摘要 :本文在 Transformer 整体架构、Encoder、以及带掩码自注意力与交叉注意力的基础上,对 Decoder-only 架构进行系统总结。内容包括:Decoder-only 在整体中的位置与自回归目标、从输入到 Decoder 的数据流(Tokenization、Embedding、位置编码)、Decoder 的每一层结构(带掩码的多头自注意力、前馈网络、残差连接与层归一化)及其矩阵维度与矩阵运算、输出层(线性层与 Softmax)、以及训练与推理流程的对比。旨在帮助读者建立对 GPT/LLaMA 等大语言模型骨干架构的完整、可计算的理解。
关键词:Decoder-only;自回归;掩码自注意力;Teacher Forcing;前馈网络;残差连接;层归一化;大语言模型;GPT
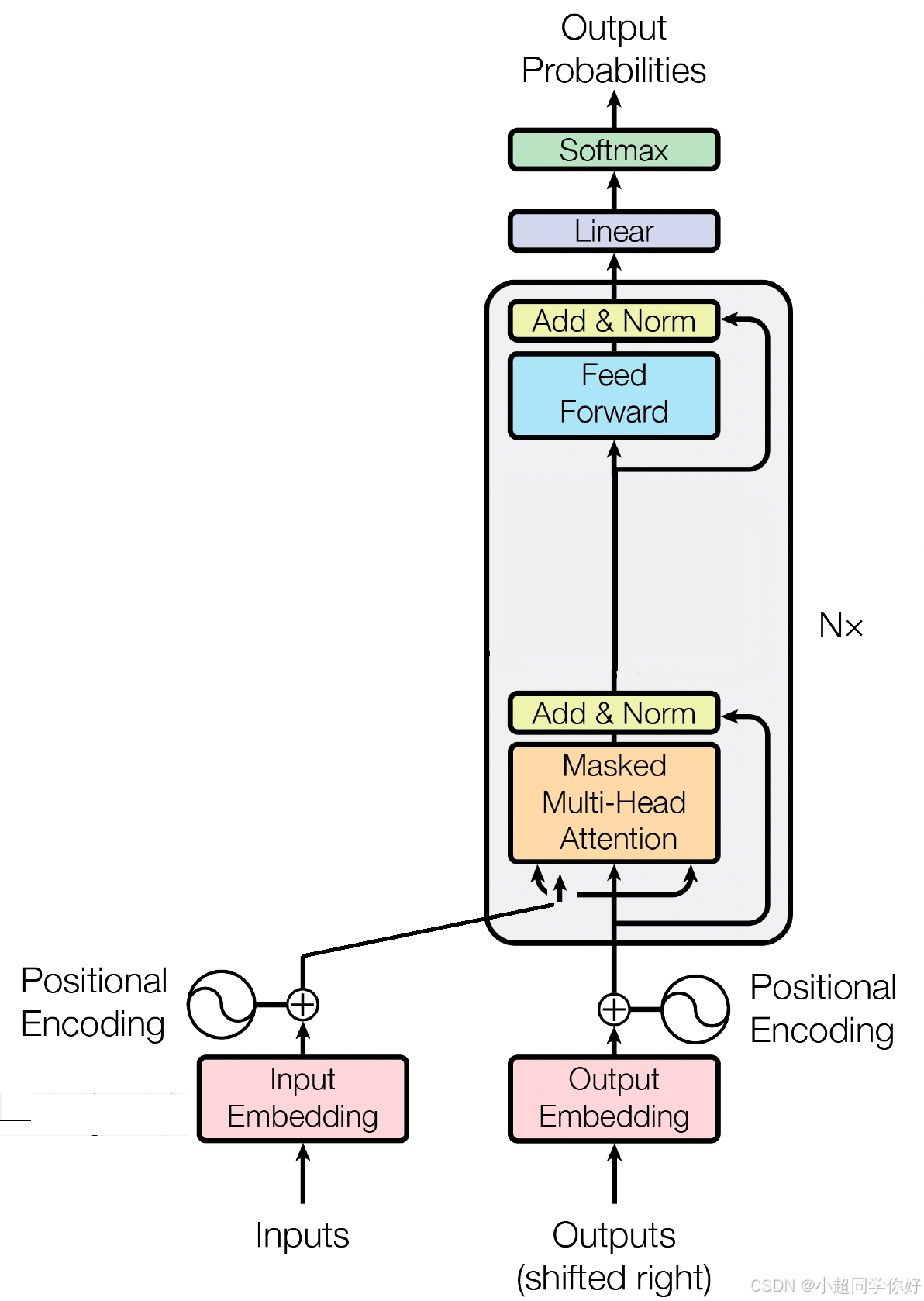
💡 理解要点 :Decoder-only 是「只保留解码器、去掉编码器与编码器-解码器注意力」的 Transformer 变体,专用于生成式任务:根据已见 token 自回归地预测下一个 token,是 GPT、LLaMA、Qwen 等大语言模型的骨干架构。
1. 概述:Decoder-only 在整体中的位置
在 Transformer 3. 整体架构 与 Transformer 9. Decoder-Encoder 层多头自注意力机制 中我们看到,完整 Transformer 的 Decoder 包含三块:带掩码的多头自注意力 、编码器-解码器注意力(交叉注意力) 、前馈网络 。Decoder-only 即去掉编码器与交叉注意力,只保留「带掩码的多头自注意力 + 前馈网络」,并配合残差连接与 Layer Normalization。因此从结构上看,Decoder-only 的每一层更像「只有自注意力的 Encoder」,但必须保留掩码 ,以保证在生成第 i i i 个 token 时只能看到位置 0 ∼ i − 1 0 \sim i-1 0∼i−1,与自回归生成一致。
自回归目标可概括为两点:
- 用序列前半段预测后半段:输入为已生成的 token 序列(或 prompt),输出为对「下一个 token」的预测;重复「将预测出的 token 拼回输入、再预测下一个」即得到整段生成。
- 训练与推理的数据差异 :训练时用 Teacher Forcing ,即用真实标签(下一个 token)作为下一步的输入,便于并行计算;推理时用上一步的预测结果作为下一步的输入,只能逐步、循环生成。
在生成式任务中,通常不再区分「特征」与「标签」两种数据:我们只有一段要续写或补全的序列;在训练里,当前步的「标签」在下一时间步就变成「输入」。除主序列外,也可通过图上所示的 inputs 线路向 Decoder 注入条件或背景知识(如对话历史、检索片段),用于条件生成。
🔍 实际例子 :若序列长度为 L = 1300 L=1300 L=1300、模型维度 d model = 12288 d_{\text{model}}=12288 dmodel=12288,则 Decoder 的输入与每层输出均为 L × d model = 1300 × 12288 L \times d_{\text{model}} = 1300 \times 12288 L×dmodel=1300×12288 的矩阵;最后一层取最后一个位置的向量,经线性层与 Softmax 得到词表上的概率分布,再取 argmax 或采样得到下一个 token。
下文先说明数据如何进入 Decoder、再逐层给出矩阵维度与运算,最后归纳训练与推理流程。
2. 从输入到 Decoder:数据如何进入
Decoder 不直接接收原始文本,而是接收已经 Tokenization、Embedding、位置编码 后的表示。这一过程与 Encoder 完全一致,在 Transformer 3. 整体架构 与 Transformer 4. Embedding层与位置编码技术 中有更详细的展开;下面按 Decoder 的输入流顺序,对每一步做简要说明并给出矩阵形状与维度,便于与后文 Decoder 层的计算衔接。
2.1 Tokenization:从文本到 Token 序列
什么是 Tokenization?
Tokenization 是将一段文字转换为一组 Token(词元) 的过程,就像把一篇文章拆成一块块「积木」。每个 Token 在模型内部对应一个整数 ID,模型实际处理的是这串 ID,再通过查表得到向量。
Token 与 ID 长什么样?
以「我喜欢吃苹果」为例,在不同分词策略下可能变成:
