您好,我是@iFeng的小屋,一枚4年程序猿。
一、爬取目标
很多做市场调研或出行规划的朋友,都想深入了解某家酒店的真实口碑。但携程评论页翻来翻去很麻烦,而且酒店的回复内容往往藏在折叠层里,手工复制太累。
所以,我写了这个携程酒店评论爬虫,它能:
-
根据酒店ID,一键抓取指定页数的评论
-
获取每条评论的正文、评分、时间、用户名、点赞数、房型、出行类型
-
自动提取酒店的回复内容,包括回复时间
-
使用多线程(可调并发数)加速,同时控制请求频率
-
所有数据直接保存为Excel,规整好用
目前是源码格式,还没有封装成软件,如果想要软件的我后续开发一个软件版本的。
二、展示爬取结果
话不多说,先看成果。爬取结果包含以下字段:
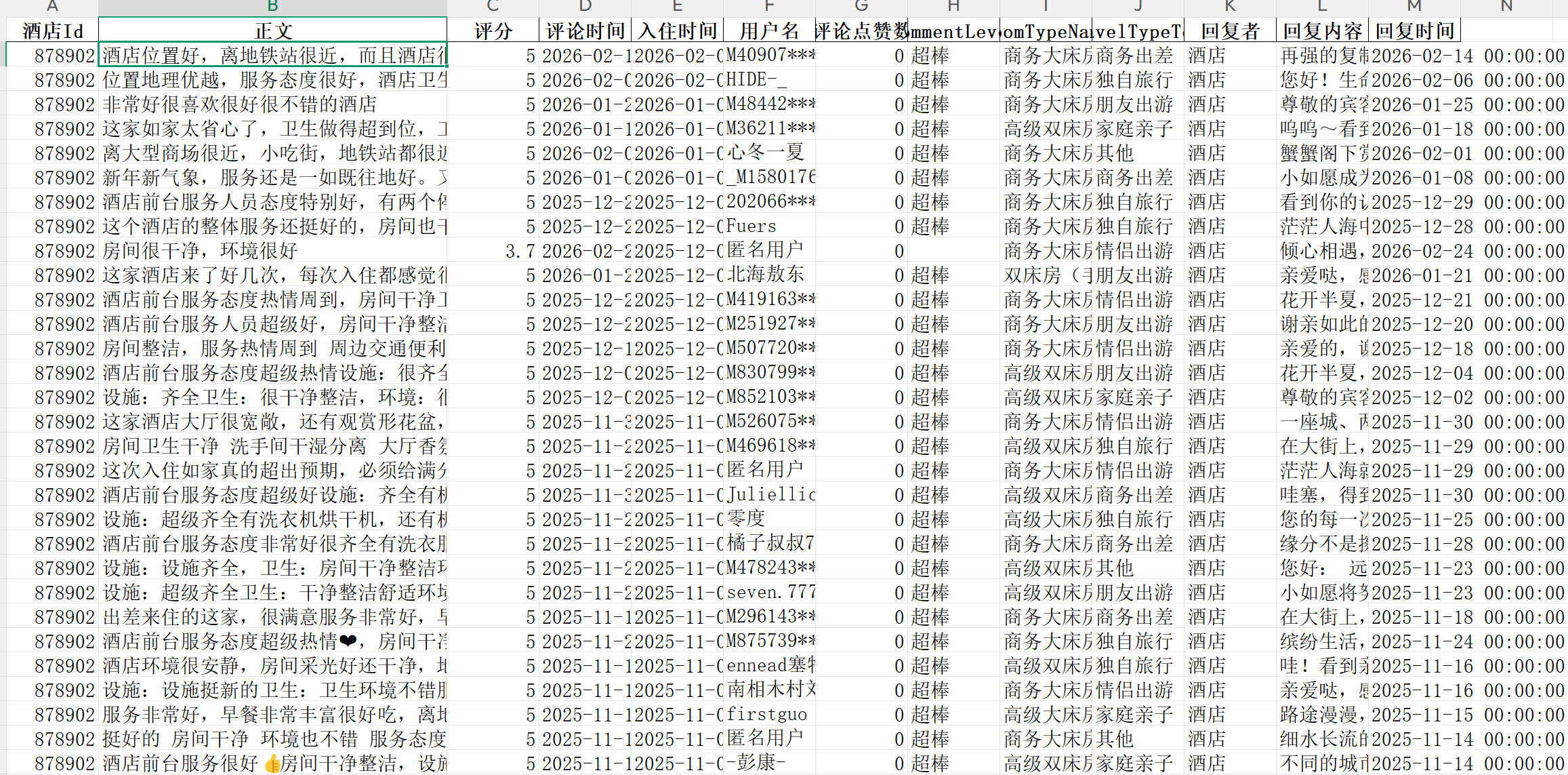
字段:酒店id,正文,评分,评论时间,入住时间,用户名,评论点赞量,评论等级,房间类型名称,旅游类型,回复者,回复内容,回复时间。
字段齐全,可作为后续研究分析使用。
三、原理讲解
-
打开携程酒店详情页,按F12进入开发者工具,翻看评论页,找到评论数据的接口。发现是
restapi/soa2/33278/getHotelCommentList,POST请求。 -
接口请求体是JSON格式,包含
hotelId(酒店ID)、pageIndex(页码)、pageSize(每页条数)、orderBy(排序方式)等参数。 -
用
requests模拟这个POST请求,带上必要的Headers,就能拿到JSON数据。 -
解析JSON中的
commentList,提取每条评论的字段。特别注意feedbackList里藏着酒店的回复内容。 -
最后用
pandas把数据存成Excel。
四、爬虫代码讲解
导入库:
python
import requests
import json
import time
import pandas as pd
from concurrent.futures import ThreadPoolExecutor3.1 核心思路与配置
需要两个关键参数:酒店ID 和 要爬的页数 。酒店ID可以从URL中获取,比如 https://hotels.ctrip.com/hotels/878902.html,878902 就是酒店ID。
为了方便使用,我直接把酒店ID和页数写在脚本末尾,你也可以改成input输入。
python运行
3.2 关键步骤:构造请求与解析数据
这是爬虫的核心,POST请求的构造必须准确:
python
def fetchComments(hotelId, pageIndex):
url = "https://m.ctrip.com/restapi/soa2/33278/getHotelCommentList"
headers = {
'Content-type': 'application/json',
