前言: 本文适合深度学习入门,手把手教你自动遍历图片生成 train.txt/test.txt 标注文件 + 自定义 CNN 分类模型 + 完整训练测试流程,无 GPU、轻薄本 CPU 也能流畅运行。
一、项目介绍
本项目实现一个简易食物图像分类系统,核心功能:
- 自动遍历数据集目录,按文件夹名生成标签,生成
train.txt和test.txt标注文件 - 自定义
Dataset类加载图片与标签 - 搭建轻量化 CNN 卷积神经网络
- 完整训练 + 测试流程,CPU 环境可直接运行
项目结构
food_dataset/
├─ train/
│ ├─ 薯条/
│ ├─ 苹果/
│ └─ ...(其他类别文件夹)
├─ test/
│ ├─ 薯条/
│ ├─ 苹果/
│ └─ ...
└─ 食物识别pro.py # 主代码二、环境配置
Python 3.9
torch
torchvision
Pillow
numpy安装命令:
pip install torch torchvision pillow numpy三、核心代码实现(逐行详解)
1. 自动生成 train.txt/test.txt 标注文件
核心逻辑:遍历数据集目录,以「类别文件夹名」作为标签名,文件夹索引作为数字标签,自动写入 txt 文件,无需手动标注。
import os
def train_test_file(root, dir_name):
dirs = [] # 初始化类别列表,避免"赋值前引用"报错
# 拼接标注文件路径,指定utf-8编码防止中文乱码
txt_path = os.path.join(root, dir_name + '.txt')
with open(txt_path, 'w', encoding='utf-8') as file_txt:
path = os.path.join(root, dir_name) # 拼接train/test目录路径
# os.walk遍历目录:roots=当前路径, directories=子文件夹, files=文件
for roots, directories, files in os.walk(path):
if len(directories) != 0:
dirs = directories # 保存所有类别文件夹名(如薯条、苹果)
else:
# 拆分路径,获取当前图片所属类别文件夹名
now_dir = roots.split(os.sep) # os.sep适配Windows(\)和Linux(/)
current_class = now_dir[-1]
# 只处理图片文件,过滤缓存/隐藏文件
for file in files:
if file.lower().endswith(('.jpg', '.jpeg', '.png')):
path_1 = os.path.join(roots, file) # 图片绝对路径
if current_class in dirs:
# 写入格式:图片路径 + 空格 + 数字标签(类别索引)
file_txt.write(f"{path_1} {dirs.index(current_class)}\n")
# 生成标注(替换为你的数据集绝对路径)
root = r'D:\兰智\dlproject\cnn\food_dataset'
train_test_file(root, 'train') # 生成train.txt
train_test_file(root, 'test') # 生成test.txt代码关键说明:
os.walk():递归遍历目录,是批量处理文件的核心函数os.sep:替代硬编码的\\,解决 Windows/Linux 路径兼容问题encoding='utf-8':必须指定,否则中文路径 / 文件名会乱码dirs.index(current_class):将类别名转为数字标签(如薯条→0、苹果→1)
生成的 train.txt 示例:
D:\兰智\dlproject\cnn\food_dataset\train\薯条\img_薯条_35.jpeg 0
