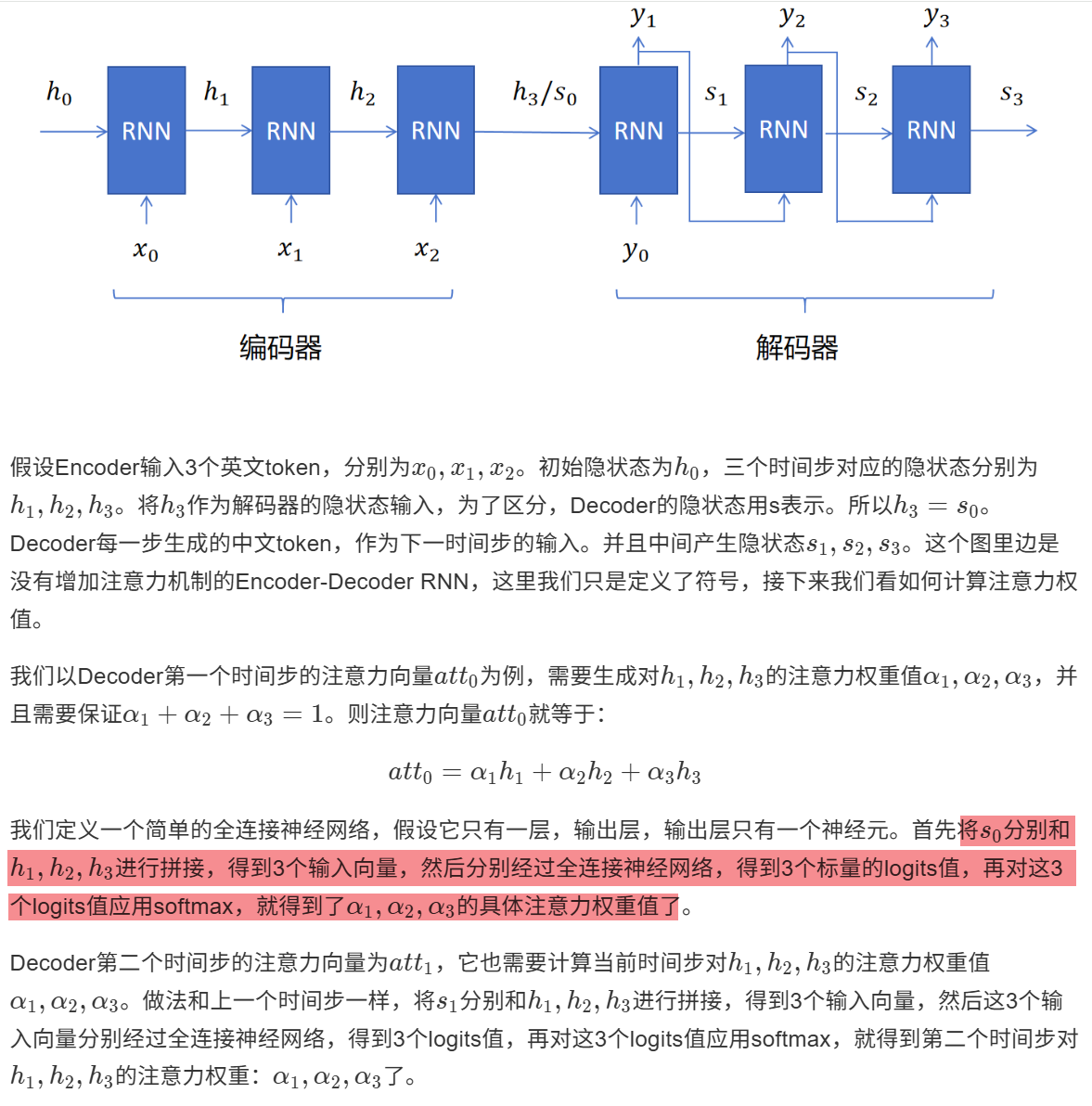
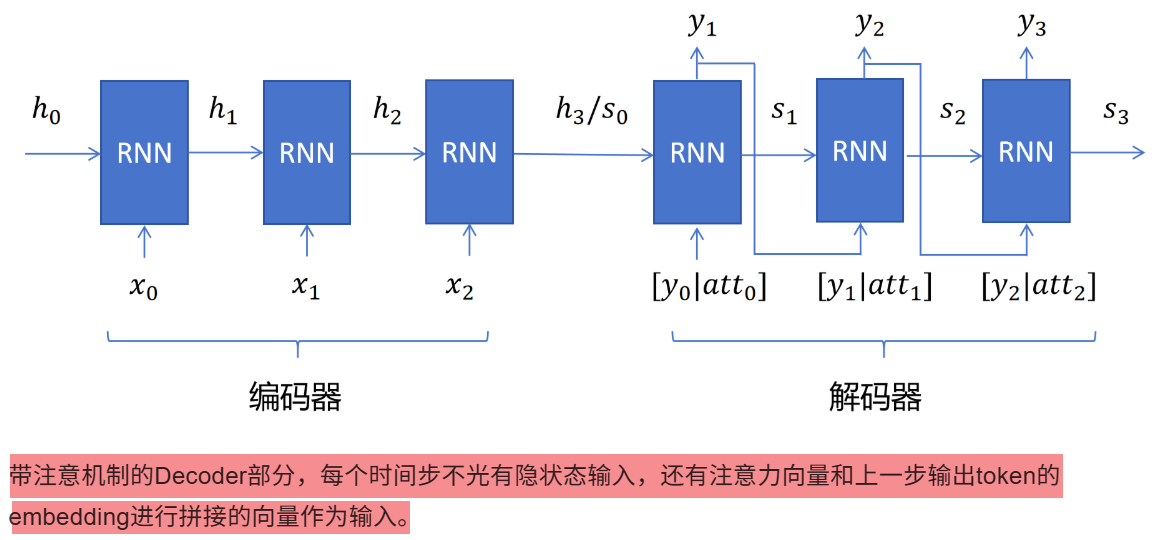
7 神经网络
7.1 神经网络构成
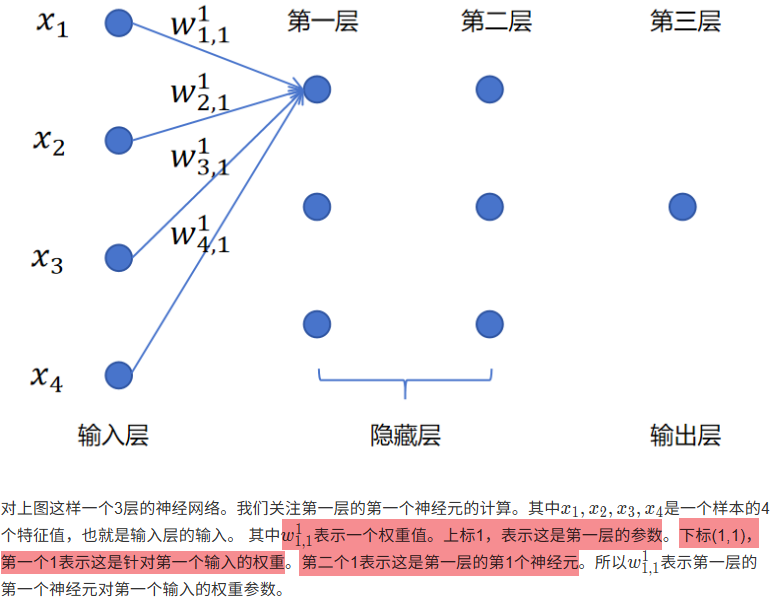
神经网络------xx层

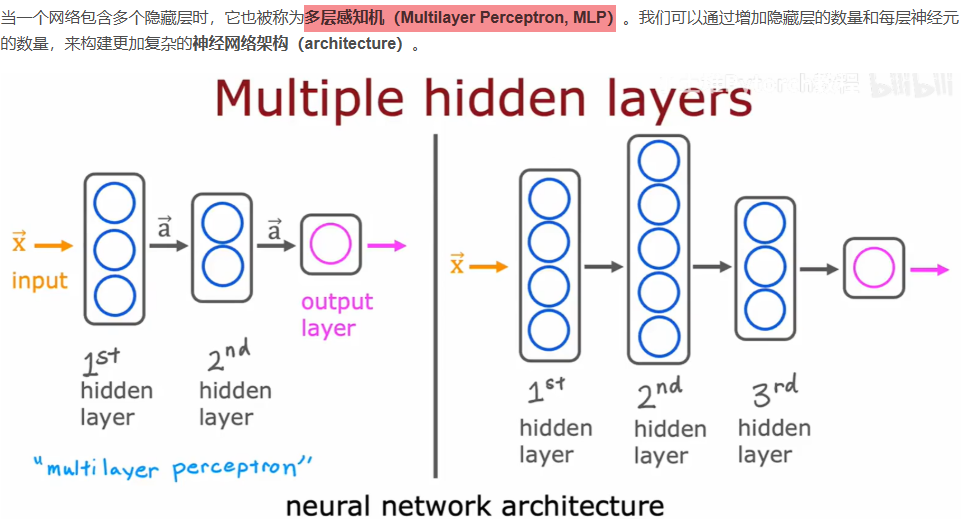
神经网络------神经元
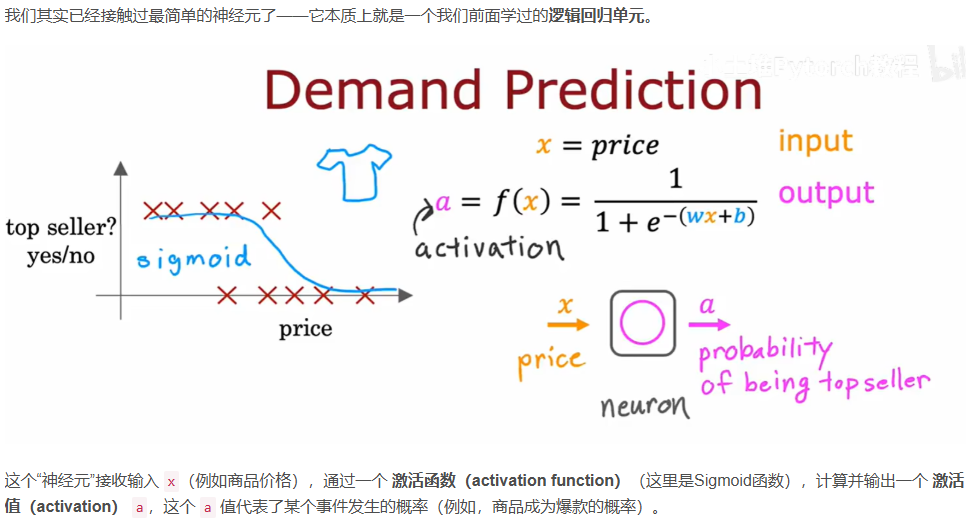
为什么深度申请网络近几年飞速发展?
1.神经网络架构设计统一和可扩展,你可以增加任意多个隐藏层,每一层可以设计任意多个神经元。从而可以应对任意复杂规模的问题
2.大数据量/海量数据
3.GPU技术发展(GPU与CPU最大的不同是GPU拥有大量的上千个计算核心,这些核心
可以同时处理大量简单的计算任务。而神经网络神经元中的矩阵运算本质就是大量相同的操作(如乘法和加法),非常适合并行化。进行矩阵乘法时,每个结果矩阵的元素可以由不同的GPU核心并行进行计算,彼此并不影响)
7.2 神经网络与矩阵计算


