【DepthPro】实战教程:单目深度估计算法详解与应用
前言
在计算机视觉领域,深度估计一直是备受关注的研究方向。传统的双目视觉方法需要多摄像头设备,而单目深度估计算法则仅使用单个摄像头就能实现场景深度感知,具有更广泛的应用前景。DepthPro作为苹果公司推出的基础模型,实现了零样本单目深度估计,能够生成高分辨率、高清晰度的深度图。本文将详细介绍DepthPro的技术原理、模型架构以及实战应用,帮助读者快速上手这一先进技术。
一、DepthPro简介
DepthPro是一个用于零样本度量单目深度估计的基础模型,能够生成具有卓越清晰度和细粒度细节的高分辨率深度图。与传统的深度估计算法不同,DepthPro无需相机内参等元数据即可输出具有绝对尺度的深度预测,并且计算速度极快,在标准GPU上0.3秒即可生成225万像素的深度图。

DepthPro的核心创新点包括:
- 高效的多尺度视觉Transformer架构
- 结合真实和合成数据集的训练协议
- 专为边界准确性设计的评估指标
- 单图像焦距估计的最先进方法
二、模型架构详解
DepthPro采用了多尺度Vision Transformer (ViT)架构,其核心思想是将图像下采样、分割成块,并使用共享的Dinov2编码器进行处理。提取的块级特征经过合并、上采样和DPT-like融合阶段,实现精确的深度估计。
2.1 模型整体结构
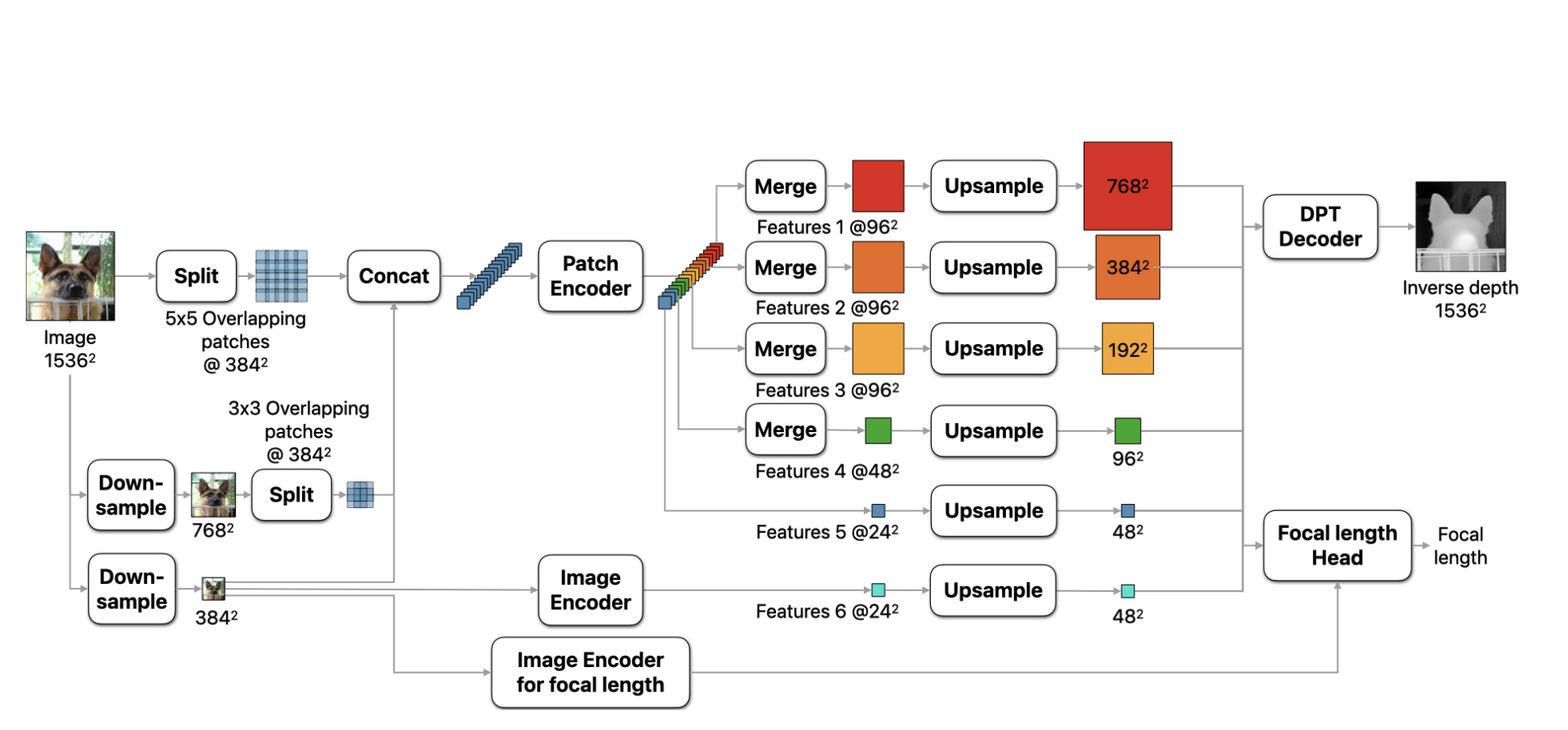
DepthPro模型主要由两部分组成:
- DepthProEncoder:用于编码输入图像
- FeatureFusionStage:融合编码器输出的特征
2.2 编码器设计
DepthProEncoder进一步使用两个编码器:
2.2.1 Patch Encoder(块编码器)
- 输入图像按照指定的
scaled_images_ratios进行多尺度缩放 - 每个缩放后的图像被分割成大小为
patch_size的小块,重叠区域由scaled_images_overlap_ratios决定 - 这些块由
patch_encoder处理
2.2.2 Image Encoder(图像编码器)
- 输入图像被缩放到
patch_size并由image_encoder处理
这两个编码器都可以通过patch_model_config和image_model_config分别配置,默认情况下都是独立的Dinov2Model。
2.3 特征融合
两个编码器(patch_encoder和image_encoder)的输出(last_hidden_state)以及patch_encoder的选定中间状态(hidden_states)通过基于DPT的FeatureFusionStage进行融合,用于深度估计。
2.4 焦距估计头
网络还配备了一个焦距估计头,小型卷积头接收来自深度估计网络的冻结特征和来自独立ViT图像编码器的特定任务特征,以预测水平视场角。
三、环境搭建与准备
3.1 系统要求
- Python 3.8或更高版本
- PyTorch 1.12或更高版本
- Transformers库
- CUDA支持(可选,用于GPU加速)
3.2 安装依赖
bash
pip install torch torchvision
pip install transformers
pip install requests pillow numpy四、实战应用
4.1 基础使用示例
下面是一个完整的DepthPro使用示例,展示如何从单张图像生成深度图:
python
import requests
from PIL import Image
import torch
from transformers import DepthProImageProcessorFast, DepthProForDepthEstimation
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载图像
url = 'https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# 初始化模型和处理器
image_processor = DepthProImageProcessorFast.from_pretrained("apple/DepthPro-hf")
model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
# 图像预处理
inputs = image_processor(images=image, return_tensors="pt").to(device)
# 模型推理
with torch.no_grad():
outputs = model(**inputs)
# 后处理
post_processed_output = image_processor.post_process_depth_estimation(
outputs, target_sizes=[(image.height, image.width)],
)
# 获取结果
field_of_view = post_processed_output[0]["field_of_view"]
focal_length = post_processed_output[0]["focal_length"]