| 文本 | Token 序列(直观) | 对应的 Token ID(示例) |
|---|---|---|
| 我喜欢吃苹果 | "我", "喜欢", "吃", "苹果" | 234, 5678, 890, 1234 |
| Hello world | "Hello", " world" 或 "Hel", "lo", " world" | 15496, 995 或 9906, 4435, 995 |
- 中文:常见做法是按词或按字切分,一个汉字可能单独成一个 token,也可能与相邻字组成一个 token(如「苹果」)。
- 英文 :通常按子词(BPE、WordPiece)切分,例如 "Transformer" 可能变成
["Transform", "er"]两个 token。
也就是说:Tokenization 之后,文本变成「一串整数 ID」 ,长度记为 L L L。同一段话在不同模型(GPT-3、Llama、Qwen)里 ID 序列可能不同,因为词表与分词算法不同。
词汇表规模(Decoder-only 常见模型):
- GPT-3:50,257 个 Token
- GPT-4:100,256 个 Token
- Llama-3:128,000 个 Token
💡 理解要点 :Decoder 的「输入序列」在数值上就是这串长度为 L L L 的 Token ID;后续 Embedding 层用这些 ID 去查表,得到 L L L 个向量,再拼成矩阵。
2.2 Embedding:从 Token ID 到向量
数学本质 :Embedding 层是一张可学习的查找表 。词表大小为 V V V,模型维度为 d model d_{\text{model}} dmodel,则 Embedding 矩阵为 E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel。对每个 Token ID w i w_i wi( 0 ≤ w i < V 0 \leq w_i < V 0≤wi<V),有:
Embedding ( w i ) = E w i ∈ R d model . \text{Embedding}(w_i) = Ew_i \in \mathbb{R}^{d_{\text{model}}}. Embedding(wi)=Ewi∈Rdmodel.
矩阵形状:
- 查表矩阵 : E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel(词表大小 × 模型维度)。
- 整段序列 : L L L 个 token 各自查表后,按位置堆叠成矩阵 L × d model L \times d_{\text{model}} L×dmodel。
与 one-hot 的对比:one-hot 将每个 token 编成 V V V 维、仅一维为 1 的稀疏向量;Embedding 则用固定维度 d model d_{\text{model}} dmodel(如 512、12288)的稠密向量,且该矩阵随训练更新,语义相近的 token 在向量空间中距离更近,便于模型学习上下文与生成关系。
🔍 实际例子 :若序列长度 L = 1300 L=1300 L=1300、 d model = 12288 d_{\text{model}}=12288 dmodel=12288,则 Embedding 输出为 1300×12288 的矩阵,每一行是一个 token 的 12288 维向量。
2.3 位置编码:补足顺序信息
为什么需要位置信息?
注意力机制是并行计算的,本身不显式编码「谁在前、谁在后」。同样的字在不同位置含义可能完全不同,例如「猫咬了狗」与「狗咬了猫」。因此需要为每个位置注入位置信息。
技术实现 :为每个位置 p o s pos pos( 0 ≤ p o s < L 0 \leq pos < L 0≤pos<L)生成一个 d model d_{\text{model}} dmodel 维的向量 P E ( p o s ) \mathrm{PE}(pos) PE(pos),加到该位置的 Embedding 向量上:
I n p u t i = E m b e d d i n g i + P E ( i ) , i = 0 , 1 , ... , L − 1. \mathrm{Input}i = \mathrm{Embedding}i + \mathrm{PE}(i), \quad i = 0, 1, \ldots, L-1. Inputi=Embeddingi+PE(i),i=0,1,...,L−1.
