
前言
大家好,这里是程序员阿亮
这一期给大家讲一下Redis的底层原理与其衍生问题
在 Redis 的众多数据结构中,ZSet(有序集合,Sorted Set)是常用的数据结构。从游戏排行榜、延时队列,到热搜榜单、时间线排序,ZSet 都能游刃有余地解决。
但是,Redis 为了在"内存占用"和"查询性能"之间找到完美的平衡,在 ZSet 的底层实现上可谓煞费苦心。随着 Redis 版本的迭代,ZSet 的底层结构也经历了一场从 Ziplist(压缩列表) 到 Listpack(紧凑列表) 的底层变革。
今天,我们就来扒一扒 ZSet 的底层原理,并深入探讨 Ziplist 臭名昭著的"级联更新"问题,以及 Listpack 是如何完美救场的。
一、ZSet的宏观设计
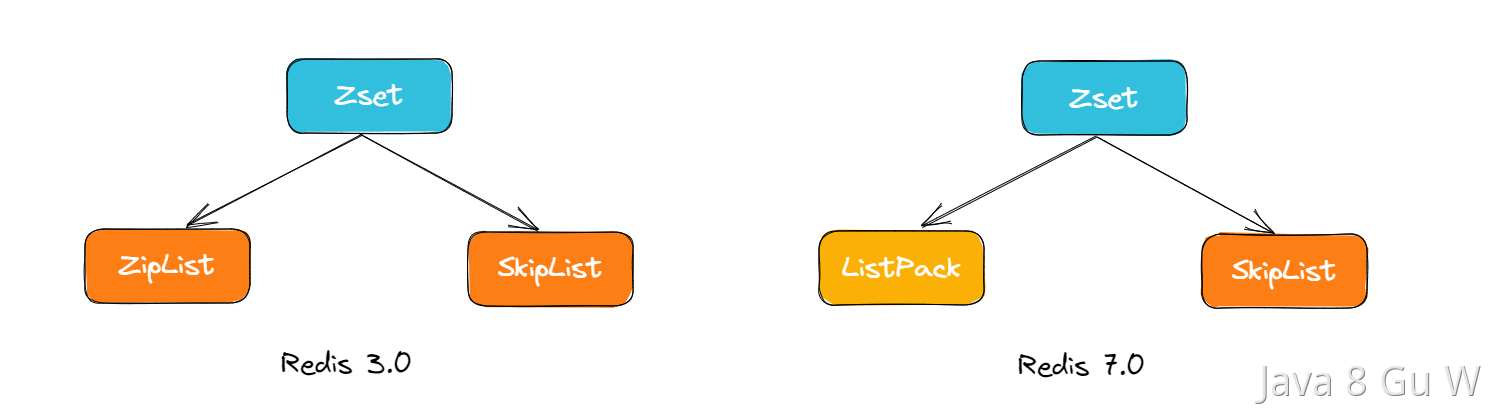
ZSet 需要同时支持高效的按分值范围查找 (如获取 Top 10)以及根据元素查分值(如获取某个用户的排名)。为了兼顾效率与内存,Redis 对 ZSet 采用了"动态切换"的双重实现策略:
-
元素较少且体积较小时 :使用一块连续的内存结构(早期是 Ziplist ,Redis 7.0 之后是 Listpack)。
-
元素较多或体积较大时 :切换为 跳表(Skiplist) + 字典(Hash Table/Dict) 的组合。
为什么大数据量下要用 跳表 + 字典?
