Keywords | OpenAI | 自定义API |
|---|---|---|---|
| 响应速度 | ⚡⚡⚡ 快 | ⚡ 慢 | ⚡⚡ 中 |
| 准确度 | ⭐⭐ 低 | ⭐⭐⭐⭐⭐ 高 | ⭐⭐⭐ 中高 |
| 成本 | 💰 无 | 💰💰 高 | 💰 根据实现 |
| 定制性 | ⭐ 低 | ⭐ 低 | ⭐⭐⭐⭐ 高 |
| 多语言 | ⭐⭐ 差 | ⭐⭐⭐⭐⭐ 优 | ⭐⭐⭐ 良 |
测试用例
文件 : api/tests/unit_tests/core/moderation/test_content_moderation.py
测试类
| 测试类 | 场景 |
|---|---|
TestKeywordsModeration |
关键词审核功能测试 |
关键测试
python
def test_moderation_for_inputs_no_violation(self):
"""输入无违规内容"""
inputs = {"user_input": "This is a clean message"}
result = keywords_moderation.moderation_for_inputs(inputs, "")
assert result.flagged is False
def test_moderation_for_inputs_with_violation(self):
"""输入包含敏感词"""
inputs = {"user_input": "This message contains spam"}
result = keywords_moderation.moderation_for_inputs(inputs, "")
assert result.flagged is True
assert result.action == ModerationAction.DIRECT_OUTPUT
def test_moderation_for_outputs_with_violation(self):
"""输出包含敏感词"""
text = "This response contains spam content"
result = keywords_moderation.moderation_for_outputs(text)
assert result.flagged is True配置方式
配置数据结构
关键词审核的配置存储在应用的 sensitive_word_avoidance 字段中,采用 JSON 格式:
json
{
"enabled": true,
"type": "keywords",
"config": {
"keywords": "敏感词1\n敏感词2\n敏感词3",
"inputs_config": {
"enabled": true,
"preset_response": "您的输入包含敏感词,请重新输入"
},
"outputs_config": {
"enabled": true,
"preset_response": "抱歉,我无法回答这个问题"
}
}
}字段说明:
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
enabled |
boolean | 是 | 是否启用审核功能 |
type |
string | 是 | 审核类型,关键词审核为 "keywords" |
config.keywords |
string | 是 | 关键词列表,每行一个,最多100行,总长度≤10000字符 |
config.inputs_config |
object | 是 | 输入审核配置 |
config.inputs_config.enabled |
boolean | 是 | 是否启用输入审核 |
config.inputs_config.preset_response |
string | 否 | 输入违规时的预设响应(≤100字符) |
config.outputs_config |
object | 是 | 输出审核配置 |
config.outputs_config.enabled |
boolean | 是 | 是否启用输出审核 |
config.outputs_config.preset_response |