depth = post_processed_output[0]["predicted_depth"]
# 归一化深度图
depth = (depth - depth.min()) / (depth.max() - depth.min())
depth = depth * 255.
depth = depth.detach().cpu().numpy()
depth = Image.fromarray(depth.astype("uint8"))4.2 批量处理图像
我们可以扩展上面的代码,实现批量处理图像的功能:
python
def process_images(image_paths, output_dir="output_depth"):
import os
from tqdm import tqdm
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 初始化模型和处理器
image_processor = DepthProImageProcessorFast.from_pretrained("apple/DepthPro-hf")
model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
for img_path in tqdm(image_paths, desc="Processing images"):
# 加载图像
image = Image.open(img_path)
# 预处理
inputs = image_processor(images=image, return_tensors="pt").to(device)
# 推理
with torch.no_grad():
outputs = model(**inputs)
# 后处理
post_processed_output = image_processor.post_process_depth_estimation(
outputs, target_sizes=[(image.height, image.width)]
)
# 获取深度图
depth = post_processed_output[0]["predicted_depth"]
depth = (depth - depth.min()) / (depth.max() - depth.min())
depth = depth * 255.
depth = depth.detach().cpu().numpy()
depth = Image.fromarray(depth.astype("uint8"))
# 保存结果
base_name = os.path.splitext(os.path.basename(img_path))[0]
depth.save(os.path.join(output_dir, f"{base_name}_depth.png"))
print(f"Processed and saved: {img_path}")
# 使用示例
image_paths = [
"path/to/image1.jpg",
"path/to/image2.jpg",
"path/to/image3.jpg"
]
process_images(image_paths)4.3 视频深度估计
对于视频序列,我们可以逐帧处理并保持时间一致性:
python
import cv2
import numpy as np
def process_video(video_path, output_path="output_depth.mp4"):
# 打开视频
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 初始化视频写入器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
# 初始化模型和处理器
image_processor = DepthProImageProcessorFast.from_pretrained("apple/DepthPro-hf")
model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 转换RGB
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image = Image.fromarray(frame_rgb)
# 预处理
inputs = image_processor(images=image, return_tensors="pt").to(device)
# 推理
with torch.no_grad():
outputs = model(**inputs)
# 后处理
post_processed_output = image_processor.post_process_depth_estimation(
outputs, target_sizes=[(image.height, image.width)]
)
# 获取深度图
depth = post_processed_output[0]["predicted_depth"]
depth = (depth - depth.min()) / (depth.max() - depth.min())
depth = depth * 255.
