文章目录
前言
之前学习过多线程基础知识,这里再复习并拓展一下,有兴趣的可以看看之前这篇博客:
线程和进程
线程
- 进程的基本执行单元,一个进程的所有任务都是在线程中执行
- 进程想要执行任务必须要有线程,至少一条
- 程序启动会默认开启一条主线程,也可以叫做UI线程
进程
进程是指在系统中正在运行的一个应用程序- 每个
进程之间是独立的,均运行在其专用且受保护的内存空间内
所以可以理解为进程是线程的容器,而线程用来执行任务,在iOS中是单线程开发,一个进程就是一个app,进程之间是相互独立的。
进程与线程的关系
-
地址空间
- 同一个进程的线程共享本进程的地址空间
- 而进程之间是独立的地址空间
-
资源拥有
- 同一个进程内线程共享进程的资源,如内存、I/O、CPU等
- 但是进程之间资源是独立的
补充
- 多进程比多线程健壮
- 一个进程崩溃后,在保护模式下不会对其进程产生影响
- 一个线程崩溃后整个进程都gg
- 使用场景:频繁切换、并发操作
- 进程切换时,消耗的资源大、效率高。
- 如果要求
同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程
- 执行过程
- 每个独立的进程有一个程序的运行入口、顺序执行序列和程序入口
- 线程不能独立执行,必须依存于应用程序中,由应用程序提供多个线程执行控制
- 线程是处理器调度的基本单位
- 线程没有地址空间,线程包含在进程的地址空间中
线程和RunLoop的关系
- 一个runLoop对应一个核心线程,runLoop是可以嵌套的,但是核心只能有一个,他们的关系保留在一个全局的字典中
- RunLoop 是线程的事件循环管理机制,是用来管理线程的,当线程的runLoop被开启后,线程会在执行完成之后进入休眠状态,有任务的时候就会被唤醒
- 在第一次被获取时创建,在线程结束后被销毁(这里需要注意个问题就是任务执行结束之后是销毁还是休眠取决于创建方式)
- 主线程的runLoop在程序启动时就默认创建好了
- 对于子线程来说,runLoop是懒加载的,只有当我们使用的时候才会去创建,所以在子线程中使用定时器时需要注意确保子线程的runloop被创建,不然不会回调
| 线程类型 | 任务结束后 |
|---|---|
| NSThread (无RunLoop) | 线程销毁 |
| NSThread (有RunLoop) | 线程休眠 |
| GCD线程 | 回到线程池休眠 |
| 主线程 | 永远存在 |
多线程
多线程原理
- 对于
单核CPU,同一时间,CPU只能处理一条线程,即只有一条线程在工作, - iOS中的
多线程同时执行的本质是CPU在多个任务直接进行快速的切换,由于CPU调度线程的时间足够快,就造成了多线程的"同时"执行的效果。其中切换的时间间隔就是时间片
多线程意义
优点
- 能适当
提高程序的执行效率 - 能适当
提高资源的利用率,如CPU、内存 - 线程上的任务执行完成后,
线程会自动销毁
缺点
开启线程需要占用一定的内存空间,默认情况下,每一个线程占用512KB- 如果开启
大量线程,会占用大量的内存空间,降低程序的性能 线程越多,CPU在调用线程上的开销就越大- 程序设计更加复杂,比如线程间的通信,多线程的数据共享
多线程内存空间
多线程的生命周期主要分为5个部分:
新建->就绪->运行->阻塞->死亡
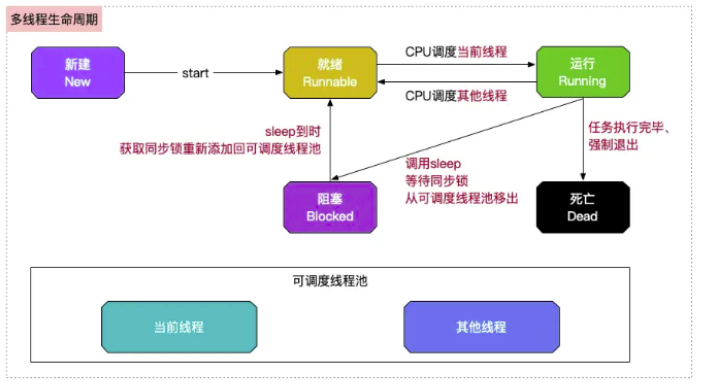
线程对象调用start方法将对象加入可调度线程池等待CPU调用
运行中的线程拥有一段可执行的时间称为时间片
- 如果时间片用尽线程就会进入就绪状态
- 如果时间片没有用尽,并且需要等待某事件,就会进入阻塞状态队列
- 等待事件发生后就又回到就绪状态
- 每当一个线程离开运行,即执行完毕或者强制退出后,会重新
从就绪状态队列中选择一个线程继续执行
线程的优先级越高是不是意味着任务的执行越快?
