目录
一.线程
"线程"的概念在上一篇文章"进程与线程的区别和联系"中有详细的讲解,下面也会重新讲解重要概念。
1.线程是什么
线程,可以想象成,一个"盒子"里面实现了一堆要运行的代码,这个盒子就是线程。操作系统通过cpu调用线程,并执行其中的代码,完成线程的使命!
2.多线程编程
多线程编程就是"并发编程"。我们在多个线程中实现代码,为什么就叫"并发编程"?其实是因为有操作系统的随机调度,这层背景。并发的详细定义在"进程与线程的区别和联系".
注意,多线程之间可能"并行执行"也可能"并发执行",程序员不用关注是哪种执行方式,我们既知道不了,也干预不了。
3.认识线程类Thread
3.1.Thread的常用构造方法
|-------------------------|-------------------------------------------|
| 构造方法 | 解释 |
| Thread() | 创建一个线程 |
| Thread(Runnable) | 创建一个参数只允许传入Runnable接口,或实现了Runnable接口的类的线程 |
| Thread(String) | 创建线程,并给线程起个名字 |
| Thread(Runnable,String) | 上面两个解释的和 |
3.2.Thread常见的属性
|----------|-----------------|
| 线程属性 | 获取方法 |
| ID | getId() |
| 名称 | getName() |
| 状态 | getState() |
| 优先级 | getPriority() |
| 是否存活 | isAlive() |
| 是否后台线程 | isDaemon() |
| 是否终止了 | isInterrupted() |
- 每个线程独有一个ID,ID是线程的唯一标识。
- 名称是各种调试工具用到。
- 状态表示线程所处的情况。
- 优先级高的,理论上来说更容易被调用。
- 判断线程是否正在运行(run方法是否运行结束)。
- 是否是后台线程。就算后台线程还在运行,非后台线程(前台线程)运行结束,进程就结束(关闭)了。
- 线程是否终止,是则返回true,否返回false。
