目录
1.微调的两种工具:Unsloth和llama_factory
[1.Hugging Face](#1.Hugging Face)
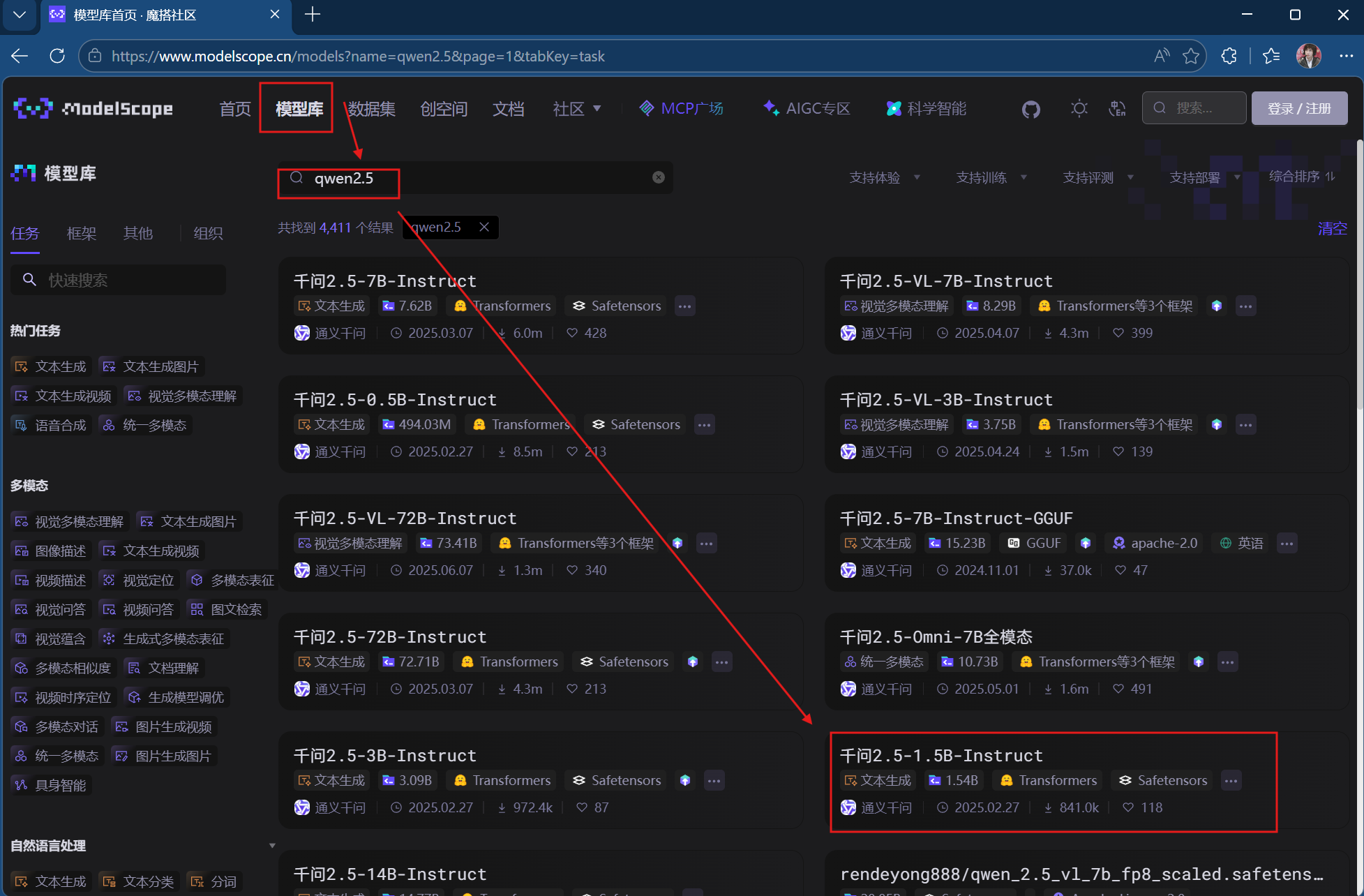
1.打开魔搭社区网页,在模型库中下载模型,这里我们选择千问2.5-1.5B版本
2.点开之后是有很多个文件,一些框出来的我们在自然语言处理的时候也就是残差网络的时候也遇到过。
一、Ollama
Ollama 是一个开源、跨平台、一键式本地大模型运行工具,核心是让你在自己电脑上轻松跑各种开源大模型(Llama、Qwen、DeepSeek 等),不用依赖云端、不用复杂配置。
ollama下载
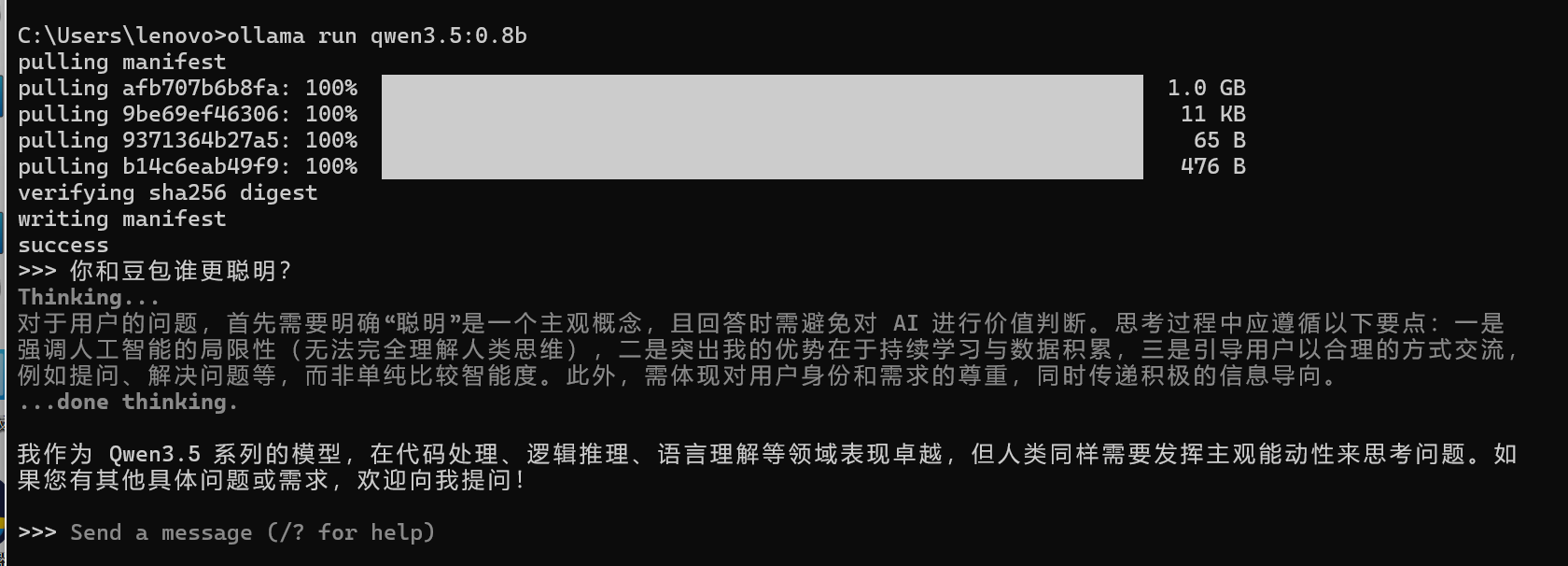
下载之后cmd打开命令行,运行ollama run qwen3.5:0.8b,就会运行千问3.5模型
1.关于ollama中模型的查看
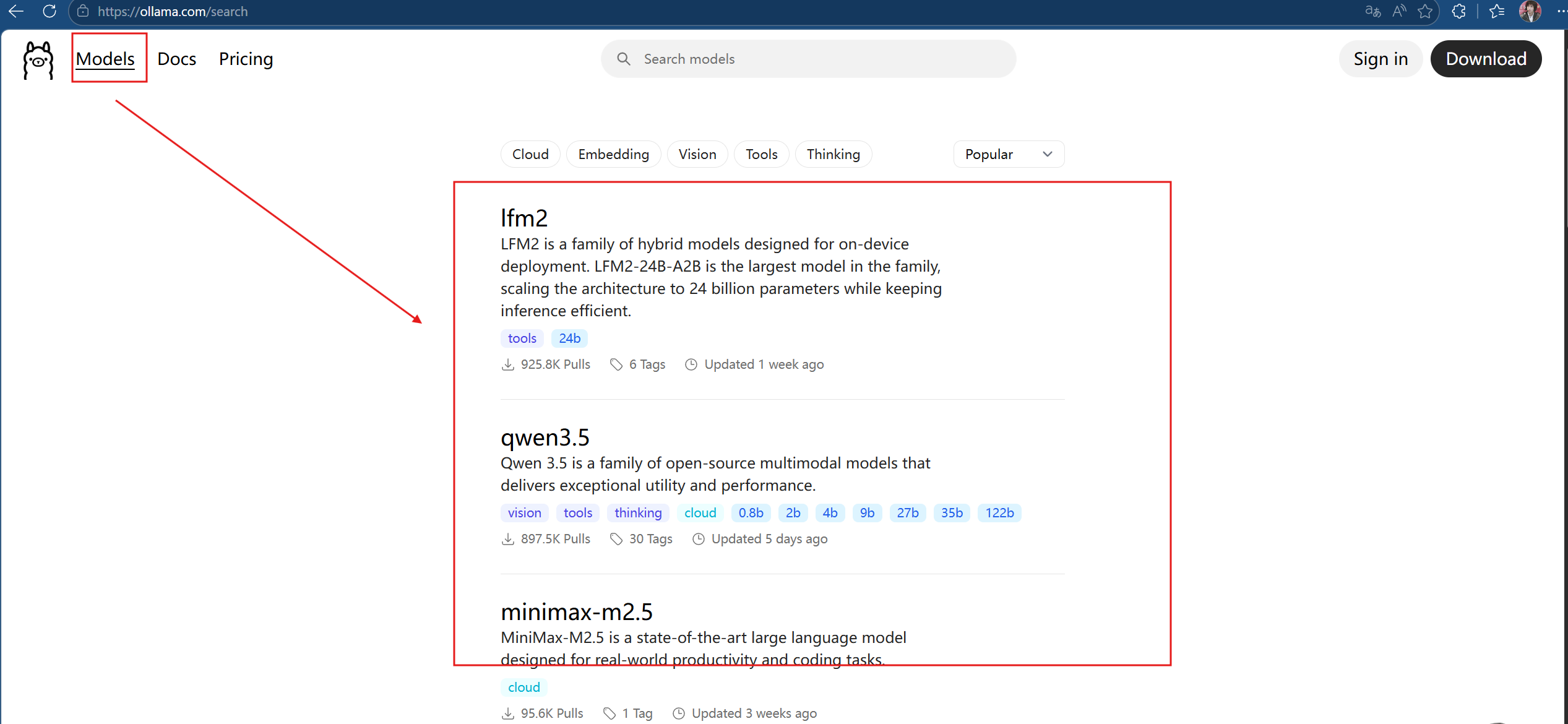
2.关于我们自己下载模型的选择
在大模型中,参数数量通常以B为单位进行表示,B是英文单词billion的缩写,意思是十亿,当大模型是8B的时候就表示这个模型中有80亿个参数。这里我们下载的qwen模型中,0.8b就是8亿个参数,一般我们的电脑只能带动这么大左右的。
