文章目录
- 前言
- [1. Overview:集群总览与健康监控](#1. Overview:集群总览与健康监控)
-
- [1.1 功能定位](#1.1 功能定位)
- [1.2 核心指标解析](#1.2 核心指标解析)
- [1.3 实战应用场景](#1.3 实战应用场景)
- [2. Jobs:作业生命周期管理](#2. Jobs:作业生命周期管理)
-
- [2.1 Running Jobs:运行中作业监控](#2.1 Running Jobs:运行中作业监控)
-
- [2.1.1 作业列表视图](#2.1.1 作业列表视图)
- [2.1.2 作业详情页](#2.1.2 作业详情页)
- [2.2 Completed Jobs:历史作业复盘](#2.2 Completed Jobs:历史作业复盘)
-
- [2.2.1 作业分类](#2.2.1 作业分类)
- [2.2.2 异常排查](#2.2.2 异常排查)
- [2.3 实战应用场景](#2.3 实战应用场景)
- [3. Task Managers:计算节点深度剖析](#3. Task Managers:计算节点深度剖析)
-
- [3.1 列表视图:节点资源总览](#3.1 列表视图:节点资源总览)
- [3.2 详情视图:单节点深度监控](#3.2 详情视图:单节点深度监控)
- [3.3 实战应用场景](#3.3 实战应用场景)
- [4. Job Manager:Master 节点系统视图](#4. Job Manager:Master 节点系统视图)
-
- [4.1 功能定位](#4.1 功能定位)
- [4.2 核心内容](#4.2 核心内容)