后面会实例线程,使用线程方法,并作出细节说明!!
4.实战线程
4.1.创建线程的五种方式
设计好run()后,使用"引用.start()"启动线程,线程启动后会自动调用run方法,这个run方法就是线程要执行的任务,所以run必须设计好.
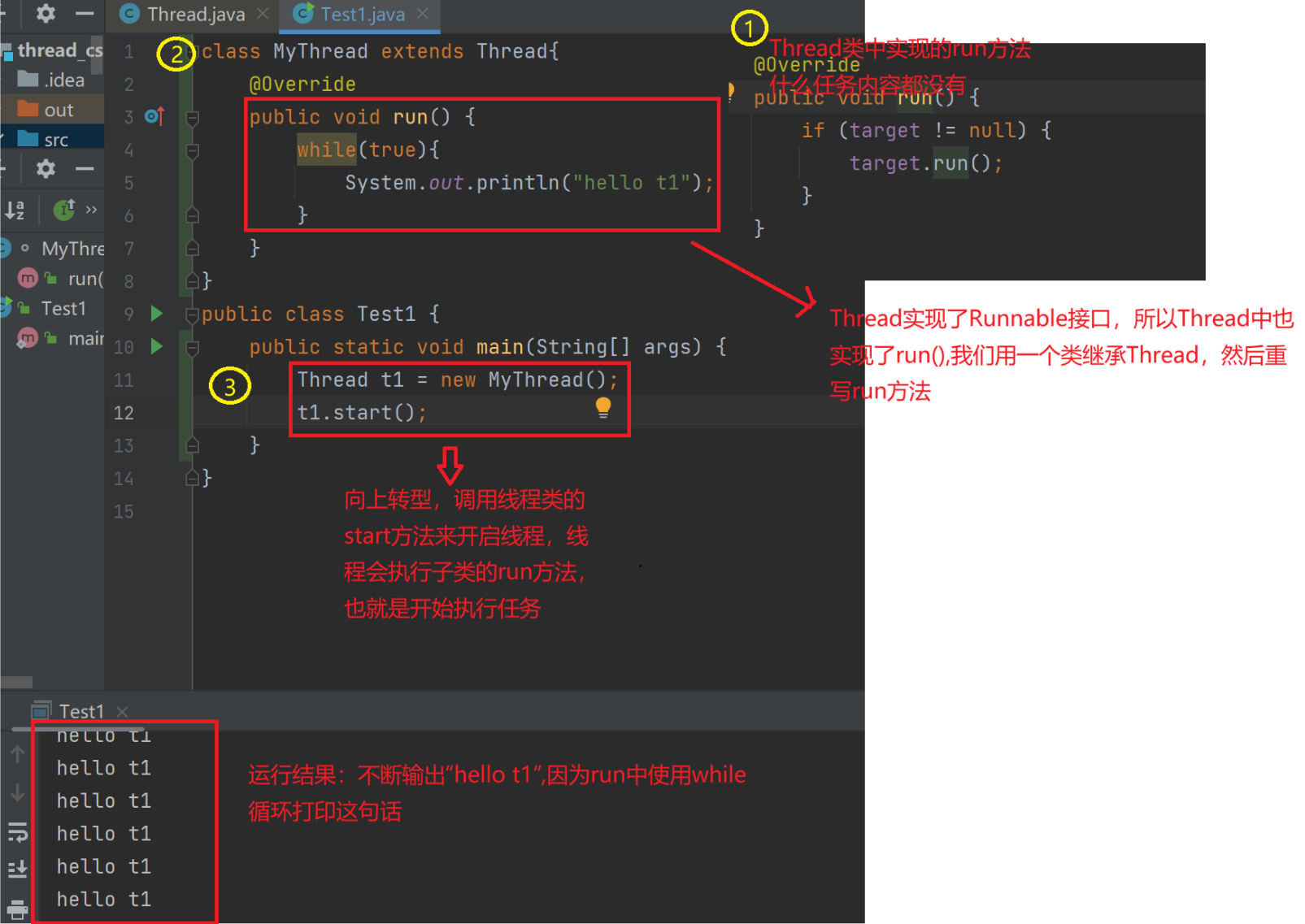
上述,采用创建一个类继承Thread,并重写run方法的方式创建线程,除这种方式能创建线程外,还有四种创建的方式。
java
//方式2:创建类,实现Runnable接口,并重写run方法,然后将含有MyRunnable对象的引用作为构造参数
class MyRunnable implements Runnable{
@Override
public void run() {
while(true){
System.out.println("hello t1");
}
}
}
public class Test2 {
public static void main(String[] args) {
//不能实例化接口,只能实例实现了接口的类
//向上转型
Runnable runnable = new MyRunnable();
Thread t1 = new Thread(runnable);
//线程启动后,调用MyRunnable的run
t1.start();
}
}
//----------------------------------------------------------------------------
//方式3:使用"匿名内部类"的方式创建线程
public class Test3 {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
while(true){
System.out.println("hello t1");
}
}
};
Thread t1 = new Thread(runnable);
t1.start();
}
}
//----------------------------------------------------------------------------