string | 否 | 输出违规时的预设响应(≤100字符) |
通过 UI 配置(前端)
步骤 1: 打开功能面板
- 打开应用编辑界面
- 在右侧找到"功能"(Features) 按钮/面板
- 在功能列表中找到"内容审核"卡片
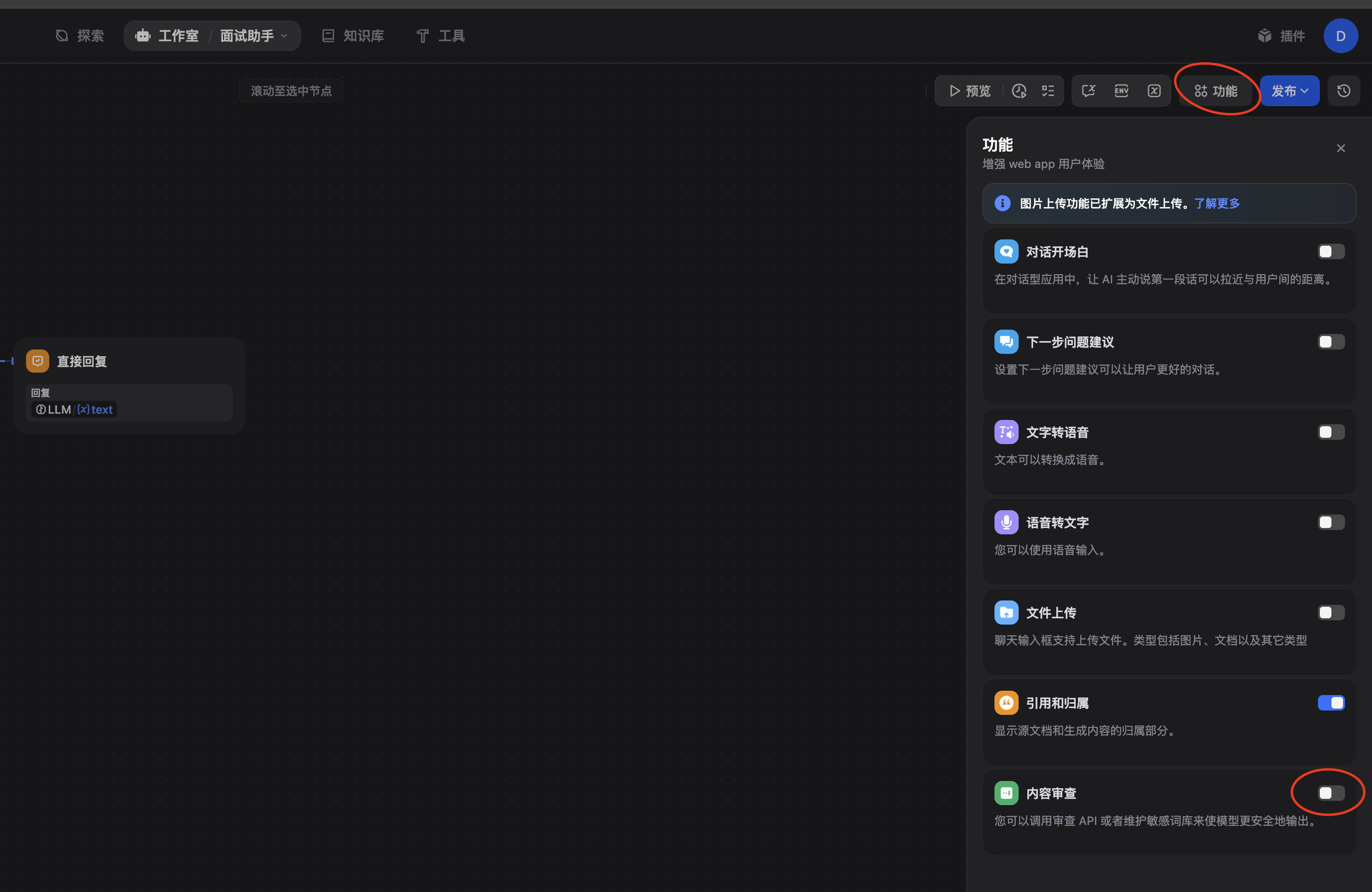
步骤 2: 选择审核类型
在功能卡片上点击启用开关或"设置"按钮,打开审核配置弹窗:
- 选择 "关键词" (Keywords) 作为审核提供者
- 系统会显示关键词配置表单
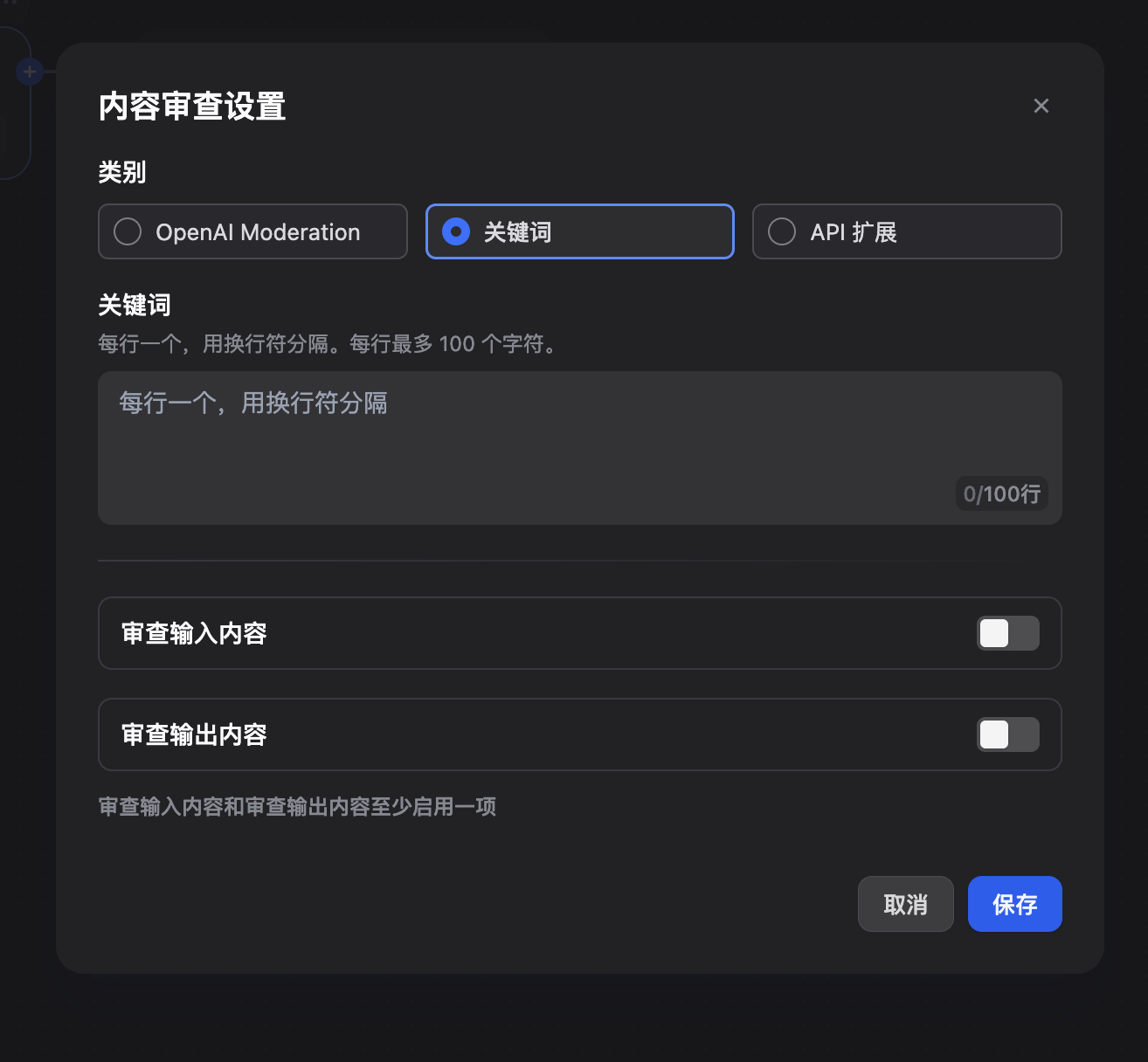
步骤 3: 配置关键词列表
在关键词文本框中输入敏感词:
敏感词1
敏感词2
敏感词3限制说明:
- ✅ 每行一个关键词(自动换行)
- ✅ 最多支持 100 行
- ✅ 总字符数不超过 10,000
- ✅ 每个关键词最长 100 字符
- ⚠️ 超出部分会被自动截断
步骤 4: 配置审核范围
可选择审核的内容类型:
输入审核 (Input Moderation):
- ☑️ 启用输入审核
- 📝 预设响应:
"您的输入包含不当内容,请重新输入" - 作用:检查用户输入是否包含关键词
输出审核 (Output Moderation):
- ☑️ 启用输出审核
- 📝 预设响应:
"抱歉,我无法回答这个问题" - 作用:检查 AI 生成内容是否包含关键词
注意: 至少需要启用输入或输出审核之一
步骤 5: 保存配置
点击"保存"按钮,系统会:
- 验证关键词列表格式
- 检查字符数和行数限制
- 确认至少启用一种审核类型
- 保存配置到数据库
通过 API 配置(后端)
1. 获取当前配置
请求示例:
bash
curl -X GET 'https://api.dify.ai/v1/apps/{app_id}/model-config' \
-H 'Authorization: Bearer {api_key}'响应示例:
json
{
"sensitive_word_avoidance": {
"enabled": true,
"type": "keywords",
"config": {
"keywords": "spam\nscam\nfake",
"inputs_config": {
"enabled": true,
"preset_response": "Invalid input"
},
"outputs_config": {
"enabled": false
}
}
}
}2. 更新配置
请求示例:
bash
curl -X POST 'https://api.dify.ai/v1/apps/{app_id}/model-config' \
-H 'Authorization: Bearer {api_key}' \
-H 'Content-Type: application/json' \
-d '{
"sensitive_word_avoidance": {
"enabled": true,
"type": "keywords",
"config": {
"keywords": "敏感词1\n敏感词2\n敏感词3",
"inputs_config": {
"enabled": true,
"preset_response": "输入包含敏感内容"
},
"outputs_config": {
"enabled": true,
"preset_response": "无法提供此内容"
}
}
}
}'3. 配置验证
后端会自动进行以下验证:
文件 : api/core/moderation/keywords/keywords.py
python
@classmethod
def validate_config(cls, tenant_id: str, config: dict):
# 验证基础结构
cls._validate_inputs_and_outputs_config(config, True)
# 验证关键词字段存在
if not config.get("keywords"):
raise ValueError("keywords is required")
# 验证关键词总长度
if len(config.get("keywords", [])) > 10000:
raise ValueError("keywords length must be less than 10000")
# 验证关键词行数
keywords_row_len = config["keywords"].split("\n")
if len(keywords_row_len) > 100:
raise ValueError("the number of rows for the keywords must be less than 100")验证错误示例:
json
// 错误:关键词为空
{
"error": "keywords is required"
}
// 错误:超过字符限制
{
"error": "keywords length must be less than 10000"
}
// 错误:超过行数限制
{
"error": "the number of rows for the keywords must be less than 100"
}
// 错误:未启用任何审核
{
"error": "At least one of inputs_config or outputs_config must be enabled"
}存储位置
配置最终存储在数据库中:
表 : app_model_configs
字段 : sensitive_word_avoidance (LongText)
格式: JSON 字符串
sql
SELECT
id,
app_id,
JSON_EXTRACT(sensitive_word_avoidance, '$.type') as moderation_type,
JSON_EXTRACT(sensitive_word_avoidance, '$.enabled') as is_enabled
FROM app_model_configs
WHERE JSON_EXTRACT(sensitive_word_avoidance, '$.type') = 'keywords';配置加载流程
1. 用户保存配置
↓
2. 前端调用 API: POST /apps/{app_id}/model-config
↓
3. AppModelConfigService.validate_configuration()
↓
4. KeywordsModeration.validate_config() # 验证配置
↓
5. 保存到 app_model_configs.sensitive_word_avoidance
↓
6. 下次请求时,ModerationFactory 加载配置
↓
7. 创建 KeywordsModeration 实例
↓
8. 执行审核逻辑配置示例
示例 1: 仅审核输入
适用场景:防止用户输入敏感问题
json
{
"enabled": true,
"type": "keywords",
"config": {
"keywords": "政治\n色情\n赌博\n暴力",
"inputs_config": {
"enabled": true,
"preset_response": "您的输入包含敏感词,请重新输入合适的问题"
},
"outputs_config": {
"enabled": false
}
}
}示例 2: 仅审核输出
适用场景:防止 AI 生成不当内容
json
{
"enabled": true,
"type": "keywords",
"config": {
"keywords": "竞品A\n竞品B\n内部机密",
"inputs_config": {
"enabled": false
},
"outputs_config": {
"enabled": true,
"preset_response": "抱歉,我无法提供相关信息"
}
}
}示例 3: 双向审核
适用场景:全方位内容安全保护
json
{
"enabled": true,
"type": "keywords",
"config": {
"keywords": "垃圾邮件\nspam\n刷单\n返利",
"inputs_config": {
"enabled": true,
"preset_response": "检测到违规内容"
},
"outputs_config": {
"enabled": true,
