
标题:《WorldWarp: Propagating 3D Geometry with Asynchronous Video Diffusion》
项目:https://hyokong.github.io/worldwarp-page/
来源:新加坡国立大学 ;香港理工大学
文章目录
- 摘要
- 预备知识
-
- 1.相机为条件的视频生成
- [2 Diffusion Forcing 与非因果先验](#2 Diffusion Forcing 与非因果先验)
- 二、具有投影(warp)先验的时空扩散
-
- [1. 3D 几何缓存与投影先验 (Warping Prior)](#1. 3D 几何缓存与投影先验 (Warping Prior))
- [2. 潜空间的合成 (Latent-space Composition)](#2. 潜空间的合成 (Latent-space Composition))
- [3. 关键创新:时空变化噪声调度 (Spatio-Temporal Varying Noise)](#3. 关键创新:时空变化噪声调度 (Spatio-Temporal Varying Noise))
- [4. 密集相机控制 (Dense Camera Control)](#4. 密集相机控制 (Dense Camera Control))
- 三、自回归推理框架
- 实验
摘要
生成长距离且几何一致性的视频 面临一个根本性难题:虽然一致性要求严格遵循像素空间中的三维几何结构,但最先进的生成模型在相机条件下的潜在空间中运行效果最佳。这种脱节导致现有方法在处理遮挡区域和复杂摄像机运动轨迹时存在困难。
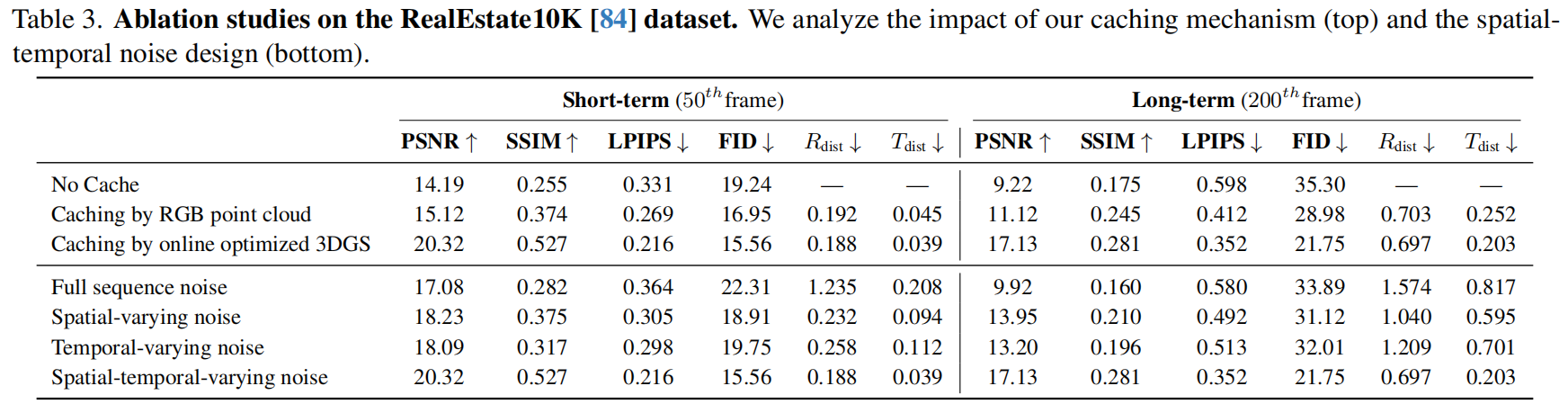
WorldWarp 将三维结构锚点与二维生成精炼器相结合。通过建立几何基准,WorldWarp采用 3DGS 构建在线三维几何缓存 。通过将历史内容显式 warp 为新视角,该缓存作为结构支架,确保每个新帧都遵循先前的几何结构。然而静态投影(static warping)不可避免地会因遮挡产生空洞和伪影。我们采用专为"fill-and-revise"目标设计的时空扩散(ST-Diff)模型 来解决这一问题。我们的核心创新在于时空变化的噪声调度机制:空白区域接收完整噪声以触发生成,而 warped 区域接收局部噪声以实现微调。通过每一步动态更新三维缓存,WorldWarp确保视频片段间的一致性。最终,它通过确保三维逻辑引导结构、扩散逻辑完善纹理,实现了业界领先的保真度。
预备知识
1.相机为条件的视频生成