//方式4:对Thread使用匿名内部类,重写run,并让Thread类型的引用继承匿名内部类
public class Test4 {
public static void main1(String[] args) {
Thread t1 = new Thread(){
@Override
public void run() {
while(true){
System.out.println("hello t1");
}
}
};
t1.start();
}
}
//----------------------------------------------------------------------------
//方式5:用lambda表达式
public class Test5 {
public static void main(String[] args) {
//lambda表达式
Thread t1 = new Thread(()->{
while(true){
System.out.println("hello t1");
}
});
t1.start();
}
}上述五种创建线程的方式中,最常用的就是方式5,使用lambda创建线程。
4.2.线程常见属性的实例
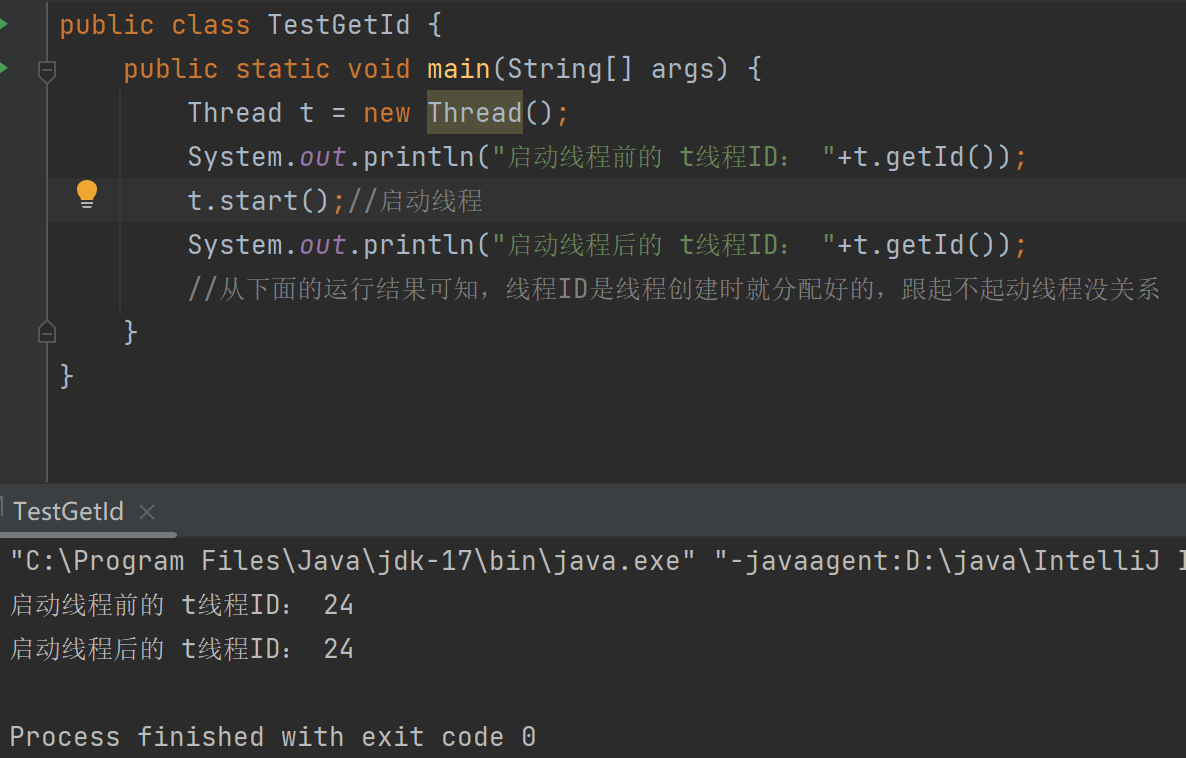
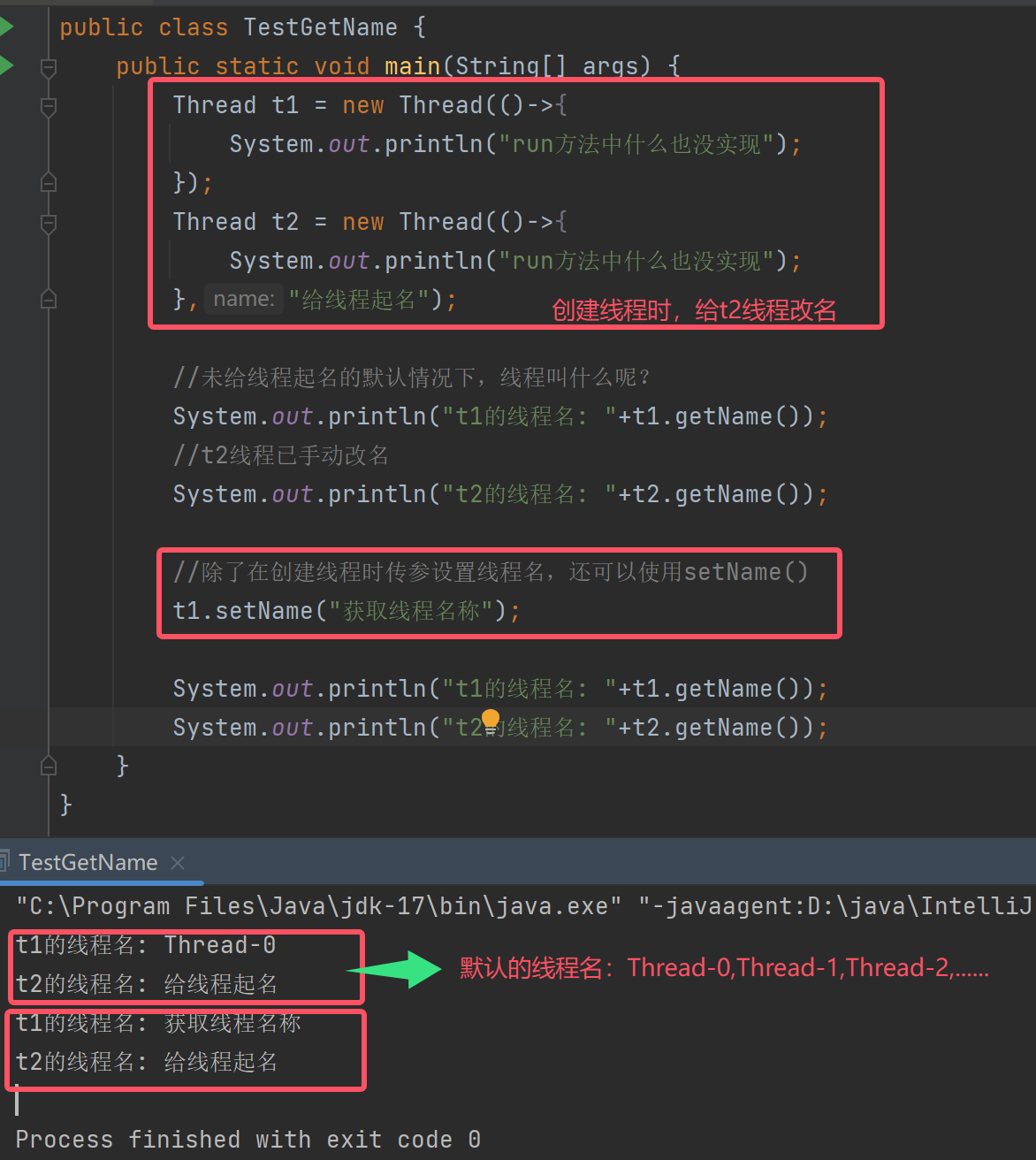
注意:线 程属性,是线程创建时就默认分配好的,不存在只有启动线程才能获取属性的说法。
4.2.1获取线程ID
4.2.2获取线程名称
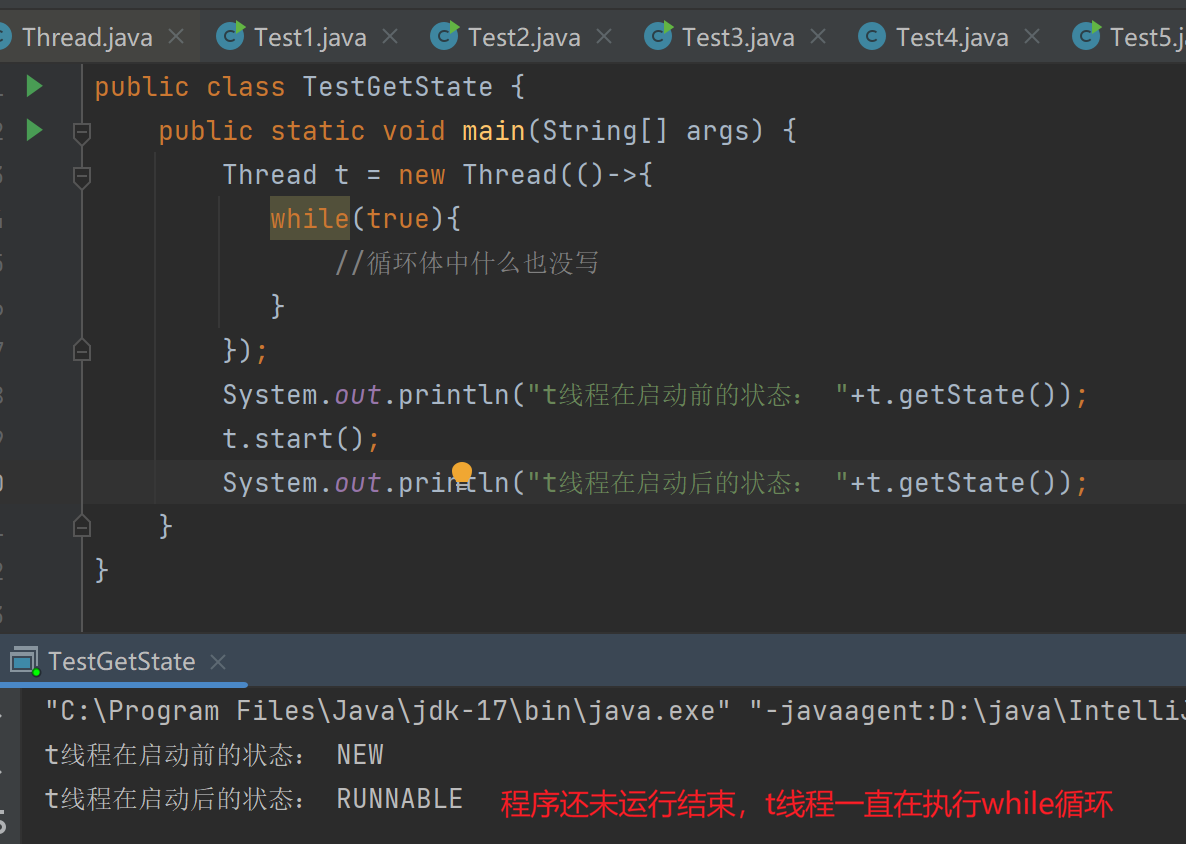
4.2.3获取线程状态
Java给线程设定了这么几种状态:NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING,TERMINATED
|---------------|----------------------------------------------------------|
| 状态 | 说明 |