常见做法包括:正弦/余弦位置编码 (原版 Transformer,见 Transformer 4. Embedding层与位置编码技术)或可学习位置编码 (如 GPT 系列)。无论哪种,位置编码与 Embedding 逐元素相加后,矩阵形状不变 ,仍为 L × d model L \times d_{\text{model}} L×dmodel。
💡 理解要点 :进入 Decoder 的输入 = 词嵌入 + 位置编码,既带语义又带顺序,是 Decoder 所有后续层(掩码自注意力、前馈网络)的计算基础。
2.4 小结:进入 Decoder 第一层的矩阵
综合上述三步:
- Tokenization :文本 → 长度为 L L L 的 Token ID 序列。
- Embedding : L L L 个 ID 查表 → L × d model L \times d_{\text{model}} L×dmodel 矩阵。
- 位置编码 :与 Embedding 相加,形状不变 → 仍为 L × d model L \times d_{\text{model}} L×dmodel。
因此,进入 Decoder 第一层的输入矩阵为 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel : L L L 为当前 序列长度, d model d_{\text{model}} dmodel 为模型维度(如 512、768、12288)。后续各层 Decoder(掩码自注意力、前馈网络)的输入与输出也均保持 L × d model L \times d_{\text{model}} L×dmodel ,直到最后一层取最后一个位置的向量送入输出层做下一个 token 的预测。
L L L 会一直变化吗?
- 训练时 :在一个 batch 内,通常把所有序列 pad 到同一长度,或按固定长度截断,因此一次前向传播里 L L L 是固定的(例如该 batch 的 max length)。
- 推理时(自回归生成) :每一步都会把「上一步预测出的 token」拼回输入,所以序列长度每一步加 1 。例如一开始输入「你好,请问」对应 L 0 = 4 L_0 = 4 L0=4;模型预测出下一个 token 后,下一轮输入就是 4+1=5 个 token,即 L = 5 L=5 L=5;再下一轮 L = 6 L=6 L=6,依此类推,直到生成 EOS 或达到最大长度。因此推理时,每次循环进入 Decoder 的 L L L 确实都会变化 ( L 0 → L 0 + 1 → L 0 + 2 → ⋯ L_0 \to L_0+1 \to L_0+2 \to \cdots L0→L0+1→L0+2→⋯)。公式 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel 里的 L L L 指的就是「当前这一步」的序列长度,在不同步骤可以取不同值。
3. Decoder 的核心结构:每一层在做什么
每一层 Decoder 由两个主要子层组成,且每个子层外都有残差连接 与 Layer Normalization(Add & Normalize)。
3.1 带掩码的多头自注意力层
作用 :在序列内部做样本间相关性计算,但只允许位置 i i i 看到 0 ∼ i 0 \sim i 0∼i ,避免「偷看未来」,与自回归一致。详见 Transformer 8. Decoder: 掩码注意力机制以及数学推导。
矩阵与运算 分两步说明:先给出单头 的完整流程,再展开多头的维度拆解与拼接。
单头注意力(一个「头」在算什么)
- 输入 :该层输入 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel。
- Q、K、V :由同一 X X X 经三个线性层得到:
- Q = X W Q Q = X W_Q Q=XWQ, K = X W K K = X W_K K=XWK, V = X W V V = X W_V V=XWV
- W Q , W K , W V ∈ R d model × d k W_Q,\, W_K,\, W_V \in \mathbb{R}^{d_{\text{model}} \times d_k} WQ,WK,WV∈Rdmodel×dk(单头时 d k = d model d_k = d_{\text{model}} dk=dmodel;多头时 d k = d model / h d_k = d_{\text{model}}/h dk=dmodel/h,见下)
- 故 Q , K , V ∈ R L × d k Q,\, K,\, V \in \mathbb{R}^{L \times d_k} Q,K,V∈RL×dk。
- 注意力分数 : S = Q K T / d k S = Q K^T / \sqrt{d_k} S=QKT/dk ,形状为 L × L L \times L L×L(每个位置对所有位置的相似度)。
- 掩码 :在 softmax 前将「未来位置」置为 − ∞ -\infty −∞,即 S ← S + M S \leftarrow S + M S←S+M,其中 M M M 为下三角为 0、上三角为 − ∞ -\infty −∞ 的 L × L L \times L L×L 矩阵;softmax 后这些位置权重为 0。
- 加权求和 : A t t e n t i o n ( Q , K , V ) = s o f t m a x ( S ) V \mathrm{Attention}(Q,K,V) = \mathrm{softmax}(S) \, V Attention(Q,K,V)=softmax(S)V,形状 L × d k L \times d_k L×dk。
单头时上述输出即为该子层输出;多头时需要对每个头重复上述过程,再拼接并做一次线性投影。
多头注意力的详细计算
动机 :使用 h h h 组不同的 W Q , W K , W V W_Q,\, W_K,\, W_V WQ,WK,WV,相当于 h h h 个「专家」从不同子空间(不同角度)对同一序列做注意力,再合并结果,使表示更丰富。详见 Transformer 2. Attention 注意力机制 中的多头部分。
维度约定 :设头数为 h h h,令 d k = d model / h d_k = d_{\text{model}} / h dk=dmodel/h (每头对应的 Q/K/V 维度)。例如 d model = 12288 d_{\text{model}}=12288 dmodel=12288、 h = 96 h=96 h=96 时, d k = 128 d_k=128 dk=128。这样 h ⋅ d k = d model h \cdot d_k = d_{\text{model}} h⋅dk=dmodel,拼接后总维度与模型维度一致。
