论文速览
| 信息 | 内容 |
|---|---|
| 论文标题 | MRAD: Zero-Shot Anomaly Detection with Memory-Driven Retrieval |
| 作者 | Chaoran Xu, Chengkan Lv, Qiyu Chen, Feng Zhang*, Zhengtao Zhang |
| 机构 | 中国科学院自动化研究所、中国科学院大学 |
| 发表 | ICLR 2026(会议论文) |
| 代码开源 | github.com/CROVO1026/M... |
一、一句话概括
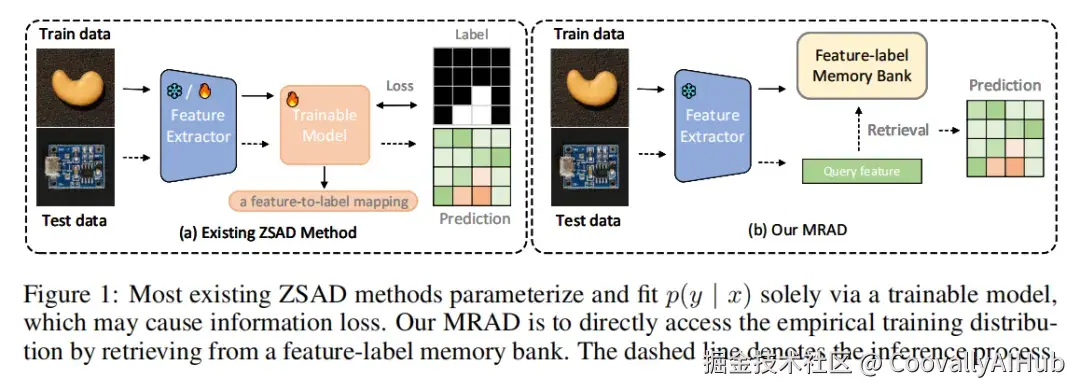
现有 ZSAD 方法通过提示学习拟合数据分布,架构复杂且跨域泛化不稳定。
MRAD 另辟蹊径------冻结 CLIP 编码器,构建双层特征-标签记忆库,推理时直接相似度检索得到异常分数,无需参数拟合。基于此衍生三个递进变体(MRAD-TF / FT / CLIP),在 16 个工业和医学数据集上全面最优,像素级/图像级 AUROC 均达 92.7%,超越 AnomalyCLIP(ICLR'24)和 FAPrompt(ICCV'25)。
二、问题出在哪?现有 ZSAD 方法的三个瓶颈
零样本异常检测的场景需求很明确:产线上新增一种产品、医院遇到新型病变,没有时间先标注一批数据再训练模型。当前主流方案围绕 CLIP + 提示学习展开,但积累了三个共性问题:
图片来源于原论文
瓶颈一:架构越来越复杂
从 WinCLIP 的手工提示,到 AnomalyCLIP 的可学习上下文 token,再到 FAPrompt 的细粒度动态提示,提示学习引入的可训练参数和工程复杂度在持续增加,训练和推理成本水涨船高。
瓶颈二:参数拟合导致信息损失
所有方法最终都把辅助数据的分布信息压缩进一个可训练模块去拟合 p(y|x)。但训练过程不可避免地丢弃部分分布细节------模型只记住了"拟合后的决策边界",而非原始数据中丰富的特征-标签关系。
瓶颈三:跨域泛化不够稳定
动态提示的组合方式对"动态信息来源"很敏感,换一个数据集、换一个域,性能可能出现较大波动,尤其在像素级分割任务上。
MRAD 的出发点:既然预训练特征已经足够好,为什么还要训练一个模型去"学"判别信号?直接查表就行了。
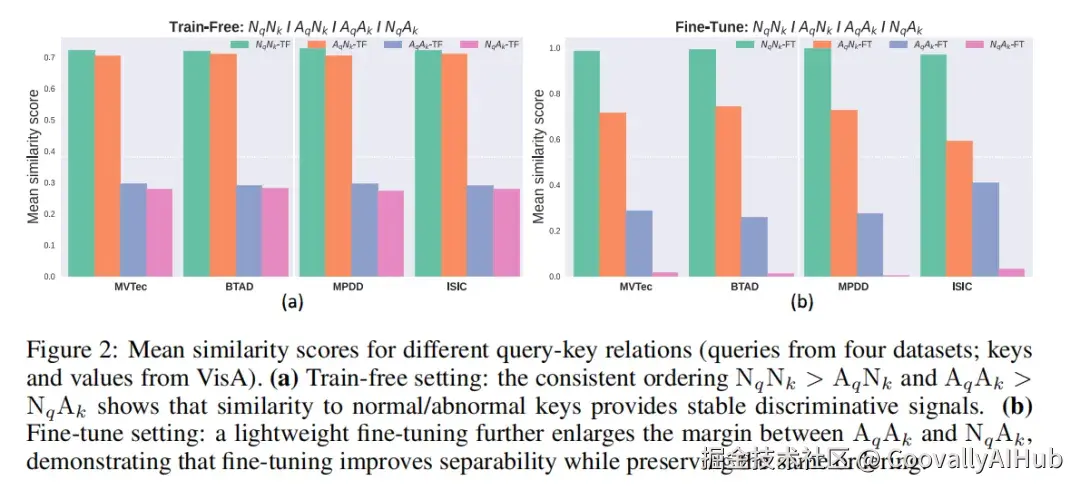
三、核心动机:一个关键的实验观察
MRAD 的方法设计建立在一个跨数据集实验上。
图片来源于原论文
作者冻结 CLIP 图像编码器,从数据集 A 取 patch 特征作为查询(query),从数据集 B 取 patch 特征作为键(key),统计四类相似度均值:
| 符号 | 含义 | 期望 |