| NEW | 创建了线程,但还未启动线程 |
| RUNNABLE | 正在工作或即将工作(随叫随到) |
| BLOCKED | 由于锁导致的阻塞状态 |
| WAITING | 死等,没有超时时间的等待 |
| TIMED_WAITING | 1.由设定了超时时间的阻塞;2.线程阻塞(由于线程没吃到cpu资源,就不继续执行线程内容)引起的有时间限制的阻塞 |
| TERMINATED | 工作完成 |
NEW、RUNNABLE
BLOCKED
(不了解"锁"的,可以先看下面"5.2 synchronized"这一主题中锁的定义)
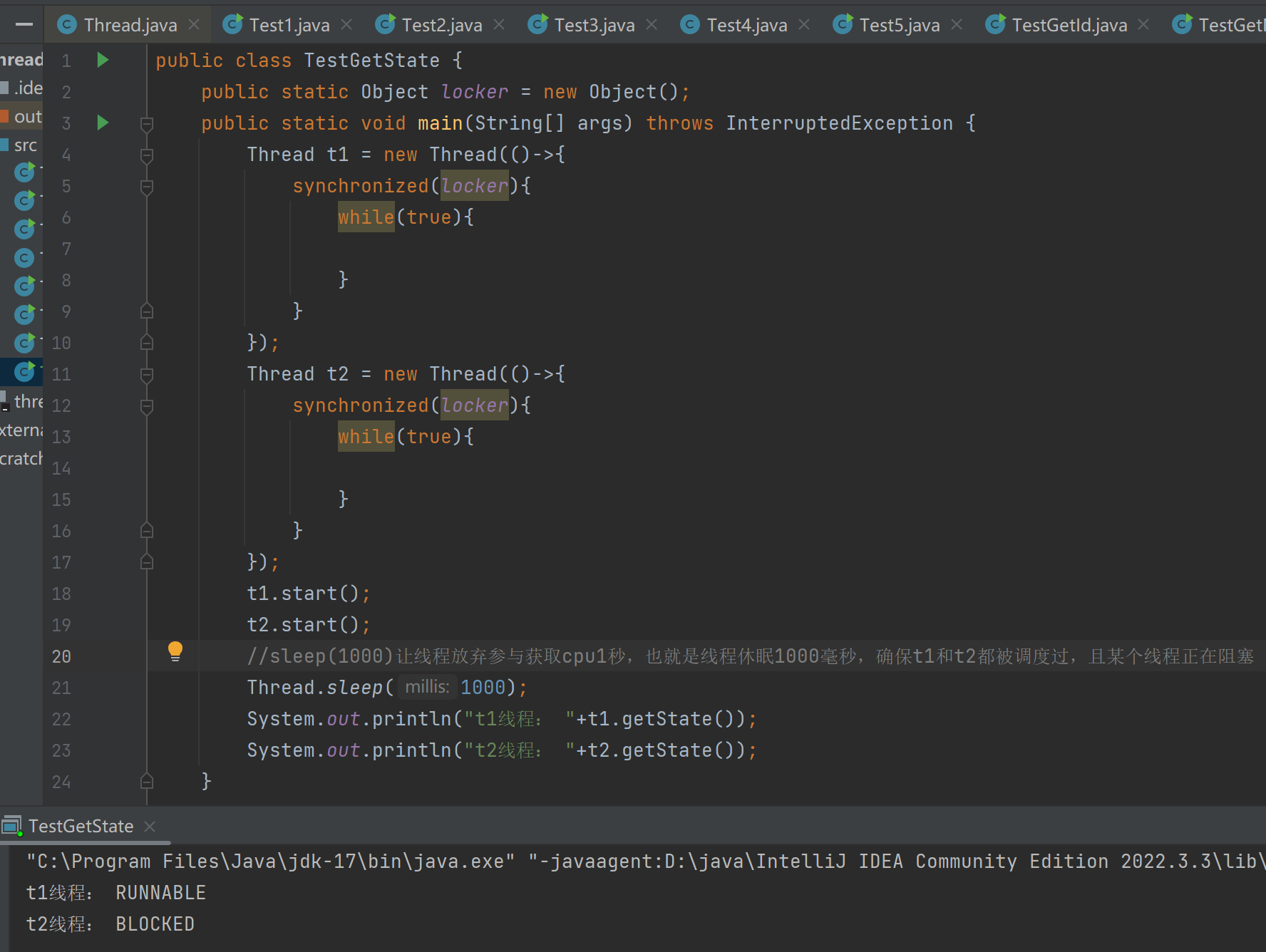
WAITING
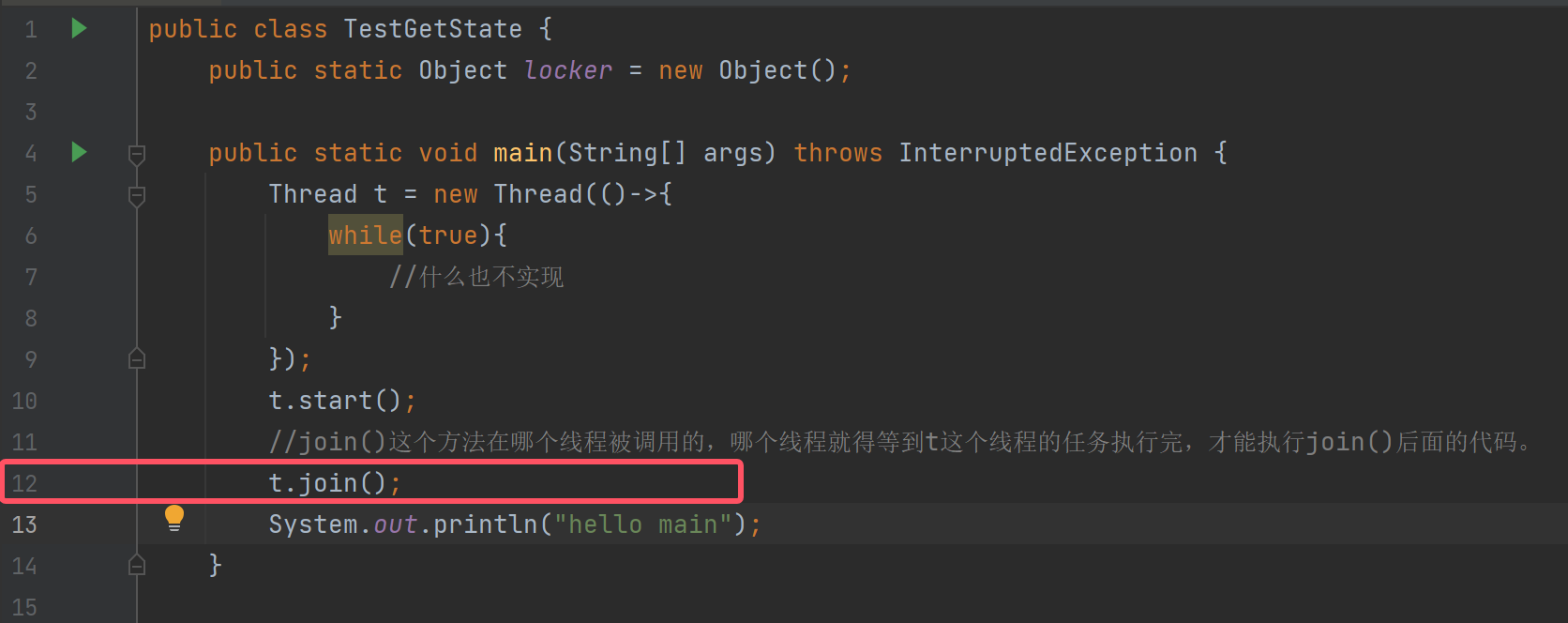
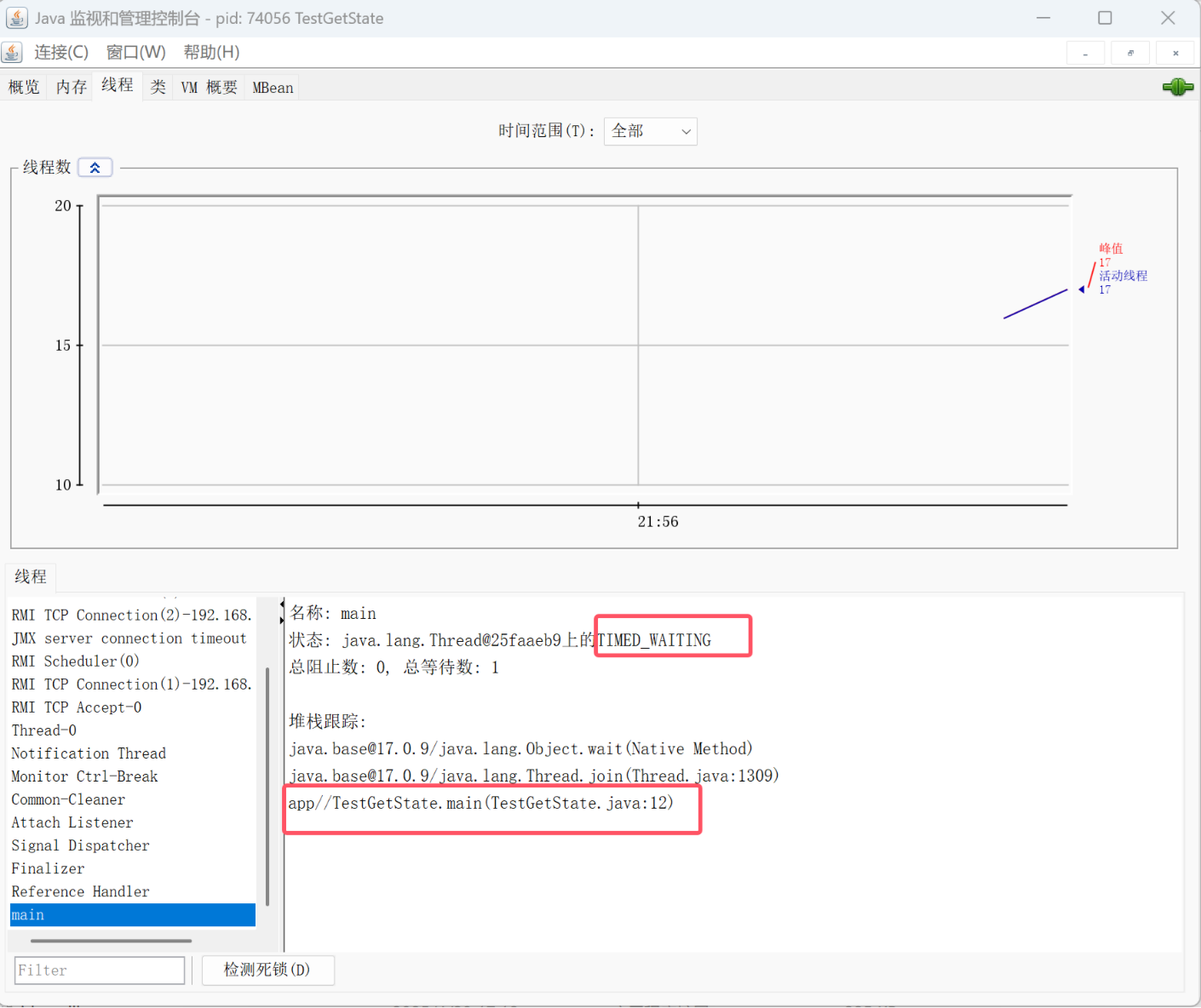
在上述代码中比较难获取到主线程的状态,我们可以点开 C:\Program Files\Java\jdk-17\bin下的jconsole.exe,观察我们正在运行的程序(进程)。
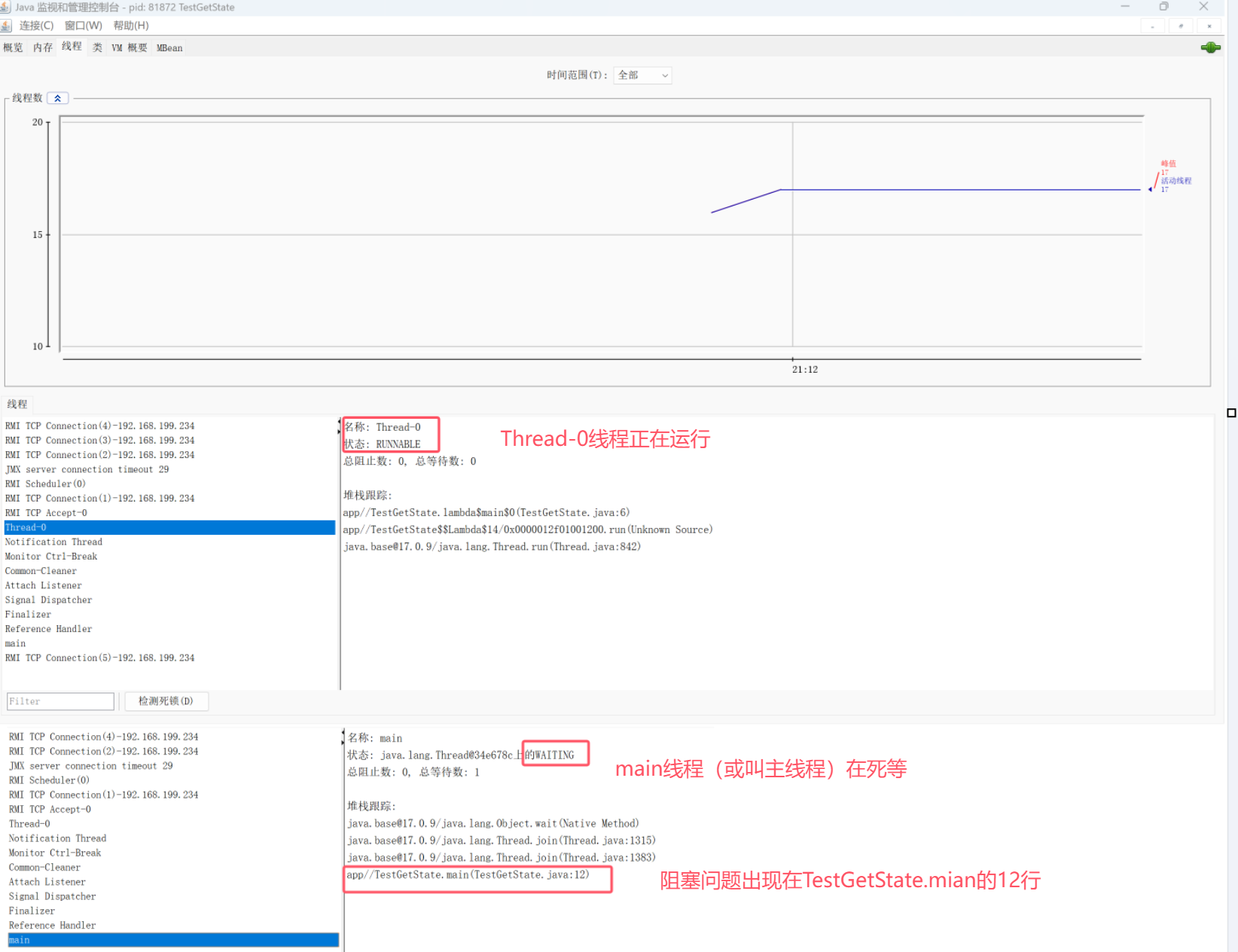
第12行就是join()语句的位置。
TIMED_WAITING
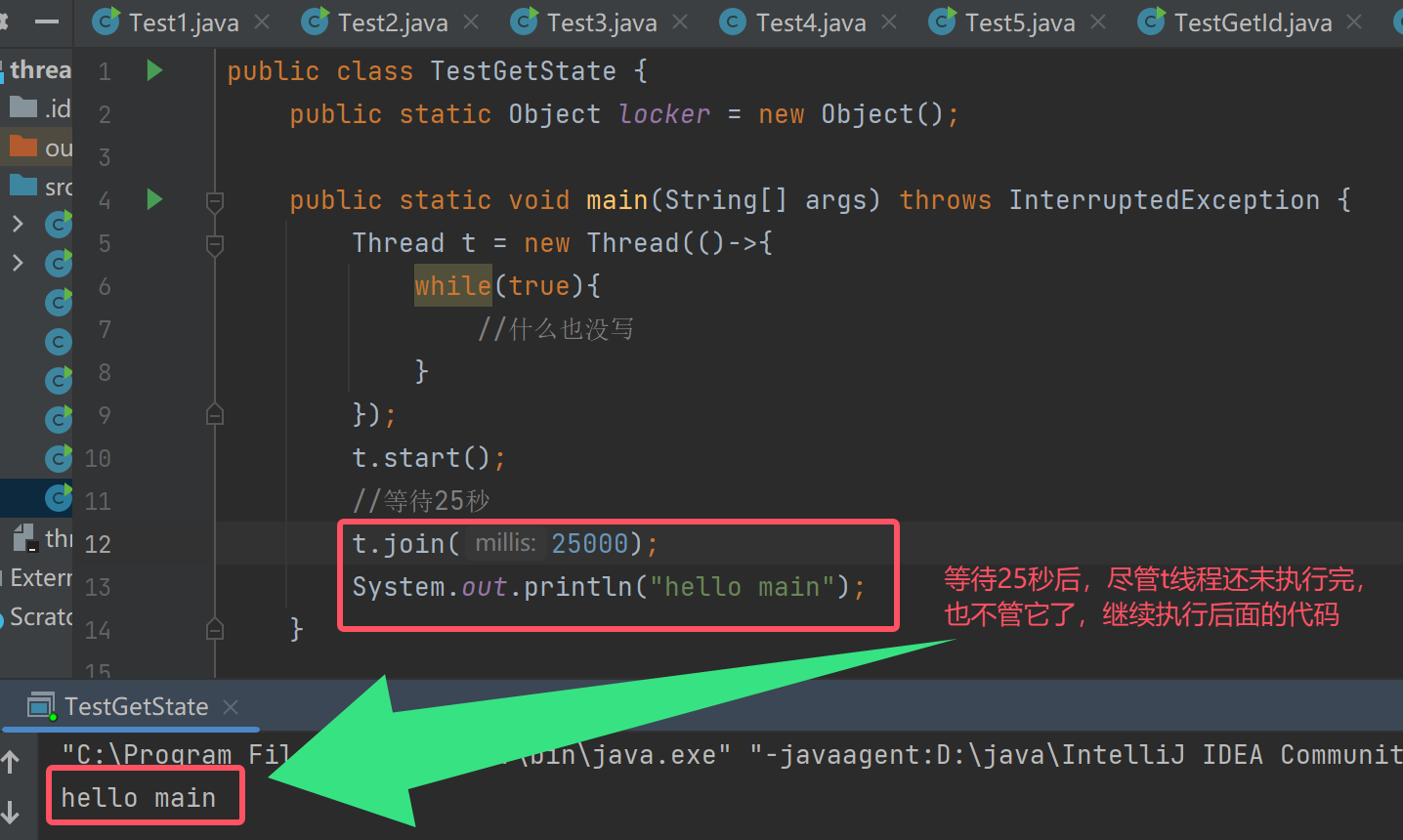
看见join方法的使用是不是感觉很不科学?假如我们在外面等一个人,等了三四、四五小时人还没来,我们就会不等走了。join方法也一样,join还可以设定超时时间,join(1000)->超时时间为1000毫秒,超过这个时间没等到就接着执行下面的代码了;join(1000,500)->超时时间为1000毫秒+500纳秒。(sleep的休眠时间单位也如此)
4.2.4获取状态优先级
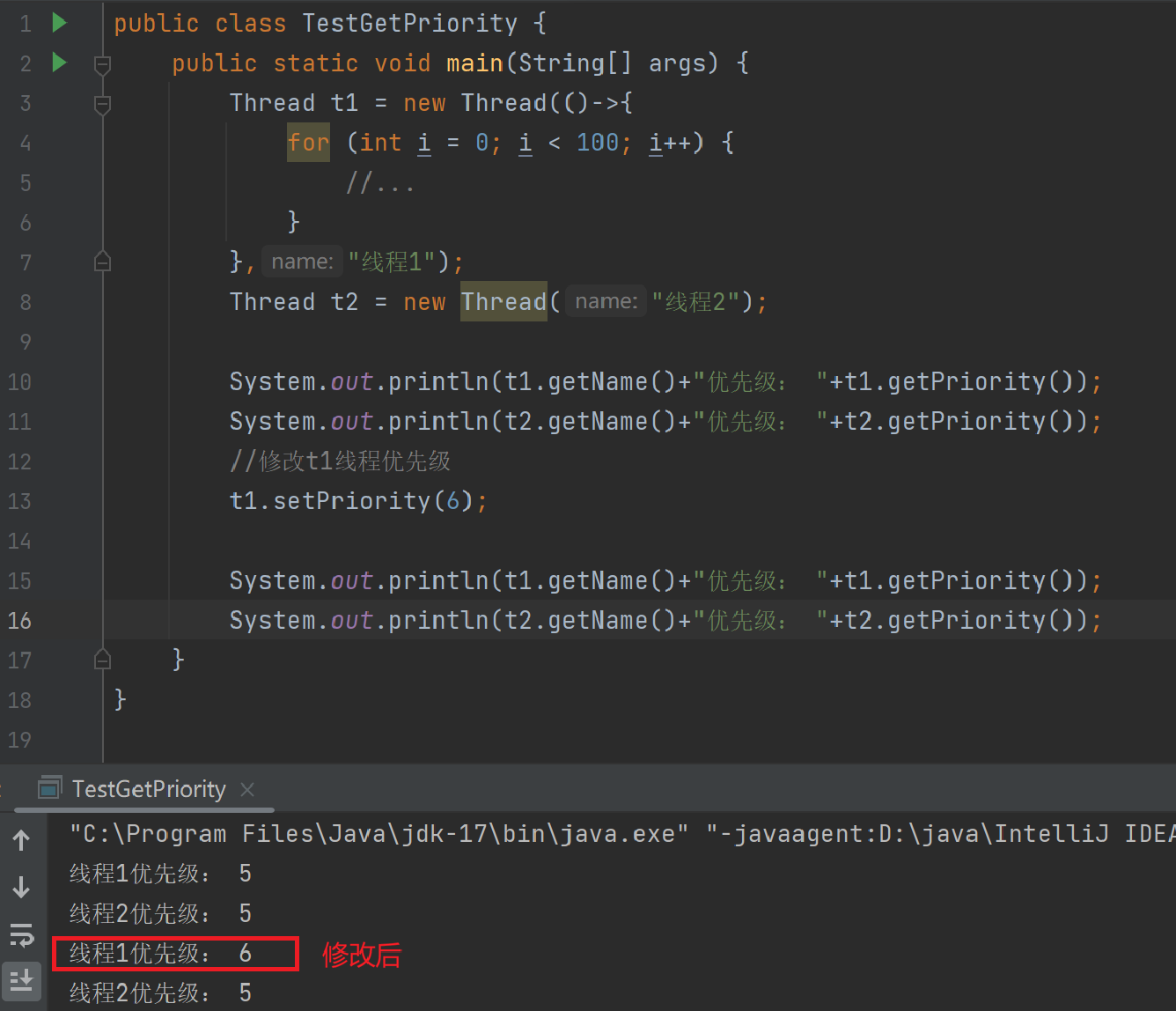
优先级高的进程或线程更容易被调用,这一现象也体现在开启多个后台玩游戏。我们玩游戏,可能电脑卡一下游戏就结束了,但是qq等程序延迟接收信息一分钟也没关系,所以游戏程序的优先级比qq高,才能保障游戏吃到更多的cpu资源,画面更流畅。