- [4.3 实战应用场景](#4.3 实战应用场景)
- [5. Submit New Job:作业提交与参数配置](#5. Submit New Job:作业提交与参数配置)
-
- [5.1 页面布局](#5.1 页面布局)
- [5.2 实战应用场景](#5.2 实战应用场景)
- [6. 总结与最佳实践](#6. 总结与最佳实践)
-
- [6.1 各菜单快速索引](#6.1 各菜单快速索引)
- [6.2 学习建议](#6.2 学习建议)
前言
在 Apache Flink 的生态体系中,Web UI 是开发者和运维人员最常用的可视化工具之一。无论是监控作业状态、调试任务失败原因,还是评估集群资源使用情况,Flink UI 都提供了直观且强大的支持。然而,对于初学者来说,面对 Overview、Jobs、Task Managers 等菜单项,往往不清楚每个页面的具体作用和使用场景。
本文将深入剖析 Flink Web UI 的每一个菜单项,从功能定义、页面布局到实战应用场景,帮助你全面掌握这一核心工具。如果你本地已经启动了 Flink(访问 http://localhost:8081),可以一边阅读一边对照操作,效果更佳。
1. Overview:集群总览与健康监控
1.1 功能定位
Overview 页面是 Flink 集群的仪表盘,当你第一次访问 Web UI 时,首先看到的就是这个页面。它提供了整个集群的宏观视图,包括运行状态、资源配置和底层网络指标。
1.2 核心指标解析
进入 Overview 页面,你会看到以下几个关键区域:
-
集群概要
- JobManager:显示当前活跃的 JobManager 地址和版本信息(如 Flink 版本号、Commit ID)。