要有效表征三维相机运动,单纯用原始的相机内参 K K K和外参 E E E往往效果欠佳 ,因为这些参数的数值(如平移向量t)缺乏约束条件,网络难以将其与视觉内容建立关联。更有效的解决方案是将这些抽象参数转化为像素级的密集表征,从而获得更清晰的几何解释。例如,Plücker embeddings 56为每个像素定义了6维射线向量,将抽象矩阵转化为密集张量 P ∈ R n × 6 × h × w P∈R^{n×6×h×w} P∈Rn×6×h×w,这种形式对扩散模型具有更强的信息承载能力。这种基于几何特征的密集先验原则,是实现精细相机控制的关键所在。
2 Diffusion Forcing 与非因果先验
Diffusion Forcing Transformer (DFoT) 57范式将噪声操作重构为渐进式mask,其中视频的每一帧 x t x_t xt都被赋予一个独立的噪声水平 k t ∈ 0 , 1 k_t∈0,1 kt∈0,1 。这与传统模型使用统一噪声水平 k k k处理所有帧形成对比。随后,模型 ϵ ^ θ \hat{ϵ}_θ ϵ^θ 在逐帧噪声预测损失上进行训练:
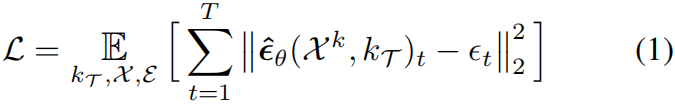
这种逐帧噪声处理方法的关键优势在于,它能够使模型通过非因果注意力进行训练,学会通过条件化任意部分遮蔽的其他帧来去噪单帧。
这种非因果范式 特别适合我们的任务需求。在常规视频生成中,由于未来状态不可预知,必须采用因果架构 。但在相机条件下的新视角合成中,我们可以通过前向投影(feedforward warp)技术,为所有未来帧同时生成强效且几何一致的先验信息。这些投影图像提供了强大的非因果条件信号。这一洞见构成了ST-Diff模型的核心基础,使我们能够摒弃严格的因果约束,采用双向时空扩散策略。
二、具有投影(warp)先验的时空扩散

1. 3D 几何缓存与投影先验 (Warping Prior)
为了确保长视频的几何一致性,系统首先利用 3DGS 维持一个在线的 3D 几何缓存。

- 点云生成 :通过源图像 x s x_s xs 及其深度图 D s D_s Ds,利用相机内参 K s K_s Ks 将像素反投影为 3D RGB 点云 P s \mathcal{P}_s Ps。
- 一对多投影 (One-to-all warping):将点云 P s \mathcal{P}s Ps 渲染到所有目标视角的相机位姿 { E i , K i } \{E_i, K_i\} {Ei,Ki} 中,生成初步的投影先验序列 X s → V \mathcal{X}{s \to \mathcal{V}} Xs→V。
- 有效性掩码 (Validity Mask):生成对应的掩码序列 M \mathcal{M} M,明确标注出哪些像素是成功从源图投影过来的(投影区域 ),哪些是由于遮挡产生的空洞(待填充区域)。
