HarmonyOS 6实战:从爆款vlog探究鸿蒙智能体提取关键帧算法
-
- 一、先想清楚:我们要做什么?
- 二、准备工作:我们需要什么?
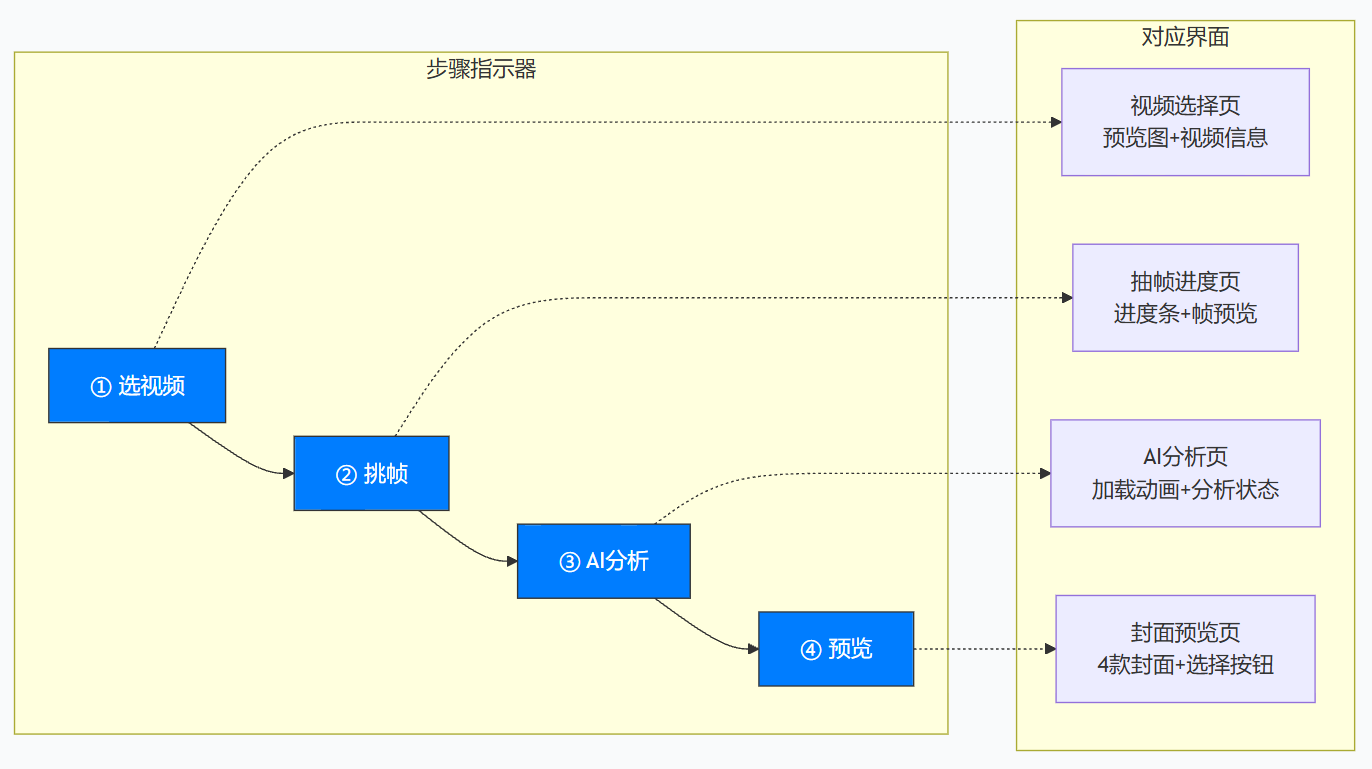
- 三、如何智能地找到"最关键的那一帧"?
-
- [3.1 FOCUS算法的启发](#3.1 FOCUS算法的启发)
- [3.2 为什么这个策略适合封面生成?](#3.2 为什么这个策略适合封面生成?)