- 运行时间:集群从启动到现在的持续时间,可用于判断集群是否近期重启过。
-
资源使用情况
- Task Slots:总槽位数与已使用槽位数。Task Slot 是 Flink 中定义的最小资源单元,一个 Task Slot 可以执行一个并行子任务。这个比例直接反映了集群的资源利用率。
- 可用内存:JobManager 当前可用的堆内存和非堆内存情况。
-
系统指标
- 网络缓冲池:显示网络缓冲区的使用情况,如果这里出现大量等待或超限,可能意味着网络 I/O 存在瓶颈。
1.3 实战应用场景
场景一:集群健康检查
运维人员每天上班第一件事,就是查看 Overview 页面。通过 Task Slots 使用率和可用内存变化,可以快速判断集群是否处于健康状态。
场景二:资源规划
在提交新作业前,先查看 Overview 的空闲 Slot 数量,确认是否有足够资源运行新任务,避免因资源不足导致作业排队或失败。
2. Jobs:作业生命周期管理
Jobs 菜单是 Flink UI 中使用频率最高的模块,它下面分为两个子页面:Running Jobs 和 Completed Jobs,分别对应运行中和已结束的作业。
2.1 Running Jobs:运行中作业监控
2.1.1 作业列表视图
进入 Running Jobs,你会看到当前所有正在执行的作业列表,包含以下信息:
- Job ID:作业的唯一标识符,在日志和命令行中经常用到。
- 作业名称:提交作业时指定的名称。
- 状态:通常显示为 RUNNING。
- 开始时间:作业启动的时间戳。
- 运行时长:作业已经运行了多久。
2.1.2 作业详情页