"preset_response": "系统无法处理此请求"
}
}
}示例 4: 多语言关键词
json
{
"enabled": true,
"type": "keywords",
"config": {
"keywords": "spam\nスパム\n垃圾邮件\nmalware\nマルウェア\n恶意软件",
"inputs_config": {
"enabled": true,
"preset_response": "Invalid content detected"
},
"outputs_config": {
"enabled": true,
"preset_response": "无法提供此信息"
}
}
}常见问题
Q: 如何处理多语言关键词?
A: 关键词列表支持任何语言的 UTF-8 文本,直接添加即可:
spam
垃圾邮件
スパムQ: 能否支持正则表达式?
A: 当前实现不支持,但可以扩展:
python
import re
keywords_patterns = [re.compile(pattern) for pattern in config["keywords"].split("\n")]
def _check_keywords_in_value(self, keywords, value):
value_str = str(value).lower()
return any(pattern.search(value_str) for pattern in keywords)Q: 如何处理繁简体变换?
A: 可使用 OpenCC 库进行繁简转换:
python
from opencc import OpenCC
cc = OpenCC('s2t') # 简体转繁体
text = cc.convert(value)Q: 关键词修改后何时生效?
A : 下次创建 ModerationFactory 时加载新配置。已有的审核实例不受影响。
扩展建议
1. 缓存优化
python
class KeywordsModeration(Moderation):
_keywords_cache: dict[str, set[str]] = {}
def __init__(self, app_id, tenant_id, config=None):
super().__init__(app_id, tenant_id, config)
self._cache_key = f"{tenant_id}:{app_id}"
if self._cache_key not in self._keywords_cache and config:
self._keywords_cache[self._cache_key] = set(
k.lower() for k in config.get("keywords", "").split("\n") if k
)2. 分布式匹配
python
# 使用 Elasticsearch 进行大规模关键词匹配
def _is_violated_distributed(self, inputs, keywords_list):
content = " ".join(str(v) for v in inputs.values())
response = es.search(
index="keywords",
query={"match": {"content": content}}
)
return len(response['hits']['hits']) > 03. 动态权重
python
# 不同关键词的风险等级
HIGH_RISK = ["非法", "诈骗"] # 立即拒绝
MEDIUM_RISK = ["广告", "推销"] # 需要审核
LOW_RISK = ["可能", "了解"] # 只记录
def _is_violated(self, inputs, keywords_map):
for risk_level, keywords in keywords_map.items():
if self._check_keywords_in_value(keywords, value):
if risk_level == "HIGH_RISK":
return True # 立即返回最后更新: 2026-01-18