目录
1、实现原理
PCA 的核心机制是将高维数据映射到低维子空间,该子空间由一组相互正交的主成分(新特征向量)构建,这些主成分通过原始高维特征的线性变换生成。其降维过程可概括为:先在数据分布中选取离散度最大的方向作为首个基向量;接着在与该基向量正交的子空间内,选择离散度次大的方向作为第二个基向量;随后在与前两个基向量均正交的空间中,继续选取离散度最大的方向作为第三个基向量,依此循环确定 n 个正交基向量。经此变换,数据的核心信息(以方差衡量)集中于前 k 个基向量,剩余 n-k 个基向量的信息量极少。基于这一特性,PCA 通过保留前 k 个基向量、舍弃其余向量完成降维,在剔除无关特征维度的同时留存关键信息,为后续分析奠定基础。三维 PCA 的原理如图1所示。
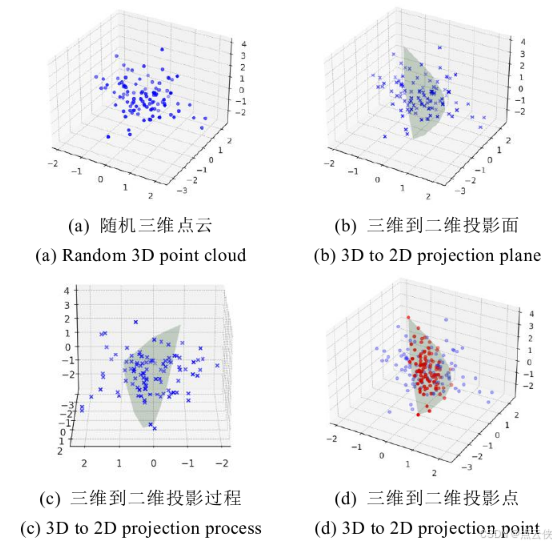
在PCA算法确定最优投影方向的过程中,需依次完成以下五个关键操作环节:
第一步为原始数据的中心化预处理。针对输入的原始数据矩阵,通过减去其均值向量的方式,使处理后的数据满足零均值特性,这一操作可消除数据整体偏移对后续相关性分析的干扰,为后续步骤奠定统一的数据基准。
第二步是协方差矩阵的构建与计算。基于中心化后的数据集,通过计算协方差矩阵量化不同特征维度之间的线性相关程度,该矩阵的元素值直接反映了任意两个特征维度数据的协同变化趋势,是后续特征分解的核心分析对象。
第三步执行协方差矩阵的特征值分解。借助线性代数工具对协方差矩阵进行分解,从中提取出对应的特征值与特征向量:其中特征值表征了对应特征向量方向上数据的离散程度,特征向量则代表了数据分布的潜在主方向。
第四步完成投影矩阵的筛选与构建。将分解得到的特征值按从大到小的顺序排序,根据预设的降维目标(即低维空间维度k),选取前k个最大特征值所对应的特征向量,由这些特征向量共同构成用于数据映射的投影矩阵。
第五步实现高维数据向低维空间的映射。将原始高维数据矩阵与构建好的投影矩阵进行矩阵运算,完成数据从高维特征空间到k维子空间的转换,最终实现数据维度的有效降低,同时最大限度保留原始数据的核心信息。
在PCA算法中,针对协方差矩阵求解特征值与特征向量的过程,常用两类数值计算方案:一类是直接对构建完成的协方差矩阵执行特征值分解操作,另一类则是借助奇异值分解(SVD)技术间接获取所需特征参数。这两种数值方法的差异,进一步衍生出PCA的两种核心实现路径:其一为基于谱分解原理的传统PCA方法,其二为依托SVD技术优化的改进型PCA方法。结合本研究数据特性与分析需求,本节选用基于谱分解的传统PCA方案开展数据降维工作。该方案的核心操作逻辑为:先通过前述步骤构建协方差矩阵,再对该矩阵进行特征值分解,从中提取出能够表征数据主成分的特征向量,最终依托这些主成分特征向量完成高维数据向低维空间的映射,实现数据维度的精简。
样本均值的计算方法如公式(1)所示:
x ˉ = 1 n ∑ i = 1 n x i ( i = 1 , 2 , 3 , ... . . ) (1) \bar{x}=\frac{1}{n} \sum_{i=1}^{n} x_{i}(i=1,2,3, \ldots . .) \tag{1} xˉ=n1i=1∑nxi(i=1,2,3,.....)(1)
样本方差的计算方法如公式(2)所示:
S 2 = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 ( i = 1 , 2 , 3 , ... . . ) (2) S^{2}=\frac{1}{n-1} \sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2}(i=1,2,3, \ldots . .) \tag{2} S2=n−11i=1∑n(xi−xˉ)2(i=1,2,3,.....)(2)
样本X和样本Y的协方差计算方法如公式(3)所示:
Cov ( X , Y ) = E ( X − E ( X ) ) ( Y − E ( Y ) ) = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ( i = 1 , 2 , 3...... ) (3) \operatorname{Cov}(X, Y)=E\left(X-E(X))(Y-E(Y))\\right=\frac{1}{n-1}\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)(i=1,2,3......) \tag{3} Cov(X,Y)=E(X−E(X))(Y−E(Y))=n−11i=1∑n(xi−xˉ)(yi−yˉ)(i=1,2,3......)(3)
方差作为描述单一特征离散程度的量化指标,其计算逻辑是通过比对同一特征在不同样本中的取值差异来实现的。与之不同的是,协方差主要用于衡量至少两个特征间的线性关联程度,更适用于二维及更高维度的特征关系分析。需要特别说明的是,方差可视为协方差的一种特殊情形,当协方差所分析的两个特征完全相同时,其计算结果即等同于该特征的方差。在具体计算过程中,方差与协方差的分母项通常取样本数量减一(n-1),这一设定的目的是确保计算结果能够构成无偏估计,提升统计分析的可靠性。