点击具体的作业名称,将进入该作业的详情页,这是调试和监控的核心战场。
① 拓扑视图
这是最直观的部分,以 DAG(有向无环图)形式展示作业的执行计划。你可以看到:
- 数据流向:Source → Transformation → Sink 的完整链路。
- 并行度 :每个算子旁边显示的数字,如
Map (4/4)表示 Map 算子的并行度为 4。 - 数据交换:算子之间的数据分区方式(如 KeyBy、Rebalance 等)。
② 指标看板
点击任意算子节点,右侧会弹出该算子的实时指标:
- 接收/发送记录数:算子处理的数据量。
- 接收/发送字节数:网络传输的数据大小。
- 背压指标:通过颜色(OK/LOW/HIGH)直观显示背压状态,红色表示下游处理速度跟不上上游发送速度。
③ Checkpoint 历史
点击顶部导航的 Checkpoints 标签,可以查看作业的 Checkpoint 历史记录:
- 最新 Checkpoint:最近一次成功的 Checkpoint 时间点。
- 失败记录:如果 Checkpoint 频繁失败,这里会显示失败原因,是排查状态一致性问题的关键入口。
2.2 Completed Jobs:历史作业复盘
2.2.1 作业分类
Completed Jobs 页面集中展示了所有已终止的作业,按结束状态分为三类:
- FINISHED:正常执行完毕的作业。
- CANCELED:手动取消的作业。
- FAILED:执行过程中出现异常的作业。
2.2.2 异常排查
点击 FAILED 状态的作业,进入详情页后重点关注:
- Exceptions 标签:这里会记录作业失败的完整堆栈信息,是定位代码 bug 的第一手资料。