D:\兰智\dlproject\cnn\food_dataset\train\苹果\img_苹果_12.jpg 12. 自定义 Dataset 加载数据
核心逻辑 :继承 PyTorch 的Dataset抽象类,实现__init__/__len__/__getitem__三个核心方法,完成「标注文件解析→图片读取→标签转换」全流程。
from torch.utils.data import Dataset
from PIL import Image
import torch
class food_dataset(Dataset):
def __init__(self, file_path, transform=None):
"""初始化:解析标注文件,保存图片路径和标签"""
self.imgs = [] # 存储所有图片路径
self.labels = [] # 存储所有标签(字符串格式)
self.transform = transform # 图像预处理函数
# 读取标注文件,指定utf-8编码
with open(file_path, encoding='utf-8') as f:
# 按行拆分,过滤空行
samples = [x.strip().split() for x in f if x.strip()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self):
"""返回数据集总长度,支持len(dataset)调用"""
return len(self.imgs)
def __getitem__(self, idx):
"""核心方法:按索引返回单张图片+标签,支持dataset[idx]调用"""
try:
# 读取图片并统一转为RGB(避免灰度图通道数错误)
image = Image.open(self.imgs[idx]).convert('RGB')
except FileNotFoundError:
# 容错处理:图片不存在时返回空图像,避免程序崩溃
print(f"警告:图片 {self.imgs[idx]} 不存在,返回空图像")
image = Image.new('RGB', (256, 256))
# 应用图像预处理(如Resize、ToTensor)
if self.transform:
image = self.transform(image)
# 标签转换:字符串→整数→Tensor(PyTorch训练必需)
label = torch.tensor(int(self.labels[idx]), dtype=torch.int64)
return image, label代码关键说明:
Dataset是 PyTorch 数据加载的基础类,必须实现三个核心方法convert('RGB'):统一图片通道数(避免灰度图只有 1 通道,和 RGB 图 3 通道冲突)torch.tensor(..., dtype=torch.int64):标签必须转为 64 位整数 Tensor,否则 CrossEntropyLoss 会报错- 异常捕获:处理图片缺失场景,提升代码健壮性
3. 图像预处理(CPU 友好版)
核心逻辑:对图像进行「尺寸归一化→Tensor 转换」,统一输入格式,适配 CNN 模型输入要求。
from torchvision import transforms
data_transforms = {
'train': transforms.Compose([
transforms.Resize([256, 256]), # 缩放到256×256(统一输入尺寸)
transforms.ToTensor(), # 转换为Tensor:HWC→CHW,值归一化到0-1
]),
'valid': transforms.Compose([
transforms.Resize([256, 256]), # 测试集和训练集保持一致
transforms.ToTensor(),
])
}代码关键说明:
transforms.Compose():将多个预处理操作组合成流水线ToTensor():PIL 图片(HWC,0-255)→ Tensor(CHW,0-1),是 PyTorch 必需步骤- CPU 版简化:暂不加入随机翻转 / 旋转等增强(可后续优化时添加)
4. 搭建轻量化 CNN 模型
核心逻辑:采用「卷积 + ReLU + 池化」的经典组合,逐步提取图像特征,最后通过全连接层完成分类。
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 卷积层1:输入3通道(RGB)→ 16通道特征图,5×5卷积核
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 5, 1, 2), # in_channels=3, out_channels=16, kernel_size=5, stride=1, padding=2
nn.ReLU(), # 激活函数,引入非线性
nn.MaxPool2d(2), # 池化:2×2窗口,尺寸缩小一半(256→128)
)
# 卷积层2:16通道→32通道,两次卷积+一次池化
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2), # 尺寸:128→64
)
# 卷积层3:32通道→128通道,无池化(保持64×64尺寸)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 128, 5, 1, 2),
nn.ReLU(),
)
# 全连接层:展平特征→分类输出(20类可根据实际数据集修改)
self.out = nn.Linear(128*64*64, 20)
def forward(self, x):
"""前向传播:定义数据流经网络的路径"""
x = self.conv1(x) # 输出:(batch, 16, 128, 128)
x = self.conv2(x) # 输出:(batch, 32, 64, 64)
x = self.conv3(x) # 输出:(batch, 128, 64, 64)
x = x.view(x.size(0), -1) # 展平:(batch, 128*64*64)
return self.out(x) # 输出:(batch, 20) → 20类的预测概率代码关键说明:
nn.Sequential():将多个层组合成模块,简化代码Conv2d参数:padding=2保证卷积后尺寸不变(padding=(kernel_size-1)/2)MaxPool2d(2):池化层缩小特征图尺寸,减少计算量x.view(x.size(0), -1):展平四维特征图为二维,适配全连接层输入(-1自动计算维度)- 输出维度:
128*64*64是卷积层 3 的输出特征数,需和全连接层输入一致
5. 训练函数 + 测试函数
5.1 训练函数
def trainda(dataloader, model, loss_fn, optimizer):
model.train() # 切换为训练模式(启用Dropout/BatchNorm等训练逻辑)
batch_size_num = 1
for X, y in dataloader: # 遍历DataLoader,每次取一个batch
# 将数据移到指定设备(CPU/GPU)
X, y = X.to(device), y.to(device)
# 前向传播:模型预测
pred = model(X) # 等价于model.forward(X),简化写法
# 计算损失(预测值与真实标签的差距)
loss = loss_fn(pred, y)
# 反向传播+参数更新(核心三步)
optimizer.zero_grad() # 梯度清零(避免累积上一轮梯度)
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
# 打印训练进度
loss_val = loss.item() # Tensor→Python数值
