
目录
一、Redis集群概述
1、什么是Redis集群
2018年十月 Redis 发布了稳定版本的 5.0 版本,推出了各种新特性,其中一点是放弃 Ruby的集群方式,改为 使用 C语言编写的 redis-cli的方式,使集群的构建方式复杂度大大降低。关于集群的更新可以在 Redis5 的版本说明中看到,如下:
The cluster manager was ported from Ruby (redis-trib.rb) to C code inside redis-cli. check
redis-cli --cluster helpfor more info.
https://redis.io/topics/cluster-tutorial可以查看Redis官网查看集群搭建方式,链接 https://redis.io/topics/cluster-tutorial
以下步骤是在一台 Linux 服务器上搭建有6个节点的 Redis集群。
注:实际运维工作中,大概需要3台机器,每台机器2个Redis实例。但是详细规划主从关系,尽量不要把一组主从放在同一台服务器中。
2、规划基础环境
IP地址:根据自己的主机设置规划
主机名称:redis01.itcast.cn/redis02.itcast.cn/redis03.itcast.cn
3、下载源码并解压编译
bash
yum install wget -y
wget https://download.redis.io/releases/redis-7.4.0.tar.gz
tar xzf redis-7.4.0.tar.gz
cd redis-7.4.0
make
make PREFIX=/usr/local/redis install4、清理Redis集群环境
bash
systemctl stop redis # 我这里是因为编写了service,如果你没有编写,请使用pkill,kill 或者 redis-clis 关闭或者停止
cd /usr/local/redis
rm -rf conf/*
rm -rf dump.rdb
rm -rf appendonlydir如果哨兵是后台运行,还可以使用pkill删除 pkill redis-sentinel二、Redis集群配置
(一)、单节点
单节点的配置我们就不在这儿赘述了,在实际工作中使用多的还是多节点的。
(二)、多节点
1、Redis集群实现
第一步:环境规划(3主3从,对外提供服务的一共是3个节点)
前提:Redis集群往往在搭建环境时必须要提前设计,而且Redis集群要求,在创建集群之前,任何都不能有数据!!!
|----|-------------------|----------------|-----------|
| 编号 | 主机名称 | IP地址 | 角色 |
| 1 | redis01.itcast.cn | 192.168.177.80 | redis7001 |
| 2 | redis01.itcast.cn | 192.168.177.80 | redis7002 |
| 3 | redis02.itcast.cn | 192.168.177.81 | redis7003 |
| 4 | redis02.itcast.cn | 192.168.177.81 | redis7004 |
| 5 | redis03.itcast.cn | 192.168.177.82 | redis7005 |
| 6 | redis03.itcast.cn | 192.168.177.82 | redis7006 |
设置之前,把Redis01、Redis02、Redis03机器上的所有Redis全部停止,删除所有配置文件redis.conf、sentinel.conf
第二步:在/usr/local/redis/conf目录中创建redis7001.conf...redis7006.conf
Redis01 => redis7001.conf/redis7002.conf
Redis02 => redis7003.conf/redis7004.conf
Redis03 => redis7005.conf/redis7006.conf
节点配置类似:
bash
port 7001
cluster-enabled yes
cluster-config-file nodes_7001.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes
protected-mode no
pidfile /var/run/redis_7001.pid
logfile "/usr/local/redis/log/redis7001.log"
masterauth "123456"
requirepass "123456"参考以上配置,准备7002 ~ 7006!!!
注意更改:port、cluster-config-file、pidfile、logfile
第三步:配置完成后,启动Reids6个节点
bash
# cd /usr/local/redis
# bin/redis-server conf/redis7001.conf
# bin/redis-server conf/redis7002.conf
# cd /usr/local/redis
# bin/redis-server conf/redis7003.conf
# bin/redis-server conf/redis7004.conf
# cd /usr/local/redis
# bin/redis-server conf/redis7005.conf
# bin/redis-server conf/redis7006.conf
注意 :启动完成之后每个节点上执行该命令,检查每个redis 实例是否启动成功!