- Task Metrics:查看失败前的指标趋势,可能发现内存溢出或数据倾斜的迹象。
2.3 实战应用场景
场景一:实时监控作业健康度
开发者在 Running Jobs 中持续观察背压指标和 Checkpoint 成功率,一旦发现背压持续 HIGH,立即分析对应算子的处理逻辑,优化性能瓶颈。
场景二:深夜故障排查
早上到岗发现作业失败,打开 Completed Jobs 找到 FAILED 作业,直接查看 Exceptions 堆栈,无需重复跑任务就能定位问题。
3. Task Managers:计算节点深度剖析
3.1 列表视图:节点资源总览
Task Managers 页面展示了所有参与计算的节点(或容器)信息:
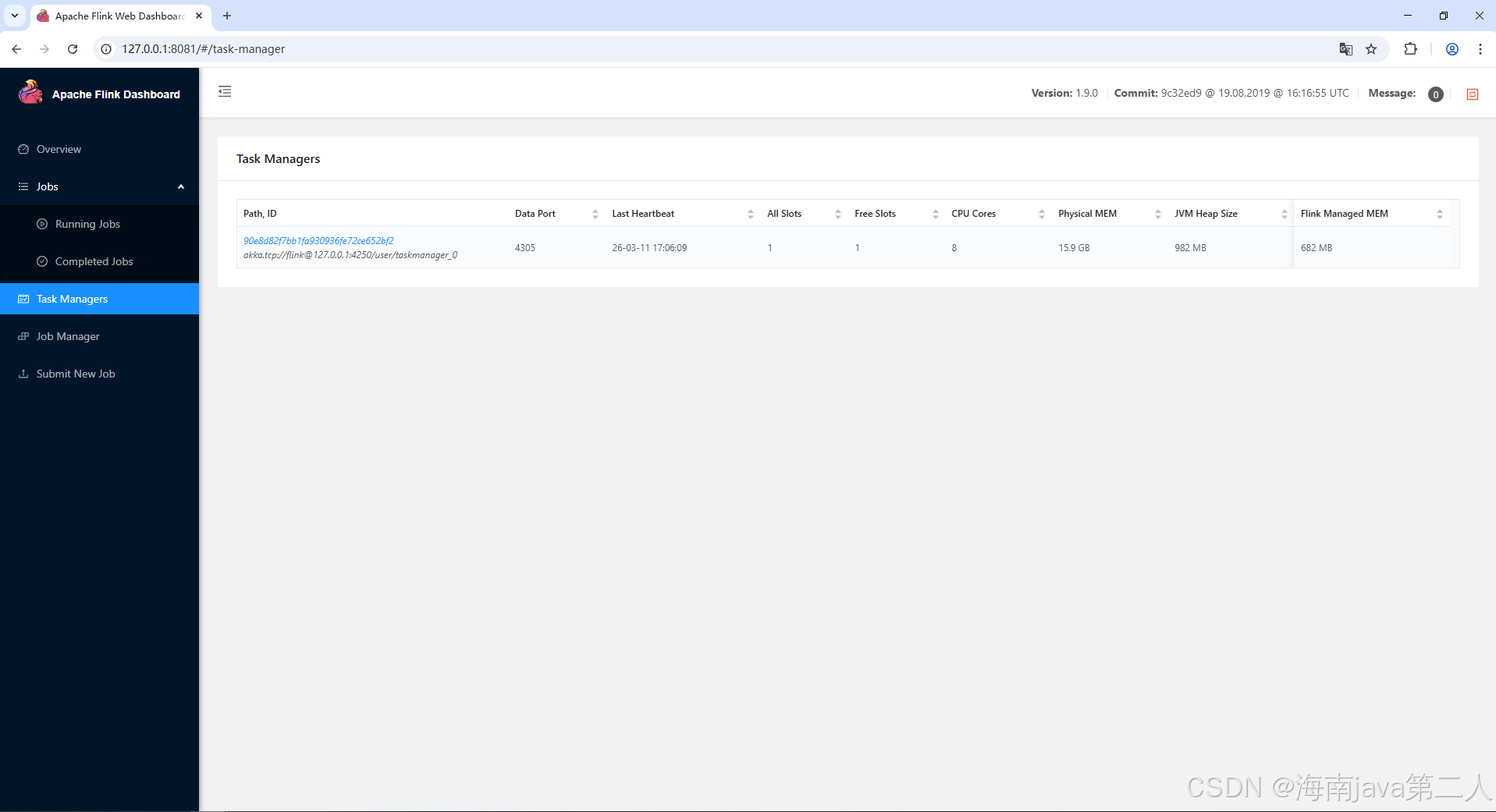
- TaskManager ID:节点的唯一标识。
- 地址:节点的 IP 和端口。
- 状态:通常为 RUNNING。
- Slots:该节点的总 Slot 数/已用 Slot 数。
- 内存:该节点当前使用的堆内存量。
- 磁盘/网络:底层资源使用情况。
3.2 详情视图:单节点深度监控
点击任意 TaskManager ID,进入详情页:
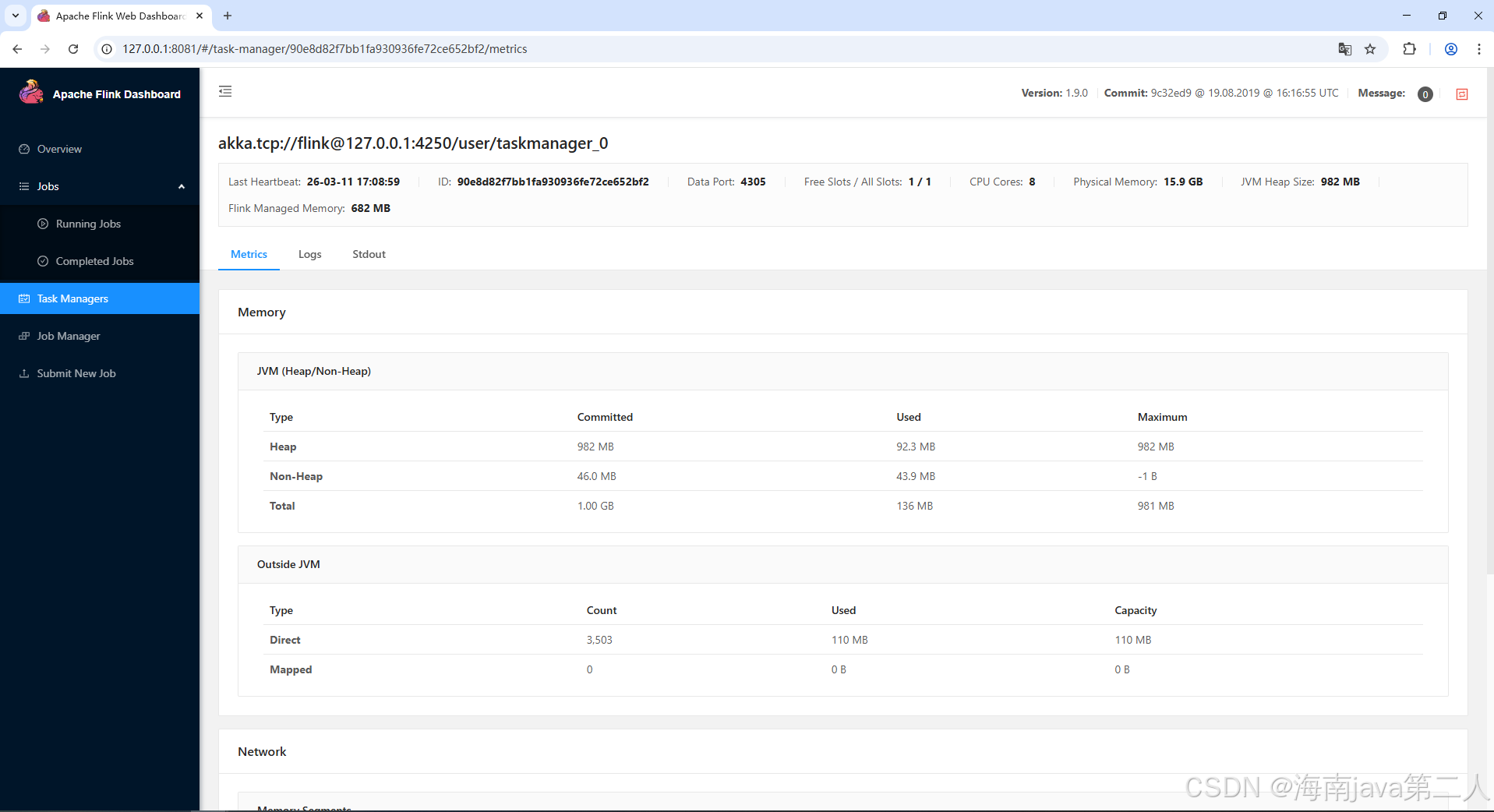
① Metrics 标签
展示该节点的实时性能指标:
- Heap Memory:堆内存使用趋势,如果持续上涨且不回落,可能存在内存泄漏风险。
- Garbage Collection :GC 时间和次数,频繁的 Full GC 会影响处理性能。
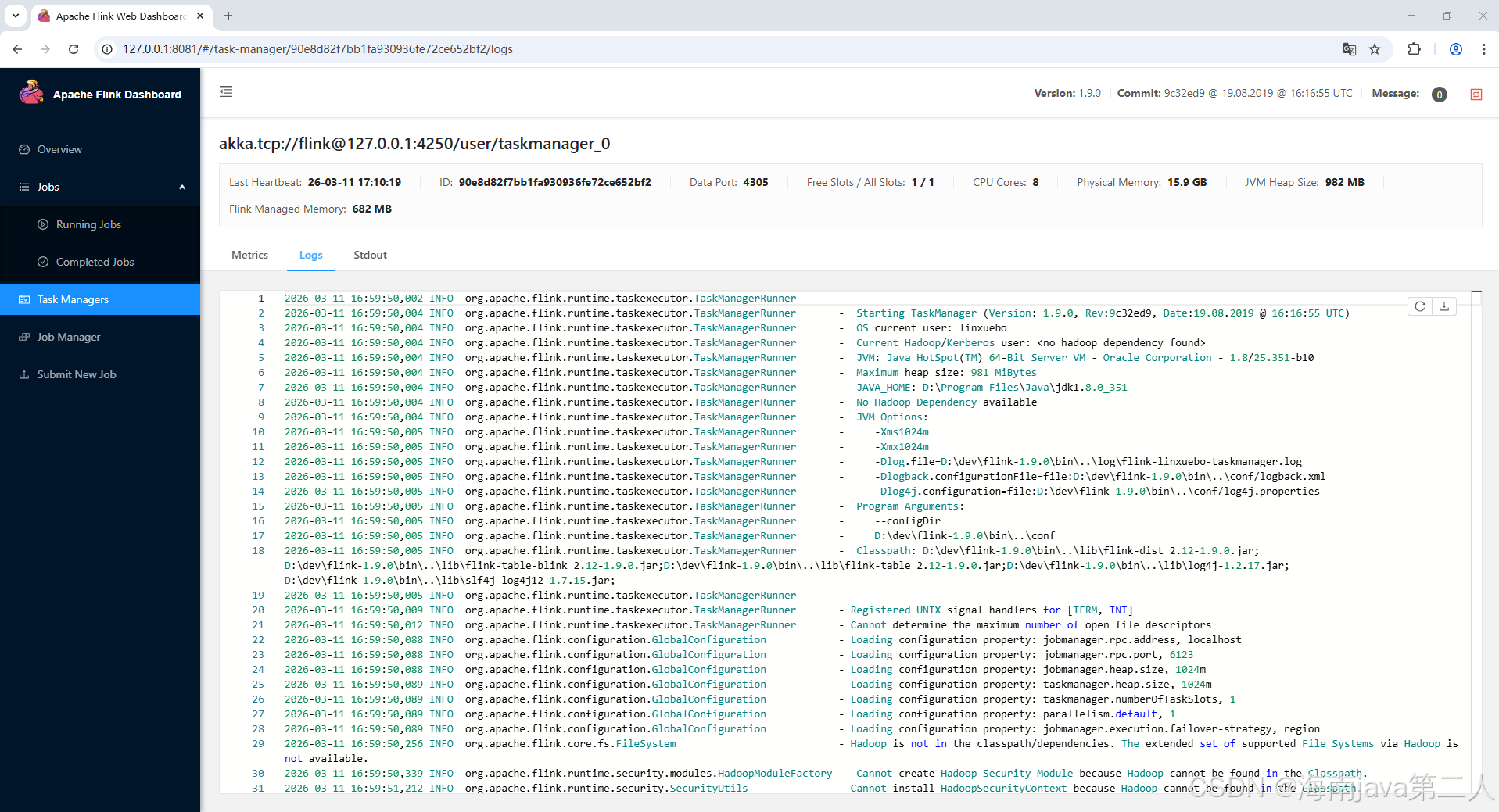
② Logs 标签