线程执行的快慢除了要看优先级,还需要查看资源的大小,即任务的复杂度,以及CPU调度轻快。在NSThread中,线程优先级
threadPriority已经被服务质量qualityOfService取代(早期的threadPriority只是数值,没有语义 系统不知道任务类型无法根据用户体验和能耗优化调度)
简单介绍一下这个服务质量机制:
- 标识任务的重要程度,系统根据QoS决定CPU的调度、线程优先级、能耗策略、IO优先级,由系统内核XNU进行实际调度
- 枚举值:
objctypedef NS_ENUM(NSInteger, NSQualityOfService) { NSQualityOfServiceUserInteractive = 0x21,//最高优先级,必须立即执行,影响UI流程度,性能核 NSQualityOfServiceUserInitiated = 0x19,//用户正在等待结果,高优先级、快速完成,性能核 NSQualityOfServiceUtility = 0x11,//长时间任务,混合使用核心 NSQualityOfServiceBackground = 0x09,//最低级, 能效核 NSQualityOfServiceDefault = -1 } API_AVAILABLE(macos(10.10), ios(8.0), watchos(2.0), tvos(9.0));
QoS 含义 使用场景 UserInteractive用户正在操作 UI刷新、动画 UserInitiated用户触发任务 加载数据 Utility长时间任务 下载 Background后台任务 日志、同步
- QoS可以在多个API中使用,NSThread、NSOperation、GCD
- 现代iPhone CPU通常使用大小核结构,性能核和能效核。
- 使用示例:
objc//GCD: dispatch_async(dispatch_get_global_queue(QOS_CLASS_UTILITY, 0), ^{ NSLog(@"download"); }); //NSThread: NSThread *thread = [[NSThread alloc] initWithBlock:^{ NSLog(@"task"); }]; thread.qualityOfService = NSQualityOfServiceUserInitiated; [thread start];
- QoS会自动继承
- 系统会自动提升QoS:当高QoS任务依赖低QoS任务时, 系统会临时提高低QoS任务的优先级。(这里的提升是临时的)
线程池原理
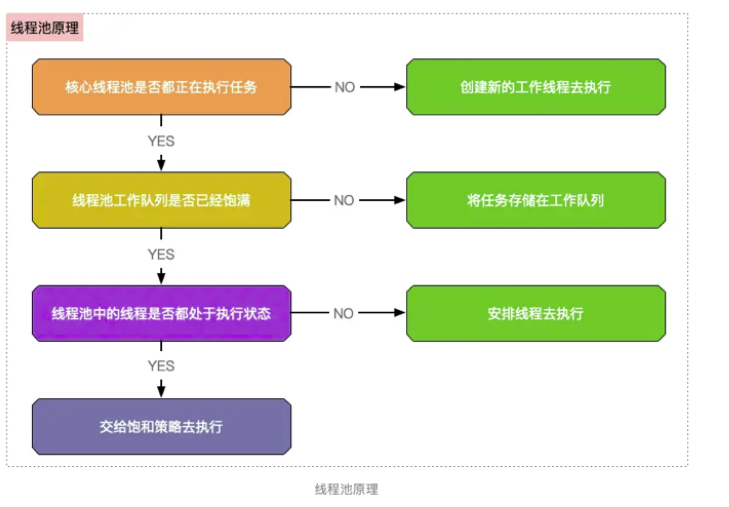
线程池内部主要有三个组件:
- 核心线程
corePoolSize - 最大线程
maximumPoolSize - 任务队列
queueCapacity
上面的流程图其实就是线程池执行execute()方法的算法:
第四步的饱和策略主要有以下四种:
AbortPolicy:直接抛出RejectedExecutionExeception异常来阻止系统正常运行CallerRunsPolicy:将任务回退到调用者DisOldestPolicy:丢掉等待最久的任务DisCardPolicy:直接丢弃任务
objc
//pthread
void *run(void *param) {
NSLog(@"pthread thread running");
return NULL;
}
- (void)testPthread {
pthread_t thread;
pthread_create(&thread, NULL, run, NULL);
/*
参数1:线程标识
参数2:线程属性
参数3:线程执行函数
参数4:参数
*/
}
//NSThread
- (void)testNSThread {
NSThread *thread = [[NSThread alloc] initWithTarget:self selector:@selector(threadTask) object:nil];
[thread start];
}
- (void)threadTask {
NSLog(@"NSThread running");
}
//法2:
[NSThread detachNewThreadSelector:@selector(threadTask) toTarget:self withObject:nil];//创建后立即启动
//法3:
[self performSelectorInBackground:@selector(threadTask) withObject:nil];//开发者不直接创建线程,而是提交任务
//NSOperaion:
//法1:
NSInvocationOperation *operation = [[NSInvocationOperation alloc] initWithTarget:self selector:@selector(operationTask) object:nil];
NSOperationQueue *queue = [[NSOperationQueue alloc] init];
[queue addOperation:operation];
//法2:NSBlockOperation:
NSBlockOperation *operation = [NSBlockOperation blockOperationWithBlock:^{
NSLog(@"block operation running");
}];
NSOperationQueue *queue = [[NSOperationQueue alloc] init];
[queue addOperation:operation];
法3:C和OC的桥接
OC对象和CF对象很多时候共用的是同一块内存结构,只是API不同(Toll-Free Bridging)
ARC只管理OC对象,CoreFoundation使用手动引用计数
__bridge只做类型的转换,不修改对象内存管理权__bridge_retained将OC对象转换为Core Foundation的对象,将对象的内存管理权交给我们,后续需要使用CFrelease或者相关方法释放__bridge_transfer将Core Foundation的对象 转换为Objective-C的对象,同时将对象(内存)的管理权交给ARC
线程安全问题
多个线程同时访问一块资源部会导致数据竞争问题
互斥锁(同步锁)
- 用于保护临界区代码,确保同一时间只有一个线程访问执行
- 如果代码中只有一个地方需要加锁,大多使用self,避免单独再创建锁对象
- 加了互斥锁后,当其他线程访问时发现加锁,就会进入休眠
- 互斥锁的锁定范围应该尽可能的小。锁的范围越大效率越差
- 任意 NSObject 都可以作为锁:
- 锁对象必须所有线程都能访问
objc
//底层
objc_sync_enter(obj)
objc_sync_exit(obj)//运行时会维护一个锁表,每个对象都可以对应一把锁常见互斥锁:
- @synchronized
- NSLock
- pthread_mutex
- os_unfair_lock
自旋锁
- 与互斥锁类似,但不是通过休眠阻塞线程,而是在获取锁之前一直处于阻塞状态(原地打转)
适用于锁持有的时间短,且线程不希望在重新调度上花太多成本的情况,属性修饰符atomic自身就有一把自旋锁- 加了自旋锁之后,当新线程访问代码时,如果发现有其他线程正在锁定代码,线程就会用死循环的方法一直等待锁定代码执行完成,不停尝试执行代码,比较消耗性能。(忙等状态)
atmoic原子锁 & nonatomic非原子锁区别
- nonatomic:非原子属性、非线程安全,适合内存小的移动设备
- atomic:原子属性、针对多线程设计的。本身就具有一把自旋锁,单个线程写入,多个线程读取,线程安全,资源消耗大
- ++建议iOS开发都是用nanatomic,尽量避免多线程抢夺同一块资源,尽量将加锁、资源抢夺的业务交给服务端处理,减小移动端压力++
线程间通讯
-
直接消息传递:一个线程直接在另一个线程上执行方法
performSelector:onThread:,因为任务的执行上下文是目标线程,所以这中方式发送的消息将被自动序列化。 -
共享变量:多个线程访问同一块内存(全局变量、单例对象、共享数组),这种共享内存块的机制虽然快and简单,但是更加脆弱,必须要使用锁或者其他同步机制仔细保护共享变量。避免数据竞争
-
条件执行:条件是一种同步工具,可以用来控制线程何时执行代码的特定部分。(NSCondition *condition
对象(内部封装了互斥锁 pthread_mutex_t 和条件变量 pthread_cond_t)和布尔标志BOOL ready)NSCondition(及底层的pthread_cond_wait) 的设计保证了一旦线程被唤醒,它会立即尝试重新获取互斥锁。(其中的条件变量结束了线程的忙等状态,改为休眠状态) -
RunLoop sources:线程通过RunLoop监听事件,一个自定义的Runloop source配置可以让一个线程收到特定的应用程序的消息。是事件驱动的,没事会进入休眠。
-
Ports and sockets:基于端口通信,可靠。端口和套接字可用于与外部实体进行通信。为了提高效率,使用 Runloop source 来实现端口,当端口上没有数据等待时,线程将进入睡眠状态。++需要
注意的是,端口通讯需要将端口加入到主线程的Runloop中,否则不会走到端口回调方法++ -
消息队列: 遵循先进先出(FIFO)原则,发送者将数据打包成消息放入队尾,接受者从队头取出。- 发送者不需要知道接受者是谁,只管发
- 具有天然缓冲作用,可以应对突发流量
- 任务天然按照顺序执行
- 具有数据拷贝开销(序列化and拷贝)
- 设计内核态介入,切换会变慢
- 任务需要排队,具有延迟
- 适合任务调度 和解耦 ,但在追求极致低延迟、大数据量传输的高频线程通信中,它的性能不如直接共享内存。
-
Cocoa 分布式对象(DO): 分布式对象是一种 Cocoa 技术,可提供基于端口的通信的高级实现。尽管可以将这种技术用于线程间通信,但是强烈建议不要这样做,因为它会产生大量开销。++分布式对象更适合与其他进程进行通信++- 核心技术:Proxy代理模式+自动序列化+Mach IPC
- 当调用远程对象方法时系统自动打包参数并通过内核发送给对方进程,对方解包、执行、打包、发回。
- DO严重依赖RunLoop处理传入消息。DO 设计之初是为了跨进程(IPC)甚至跨网络通信。它使用了重量级的 Mach Message 机制。在同一进程内的两个线程之间使用它
- 内核介入锅中
- 难得调试,堆栈追踪在跨边界时模糊