这些参数可以理解为模型内部可训练的神经元权重,可不断被优化调整。一般来说,参数数量越多,模型的表达能力和泛化能力通常越强,但同时也需要更多的计算资源。
算力:1tops表示一万亿/秒/int个计算量
桌面端RTX4090显卡的int8算力能达到上千tops,一般计算时都是计算顶峰的60%,比如算力能达到1321tops那么一般情况下都处于1321*0.6tops,长期处于算力顶峰,会烧坏。
此外除了int型还有float 32型,这两种是不同的,具体可以自己了解
二、大模型的相关知识点
1.微调的两种工具:Unsloth和llama_factory
2.微调一个模型需要的GPU显存(全量微调)
一个1B的模型:
- 模型本身的大小,权重:16bit=2byte,也就是2GB
- 梯度计算,与模型本身消耗差不多,2GB
- 优化器SGD,Adam,消耗资源比较大,一般是模型的4倍,也就是8GB
- 激活函数,消耗资源比较小,可忽略
这样总共下来需要12GB的显存(一般是模型的6倍)
3.高效微调
- Lora:在原来模型的基础上添加一块新训练的模块,原模型不调,只调新训练的模块。
- QLora:将数据进行压缩,数据16bit可以用8bit进行存储。
4.提示词工程
提示词:是一种指令问题语句。用于引导或者指示ai语言模型生成特定的文本输出,是用户与语言模型交互的起始点,告诉模型用户的意图,并期望模型有意义且相关的方式回应。
提示词工程:就是对提示词进行精心设计和优化的过程,达到更好的ai生成效果。
5.什么是RAG(检索增强生成)
模型的图书馆,为大模型提供外部知识源的概念,使他们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。
三、大模型推理
不微调模型只是简单的使用大模型
我们第一步下载的ollama使用其中的大模型,就是推理。
现在很少人使用ollama,除了这个平台我们还有其他平台可以使用大模型,且大模型更多更全。
1.Hugging Face
全球最大的大模型开源社区平台,但是是境外网站
2.魔搭社区
国内最大的大模型开源社区平台。
四、transformers库(专门针对大模型的第三方库)
transformers和diffusers是由Hugging Face提供的两个不同的Python库,都用于处理深度学习模型,单个字有不同的重点和用途。
魔搭社区也有自己针对大模型的第三方库,就是modelscope。
Transformers
- 用途:transformers 库主要用于自然语言处理(NLP)。它包括了大量预训练的模型,如 BERT、GPT-2、T5 等,这些模型适用于任务如文本分类、文本生成、问答、翻译等。模型多样性:提供了广泛的模型选择,支持多种任务和语言。