这是排查任务级错误的关键位置。当某个 Subtask 运行异常时,对应的 TaskManager 日志中会记录详细的错误信息。
3.3 实战应用场景
场景一:定位数据倾斜
在 Running Jobs 中发现某个算子处理速度明显慢于其他算子,进入 Task Managers 查看对应节点的 CPU 和内存使用率,如果某个节点负载显著高于其他节点,大概率发生了数据倾斜。
场景二:内存泄漏排查
作业运行一段时间后频繁 GC 甚至崩溃,进入 Task Managers 查看各节点的堆内存趋势,锁定内存持续增长的节点,结合日志分析具体原因。
4. Job Manager:Master 节点系统视图
4.1 功能定位
Job Manager 页面展示的是 Flink 集群主节点的信息,主要包括配置参数和系统日志。与 Task Managers 不同,这里关注的是集群层面的状态,而非具体任务。
4.2 核心内容
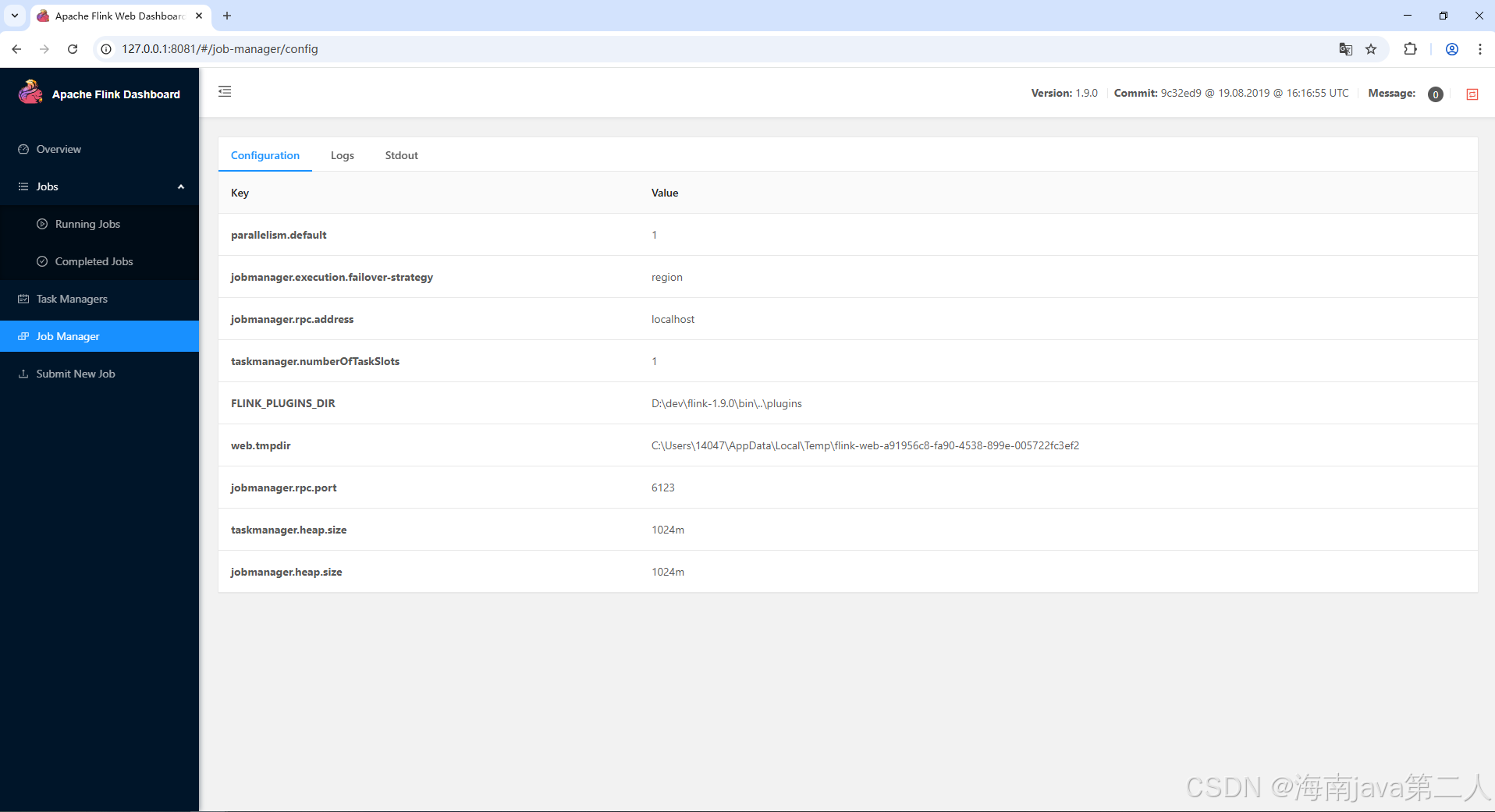
-
Configuration 标签
显示 JobManager 启动时加载的所有配置项,包括
flink-conf.yaml中的参数。当需要确认某个配置是否生效时,可以来这里核对。 -
Logs 标签
JobManager 的系统日志,记录集群启动、作业提交、资源分配等事件。如果作业提交失败且 Running Jobs 中看不到异常,大概率是 JobManager 层面的问题,需要查看这里的日志。
-
Stdout 标签
JobManager 的标准输出,通常包含系统启动时的控制台打印信息。
4.3 实战应用场景
场景一:配置生效验证