7.3 pytorch实现多分类神经网络
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
# 自定义数据集
class MNISTDataset(Dataset):
def __init__(self, file_path):
self.images, self.labels = self._read_file(file_path)
def _read_file(self, file_path):
images = []
labels = []
with open(file_path, 'r') as f:
next(f) # 跳过标题行
for line in f:
items = line.strip().split(",")
images.append([float(x) for x in items[1:]])
labels.append(int(items[0]))
return images, labels
def __getitem__(self, index):
image = torch.tensor(self.images[index], dtype=torch.float32).view(-1)
image = image / 255.0 # 归一化
image = (image - 0.1307) / 0.3081 # 标准化
label = torch.tensor(self.labels[index], dtype=torch.long)
return image, label
def __len__(self):
return len(self.images)
# 模型定义
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10)
)
def forward(self, x):
return self.model(x)
# 参数设置
batch_size = 64
learning_rate = 0.1
num_epochs = 10
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 数据加载
train_dataset = MNISTDataset(r'xxx\mnist_train.csv')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = MNISTDataset(r"xxx\mnist_test.csv")
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 模型、损失函数、优化器
model = NeuralNetwork().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练过程
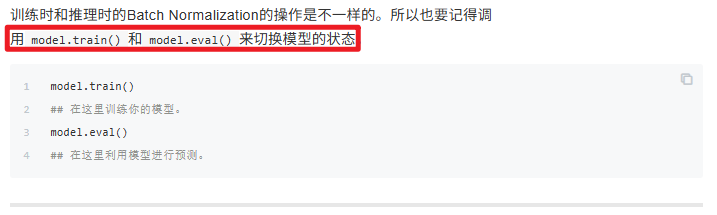
model.train()
for epoch in range(num_epochs):
total_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {avg_loss:.4f}")
# 测试过程
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
preds = torch.argmax(outputs, dim=1)
correct += (preds == labels).sum().item()
total += labels.size(0)
print(f"Test Accuracy: {100 * correct / total:.2f}%")8 激活函数
激活函数在神经网络里很重要。如果没有激活函数,不论几层的神经网络都是一个线性回归。激活函数的作用是
引入非线性。正是因为引入激活函数,模拟了大脑神经元里的抑制和激活,才让神经网络可以拟合任意函数
8.1 常用激活函数
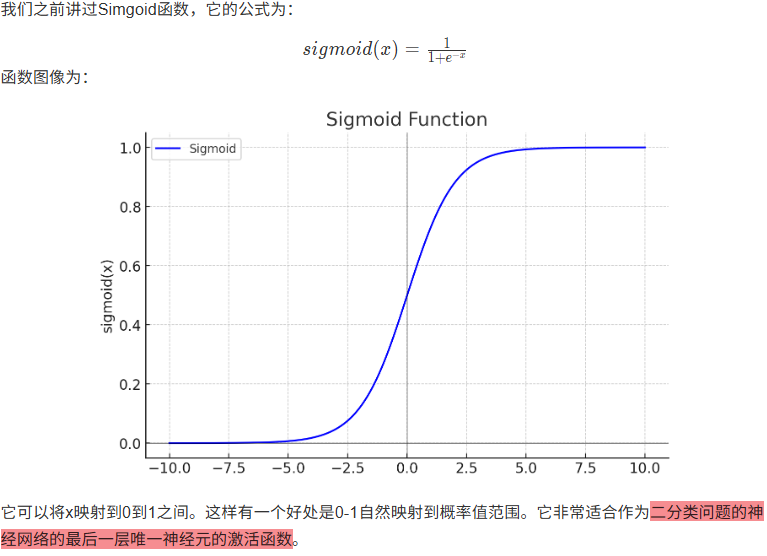
8.1.1 Sigmoid
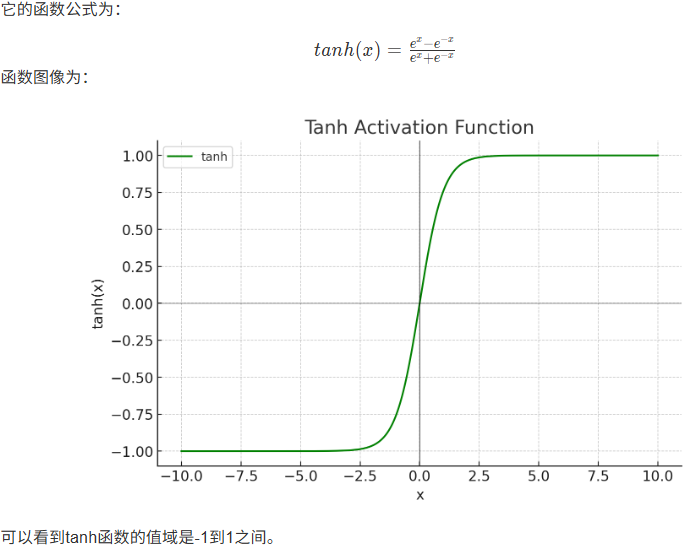
8.1.2 Tanh
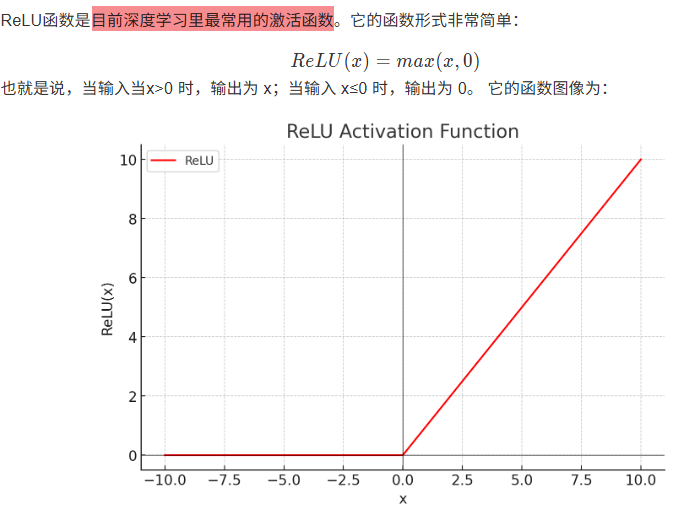
8.1.3 Relu
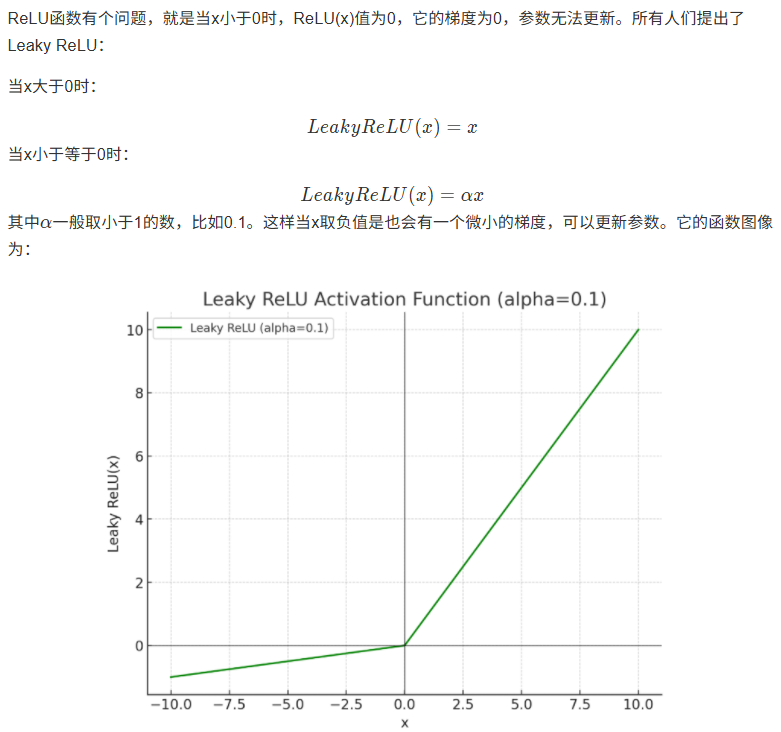
8.1.4 Leaky ReLU
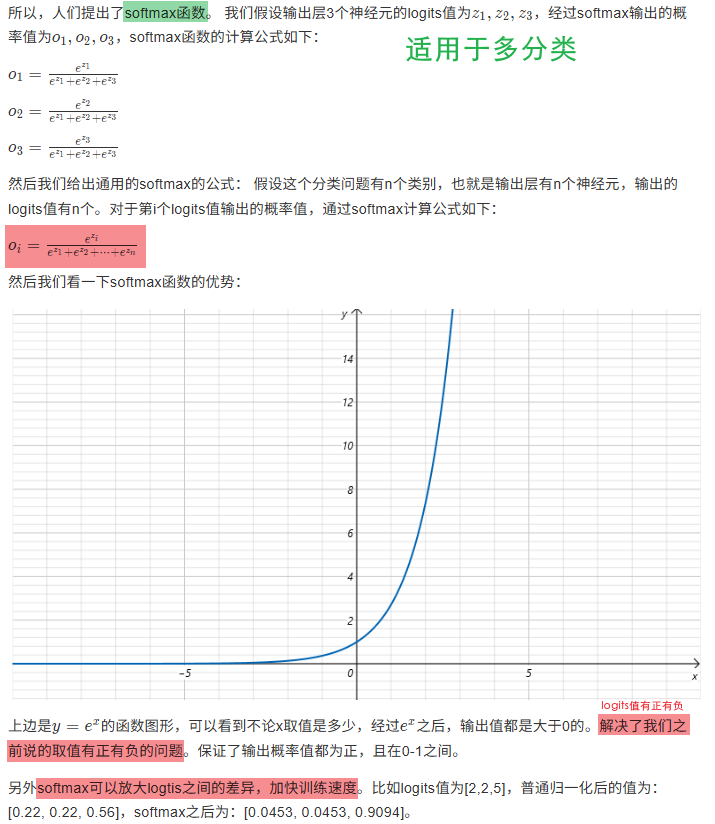
8.1.5 Softmax
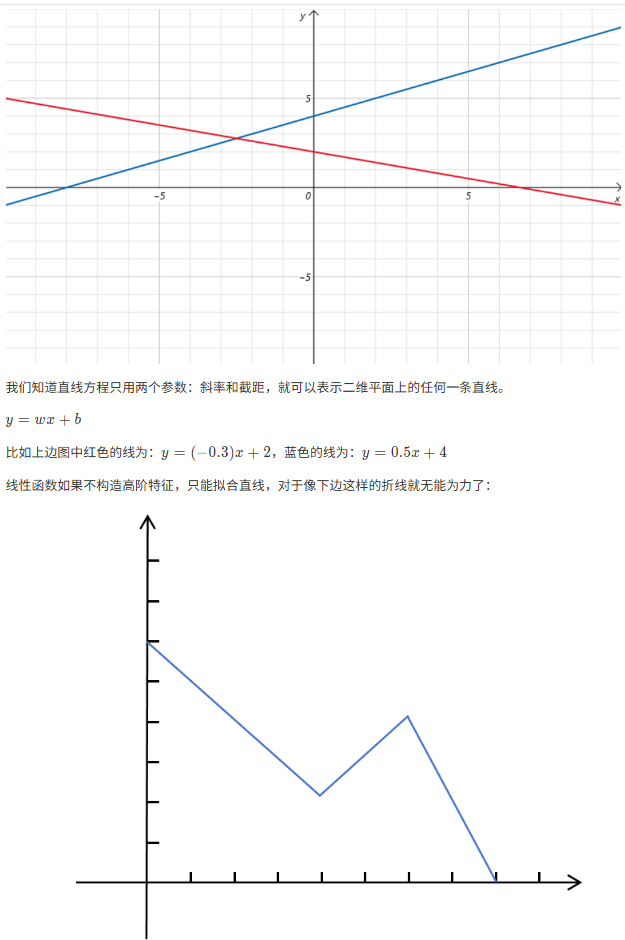
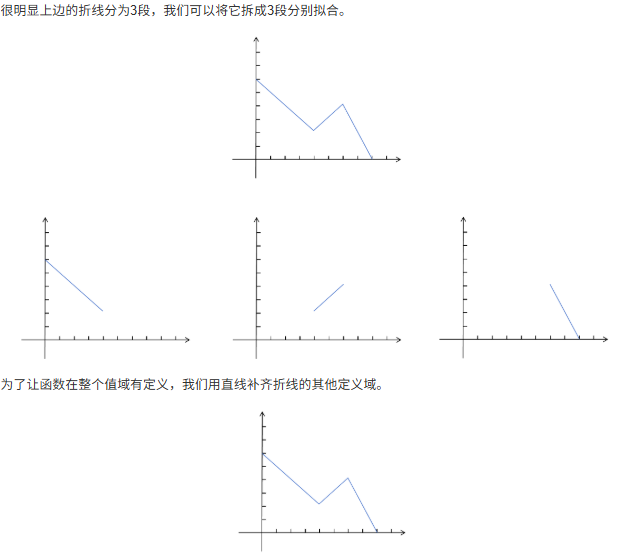
8.2 为什么神经网络可以拟合任何函数
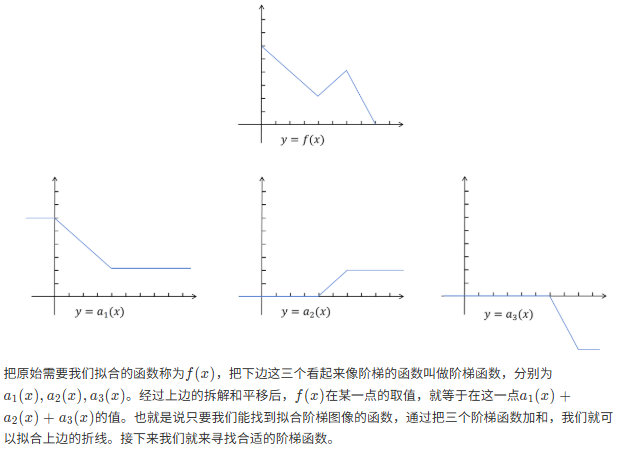
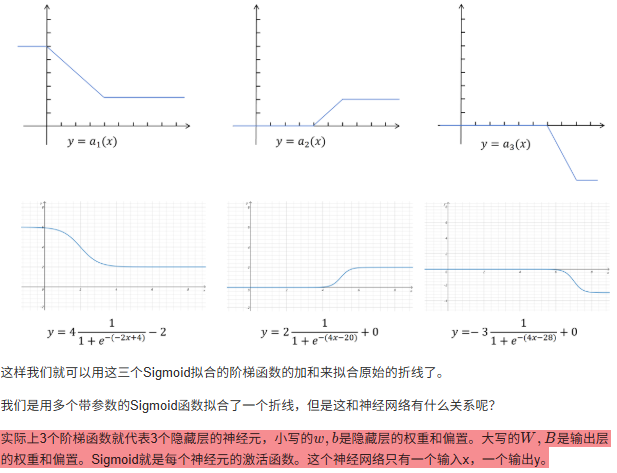
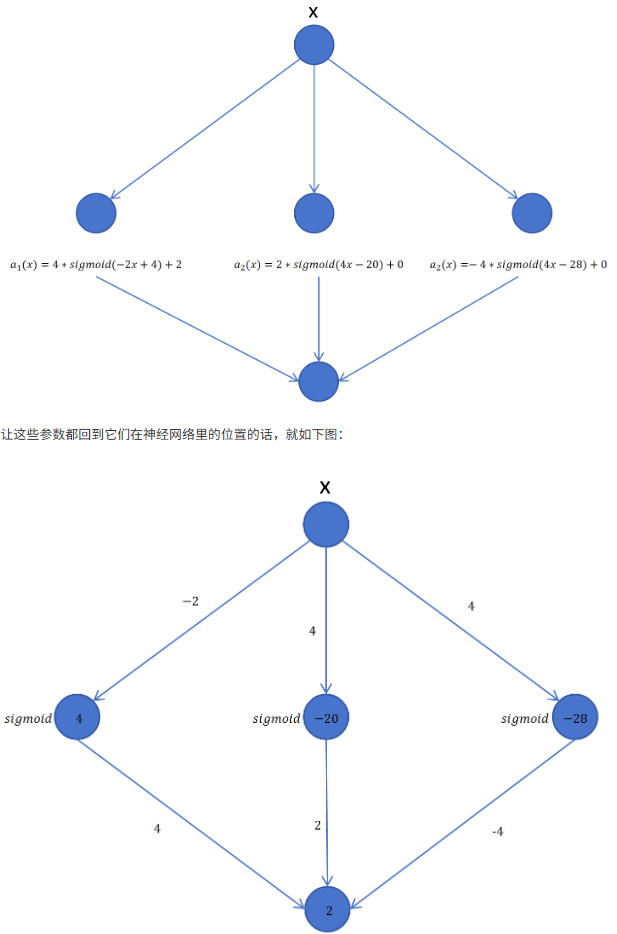
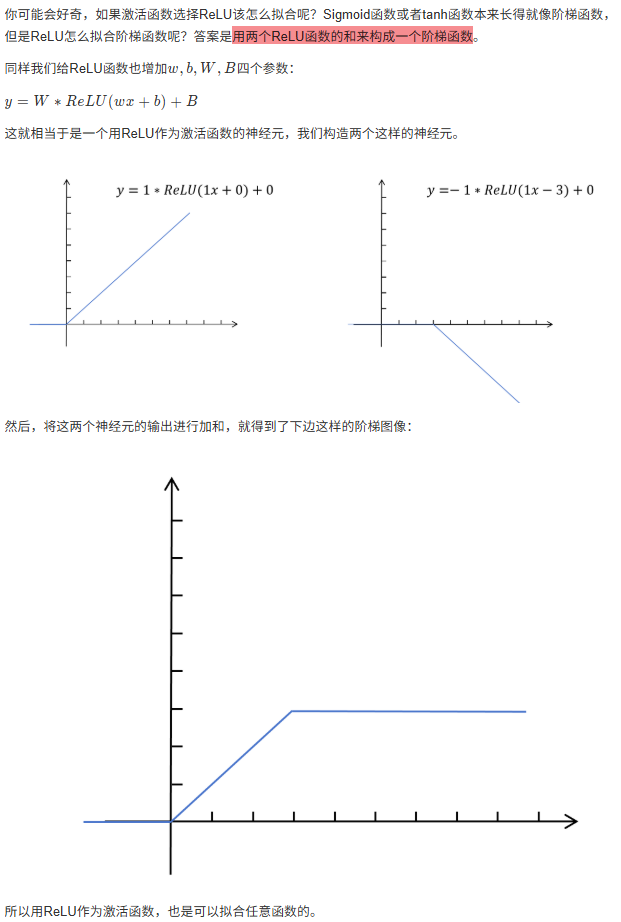
8.3 梯度消失与梯度爆炸
8.3.1 为什么会出现这个问题
本质原因是链式法则的连乘效应:在利用反向传播求解梯度时,需要进行链式法则连乘计算,如果是100层的神经网络,对于第一层的权重的梯度值,就有99个激活函数的导数值连乘,99个权重值连乘。如果这些数都小于1,比如为0.7,100个0.7的连乘约为3.2的乘10的负16次方,导致梯度非常小,几乎消失,让参数无法更新。如果这些数都大于1,比如都为1.5,100个1.5连乘,结果大概是4.1乘10的17次方。导致梯度过大,称为梯度爆炸。不论梯度消失还是梯度爆炸,都会让神经网络无法正常训练,特别是对于深度神经网络
梯度消失 → 网络前面层几乎不学习梯度爆炸 → 参数更新太大,无法收敛
梯度消失的症状:
- 前面层权重几乎不变
- 损失下降非常慢
- 模型性能差
- 只能学到浅层特征
梯度爆炸的症状:
- 损失值剧烈震荡(NaN或inf)
- 权重值变得极大
- 模型完全不收敛
- 可能出现数值溢出
8.3.2 解决方法
8.3.2.1 改进激活函数(最基础)
python
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 100)
# 不同激活函数
sigmoid = 1 / (1 + np.exp(-x))
tanh = np.tanh(x)
relu = np.maximum(0, x)
leaky = np.maximum(0.01*x, x)
# 它们的导数
sigmoid_grad = sigmoid * (1 - sigmoid) # 最大0.25
tanh_grad = 1 - tanh**2 # 最大1.0
relu_grad = (x > 0).astype(float) # 0或1
leaky_grad = np.where(x > 0, 1, 0.01) # 1或0.01✨对于tanh函数:虽然tanh函数最大值是1.0,但当其输入小于-4或者大于4时,梯度就非常接近0了,所以在训练时要非常小心,确保让tanh函数的输入不能偏离0太远
✨综上,Relu函数只要输入大于0,导数值恒等于1,输入小于0,导数值为0,神经元处于抑制状态。所以ReLU更适合用在深度神经网络里,几乎成为深度神经网络默认的激活函数
8.3.2.2 权重初始化
✨对于深度神经网络而言,参数的正确初始化也非常重要,因为我们通过前边的例子可以看到,梯度值公式里也有很多权重值相乘。如果权重值初始化为很小的值,或者很大的值,那么也会出现梯度爆炸或者梯度消失的问题
✨ 消除对称性 :参数初始化一定要随机,如果某一层的神经元的参数都设置为同样的初始值。因为对于同一层的不同神经元,它们的输入是相同的,如果参数也相同,则输出也相同,反向传播的梯度也相同,每次参数更新后的值也一样,多个神经元就失去了差异性。所以初始化参数时一定要随机,来消除神经元之间的对称性
✨ 控制方差 :一般神经网络的输入都经过了标准化,输入都是均值为0,方差为1的变量。我们可以通过随机生成均值为0,方差为1的参数值来初始化网络参数。但是有个问题,就是我们希望神经网络正向传播时,每一层输出的方差不变,保持稳定
✨方差一致的好处:
- 梯度稳定:反向传播时梯度不会消失/爆炸
- 学习率统一:所有层可以用相同的学习率
- 收敛更快:信号能有效传播
python
# 不同激活函数的敏感区间:
sigmoid: 在0附近梯度最大(0.25),两端饱和(梯度≈0)
tanh: 在0附近梯度最大(1.0),两端饱和(梯度≈0)
ReLU: 正区间线性,负区间死亡
# 如果方差太小:
# 激活值集中在0附近 → sigmoid/tanh能工作,但ReLU可能全为负(死亡)
# 如果方差太大:
# 激活值分散到两端 → sigmoid/tanh饱和(梯度消失)
# 理想情况:
# 激活值分布在激活函数的"活跃区间"
python
# 激活函数 vs 初始化方法对照表
activation_init_map = {
# 激活函数 推荐初始化 原因
'sigmoid': 'xavier', # 对称,在0附近线性
'tanh': 'xavier', # 对称,在0附近线性
'relu': 'he', # 非对称,杀死一半神经元
'leaky_relu': 'he', # 类似ReLU但负区间有小斜率
'elu': 'he', # 类似ReLU但负区间平滑
'selu': 'lecun_normal', # 自归一化网络专用
'linear': 'xavier', # 纯线性
}
python
# ReLU会"杀死"一半的神经元(负值输出0)
# 所以有效神经元数减半
# 前向传播方差:
# 对于ReLU:E[a^2] = 0.5 * Var(z) (因为一半为0)
# 所以:Var(z^[l]) = n^[l-1] * Var(W) * 0.5 * Var(z^[l-1])
# 要保持方差一致:n^[l-1] * Var(W) * 0.5 = 1
# 因此:Var(W) = 2 / n^[l-1]
# He初始化:
W ∼ N(0, √(2/fan_in)) # 前向传播稳定
# 或考虑反向传播:W ∼ N(0, √(2/fan_out))8.3.2.3 其他方法
✨ 批量归一化方法
✨残差连接网络结构设计
9 优化深度神经网络
9.1 L1和L2正则化
9.1.1 L1正则化------参数绝对值