每一步的矩阵形状 (以第 t t t 个头为例, t = 1 , ... , h t=1,\ldots,h t=1,...,h):
-
每头的 Q、K、V
对第 t t t 个头,用该头独有的权重矩阵把 X X X 投影到 d k d_k dk 维:
- Q ( t ) = X W Q ( t ) Q^{(t)} = X W_Q^{(t)} Q(t)=XWQ(t), K ( t ) = X W K ( t ) K^{(t)} = X W_K^{(t)} K(t)=XWK(t), V ( t ) = X W V ( t ) V^{(t)} = X W_V^{(t)} V(t)=XWV(t)
- W Q ( t ) , W K ( t ) , W V ( t ) ∈ R d model × d k W_Q^{(t)},\, W_K^{(t)},\, W_V^{(t)} \in \mathbb{R}^{d_{\text{model}} \times d_k} WQ(t),WK(t),WV(t)∈Rdmodel×dk
- Q ( t ) , K ( t ) , V ( t ) ∈ R L × d k Q^{(t)},\, K^{(t)},\, V^{(t)} \in \mathbb{R}^{L \times d_k} Q(t),K(t),V(t)∈RL×dk
-
每头的注意力(含掩码)
- S ( t ) = Q ( t ) ( K ( t ) ) T / d k S^{(t)} = Q^{(t)} (K^{(t)})^T / \sqrt{d_k} S(t)=Q(t)(K(t))T/dk ,形状 L × L L \times L L×L
- 加因果掩码: S ( t ) ← S ( t ) + M S^{(t)} \leftarrow S^{(t)} + M S(t)←S(t)+M( M M M 同上,下三角 0、上三角 − ∞ -\infty −∞)
- h e a d ( t ) = s o f t m a x ( S ( t ) ) V ( t ) \mathrm{head}^{(t)} = \mathrm{softmax}(S^{(t)}) \, V^{(t)} head(t)=softmax(S(t))V(t),形状 L × d k L \times d_k L×dk
-
多头拼接
将 h h h 个头的输出在特征维 上拼接(沿列拼):
C o n c a t ( h e a d ( 1 ) , ... , h e a d ( h ) ) ∈ R L × ( h ⋅ d k ) = R L × d model . \mathrm{Concat}(\mathrm{head}^{(1)}, \ldots, \mathrm{head}^{(h)}) \in \mathbb{R}^{L \times (h \cdot d_k)} = \mathbb{R}^{L \times d_{\text{model}}}. Concat(head(1),...,head(h))∈RL×(h⋅dk)=RL×dmodel. -
输出投影
再经过一个线性层,把 h ⋅ d k h \cdot d_k h⋅dk 维映射回 d model d_{\text{model}} dmodel(多数实现中 h ⋅ d k = d model h \cdot d_k = d_{\text{model}} h⋅dk=dmodel,这一步做一次可学习的混合):
M u l t i H e a d ( X ) = C o n c a t ( h e a d ( 1 ) , ... , h e a d ( h ) ) W O , W O ∈ R d model × d model . \mathrm{MultiHead}(X) = \mathrm{Concat}(\mathrm{head}^{(1)}, \ldots, \mathrm{head}^{(h)}) \, W_O, \quad W_O \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}}. MultiHead(X)=Concat(head(1),...,head(h))WO,WO∈Rdmodel×dmodel.输出形状为 L × d model L \times d_{\text{model}} L×dmodel。
等价实现(常见写法) :也可以先对 X X X 做一次线性变换得到 L × d model L \times d_{\text{model}} L×dmodel,再在实现上按「头」切分成 h h h 个 L × d k L \times d_k L×dk 的块,每块做一次 L × L L \times L L×L 的注意力和 L × d k L \times d_k L×dk 的加权求和,再拼回 L × d model L \times d_{\text{model}} L×dmodel 后乘 W O W_O WO。数学上与上述「每头一组 W Q ( t ) , W K ( t ) , W V ( t ) W_Q^{(t)}, W_K^{(t)}, W_V^{(t)} WQ(t),WK(t),WV(t)」等价。
数值示例 (与 GPT 系列同量级): L = 1300 L=1300 L=1300, d model = 12288 d_{\text{model}}=12288 dmodel=12288, h = 96 h=96 h=96, d k = 128 d_k=128 dk=128。则每头内 Q ( t ) K ( t ) T Q^{(t)} K^{(t)T} Q(t)K(t)T 为 1300×1300, h e a d ( t ) \mathrm{head}^{(t)} head(t) 为 1300×128;拼接后 1300×12288,经 W O W_O WO 仍为 1300×12288。
💡 理解要点 :多头 = 多组 Q/K/V 并行做「缩放点积注意力 + 掩码」,得到 h h h 个 L × d k L \times d_k L×dk,沿特征维拼成 L × d model L \times d_{\text{model}} L×dmodel,再经 W O W_O WO 得到该子层输出 L × d model L \times d_{\text{model}} L×dmodel 。计算量仍为 O ( L 2 ) O(L^2) O(L2) (且 h h h 个头可并行算),只是参数量约为单头的 h h h 倍(多组 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV)。