优先级高低形式还分场景。在Linux中,优先级值越小,优先级别越高。Java中,优先级值越大,优先级别越低。
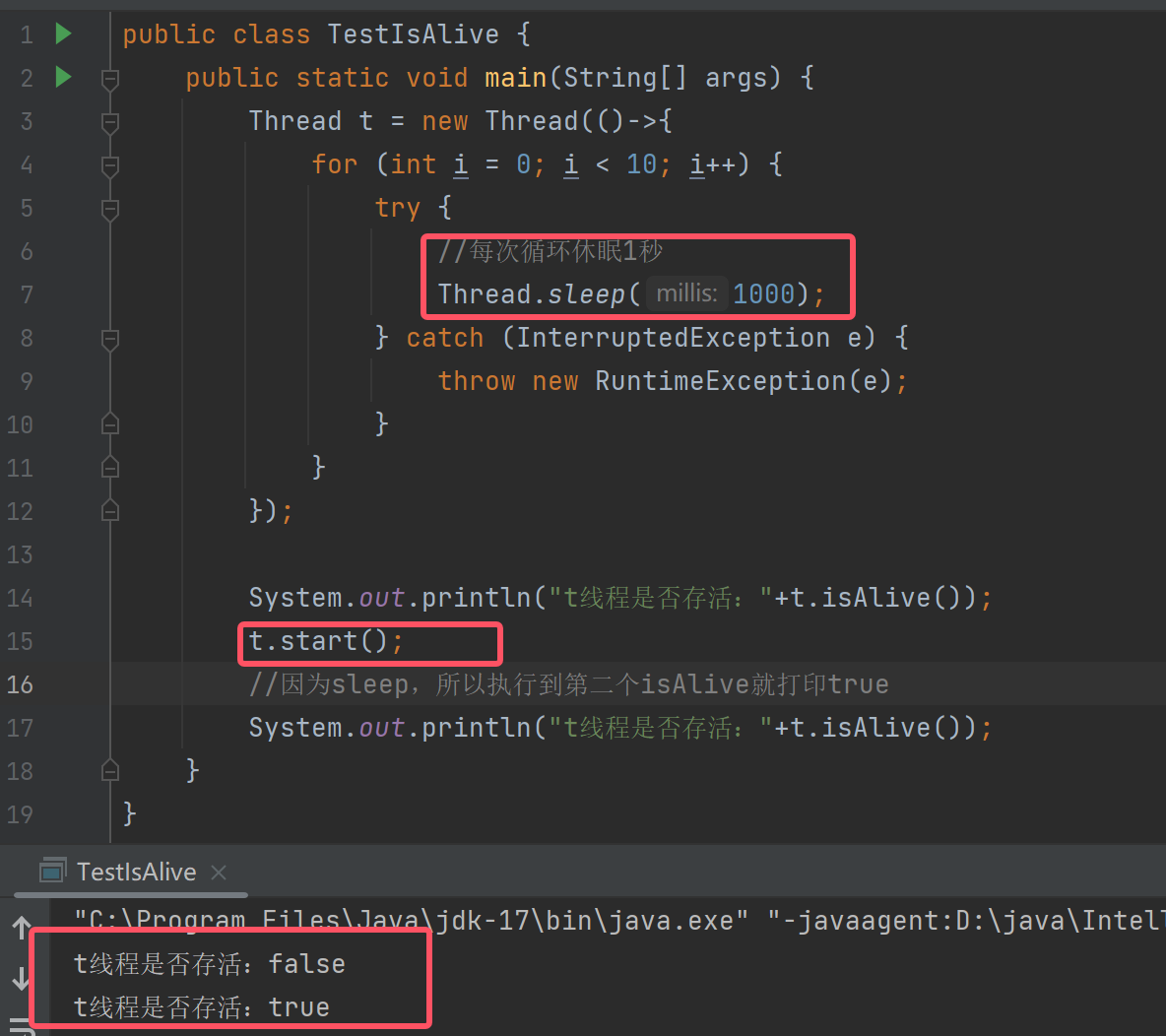
4.2.5线程是否存活
4.2.6是否后台线程
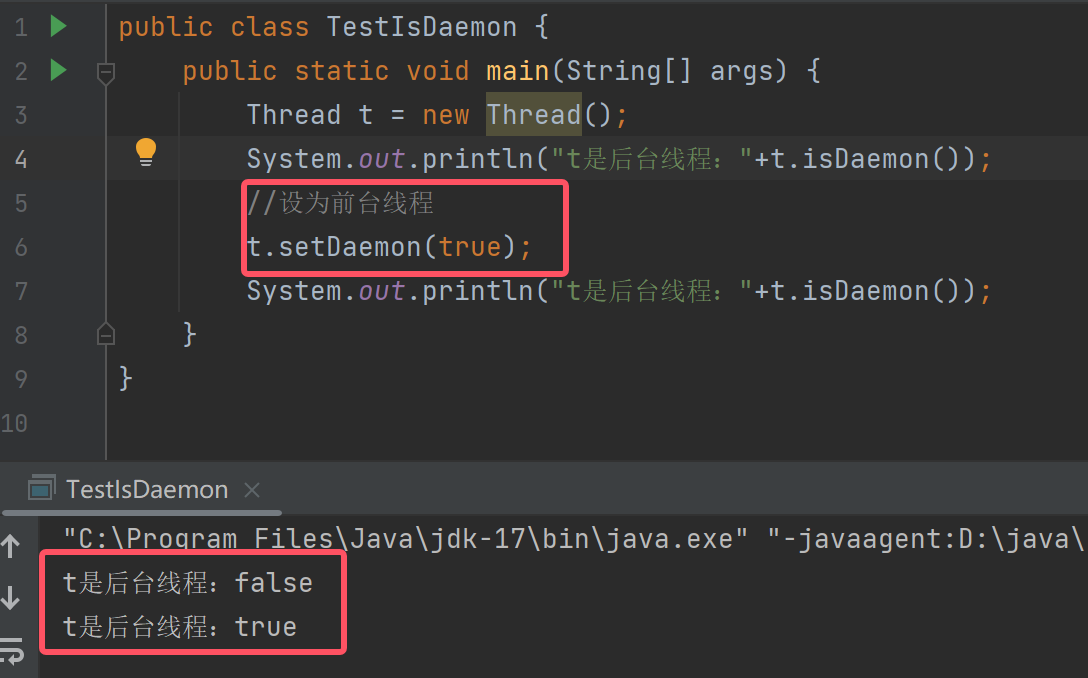
手动创建的线程都默认为"前台线程"。前台线程和进程的结束息息相关,前台线程全部结束了,就算还有后台线程在运行,进程也会结束。
4.2.7线程是否终止
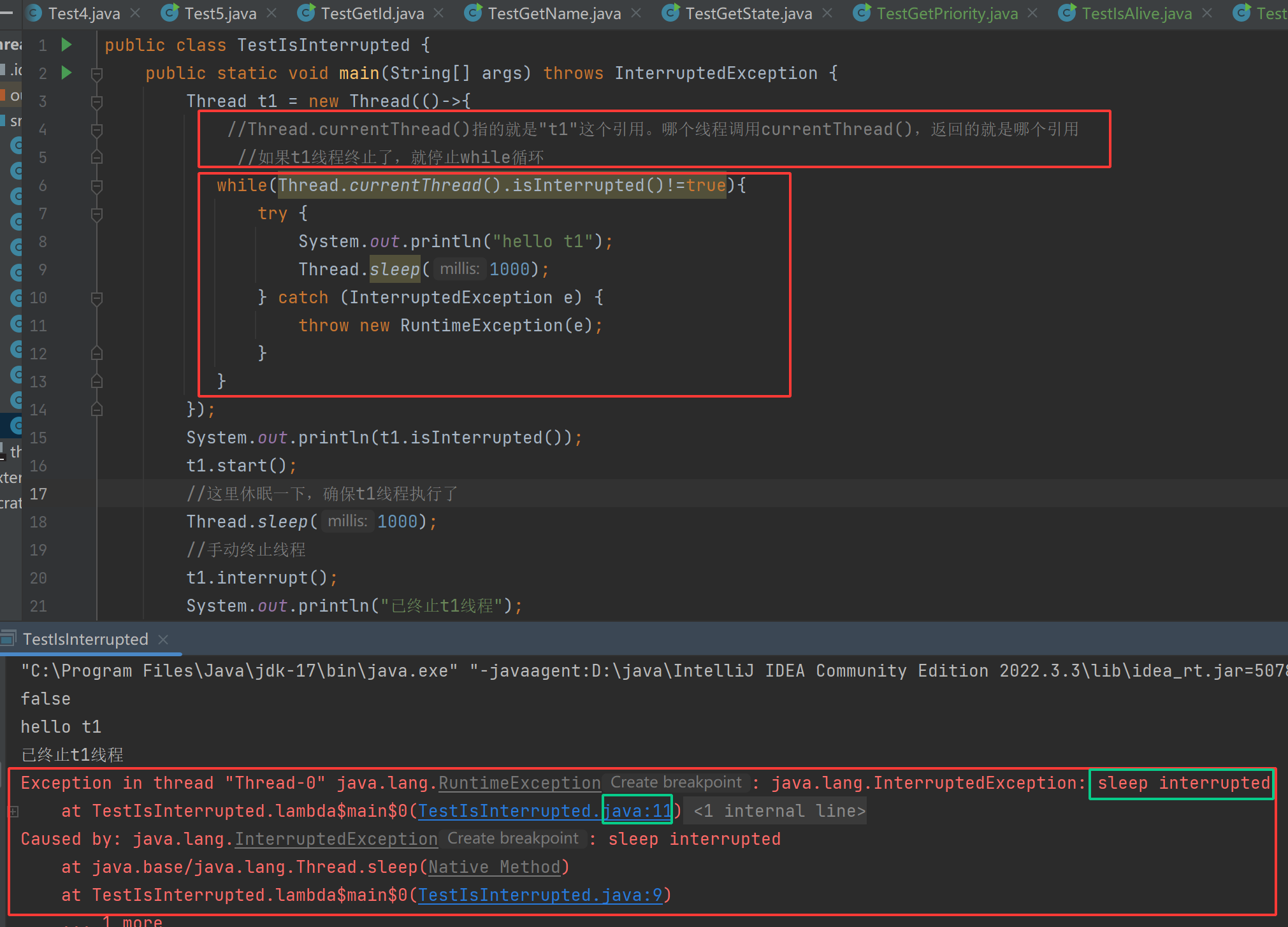
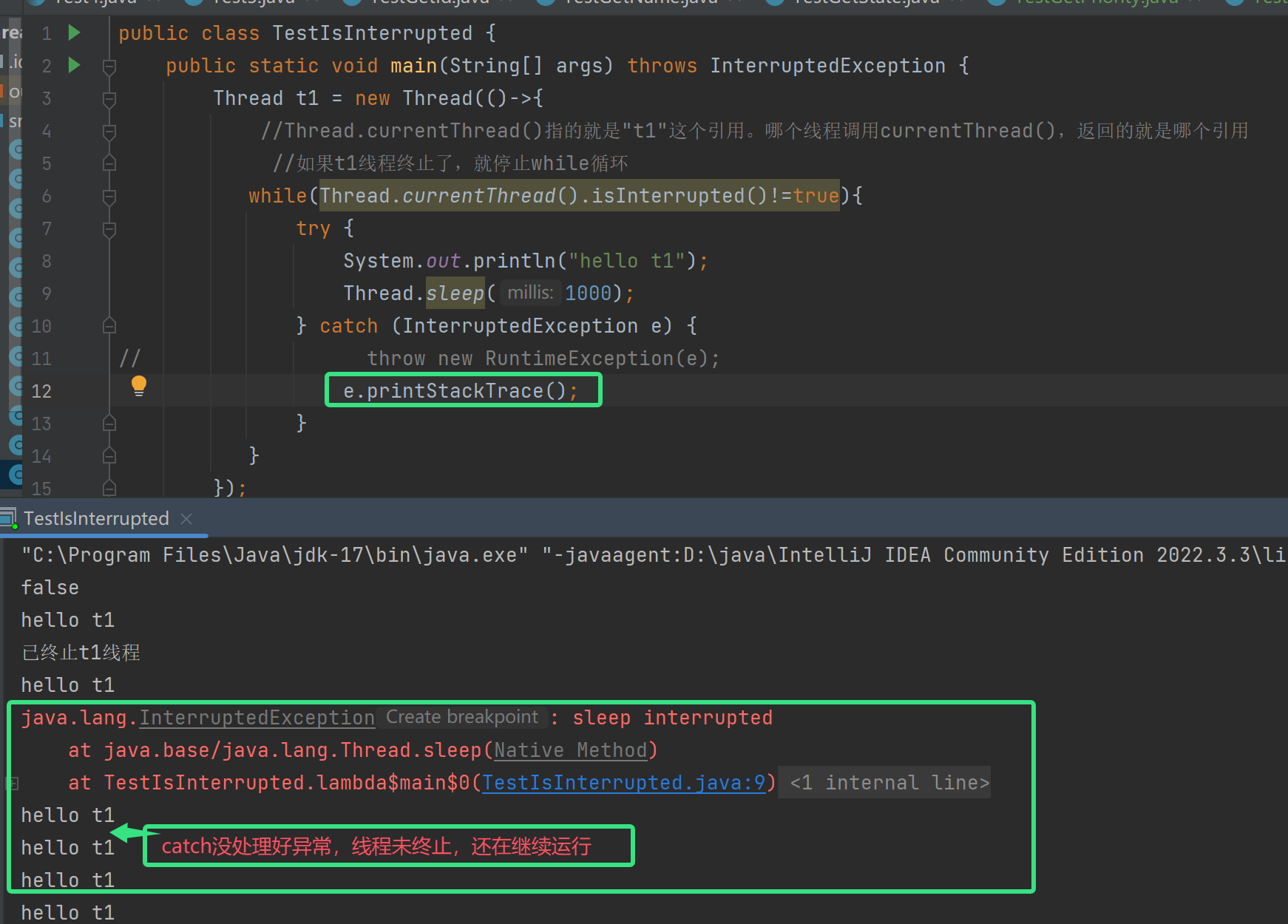
看懂上述代码逻辑结构后,我们不明白为什么在主线程中,手动终止t1线程会报错呢?说sleep interrupt。其实是sleep()在作怪,当我们手动终止(终止原理,将isInterrupted()中的标志位改为true)线程时,如果线程正在sleep休眠,那么sleep就会被唤醒并抛出InterruptedException,并把isInterrupted方法中的标志位改为false,这时要是catch没处理好就会出现,如下图手动终止了,但是线程没终止的bug。
5.线程安全问题
"线程安全问题"又叫"线程不安全",通过下面一个示例,了解保障线程安全的重要性。
java
public class Test6 {
public static int count =0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
for(int i=0;i<50000;i++){
count++;
}
});
Thread t2 = new Thread(()->{
for(int i=0;i<50000;i++){
count++;
}
});
t1.start();
t2.start();
//main线程等待t1、t2线程结束
t1.join();
t2.join();
System.out.println("count= "+count);
}