9.1.2 L2正则化------参数平方
内容同6.2.3

9.1.3 L1正则化与L2正则化区别

9.1.4 pyTorch添加正则化
python
l2_norm = 0.0
for param in model.parameters():
l2_norm += param.pow(2).sum()
loss = criterion(outputs, labels) + 1e-4 * l2_norm9.2 指数加权平均
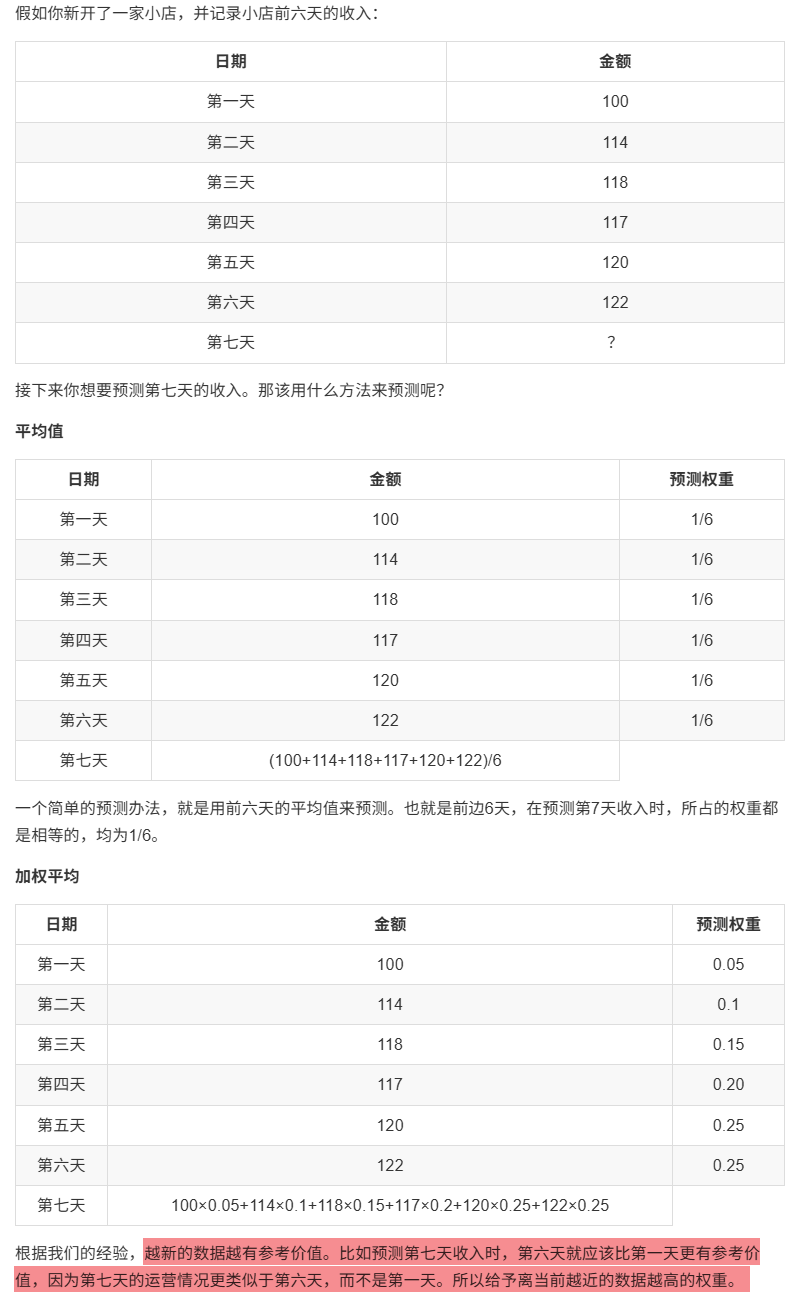

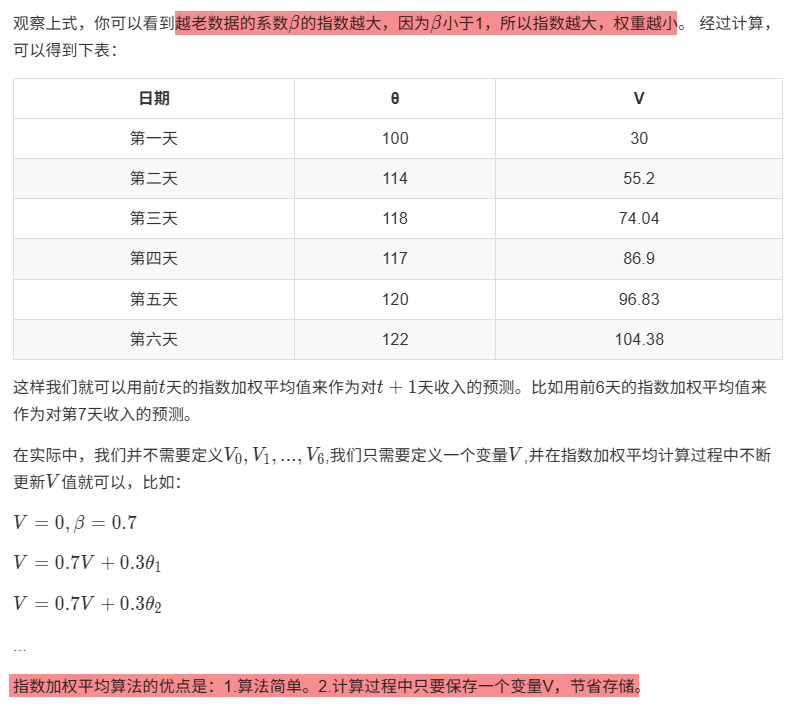
指数加权平均算法改进
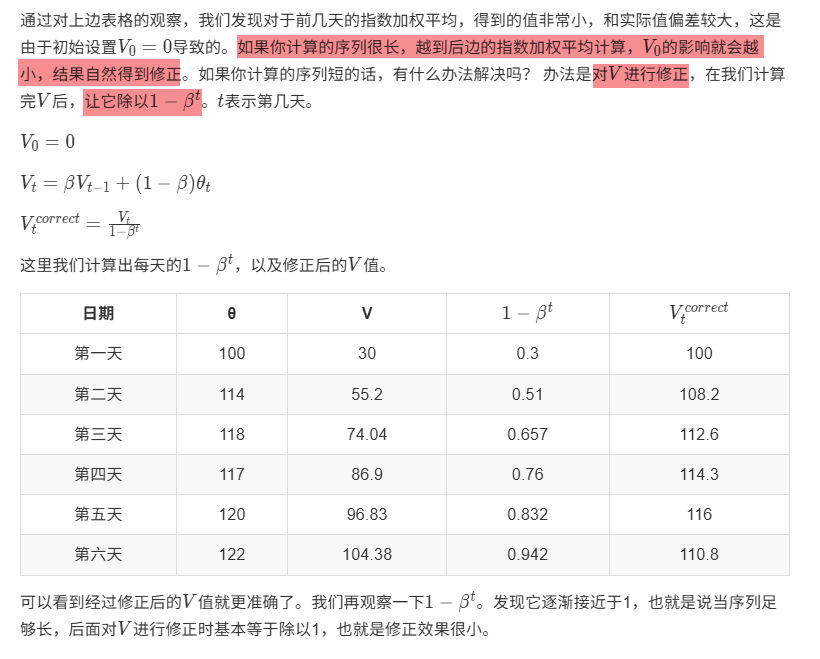
9.3 动量梯度下降Momentum
动量梯度下降算法(Momentum Gradient Descent)是对标准的随机梯度下降(SGD)的一种改进,它可以让训练更稳定且迅速
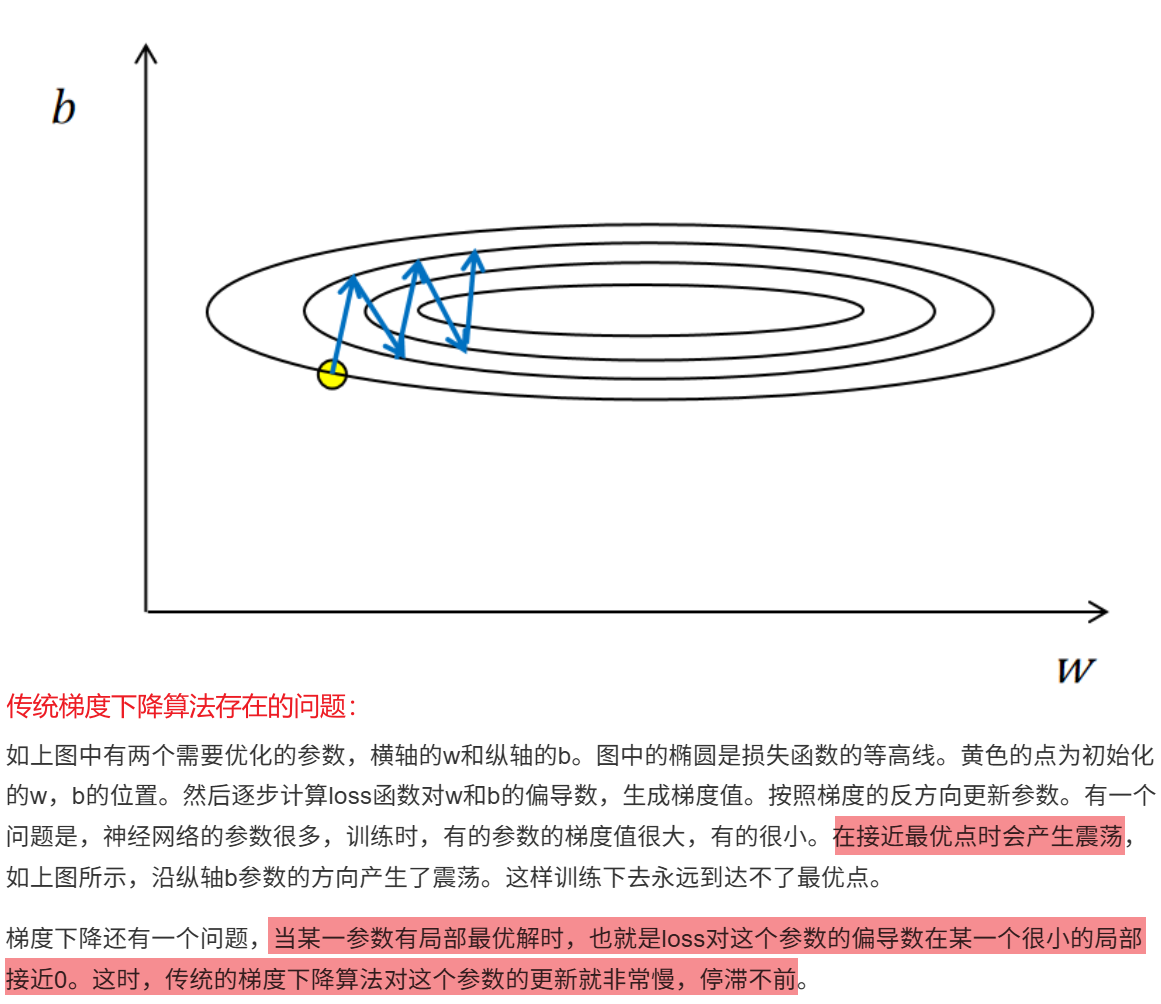
9.3.1 动量梯度下降原理

9.3.2 动量梯度下降更新过程

9.4 RMSProp优化器

9.5 Adam优化器

9.6 权重衰减


9.7 Dropout
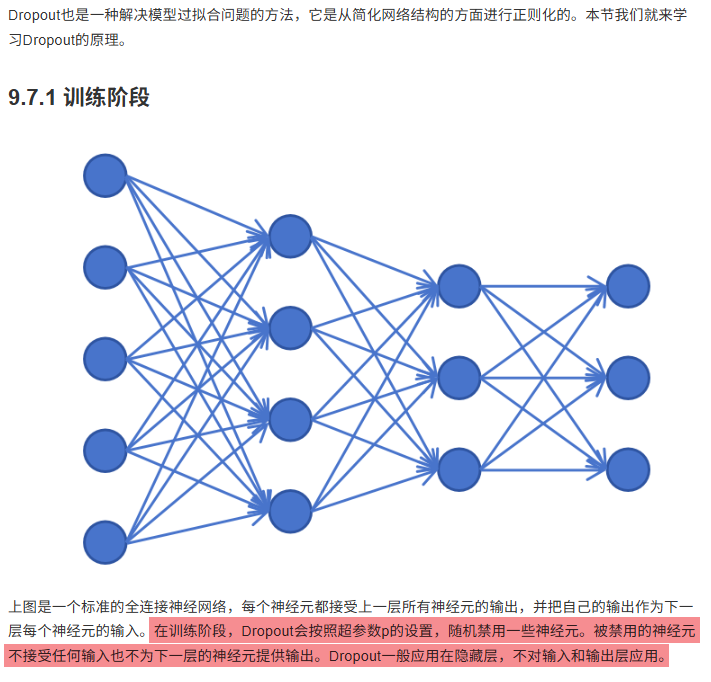
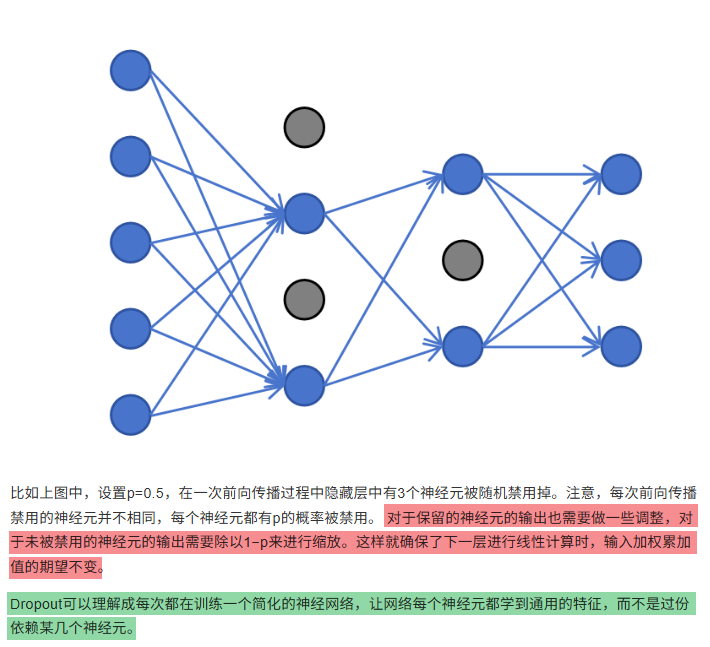
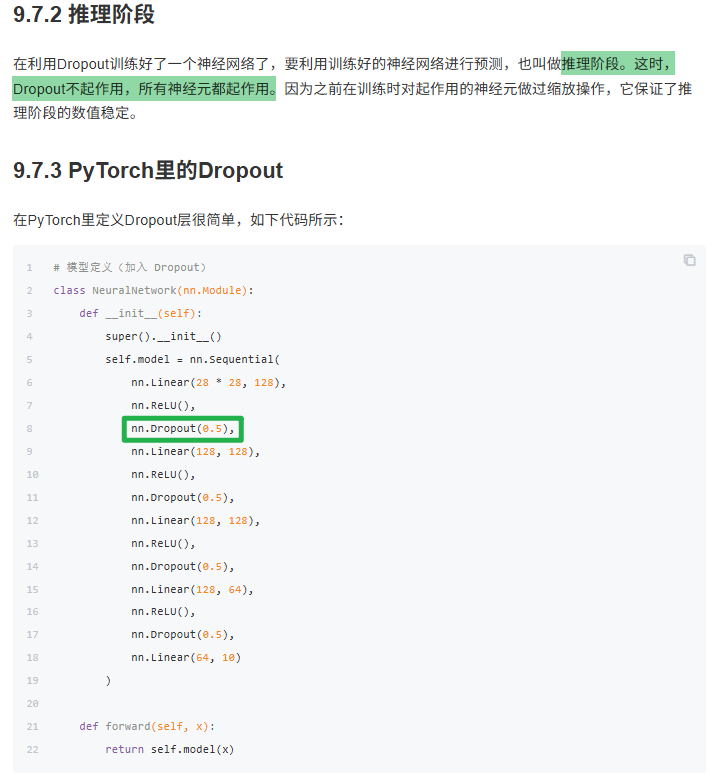

