Day05
张量的拼接操作
python
"""
案例:
演示张量的拼接操作
涉及到的API:
cat() 不改变维度数,拼接张量,除了拼接的那个维度维,其他维度必须保持一致 (2,3)+(2,3)=(2,6)
stack() 会改变维度数,拼接张量,所有的维度数都必须保持一致 (2,3)+(2,3),dim=0->(2,2,3)
"""
import torch
t1=torch.randint(1,10,(2,3))
print(f't1:{t1},shape:{t1.shape}')
t2=torch.randint(1,10,(2,3))
print(f't2:{t2},shape:{t2.shape}')
#演示张量的拼接
#思路1:cat()拼接张量
t3=torch.cat([t1,t2],dim=0)
print(f't3:{t3},shape:{t3.shape}')
#思路2:stack()拼接张量
t4=torch.stack([t1,t2],dim=2) #(2,3)+(2,3)
print(f't4:{t4},shape:{t4.shape}')自动微分模块(对损失函数求导,结合反向传播,更新权重参数w,b)
训练神经网络时,最常用的算法就是反向传播。在该算法中,参数(模型权重)会根据损失函数关于对应参数的梯度进行调整。为了计算这些梯度,PyTorch内置了名维torch.autograd的微分模块。它支持任意计算图的自动梯度计算:
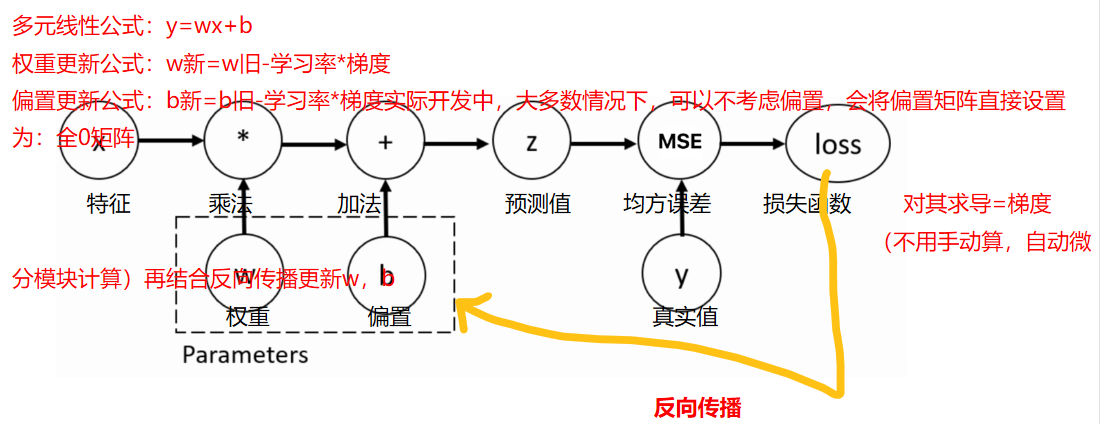
接下来我们使用这个结果进行自动微分模块的介绍。我们使用backward方法、grad属性来实现梯度的计算与访问
梯度基本计算
PyTorch不支持向量张量对向量张量的求导,只支持标量张量对向量张量的求导,如果x是张量,y必须是标量才可以进行求导
计算梯度值:y.backward()
获取x点的梯度值:x.grad(),会累加上一次的梯度值
python
"""
案例:
演示自动微分模块,具体如何求导
回顾:
权重更新公式:
W新=W旧-学习率*梯度
梯度=损失函数的导数
关于损失函数的导数,无需我们手动计算,因为非常常用,所有PyTorch模块内置有 自动微分模块,专门实现针对于 不同的损失函数的求导,
从而实现 结合 反向传播,更新 权重参数w 和 偏置参数b
细节:
只有标量张量才能求导,且大多数底层操作都是 浮点型,记得转型
"""
from importlib.metadata import requires
import torch
#参1:参1:初始值,参2:是否自动微分/求导,参3:数据类型
#定义变量,记录初始的权重w(旧)
w=torch.tensor(10,requires_grad=True,dtype=torch.float32)
#定义loss变量,表示损失函数
loss=2*w**2 #求导得->4w
#打印梯度函数类型
#print(f'梯度函数类型:{loss.grad_fn}'# )
#计算梯度,梯度=损失函数的导数,计算完毕后,会记录到w.grad属性中
#loss.sum().backward() #保证loss是一个标量
loss.backward() #这里因为y本身就是标量,可以不写sum()
#代入 权重更新公式:W新=W旧-学习率*梯度
w.data=w.data-0.01*w.grad
#打印最终结果
print(f'更新后的权重:{w}')梯度下降法最优解
梯度下降法公式:w=w-r*grad(r是学习率,grad是梯度值)
清空上一次的梯度值:x.grad.zero_()
python
"""
案例:
演示detach函数的功能,解决 自动微分的弊端
n2=t1.detach().numpy()
回顾:
自动微分=求导,即:基于损失函数,计算梯度
结婚权重更新公式:w新=w旧-学习率*梯度
问题:
一个张量一旦设置了自动微分,就不能直接转换成numpy的ndarray对象了,需要通过detach函数转换
"""
import torch
import numpy as np
t1=torch.tensor([10,20],requires_grad=True,dtype=torch.float)
print(f't1:{t1},type:{type(t1)}')
#尝试把上述对象转化为numpy对象
# n1=t1.numpy() #报错
# print(f'n1:{n1},type:{type(n1)}')
#解决方法:通过detach函数拷贝一份张量,然后转换
t2=t1.detach()
print(f't2:{t2},type:{type(t2)}')
#测试上述t1与t2是否共享一个空间->共享