第四步:创建集群(集群最少需要3个主节点)
|---------|---------|---------|
| Redis01 | Redis02 | Redis03 |
| 1主7001 | 1从7003 | |
| | 2主7004 | 2从7005 |
| 3从7002 | | 3主7006 |
bash
redis-cli -a 123456 --cluster create 192.168.177.80:7001 192.168.177.81:7004 192.168.177.82:7006 192.168.177.81:7003 192.168.177.82:7005 192.168.177.80:7002 --cluster-replicas 1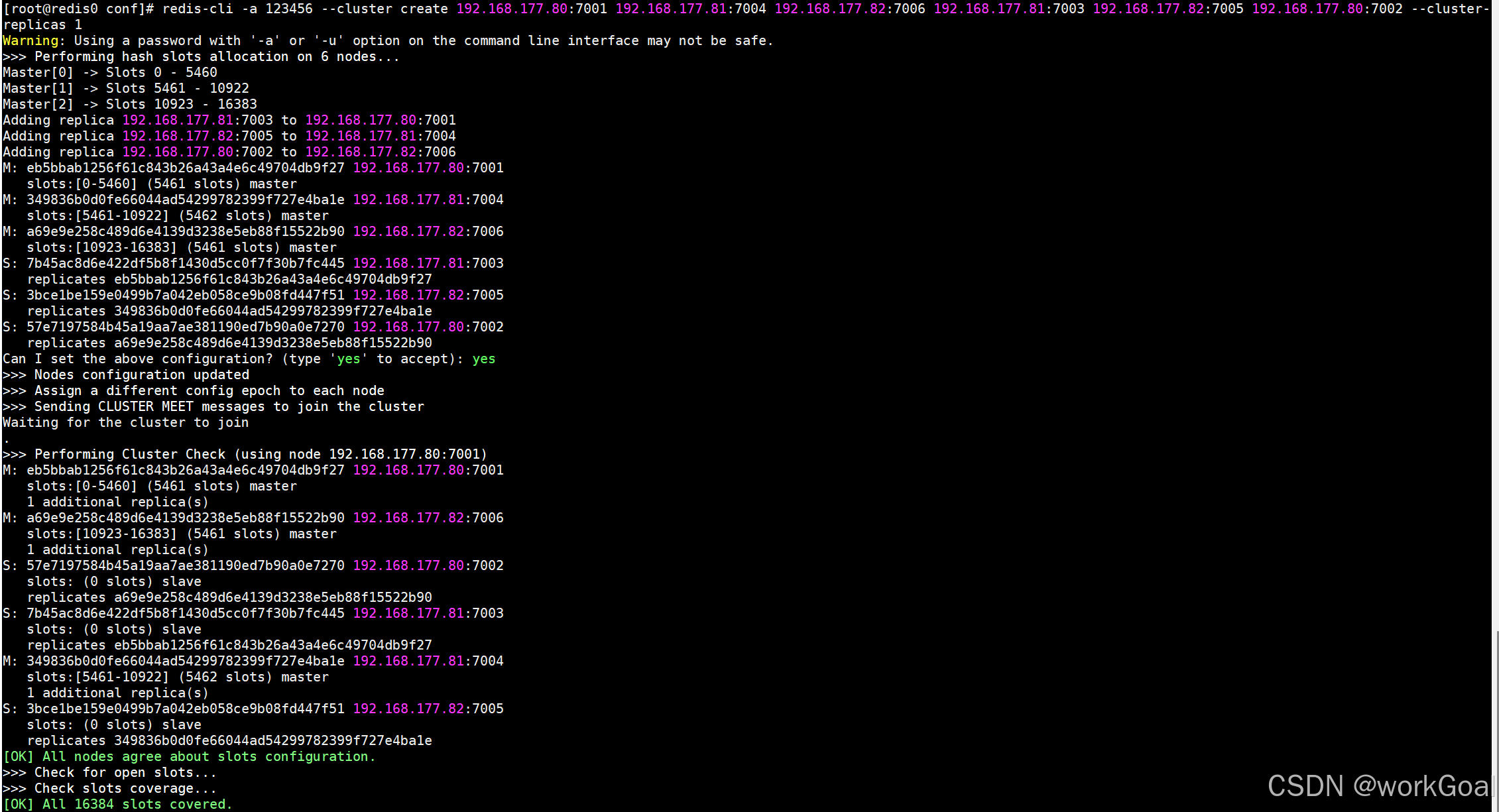
上面这是执行成功后的界面!