9.8 批量归一化
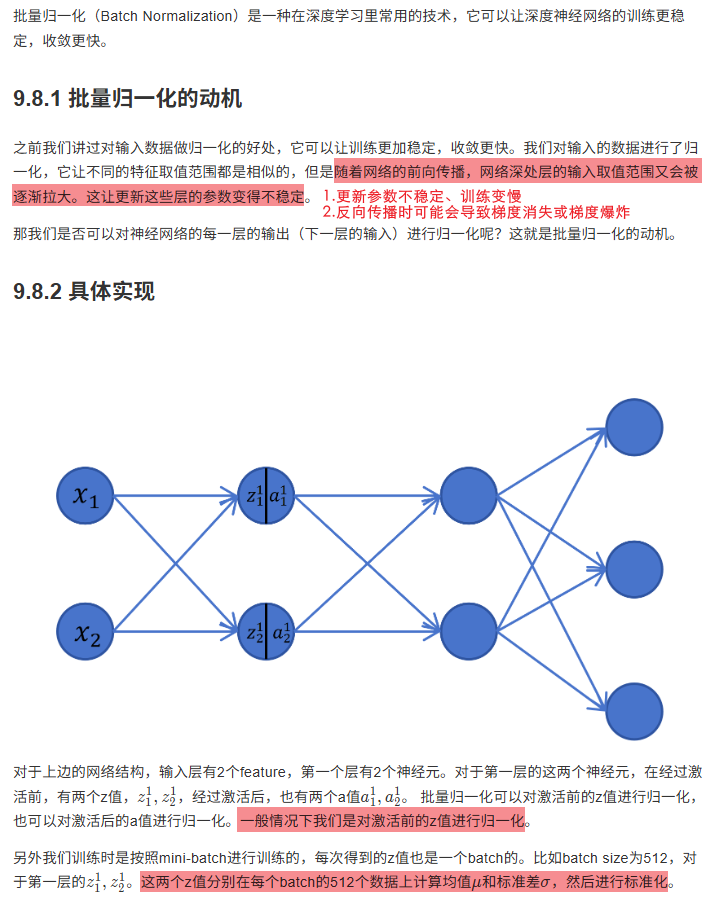


10 卷积神经网络
视觉问题特点
1.
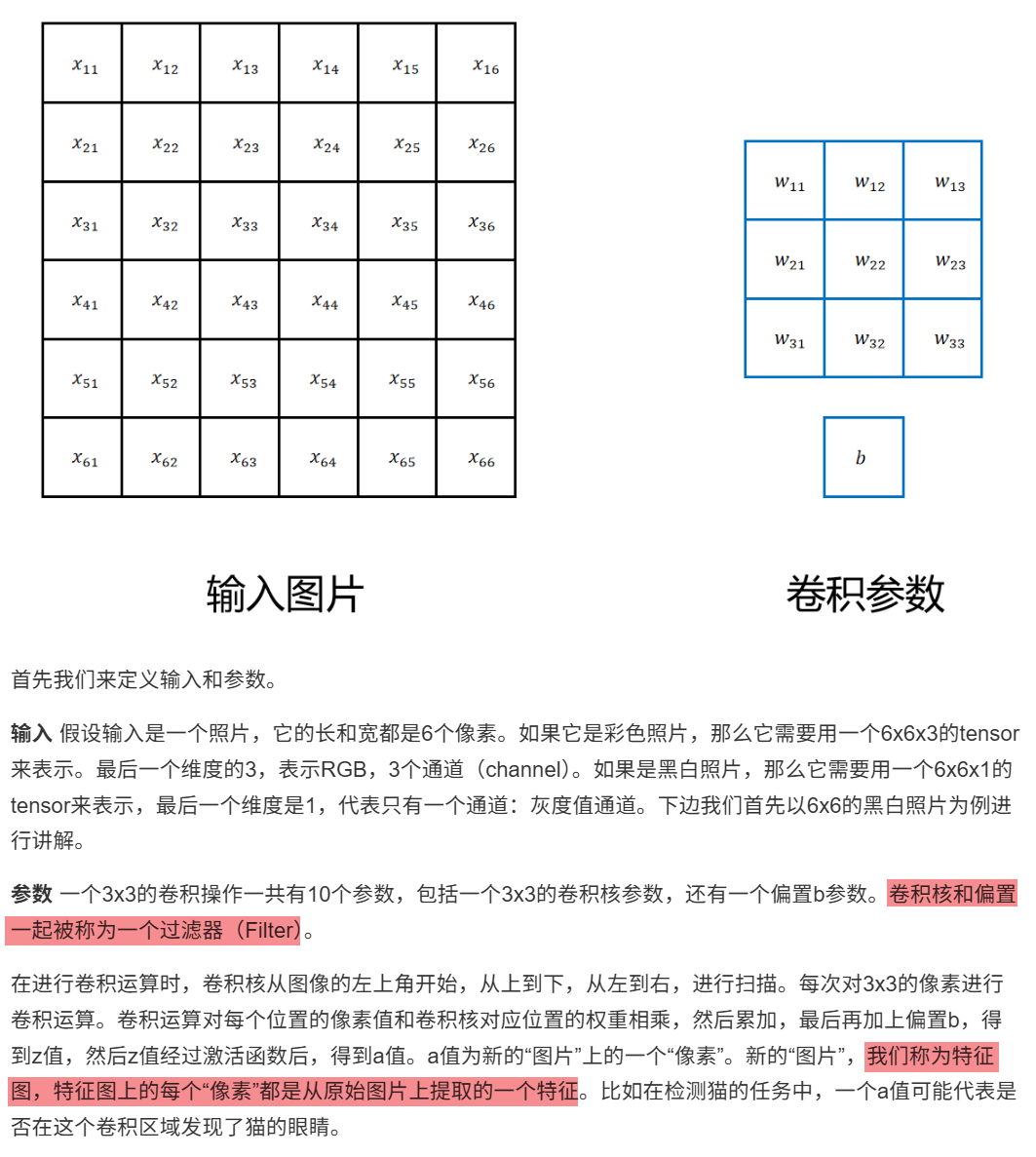
特征要素多:彩色图片每个像素有(R,G,B)三个值,如果一个图片长宽为1000x1000个像素的彩色图片,如果我们构造一个神经网络来处理这个图片,它的输入特征有300万个,如果隐藏层为1000个神经元,输出层为1个神经元,那么这个网络将有30亿个参数,以Float32来存储,模型大小为12GB。这么大的模型推理一次的运算代价是非常大的
2.局部性:在图像里局部区域内的像素构成了重要的特征,每个像素和它周围局部区域内的像素关系紧密。比如我们识别一只猫,只要观察这个猫在图片里的区域就可以确定,无需依赖其他地方的像素信息。如果我们用全连接神经网络,每个神经元都是和所有输入像素相连的。隐藏层的神经元判断一个特征,只需要局部像素就可以,没有必要用全部的像素。这些没有必要的连接浪费了大量的权重参数
3.平移不变性:不论一只猫在图片的左上角还是右下角。都不改变它是一只猫的语义信息。在计算机视觉中,语义信息是指图像中所表达的高层次、具有人类可理解意义的内容。如果我们训练了一个神经元,它可以接入局部的像素信息,识别一个猫,那么它就可以被重复使用,识别图片任意区域的猫。
10.1 卷积操作
10.1.1 卷积操作过程
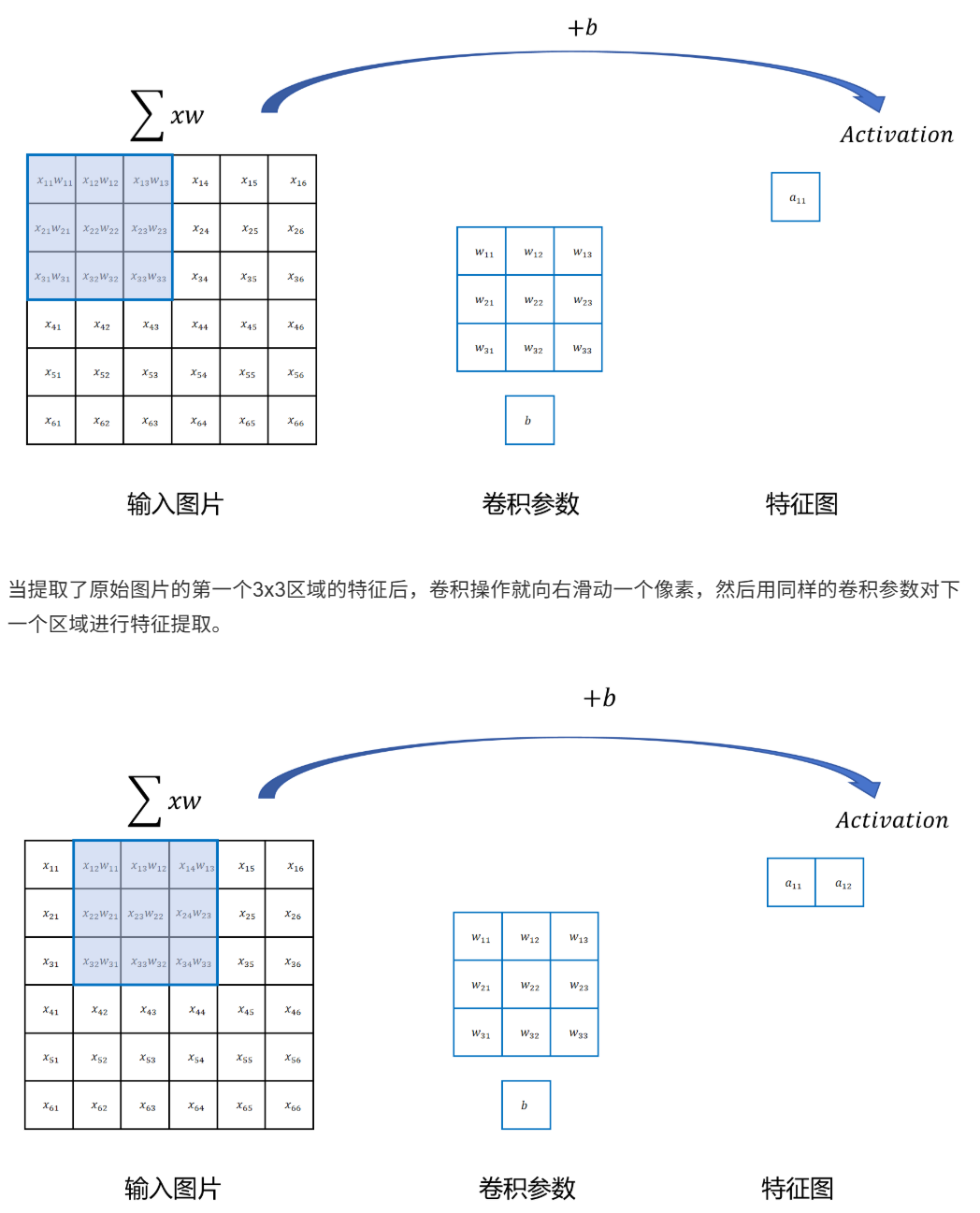
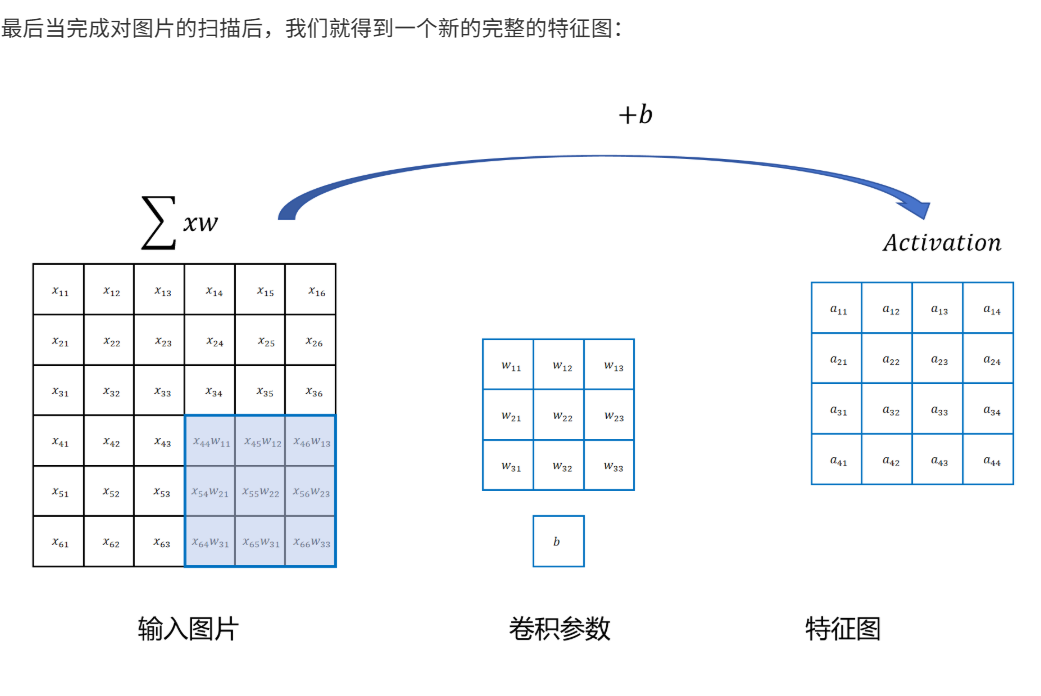
10.1.2 卷积操作优点
卷积操作完美解决了视觉问题的三个痛点
1.图片输入特征多:图片输入特征多,但是一个3x3的卷积操作只有10个参数,就可以对整个图片进行扫描。2.
特征局部性:卷积操作的每个运算只在特定相邻区域内进行,并不要所有输入特征都参与运算。3.
平移不变性:卷积操作在整个图片上进行滑动检测,就是假设图片的特征具有平移不变性。
所以对于一个3x3的卷积操作,它只用10个参数就可以在任意大的图片上提取特征
10.1.3 多通道卷积操作
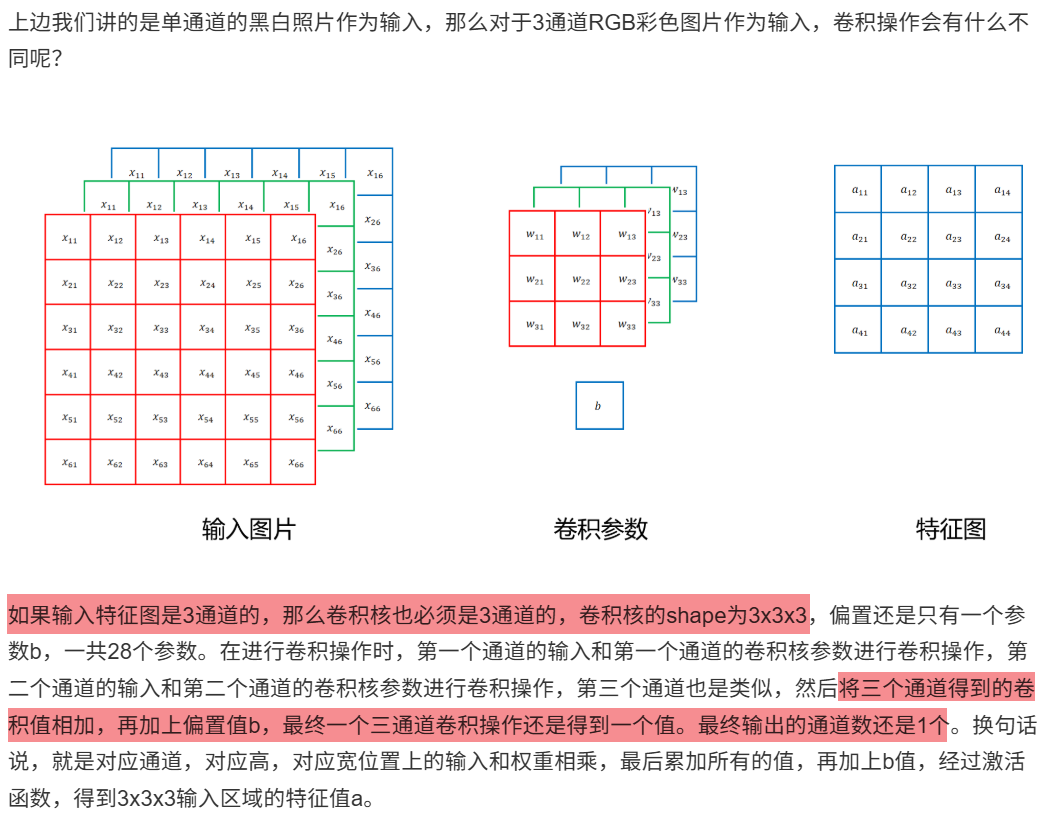
10.1.4 多Filter操作
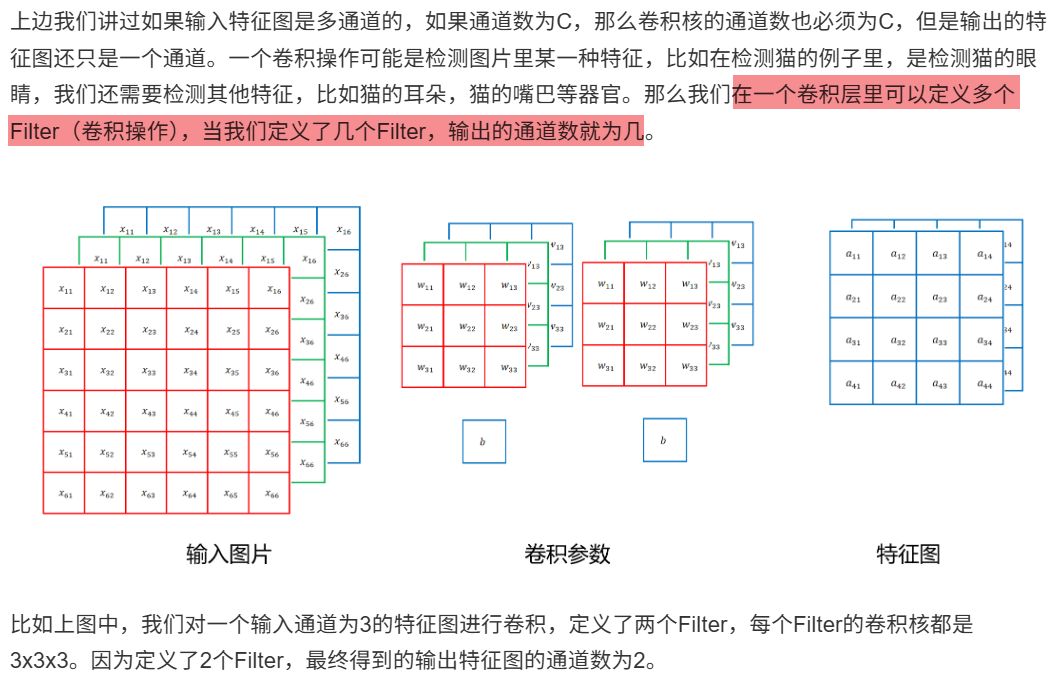
10.1.5 定义多个卷积层