if batch_size_num % 2 == 0: # 每2个batch打印一次,减少输出
print(f"loss: {loss_val:>7f} [batch:{batch_size_num}]")
batch_size_num += 15.2 测试函数
def testda(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集总样本数
num_batches = len(dataloader) # 测试集总批次数
model.eval() # 切换为测试模式(关闭Dropout/BatchNorm)
test_loss, correct = 0, 0
# 关闭梯度计算(测试无需反向传播,节省内存+加速)
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
# 累加损失和正确数
test_loss += loss_fn(pred, y).item()
# pred.argmax(1):取每行最大值索引(预测类别),与真实标签对比
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# 计算平均损失和准确率
test_loss /= num_batches
correct /= size
print(f"测试结果:\n 准确率: {(100*correct):>0.1f}%, 平均损失: {test_loss:>8f}")代码关键说明:
model.train()/model.eval():训练 / 测试模式切换,必加(否则 Dropout/BatchNorm 会影响结果)optimizer.zero_grad():梯度清零是 PyTorch 的坑点,漏加会导致梯度累积,训练崩溃torch.no_grad():测试时关闭梯度,减少内存占用,提升速度pred.argmax(1):对预测结果取最大值索引,得到最终分类结果(dim=1 表示按行取)
6. 主训练流程(CPU 专用版)
# 设备设置:强制使用CPU(轻薄本无GPU)
device = torch.device("cpu")
model = CNN().to(device) # 模型移到CPU
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失(多分类任务标配)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 加载数据集
from torch.utils.data import DataLoader
training_data = food_dataset(os.path.join(root,'train.txt'), data_transforms['train'])
test_data = food_dataset(os.path.join(root,'test.txt'), data_transforms['valid'])
# 数据加载器(CPU适配:减小batch_size+关闭多线程)
train_dataloader = DataLoader(training_data, batch_size=8, shuffle=True, num_workers=0)
test_dataloader = DataLoader(test_data, batch_size=8, shuffle=False, num_workers=0)
# 开始训练
epochs = 10 # 训练轮数(可根据效果调整)
print("\n开始训练:")
for t in range(epochs):
print(f"\nEpoch {t+1}/{epochs}\n-------------------------------")
trainda(train_dataloader, model, loss_fn, optimizer) # 训练
