目录
做网络运维的人,大概都经历过这样的时刻:业务方反馈「系统很慢」「访问超时」,你打开监控,CPU、内存、磁盘都正常,可问题究竟出在哪一层?是应用、数据库,还是网络本身?没有完整的流量记录,很多时候只能靠经验猜,或者等下次复现再抓包------而下次,往往又抓不到。
这种「事后无法回溯」的困境,在分布式、微服务架构下尤其明显。传统的 Wireshark、tcpdump 只能解决单点、单次的问题,依赖人工触发,一旦错过关键时间窗口,当时的真实通信就再也找不回来。这也是为什么,越来越多团队开始关注「全流量采集与回溯分析」------不是事后补抓,而是持续采集、长期存储,让问题发生之后,依然可以回到那个时间点,重新分析当时的网络状况。

最近在试用一款面向复杂网络环境的流量分析平台时,对这种思路有了更直观的感受,顺便也聊一聊「免费版」能做什么,以及和 AI 智能助手结合后,可能带来的变化。
一、持续采集:让数据「一直在」
和传统抓包工具最大的不同在于,这类系统是以「持续采集」的方式工作的。流量不是出了问题才抓,而是 7×24 小时不间断采集、存储。这意味着:
-
问题发生之后,你依然可以回溯到任意时间点,查看当时的带宽、连接数、协议分布、应用流量等;
-
原始 PCAP 数据被保留下来,可以重新解析、深入分析,而不是只依赖日志或摘要;
-
对于等保合规、安全审计等场景,也能提供满足要求的原始证据链。
对中小型网络、实验室、开发测试环境来说,这种能力已经足够支撑日常的故障排查和性能分析。而如果部署在 KVM 或 VMware ESXi 虚拟化环境中,还可以直接使用虚拟机镜像,即插即用,无需复杂的网络配置。

二、免费版能覆盖哪些场景?
在试用过程中,我注意到官方提供了 AnaTraf Community 免费版,适用于 KVM 与 VMware ESXi 的虚拟机镜像,功能上是全功能、不限时长的。性能规格大致是:带宽 100M、分析数据存储 7 天、PCAP 存储约 512G。
对很多场景来说,这个规格已经够用:
-
**办公室、小型数据中心**:维护网络健康、保障业务连续性;
-
**IT 系统集成商**:为客户提供网络监控和诊断能力;
-
**校园网、园区网**:7×24 小时实时监控、2--7 层流量透视;
-
**开发测试环境**:排查联调问题、验证协议行为、做性能压测分析。
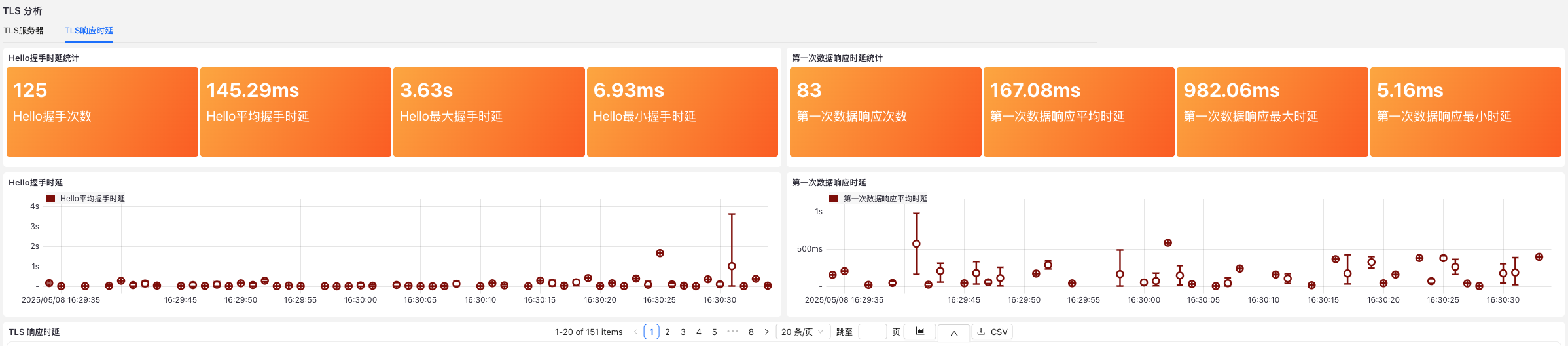
免费版支持全流量采集、深度协议解析、实时统计与可视化、自定义分析面板等核心能力,可以按接口、IP、协议、应用等维度进行自定义统计,满足「看得见、查得到、能回溯」的基本需求。
三、从「看得见」到「看得懂」:智能分析的价值
流量数据有了,但数据量大、维度多,人工逐条排查并不现实。这时候,智能分析能力就显得尤为重要。
在 NPMD(网络性能监控与诊断)类产品中,通常会提供 300+ 性能指标监控、60+ 预设看板、实时性能分析,以及基于规则的智能告警。系统能够自动识别协议异常、连接中断、网络延迟等问题,并结合可视化工具帮助运维人员快速锁定故障点,缩短故障处理时间。
更进一步,随着 AI 技术的不断发展,越来越多的网络分析工具开始引入「智能助手」类能力:通过自然语言理解运维人员的提问,自动关联流量数据、协议解析结果、历史告警等信息,给出分析建议或排查方向。这种「对话式」的交互方式,可以降低使用门槛,让非专业运维人员也能快速理解网络状况,同时让资深工程师把精力集中在更有价值的决策上。
四、灵活部署与易用性
无论是硬件设备、虚拟化部署还是软件版本,这类产品通常都支持多种部署方式。免费版以虚拟机镜像的形式提供,部署过程相对简单:下载镜像、导入 KVM 或 ESXi、按文档配置网络即可。Web 管理界面清晰直观,即插即用,无需复杂的网络配置,对中小团队来说,上手成本较低。
五、一点思考
网络运维的本质,是让「看不见」的东西变得「看得见」,再进一步「看得懂」。全流量采集与回溯分析解决的是「看得见」和「查得到」的问题;智能告警、异常检测、多维分析解决的是「看得懂」的问题;而 AI 智能助手,则是把「看得懂」的能力进一步封装成对话式的交互,让更多人能够参与到网络问题的诊断和优化中来。
如果你正在为「事后无法回溯」「抓包总是错过关键窗口」而头疼,不妨试试这类支持持续采集、全流量回溯的工具。免费版的存在,也让中小团队有机会在零成本的前提下,先验证自己的网络环境和需求是否匹配,再考虑是否升级到更高规格的版本。
技术本身没有「最好」,只有「最合适」。找到适合自己的工具,才是持续运维的第一步。