10.1.6 PyTorch 里的特征图的表示

10.2 进阶的卷积操作
10.2.1 感受野
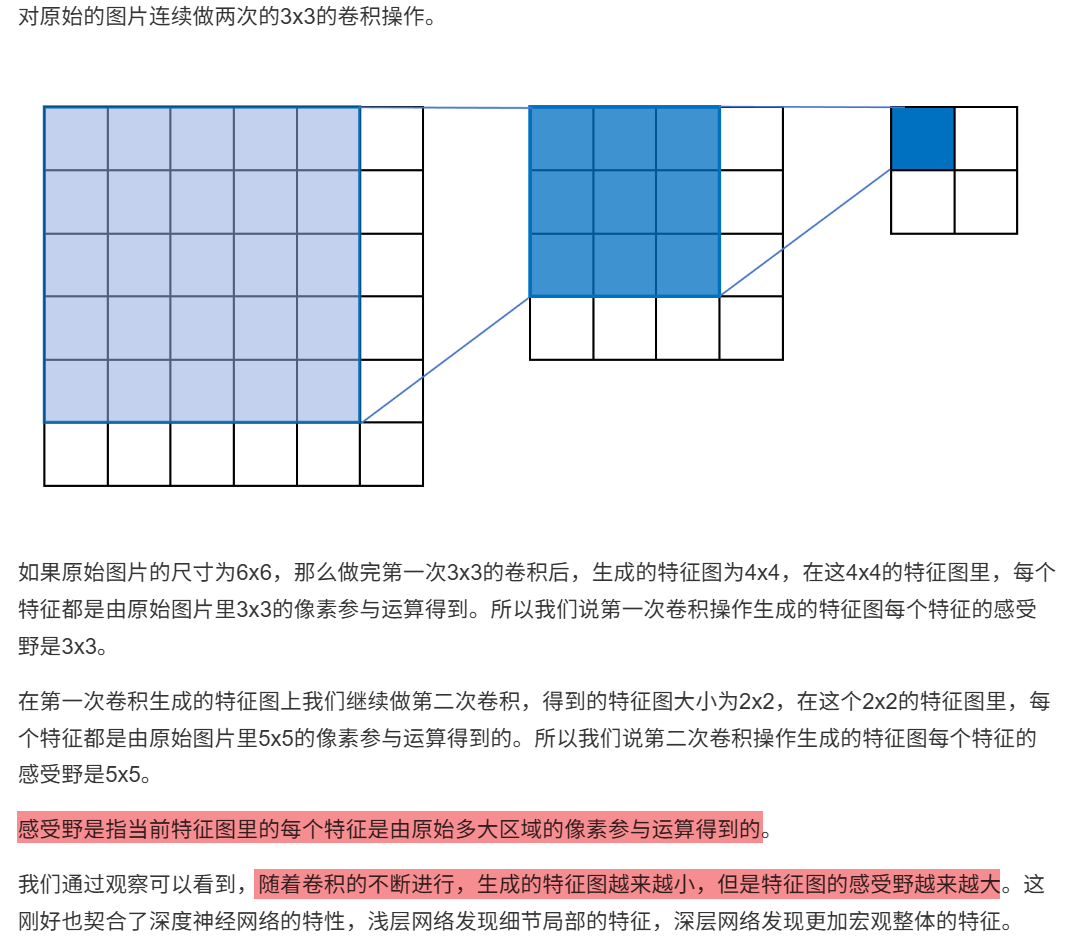
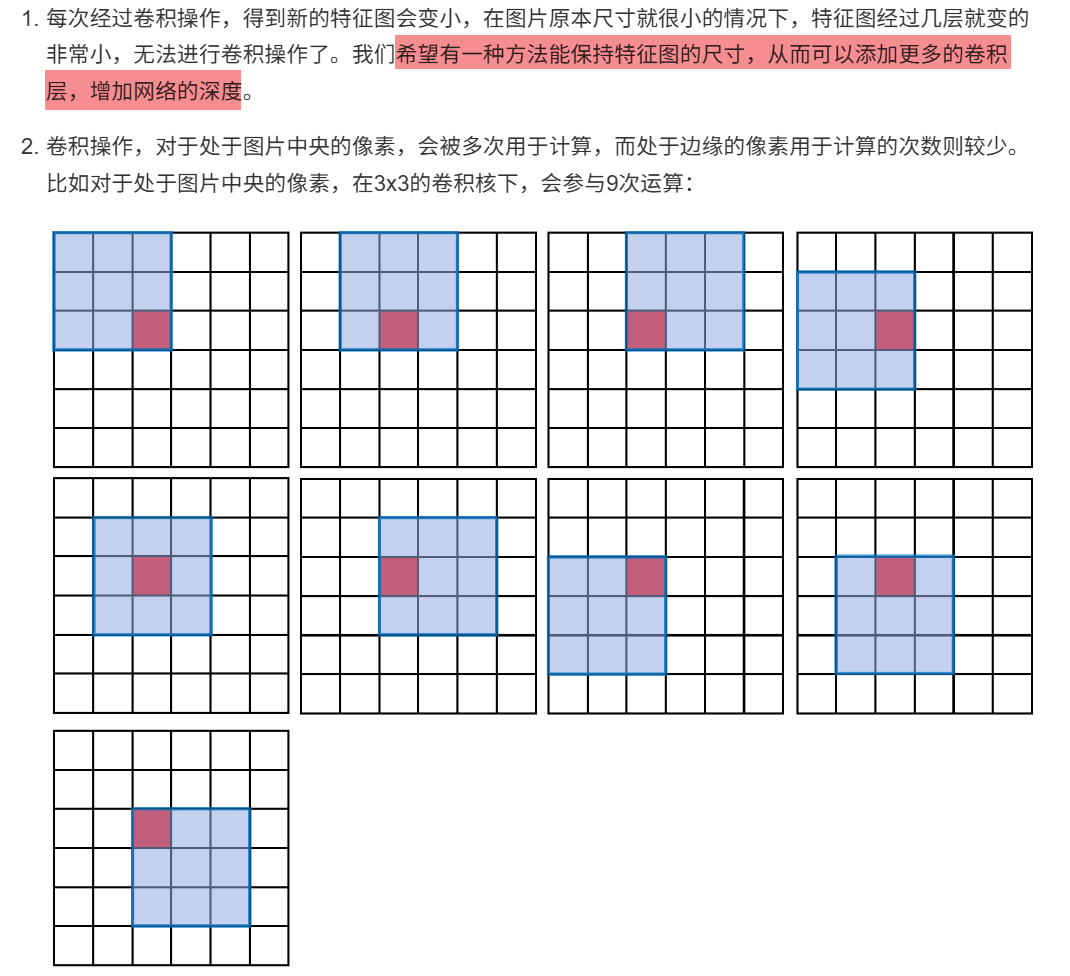
10.2.2 卷积核的大小

10.2.3 步长

10.2.4 Padding
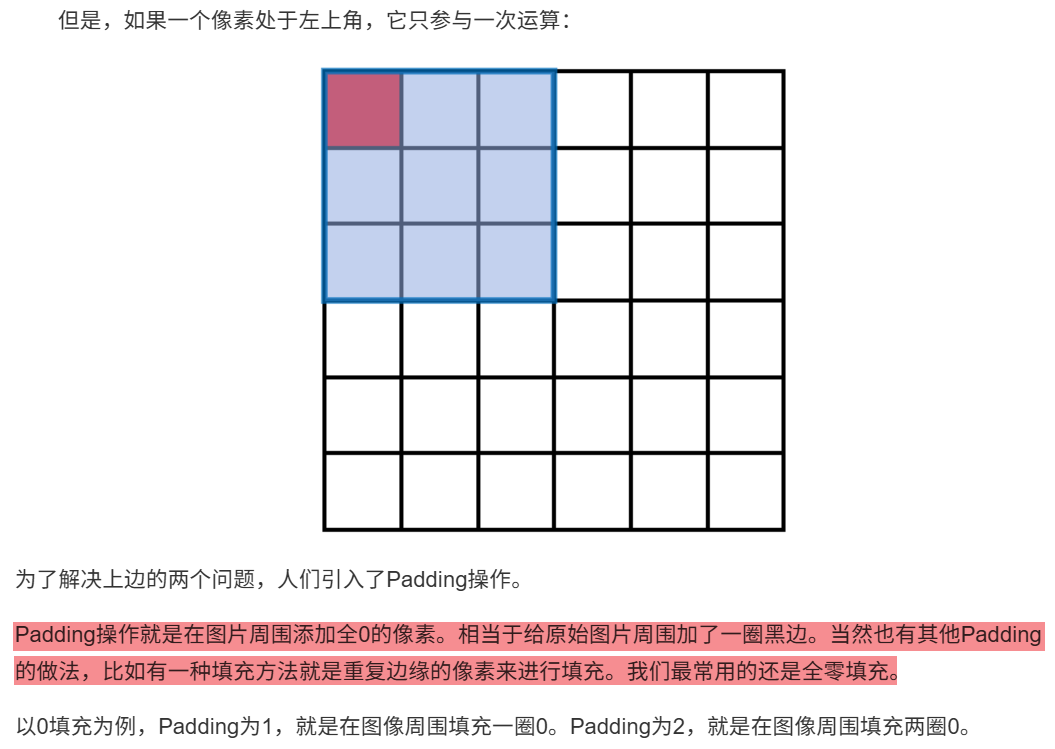

10.3 池化层
10.3.1 最大池化操作
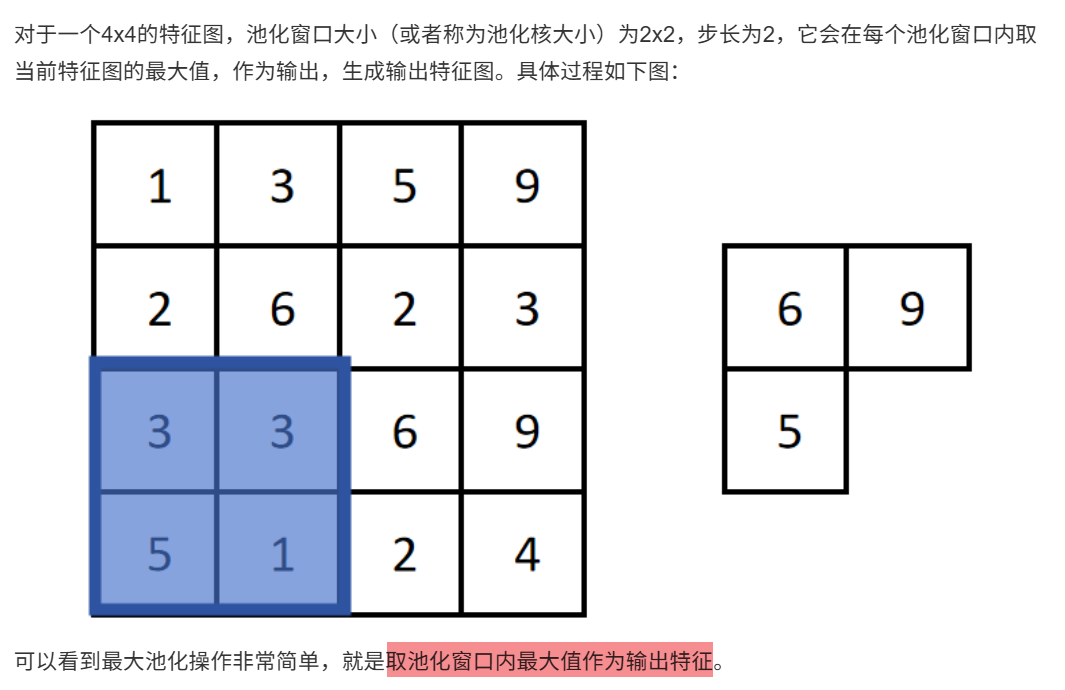
10.3.2 池化操作的作用

10.3.3 多通道池化层

10.3.4 和卷积层相比

10.3.5 平均池化操作

10.4 一个完整的卷积神经网络
10.4.1 使用全连接层
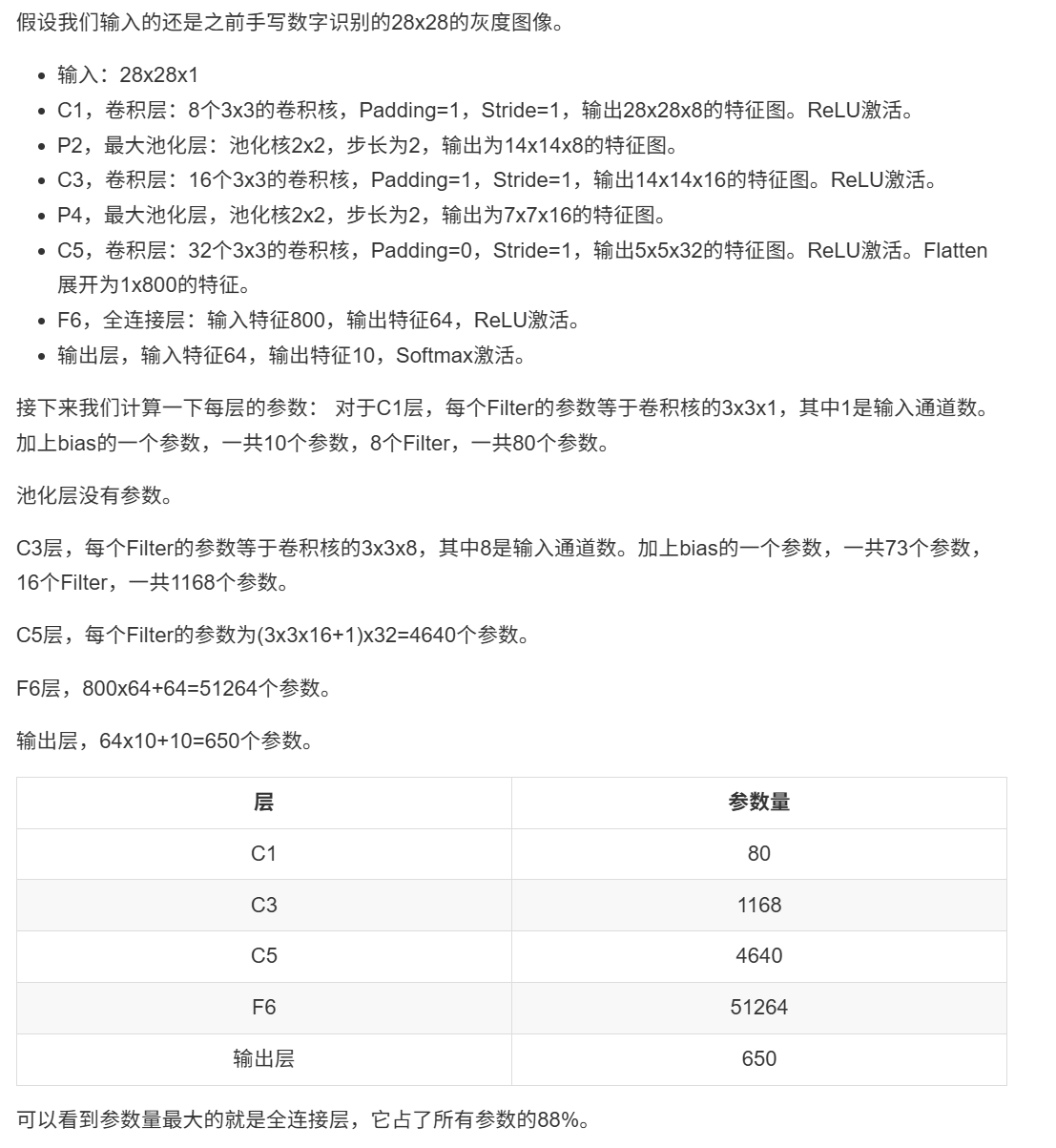
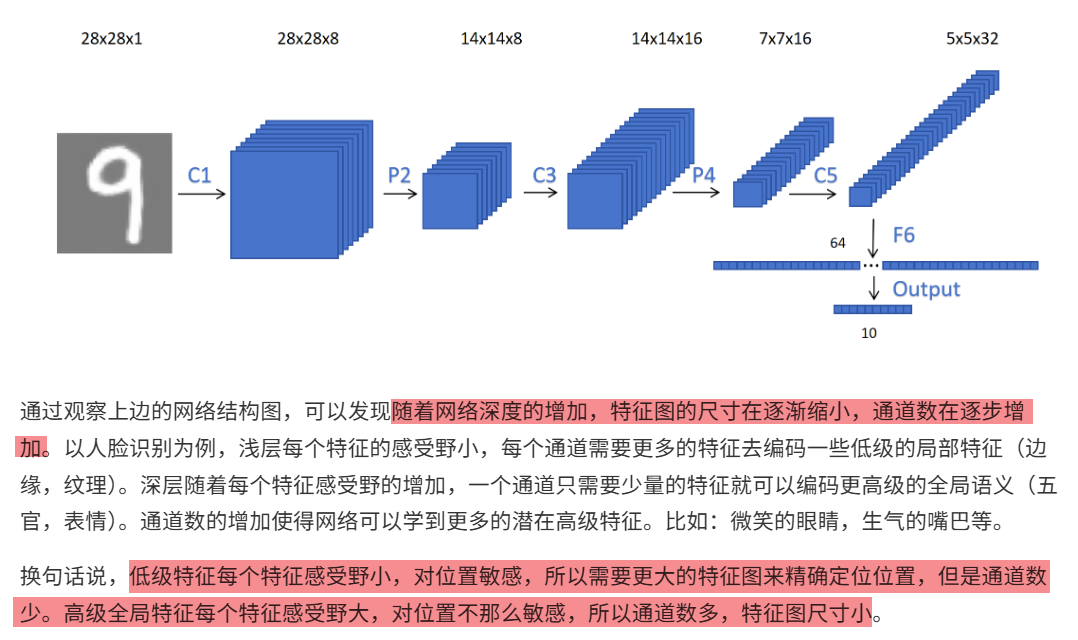
10.4.1 1乘1卷积和全局平均池化层
10.4.1.1 1乘1卷积
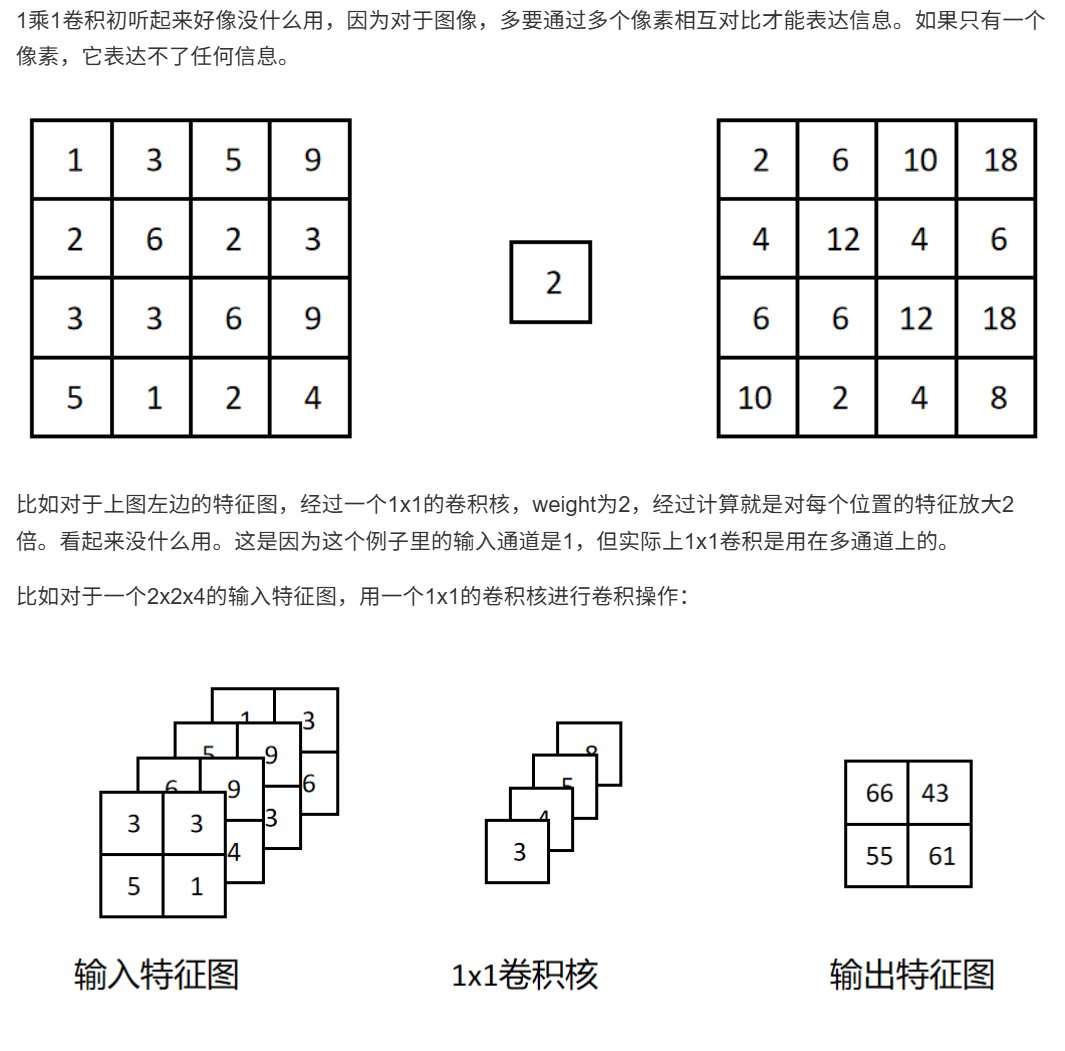
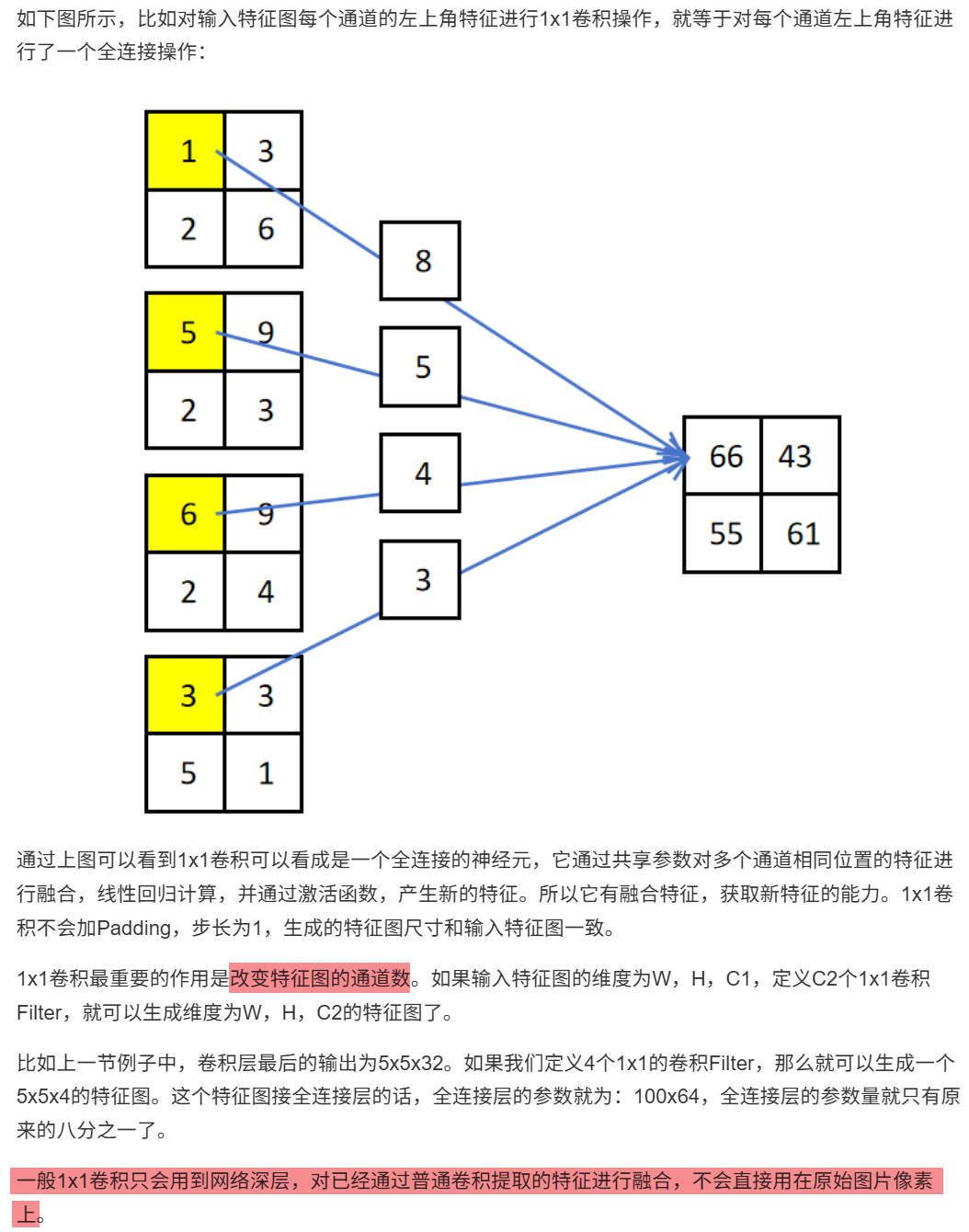
10.4.1.2 全局平均池化层