参数说明:
--cluster create创建集群,后面跟Redis及端口号--cluster-replicas 1,每个主节点默认都有1个从节点注:
集群模式不需要提前搭建主从架构,而是在创建集群时,系统会自动配置主从,不需要人工干预。命令格式 :
bin/redis-cli --cluster create ①主节点 ②主节点 ③主节点 ①从节点 ②从节点 ③从节点
常见问题说明:
**问题描述:**Redis集群要求Redis中不能有数据,包括appendonlydir、dump.rdb、nodes_700X.conf
**解决方案:**哪个节点报错,就清除哪个节点(以7001为例)
bash
ps -ef |grep redis-server
# 找到7001对应的进程
kill -9 进程号
rm -rf appendonlydir
rm -rf dump.rdb
rm -rf node_7001.conf
# 清除完成后,重启Redis
bin/redis-server conf/redis7001.conf2、测试集群
bash
redis-cli -c -h 主节点IP地址 -p 7001 -a 123456
# 选项说明: -c代表已集群的方式进行连接
# 举个例子:redis-cli -c -h 192.168.177.80 -p 7001 -a 1234563、关闭集群
bash
# redis-cli -a 123456 -c -h 192.168.177.80 -p 7001 shutdown
# 其他实例的关闭操作类似4、集群重启
重启步骤非常简单,只需要把每台服务器的各个节点依次启动即可。
四、Redis集群原理
1、16384个哈希槽
- redis cluster在设计的时候,就考虑到了去中心化。
- 去中心化,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
- Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用**
CRC16算法来取模得到所属的slot** ,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384``。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了700X节点。- Redis兼具高可用以及故障切换能力:Redis 集群会把数据存在某一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也会根据CRC16算法找到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是: 必须要
3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。3主 3从 = 正常
3主 2从 = 3 < 5/2 = 2.5 = 不成立,集群依然可以正常对外提供服务
简单理解:Redis集群就是一个大仓库,这个仓库中为了方便数据存储,拆分为16384 slot哈希槽。
因为写只和master主节点相关,所以16384要被3个master拆分
Master0 -> Slots 0 - 5460 、Master1 -> Slots 5461 - 10922、 Master2 -> Slots 10923 - 16383
**问题:**为什么要分槽?写入一条记录如name:itheima,写入到哪个槽中?
**答:**分槽目的是为了实现数据最大程度使用,也可以避免数据写入混乱。
写入一条记录如name:itheima,写入到哪个槽中?
在Redis设计过程中,引入了一个CRC16函数,用于针对key求解,结果返回一个数字 => CRC16(name),
槽号 = CRC16(key) % 16384举个例子:
set user:1 "Tom"→ 算出槽号比如是 1234 → 放到槽 1234
set user:2 "Jerry"→ 算出槽号比如是 5678 → 放到槽 5678问题:哈希槽一共有16384个,如果存储16385个key会不够么?
答:Redis 集群将数据分布到 16384 个哈希槽中,并且**每个哈希槽并不是专门为某个键留出一个空间,而是作为一个逻辑单元,存储多个键。每个键通过 CRC16 算法和取模操作(
CRC16(key) % 16384)被映射到某个哈希槽。一个哈希槽可以存放该哈希槽下的所有键值对。**换句话说,多个键会被分配到同一个哈希槽中,这完全取决于这些键的哈希值和哈希槽的数量。每个哈希槽并没有固定的容量限制,只要 Redis 集群的内存容量足够,哈希槽就可以存储多个键。此外,哈希槽的概念主要是用于决定数据存储位置和数据分片。Redis 集群通过将不同的哈希槽分配给不同的节点来实现数据的分布式存储。在这种机制下,每个哈希槽可以容纳多个键值对,而不会因为哈希槽数量有限而影响到能存储的数据量。
2、扩展:添加新节点
第一步:添加新的主节点
bash
redis-cli --cluster add-node 192.168.177.83:7007 192.168.177.80:7001第二步:修复未完成的槽迁移(若存在)
第三步:迁移槽到新主节点(自动平衡)
bash
redis-cli --cluster rebalance 192.168.177.80:7001 --cluster-threshold 1Redis 7 的
rebalance命令更智能,可能减少人工干预。
第四步:添加从节点 192.168.177.83:7008
bash
# 获取新主节点
# ID NODE_ID_7007=$(redis-cli -h 192.168.177.83 -p 7007 cluster nodes | grep myself | awk '{print $1}')
# 添加从节点并绑定到主节点
# redis-cli --cluster add-node 192.168.177.83:7008 192.168.177.80:7001 \
--cluster-slave --cluster-master-id $NODE_ID_7007第五步:验证集群状态
bash
redis-cli --cluster check 192.168.177.80:7001本 篇 完 结 ... ...
持 续 更 新 中 ... ...