目录
[1 哈希表核心原理](#1 哈希表核心原理)
[2 哈希函数](#2 哈希函数)
[3 哈希冲突](#3 哈希冲突)
[4 key必须是不可变的](#4 key必须是不可变的)
[5 总结](#5 总结)
哈希表和我们常说的 Map(键值映射)不是同一个东西。
Map 是一个Java 接口 ,仅仅声明了若干个方法,并没有给出方法的具体实现。HashMap、TreeMap、LinkedHashMap 等是实现类。
换句话说,你可以说 HashMap 的 get, put, remove 方法的复杂度都是**O(1)**的,但你不能说 Map 接口的复杂度都是 O(1)。
1 哈希表核心原理
哈希表可以理解为一个加强版的数组。哈希表可以通过 key 在 O(1) 的时间复杂度内查找到这个 key 对应的 value。key 的类型可以是数字、字符串等多种类型。
哈希表的底层实现就是一个数组,它先把这个 key 通过一个哈希函数hash转化成数组里面的索引,然后增删查改操作和数组基本相同。
2 哈希函数
作用:把任意长度的输入(key)转化成固定长度的输出(索引)。
增删查改的方法中都会用到哈希函数来计算索引,如果你设计的这个哈希函数复杂度是 O(N),那么哈希表的增删查改性能就会退化成 O(N),所以说这个函数的性能很关键。
输入相同的key,输出也必须要相同,这样才能保证哈希表的正确性。
任意 Java 对象都会有一个 int hashCode() 方法,在实现自定义的类时,如果不重写这个方法,那么它的默认返回值可以认为是该对象的内存地址。一个对象的内存地址显然是全局唯一的一个整数。(但这个方法也有一些问题,此处不深究。)
3 哈希冲突
两个不同的 key 通过哈希函数得到了相同的索引。
哈希冲突是否可以避免?哈希冲突不可能避免,只能在算法层面妥善处理出现哈希冲突的情况。因为这个 hash 函数相当于是把一个无穷大的空间映射到了一个有限的索引空间,所以必然会有不同的 key 映射到同一个索引上。
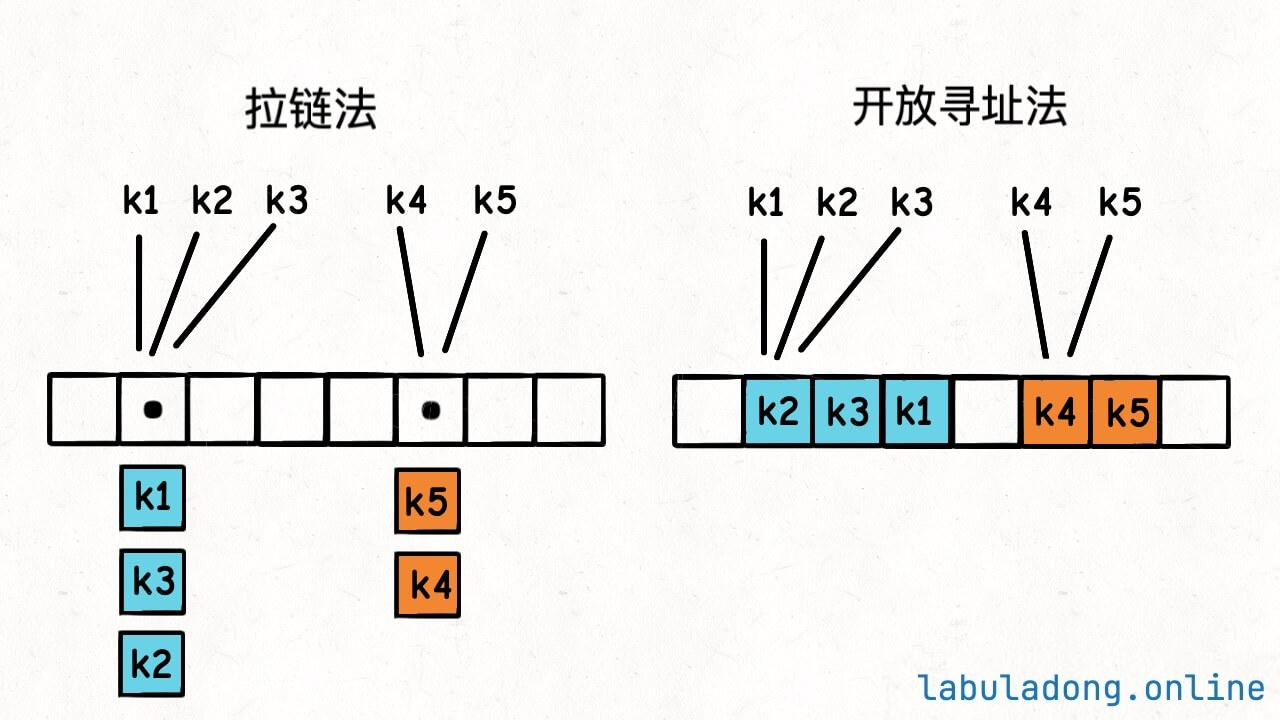
出现哈希冲突的情况怎么解决?两种常见的解决方法,一种是拉链法 ,另一种是线性探查法 (也经常被叫做开放寻址法)。
key 的插入顺序是 k2, k4, k5, k3, k1,那么哈希表底层就会变成这样:
4 key必须是不可变的
只有那些不可变类型,才能作为哈希表的 key,这一点很重要。
这个对象一旦创建,它的值就不能再改变了。比如 Java 中的 String, Integer 等类型,一旦创建了这些对象,你就只能读取它的值,而不能再修改它的值了。
作为对比,Java 中的 ArrayList、LinkedList 这些对象,它们创建出来之后,可以往里面随意增删元素,所以它们是可变类型。
5 总结
1、为什么我们常说,哈希表的增删查改效率都是 O(1)?
因为哈希表底层就是操作一个数组,其主要的时间复杂度来自于哈希函数计算索引和哈希冲突。只要保证哈希函数的复杂度在 O(1),且合理解决哈希冲突的问题,那么增删查改的复杂度就都是 O(1)。
2、哈希表的遍历顺序为什么会变化?
因为哈希表在达到负载因子时会扩容,这个扩容过程会导致哈希表底层的数组容量变化,哈希函数计算出来的索引也会变化,所以哈希表的遍历顺序也会变化。
3、哈希表的增删查改效率一定是 O(1) 吗?
不一定,正如前面分析的,只有哈希函数的复杂度是 O(1),且合理解决哈希冲突的问题,才能保证增删查改的复杂度是 O(1)。
哈希冲突好解决,都是有标准答案的。关键是哈希函数的计算复杂度。如果使用了错误的 key 类型,比如前面用 ArrayList 作为 key 的例子,那么哈希表的复杂度就会退化成 O(N)。
4、为啥一定要用不可变类型作为哈希表的 key?
因为哈希表的主要操作都依赖于哈希函数计算出来的索引,如果 key 的哈希值会变化,会导致键值对意外丢失,产生严重的 bug。