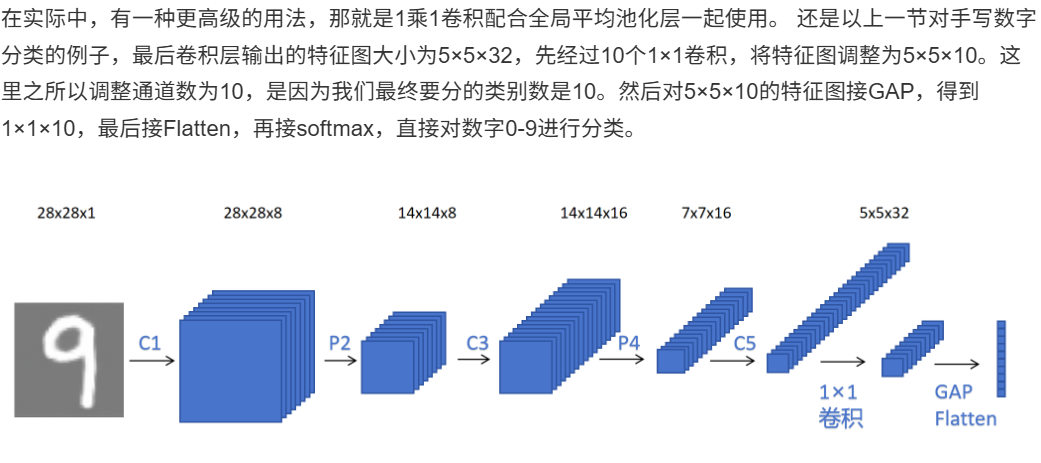
10.4.1.3 两者配合使用
10.4.1.4 去掉全连接层的好处

10.5 图像增强

具体内容:[图像增强](https://www.rethink.fun/chapter10/%E5%9B%BE%E5%83%8F%E5%A2%9E%E5%BC%BA.html)
11 自然语言处理(NLP)
11.1 NLP常见任务
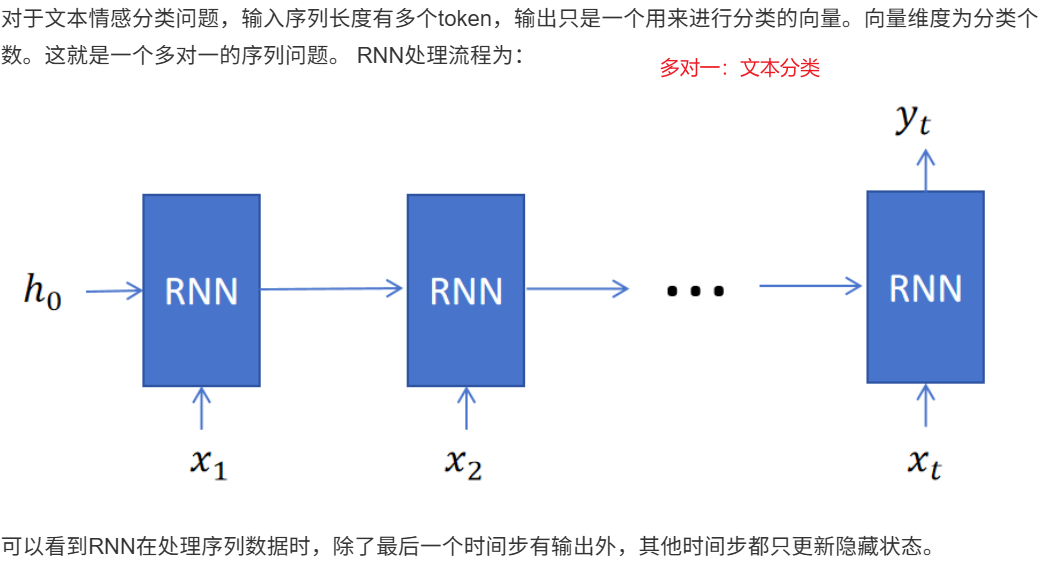
11.1.1 文本分类

11.1.2 文本回归

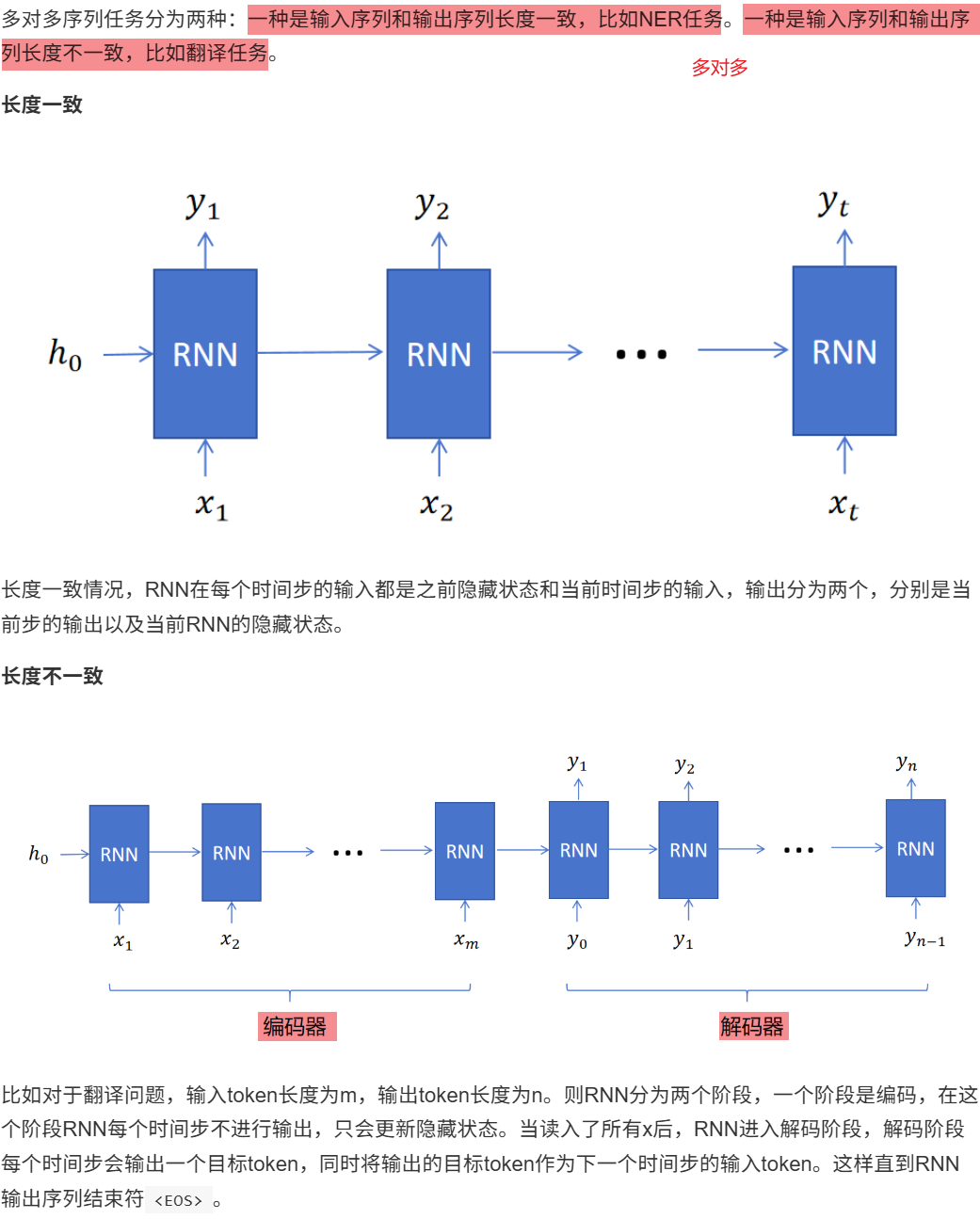
11.1.3 命名实体识别(NER)

11.1.4 翻译、摘要

11.1.5 文本蕴含

11.1.6 语言模型


11.2 词典生成

11.2.1 利用现成的词典

11.2.2 特殊的Token

11.2.3 词典大小的设计

11.2.4 字节对编码(BPE)
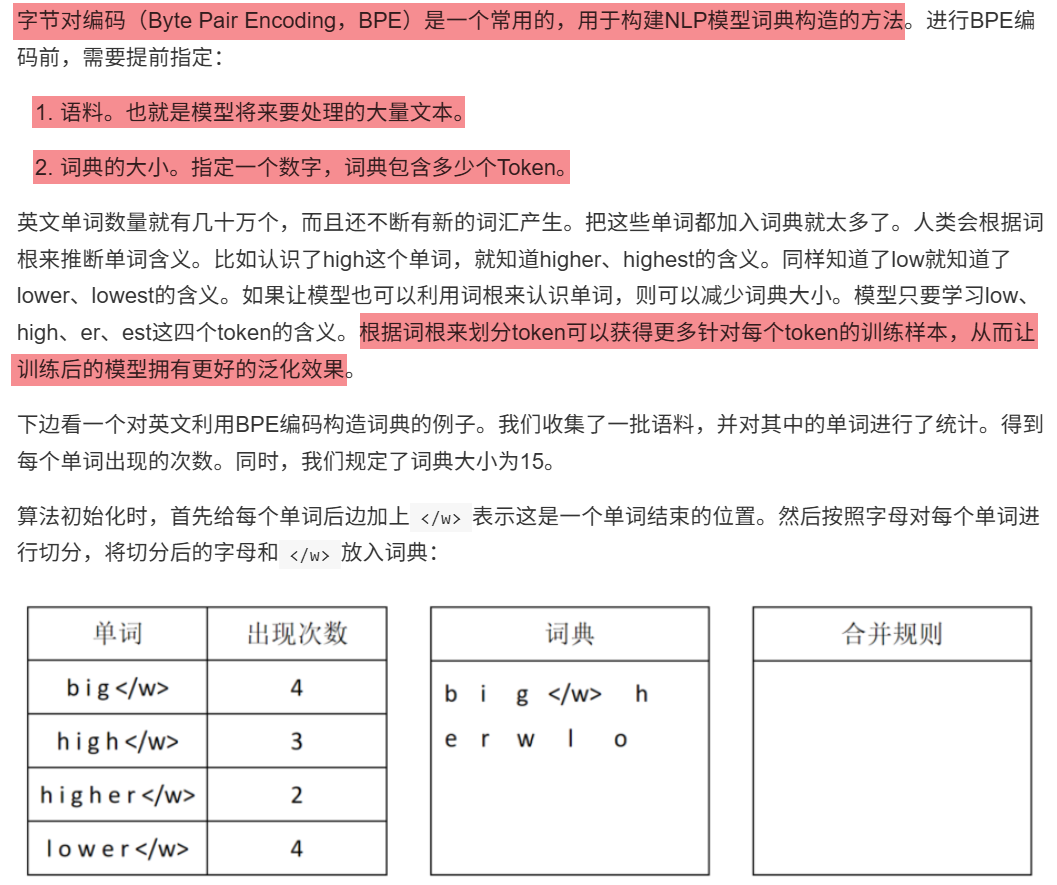
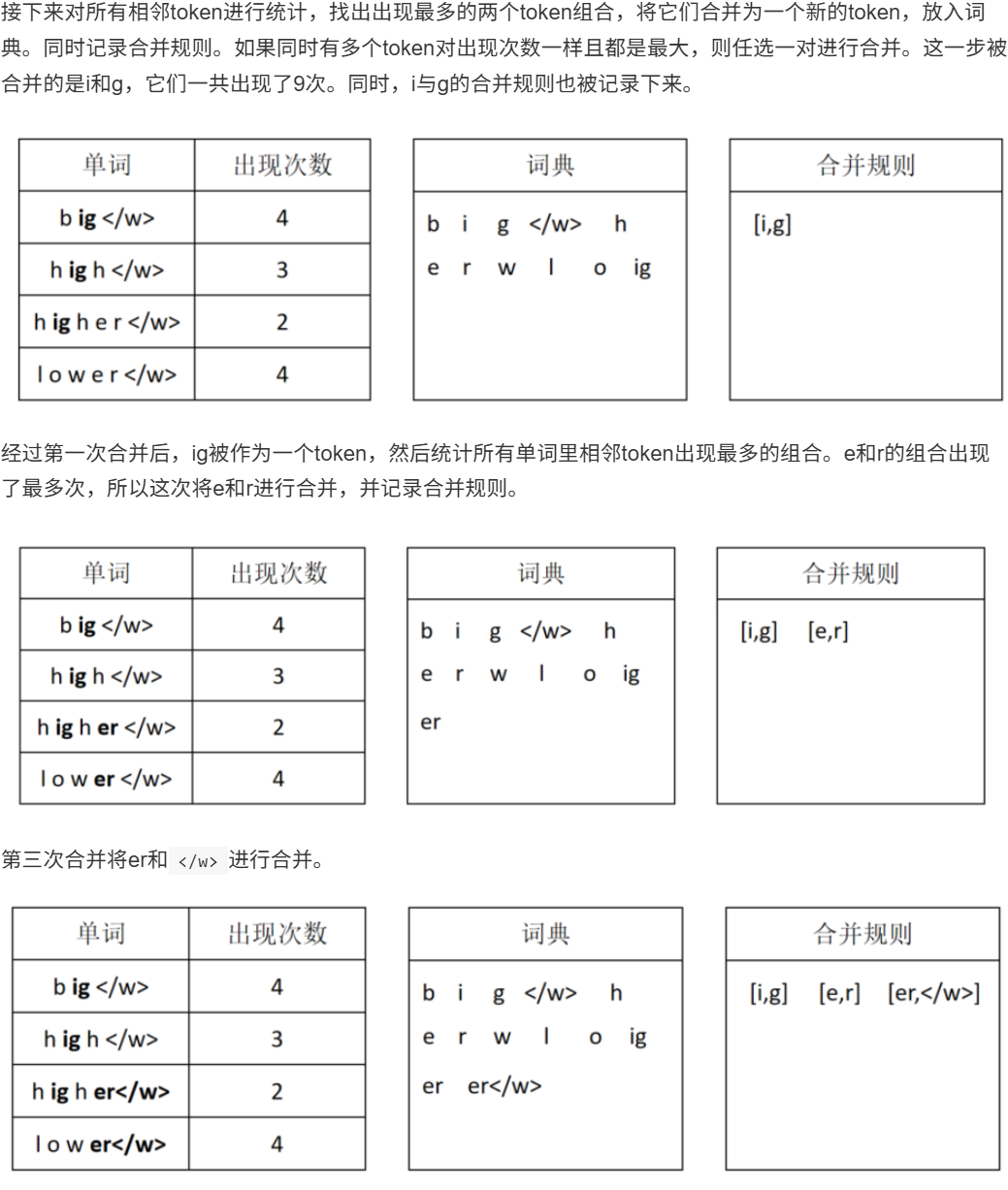