}按上述逻辑count最后应该等于100000才符合o预期。

原因解释:图下附带说明
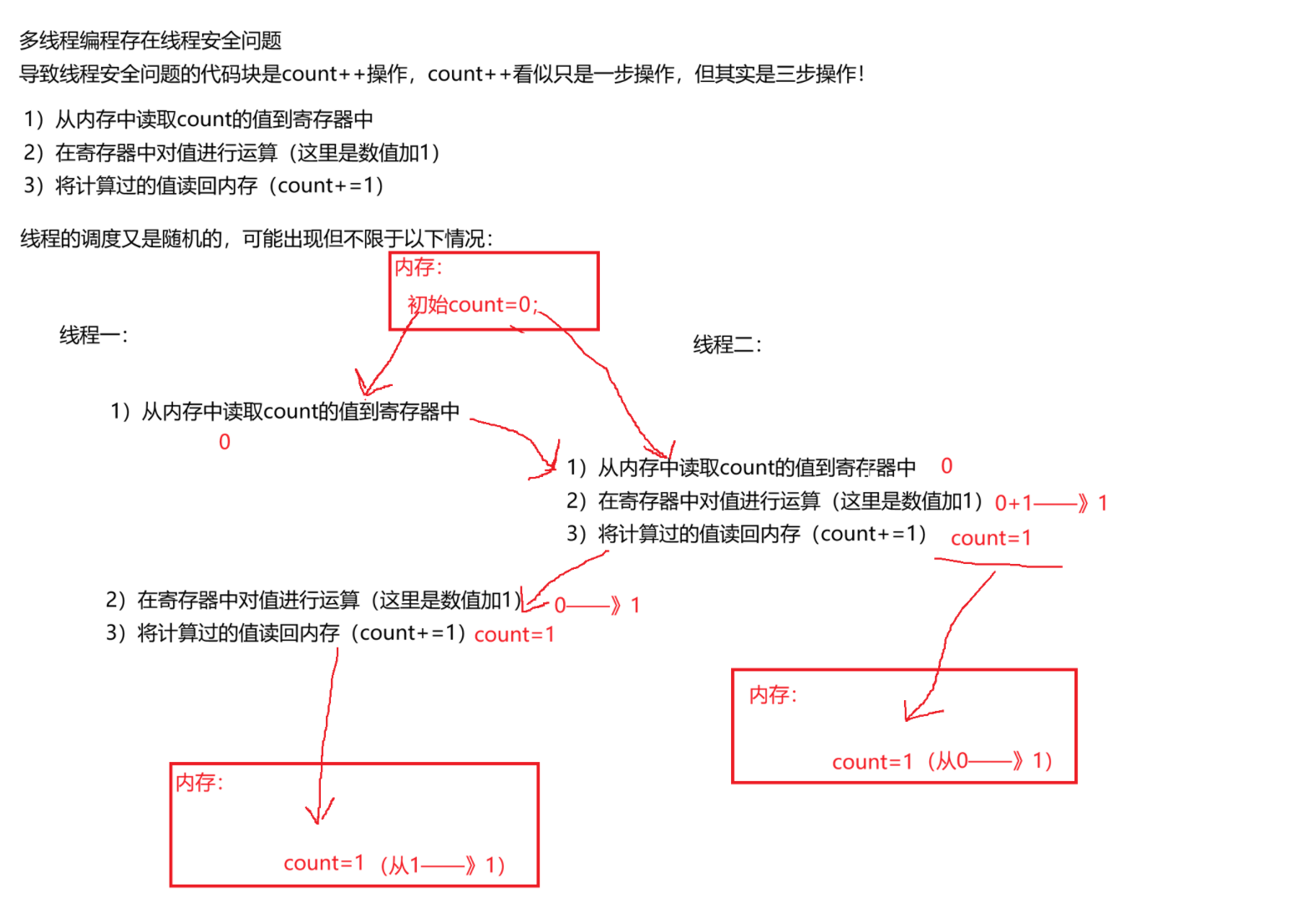
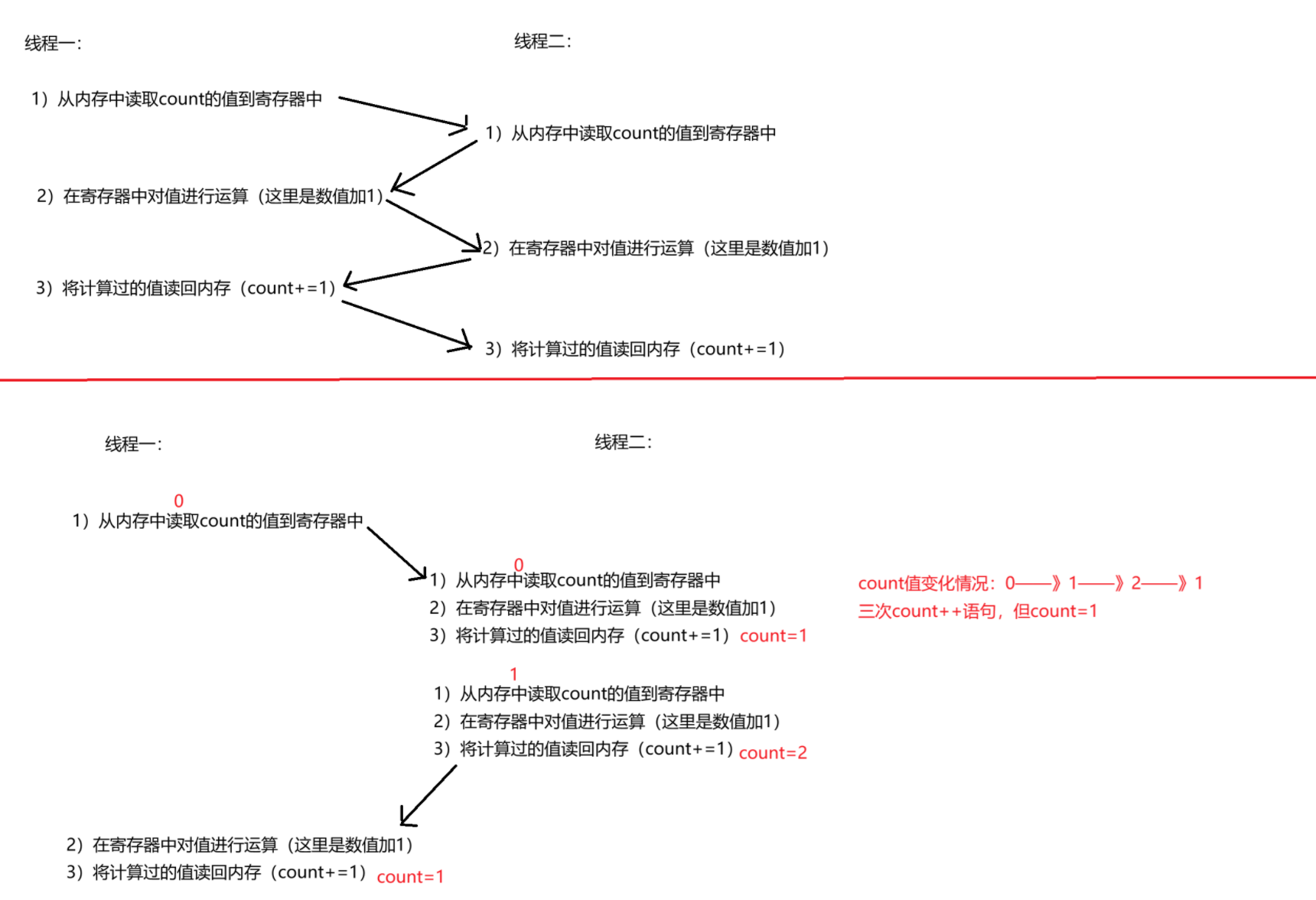
图片说明:count++语句在操作系统中是三步操作,线程一在执行完第一步操作后,cpu就被调走了;线程二被调用,执行了三步操作,count值加1,等于1;然后线程一被调用,由于"线程上下文"功能,寄存器就从第二步开始执行,因为寄存器中的值还是0,所以0+1=1,执行第三步,将1读回内存,赋给count的值为1,所以进行两次count++语句,count还等于1。
除了上述这种情况,还有但不限于:
5.1线程不安全的原因
1)(根本)操作系统对线程的调度是随机的。抢占式执行。
2)多线程同时修改同一个变量。
3)修改操作,不是原子的(原子性)。(如果一条语句只对应一条CPU指令,就认为是原子的,那么就不会出现"一条语句执行一半"的情况)
4)内存可见性问题。
5)指令重排序问题。
这些都是引起线程安全问题的原因,根据原因我们可以自己解决开发中的安全问题。
5.1.1多线程同时修改同一个变量
首先不能从原因1下手解决问题,因为程序员修改不了操作系统;
可以从原因2入手,把"并发编程"风格代码,改成"串行"风格。修改如下:
java
public class Test7 {
public static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
//等待t1线程执行完,再执行后续代码。
t1.join();
//t1线程执行完,执行t2线程。
t2.start();
t2.join();
System.out.println("count="+count);
}
}这样等待一个线程结束再执行另一个线程的方式就是"串行执行",避免多个线程同时修改同一个变量,出现线程安全问题。但上面的方案还不够通用,第二种方案是加"锁"。方案二解决了原因3。
5.1.2修改操作,不是原子的
方案二:
java
public class Test8 {
public static int count=0;