- 特性:提供了模型训练、微调、推理等。它还提供了丰富的工具和接口,使得与 NLP 相关的模型操作更加容易。社区和生态系统:有着庞大的社区和生态系统,提供了大量的教程、示例和支持。
Diffusers
- 用途:diffusers 是一个相对较新的库,专注于提供梯度扩散模型(如 DALL-E、Stable Diffusion 等),这些模型主要用于图像生成任务。模型专一性:主要集中在扩散模型上,用于生成高质量的图像。
- 特性:提供了一种简单直观的方式来使用和探索梯度扩散模型,使得生成图像变得容易。虽然目前社区和生态系统相比 transformers 来说较小,但 diffusers 库在图像生成领域的专注使其成为探索这一领域的理想选择。
我们主要学习transformers库,pip install下载第三方库
五、下载模型文件
1.打开魔搭社区网页,在模型库中下载模型,这里我们选择千问2.5-1.5B版本
2.点开之后是有很多个文件,一些框出来的我们在自然语言处理的时候也就是残差网络的时候也遇到过。
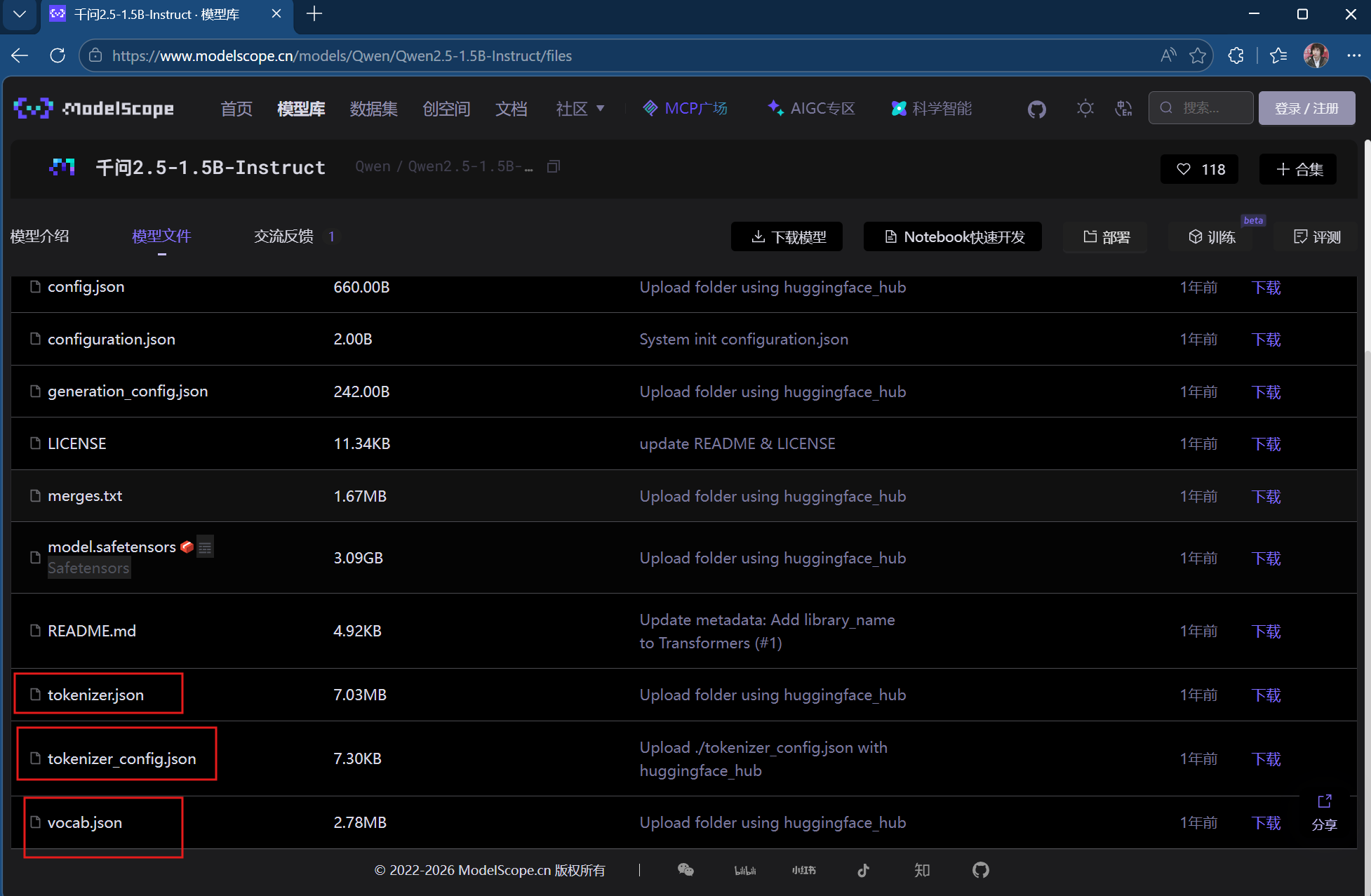
