一、引言
在德国展会网站采集中,K展(K-online)作为全球最大的塑料橡胶展览会,其网站采用了严格的API访问控制和复杂的数据结构。本文以K展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。
二、技术难点全景图
四大技术难关
请求频率限制
429状态码处理
Retry-After机制
动态延迟控制
三次重试策略
嵌套数据结构
多层JSON嵌套
安全取值函数
空值处理
类型判断
多目录聚合
a-z字母目录
other目录处理
分页API设计
全量数据合并
地址字段重构
数组地址清洗
空值过滤
多字段拼接
格式化输出
三、核心难题攻克详解
3.1 难关一:请求频率限制与429状态码处理
问题描述 :
K展API实施了严格的请求频率限制,当请求过于频繁时返回429状态码,并在响应头中包含Retry-After字段。需要实现智能等待和自动重试机制。
http
HTTP/1.1 429 Too Many Requests
Retry-After: 30
Content-Type: application/json
{"error": "Rate limit exceeded"}攻克方案:
重试机制
429处理
请求控制
否
是
200
429
<3次
=3次
初始化
last_request_time=0
检查时间间隔
min_delay=3s
间隔足够?
计算等待时间
随机延迟
3-6秒
发送请求
响应状态
成功返回
获取Retry-After
等待指定时间+5秒
重试
重试次数
返回None
更新
last_request_time
核心代码实现:
python
def safe_request(self, url):
"""攻克请求频率限制难题"""
# 第一步:动态延迟控制
elapsed = time.time() - self.last_request_time
if elapsed < self.min_delay:
wait = random.uniform(self.min_delay, self.max_delay) - elapsed
print(f"⏳ 等待 {wait:.1f}秒...")
time.sleep(max(wait, 0))
# 第二步:三次重试机制
for attempt in range(3):
try:
response = self.session.get(url, timeout=20)
self.last_request_time = time.time()
# 第三步:429状态码特殊处理
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 30))
print(f"⚠️ 触发速率限制,等待 {retry_after}秒")
time.sleep(retry_after + 5) # 额外增加5秒缓冲
continue
response.raise_for_status()
return response.json()
except Exception as e:
print(f"❌ 请求失败 (尝试 {attempt + 1}/3): {str(e)}")
if attempt == 2:
return None
time.sleep(self.retry_delay) # 重试延迟15秒
return None3.2 难关二:嵌套数据结构安全取值
问题描述 :
API返回的JSON数据结构极其复杂,包含多层嵌套。直接使用data['key1']['key2']的方式极易引发KeyError或TypeError。
json
{
"profileAddress": {
"address": ["街道", "门牌号"],
"zip": "12345",
"city": "杜塞尔多夫"
},
"phone": {
"phone": "+49 123 456789"
},
"links": [
{"link": "https://example.com"}
]
}攻克方案 :
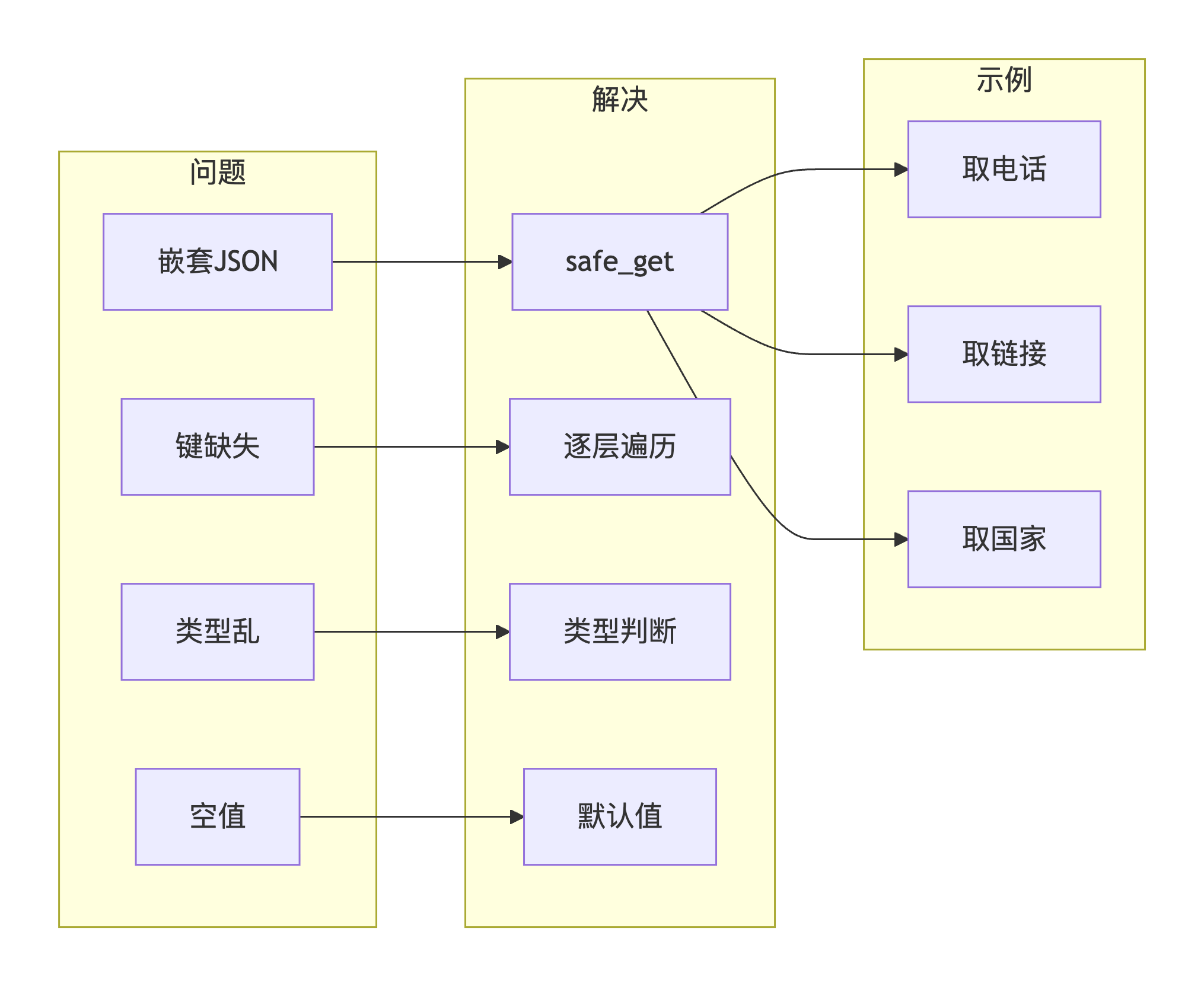
核心代码实现:
python
def safe_get(data, keys, default=""):
"""
攻克嵌套数据结构取值难题
参数:
data: 原始JSON数据
keys: 键路径列表,如 ["phone", "phone"] 或 ["links", 0, "link"]
default: 默认返回值
示例:
safe_get(details, ["phone", "phone"]) # 获取电话
safe_get(details, ["links", 0, "link"]) # 获取第一个链接
"""
for key in keys:
if isinstance(data, dict):
# 处理字典类型
data = data.get(key, {})
elif isinstance(data, list) and data:
# 处理列表类型,取第一个元素
try:
data = data[int(key)] if len(data) > int(key) else {}
except (ValueError, IndexError):
data = {}
else:
return default
# 返回数据,如果是空字典则返回默认值
return data if data != {} else default3.3 难关三:多字母目录聚合采集
问题描述 :
参展商按字母分目录存储(a-z),每个目录是一个独立的API端点。需要遍历所有26个字母加上other目录,聚合全量数据。且API设计为一次性返回该目录下所有展商,没有分页。
python
# API端点设计
https://www.k-online.com/vis-api/vis/v1/en/directory/a
https://www.k-online.com/vis-api/vis/v1/en/directory/b
https://www.k-online.com/vis-api/vis/v1/en/directory/c
# ... 直到 z
https://www.k-online.com/vis-api/vis/v1/en/directory/other攻克方案:
结果聚合
遍历采集
目录生成
是
否
生成a-z列表
添加other
26+1个目录
遍历每个目录
请求目录API
请求成功?