depth = depth.detach().cpu().numpy()
depth = Image.fromarray(depth.astype("uint8"))
# 转换为BGR并写入视频
depth_bgr = cv2.cvtColor(np.array(depth), cv2.COLOR_RGB2BGR)
out.write(depth_bgr)
frame_count += 1
print(f"Processed frame {frame_count}")
# 释放资源
cap.release()
out.release()
print(f"Video saved to {output_path}")
# 使用示例
process_video("input_video.mp4")五、性能优化与技巧
5.1 GPU加速
DepthPro充分利用GPU加速,在支持CUDA的系统上可以获得显著的性能提升:
python
# 检查GPU是否可用
if torch.cuda.is_available():
print(f"GPU available: {torch.cuda.get_device_name()}")
model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
print("Model moved to GPU")
else:
print("Using CPU")5.2 内存优化
对于大图像或批量处理,可以使用以下技巧减少内存使用:
python
# 使用半精度浮点数
model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device).half()
# 在推理时使用half精度
with torch.no_grad():
inputs = image_processor(images=image, return_tensors="pt").to(device).half()
outputs = model(**inputs)5.3 批处理优化
python
def batch_process_images(image_paths, batch_size=4):
from transformers import DepthProImageProcessorFast, DepthProForDepthEstimation
from tqdm import tqdm
# 初始化模型和处理器
image_processor = DepthProImageProcessorFast.from_pretrained("apple/DepthPro-hf")
model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
# 分批处理
for i in tqdm(range(0, len(image_paths), batch_size), desc="Processing batches"):
batch_paths = image_paths[i:i+batch_size]
images = [Image.open(p) for p in batch_paths]
# 预处理
inputs = image_processor(images=images, return_tensors="pt").to(device)
# 推理
with torch.no_grad():
outputs = model(**inputs)
# 后处理
post_processed_outputs = image_processor.post_process_depth_estimation(
outputs, target_sizes=[(img.height, img.width) for img in images]
)
# 处理每个结果
for j, (img, output) in enumerate(zip(images, post_processed_outputs)):
depth = output["predicted_depth"]
depth = (depth - depth.min()) / (depth.max() - depth.min())
depth = depth * 255.
depth = depth.detach().cpu().numpy()
depth = Image.fromarray(depth.astype("uint8"))
# 保存结果
base_name = os.path.splitext(os.path.basename(batch_paths[j]))[0]
depth.save(f"{base_name}_depth.png")六、训练数据与评估
6.1 训练数据
DepthPro模型在多种数据集上进行了训练,包括真实和合成数据集的结合。这种混合训练策略使得模型能够在保持高度量准确性的同时,实现精细的边界追踪。

6.2 训练超参数
6.3 评估结果
七、应用场景
DepthPro的单目深度估计能力使其在多个领域具有广泛应用:
- 增强现实(AR)和虚拟现实(VR):提供场景深度信息,实现更逼真的虚拟对象融合
- 机器人导航:帮助机器人理解环境结构,实现自主导航
- 自动驾驶:辅助车辆理解道路和障碍物的距离
- 3D重建:从单张图像生成场景的深度信息
- 图像编辑:提供深度信息用于景深效果和背景虚化
八、总结与展望
DepthPro代表了单目深度估计领域的重大突破,它不仅在精度上达到了前所未有的水平,还实现了实时处理能力。其创新的多尺度Vision Transformer架构和训练策略为深度估计任务提供了新的思路。
未来,我们可以期待DepthPro在以下方向的发展:
- 更高效的模型压缩,使其能在移动设备上实时运行
- 与其他视觉任务的深度融合,如语义分割和实例分割
- 结合多模态信息,进一步提升深度估计的准确性
- 应用于更多实时交互场景,如AR/VR和自动驾驶
通过本文的介绍,相信读者已经对DepthPro有了全面的了解,并掌握了基本的实战应用技巧。随着技术的不断进步,单目深度估计算法将在更多领域发挥重要作用,推动计算机视觉应用的普及和创新。
与展望
DepthPro代表了单目深度估计领域的重大突破,它不仅在精度上达到了前所未有的水平,还实现了实时处理能力。其创新的多尺度Vision Transformer架构和训练策略为深度估计任务提供了新的思路。
未来,我们可以期待DepthPro在以下方向的发展:
- 更高效的模型压缩,使其能在移动设备上实时运行
- 与其他视觉任务的深度融合,如语义分割和实例分割
- 结合多模态信息,进一步提升深度估计的准确性
- 应用于更多实时交互场景,如AR/VR和自动驾驶
通过本文的介绍,相信读者已经对DepthPro有了全面的了解,并掌握了基本的实战应用技巧。随着技术的不断进步,单目深度估计算法将在更多领域发挥重要作用,推动计算机视觉应用的普及和创新。