视觉几何基础变换器(VGGT)在静态场景中表现优异,但在动态场景下面临固有矛盾:相机姿态估计需抑制动态区域,而几何重建则需建模动态信息。如何在统一框架下协调这一任务冲突?
来自MIT和Harvard的研究团队提出了PAGE-4D(Disentangled Pose and Geometry Estimation for VGGT-4D Perception)模型。
该模型通过动态感知聚合器(Dynamics-aware Aggregator)预测动态感知掩码,实现静态与动态信息的解耦:在姿态估计中抑制运动线索,在几何重建中增强动态表示。该框架无需后处理,可端到端完成相机姿态估计、深度预测和点云重建等任务。

论文标题:PAGE-4D: Disentangled Pose and Geometry Estimation for VGGT-4D Perception
论文链接:https://arxiv.org/abs/2510.17568
项目主页:https://page4d.github.io/
作者团队:Kaichen Zhou, Yuhan Wang, Grace Chen, Xinhai Chang, Gaspard Beaudouin, Fangneng Zhan, Paul Pu Liang, Mengyu Wang研究背景与挑战
真实世界场景中动态对象普遍存在,对三维感知任务提出了不同要求:
- 相机姿态估计:需抑制动态区域以获取准确相机运动
- 几何重建:需建模动态区域以还原完整场景几何
这种任务间的固有冲突是多任务4D重建的核心挑战。传统方法往往难以在同一框架下同时满足这两种相反的需求,导致在动态场景中性能下降。
核心发现:从实验观察到问题洞察
实验观察: 虽然VGGT在静态场景理解中达到了最先进的性能,但在存在动态对象时,其精度显著下降。在Odyssey测试集上,动态区域的绝对深度误差比静态区域高94%,这凸显了需要一个能够在静态和动态场景中都实现可靠场景理解的架构。
特征可视化分析: 通过对VGGT关键层的特征可视化分析,研究团队观察到动态区域表现出比静态区域更弱的激活,这表明VGGT倾向于忽略动态内容。进一步的消融实验显示,当明确抑制动态token的跨帧注意力时,相机姿态估计得到改善,但同时导致几何重建性能急剧下降。