2. 潜空间的合成 (Latent-space Composition)
模型在 VAE 编码器 E ( ⋅ ) \mathcal{E}(\cdot) E(⋅) 的潜空间(Latent Space,而非像素空间)中合成 特征latent:
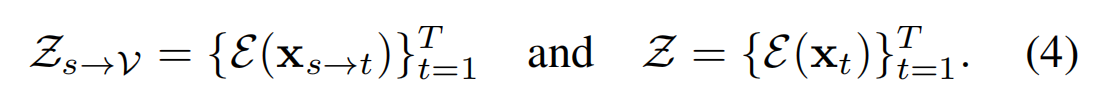
- 特征融合 :创建一个复合潜序列 Z c \mathcal{Z}c Zc。对于每一帧,该序列在有效掩码区域提取变形后的特征 z s → t z{s \to t} zs→t,在空洞区域则由模型进行预测填充。
3. 关键创新:时空变化噪声调度 (Spatio-Temporal Varying Noise)
"遮挡填充"的核心:不对整张图像施加统一的噪声,而是根据掩码 M \mathcal{M} M 进行空间差异化加噪:
- 全噪声(填充区):对于变形后的空白区域(空洞),施加全量噪声以触发全新的内容生成。
- 部分噪声(变形区):对于已有的变形区域,仅施加少量噪声以允许模型进行细节微调和伪影修复。
- 噪声图公式:通过以下公式实现对每个 token 的精确噪声控制:
z c , t = M l a t e n t , t ⊙ z s → t + ( 1 − M l a t e n t , t ) ⊙ z t ( 5 ) z_{c,t} = \mathbf{M}{latent,t} \odot z{s\rightarrow t} + (1 - \mathbf{M}{latent,t}) \odot z{t}(5) zc,t=Mlatent,t⊙zs→t+(1−Mlatent,t)⊙zt(5)
Σ t = M l a t e n t , t ⊙ σ w a r p e d , t + ( 1 − M l a t e n t , t ) ⊙ σ f i l l e d , t ( 6 ) \Sigma_t = \mathbf{M}{latent,t} \odot \sigma{warped,t} + (1 - \mathbf{M}{latent,t}) \odot \sigma{filled,t}(6) Σt=Mlatent,t⊙σwarped,t+(1−Mlatent,t)⊙σfilled,t(6)
随后通过采样噪声序列 E = \mathcal{E}= E={ ϵ t ϵ_t ϵt} t = 1 T ∼ N ( 0 , I ) ^T_{t=1}∼N(0,I) t=1T∼N(0,I),生成最终的含噪输入序列 Z n o i s y , t Z_{noisy,t} Znoisy,t:
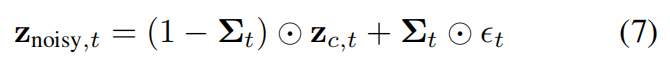
ST-Diff模型则专门针对每个token,生成独特的噪声水平。我们将噪声图序列 Σ V = Σ_V= ΣV={ Σ t Σ_t Σt} t = 1 T ^T_{t=1} t=1T广播到完整的潜在序列维度 ( B × T × H ′ × W ′ ) (B×T×H'×W') (B×T×H′×W′),并将其输入时间嵌入网络,从而为每个对应标记生成独特的时空嵌入。
4. 密集相机控制 (Dense Camera Control)
为实现精细运动轨迹控制,放弃 12 维相机矩阵,使用 Plücker 嵌入:6D 射线向量 :为每个像素定义一个 6D 射线向量,将相机控制转化为 n × 6 × h × w n \times 6 \times h \times w n×6×h×w 的密集张量。这种表示法比原始数值更容易让神经网络理解像素随相机移动的物理规律。
训练目标:预测"速度" v t \mathbf{v}_t vt。
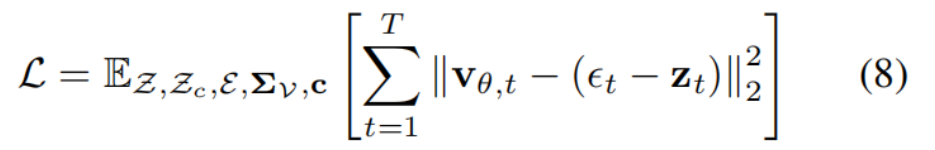
公式 (8) 中,模型 G θ G_\theta Gθ 输出的是 v θ , t \mathbf{v}{\theta, t} vθ,t,这对应于 Flow Matching 或 Velocity Prediction ( v v v-prediction) 的思路。输入 : Z noisy \mathcal{Z}{\text{noisy}} Znoisy:添加了噪声的完整潜空间序列。 Σ V \mathbf{\Sigma}{\mathcal{V}} ΣV:噪声图序列。 c \mathbf{c} c:条件信息(如文本描述、相机姿态等)。预测目标: 模型试图拟合一个"目标速度序列" V target \mathcal{V}{\text{target}} Vtarget
三、自回归推理框架
如图3,推理过程采用自回归生成新视图序列,以循环迭代方式逐帧生成视频。与使用固定半径点云表示的训练过程不同,推理流程采用动态优化的测试时间的3D表示作为显式几何缓存,整合了高保真变形的 3DGS 和语义引导的视觉语言模型(VLM)1。
1.在线3D几何缓存
生成循环的迭代 k k k开始时,利用历史数据( k = 1 k=1 k=1时的初始源视图或前次迭代 k − 1 k−1 k−1生成的视频片段)。
- 1.首先使用3D几何模型(TTT3R)9处理帧,估算其相机位姿并生成初始3D点云。
- 2.利用该点云初始化 3DGS ,并基于历史帧及其估算位姿进行数百步(如200步)优化。