-
跳表(Skiplist):通过多层索引实现快速的范围查询和插入,时间复杂度为 O(log N)。
-
字典(Dict) :存储 元素 -> 分值 的映射关系,使得查询特定元素分值的复杂度降为 O(1)。
两者通过指针共享同一份元素数据,既保证了查询和排序的高效,又避免了数据冗余。
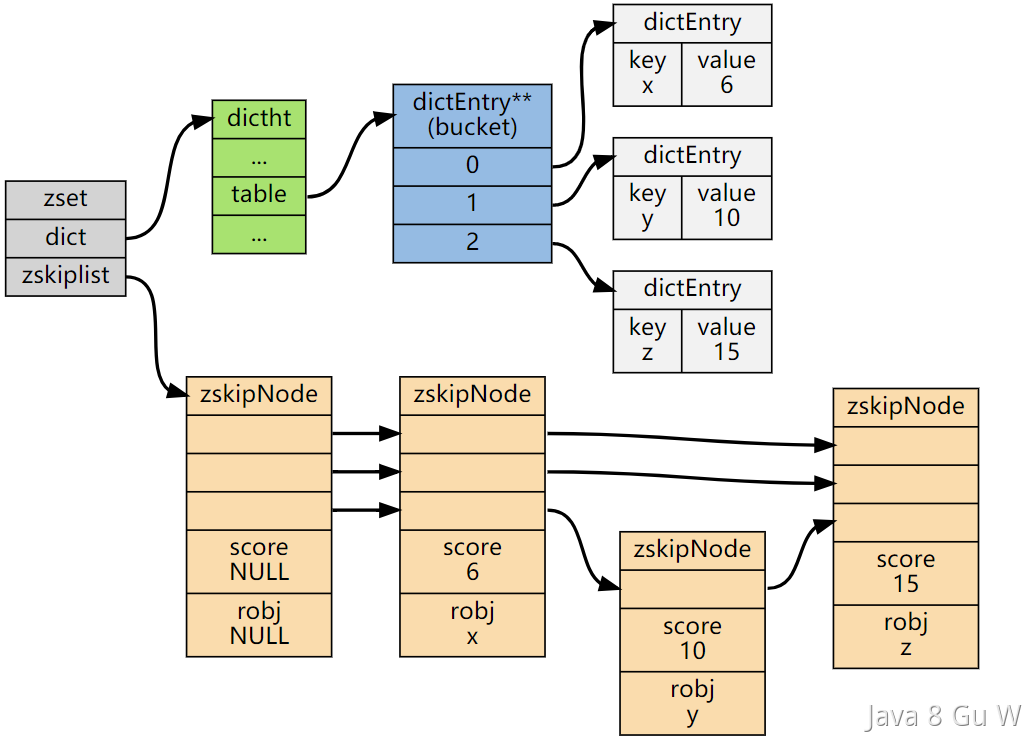
跳表是一种在链表的基础上建立多层索引的数据结构,通过多层数据结构可以大大提高增删改查的时间复杂度(logn)

在元素少的时候使用ziplist(listpack)这种连续的存储结构,内存是连续的,没有索引,存储的内存占用小但是相对于skiplist的增删改的时间复杂度就高一些,但是n与logn在数据量小的情况下的差距是不大的,所以是可以接受的
二、Ziplist及其级联问题
前文说到ziplist在元素少的情况下会被使用到,那么它的级联问题又是什么呢?
当 ZSet 元素不多时,为了节省指针带来的内存开销,Redis 将元素和分值连续交替存放在一块连续的内存中(即 member1, score1, member2, score2...)。在 Redis 7.0 之前,这个重担落在 Ziplist(压缩列表) 的肩上。
1. Ziplist 的结构
Ziplist 是一块连续的内存,它的每个节点(Entry)并没有固定的长度,而是按需分配。一个 Ziplist 节点的结构如下:
code Text
+-----------------------+----------+---------+
| previous_entry_length | encoding | content |
+-----------------------+----------+---------+-
previous_entry_length (prevlen) :(重点!) 记录前一个节点的长度,用于支持从后向前的反向遍历。
-
encoding:当前节点数据的编码类型和长度。
-
content:实际存储的数据(字符串或整数)。
2. 致命缺陷:级联更新 (Cascade Update)
prevlen 字段的设计非常精妙,为了省内存,它的长度是动态的:
-
如果前一个节点长度 < 254 字节 ,prevlen 只需要 1 字节 就能存下。
-
如果前一个节点长度 >= 254 字节 ,prevlen 就需要扩展为 5 字节(第1个字节固定为0xFE作为标识,后4个字节存实际长度)。
灾难是如何发生的?