核心洞察: 这些发现揭示了动态场景中的根本矛盾:相机姿态估计需要抑制动态区域以保持对极一致性,而几何重建则需要利用它们的运动线索。
在动态场景中,相机姿态估计对动态运动很脆弱,小的残差可能破坏本质矩阵拟合;而几何和跟踪任务实际上可以从建模动态运动中受益。
PAGE-4D方法概述
基于这一洞察,研究团队提出了PAGE-4D,一个动态感知的VGGT扩展。PAGE-4D由四个关键组件组成:
1.预训练的DINO-style编码器:提取图像级表示
2.动态感知聚合器(Dynamics-aware Aggregator):通过三个模块整合空间和时间线索------Frame Attention用于帧间patch关系,Global Attention用于帧内patch关系,Dynamics-Aware Global Attention用于解耦动态和静态内容
3.轻量级解码器:用于深度和3D点云地图
4.更大的解码器:专门用于相机姿态估计
PAGE-4D继承了VGGT的组件(1)、(3)和(4),而将组件(2)扩展为三阶段动态感知聚合器。
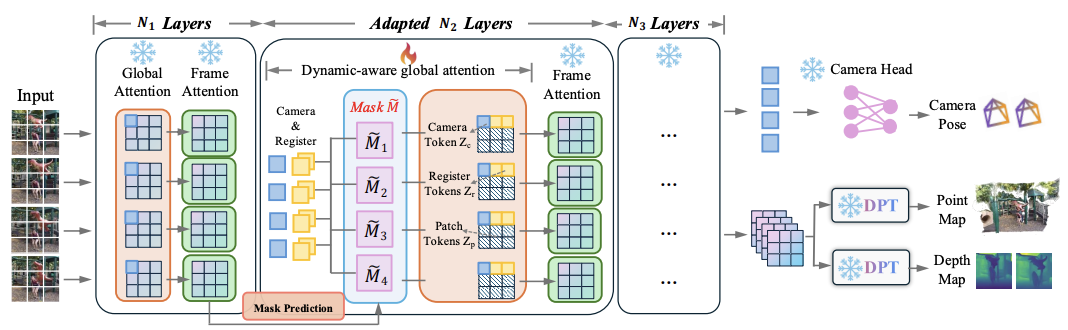
三阶段动态感知聚合器:
第一阶段:由N₁层组成,每层包含一个Global Attention块和一个Frame Attention块。其输出送入动态掩码预测模块,生成动态感知掩码。
动态掩码预测: 动态掩码预测模块以自监督方式学习哪些空间区域可能对应动态对象。如图(a)所示,该模块从聚合器中提取patch tokens,通过线性映射投影到低维表示,然后使用深度卷积头生成掩码logits。
通过引入可学习的温度参数τ和缩放因子α,将logits转换为抑制概率,形成连续的自适应抑制权重而非二值掩码,使其对模糊的运动边界和部分遮挡更加鲁棒。
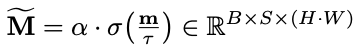
第二阶段:应用动态感知掩码来解耦动态和静态内容,用于姿态和几何估计。该阶段由N₂层组成,每层包含一个Dynamics-Aware Global Attention块和一个Frame Attention块。
掩码注意力机制: 一旦预测出动态掩码,它可以被直接整合到transformer注意力机制中。如图(b)所示,对于相机姿态估计任务,掩码主动抑制对动态区域的注意力,确保与对极几何和静态场景约束的一致性。
而对于深度和点云任务,掩码不应用于相关patch,允许网络利用动态运动线索来改善点云地图重建和2D-3D跟踪精度。这种非对称设计明确解耦了动态区域在不同任务中的作用。

第三阶段:由N₃层组成,结构与第一阶段类似。
实验结果
研究团队在多个动态场景中对PAGE-4D进行了广泛的实验验证,涵盖了视频深度估计、单目深度估计、相机姿态估计、点云地图重建和新视角合成等多个任务。
定量结果: 广泛的实验表明,PAGE-4D在动态场景中始终优于原始VGGT,在相机姿态估计、单目和视频深度估计以及密集点云地图重建等任务上均取得了卓越的成果。
相比VGGT,PAGE-4D在多个基准测试上实现了显著改进:深度估计准确率提升20-40% ,相机姿态估计误差降低13-21% ,点云重建准确度误差降低60%以上。
定性结果: PAGE-4D能够从RGB输入中估计相机姿态和深度图,即使在存在动态对象的情况下也能实现高质量的点云重建。如图5所示,对比VGGT,PAGE-4D生成的点云更加密集、完整,几何一致性更好,能够有效捕捉动态物体的细节和完整场景结构。

鲁棒性: PAGE-4D在显著提升性能的同时,保持了与VGGT相同的推理速度(43.2FPS),未增加计算成本。该方法在从视频序列到单帧输入的泛化方面表现良好,优于DUSt3R、MonST3R和FLARE等专用基线方法。
在动态场景渲染应用中,将PAGE-4D重建的点云作为4D-Gaussian splatting框架的初始化,在Nerfie基准测试上实现了优于现有前馈3D重建模型的渲染性能,展现了良好的鲁棒性和泛化能力。
总结
PAGE-4D通过动态感知聚合器实现了静态与动态信息的有效解耦,在相机姿态估计、深度预测和密集点云地图重建等任务上均取得了卓越的成果。这项工作为三维视觉感知在复杂动态环境中的应用提供了新的思路和方法,有望推动动态感知技术的进一步发展。
重要的是,PAGE-4D展示了通过有效的解耦策略,即使在有限的动态数据下也能实现强大的泛化能力,为可扩展和高效的4D场景理解铺平了道路。
如果你对4D感知、动态场景理解或多任务视觉模型感兴趣,欢迎在评论区留言交流!