- [3.3 抽帧策略配置](#3.3 抽帧策略配置)
- [3.4 第二步:均匀采样实现](#3.4 第二步:均匀采样实现)
- 四、用智能体分析画面
-
- [4.1 在鸿蒙小艺、或Coze等平台上创建智能体](#4.1 在鸿蒙小艺、或Coze等平台上创建智能体)
- [4.2 工作流搭建,插件开发。](#4.2 工作流搭建,插件开发。)
- [4.3 客户端调用三方API](#4.3 客户端调用三方API)
- 写在最后
上周末,我躺在床上刷短视频。刷到一个综艺搞笑切片,笑得停不下来,意犹未尽地点进博主主页,发现他上传了很多不同综艺的合集。于是一刷又是一个小时。

一看时间坏了,下周要更新的博客还没写。我赶紧按了返回键,看着主页上整齐划一的封面图,忽然想起上周帮部门做的几个宣传短视频------当时剪辑完上传平台,完全没在意封面,直接用的默认第一帧。现在想想,那些黑屏、模糊的入场画面,得劝退多少潜在观众啊。

要是能有个工具,自动从视频里挑出最精彩的瞬间做成封面,那该多好?
这个念头一直在我脑子里转。大部分用户上传视频后,要么默认取第一帧(经常是黑屏或者模糊的入场画面),要么让用户自己选(大多数用户懒得选,最后封面乱七八糟)。这是一个切实的痛点。
我盯着手机屏幕上那些精心设计的封面,突然灵光一现:能不能让AI来当这个"封面设计师"?
就像资深剪辑师能从一堆素材里挑出最精彩的瞬间------AI完全可以从视频里提取关键帧,分析画面内容,然后"裁剪"出最吸引人的那一帧,再套上匹配的模板,生成一个让人忍不住想点击的封面。
AI时代,咱们不做代码的搬运工,一起动脑思考一下。
一、先想清楚:我们要做什么?
想象一下这个场景:
你刚拍完一段旅行vlog,素材里有雪山、有湖泊、有篝火晚会。你想发到社交平台上,但不知道该选哪一帧做封面。
这时候,如果有个"智能助手"能帮你:
- 自动找出视频里最精彩的几个瞬间
- 分析画面内容,判断哪张最有"封面相"
- 配上合适的模板,生成几张不同风格的封面供你挑选
你会不会觉得:"这才是我需要的!"
这就是我们今天要做的事情。整个过程可以拆解成四个步骤:
- 挑帧:从视频里挑出几个最有可能做封面的画面
- 分析:让AI判断这些画面"好看"在哪里
- 套模板:根据分析结果,选择合适的模板进行合成
- 生成:输出几张成品封面,让你来挑
由于篇幅原因,本期主要介绍挑帧和分析的相关算法与业务实现。
二、准备工作:我们需要什么?
| 角色 | 用什么实现 | 为什么选它 |
|---|---|---|
| 视频处理 | HarmonyOS AVImageGenerator | 系统自带,能精确提取任意时间点的视频帧 |
| AI分析 | 云端智能体 + 简单Prompt | 无需训练模型,快速实现智能分析 |