11.3 Token编码

11.3.1 独热编码

11.3.2 词嵌入
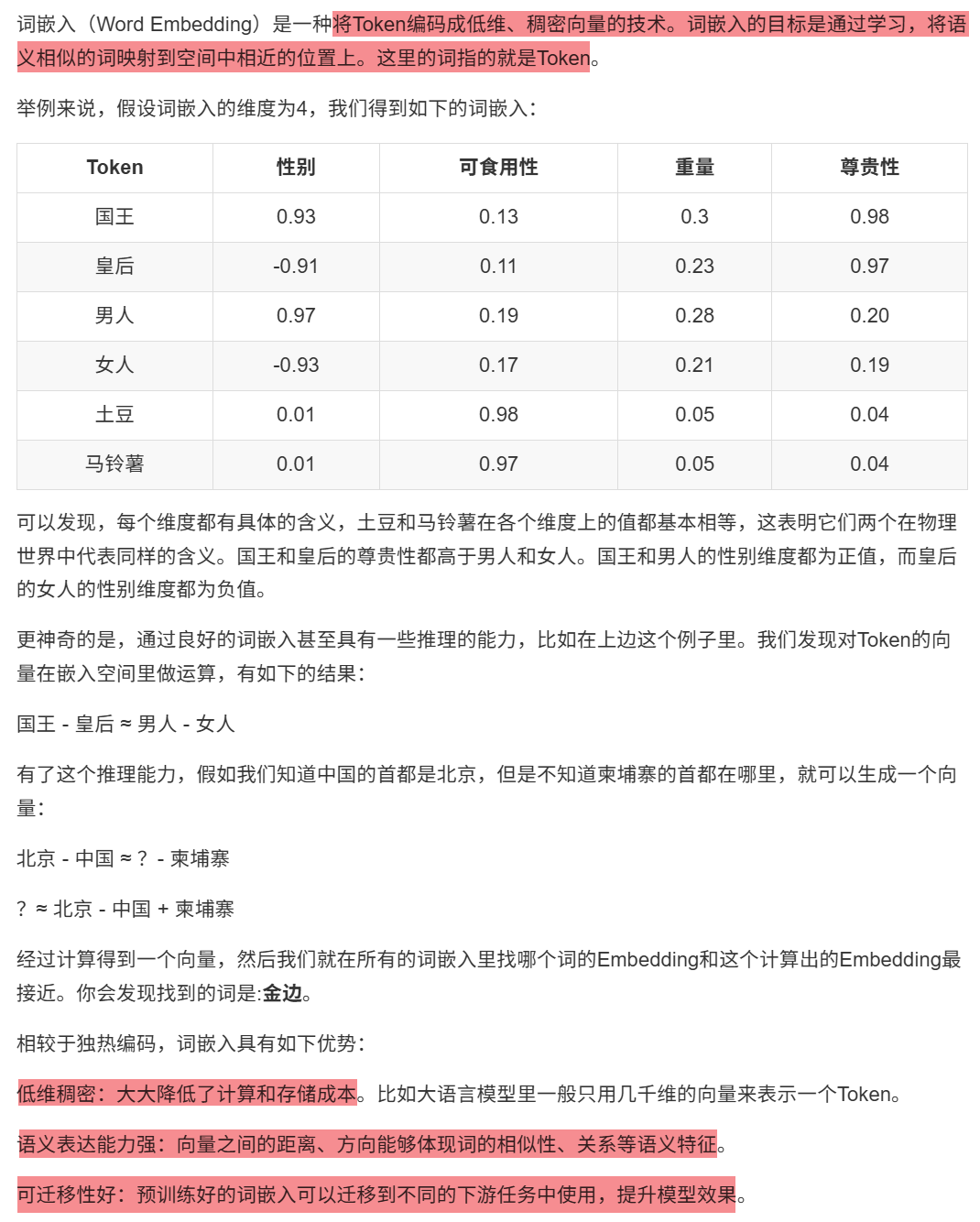

10.3.2.1 CBOW

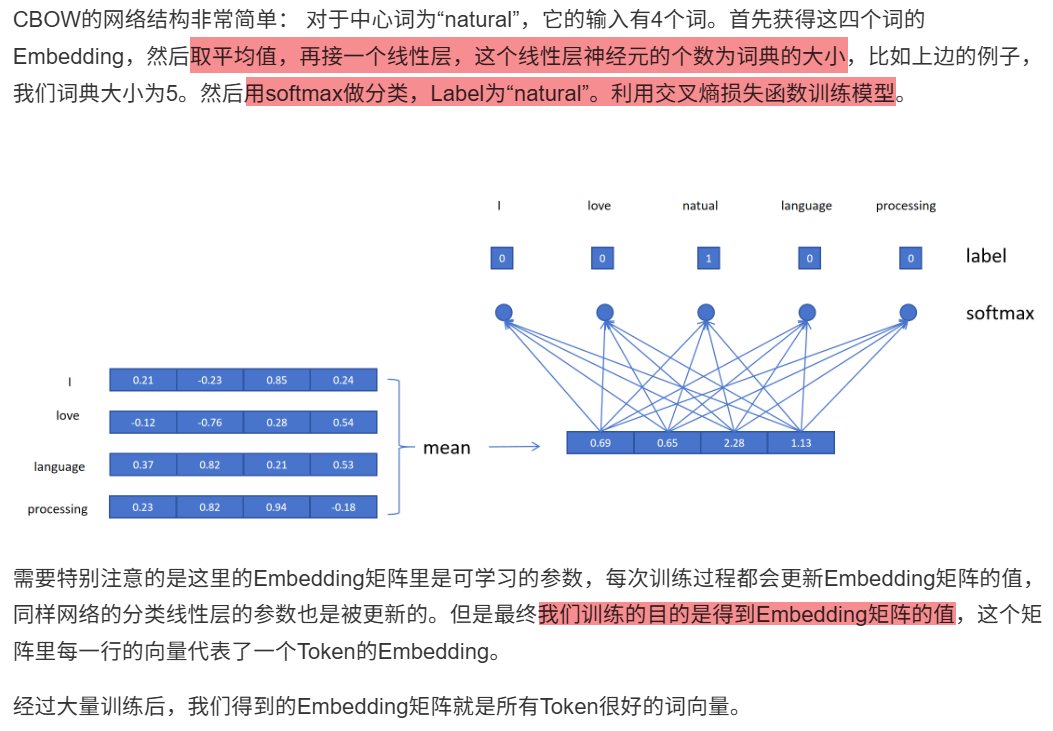
10.3.2.2 Skip-gram
11.4 语言模型采样

11.4.1 概率最大生成策略

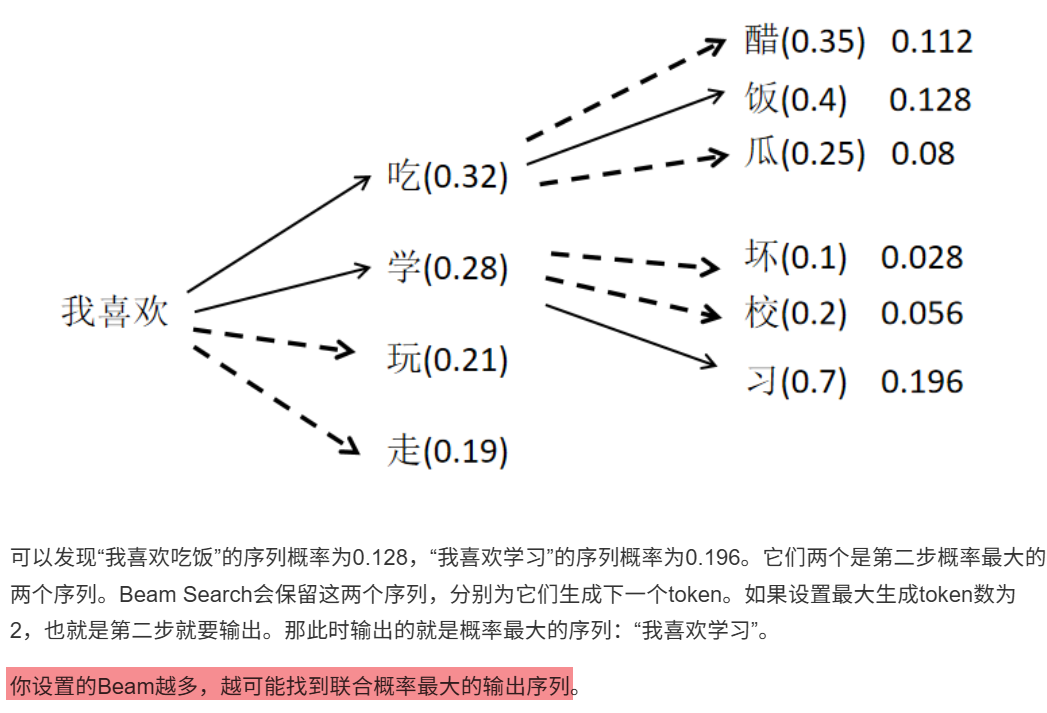
11.4.2 随机生成策略

12 循环神经网络
12.1 RNN

12.1.1 RNN网络结构
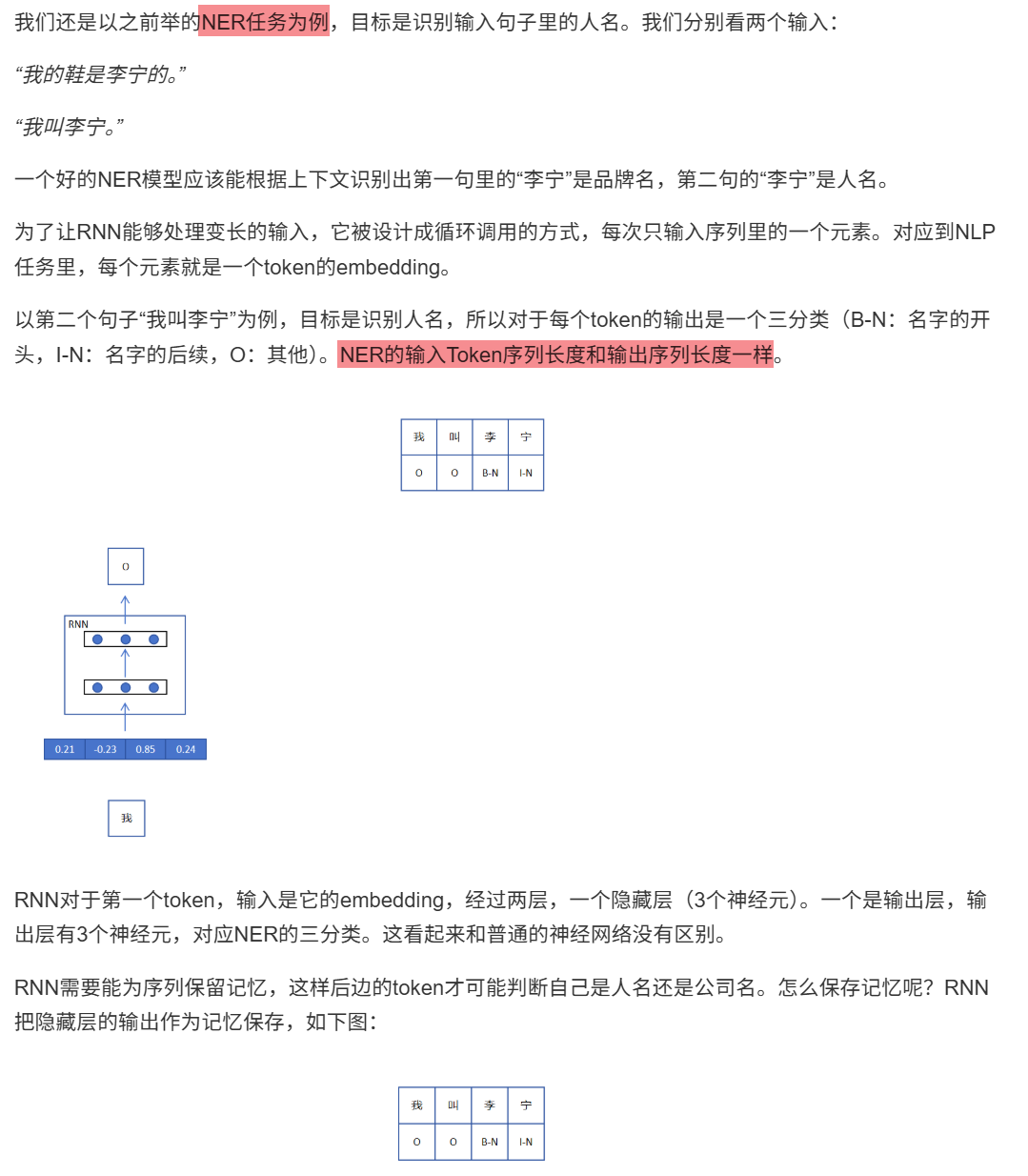
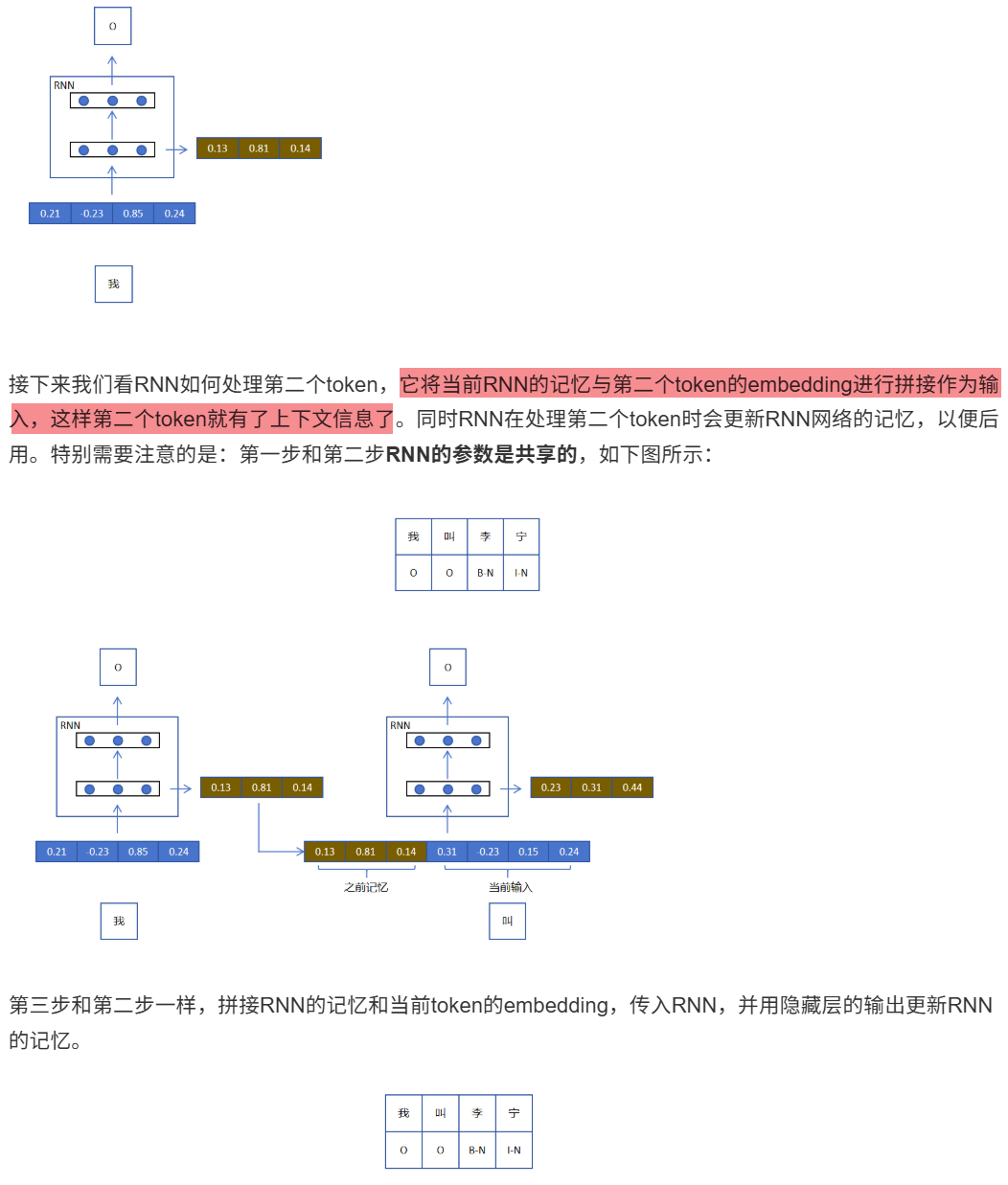
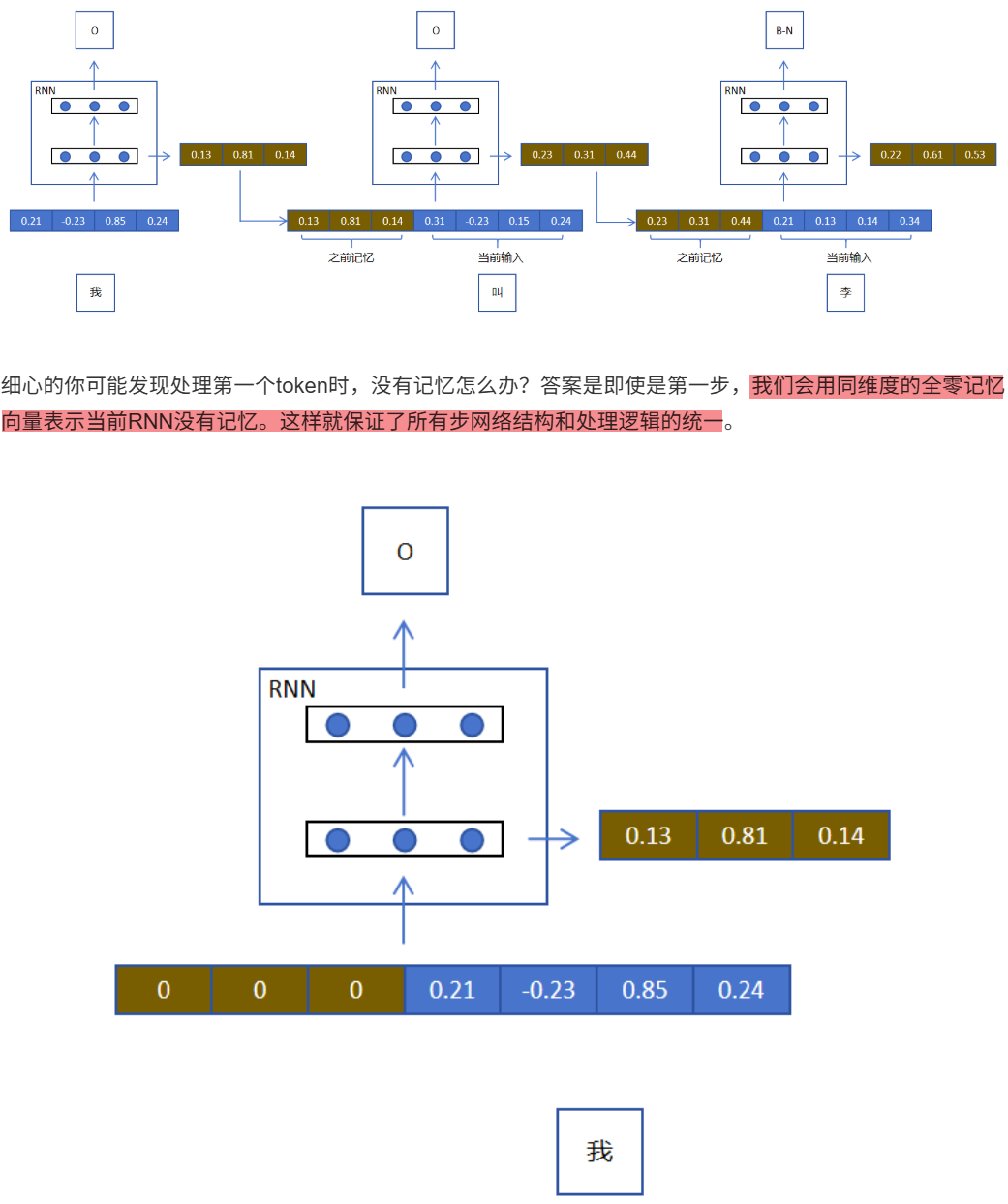