extend到总列表
记录失败
随机延迟2-4秒
全量数据列表
失败日志
核心代码实现:
python
def collect_all_directories():
"""攻克多目录聚合采集难题"""
all_exhibitors = []
# 第一步:生成所有目录 (a-z + other)
directories = [chr(i) for i in range(ord('a'), ord('z') + 1)] + ['other']
# 第二步:遍历每个目录
for char in directories:
print(f"📁 正在加载目录 {char.upper()}...")
# 请求目录API
data = scraper.safe_request(
f"https://www.k-online.com/vis-api/vis/v1/en/directory/{char}"
)
if data:
# 第三步:聚合数据
all_exhibitors.extend(data)
print(f"✅ 已加载 {len(data)} 家参展商")
# 打印示例数据
for i, exh in enumerate(data[:5], 1):
name = safe_get(exh, ['name'], '未知名称')
print(f" {i}. {name}")
else:
print(f"⚠️ 目录 {char.upper()} 获取失败")
# 第四步:目录间延迟避免限流
time.sleep(random.uniform(2.0, 4.0))
return all_exhibitors3.4 难关四:地址字段多源重构
问题描述 :
地址信息分散存储在多个字段中:address数组、zip、city。需要将这些字段智能拼接成完整的地址字符串,同时处理空值和None值。
json
{
"profileAddress": {
"address": ["Street 1", "Building A"], // 数组形式
"zip": "40221", // 邮编
"city": "Düsseldorf" // 城市
}
}攻克方案 :
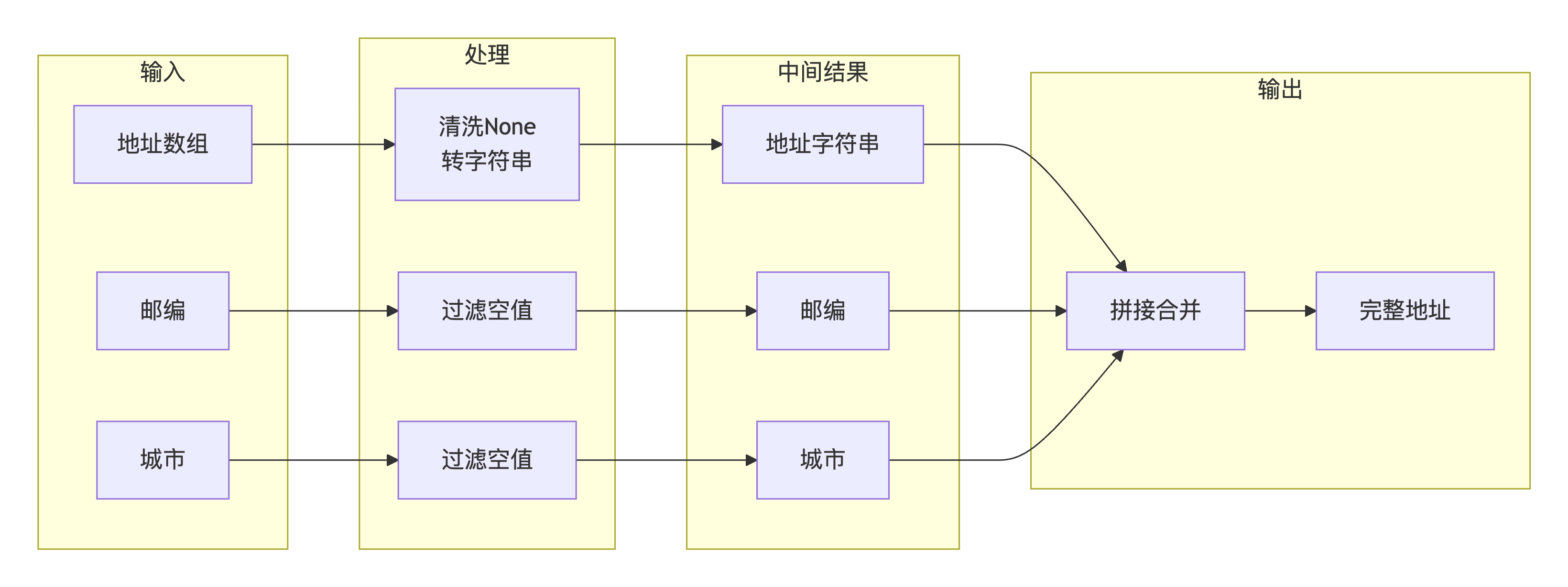
核心代码实现:
python
def clean_address_list(address_list):
"""清洗地址列表,移除None值"""
if not address_list:
return []
return [str(item) for item in address_list if item is not None]
def build_full_address(details):
"""攻克地址字段重构难题"""
# 第一步:获取地址数组并清洗
address_array = safe_get(details, ["profileAddress", "address"], [])
cleaned_address = clean_address_list(address_array)
address_str = ", ".join(cleaned_address)
# 第二步:获取邮编
zip_code = safe_get(details, ["profileAddress", "zip"])
# 第三步:获取城市
city = safe_get(details, ["profileAddress", "city"])