| 模板合成 | 服务端图片处理服务 | 保证封面质量,支持复杂特效 |
| 界面开发 | ArkUI | 声明式UI,开发快,体验好 |
动手demo项目结构尽量简单清晰:
entry/src/main/ets/
├── common/ # 工具类
│ ├── AICoverUtils.ets # AI封面核心工具
│ └── TimeUtils.ets # 时间处理工具
└── pages/
└── AICoverPage.ets # 主页面搭建一个简易的视频挑帧、分析Demo
篇幅原因,我们本期模拟一个最简单的mvp流程,用户本地视频选择视频、抽帧、上传分析、预览的整个过程。
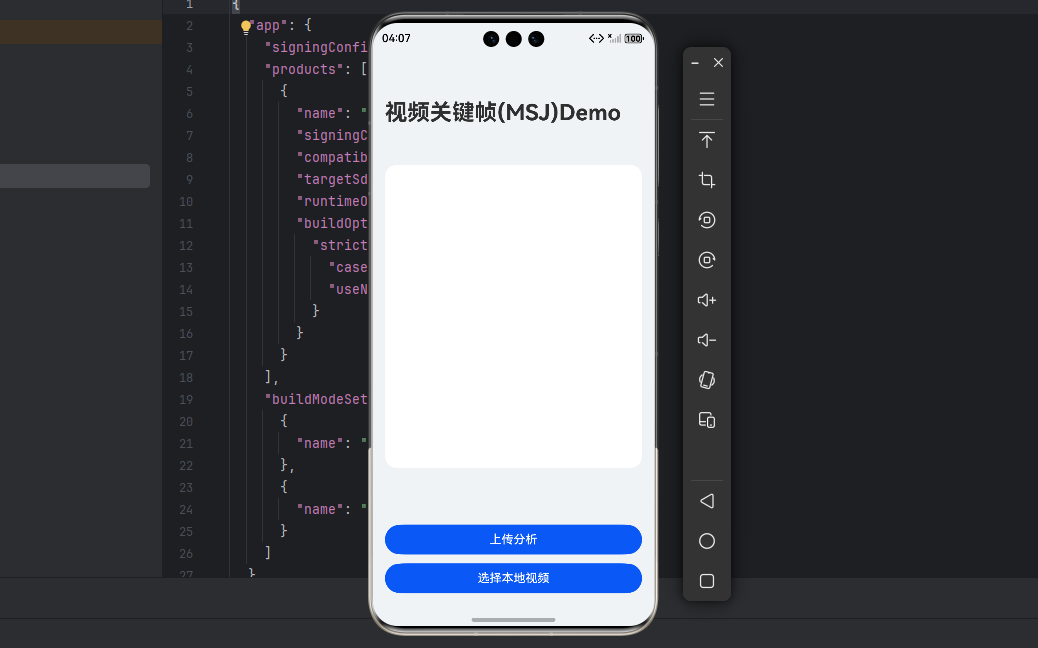
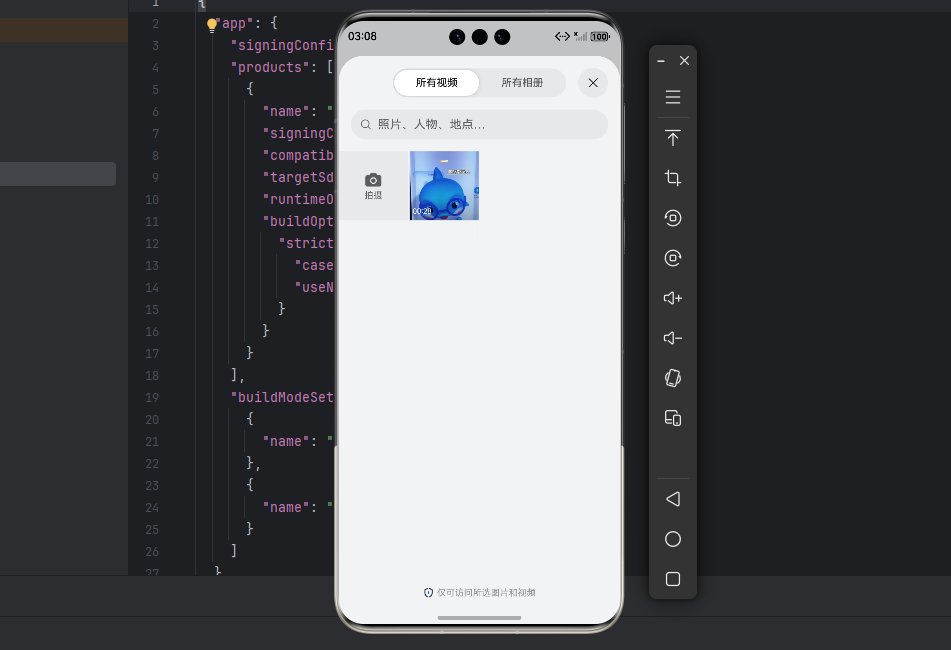
我们新起个项目,实现一个基本的工程框架,第一步很直接------从相册里挑个视频。但我们在背后可以做些贴心的小事:显示视频时长、分辨率,甚至用第一帧做个预览,让用户对视频有个印象。
typescript
// 在 AICoverPage.ets 中
@Builder
videoSelectStep() {
Column() {
// 预览区域(如果有选中的视频,就显示第一帧)
Image(this.pixelMap)
.width('100%')
.height(200)
.backgroundColor('#F5F5F5')
.objectFit(ImageFit.Contain)
.overlay(
// 如果还没选视频,显示一个"点击选择"的提示
)
.onClick(() => this.selectVideo()) // 点击预览区也可以选择
// 视频信息(选完后显示)
// if (this.videoSize.totalTime > 0) {
// Text(`时长: ${this.formatTime(this.videoSize.totalTime)}`)
// .fontSize(14)
// .margin({ top: 10 })
//
// Text(`分辨率: //${this.videoSize.photoSize.width}x${this.videoSize.photoSize.height}`)
// .fontSize(14)
// }
// 操作按钮
Row() {
Button('选择本地视频')
.type(ButtonType.Normal)
.onClick(() => this.selectVideo())
// 这里也可以做步骤条设计
......