12.1.2 循环层和普通层
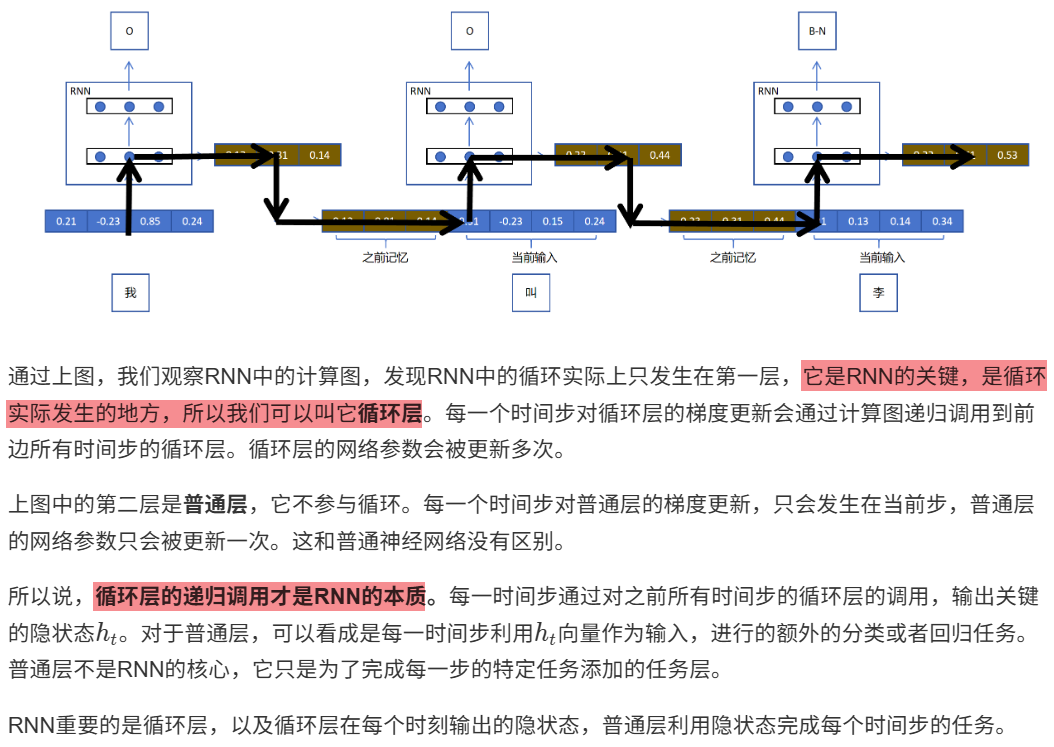
12.1.3 RNN优势

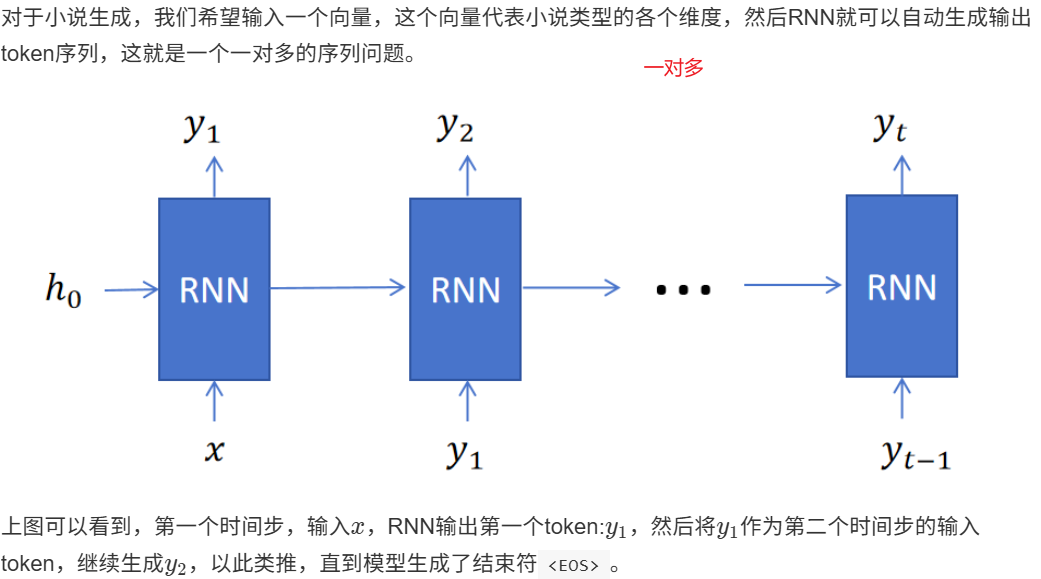
12.2 RNN的不同类型
12.3 LSTM
12.3.1 RNN中的问题

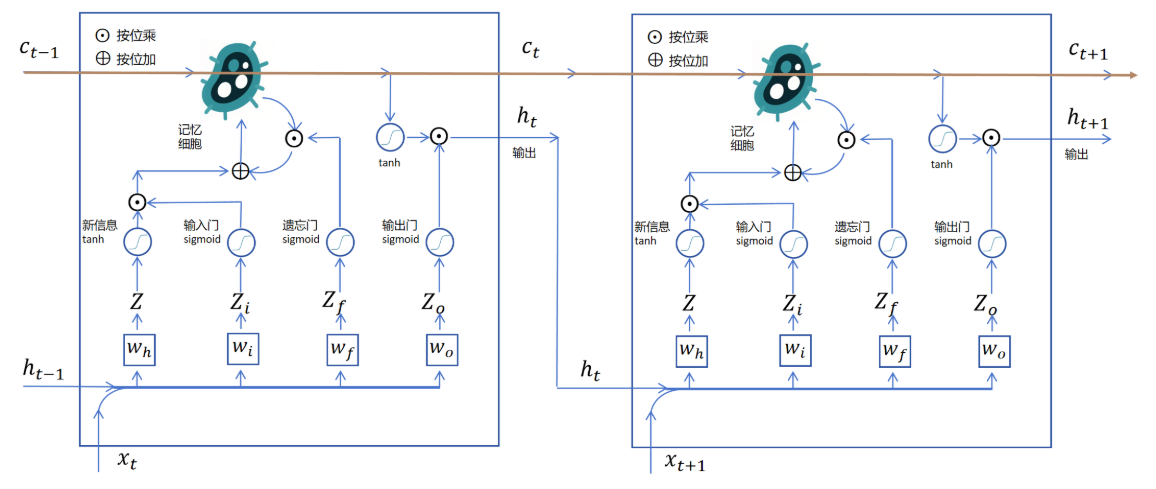
12.3.2 LSTM网络结构(输入门、遗忘门、输出门)
具体细节:https://www.rethink.fun/chapter13/LSTM.html
输入门决定该时间步向记忆细胞中存储新记忆,遗忘门决定从记忆细胞中取出一些记忆遗忘,输出门决定该时间步输出的隐信息


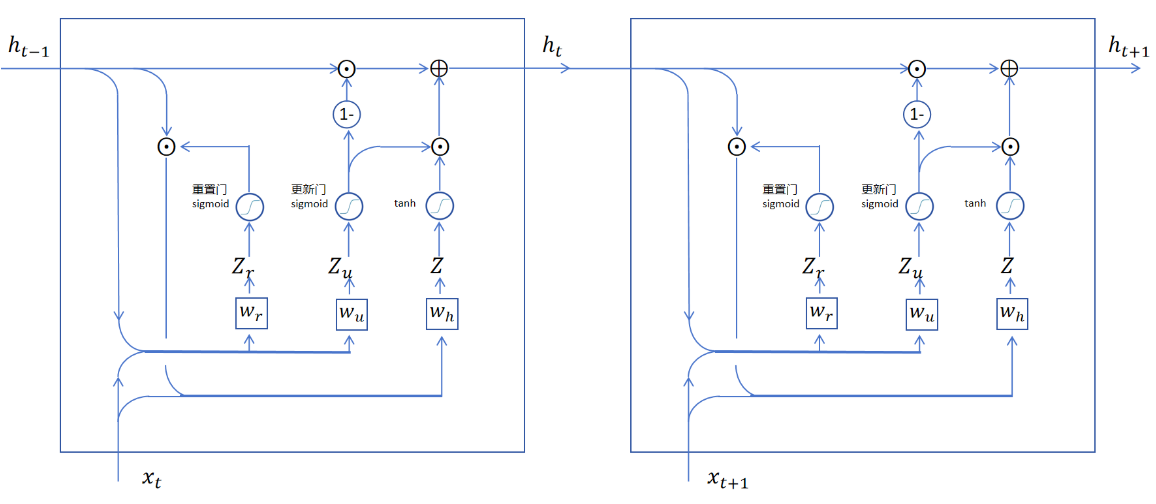
12.4 GRU(重置门、更新门)
门控循环单元(Gated Recurrent Unit,GRU)是对LSTM的简化版,实验表明,GRU的性能基本和LSTM相当
具体细节:https://www.rethink.fun/chapter13/GRU.html
重置门决定用多少旧知识理解新内容,更新门用来遗忘不用的记忆和新增新记忆
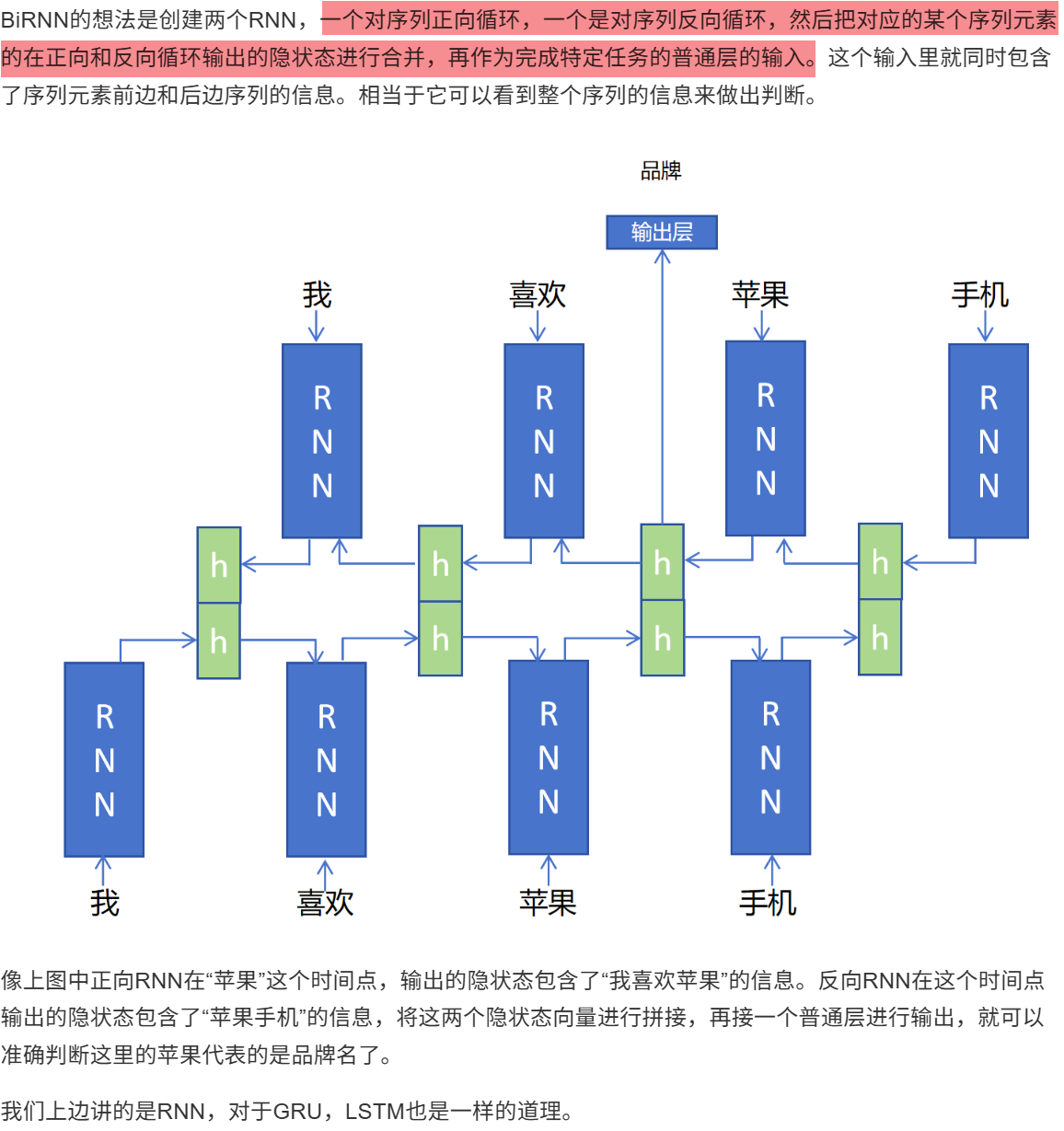
12.5 双向循环神经网络
12.6 深度循环神经网络
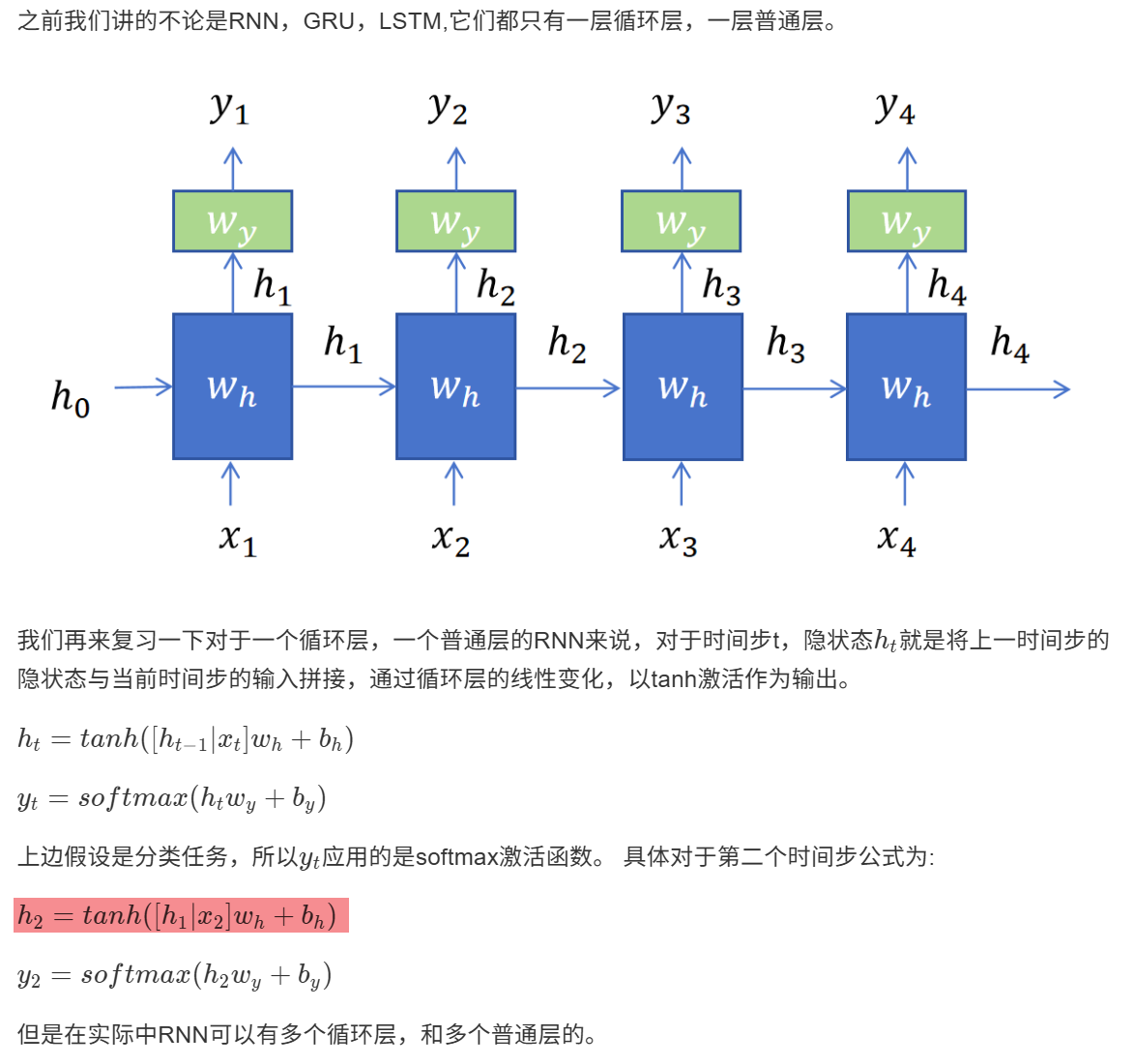
12.6.1 增加更多的循环层

12.7 注意力机制