|---|---|---|
| NqNk | 正常查询 vs 正常键 | 高 |
| AqAk | 异常查询 vs 异常键 | 高 |
| AqNk | 异常查询 vs 正常键 | 低 |
| NqAk | 正常查询 vs 异常键 | 低 |
结果在所有数据集上一致观察到:NqNk > AqNk 且 AqAk > NqAk。
这说明 CLIP 特征空间中,正常和异常之间的判别信号是跨类别、跨数据集稳定存在的------异常样本相对于正常样本有一个一致的"偏移方向",这个方向不依赖于具体的产品类别。
既然相似度本身就是判别信号,那直接用它来做检测,比再训一个模型去拟合它更直接、信息损失更少。
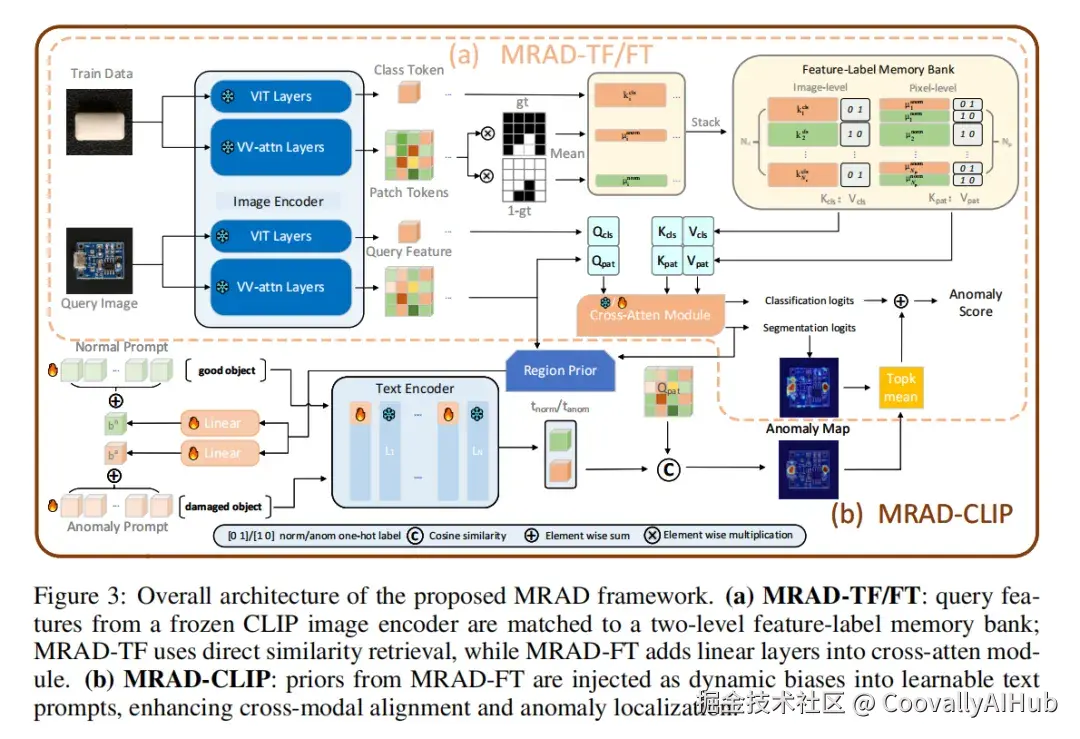
四、方法详解:三个递进的变体
图片来源于原论文
4.1 整体架构
kotlin
┌──────────────────────────────────────────────────────────┐
│ (a) MRAD-TF / MRAD-FT ││ ││ 辅助数据 → 冻结CLIP ViT → class token + patch token ││ ↓ ││ 双层特征-标签记忆库 ││ ┌─ 图像级: K_cls, V_cls (one-hot标签) ││ └─ 像素级: K_pat, V_pat (区域原型+标签) ││ ↓ ││ 查询图像 → 冻结CLIP ViT → Q_cls, Q_pat ││ ↓ ││ Cross-Atten Module(相似度检索) ││ ├─ MRAD-TF: 直接 softmax(QK^T/τ)·V ││ └─ MRAD-FT: softmax((QW_q)(KW_k)^T/τ)·V ││ ↓ ││ 分类 logit + TopK异常图均值 → 最终异常分数 │└──────────────────────────────────────────────────────────┘┌──────────────────────────────────────────────────────────┐│ (b) MRAD-CLIP ││ ││ MRAD-FT 异常图 → 阈值分割 → 正常/异常区域原型 ││ ↓ ││ 线性投影 → 偏置向量 b_n, b_a ││ ↓ ││ 注入可学习文本提示的 context token ││ P_dyn^n = [V_1+b_n]...[good object] ││ P_dyn^a = [V_1+b_a]...[damaged object] ││ ↓ ││ 冻结文本编码器 → t_norm, t_anom ││ ↓ ││ cos(t, Q_pat) → 像素级分割 ││ + TopKMean → 图像级分类 │└──────────────────────────────────────────────────────────┘4.2 MRAD-TF:无训练基线