'Origin': 'https://hotels.ctrip.com',
'Referer': 'https://hotels.ctrip.com',
'user-agent': 'Mozilla/5.0...'
}
...
r = requests.post(url, json=formData, headers=headers)
data = r.json()
comment_list = data.get("data", {}).get("commentList", [])
# ... 解析每条评论3.3 关键步骤:多线程抓取
虽然单线程也能跑,但多线程能让速度翻倍(但要控制并发数,别把网站搞崩了):
python
def fetchHotelComments(hotelId, numPages=10):
all_comments = []
def fetch_page(pageIndex):
return fetchComments(hotelId, pageIndex)
with ThreadPoolExecutor(max_workers=3) as executor: # 最多3个线程
results = executor.map(fetch_page, range(1, numPages + 1))
for page_comments in results:
all_comments.extend(page_comments)
time.sleep(1) # 每页间隔1秒,太猛容易被封
return all_comments四、如何运行?
-
安装依赖 :
pip install requests pandas openpyxl -
修改参数 :在
if __name__ == "__main__":下面,把hotel_id换成你想爬的酒店ID,把total_pages改成你要的页数(每页10条)。 -
运行脚本:直接执行,等待结果。
-
查看结果 :当前目录下会生成
comments_酒店ID.xlsx文件。
五、说明
-
酒店ID获取 :在携程酒店详情页的URL里,比如
https://hotels.ctrip.com/hotels/878902.html,数字部分就是酒店ID。 -
翻页逻辑:代码目前只爬指定页数,如果你需要爬全部评论,可以先通过第一页的响应获取总条数,再计算总页数,然后循环。为简化示例,这里只演示指定页数。
-
请求频率 :代码中已经加入了
time.sleep,请勿修改太快,以免被网站封IP。 -
完整源码 :上述代码为核心模块,完整可运行的源码包含更详细的异常处理和注释,已打包整理。
需要本文完整可运行Python源码的小伙伴,我都放在了与此号同名的公主号里,大家自行获取。
持续分享Python干货中!更多爬虫源码干货,请前往主页查看~