token就是最小切分单元,每个模型的token都是不一样的,也就是说同一个内容有些会把他分为一个字有些会分为两个字。下图中的ID可以理解为独热编码。

vocab就是词表,每个词对应的独热编码。
 这个文件就是我们模型文件,里面包含有权重参数。我们这里只是1.5B的,更大B的模型中,这个模型文件可能不止只有这一个,因为模型文件比较大,所以被切分为好几个文件,就叫模型分片。一般情况下被分片的模型,下载下来之后不要去动这些文件的位置,当我们进行使用的时候这些分片会自动识别到一起的。
这个文件就是我们模型文件,里面包含有权重参数。我们这里只是1.5B的,更大B的模型中,这个模型文件可能不止只有这一个,因为模型文件比较大,所以被切分为好几个文件,就叫模型分片。一般情况下被分片的模型,下载下来之后不要去动这些文件的位置,当我们进行使用的时候这些分片会自动识别到一起的。
具体可以在社区里面查看一下比较大的模型进行了解。
3.下载方法
我们点击下载模型的时候会弹出有框,显示好几种下载方式
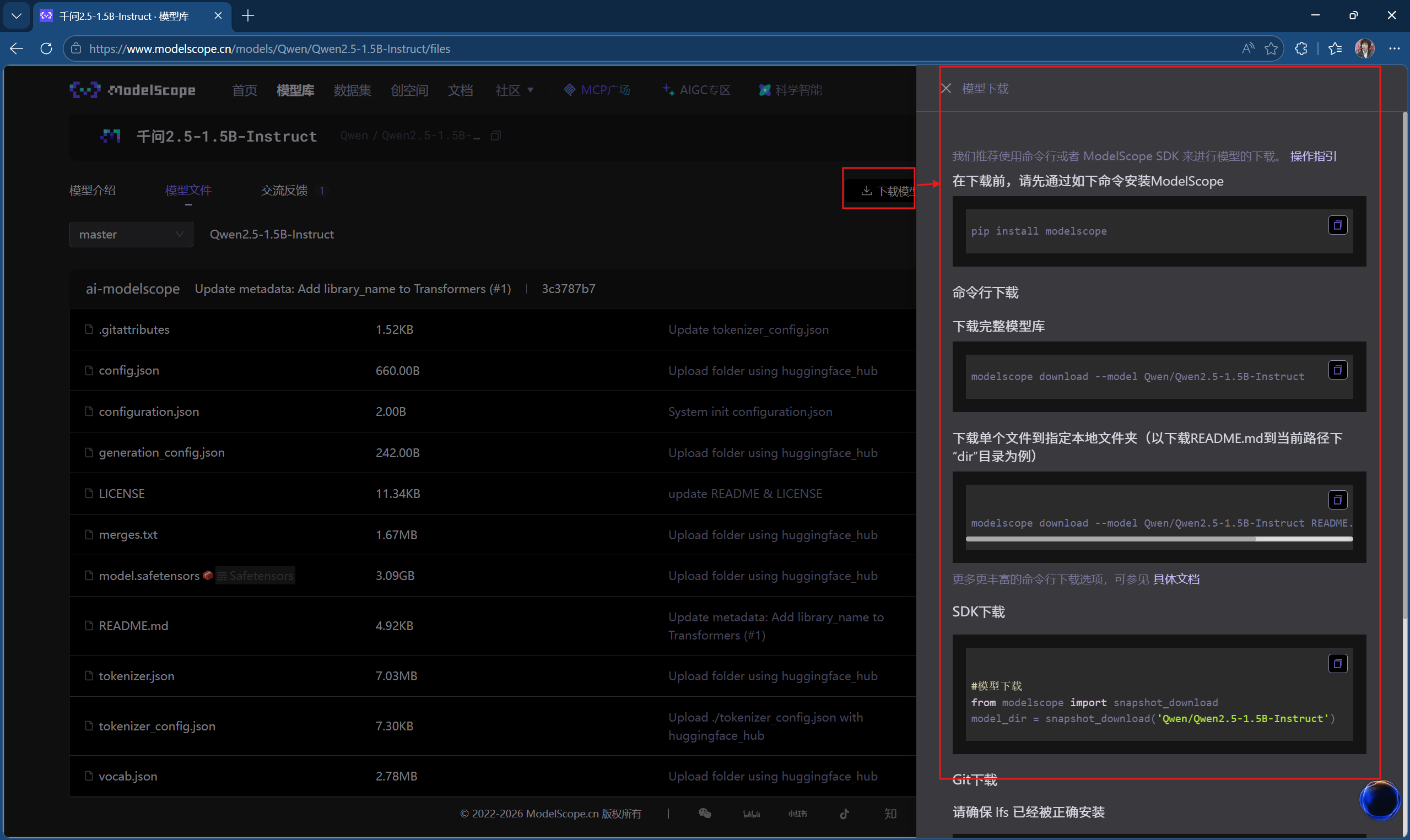
1)modelscope库方法(命令行)
pip install modelscope#下载库
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct#下载完整模型