public static Object object = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
synchronized(object){
for (int i = 0; i < 50000; i++) {
count++;
}
}
});
Thread t2 = new Thread(()->{
synchronized(object){
for (int i = 0; i < 50000; i++) {
count++;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count="+count);
}
}synchronized说明:
synchronized是一个锁;synchronized()的括号中写入一个对象(这个对象又叫"锁对象",锁对象可以是任何类型),进入synchronized代码块就对"锁对象"上锁,出代码块就解锁;在多线程编程中,锁对象还未解锁,t2线程就被调度,执行synchronized对同一个锁对象加锁,这样会造成t2线程阻塞等待,只有等待前面的synchronized执行完,将锁对象解锁了其他线程才有机会上锁。只有锁对象相同才会产生阻塞效果。(synchronized在5.2详细介绍)
上述代码解释:t1、t2线程要执行的run()中,synchronized的锁对象是同一个,所以在先执行的synchronized结束前,t2线程中的synchronized是不能被执行的。因此count=100000;
5.1.3内存可见性问题
解决原因4。
产生内存可见性问题的背景:JVM会主动优化我们写的代码,但程序逻辑不会改变,被优化后的代码就可能出现"内存可见性问题",例如下面代码
java
import java.util.Scanner;
public class Test9 {
public static int num=0;
public static void main(String[] args) {
Thread t1 = new Thread(()->{
while(num==0){
//......