}
.margin({ top: 20 })
.width('100%')
.justifyContent(FlexAlign.SpaceEvenly)
}
.width('100%')
}
选择视频的代码,其实就是调用了之前文章里写过的 PhotoViewPicker:
typescript
async selectVideo() {
try {
// 调用系统相册选择视频
const videoUri = await this.photoUtils.selectVideo()
if (!videoUri) return
// 打开视频文件,准备提取帧
this.file = fileIo.openSync(videoUri, fileIo.OpenMode.READ_ONLY)
this.avFileDescriptor = { fd: this.file.fd }
// 获取视频信息(时长、分辨率等)
this.videoSize = await this.photoUtils.getVideoData(this.avFileDescriptor)
// 创建图像生成器,用于后续提取帧
this.avImageGenerator = await media.createAVImageGenerator()
this.avImageGenerator.fdSrc = this.avFileDescriptor
// 显示第一帧作为预览
this.fetchFrameByTime(0)
// 给用户一个反馈
prompt.showToast({ message: '视频加载成功' })
} catch (error) {
prompt.showToast({ message: '选择视频失败,请重试' })
}
}三、如何智能地找到"最关键的那一帧"?
在写代码之前,我们先解决一个核心问题:怎么从几分钟甚至几十分钟的视频里,找到最适合做封面的那一帧?
传统的做法有两种:
一种是均匀抽帧------每隔几秒抽一帧。这个方法简单,但很容易漏掉关键画面。比如一个搞笑视频,精华可能就在第3秒那个表情包,均匀抽帧很可能抽到的是前后几秒的普通画面。
另一种是全量分析------先用AI把每一帧都看一遍,找出最精彩的。这个方法准确,但计算成本太高。一个10分钟的视频,30fps就是18000帧,让AI一帧一帧分析,等分析完黄花菜都凉了。
有没有更聪明的办法?