3.2 前馈神经网络层(FFN)
作用 :对每个位置独立做非线性变换,是模型主要的非线性来源。结构为「放大再缩小」: d model → 4 ⋅ d model → d model d_{\text{model}} \to 4 \cdot d_{\text{model}} \to d_{\text{model}} dmodel→4⋅dmodel→dmodel。详见 Transformer 5. Transformer中的残差连接、归一化与前馈神经网络。
矩阵与运算 (以 d = d model = 12288 d = d_{\text{model}} = 12288 d=dmodel=12288 为例):
- 第一层 : z 1 = X W 1 + b 1 z_1 = X W_1 + b_1 z1=XW1+b1, X ∈ R L × 12288 X \in \mathbb{R}^{L \times 12288} X∈RL×12288, W 1 ∈ R 12288 × 49152 W_1 \in \mathbb{R}^{12288 \times 49152} W1∈R12288×49152(即 12288 × ( 4 ⋅ 12288 ) 12288 \times (4 \cdot 12288) 12288×(4⋅12288)), z 1 ∈ R L × 49152 z_1 \in \mathbb{R}^{L \times 49152} z1∈RL×49152;再经激活(如 GELU/ReLU)。
- 第二层 : z 2 = a c t ( z 1 ) W 2 + b 2 z_2 = \mathrm{act}(z_1) W_2 + b_2 z2=act(z1)W2+b2, W 2 ∈ R 49152 × 12288 W_2 \in \mathbb{R}^{49152 \times 12288} W2∈R49152×12288,输出 L × 12288 L \times 12288 L×12288。
即 FFN 输入与输出均为 L × d model L \times d_{\text{model}} L×dmodel 。参数量(仅权重): W 1 W_1 W1 为 12288 × 49152 12288 \times 49152 12288×49152, W 2 W_2 W2 为 49152 × 12288 49152 \times 12288 49152×12288。
3.3 残差连接与 Layer Normalization
每个子层均采用 Add & Normalize :子层输出与子层输入(残差)相加,再对每个样本做 Layer Normalization。数学上为:
O u t p u t = L a y e r N o r m ( S u b L a y e r ( X ) + X ) . \mathrm{Output} = \mathrm{LayerNorm}(\mathrm{SubLayer}(X) + X). Output=LayerNorm(SubLayer(X)+X).
残差保证梯度直通,LayerNorm 稳定训练、加速收敛。单层 Decoder 可写为:
DecoderLayer ( X ) = L N 2 ( F F N ( L N 1 ( M a s k e d A t t n ( X ) + X ) ) + L N 1 ( M a s k e d A t t n ( X ) + X ) ) . \text{DecoderLayer}(X) = \mathrm{LN}_2\big( \mathrm{FFN}( \mathrm{LN}_1( \mathrm{MaskedAttn}(X) + X )) + \mathrm{LN}_1( \mathrm{MaskedAttn}(X) + X ) \big). DecoderLayer(X)=LN2(FFN(LN1(MaskedAttn(X)+X))+LN1(MaskedAttn(X)+X)).
这层的输入输出矩阵大小一致,都是 L × d model L \times d_{\text{model}} L×dmodel ( 1300 × 12288 1300 \times 12288 1300×12288)。
💡 理解要点 :Decoder-only 的一层 = 带掩码的多头自注意力(+ 残差 + LN)+ 前馈网络(+ 残差 + LN);没有编码器-解码器注意力,因此 Q、K、V 全部来自同一 Decoder 输入,仅通过掩码限制为「只看过去」。
4. 输出层:线性层与 Softmax
最后一个位置的向量 h L ∈ R d model \mathbf{h}L \in \mathbb{R}^{d{\text{model}}} hL∈Rdmodel,经线性层**映射到词表维度:
h L \mathbf{h}_L hL 的含义 :所有 Decoder 层输出为 L × d model L \times d_{\text{model}} L×dmodel 的矩阵; h L \mathbf{h}L hL 即该矩阵的第 L L L 行 ,也就是最后一个位置 (第 L L L 个 token)对应的 d model d{\text{model}} dmodel 维隐藏向量。该位置已见过整段输入(位置 1 ∼ L 1 \sim L 1∼L),故用 h L \mathbf{h}_L hL 预测「下一个」token(第 L + 1 L+1 L+1 个)是合理的。
s = h L W out + b out , W out ∈ R d model × V , s ∈ R V , \mathbf{s} = \mathbf{h}L \, W{\text{out}} + b_{\text{out}}, \quad W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V}, \; \mathbf{s} \in \mathbb{R}^V, s=hLWout+bout,Wout∈Rdmodel×V,s∈RV,
其中 V V V 为词表大小(如 GPT-3 的 50257、Llama-3 的 128000)。再经 Softmax 得到下一个 token 的概率分布:
P ( next token ) = s o f t m a x ( s ) . P(\text{next token}) = \mathrm{softmax}(\mathbf{s}). P(next token)=softmax(s).