这种在线优化的3DGS模型可作为显式、高保真度的3D表示缓存。 相较于训练阶段使用的固定半径点云,该3DGS能为非空白(投影)区域提供显著更高质量的特征,这对保持几何一致性至关重要。
2.基于分块(chunk)生成
模型需要处理从 3DGS(3D Gaussian Splatting)缓存中渲染出的初步图像序列。这些图像通常存在两类问题:填充(Fill-in: 填补被遮挡的空白区)和修正(Revise: 修复非空白的扭曲/模糊区域,提升图像质量)。
空间可变噪声初始化 (Spatially-varying Noising) :模型根据潜空间掩码(Latent-space Mask) 进行差异化处理:
-
空白区域: 注入纯噪声 ( σ filled \sigma_{\text{filled}} σfilled),以便从头生成内容。
-
投影区域: 注入部分噪声 ( σ start \sigma_{\text{start}} σstart),由强度参数 τ \tau τ 控制,保留原有几何结构的同时进行细节修复。
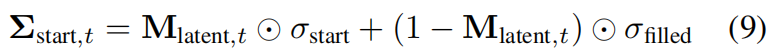
公式 (9): 计算空间可变的噪声图 Σ start , t \mathbf{\Sigma}_{\text{start}, t} Σstart,t,将不同强度的噪声分布在图像的不同位置。
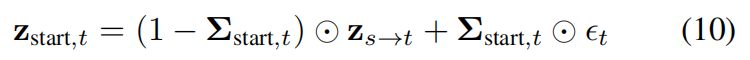
公式 (10): 将噪声图应用到原始潜变量 z s → t \mathbf{z}{s \to t} zs→t 上,生成扩散过程的初始状态 z start , t \mathbf{z}{\text{start}, t} zstart,t。
- 迭代生成过程去噪: 模型 G θ G_\theta Gθ 接收初始噪声序列、文本提示和时间嵌入,将其从起始步长(如 T start T_{\text{start}} Tstart 或 T N T_N TN)去噪至 T 1 T_1 T1。分块循环: 每生成一个"块(Chunk)"的新视角,该块就会作为下一轮迭代的"历史参考",从而确保长视频生成的连续性 。
实验
实验细节
基于Wan2.1-T2V-1.3B 60模型 对WorldWarp进行微调,分辨率设为720x480 ,批量大小为8,使用8个H200 GPU 进行10,000次迭代。采用TTT3R 9作为三维重建基础模型,用于估计相机参数和深度图。
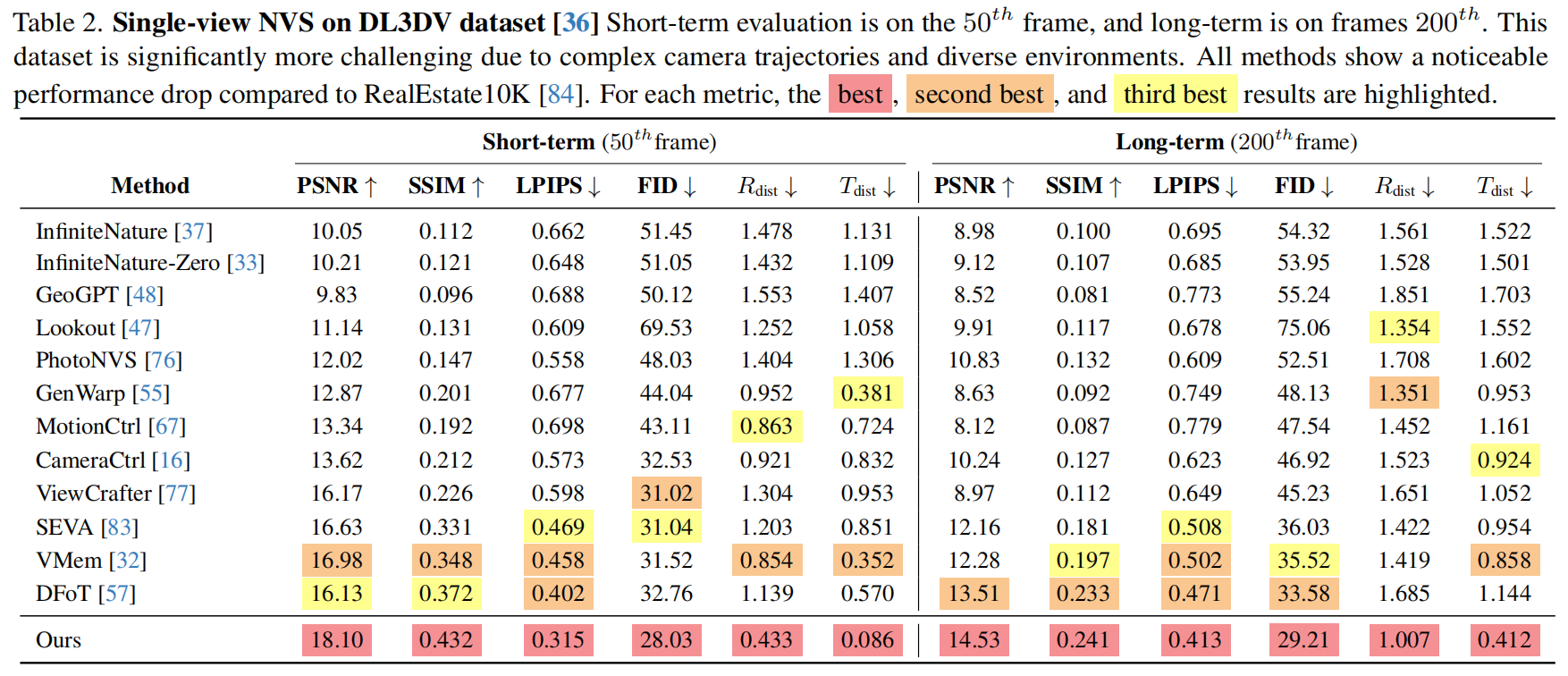
数据集与评估指标。RealEstate10K(Re10K)和DL3DV 数据集。新视图合成质量评估:
- 感知质量:使用Frechet图像距离(FID)测量生成与测试视图之间的分布相似性。