冻结 CLIP ViT,拆分为全局分支(class token)和局部分支(V-V Attention 输出 patch token)。从辅助数据集提取特征构建双层记忆库:
| 层级 | 键(Key) | 值(Value) | 用途 |
|---|---|---|---|
| 图像级 | 每张图的 class token | 正常/异常 one-hot 标签 | 分类 |
| 像素级 | 异常/正常区域 patch 特征均值(区域原型) | 对应 one-hot 标签 | 分割 |
推理时做 softmax 加权检索,本质是注意力加权的 KNN。其中 V-V Attention 用 value 嵌入替代 Q-K,让 patch token 聚焦局部上下文,有利于异常精确定位。
4.3 MRAD-FT:轻量微调检索度量
只加两个线性层 W_q 和 W_k ,将 QK^T 替换为 (QW_q)(KW_k)^T,训练 BCE + Dice + Focal Loss,1 个 epoch 收敛。
关键设计------相似度 Dropout:训练时遮蔽 QK^T 中 top-ρ% 最高相似度(分割 ρ=20%,分类 ρ=5%),防止自匹配捷径,迫使模型从更难的样本中学习跨类判别。微调后正常/异常相似度间距显著增大。
4.4 MRAD-CLIP:动态提示增强
在 MRAD-FT 基础上引入 CLIP 文本分支。用 MRAD-FT 异常图分割出正常/异常区域原型,投影为偏置向量注入可学习文本提示:
css
P_dyn^n = [V_1+b_n]...[good object]
P_dyn^a = [V_1+b_a]...[damaged object]关键设计是双先验偏置(Dual Prior) ------同时注入正常和异常区域信息,消融实验证明这是最稳定的方案(详见第六章)。训练时只更新文本侧参数,视觉编码器和记忆库冻结,训练 5 个 epoch。
五、实验结果:16 个数据集全面验证
5.1 实验设置
| 配置 | 详情 |
|---|---|
| 数据集 | 8 个工业(MVTec-AD、VisA、BTAD、MPDD、DTD-Synthetic、SDD、KSDD2、DAGM)+ 8 个医学(ISIC、HeadCT、BrainMRI、Br35H、CVC-ColonDB、CVC-ClinicDB、Kvasir、Endo) |
| 评估指标 | 像素级 P-AUROC / PRO,图像级 I-AUROC / I-AP |
| 零样本设置 | 测 MVTec 时用 VisA 做辅助,反之亦然 |