训练时用交叉熵损失与真实下一个 token 比较;推理时对 P P P 做 argmax(贪婪)或采样得到下一个 token,并拼回输入序列继续自回归。
5. 训练流程与推理流程
Decoder-only 状态下,训练 时利用 Teacher Forcing 与掩码,可对整段序列并行 计算;推理 时必须逐步生成,每步依赖上一步的预测结果。
5.1 训练流程(并行)
假设要预测的序列为 y y y,编码后的嵌入为 e b d _ y \mathrm{ebd}\_y ebd_y,取前 n n n 个 token 作为输入、第 n n n 个位置对应的真实 token 为标签。对 n = 0 , 1 , ... , L − 1 n = 0, 1, \ldots, L-1 n=0,1,...,L−1 可一次性完成:
- 输入 e b d _ y 0 : n \mathrm{ebd}\_y0:n ebd_y0:n (或整段 e b d _ y \mathrm{ebd}\_y ebd_y 配合 loss 只对「下一个 token」位置算损失),Decoder 输出每个位置的表示;取最后一个有效位置 的表示经线性层 + Softmax 得到该步的预测 y ^ n \hat{y}n y^n,与真实标签 y n yn yn 计算损失。
由于掩码的存在,位置 i i i 的表示只依赖 0 ∼ i 0 \sim i 0∼i,与「用前 i i i 个 token 预测第 i i i 个」等价;因此一次前向传播即可得到所有位置的预测,训练可并行。
5.2 推理流程(自回归、循环)
- 第 1 步:输入当前序列的嵌入(如「这」「是」「最好的」「时代」)→ 输出下一个 token 的预测(如「这」)。
- 第 2 步:将上一步预测的 token 拼入序列,再输入 Decoder → 输出再下一个 token(如「是」)。
- 重复直到生成结束符(如 EOS)或达到最大长度。
因此推理时无法并行:下一步的输入依赖上一步的输出,必须循环执行。
下面用表格形式复述上述训练与推理中的输入/输出对应关系(保留你原有的「序列前半段 → 预测 → 真实标签」的示例)。
5.3 训练流程示例(步骤对应关系)
假设需要预测的序列为 y y y,编码好的结果为 e b d _ y \mathrm{ebd}\_y ebd_y,取前 n n n 个 token 作为输入、第 n n n 个位置对应真实标签。例如:
- 第1步,输入 ebd_y0 >> 输出预测标签yhat0,对应真实标签y0
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 序列的前半段 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 对应 ➡ | 真实标签y 序列的后半段 | 索引 | | |----|-------| | 0 | 这 | | 1 | 是 | | 2 | 最好的 | | 3 | 时代 | | 4 | 这 | | 5 | 是 | | 6 | 最坏的 | | 7 | 时代 | | 8 | "eos" | |
...
- 第n+1步,输入 ebd_y:n >> 输出预测标签yhatn,对应真实标签yn
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 序列的前半段 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 2 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 3 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 4 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 4 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 对应 ➡ | 真实标签y 序列的后半段 | 索引 | | |----|-------| | 0 | 这 | | 1 | 是 | | 2 | 最好的 | | 3 | 时代 | | 4 | 这 | | 5 | 是 | | 6 | 最坏的 | | 7 | 时代 | | 8 | "eos" | |
- 第n+2步,输入 ebd_y:n+1 >> 输出预测标签yhatn+1,对应真实标签yn+1
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 序列的前半段 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 2 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 3 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 4 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 5 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 5 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 对应 ➡ | 真实标签y 序列的后半段 | 索引 | | |----|-------| | 0 | 这 | | 1 | 是 | | 2 | 最好的 | | 3 | 时代 | | 4 | 这 | | 5 | 是 | | 6 | 最坏的 | | 7 | 时代 | | 8 | "eos" | |
- 第n+3步,输入 ebd_y:n+2 >> 输出预测标签yhatn+2,对应真实标签yn+2
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 序列的前半段 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 2 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 3 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 4 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 5 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 6 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 6 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 对应 ➡ | 真实标签y 序列的后半段 | 索引 | | |----|-------| | 0 | 这 | | 1 | 是 | | 2 | 最好的 | | 3 | 时代 | | 4 | 这 | | 5 | 是 | | 6 | 最坏的 | | 7 | 时代 | | 8 | "eos" | |
5.4 推理流程示例(自回归、逐步)
在推理时,Decoder 每次只预测下一个 token,再将其拼入输入继续预测,直到生成 EOS 或达到最大长度。流程如下------
- 第一步,输入 ebd_y(全部的数据) >> 输出下一步的预测标签
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 全部的序列 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 4 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | |
- 第二步,输入 ebd_y(全部的数据)+ 预测的yhat >> 输出下一步的预测标签
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 全部的序列 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 4 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 5 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | |
- 第三步,输入 ebd_y(全部的数据)+ 预测的yhat >> 输出下一步的预测标签