}
System.out.println("t1线程结束");
});
Thread t2 = new Thread(()->{
Scanner sc = new Scanner(System.in);
System.out.println("输入num值");
num=sc.nextInt();
System.out.println("num变量修改完成="+num);
});
t1.start();
t2.start();
}
}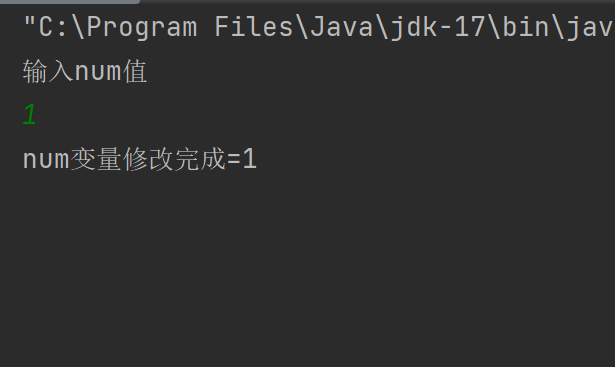
运行上述代码后,修改num的值为1,可是程序还在运行,也就是说t1线程的while循环还在继续,这就让人疑惑,num!=0,为什么while循环还不结束?t1线程还不结束?
其实是因为,t2线程被调度后等待用户输入内容的时间,对于电脑CPU来说简直"沧海山田",现在普通CPU一秒的计算次数高达39亿次以上,所以就算是一毫秒,对电脑CPU来说也是非常久远的时间。
在反复进行while循环条件判定后,JVM发现这个条件一直成立,后续JVM就把判断条件num==0的认为恒成立,所以就算后续num的值不等于0,while循环也不受影响。
这样变量 被JVM优化后导致的线程安全问题,就叫"内存可见性问题",使用volatile修饰变量,可以解决内存可见性问题;(用volatile修饰变量,就是在告诉JVM不能优化这个变量;volatile只能修饰变量)
修改如下:
javapublic volatile static int num=0;
5.1.4指令重排序
java
public class Test10 {
//代码背景:多线程环境下
private static Test10 instance = null;
public static Object object = new Object();
public static Test10 getInstance(){
//外层if是判断instance是否需要加锁,如果没有外层if的话每次都要竞争锁,会阻塞等待,减低效率
if(instance==null){
synchronized(object){
//里面这个if是为了,判断是否给instance new对象,在并发编程下,可能在外层if判
// 断为空,进入外层if,但由于随机调度的原因,可能instance又有对象了,如果进入
// synchronized不再次判断就会再次new对象
if(instance==null){
instance=new Test10();
}
}
}
return instance;
}
}上述代码看似没问题,但其实暗藏玄机!
instance=new Test10;语句涉及三步操作,1)申请内存;2)在空间上构造对象;3)内存空间的首地址,赋值给引用变量。
一般是1、2、3这样的执行顺序,但也有可能1、3、2,当执行完3后,CPU去调度其他线程,结果其他线程判断出instance不为空(虽然该引用变量指向的空间没有任何东西,但是它依然不等于空),就直接return instance。这样因为执行指令的顺序改变,而引起线程安全问题的原因就叫"指令重排序"。
解决"指令重排序"的方法也很简单,就是使用volatile修饰变量。
volatile有两个作用:1.确保每次读取操作,都是都内存;2.volatile修饰的变量在读取或修改,不会触发重排序。
5.2.synchronized
synchronized语法:
synchronized(锁对象){
//加锁内容
}
说明:synchronized是一个锁,锁对象可以是任意类型的对象,Object类型、Student类型都行,例如5.1.1.2的修改例子,synchronized的锁对象就是Object类型。
5.2.1互斥
synchronized有互斥效果;
- 进入synchronized修饰的代码块,对锁对象自动加锁;
- 退出synchronized代码块,锁对象自动解锁;
某个线程正在执行synchronized代码块,另一个(或另一些)线程如果也执行到同一个对象的synchronized,那后面这个synchronized就会阻塞等待,等待对象解锁后,才有机会竞争到锁(简单来说就是,我和你有同一个对象,我先对这个对象上锁了,我的事还没做完,你就算也有事,你也得等我结束了才行)。互斥效果在count==10万前后对比明显。
5.2.2可重入
讲到可重入就离不开"死锁"的情况。
死锁的第一种典型情况如下:
java
public class Test11 {
public static Object object = new Object();
public static void main(String[] args) {
Thread t = new Thread(()->{
synchronized(object){
synchronized(object){
System.out.println("因为synchronized是可重入锁,所以没成死锁");
}
}
});
t.start();
}
}上述代码,synchronized相互嵌套,而且两个锁的锁对象是同一个。外层synchronized已经对object指向的对象加锁,只有退出了外层代码块之后,才能再次对object指向的对象加锁。那么内层synchronized也要加锁,就会产生阻塞,只有等待退出外层synchronized代码块,才能轮到内层加锁,但这就产生死循环了。
理论上会"死锁",程序不会结束,但这个代码真正运行后发现程序打印完后就正常结束了,这是怎么回事呢?
原来是因为synchronized是一个**可重入锁,**可重入锁会判断嵌套的锁的锁对象是否相同,如果相同会放行;还会使用一个计数器(count)计算,套了多少层相同对象的锁,出代码块count--;当count==0时,这个可重入锁就结束了。(Java中这样嵌套可以运行,当C++则会真正死锁)
下面就不涉及可重入知识点,但也是典型的死锁方式。
死锁的第二种典型情况:
java
public class Test12 {
public static Object lock1 = new Object();
public static Object lock2 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(()->{
synchronized(lock1){
try {
Thread.sleep(1000);//t1线程休眠1秒
synchronized(lock2){
System.out.println("t1线程结束!");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread t2 = new Thread(()->{
synchronized(lock2){
try {
Thread.sleep(1000);//t2线程休眠1秒
synchronized(lock1){
System.out.println("t2线程结束!");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
//使用sleep防止某个线程直接执行完,达不到实验效果
t1.start();
t2.start();
}
}
这种A嵌套B,B嵌套A产生的死锁。
5.3.wait和notify
由于线程之间是抢占式执行的,因此线程的先后执行顺序是难以预知的。
但在开发中,程序员更希望线程的执行顺序是可预知。这时使用wait和notify就能控制线程的执行顺序。
5.3.1wait和notify的介绍
wait和notify是Object类的两个方法,都无返回值。
wait()和notify()必须 在synchronized内使用(否则报错),而且调用这两个方法的对象必须和synchronized的锁对象相同,否则报错。看下面的伪代码,就能明白。
java
Thread t1= new Thread(()->{
synchronized(lock1){//对lock1对象加锁
//...
lock1.wait();//wait把lock1对象解锁,然后进行休眠,只有等待lock1.notify()唤醒后才能接着执行后续代码,wait被唤醒后会重新对lock1上锁
}
);
Thread t2= new Thread(()->{
synchronized(lock1){//对lock1对象加锁
//...
lock1.notify();//把相同对象的wait唤醒,如果有多个同对象的wait正在休眠,则随机唤醒一个
}
);可以使用lock1.notifyAll()唤醒所有lock1.wait(),但是全部唤醒后锁对象会重新加锁,其他线程就会阻塞,所以这个方法一般也不会使用的。
5.3.2方法的使用
java
public class Test13 {
public static Object lock1 = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
synchronized(lock1){
System.out.println("执行wait之前");
try {
lock1.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("执行wait之后");
}
});
Thread t2 = new Thread(()->{
synchronized(lock1){
System.out.println("执行notify之前");
lock1.notify();
System.out.println("执行notify之后");
}
});
t1.start();
t2.start();
t1.join();
System.out.println("main线程结束");
}
}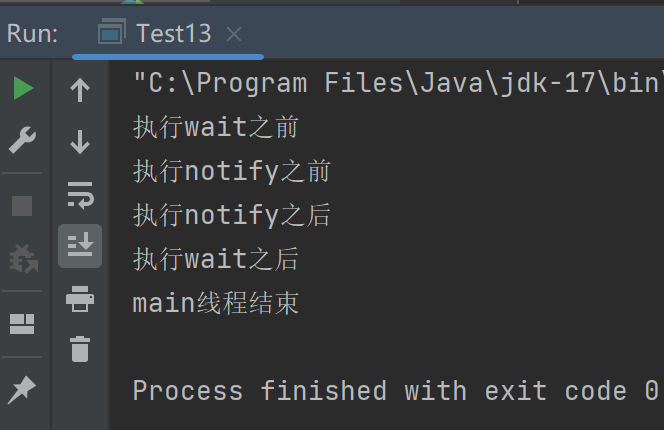
代码说明:当执行到wait,锁对象解锁,wait进入休眠等待被同对象的notify唤醒;wait被唤醒后继续执行后续代码。(wait和notify的作用就是这么简单)
6.总结
本章讲述了线程属性、线程的构造方法、创建线程的5种方式 和 并发编程时(多线程编程)怎么解决或规避线程安全问题。
如果只学了线程这些知识,开发中还是不够的,我们还得了解更多关于线程的知识,下一章就是本章的延续,会讲多线程的四大案例。