报表制作实战:Excel/PDF 导出与前端可视化图表
在 Web 项目中,报表是数据的可视化呈现形式(报表 = 多样的格式 + 动态的数据)。本节课将基于 Django 实现三类核心报表功能:Excel 文件导出、PDF 文件导出、前端 ECharts 统计图表,满足不同场景下的数据展示需求。
一、导出 Excel 报表
报表就是用表格、图表等格式来动态显示数据,所以有人用这样的公式来描述报表:
报表 = 多样的格式 + 动态的数据Excel 报表适合数据批量下载、离线分析,我们选用xlwt库(轻量、性能优,仅支持 xls 格式)实现教师信息 Excel 导出。
1.安装依赖
pip install xlwt2.编写 Excel 导出视图函数
def export_teachers_excel(request):
# 创建工作簿
wb = xlwt.Workbook()
# 添加工作表
sheet = wb.add_sheet('老师信息表')
# 查询所有老师的信息
queryset = Teacher.objects.all()
# 向Excel表单中写入表头
colnames = ('姓名', '介绍', '好评数', '差评数', '学科')
for index, name in enumerate(colnames):
sheet.write(0, index, name)
# 向单元格中写入老师的数据
props = ('name', 'detail', 'good_count', 'bad_count', 'subject')
for row, teacher in enumerate(queryset):
for col, prop in enumerate(props):
value = getattr(teacher, prop, '')
if isinstance(value, Subject):
value = value.name
sheet.write(row + 1, col, value)
# 保存Excel
buffer = BytesIO()
wb.save(buffer)
# 将二进制数据写入响应的消息体中并设置MIME类型
resp = HttpResponse(buffer.getvalue(), content_type='application/vnd.ms-excel')
# 中文文件名需要处理成百分号编码
filename = quote('老师.xls')
# 通过响应头告知浏览器下载该文件以及对应的文件名
resp['content-disposition'] = f'attachment; filename*=utf-8\'\'{filename}'
return resp-
配置 URL 路由
urlpatterns = [
path('excel/', views.export_teachers_excel),]
核心优化说明
• select_related('subject'):关联查询学科,避免循环中多次查询数据库(N+1 问题);
• BytesIO:内存中操作文件,无需生成临时文件,提升性能;
• quote():处理中文文件名,避免浏览器解析乱码;
• 表头样式:可选配置,提升 Excel 可读性。
二、导出 PDF 报表
-
安装依赖
安装reportlab库(PDF生成核心库)
pip install reportlab
-
编写 PDF 导出视图函数
def export_pdf(request: HttpRequest) -> HttpResponse:
buffer = io.BytesIO()
pdf = canvas.Canvas(buffer)
pdf.setFont("Helvetica", 80)
pdf.setFillColorRGB(0.2, 0.5, 0.3)
pdf.drawString(100, 550, 'hello, world!')
pdf.showPage()
pdf.save()
resp = HttpResponse(buffer.getvalue(), content_type='application/pdf')
resp['content-disposition'] = 'inline; filename="demo.pdf"'
return resp -
配置 URL 路由
urlpatterns = [
# 其他路由...
path('export/pdf/', views.export_teachers_pdf, name='export_pdf'), # PDF导出
]
关键说明
• 字体问题 :reportlab默认无中文字体,需指定系统存在的中文字体(如SimSun宋体、Microsoft YaHei微软雅黑);