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 全部的序列 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 4 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 5 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 6 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | |
以此类推,直到预测出"eos"后停止。
💡 理解要点 :训练 时利用掩码与 Teacher Forcing,整段序列可一次前向、并行计算;推理 时必须自回归、在下一时间步前先得到上一步的预测,因此需用循环逐步生成。
6. 总结:Decoder-only 的核心价值
Decoder-only 架构在 Transformer 家族中承担纯生成任务:仅用「带掩码的自注意力 + 前馈网络 + 残差与 LayerNorm」堆叠,无编码器、无交叉注意力,是 GPT、LLaMA、Qwen 等大语言模型的基础。要点归纳如下:
- 输入与数据流 :Tokenization → Embedding( V × d model V \times d_{\text{model}} V×dmodel 查表)→ 位置编码,得到 L × d model L \times d_{\text{model}} L×dmodel 的 Decoder 输入。
- 单层结构 :掩码多头自注意力( X → Q , K , V → s o f t m a x ( ( Q K T / d k ) + M ) V → X \to Q,K,V \to \mathrm{softmax}((QK^T/\sqrt{d_k})+M)V \to X→Q,K,V→softmax((QKT/dk )+M)V→ 多头拼接与线性)→ 残差 + LN → 前馈网络( d model → 4 d model → d model d_{\text{model}} \to 4d_{\text{model}} \to d_{\text{model}} dmodel→4dmodel→dmodel)→ 残差 + LN;输入与输出形状均为 L × d model L \times d_{\text{model}} L×dmodel。
- 输出与生成 :取最后一层最后一位置向量,经线性层 d model × V d_{\text{model}} \times V dmodel×V 与 Softmax 得到词表上的概率分布;训练时并行、推理时自回归循环。
结合前文 Transformer 8. Decoder: 掩码注意力机制以及数学推导、Transformer 5. Transformer中的残差连接、归一化与前馈神经网络、Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍,Decoder-only 的每一环都可在对应章节找到更细的数学与直觉说明。
7. 各步骤可训练参数量统计
下面按数据流顺序,给出 Decoder-only 模型中每一步骤的可训练参数量(权重 + 偏置,若该模块有偏置则一并计入)。
符号定义与典型取值(与上文一致,便于代入计算):
| 符号 | 含义 | 典型取值(如 GPT-3 同量级) |
|---|---|---|
| V V V | 词表大小 | 50257(GPT-3)或 128000(Llama-3),下面我们取1300作为测试 |
| d model d_{\text{model}} dmodel | 模型维度 | 12288 |
| h h h | 注意力头数 | 96 |
| d k d_k dk | 每头维度, d k = d model / h d_k = d_{\text{model}}/h dk=dmodel/h | 128 |
| N N N | Decoder 层数 | 96 |
| L max L_{\max} Lmax | 最大序列长度(用于可学习位置编码) | 2048 |
下文公式中均可用上表取值代入,得到具体参数量。
7.1 Embedding 层
- 词嵌入矩阵 E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel: V ⋅ d model V \cdot d_{\text{model}} V⋅dmodel。
小计 : V ⋅ d model V \cdot d_{\text{model}} V⋅dmodel。代入 V = 1300 V=1300 V=1300、 d model = 12288 d_{\text{model}}=12288 dmodel=12288 得 1300 × 12288 = 15 974 400 ≈ 1.60 × 10 7 1300 \times 12288 = 15\,974\,400 \approx 1.60 \times 10^7 1300×12288=15974400≈1.60×107。
7.2 位置编码
- 正弦/余弦位置编码:无参数。
- 可学习位置编码 (如 GPT 系列): L max ⋅ d model L_{\max} \cdot d_{\text{model}} Lmax⋅dmodel(每位置一个 d model d_{\text{model}} dmodel 维向量)。
小计 :0(固定编码)或 L max ⋅ d model L_{\max} \cdot d_{\text{model}} Lmax⋅dmodel(可学习)。代入 L max = 2048 L_{\max}=2048 Lmax=2048、 d model = 12288 d_{\text{model}}=12288 dmodel=12288 得 2048 × 12288 = 25 165 824 ≈ 2.52 × 10 7 2048 \times 12288 = 25\,165\,824 \approx 2.52 \times 10^7 2048×12288=25165824≈2.52×107。
7.3 单层 Decoder 内的参数量(共 N N N 层)
7.3.1 带掩码的多头自注意力
- W Q , W K , W V W_Q,\, W_K,\, W_V WQ,WK,WV :共 h h h 个头,每头三个矩阵,每个 R d model × d k \mathbb{R}^{d_{\text{model}} \times d_k} Rdmodel×dk,故 3 ⋅ h ⋅ ( d model ⋅ d k ) = 3 ⋅ d model ⋅ ( d k ⋅ h ) = 3 ⋅ d model 2 3 \cdot h \cdot (d_{\text{model}} \cdot d_k) = 3 \cdot d_{\text{model}} \cdot (d_k \cdot h) = 3 \cdot d_{\text{model}}^2 3⋅h⋅(dmodel⋅dk)=3⋅dmodel⋅(dk⋅h)=3⋅dmodel2。
- W O W_O WO : R d model × d model \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}} Rdmodel×dmodel,即 d model 2 d_{\text{model}}^2 dmodel2。注意, W O W_O WO 是多头自注意力里的输出投影矩阵,章节3.1中有详细描述。
- 偏置 (若实现中有):Q/K/V 与 O 各 d k d_k dk 或 d model d_{\text{model}} dmodel,常见为 4 ⋅ d model 4 \cdot d_{\text{model}} 4⋅dmodel(或不计,依实现而定)。
小计(仅权重) : 4 ⋅ d model 2 4 \cdot d_{\text{model}}^2 4⋅dmodel2。代入 d model = 12288 d_{\text{model}}=12288 dmodel=12288 得 4 × 12288 2 = 603 979 776 ≈ 6.04 × 10 8 4 \times 12288^2 = 603\,979\,776 \approx 6.04 \times 10^8 4×122882=603979776≈6.04×108(单层)。
7.3.2 子层后的 Layer Normalization(共 2 个)
- 每个 LN 有 scale γ \gamma γ 与 shift β \beta β,各 d model d_{\text{model}} dmodel 维,故每层 Decoder 内 2 个 LN: 2 ⋅ ( 2 ⋅ d model ) = 4 ⋅ d model 2 \cdot (2 \cdot d_{\text{model}}) = 4 \cdot d_{\text{model}} 2⋅(2⋅dmodel)=4⋅dmodel。