- 细节保留:计算 PSNR 、 SSIM 和 LPIPS 来评估模型在不同视图间保留图像细节的能力。
- 几何对齐:通过真实位姿 ( R g t , t g t ) (R_{gt},t_{gt}) (Rgt,tgt) 评估相机位姿精度。使用DUST3R从生成视图中提取姿态 ( R g e n , t g e n ) (R_{gen},t_{gen}) (Rgen,tgen),随后计算旋转距离 ( R d i s t ) (R_{dist}) (Rdist)和平移距离 ( t d i s t ) (t_{dist}) (tdist):
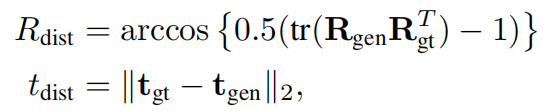
RealEstate10K数据集的比较:
表1:针对短期(第50帧)和长期(第200帧)合成任务,分别从生成质量和相机姿态精度两个维度进行分析。其在所有12项指标上均取得领先水平,超越了所有基准模型。这种优势在具有挑战性的长期合成场景中尤为突出 :当多数方法出现显著质量下降时,我们的模型仍保持最高 PSNR(17.13)和 LPIPS(0.352),超越了 SEVA 、VMem和DFoT等强敌。这种高保真度至关重要,因为位姿估计(使用Master3R)在基准模型的低质量或模糊输出上会失效。因此,我们的模型实现了最低的长期姿态误差(Rdist 0.697,Tdist 0.203)。这清晰揭示了一个显著差异:相机嵌入方法(MotionCtrl、CameraCtrl)存在严重位姿漂移,而三维感知方法(GenWarp、VMem)虽更稳定,但我们的时空噪声扩散策略显著超越两者,证明其在缓解累积相机漂移方面具有卓越能力。定性结果见图4。
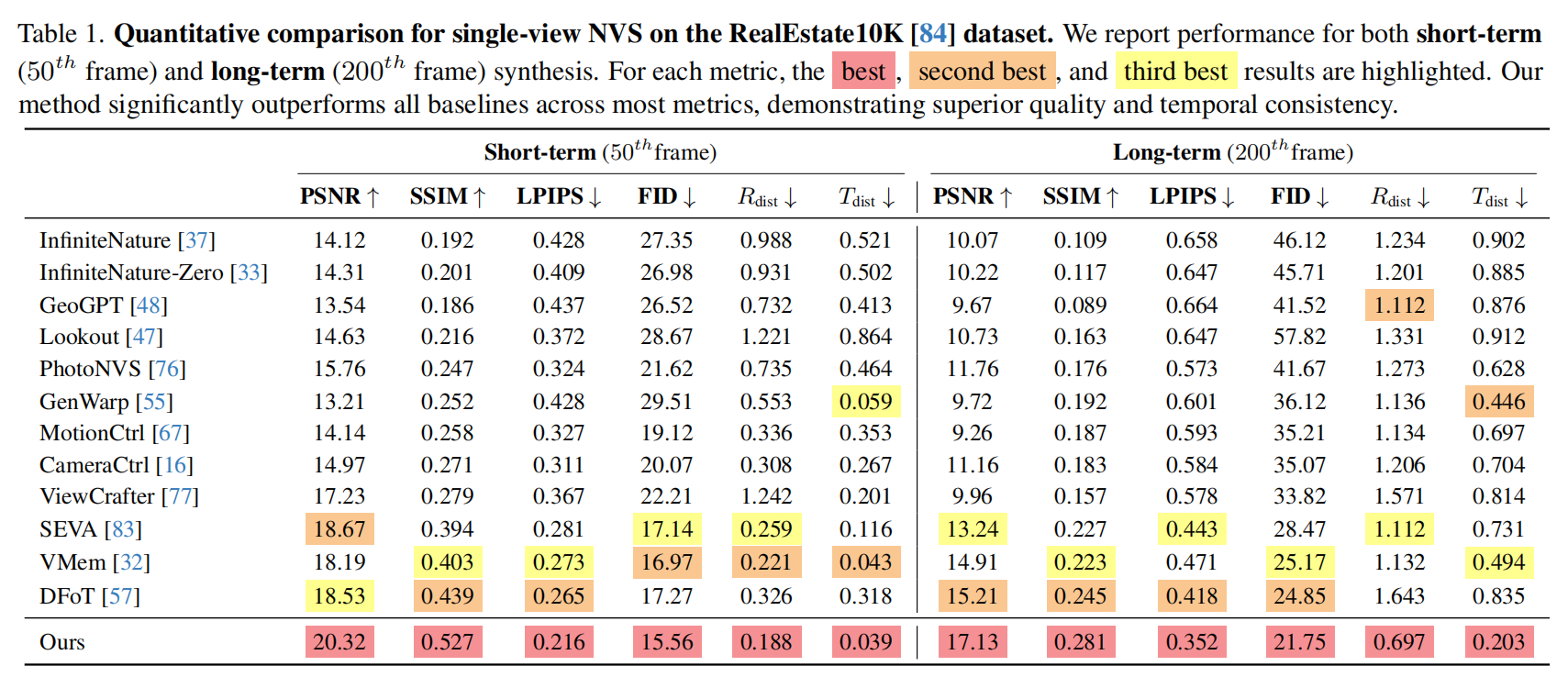

表2:DL3DV数据集性能。在严苛的长期(第200帧)测试场景中,模型 PSNR(14.53)明显优于次优方案DFoT(13.51)和VMem(12.28),这再次证明了保真度对姿态精度的关键作用。在该复杂数据集上,我们的模型保持最高稳定性,实现最低的 R d i s t R_{dist} Rdist(1.007)和 T d i s t T_{dist} Tdist(0.412)。竞争方法的不足在此被放大,如GenWarp(1.351Rdist)和VMem(1.419Rdist)等三维感知方法稳定性下降。这证明我们的时空噪声扩散策略在保持三维一致性、缓解复杂长距离轨迹上的严重相机漂移方面更为有效。可视化结果见图4及补充材料。
#pic_center =80%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E