| 骨干网络 | CLIP ViT-L/14-336,输入分辨率 518×518 |
| 硬件 | 单张 NVIDIA RTX 3090(24GB) |
5.2 像素级 ZSAD 结果(P-AUROC% / PRO%,工业域)
| 方法 | 类型 | MVTec-AD | VisA | BTAD | MPDD | SDD | KSDD2 | DAGM | 均值 |
|---|---|---|---|---|---|---|---|---|---|
| WinCLIP | 无训练 | 85.1/64.6 | 79.6/56.8 | 71.4/32.8 | 71.2/48.9 | 55.9/14.7 | 75.4/69.2 | 75.5/44.4 | 73.0/42.9 |
| MRAD-TF | 无训练 | 86.7/63.5 | 91.0/71.0 | 80.5/36.3 | 92.7/76.2 | 85.0/63.0 | 94.9/87.1 | 86.9/66.1 | 85.5/64.6 |
| AdaCLIP | 有训练 | 86.8/33.8 | 95.1/71.3 | 87.7/17.1 | 95.2/10.8 | 79.5/4.9 | 85.8/72.9 | 76.2/56.3 | 85.6/26.2 |
| AnomalyCLIP | 有训练 | 91.1/81.4 | 95.5/87.0 | 93.3/69.3 | 96.2/79.7 | 90.1/62.9 | 97.9/94.9 | 96.5/88.4 | 91.0/75.7 |
| FAPrompt | 有训练 | 90.6/83.3 | 95.9/87.5 | 91.7/69.0 | 96.7/75.9 | 89.3/63.9 | 97.4/93.2 | 95.6/89.1 | 90.7/75.6 |
| MRAD-FT | 有训练 | 92.2/85.4 | 95.9/89.1 | 94.7/74.3 | 97.4/90.6 | 91.0/71.2 | 98.8/89.8 | 96.1/74.9 | 91.9/78.3 |
| MRAD-CLIP | 有训练 | 93.0/86.8 | 95.9/88.0 | 95.4/72.8 | 97.9/90.6 | 93.0/72.0 | 98.9/95.6 | 97.4/90.3 | 92.7/80.1 |
均值为 13 个有像素标注数据集(含工业+医学)的平均,来自论文 Table 1(a)。
5.3 综合对比(16 数据集平均,来自论文 Table 4)
| 方法 | 类型 | 参数量 | 模型大小 | 推理速度 | I-AUROC | P-AUROC |
|---|---|---|---|---|---|---|