从协方差的数值结果可直接判断两个特征(以特征X和特征Y为例)的线性关联方向:若协方差计算结果为正值,表明特征X与特征Y呈现正相关关系,即一个特征的数值增大时,另一个特征的数值也随之增大;若协方差结果为负值,则特征X与特征Y呈负相关关系,即一个特征数值增大时,另一个特征数值相应减小;若协方差结果为零,则说明特征X与特征Y之间不存在线性关联,二者呈现相互独立的关系。需要进一步明确的是,当协方差分析的对象为同一特征(即Cov(X,X))时,其计算结果恰好等于该特征(特征X)的方差,这一关系再次印证了方差是协方差在单特征场景下的特殊形式。对于n维数据而言,各特征之间的协方差关系需通过协方差矩阵进行统一表征,且该矩阵具有对称矩阵的数学特性。矩阵中的第i行第j列的元素值与第j行第i列的元素值完全相等。以三维数据(x,y,z)为例,其对应的协方差矩阵具体形式如公式(4)所示:
C o v ( X , Y , Z ) = C o v ( x , x ) C o v ( x , y ) C o v ( x , z ) C o v ( y , x ) C o v ( y , y ) C o v ( y , z ) C o v ( z , x ) C o v ( z , y ) C o v ( z , z ) (4) \mathrm{Cov}(X, Y, Z)=\left\\begin{array}{ccc}\\mathrm{Cov}(x, x)\&\\mathrm{Cov}(x, y)\&\\mathrm{Cov}(x, z)\\\\\\mathrm{Cov}(y, x)\&\\mathrm{Cov}(y, y)\&\\mathrm{Cov}(y, z)\\\\\\mathrm{Cov}(z, x)\&\\mathrm{Cov}(z, y)\&\\mathrm{Cov}(z, z)\\end{array}\\right \tag{4} Cov(X,Y,Z)= Cov(x,x)Cov(y,x)Cov(z,x)Cov(x,y)Cov(y,y)Cov(z,y)Cov(x,z)Cov(y,z)Cov(z,z) (4)
在完成数据预处理与特征维度分析后,需通过散度矩阵量化数据的分布特性,计算数学表达式如公式(5)和公式(6)所示。这两个公式从数据矩阵运算逻辑出发,明确散度矩阵各元素的推导方式,为后续协方差矩阵构建及特征值分解提供基础计算依据。
S = ∑ k = 1 n ( x k − m ) ( x k − m ) T ( k = 1 , 2 , 3 ... ... ) (5) S=\sum_{k=1}^{n}\left(x_{k}-m\right)\left(x_{k}-m\right)^{T}(k=1,2,3 \ldots \ldots) \tag{5} S=k=1∑n(xk−m)(xk−m)T(k=1,2,3......)(5)
m = 1 n ∑ k = 1 n x k ( k = 1 , 2 , 3 ... ... ) (6) m=\frac{1}{n} \sum_{k=1}^{n} x_{k}(k=1,2,3 \ldots \ldots) \tag{6} m=n1k=1∑nxk(k=1,2,3......)(6)
式中,m是平均向量。
在数据统计分析领域,散度矩阵与协方差矩阵存在紧密的数学关联,二者的定义与运算逻辑具有明确的推导关系。针对给定的数据矩阵X,散度矩阵的数学定义可表示为 X X T XX^{T} XXT(即矩阵X与其转置矩阵 X T X^{T} XT的乘积);而协方差矩阵的计算,则是在散度矩阵的基础上,除以数据总数量减一(n-1)得到的结果。从线性代数特性来看,这一运算关系决定了散度矩阵与协方差矩阵具有完全相同的特征向量和特征值。因为除以(n-1)这一常数仅会改变矩阵元素的数值大小,不会改变矩阵的特征结构(特征向量的方向与特征值的相对比例)。需要特别指出的是,散度矩阵在奇异值分解(SVD)过程中承担着关键角色,是实现数据奇异值分解的核心计算对象之一。正是基于散度矩阵这一桥梁作用,主成分分析(PCA)与奇异值分解(SVD)之间建立了深度关联,二者在数据降维的数学原理与实际应用中存在显著的内在一致性。
针对任意给定矩阵A,若其存在对应的特征向量组v,可先对该特征向量组执行正交化处理以消除向量间的线性相关性,再通过单位化操作将各向量转换为模长为1的标准向量。在完成上述向量预处理后,特征值分解的核心任务便是将矩阵A分解为特定的数学形式,其具体表达式如公式(7)所示:
A = Q Σ Q − 1 (7) A=Q\Sigma Q^{-1} \tag{7} A=QΣQ−1(7)
式中,Q代表由矩阵A的特征向量组成的矩阵,∑表示一个对角阵,对角线上的元素就是特征值。
经PCA降维操作处理后,原始高维数据中的核心特征被高效压缩至低维空间内,且在压缩过程中最大限度保留了数据固有的空间结构信息。
2、参考文献
基于深度学习与三维重建的古建筑木结构裂缝智能检测研究_马健