修改了 flink-conf.yaml 中的 jobmanager.rpc.address 后重启集群,进入 Job Manager Configuration 页面搜索该配置项,确认新值已生效。
场景二:集群启动问题排查
Flink 集群启动失败,Web UI 无法访问?如果无法访问 UI,需要查看启动命令行的日志输出;如果 UI 能打开但作业提交报错,优先查看 Job Manager Logs。
5. Submit New Job:作业提交与参数配置
5.1 页面布局
Submit New Job 页面提供了一个可视化的作业提交入口,包含三个主要区域:
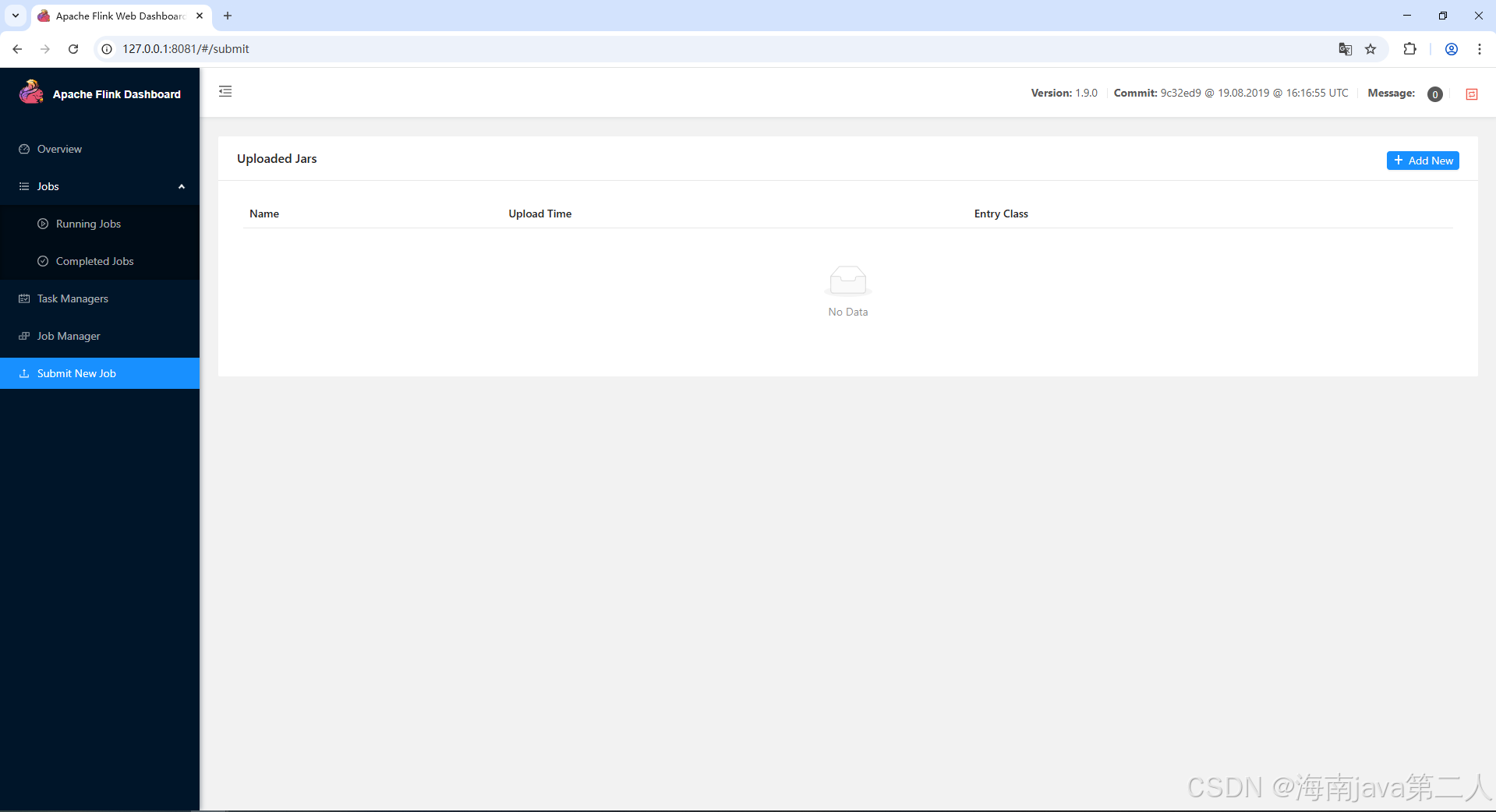
① JAR 上传区
点击 "Add New" 按钮,选择本地编译好的 Flink 任务 JAR 包。上传成功后,页面会自动解析 JAR 包中的可执行类。
② 执行参数配置
- Entry Class:选择或填写程序入口类(包含 main 方法的类)。
- Program Arguments :传递运行时参数,如
--input file:///data/input.txt --output file:///data/output。 - Parallelism:设置整个作业的默认并行度。
- Savepoint Path:如果要从指定 Savepoint 恢复作业,在这里填写路径。
③ 提交按钮
配置完成后,点击 "Submit" 即可将作业提交到集群运行。
5.2 实战应用场景
场景一:快速测试本地 JAR
开发完成后,在本地打包成 JAR 文件,通过 Submit New Job 上传并配置参数,无需命令行即可快速验证功能。
场景二:从 Savepoint 恢复