• 页面布局:
canvas:适合自定义位置绘制(如报表、证件),灵活度高;
SimpleDocTemplate:适合流式文档(如长文本、列表),自动分页;
• 响应头配置:
inline:浏览器在线预览 PDF;
attachment:强制下载 PDF 文件。
三、生成前端统计图表
前端图表适合数据可视化展示(柱状图、折线图、饼图等),我们使用百度 ECharts(开源、易用)实现教师好评 / 差评统计。
-
编写数据接口视图
def get_teachers_data(request):
queryset = Teacher.objects.all()
names = [teacher.name for teacher in queryset]
good_counts = [teacher.good_count for teacher in queryset]
bad_counts = [teacher.bad_count for teacher in queryset]
return JsonResponse({'names': names, 'good': good_counts, 'bad': bad_counts}) -
配置 URL 路由
urlpatterns = [
path('teachers_data/', views.get_teachers_data),
] -
编写前端图表页面(ECharts)
老师评价统计
运行效果如下图所示。
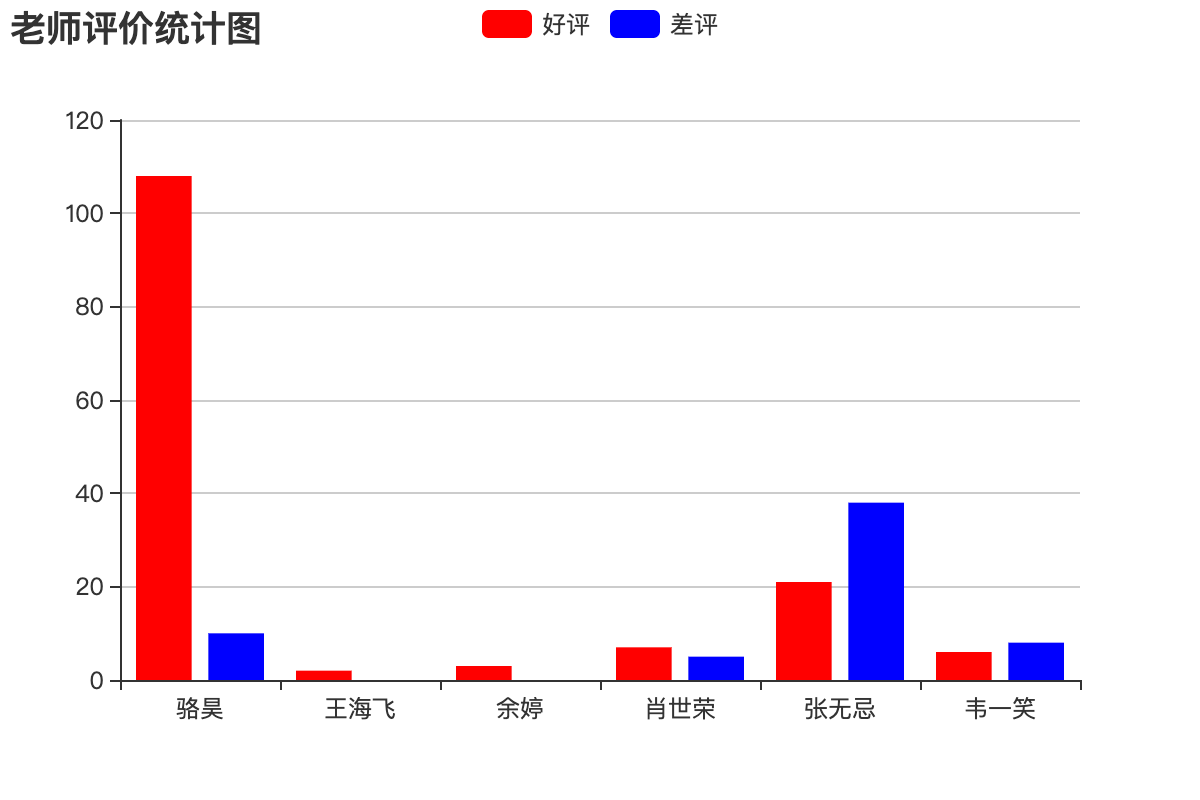
核心优化说明
• 数据请求 :使用fetch异步获取数据,添加错误处理,提升用户体验;
• 图表适配 :
resize事件:窗口大小变化时图表自适应;
rotate:X 轴标签旋转,避免教师姓名重叠;
min: 0:Y 轴最小值设为 0,数据展示更合理;
• 样式优化:自定义颜色(好评绿、差评红)、柱子宽度,提升可读性;
• 性能优化:后端仅返回所需字段(values查询),减少数据传输量。
四、扩展与最佳实践
- Excel 格式扩展(xlsx)
若需支持 xlsx 格式,可改用openpyxl库,核心代码调整:
from openpyxl import Workbook
from openpyxl.styles import Font
def export_teachers_xlsx(request):
wb = Workbook()
sheet = wb.active
sheet.title = '老师信息表'
# 写入表头(略)
# 写入数据(略)
buffer = BytesIO()
wb.save(buffer)
resp = HttpResponse(buffer.getvalue(), content_type='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet')
resp['Content-Disposition'] = f'attachment; filename*=utf-8\'\'{quote("老师信息表.xlsx")}'
return resp- PDF 复杂报表优化
• 批量数据:使用SimpleDocTemplate+Table组件实现表格;
• 中文支持:若reportlab无中文字体,可手动加载字体文件:
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
# 注册字体(需提前准备字体文件,如simsun.ttf)
pdfmetrics.registerFont(TTFont('SimSun', 'static/fonts/simsun.ttf'))- 前端图表扩展
• 切换图表类型:将type: 'bar'改为'line'(折线图)、'pie'(饼图)即可;
• 数据筛选:前端添加时间 / 学科筛选条件,后端接收参数后过滤数据;
• 动态刷新:添加定时刷新(setInterval),实时更新数据。
五、小结
本次实战完成了三类报表的核心实现,覆盖数据下载、离线文档、在线可视化场景:
关键点回顾
1.Excel 导出 :xlwt(xls)/openpyxl(xlsx),内存缓冲区操作,中文文件名编码;
-
PDF 导出 :
reportlab库,canvas 自定义绘制,注意中文字体配置; -
前端图表 :ECharts 异步获取数据,适配性优化,样式自定义;
-
性能优化:关联查询、字段筛选、内存操作,减少数据库 / 网络开销。
六、AI工具,提高学习,工作效率,神器
国内直接使用顶级AI工具
谷歌浏览器访问:
https://www.nezhasoft.cloud/r/vMPJZr