# t1.data[0]=100
# print(f't1:{t1}')
# print(f't2:{t2}')
#查看t1,t2谁可以自动微分
print(f't1.requires_grad:{t1.requires_grad}') # True
print(f't2.requires_grad:{t2.requires_grad}') # False
#把t2转换为numpy
n1=t2.numpy()
print(f'n1:{n1},type:{type(n1)}')
#综合最终版:
n2=t1.detach().numpy()
print(f'n2:{n2},type:{type(n2)}')简单真实案例
python
"""
案例:
自动微分真实应用场景
结论:
先向前传播(正向传播)计算出 预测值(z)
基于损失函数 结合 预测值(z) 和 真实值(y)来计算 梯度
结合权重更新公式 w新=w旧-学习率*梯度 来更新权重
"""
from pydoc import cram
import torch
#1、定义x 表示:特征(输入数据),假设:2行5列,全1矩阵
x=torch.ones(2,5)
print(f'x:{x}')
#2、定义y :真实值,假设:2行3列,全0矩阵
y=torch.zeros(2,3)
print(f'y:{y}')
#3、初始化(可自动微分的)权重 和 偏置
w=torch.randn(5,3,requires_grad=True)
print(f'w:{w}')
b=torch.randn(3,requires_grad=True)
print(f'b:{b}')
#前向传播(正向传播),计算出预测值z
z=torch.matmul(x,w)+b
print(f'z:{z}')
#5、定义损失函数
criterion=torch.nn.MSELoss() #naural network:神经网络
loss=criterion(z,y) #loss=损失
#6、进行自动微分求导,结合反向传播,更新权重
loss.backward()
#7、打印w,b用来更新的梯度
print(f'w.grad:{w.grad}')
print(f'b.grad:{b.grad}')
PyTorch线性回归案例实现
要使用的API:
PyTorch的nn.MSELoss()代替平方损失函数
PyTorch的data.DataLoader代替数据加载器
PyTorch的optim.SGD代替优化器
PyTorch的nn.Linear代替假设函数



python
# 导入相关模块
from uuid import main
import torch
from torch.utils.data import TensorDataset # 构造数据集对象
from torch.utils.data import DataLoader # 数据加载器
from torch import nn # nn模块中有平方损失函数和假设函数
from torch import optim # optim模块中有优化器函数
from sklearn.datasets import make_regression # 创建线性回归模型数据集
import matplotlib.pyplot as plt # 导入可视化库
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def progress_bar(num):
"""
根据百分比生成可视化进度条(小于1%时显示等待状态)
参数:
num (int/float): 进度百分比,范围0-100
返回:
str: 可视化的进度条字符串
"""
# 边界值处理:确保百分比在0-100之间
num = max(0.0, min(100.0, float(num)))
# 进度条总长度
bar_length = 50
# 核心逻辑:小于1%显示等待,否则计算进度
if num < 1:
# 小于1%时,进度条全为空白,标注"等待中"
progress_bar_str = f"Progress: |{'-' * bar_length}| {num:.2f}% 等待中"
else:
# ≥1%时,正常计算填充进度
filled_length = int(bar_length * num / 100.0)
# 构建进度条(填充字符+空白字符)
progress = '█' * filled_length + '-' * (bar_length - filled_length)
progress_bar_str = f"Progress: |{progress}| {num:.2f}%"