假设我们有一个 Ziplist,里面连续存在多个大小介于 250 ~ 253 字节之间的节点:e1, e2, e3, e4...
-
因为所有节点都小于 254 字节,所以它们的 prevlen 都是 1 字节。
-
此时,我们在 e1 前面插入了一个新节点 e_new,它的长度达到了 255 字节。
-
e1 的 prevlen 为了记录 e_new 的长度,必须从 1 字节扩展到 5 字节。
-
e1 原本是 253 字节,加上新增的 4 字节,变成了 257 字节。
-
这导致 e2 的 prevlen 也必须从 1 字节扩展到 5 字节,e2 的总长度随之增加。
-
依此类推,e3, e4... 全部像多米诺骨牌一样发生内存扩展。
这种引起后续节点连环引发内存重分配的现象 ,被称为 级联更新(Cascade Update) 。
虽然在实际业务中,连续出现大小刚好在 250-253 字节临界值的节点概率极低,但作为底层数据结构,这种 最坏情况下 O(N²) 的时间复杂度 就像是一颗定时炸弹,会导致 Redis 发生严重的线程阻塞。
三、Redis7.0的Listpack如何解决级联问题?
为了彻底拔除"级联更新"这颗毒瘤,Redis 大佬 Antirez 在 Redis 5.0 引入了 Streams 数据类型时,顺手设计了一个全新的数据结构:Listpack(紧凑列表) 。
并在 Redis 7.0 版本中,大刀阔斧地把 ZSet 和 Hash 底层的 Ziplist 全部替换成了 Listpack。
1. Listpack 的结构设计
Listpack 的整体布局和 Ziplist 类似,依然是一块连续的内存,但它的 节点(Entry)结构 发生了决定性的变化:
+----------+---------+--------------+
| encoding | content | element_tot_len |
+----------+---------+--------------+-
encoding:当前节点的编码方式。
-
content:实际的数据。
-
element_tot_len :记录当前节点(encoding + content)的总长度。
2. 为什么 Listpack 能根除级联更新?
问题的关键就在于 element_tot_len 字段!
Ziplist 发生级联更新的根本原因是:当前节点存储了"前驱节点"的长度,导致前驱节点的变化会直接影响当前节点的内存布局。
而 Listpack 巧妙地进行了解耦:
-
element_tot_len 记录的是 当前节点本身 的长度。
-
它被放置在当前节点的 末尾。
如何实现反向遍历?
当需要从后向前遍历时,指针只需向前移动,读取上一个节点的 element_tot_len 字段(该字段经过特殊编码,可以从后向前解码得到长度值),就能知道上一个节点的总长度,从而跳到上一个节点的头部。
彻底终结级联更新 :
在 Listpack 中,如果我们插入了一个巨大的新节点,或者修改了某个节点的大小,只有它自身的 element_tot_len 会发生变化。它后方的节点完全不需要修改任何字段。这就切断了多米诺骨牌的连锁反应,无论怎么增删改,都不会引发后续节点的内存重分配。
总结
Redis ZSet 的设计是一场关于空间与时间的极限拉扯:
-
宏观层面(跳表 + 字典 vs 紧凑列表):根据数据量大小动态切换结构,是对 O(1) 时间复杂度和连续内存极致利用的权衡。
-
微观层面(Ziplist -> Listpack):Listpack 通过把**"记录别人"变成"记录自己"**,仅仅是挪动了长度字段的位置并改变了语义,就以极其优雅的方式化解了 Ziplist 的 O(N²) 级联更新危机。
对于我们日常做系统设计而言,Redis ZSet 的演进也是绝佳的教材:
不要让一个模块的状态过度依赖于相邻模块的状态(解耦),因为一旦发生变更,紧耦合的设计往往意味着不可控的雪崩。