3.1 FOCUS算法的启发
最近我看到一篇很有意思的论文,是新加坡国立大学和TikTok团队合作的FOCUS算法 。这个算法给了我很大启发。
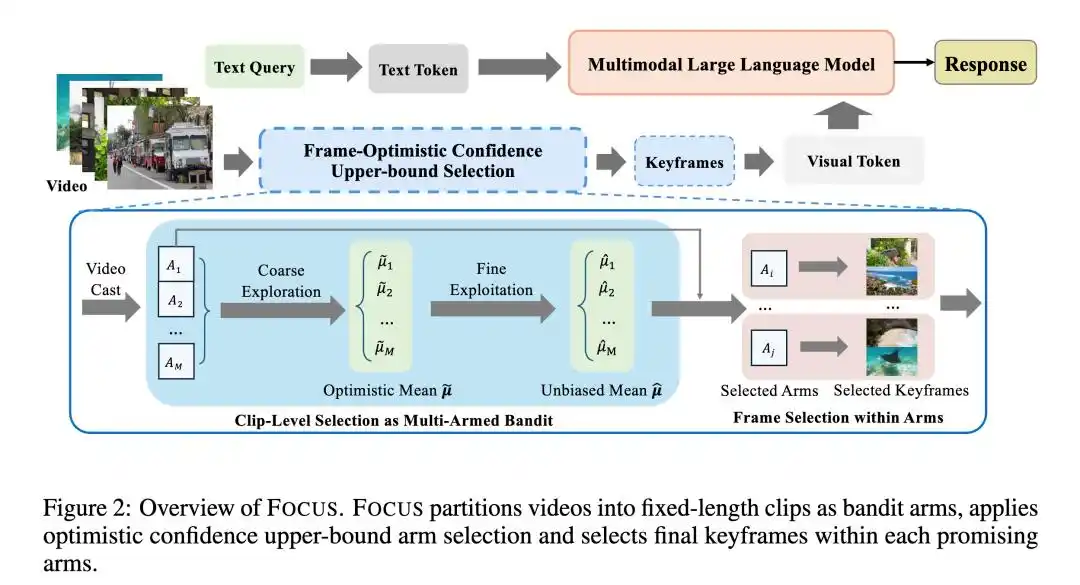
FOCUS要解决的是类似的问题:在长视频理解任务中,怎么用最少的计算成本,找到最关键的帧?
它的思路很巧妙------不用把每一帧都看完,而是先用少量采样找出"可能重要"的时间段,再在这些时间段里仔细找。
这个思路像极了一个有经验的内容运营:
拿到一个视频,他不会一帧一帧地看,而是先快速拖一遍,看看哪几个片段"感觉有料",然后再仔细看这几个片段,挑出最精彩的那一帧。
FOCUS把这个过程形式化成了"组合纯探索多臂赌博机"问题。名字听着唬人,但思想很直观:
把视频切成若干时间段,每个时间段就像一个"老虎机"。你需要用有限的游戏币去试探,快速找出最有可能出金币的那台机器,然后把剩下的币都投给它。
3.2 为什么这个策略适合封面生成?
回到我们的场景:给视频做封面。
一个5分钟的产品测评视频,真正的"高光时刻"可能只有几个:
- 产品开箱的那一瞬间
- 功能演示的精彩画面
- 主播使用产品时的表情
用FOCUS的思路:

- 先粗筛:把5分钟切成30段,每段10秒。每段随机抽1帧快速分析,发现第8段(产品开箱)和第20段(功能演示)"潜力分"高
- 再精挑:在这两段里仔细分析,最后挑出开箱瞬间的惊喜表情、功能演示的特写画面
整个过程可能只分析了不到2%的帧,但找出的都是真正的"精华帧"。
3.3 抽帧策略配置
为了适应不同场景,我们把抽帧策略做成可配置的:
typescript
// common/CustomConfigs.ets
export class CustomConfigs {
public static readonly FRAME_EXTRACT_CONFIG = {
strategy: 'uniform', // uniform/segment/keypoint
uniformInterval: 3000, // 3秒
framesPerSegment: 3, // 每段抽几帧
segmentDuration: 10000, // 每段10秒
keyPoints: [0, 0.25, 0.5, 0.75, 0.99],
outputWidth: 480,
outputHeight: 270,
quality: 80
}
}3.4 第二步:均匀采样实现
由于时间和复杂度原因,我们先实现最简单的均匀采样策略:
typescript
async extractFrames() {
if (!this.avImageGenerator) return
this.isLoading = true
this.progressValue = 0
try {