testda(test_dataloader, model, loss_fn) # 每轮训练后测试
print("\n训练完成!")
testda(test_dataloader, model, loss_fn) # 最终测试代码关键说明:
device = torch.device("cpu"):强制指定 CPU,避免 CUDA 相关报错batch_size=8:CPU 内存有限,64/32 会内存溢出,8 是轻薄本友好值num_workers=0:CPU 下关闭多线程加载(多线程易报错)shuffle=True:训练集打乱数据,提升泛化能力;测试集无需打乱lr=0.001:Adam 优化器默认学习率,新手无需调整
四、运行效果展示
1. 标注文件生成效果
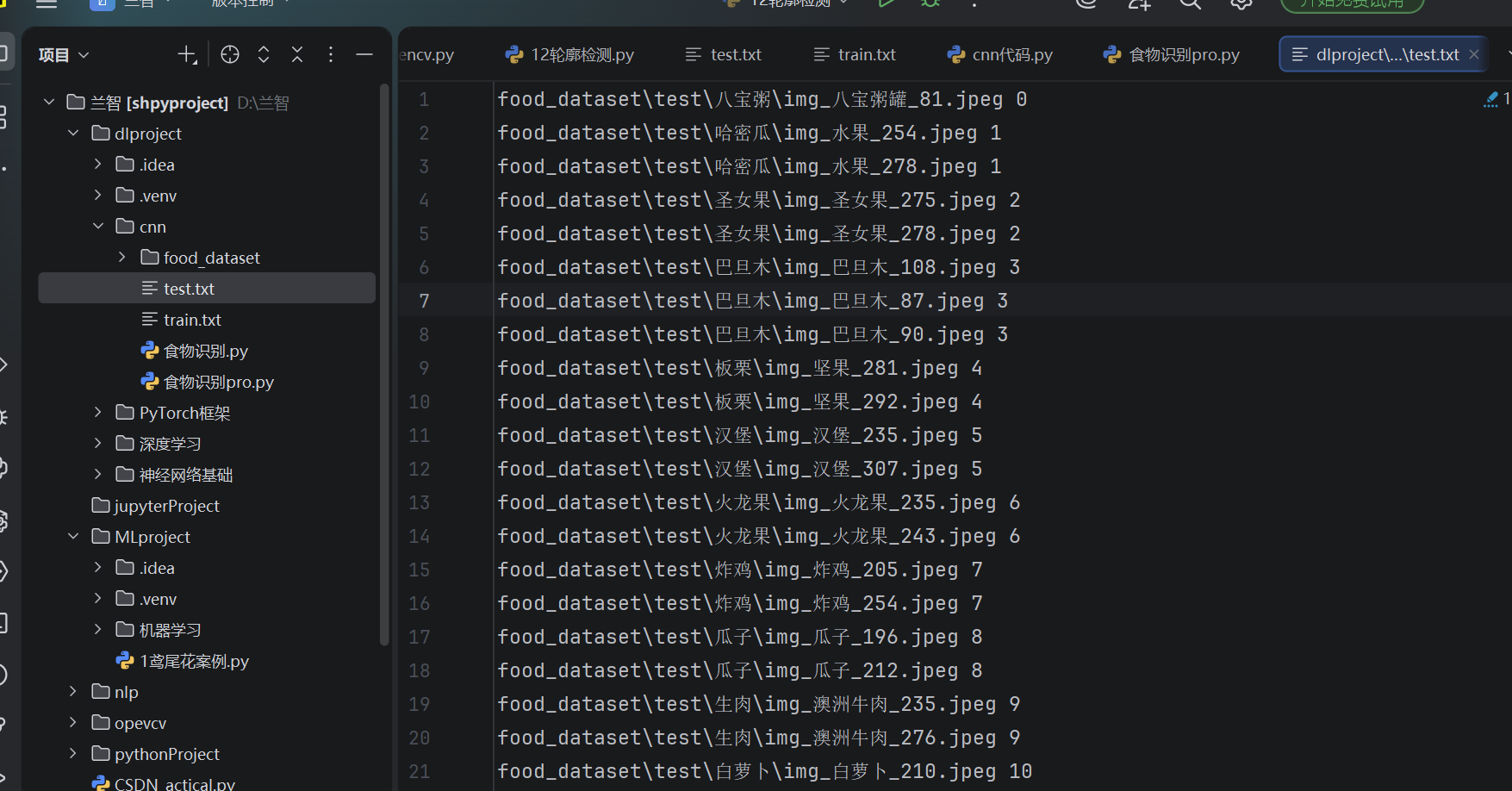
自动生成的 train.txt/test.txt,每行包含「图片绝对路径 + 数字标签」
2. 训练过程输出
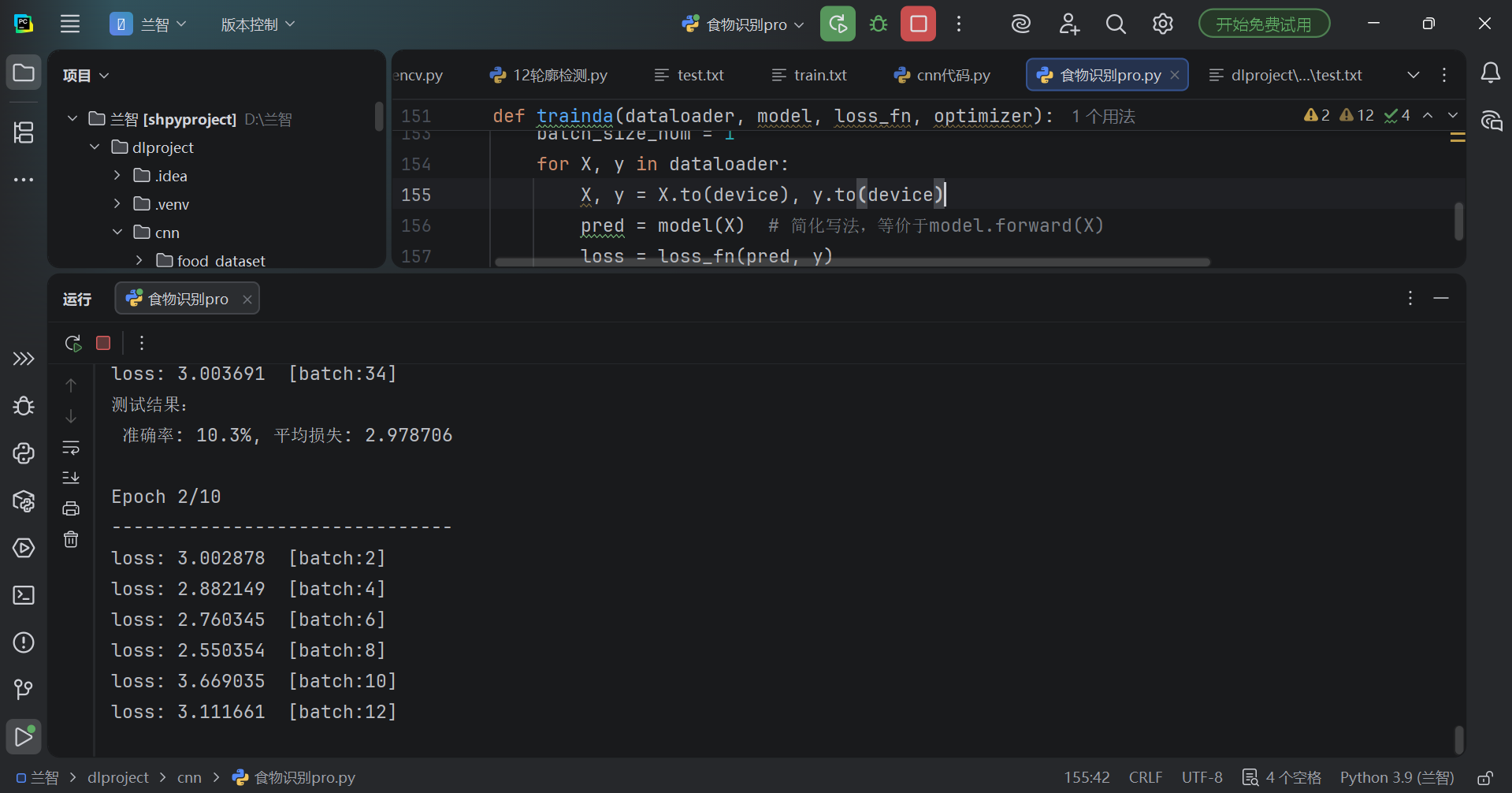
3. 模型结构输出
模型结构:
CNN(
(conv1): Sequential(
(0): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv3): Sequential(
(0): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
)
(out): Linear(in_features=524288, out_features=20, bias=True)
)五、常见问题解决
| 报错信息 | 原因 | 解决方案 |
|---|---|---|
| KeyError: 'train' | data_transforms 键名与调用不一致 | 确保键名是 'train',而非 'trainda' |
| fixture 'dataloader' not found | 运行方式错误 | PyCharm 切换为「普通 Python」运行,不要用 pytest |
| 图片路径不存在 | 相对路径错误 | 使用绝对路径(如 r'D:\xxx\food_dataset') |
| 内存不足 | batch_size 过大 | 改为 batch_size=4/2 |
| 标签类型错误 | 标签未转为 int64 | 使用 torch.tensor (..., dtype=torch.int64) |
六、模型优化思路(提升准确率)
-
数据增强 :在训练集预处理中加入随机变换,增加数据多样性
data_transforms['train'] = transforms.Compose([ transforms.Resize([256, 256]), transforms.RandomHorizontalFlip(), # 随机水平翻转 transforms.RandomRotation(10), # 随机旋转±10度 transforms.ToTensor(), ]) -
正则化防过拟合 :在卷积层后加入 Dropout 层
nn.Dropout(0.2), # 随机丢弃20%的神经元 -
学习率调整 :使用学习率衰减,后期慢更精细
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 训练循环中加入 scheduler.step() -
增加训练轮数:epochs 改为 30/50,观察准确率变化
-
调整网络结构:增加卷积层 / 调整通道数(如 64→128)
七、总结
本文从「标注生成→数据加载→模型搭建→训练测试」全流程详解了食物识别项目,核心亮点:
- ✅ 自动化标注:无需手动写 txt,代码一键生成
- ✅ 新手友好:每行代码都有详细注释,关键逻辑拆解
- ✅ CPU 兼容:适配轻薄本,无 GPU 也能运行
- ✅ 健壮性强:加入异常捕获、路径兼容等细节处理
项目适合深度学习入门、课程设计、毕业设计,代码可直接复用,只需替换数据集路径和类别数即可适配其他分类任务。