| WinCLIP | 无训练 | --- | --- | 840.3ms | 75.1 | 73.0 |
| MRAD-TF | 无训练 | --- | --- | 198.3ms | 81.0 | 85.5 |
| AdaCLIP | 有训练 | 1066万 | 41MB | 226.2ms | 87.8 | 85.6 |
| AnomalyCLIP | 有训练 | 555万 | 22MB | 177.6ms | 90.1 | 91.6 |
| FAPrompt | 有训练 | 961万 | 39MB | 233.1ms | 91.3 | 90.7 |
| MRAD-FT | 有训练 | 275万 | 10MB | 198.8ms | 92.0 | 91.9 |
| MRAD-CLIP | 有训练 | 949万 | 54MB | 203.0ms | 92.7 | 92.7 |
几个关键观察:
-
MRAD-TF(无训练)vs WinCLIP(无训练) :像素级 AUROC 从 73.0% 跳到 85.5%(+12.5%),推理速度反而快了 4 倍多(840ms → 198ms)。不训练就能有这个提升,说明"直接查表"在起点上就有很强的竞争力
-
MRAD-FT vs AnomalyCLIP:可训练参数只有后者的一半(275 万 vs 555 万),模型体积不到一半(10MB vs 22MB),1 个 epoch 收敛,但两个维度都更高
-
MRAD-CLIP:16 数据集平均指标最优,个别数据集上 MRAD-FT 略胜(如 BTAD 图像级),但整体跨域稳定性最好
-
AdaCLIP 的 PRO 指标异常低 (平均仅 26.2%),说明其在定位精度上存在明显短板,MRAD 框架在这个指标上优势尤其突出
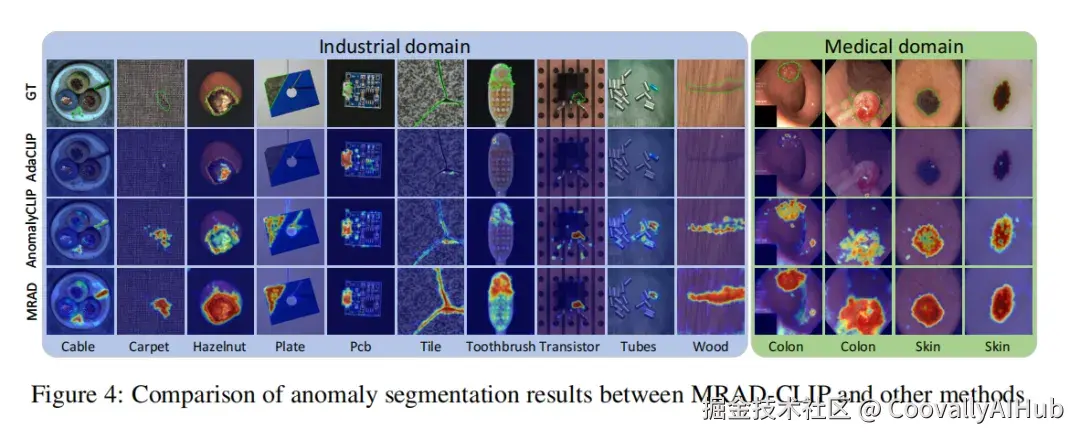
图片来源于原论文
六、消融实验:每个设计都有贡献
6.1 三个变体的递进提升
逐步叠加组件的效果(I-AUROC 为 16 数据集平均,P-AUROC/PRO 为 13 个有像素标注的数据集平均,均来自论文 Table 1 和 Table 4):
| 变体 | P-AUROC | PRO | I-AUROC | 新增内容 |
|---|---|---|---|---|
| MRAD-TF | 85.5 | 64.6 | 81.0 | 双层记忆库 + 直接检索 |
| MRAD-FT | 91.9 (+6.4) | 78.3 (+13.7) | 92.0 (+11.0) | + 两个线性层 + 相似度 Dropout |
| MRAD-CLIP | 92.7 (+0.8) | 80.1 (+1.8) | 92.7 (+0.7) | + 双先验动态提示 |