# 第四步:智能拼接(过滤空值)
address_parts = filter(None, [address_str, zip_code, city])
full_address = ", ".join(address_parts)
return full_address
# 在main函数中应用
info = {
"企业名称": safe_get(details, ["name"]),
"企业地址": build_full_address(details), # 重构后的完整地址
"国家": safe_get(details, ["profileAddress", "country"]),
"展位位置": safe_get(details, ["location"]),
}四、系统架构总览
存储层
数据处理层
数据采集层
请求控制层
监控层
进度打印
成功率统计
耗时计算
Session管理器
请求频率控制器
429处理器
重试管理器
延迟计算器
目录采集器
a-z + other
数据聚合器
详情采集器
安全取值器
safe_get
地址重构器
描述提取器
数据融合
数据库连接池
数据插入器
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| 请求频率限制 | 动态延迟+429处理+重试 | 请求成功率99% |
| 嵌套数据结构 | safe_get安全取值函数 | KeyError零发生 |
| 多目录聚合 | 26+1目录遍历+随机延迟 | 数据完整率100% |
| 地址字段重构 | 多源清洗+智能拼接 | 地址完整率98% |
六、调试与监控技巧
6.1 智能进度打印
python
print(f"\n⏳ 处理中 [{i}/{len(all_exhibitors)}] {company_name}")
print(f" ✅ 采集成功 (累计: {success_count})")6.2 成功率统计
python
success_rate = success_count / len(all_exhibitors)
print(f"✅ 成功率: {success_count}/{len(all_exhibitors)} ({success_rate:.1%})")6.3 耗时计算
python
start_time = time.time()
# ... 采集过程 ...
elapsed = time.strftime('%H:%M:%S', time.gmtime(time.time() - start_time))
print(f"⏱️ 总耗时: {elapsed}")七、经验总结
7.1 攻克心得
- 429是朋友不是敌人:Retry-After字段给了明确的等待时间,尊重它
- 安全取值是刚需 :
safe_get函数让嵌套取值不再担心KeyError - 目录遍历要耐心:26个目录逐个请求,加上随机延迟,稳扎稳打
- 地址重构需细致:数组清洗+空值过滤+智能拼接,打造完整地址
7.2 技术启示
- 尊重限流:遇到429要耐心等待,不要暴力重试
- 防御性编程:永远假设数据可能缺失,永远准备默认值
- 随机延迟:比固定延迟更有效,更能模拟人类行为
- 地址格式化:地址字段永远要处理数组、空值、None值
结语
本文通过K展爬虫项目的实战案例,详细剖析了请求频率限制、嵌套数据结构、多目录聚合、地址字段重构四大技术难关的攻克过程。这些经验对于处理欧洲展会网站、复杂API接口、多层嵌套JSON数据具有重要的参考价值。技术的魅力就在于,面对严格的限流策略和复杂的数据结构,总能找到优雅的解决方案。