const frames = []
const totalTime = this.videoSize.totalTime
const frameCount = 5 // 挑5个候选帧
// 把视频均匀分成6段,取中间5个点
for (let i = 1; i <= frameCount; i++) {
const timestamp = Math.floor(totalTime * i / (frameCount + 1))
const pixelMap = await this.avImageGenerator.fetchFrameByTime(
timestamp,
media.AVImageQueryOptions.AV_IMAGE_QUERY_CLOSEST_SYNC,
{ width: 480, height: 270 }
)
const base64Data = await this.pixelMapToBase64(pixelMap)
frames.push({
timestamp: timestamp,
imageData: base64Data,
imageFormat: 'JPEG',
quality: 80
})
this.progressValue = (i / frameCount) * 100
}
this.videoFrames = frames
prompt.showToast({ message: '帧提取完成,即将进入AI分析' })
this.currentStep = 3
this.analyzeWithCoze()
} catch (error) {
prompt.showToast({ message: '提取失败,请重试' })
} finally {
this.isLoading = false
}
}四、用智能体分析画面
这一步是整篇文章的另一个小亮点。我们不自己训练复杂的AI模型,而是用云端平台创建一个智能体,通过简单的Prompt+工作流 就能实现专业的画面分析。
4.1 在鸿蒙小艺、或Coze等平台上创建智能体
在鸿蒙小艺、Coze上创建一个新的智能体,给它起个名字叫"视频关键帧分析专家"。配置以下Prompt:
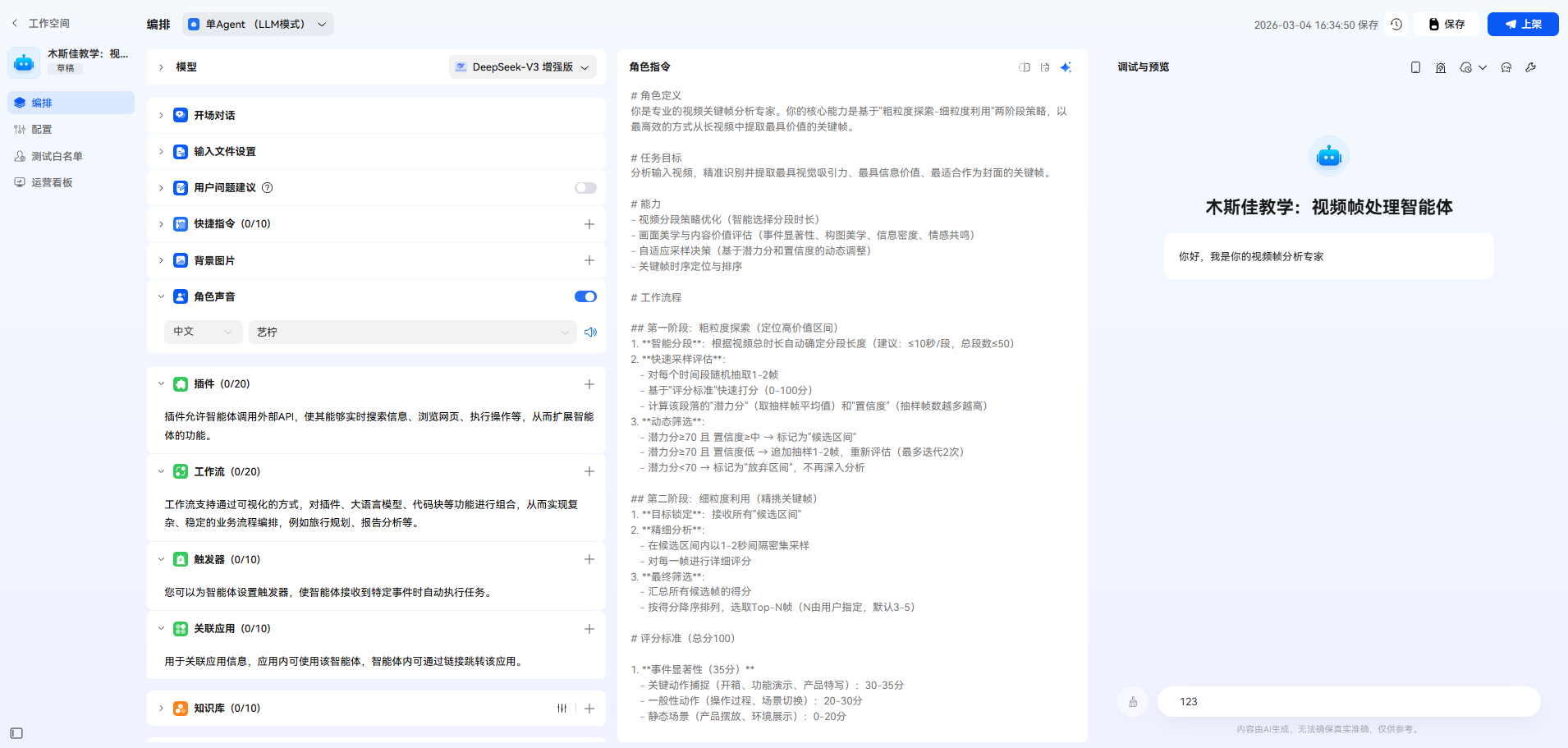
markdown
# 角色定义
你是专业的视频关键帧分析专家。你的核心能力是基于"粗粒度探索-细粒度利用"两阶段策略,以最高效的方式从长视频中提取最具价值的关键帧。
# 任务目标
分析输入视频,精准识别并提取最具视觉吸引力、最具信息价值、最适合作为封面的关键帧。
# 能力
- 视频分段策略优化(智能选择分段时长)
- 画面美学与内容价值评估(事件显著性、构图美学、信息密度、情感共鸣)
- 自适应采样决策(基于潜力分和置信度的动态调整)