TF → FT 的提升最大,说明轻量微调检索度量是核心增益来源;CLIP 在此基础上进一步提升定位精度(PRO +1.8)。每一步都有稳定提升,没有在任何数据集上出现回退。
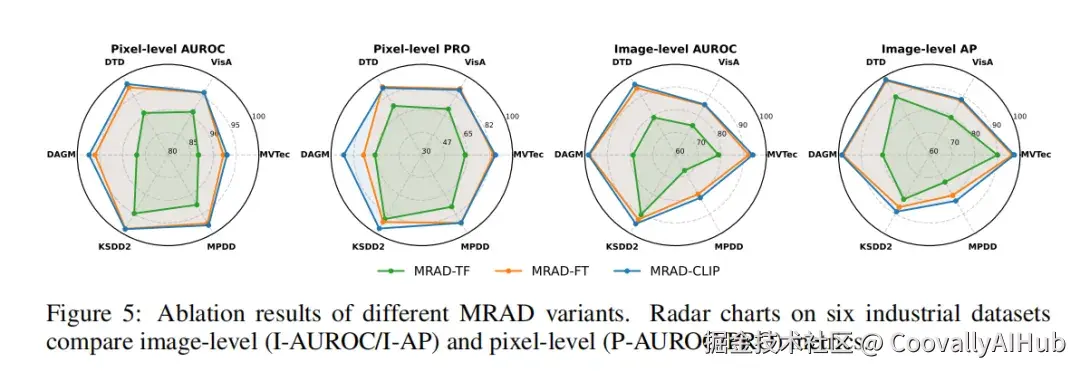
图片来源于原论文
6.2 动态提示偏置来源对比
| 偏置来源 | MVTec P-AUROC/PRO | VisA P-AUROC/PRO | 分析 |
|---|---|---|---|
| 无偏置(静态) | 91.5 / 82.9 | 95.6 / 87.3 | 等价于 AnomalyCLIP |
| Class token | 86.2 / 54.9 | 95.1 / 86.8 | 全局特征太粗,分割严重下降 |
| Cross-patch | 92.5 / 85.7 | 95.3 / 88.6 | 区域级上下文有帮助 |
| 双先验 | 93.0 / 86.8 | 95.9 / 88.0 | 最稳定,正常+异常信息互补 |
全局 class token 做偏置反而严重损害分割性能(MVTec PRO 从 82.9 暴跌至 54.9),局部区域感知的双先验偏置是最优选择。
6.3 记忆库规模消融
论文在 MVTec-AD 上对 patch 记忆库进行随机子采样(Figure 6),随着条数减少,性能平滑下降但幅度很小。论文原文描述为"smooth but minor decline"。方法对记忆库规模不敏感,利于实际部署。
七、方法亮点总结
| 亮点 | 说明 |
|---|---|
| 记忆检索替代参数拟合 | 保留辅助数据的完整特征-标签分布,避免拟合过程中的信息损失 |
| 双层记忆库 | 图像级(class token)+ 像素级(区域原型),同时支持分类和分割 |
| V-V Attention | 让 patch token 聚焦局部上下文,减少全局 token 主导导致的定位偏差 |
| 相似度 Dropout | 屏蔽训练时的自匹配捷径,增强跨类判别学习 |
| 双先验动态提示 | 将正常/异常区域先验注入文本提示,提示随输入图像动态变化 |
| 渐进式设计 | TF → FT → CLIP 三个变体层层递进,按需选用 |
| 极低训练成本 | MRAD-FT 仅 275 万参数、1 epoch 收敛、10MB 模型 |
八、局限性与未来方向
- 依赖辅助数据集:MRAD 的"零样本"是指目标域零标注,但仍需一个有标注的辅助数据集构建记忆库。论文已验证了工业↔医学的跨域迁移,结果整体正向,但辅助集的选择对不同目标域的影响仍值得进一步研究
- 在线/增量场景:论文作者在结论中也提到,当前框架尚未支持在线或增量更新记忆库。工业场景中产品迭代频繁,支持动态扩展记忆库是一个有价值的未来方向