return progress_bar_str
#1、定义函数创建线性回归样本数据
def create_dataset():
x,y,coef=make_regression(
n_samples=100, #100个样本点
n_features=1, #1个特征(一个特征点)
noise=10, #噪声,噪声越大样本点越散
coef=True, #是否返回系数,默认false,返回值为None
bias=14.5, #偏置,默认为0
random_state=3 #随机数种子,保证每次生成的数据集相同
)
#2、把上述对象转换为张量对象
x=torch.tensor(x,dtype=torch.float32)
y=torch.tensor(y,dtype=torch.float32)
return x,y,coef
#2、定义函数,表示模型训练
def train(x,y,coef):
#1、创建数据集对象,把tensor------>数据集对象->数据加载器(样本生成函数已经进行了tensor的转换)
dataset=TensorDataset(x,y)
#2、创建数据加载器
#参1:数据集对象 参2:批次大小 参3:是否打乱数据(训练集打乱,测试集不打乱)
dataloader=DataLoader(dataset,batch_size=10,shuffle=True)
#3、创建初始值的线性回归模型
#参1:输入特征数 参2:输出特征数
model=nn.Linear(1,1)
#4、创建损失函数
criterion=nn.MSELoss()
#5、创建优化器
#参1:模型参数 参2:学习率
optimizer=optim.SGD(model.parameters(),lr=0.01)
#6、具体的训练过程
#6.1定义变量,分别表示:训练轮数,每轮的(平均)损失,训练总损失值,训练的样本数
epochs,loss_list,total_loss,total_sample=10,[],0.0,0
#6.2开始训练,按轮数训练
for i in range(epochs):
#6.3每轮是分批次训练的,所以从数据加载器中获取 批次数据
for train_x,train_y in dataloader:
#6.4 模型预测
y_pred=model(train_x)
#6.5 计算损失
loss=criterion(y_pred,train_y.reshape(-1,1)) # -1是把y转换为n行1列
#6.6 计算总损失与样本批次数
total_loss+=loss.item()
total_sample+=1
#6.7 梯度清零+反向传播+梯度更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
#6.8把本轮的平均损失加入到列表中
loss_list.append(total_loss/total_sample)
#print(f'轮数:{epochs},平均损失:{total_loss/total_sample}')
#print(f'进度:{epochs/n*100:.2f}%')
print(f'进度:{progress_bar(i/epochs*100)}')
#7 打印最终训练结果
print(f'{epochs}轮的平均损失分别为:{loss_list}')
print(f'模型参数为:{model.weight.data},偏置为:{model.bias.data}')
#8 绘制损失曲线
plt.plot(range(epochs),loss_list)
plt.title('损失值曲线变化图')
plt.grid()
plt.show()
#9 绘制预测值和真实值的关系
#9.1绘制样本点分布情况
plt.scatter(x,y)
#绘制训练模型的预测值
#x:100个样本点的特征
y_pred=torch.tensor(data=[v*model.weight+model.bias for v in x])
#9.3计算真实值
y_true=torch.tensor(data=[v*coef+14.5 for v in x])
#9.4绘制预测值和真实值
plt.plot(x,y_pred,color='red',label='预测值')
plt.plot(x,y_true,color='green',label='真实值')
#9.5图例、网格
plt.legend()
plt.grid()
plt.show()
#3、测试
if __name__ == '__main__':
x,y,coef=create_dataset()
train(x,y,coef)
# print(f'x:{x},y:{y},coef:{coef}')