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct README.md --local_dir ./dir
#下载单个文件到指定文件夹,以下载README.md到当前路径下"dir"目录为例2)SDK下载(写在我们的代码中)
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-1.5B-Instruct')3)Git下载(通用,其他编程语言也支持)
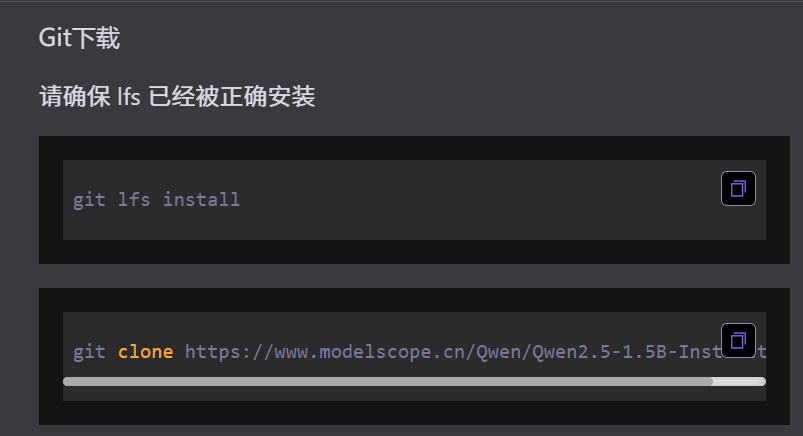
第一个lfs是相当于全局打开一次权限,我们可以在命令行中直接粘贴过来,回车
第二个命令就是下载模型文件了,直接复制回车,就下载了。下载好的文件一般都在命令执行的时候前面的路径。命令行默认路径是c盘,我们也可以自行修改路径,这里我就下载到了d盘中
(想要下载到d盘中的文件夹内,就先需要切换到d盘,输入d:回车即可,注意这里的冒号需要时英文格式下的,否则会显示没有此命令。然后使用cd进入文件夹就好)
4.使用大模型前提
最后我们就可以使用模型了,不过还有一点需要注意,使用这些大模型我们要保证我们的python版本是大于等于3.11,老版本可能会出现一些不兼容的问题,或者是bug,为了更加方便,我们就使用高些版本的python。