2.3 安装head插件和中文分词器
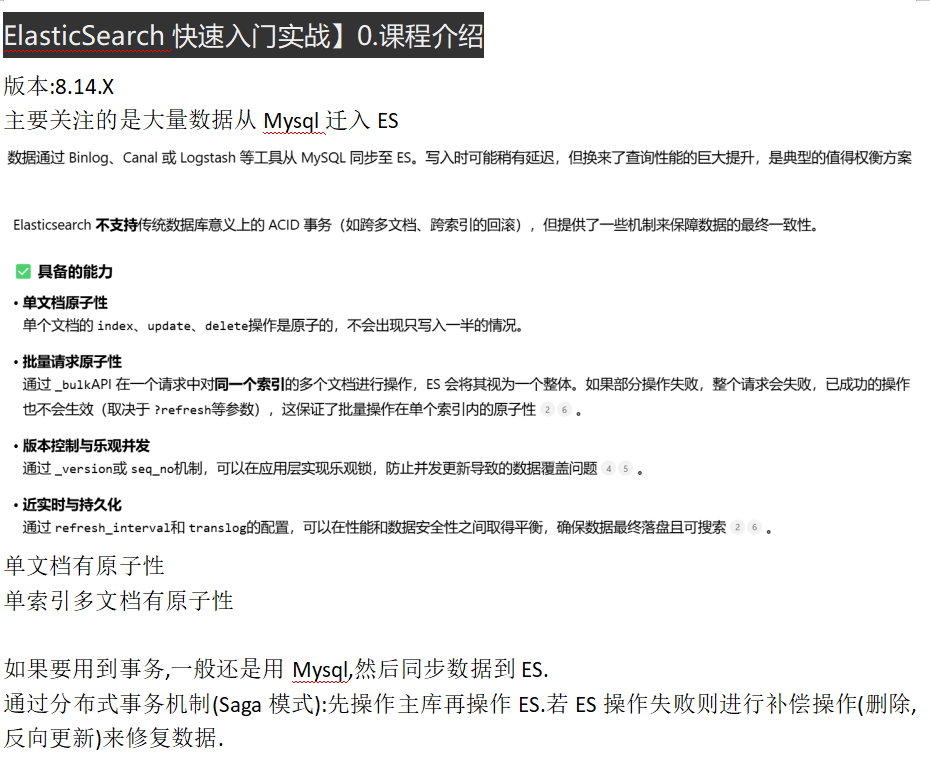
以analysis-icu为例,但是主流还是IK分词器,支持自定义词典和远程热更新.
icu提供了高级的文本分析和处理功能(正则替换).适合多语言场景,支持Unicode标准化.
IK分词器有两种模式:
ik_max_word:最细粒度拆分,穷尽所有可能的词语组合,用于索引阶段以保证高召回率;
ik_smart:最粗粒度拆分,只输出最有可能的词语,用于查询阶段以提高准确率.
还有Pinyin分词器,可以跟IK组合使用.
3.1 了解ElasticSearch核心概念
倒排索引:是把所有的分好的词列出来,然后把包含这个词的文章ID都放在一个对应的集合里.构建一个词和ID集合对应的关系.
ES8中,index相当于Mysql中的表(没有type的概念了)
mapping: 相当于Mysql表中的字段信息
document:相当于Mysql中的一条记录

3.3 索引别名详解
为什么要使用索引别名?



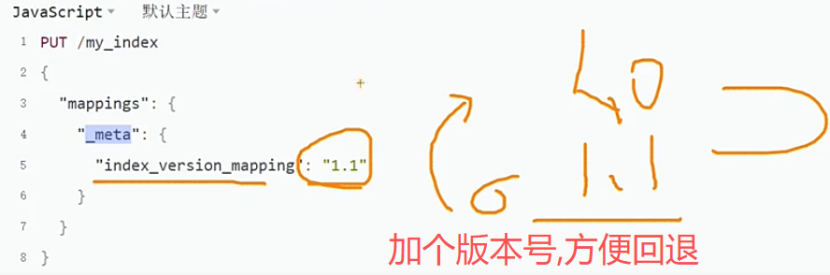
那新建索引名的时候就要习惯性的加上版本号了.然后使用别名.



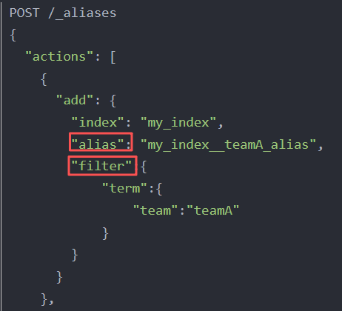 就是定义别名的时候带上一个filter.相当于一个视图
就是定义别名的时候带上一个filter.相当于一个视图



3.9 ElasticSearch文件建模最佳实践
①避免过多字段;避免开启动态新增字段.

②避免正则,通配符,前缀查询.避免模糊查询.如果要模糊查询,可以把大字段拆分为多个小字 段,动静分离把模糊条件具体化.
③避免NULL引起的聚合不准确问题.新增的时候给字段加上默认值
④为索引的Mapping加入Meta信息