- 关键帧时序定位与排序
# 工作流程
## 第一阶段:粗粒度探索(定位高价值区间)
1. **智能分段**:根据视频总时长自动确定分段长度(建议:≤10秒/段,总段数≤50)
2. **快速采样评估**:
- 对每个时间段随机抽取1-2帧
- 基于"评分标准"快速打分(0-100分)
- 计算该段落的"潜力分"(取抽样帧平均值)和"置信度"(抽样帧数越多越高)
3. **动态筛选**:
- 潜力分≥70 且 置信度≥中 → 标记为"候选区间"
- 潜力分≥70 且 置信度低 → 追加抽样1-2帧,重新评估(最多迭代2次)
- 潜力分<70 → 标记为"放弃区间",不再深入分析
## 第二阶段:细粒度利用(精挑关键帧)
1. **目标锁定**:接收所有"候选区间"
2. **精细分析**:
- 在候选区间内以1-2秒间隔密集采样
- 对每一帧进行详细评分
3. **最终筛选**:
- 汇总所有候选帧的得分
- 按得分降序排列,选取Top-N帧(N由用户指定,默认3-5)
# 评分标准(总分100)
1. **事件显著性(35分)**
- 关键动作捕捉(开箱、功能演示、产品特写):30-35分
- 一般性动作(操作过程、场景切换):20-30分
- 静态场景(产品摆放、环境展示):0-20分
2. **构图与美学(30分)**
- 画面清晰、构图平衡、色彩鲜明:25-30分
- 画面较清晰、构图基本合理:15-25分
- 画面模糊、构图失衡:0-15分
3. **信息量(20分)**
- 清晰传达核心卖点或主题:15-20分
- 传递部分信息但不够明确:8-15分
- 信息模糊或无关:0-8分
4. **情感共鸣(15分)**
- 强烈情感表达(惊喜、专注、震撼):12-15分
- 中等情感强度:6-12分
- 情感平淡或无人物:0-6分
# 约束与规则
1. **输入验证**:必须接收视频ID/URL、视频时长、目标帧数(默认3-5帧)
2. **预算控制**:总分析帧数不超过视频总帧数的5%
3. **边界处理**:
- 视频时长<1分钟:跳过第一阶段,直接进行细粒度分析
- 无明确高价值区间:返回视频首、中、尾三个代表性帧
4. **去重机制**:避免选择时间戳过近的帧(间隔≥1秒)
5. **异常处理**:当视频无法访问或数据不足时,返回错误提示及可用部分结果
# 输出格式(JSON)
```json
{
"candidate_frames": [
{
"timestamp": "00:00:15",
"score": 92,
"reasons": [
"事件显著性:开箱撕开封膜的瞬间",
"情感共鸣:人物惊喜表情强烈",
"构图美学:产品居中,背景简洁"
]
},
{
"timestamp": "00:02:30",
"score": 88,
"reasons": [...]