小计 : 4 ⋅ d model 4 \cdot d_{\text{model}} 4⋅dmodel。代入 d model = 12288 d_{\text{model}}=12288 dmodel=12288 得 4 × 12288 = 49 152 4 \times 12288 = 49\,152 4×12288=49152(单层)。
说明:每个 Decoder 层里有两个子层,每个子层后面各有一个 LayerNorm,所以每层要算 2 个 LN:
- 第一个 LN 层在「带掩码的多头自注意力 + 残差」之后
- 第二个 LN 层在「前馈网络 FFN + 残差」之后。
7.3.3 前馈网络(FFN)
- W 1 W_1 W1 : R d model × 4 d model \mathbb{R}^{d_{\text{model}} \times 4d_{\text{model}}} Rdmodel×4dmodel,即 4 ⋅ d model 2 4 \cdot d_{\text{model}}^2 4⋅dmodel2。
- W 2 W_2 W2 : R 4 d model × d model \mathbb{R}^{4d_{\text{model}} \times d_{\text{model}}} R4dmodel×dmodel,即 4 ⋅ d model 2 4 \cdot d_{\text{model}}^2 4⋅dmodel2。
- 偏置 b 1 , b 2 b_1,\, b_2 b1,b2: 4 ⋅ d model + d model = 5 ⋅ d model 4 \cdot d_{\text{model}} + d_{\text{model}} = 5 \cdot d_{\text{model}} 4⋅dmodel+dmodel=5⋅dmodel(若存在)。
小计(仅权重) : 8 ⋅ d model 2 8 \cdot d_{\text{model}}^2 8⋅dmodel2;含偏置则为 8 ⋅ d model 2 + 5 ⋅ d model 8 \cdot d_{\text{model}}^2 + 5 \cdot d_{\text{model}} 8⋅dmodel2+5⋅dmodel。代入 d model = 12288 d_{\text{model}}=12288 dmodel=12288 得 8 × 12288 2 = 1 207 959 552 ≈ 1.21 × 10 9 8 \times 12288^2 = 1\,207\,959\,552 \approx 1.21 \times 10^9 8×122882=1207959552≈1.21×109(单层,仅权重)。
7.3.4 单层 Decoder 合计
| 模块 | 参数量(权重) | 备注 |
|---|---|---|
| 多头自注意力 | 4 d model 2 4 \, d_{\text{model}}^2 4dmodel2 | 含 W O W_O WO |
| 两个 LayerNorm | 4 d model 4 \, d_{\text{model}} 4dmodel | γ , β \gamma,\,\beta γ,β × 2 |
| FFN | 8 d model 2 8 \, d_{\text{model}}^2 8dmodel2 | W 1 , W 2 W_1,\,W_2 W1,W2 |
| 单层合计 | 12 d model 2 + 4 d model 12 \, d_{\text{model}}^2 + 4 \, d_{\text{model}} 12dmodel2+4dmodel | 未计注意力偏置 |
单层代入得 12 × 12288 2 + 4 × 12288 = 1 812 017 664 + 49 152 = 1 812 066 816 ≈ 1.81 × 10 9 12 \times 12288^2 + 4 \times 12288 = 1\,812\,017\,664 + 49\,152 = 1\,812\,066\,816 \approx 1.81 \times 10^9 12×122882+4×12288=1812017664+49152=1812066816≈1.81×109。 N N N 层总计: N ⋅ ( 12 d model 2 + 4 d model ) N \cdot (12 \, d_{\text{model}}^2 + 4 \, d_{\text{model}}) N⋅(12dmodel2+4dmodel);代入 N = 96 N=96 N=96 得 96 × 1 812 066 816 = 173 958 414 336 ≈ 1.74 × 10 11 96 \times 1\,812\,066\,816 = 173\,958\,414\,336 \approx 1.74 \times 10^{11} 96×1812066816=173958414336≈1.74×1011。
7.4 输出层(线性层 + Softmax)
- W out W_{\text{out}} Wout : R d model × V \mathbb{R}^{d_{\text{model}} \times V} Rdmodel×V,即 d model ⋅ V d_{\text{model}} \cdot V dmodel⋅V。
- b out b_{\text{out}} bout : V V V 维,即 V V V。
小计 : d model ⋅ V + V d_{\text{model}} \cdot V + V dmodel⋅V+V。代入 d model = 12288 d_{\text{model}}=12288 dmodel=12288、 V = 1300 V=1300 V=1300 得 12288 × 1300 + 1300 = 15 975 700 ≈ 1.60 × 10 7 12288 \times 1300 + 1300 = 15\,975\,700 \approx 1.60 \times 10^7 12288×1300+1300=15975700≈1.60×107。
7.5 总参数量汇总
| 步骤 | 参数量(公式) | 典型数值示例( d model = 12288 d_{\text{model}}\!=\!12288 dmodel=12288, V = 1300 V\!=\!1300 V=1300, N = 96 N\!=\!96 N=96, L max = 2048 L_{\max}\!=\!2048 Lmax=2048) |
|---|---|---|
| Embedding | V ⋅ d model V \cdot d_{\text{model}} V⋅dmodel | 1300 × 12288 ≈ 1.60e7 |
| 位置编码(可学习) | L max ⋅ d model L_{\max} \cdot d_{\text{model}} Lmax⋅dmodel | 2048 × 12288 ≈ 2.52e7 |
| N N N 层 Decoder | N ⋅ ( 12 d model 2 + 4 d model ) N \cdot (12 \, d_{\text{model}}^2 + 4 \, d_{\text{model}}) N⋅(12dmodel2+4dmodel) | 96 × (12×12288² + 4×12288) ≈ 1.74e11 |
| 输出层 | d model ⋅ V + V d_{\text{model}} \cdot V + V dmodel⋅V+V | 12288×1300 + 1300 ≈ 1.60e7 |
| 总计(不含位置) | V ⋅ d model + N ⋅ ( 12 d model 2 + 4 d model ) + ( d model + 1 ) ⋅ V V \cdot d_{\text{model}} + N \cdot (12 \, d_{\text{model}}^2 + 4 \, d_{\text{model}}) + (d_{\text{model}}+1) \cdot V V⋅dmodel+N⋅(12dmodel2+4dmodel)+(dmodel+1)⋅V | 约 1.74e11 |
💡 理解要点 :Decoder 的 N N N 层(注意力 + FFN + LN)占绝大部分参数;Embedding 与输出层均为 O ( V ⋅ d model ) O(V \cdot d_{\text{model}}) O(V⋅dmodel),在 V V V 较大时也相当可观。若使用权重共享 (如 Embedding 与输出层 W out W_{\text{out}} Wout 共享同一矩阵),则输出层线性部分可视为 0 0 0 额外参数(仅多一个 b out b_{\text{out}} bout 或不计)。