作业需要停机维护,但希望保留状态。先在命令行触发 Savepoint,然后在 Submit New Job 页面填写 Savepoint 路径,提交后作业将从该状态点继续处理。
6. 总结与最佳实践
6.1 各菜单快速索引
| 菜单 | 核心用途 | 最佳实践场景 |
|---|---|---|
| Overview | 集群健康监控 | 每日巡检、资源规划 |
| Running Jobs | 实时作业调试 | 背压监控、Checkpoint 跟踪 |
| Completed Jobs | 历史问题复盘 | 异常堆栈分析 |
| Task Managers | 节点级问题定位 | 数据倾斜、内存泄漏排查 |
| Job Manager | 系统级配置与日志 | 配置验证、集群故障排查 |
| Submit New Job | 可视化作业提交 | 快速测试、Savepoint 恢复 |
6.2 学习建议
-
本地实操 :在本地启动 Flink(
./bin/start-cluster.sh或 Windows 下双击start-cluster.bat),提交一个示例作业(如 WordCount),逐一点击每个菜单,对照本文内容加深理解。 -
异常模拟:尝试提交一个会抛出异常的作业,观察 Completed Jobs 中的错误堆栈,熟悉异常排查流程。
-
指标关联:在 Running Jobs 中发现背压时,立即去 Task Managers 查看对应节点的资源使用情况,建立问题关联思维。
如需获取更多关于 Flink 流处理核心机制、状态管理与容错、实时数仓架构等深度解析,请持续关注本专栏《Flink核心技术深度与实践》系列文章。