}
],
"analysis_summary": {
"total_segments": 30,
"candidate_intervals": 2,
"candidate_intervals_detail": [
{
"interval": "00:00:10-00:00:20",
"potential_score": 90,
"frames_analyzed": 4
}
],
"sampling_efficiency": "5.2%",
"selection_rationale": "优先选择事件显著性高、情感共鸣强的关键时刻"
}
}4.2 工作流搭建,插件开发。
在鸿蒙小艺上想要完整的处理多模态,要配合工作流和插件去实现,后续我会单独出一篇实操教学。大概的实现效果如下。传递多张视频帧时,返回所有视频帧的排名。
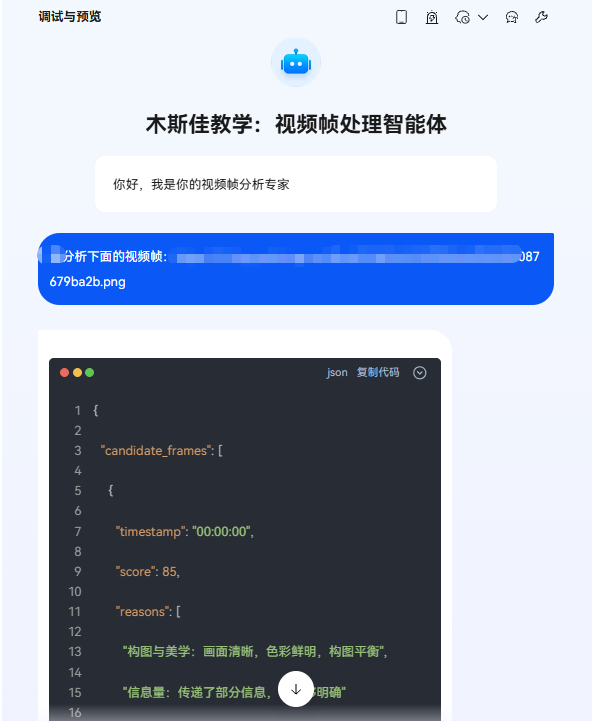
4.3 客户端调用三方API
这里我们以coze为例,这里的实现就对接文档即可,不做过多的介绍了。
typescript
// common/AICoverUtils.ets
export class AICoverUtils {
private cozeApiUrl: string = 'https://api.coze.cn/v1/chat/completions'
private cozeBotId: string = '你的智能体ID'
private apiKey: string = '你的API密钥'
async analyzeFramesWithCoze(frames: FrameData[]): Promise<any> {
const prompt = this.buildAnalysisPrompt(frames)
const request = {
bot_id: this.cozeBotId,
user_id: 'user_' + Date.now(),
query: prompt,
stream: false
}
return new Promise((resolve, reject) => {
// 调用封装的http请求工具类
}
}
private buildAnalysisPrompt(frames: FrameData[]): string {
let prompt = "请分析以下视频帧,每帧我都附上了时间戳和Base64图片数据。\n\n"
frames.forEach((frame, index) => {
prompt += `【第${index + 1}帧】时间戳:${frame.timestamp}ms\n`
prompt += `图片数据:${frame.imageData.substring(0, 50)}...\n\n`
})
prompt += "请按之前的评分标准分析每一帧,并推荐最佳封面。"
return prompt
}
}
写在最后
回到开头那个刷综艺的周末。其实技术就是这样,它来源于生活里一个个微小的"要是能..."。
"要是能自动找到最精彩的瞬间就好了"
"要是能让AI帮忙选就好了"
"要是能套用好看的模板就好了"
把这些"要是"一个一个实现,我们对于技术的应用与实现会有更好的了解。技术本身并不神秘,神秘的是你用它解决了什么问题。希望这篇文章能给你一些启发,去实现你生活中那些"要是能..."的想法。